云環境下地籍數據高效并行化的拓撲檢查
2019-01-07 01:04:44楊宜舟郭甲騰吳立新劉善軍
測繪通報 2018年12期
關鍵詞:進程
何 群,楊宜舟,郭甲騰,吳立新,劉善軍
(1.東北大學資源與土木工程學院,遼寧 沈陽 110004; 2.中南大學地球科學與信息物理學院,湖南 長沙 410012)
2013年以來,每年僅中國產生的數據總量就達到ZB級,相當于2009年全球的數據總量,而其中具有空間屬性的數據大約有80%[1]。地籍數據是一種典型性、復雜性的空間數據,其在數據海量性環境下的質量控制是亟待解決的問題,而地籍數據拓撲的一致性是其核心問題[2-3]。雖然近年計算機的計算能力迅速提高,尤其是多核計算機和并行計算機開始普及,但地籍數據本身的空間復雜性,使得傳統串行環境下的空間拓撲檢查方法難以充分利用這些先進的計算資源,已遠不能滿足實際應用中地籍數據拓撲一致性檢查效率的需求[4]。現有的并行技術、分布式技術、云技術正在與GIS理論進行著深度融合[5],在柵格方面進行的數據并行算法研究[5-6]較多,但在矢量方面關于并行拓撲質量檢查的研究較少[7-9]。
本文在分析拓撲關系計算特點的基礎上,結合四叉樹和R樹的多級多重并行空間索引(Q&R索引),解決了矢量地理對象數據的快速定位(數據過濾)和空間分割問題;同時提出一種基于Q&R索引實現拓撲計算過程中任務調度的方法,從數據層實現空間拓撲關系計算的并行化。
1 拓撲關系原理與高性能計算模式
1.1 拓撲關系基本原理
拓撲關系是GIS的重要特征,表達空間目標之間的在空間上相鄰程度的一種定性關系。現有空間拓撲關系的描述模型主要有3種[9]:基于點集理論的描述模型(4-交模型與9-交模型)、基于RCC理論的描述模型、基于Voronoi圖的9-交模型。相較于RCC理論描述模型和Voronoi圖,9-交模型適用幾何對象廣泛且有相對較高的計算效率,更加適用于研發拓撲關系計算的高性能算法(見表1)。

表1 三類拓撲關系描述模型的比較[9]
1.2 高性能計算模式
現有空間高性能計算環境主要分為并行計算、分布式計算、集群計算與云計算等,其共同點在于通過并行化算法充分利用更多的計算資源,以實現空間數據和空間分析的高效計算,而區別在于其計算模式不同[9-12]。不同于其他高性能計算,云計算是未來的發展趨勢,其特征在于空間計算資源的彈性化供給[11-13]。云計算通過虛擬化技術和資源管理技術為用戶提供多種虛擬的高性能計算環境(如圖1所示),如并行計算環境、分布式計算環境等。
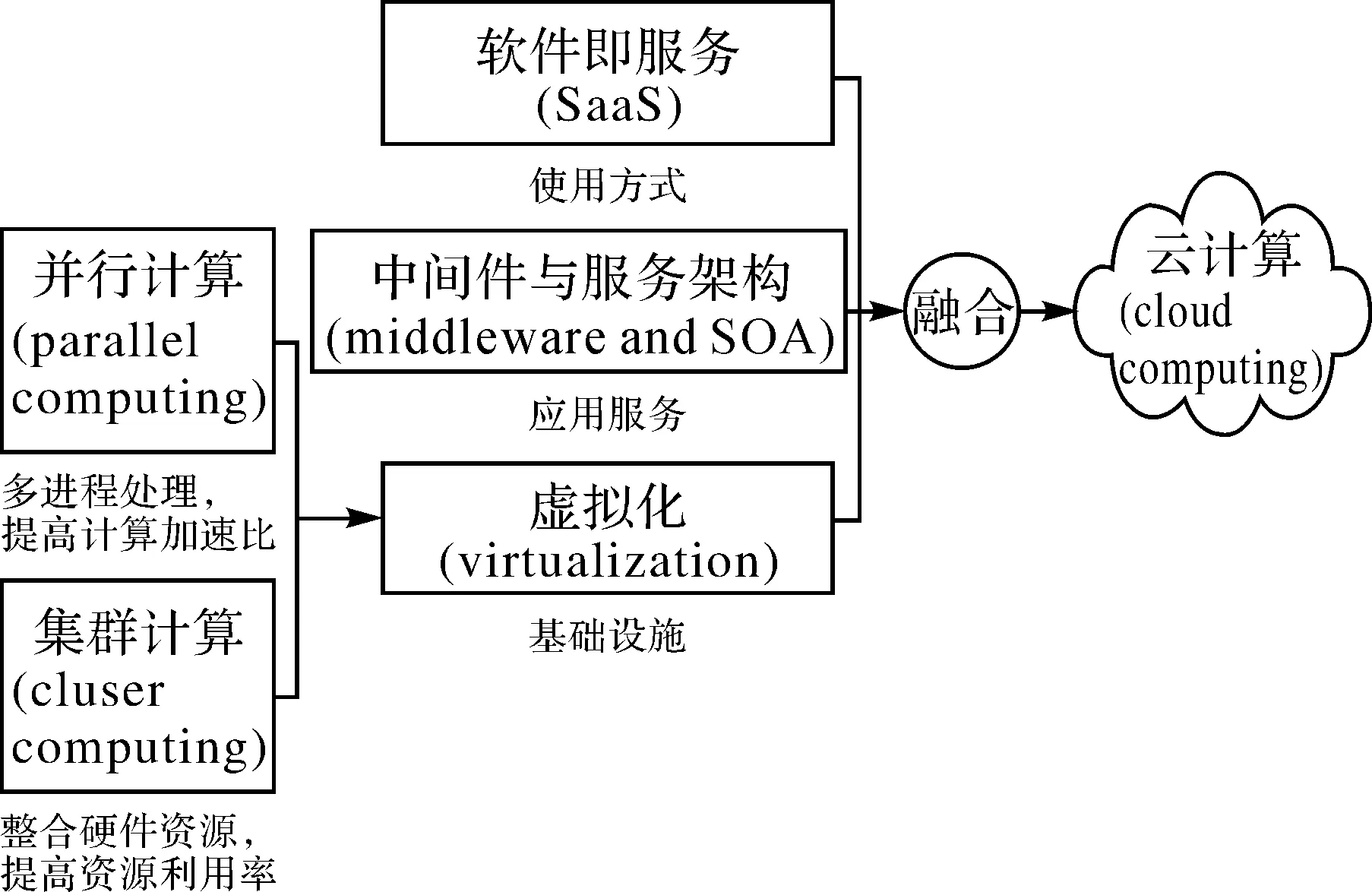
圖1 云計算平臺
據上所述,本文主要研究拓撲關系的并行化方法,以期在云平臺下虛擬并行環境或集群環境下高效運行。本文采用單程序多數據(single program multiple data,SPMD)[14]模式設計拓撲計算并行算法,基本思路為:通過空間數據集劃分方法,將空間數據分配至不同進程;在空間索引支持下,各進程對不同的空間數據集進行協同并行計算。
2 拓撲關系并行計算策略
2.1 拓撲關系檢查計算特點分析
拓撲關系的基礎算法屬于計算幾何方法的一部分,其粒度最小的算子可歸納為節點間關系計算、點與線間關系計算,而拓撲關系檢查計算是在某些約束條件下進行點與點之間或點組與點組之間的計算。矢量數據基本要素有點(Pi)、線(Li)、面(Poi),而以上數據都是由點要素構成,即Poi={L1,L2,…,Lm},Li={P1,P2,…,Pn}。點是矢量數據中最簡單、最結構化的要素,假定點每次參與計算的計算量為Cp,則矢量目標之間的關系計算,如線、線求交,屬于“乘積”型幾何計算,其計算量Cp為
(1)
2.2 拓撲關系并行化分析
根據矢量目標之間拓撲關系的層次化計算關系(如圖2所示),分析拓撲關系計算的層次關系,可知其特點為:①對于某一矢量目標,需判斷其與矢量目標集中的其他所有對象是否相交;②只進一步計算與其相交的矢量目標間的精細拓撲關系。
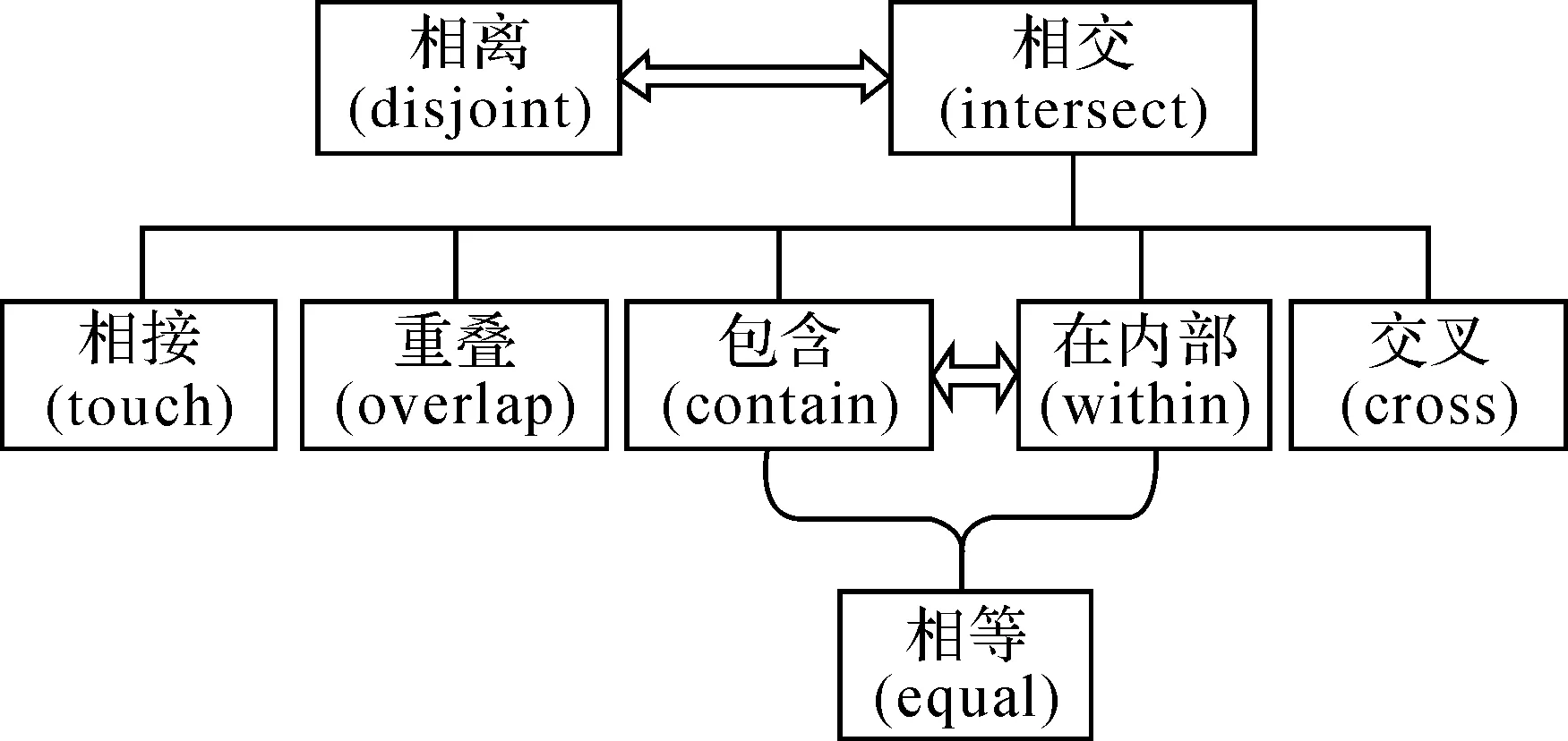
圖2 空間拓撲關系之間的聯系與計算層次
分析特點①可知:矢量目標之間一般先通過MBR(minimum bounding rectangle)的相交計算,過濾掉大部分相離的矢量目標集;若采用復雜度最高的MBR直接過濾法,過濾耗時將急劇增加,嚴重制約著拓撲計算的效率。因此,要實現高效拓撲關系并行計算,首先需要研究一種高效過濾非相交的矢量目標算法。
分析特點②可知:拓撲關系計算中的矢量目標可分解為約束條件下的點點拓撲計算集或點線拓撲計算集,若將計算集分治計算會破壞矢量目標數據的完整性。因此,需要從數據集上設計一種拓撲關系的并行化方法,既顧及矢量目標數據的完整性,又提升拓撲關系并行計算的效率。
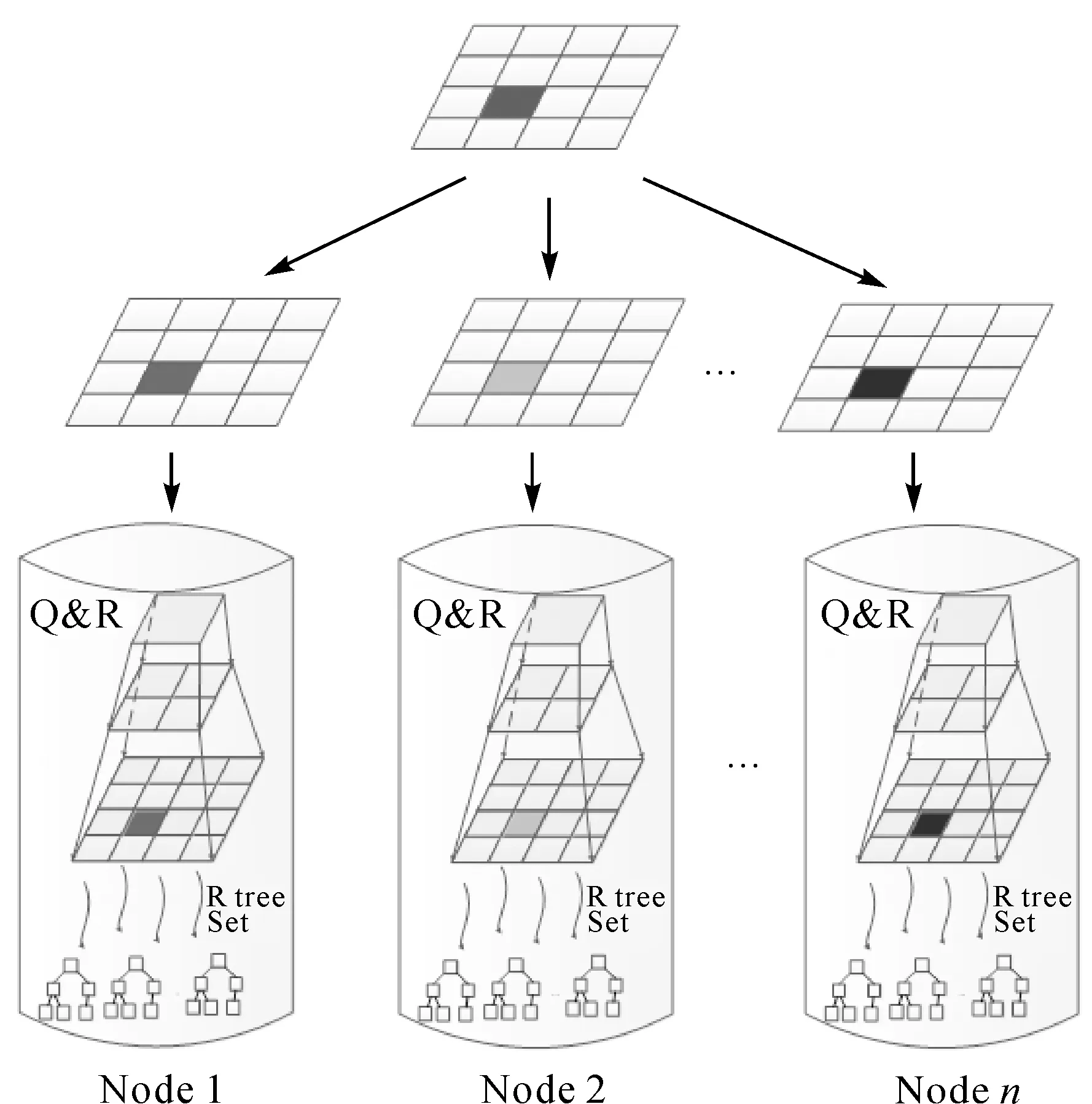
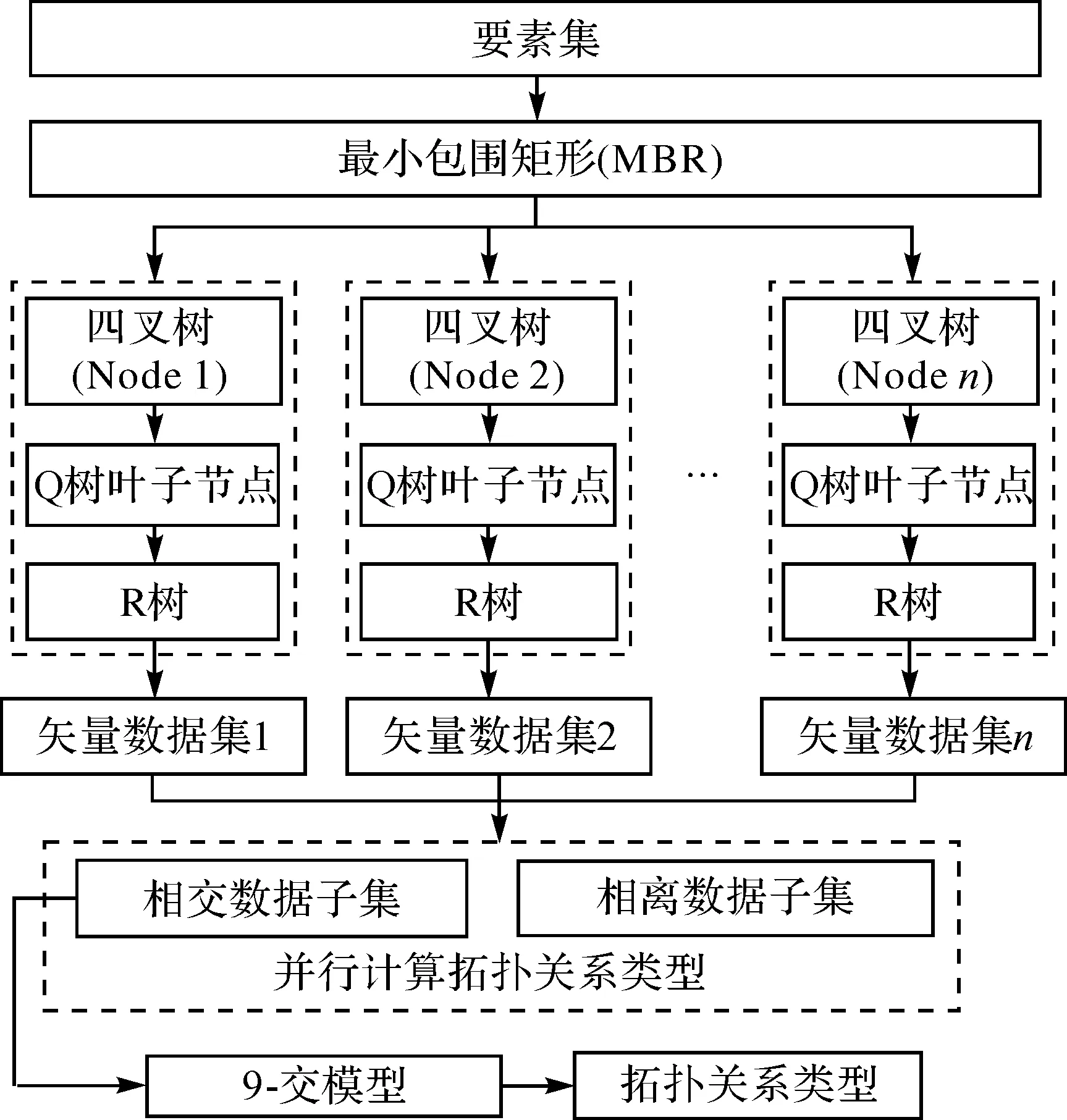
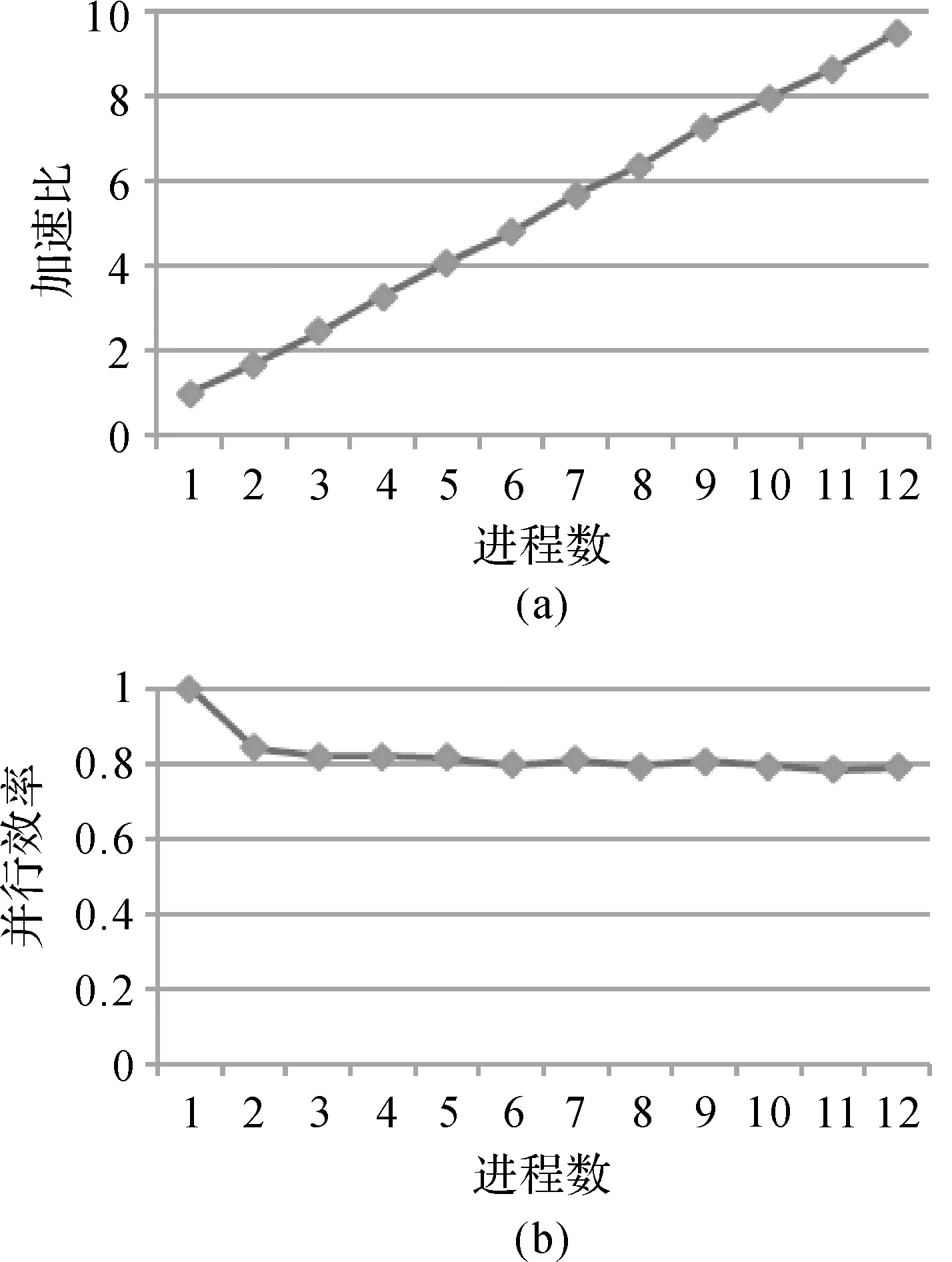
由上述分析可知:通過功能劃分實現拓撲關系的并行化會破壞矢量目標的數據完整性,而通過數據劃分實現拓撲計算并行化具有較高的可行性。數據劃分的約束條件有:①將空間索引與數據劃分相融合,提高相離矢量目標集(命中相交矢量目標集)的過濾效率,從數據劃分方法上實現拓撲關系計算量劃分均衡(任務均衡);②任務均衡通過計算量模型“乘積”相等實現,即與任一矢量目標集A有相交關系的各節點中矢量目標集合Sn(1 根據以上分析,對于計算量屬于“乘積”方式的空間拓撲計算,在數據劃分后仍保持各節點的計算量C近似相等,則各節點中要素集的點總數需近似相等,且需從各層數據的空間分布及參與計算的概率考慮,各層檢索與矢量目標集A可發生相交計算的要素集點數需要近似相等。因此,需要結合基于四叉樹(Q樹)數據初步劃分和顧及“乘積”計算量的再次劃分(再次劃分后建立R樹),即在劃分數據的過程中,不僅從數據層實現了負載(任務)均衡,并且構建的Q&R并行索引也極大提高了數據篩選的效率,特別是在海量數據的環境下更能發揮出Q&R并行索引優勢,提升并行拓撲計算的效率。 首先,通過Q樹葉子節點對矢量目標集進行初始范圍劃分,將空間數據集V分割為數據塊集S{dS1,dS2,…,dSm},Q樹各葉子節點包含對應的數據塊dSn;其次,將各葉子節點中矢量目標數據塊dSn進一步劃分為dS{dSnc1,dSnc2,…,dSncp},分配至各計算節點(將Q樹各葉子節點切片為p個葉子節點,即將Q樹切為p個深度相同的Q樹),使各計算節點位置相同的Q樹葉子節點的Cp近似相等,并對dS集合建立R樹索引,進一步提升數據篩選的效率(如圖3所示)。 拓撲關系計算分為兩種情況:①空間數據集A與空間數據集B的空間拓撲計算,篩選出符合拓撲約束條件c(c為相離、相接、疊加、包含或穿越)的空間數據C;②空間數據集A中各空間數據之間的拓撲關系,可理解為空間數據集A與空間數據集A的空間拓撲計算。因此,兩種情況可采用相同的并行方式。具體步驟如下(設并行程序運行的進程數為P): 圖3 數據劃分過程 (1) 根據本文的數據劃分方法對空間數據集A進行劃分,并建立Q&R并行索引(包含P個Q&R索引)。 (2) 根據本文的四叉樹劃分(Q樹深度為m)方法對空間數據集B進行劃分,劃分后數據塊為S1,S2,…,Sm×m。 (3) 各進程讀取空間數據塊Sn(1 (4) 各進程讀取數據塊Sn中空間目標oi的MBR,在該節點對應的Q&R索引中檢索與其進行拓撲計算的數據集di,oi與di采用V-9I模型進行拓撲計算(如圖4所示)。 (5) 重復步驟(4)直至數據塊Sn中所有空間目標都計算完畢。 (6) 重復步驟(3)—(5)直至各進程中所有空間數據塊(S1,S2,…,Sm×m)都參與計算各節點Q&R索引對應的空間數據集完畢。 (7) 收集各進程拓撲計算中符合約束條件的結果。 本文基于消息傳遞接口模式的并行框架,采用C++語言實現跨平臺的并行算法開發,實現并行算法在不同的硬件環境下(如單機、集群和云環境)運行。 圖4 拓撲關系并行計算流程 空間拓撲并行計算中間件部署在云平臺下的虛擬集群中,為實際應用提供服務。該環境由5個虛擬計算節點及1個虛擬存儲節點(4 TB)構成,集群中各節點的操作系統是Redhat 5.04(64位),消息傳遞采用OpenMPI并行庫,節點間采用高速交換機進行通信,見表2。 表2 云環境下的虛擬集群 本試驗有兩組應用數據:①矢量目標集1為國內某地區的5.6萬塊宗地;②矢量目標集2為某地區70萬塊宗地,其中第1組試驗數據用于正確性驗證, 參照對象ArcGIS;第2組數據相比第1組數據提升了一個數量級,在單節點環境下已超出ArcGIS的計算能力,用于驗證本文提出拓撲關系計算方法的并行性能。 采用第1組宗地數據進行宗地多邊形的重疊檢查,共有9處重疊區域,其與ArcGIS計算結果一致(如圖5所示)。在相同的硬件環境下,多次運行ArcGIS拓撲計算工具的平均耗時為51 s,而本文并行拓撲計算的多次運行平均耗時為15 s,相比ArcGIS拓撲計算效率提升了3倍。 圖5 宗地數據重疊檢查運行結果 如表3所示,在相同計算環境、不同進程數時宗地重疊拓撲檢查的耗時最壞差率不超過6.5%,表明本文并行算法可實現地籍數據中的宗地拓撲疊加質量檢查的負載基本均衡與任務基本均衡。隨著進程數的增多、各個進程計算量的減少,計算耗時降低、耗時差率越大,反之則表明計算的數據量越大、耗時差率越小,耗時差率與數據量的大小呈負相關性,即在大數據環境下,應用本文方法實現矢量算法并行計算,可更有效解決負載均衡與任務均衡。 表3 不同進程數條件下各進程時間消耗 由矢量拓撲關系并行計算加速比、并行效率(如圖6所示)可見:加速比與進程數呈線性正相關,在12個進程時加速比達到9.5倍,拓撲并行算法的計算效率穩定在80%(斜率約為0.8)。 數據劃分時間與拓撲關系計算的時間對比見表4。通過對數據層劃分并建立Q&R并行索引實現拓撲關系計算的并行化,所耗費的時間遠小于任務執行總時間(輸入、計算與輸出總時間)。由此可知,基于空間索引的數據劃分與數據調度方法,可有效實現拓撲關系計算的并行化。 表4 不同進程數條件下數據劃分與任務總時間比率 圖6 拓撲關系并行算法的加速比和并行效率 本文針對云環境下地籍數據拓撲關系質量檢查算法并行化進行了研究與探索,通過引入Q&R并行空間索引實現了拓撲計算前的數據劃分和拓撲計算過程中的數據過濾,基本解決了拓撲計算任務均衡和負載均衡,并且提升了拓撲并行計算的效率,使其并行效率達到80%。基于復雜度較高的地籍(宗地)數據,對拓撲并行算法進行了應用測試,驗證了本文方法的可行性與優勢性,也為其他矢量數據計算分析的并行化研究提供了參考和思路。本文空間拓撲并行算法支持云平臺下的虛擬化集群部署與運行,包括單機多核、集群等多種高性能環境,但在不同環境中仍需要考慮網絡通信、存儲和計算對空間并行算法的影響,可作為后續的研究方向。2.3 數據劃分方案
2.4 拓撲關系并行計算
3 應用試驗分析
3.1 應用環境
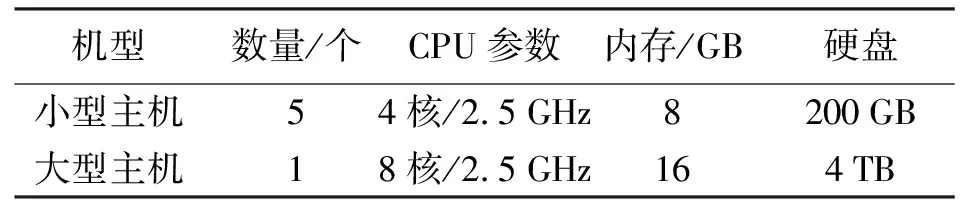
3.2 應用數據
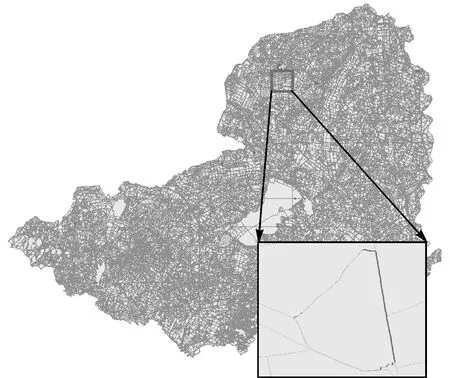
3.3 商業軟件對比分析
3.4 均衡性分析與加速效果

3.5 數據劃分時間分析

4 結 論
猜你喜歡
中國外匯(2019年20期)2019-11-25 09:54:58
中國外匯(2019年8期)2019-07-13 06:01:06
電腦愛好者(2018年15期)2018-08-23 17:24:06
民主與科學(2014年3期)2014-02-28 11:23:03
教育與職業(2014年7期)2014-01-21 02:35:04
計算機與網絡(2013年1期)2013-06-05 05:31:50
電腦迷(2012年24期)2012-04-29 00:44:03
中華女子學院學報(2012年6期)2012-03-25 13:52:27
俄羅斯問題研究(2012年1期)2012-03-25 09:54:45
杭州師范大學學報(社會科學版)(2011年3期)2011-04-04 08:58:20
