基于公共詞集對長篇小說相似度的研究
2018-12-21 01:56:22郭濤霸元婕李紹昂
軟件工程 2018年10期
郭濤 霸元婕 李紹昂


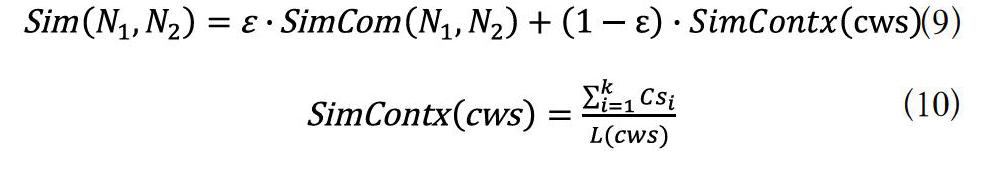
摘 要:傳統的文本相似度計算基于向量空間模型(VSM),文本映射成獨立的、互不關聯的詞構成的向量。由于長篇小說具有比普通文本更為復雜的構成元素,以及更加緊密的上下文聯系,傳統算法忽略詞項的上下文聯系,并且產生高維向量,因此算法的效率和精度不理想。為此,本文基于公共詞集對長篇小說進行相似度計算,并對公共詞集進行上下文約束檢查,得到關聯比較緊密的詞集,作為小說的主要特征。實驗結果表明,對于某些小說類型,效果有很大的提升。
關鍵詞:公共詞集;小說相似度;上下文約束
中圖分類號:TP391.1 文獻標識碼:A
Abstract:Traditional text similarity computation is based on Vector Space Model (VSM),where the text is mapped into independent and unrelated words.Because novels have more complex elements and much closer context than ordinary texts,the traditional algorithm ignores the context of the words and produces the high dimensional vector,so that the efficiency and accuracy of the algorithm are not ideal.For this reason,this paper calculates the similarity of the novels based on the common word set,and carries out the context constraint check on the common word set to achieve a more closely related word set as the main feature of the novel.The experimental results show that for some types of novels,the effect is greatly improved.
Keywords:common word set;novel similarity;context constraint
1 引言(Introduction)
隨著互聯網技術的發展,網絡上的文本數據呈現爆炸式增長,文本處理算法的相關研究也隨之發展起來。其中,文本相似度計算成為熱點研究方向,其目的在于建立一個合理的衡量模型,對文本間的相似程度進行量化。小說作為一種文學作品,與普通文本有較大區別,小說的構成要素要比普通文本復雜很多,比如時間、地點、人物、社會、環境等等,并且小說的上下段落、上下情節之間聯系十分緊密。所以,必須要從新的角度建立小說相似度的衡量模型。
目前經典的文本相似度計算算法大部分基于向量空間模型(VSM)[1]。向量空間模型將文本視作由獨立的、互不關聯的詞構成的一個向量,并且把詞語在文中出現的頻數作為文本的主要特征。通過將文本映射成一個向量模型,文本相似度計算也就轉換成向量之間的相似度計算。小說作為一種特殊的文本類型,詞語之間的關聯比普通的文本更加緊密,如果依然將小說表示成向量空間模型,將失去很多重要的特征信息,尤其是詞條間的上下文信息,詞語之間的關聯隱含著情節信息,對文義的理解起著至關重要的作用[2]。不僅如此,對于長篇小說而言,向量空間模型將產生一個維數十分巨大的向量,嚴重影響算法的效率,問題將變得不可行。
本文主要介紹了一種基于公共詞集對長篇小說相似度研究的算法[3]。對小說進行預處理后,建立Map映射結構,在構建公共詞集的過程中,加入上下文約束,最終得到滿足上下文約束的若干詞集簇,并以此作為衡量相似度的依據,建立相似度衡量算法,并通過實驗驗證算法可行。
2 相關工作(Related work)
2.1 向量空間模型
文本的內容特征常常用它所含有的基本語言單位,如字、詞或者短語等來表示,這些基本的語言單位被統稱為文本的項[4]。向量空間模型(Vector Space Model,VSM)將文本D轉化為由詞項w構成的m維向量,即:
文本中的每個項相互獨立,可以通過計算向量之間的距離來衡量文本之間的相似度。每個詞項往往都賦予一個權重(Term Weight),表示該詞項在文本中的重要程度。TF-IDF(Term Frequency-Inverse Document Frequency)是使用最廣泛的一種權重計算方法,公式如下:
其中,表示詞項的出現頻數,表示文檔集中文本數量,表示詞項在文檔集中包含該詞項的文本數量。
在文本中的出現頻率反映該詞項的重要程度,詞項在多個文本中的出現情況反映了詞項的文義甄別能力,TF-IDF綜合考慮了以上兩點,每一個詞項的權重由TF權值和IDF權值兩個部分組成。通過計算向量之間的余弦角,可以得到兩個文本向量之間的相似程度,定義如下:
2.2 公共詞集
從小說的詞法方面研究其文本特征,如果不考慮詞項之間的先后順序,可以比較小說詞域之間的相交程度來衡量相似度。將小說的詞集提取出來,兩篇小說的公共詞集可以反映小說在用詞造句方面的相似性[5]。相對于兩篇小說的平均文本長度而言,如果公共詞集包含的詞項數越多,小說的相似程度越高,兩篇小說的用詞方式更為接近;反之,若公共詞集包含的詞項數越少,相似程度越低。在對小說進行文本預處理操作后,分別統計詞項的頻數和位置信息,可以得到小說N1和N2的公共詞集CWS,公共詞集中的元素由詞項和詞項在小說中的頻數構成。可以用采取如下計算公式計算相似度:
