基于二次映射的哈希負載均衡方法
2018-12-24 03:26:34王永亮
信息記錄材料 2018年12期
王永亮
(華為軟件技術有限公司南京研究所江蘇南京 210012)
1 引言
在互聯網應用中,面對海量的數據,通常采用分布式集群服務器進行數據存儲,不可避免的面臨集群服務器之間的負載均衡問題。同時集群服務器之間可能是異構的,更是增加了負載均衡的難度,本文描述一種基于二次映射的哈希(Hash)負載均衡方法,能夠很好的支持同構或者異構的存儲服務器集群的負載均衡。
2 基于二次映射的哈希負載均衡設計
負載均衡策略分為靜態負載均衡策略和動態負載均衡策略,靜態負載均衡策略實現簡單、方便,如果規劃設計合理就能達到良好的效果;動態負載均衡策略根據系統的負載情況動態的進行調整,較靈活,但是實現復雜。
由于存儲系統涉及到數據的增刪改查,服務器集群各個節點有狀態、不對等,因此存儲系統的負載均衡算法和普通的無狀態的集群負載均衡算法不同;在存儲系統中,較廣泛使用哈希算法對數據請求進行靜態負載均衡,這種方式能解決大多數的問題,但是在服務器集群擴容或者縮容時,通常需要進行大量的數據遷移;并且難以適應服務器異構的情況;一致性哈希算法是對普通哈希算法的改進,在擴容或者縮容時能較少的進行數據遷移,但是并不能方便的對熱點數據進行精準的控制,并且如果前期規劃的數據槽位或者哈希函數的選擇不合理,針對熱點數據的處理會有極限。
在基于二次映射的哈希負載均衡算法中,所有的數據請求根據一級哈希函數映射到不同的分區Section,然后對分區Section再次進行二級哈希映射,將映射到同一分區Section的數據關鍵字映射到不同的槽位Slot上;槽位Slot和服務器Node之間通過Map表進行關聯;將數據進行分區,各個分區互不影響;將同一分區中的數據進行分槽位映射,可以針對數據熱點分區增加槽位;槽位和服務器節點進行Map映射,可以控制各個服務器節點分配的槽位和槽位數量。因此此算法可以方便的處理數據熱點和負載不均的問題。
2.1 數據模型
此算法的數據模型如圖2-1所示。
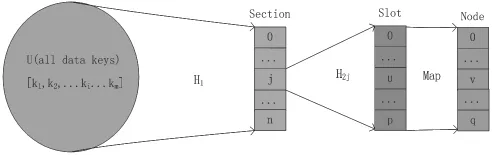
圖2-1 數據模型
所有的數據請求的key∈U,U=[k1,k2,ki,…,km],其中m為不同的key的個數;請求數據key與分區Section的關系為:j=H1(ki),其中j∈[0,n],i∈[0,m],H1為選定的一級Hash函數,j為第j個分區Section,ki為第i個key;
每個分區映射到多個槽位Slot,設第j個分區section映射到p個槽位上,數據key與槽位Slot的關系為:u=H2j(Kij)其中u為第j個分區的第u個槽位Slot,kij滿足j = H1(kii),H2j為分區j選定的二級Hash函數;
一級Hash函數和各個分區的二級Hash可以從某一全域Hash函數族中隨機選擇,這樣可以確保在二級Hash后減少Hash沖突。
服務器節點Node與槽位Slot的關系為Map表映射,可人為配置或者自動配置,類似如表2-1所示。不同分區的槽位可以映射到相同的服務器節點。

表2-1 數據槽位和服務器節點配置樣例表
2.2 服務器節點的擴容和縮容
在系統設計完成并上線運行后,隨著在線數據量及業務請求量的增加或者減少,根據服務器負載情況,需要對服務器集群進行擴容或者縮容。
數據單個分區對應的槽位在系統設計時可能無法準確的進行評估,隨著系統數據量的增多和數據請求量的不均衡,在服務器節點之間會出現負載不均衡的問題;此時需要對高負載的服務器節點進行數據槽位遷出,將多余的槽位遷出都其他負載低的服務器節點或新增服務器節點上;在遷移數據槽位都無法均衡各個服務器的負載的時候,就需要增加熱點數據對應分區的槽位個數;由于各個分區獨立,因此單個分區槽位的增加并不會影響其他分區的數據,達到了較少遷移數據的目的。
服務器存儲的數據減少后,為了節省成本通常會選擇對服務器集群進行縮容;此時針對數據減少的分區,減少服務器節點數量,將減少的服務器節點上的對應的槽位遷移到剩余的對應分區的服務器節點上即可。不會影響到其他數據槽位和其他分區。
3 實驗結果
采用此負載均衡算法進行了模擬實驗,實驗場景如下:
(1)使用隨機數產生負載請求數據;
(2)從全域Hash函數族中選擇一個一次Hash函數作為從數據key到分區Section的映射;
(3)從全域Hash函數族中選擇一個二次Hash函數作為各個分區數據到對應分區槽位Slot的映射;
(4)配置各個分區Section的槽位Slot到服務器節點Node的對應關系。
實驗模擬結束后,各個數據的分布如圖3-1所示;各個服務器節點的數據負載分布如圖3-2所示。
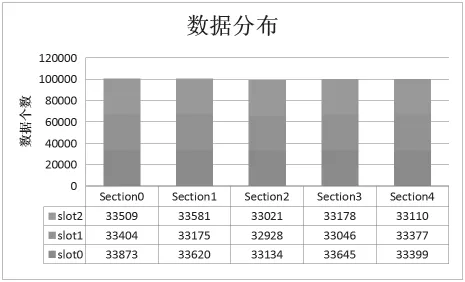
圖3-1 數據分布
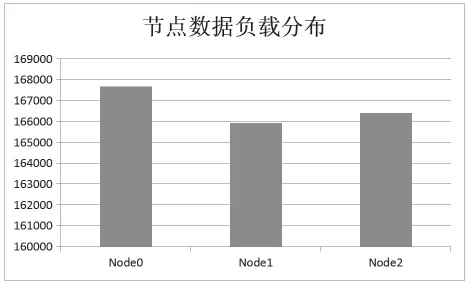
圖3-2 服務器節點數據負載分布
從實驗結果可以得出,基于二級映射的哈希負載均衡算法可以較好的完成服務器節點間的負載均衡。
4 總結
在海量存儲系統中,通常需要集群服務器進行存儲,為了均衡各個服務器之間的負載,需要考慮選擇對應的負載均衡算法,本文提出了一種基于二次映射的哈希負載均衡算法,能夠很好的完成在服務器節點間的負載均衡,并能方便的解決數據熱點和服務器的擴容、縮容,為存儲系統的負載均衡提供了新的思路和方法。
