基于PCA人臉識別原理
2019-01-18 01:15:46姚艷松
網(wǎng)絡安全技術與應用 2019年1期
◆邵 嵐 姚艷松 尚 福
?
基于PCA人臉識別原理
◆邵 嵐 姚艷松 尚 福
(CLO 北京 100054)
文章主要討論了人臉識別灰度化、生物特征的幾種方法和原現(xiàn),以及如何實現(xiàn)灰度化。同時分析了一種常見卻并不妥當?shù)幕叶然瘜崿F(xiàn),以及證明了opencv的灰度化是使用“加權灰度化”法,能從整體上反映人臉圖像的灰度相關性具有一定的實用價值。
人臉識別;灰度化;人臉特征;識別技術
0 引言
人臉識別人是基于人的面部特征信息進行身份識別的一種生物識別技術。使用攝像頭或者攝像機采集含有人臉的圖像或視頻,自動檢測圖像信息和跟蹤人臉,對檢測到的人臉進行臉部的一系列相關分析技術。
人臉檢測是指從復雜的背景當中提取我們感興趣的人臉圖像。臉部毛發(fā)、化妝品、光照、噪聲、人臉傾斜和大小變化及各種遮擋等因素都會導致人臉檢測問題變得更為復雜。人臉識別技術主要目的在于在輸入的整幅圖像上尋找特定人臉區(qū)域,從而為后續(xù)的人臉識別做準備。
在計算機領域中,灰度(Gray scale)數(shù)字圖像是每個像素只有一個采樣顏色的圖像。這類圖像通常顯示為從最暗黑色到最亮的白色的灰度,盡管理論上這個采樣可以表現(xiàn)任何顏色的不同深淺,甚至可以是不同亮度上的不同顏色。灰度圖像與黑白圖像不同,在計算機圖像領域中黑白圖像只有黑白兩種顏色,灰度圖像在黑色與白色之間還有許多級的顏色深度。但是,在數(shù)字圖像領域之外,“黑白圖像”也表示“灰度圖像”,例如灰度的照片通常叫做“黑白照片”。
“特征臉”方法中所有人共有一個人臉子空間,而我們的方法則為每一個體人臉建立一個該個體對象所私有的人臉子空間,從而不但能夠更好的描述不同個體人臉之間的差異性,而且最大可能地擯棄了對識別不利的類內差異性和噪聲,因而比傳統(tǒng)的“特征臉算法”具有更好的判別能力。另外,針對每個待識別個體只有單一訓練樣本的人臉識別問題,我們提出了一種基于單一樣本生成多個訓練樣本的技術,從而使得需要多個訓練樣本的個體人臉子空間方法可以適用于單訓練樣本人臉識別問題。人臉庫對比實驗也表明我們提出的方法比傳統(tǒng)的特征臉方法、模板匹配方法對表情、光照、和一定范圍內的姿態(tài)變化具有更優(yōu)的識別性能。
1 PCA方法
近期發(fā)展起來的用于人臉或者一般性剛體識別以及其它涉及到人臉處理的一種方法。首先把一批人臉圖像轉換成一個特征向量集,稱為“Eigenfaces”,即“特征臉”,它們是最初訓練圖像集的基本組件。識別的過程是把一副新的圖像投影到特征臉子空間,并通過它的投影點在子空間的位置以及投影線的長度來進行判定和識別。
將圖像變換到另一個空間后,同一個類別的圖像會聚到一起,不同類別的圖像會聚力比較遠,在原像素空間中不同類別的圖像在分布上很難用簡單的線或者面切分,變換到另一個空間,就可以很好的把他們分開了。Eigenfaces選擇的空間變換方法是PCA(主成分分析),利用PCA得到人臉分布的主要成分,具體實現(xiàn)是對訓練集中所有人臉圖像的協(xié)方差矩陣進行本征值分解,得到對應的本征向量,這些本征向量就是“特征臉”。每個特征向量或者特征臉相當于捕捉或者描述人臉之間的一種變化或者特性。這就意味著每個人臉都可以表示為這些特征臉的線性組合。
原始圖像投影到該特征空間中。特別說明,此時的原始圖像x存成大小是n維的向量,即:
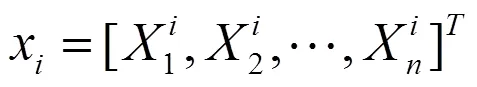
訓練集為形成矩陣X[n][p],其中行代表像元,列代表每幅人臉圖像[2]。
將訓練樣本集中的人臉圖像減去平均人臉圖像,計算離散差值,將訓練圖像中心化。中心化之后圖像組成一個大小為n×p的矩陣。
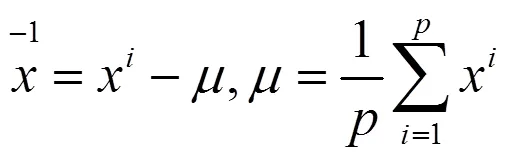
將中心化后的圖像組成的矩陣X乘以它的轉置矩陣得到協(xié)方差矩陣Ω。
求解協(xié)方差矩陣Ω的k個非零特征值,以及所對應的特征向量,一般來說,訓練圖像數(shù)量p遠遠小于一幅圖像的像素值n,所以協(xié)方差矩陣Ω最多有對應于非零特征值的p個特征向量,所以k≤p.按照特征值的從大到小的順序排列特征向量,對應于最大特征值的特征向量反應了訓練圖像間的最大差異,而對應的特征值越小的特征向量,反應的圖像間的差異越小。所有的非零特征值對應的特征向量,組成特征空間,也就是所謂的“特征臉”空間。
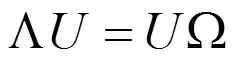
計算特征值和特征向量,其中U為對應于特征值的特征向集。排列特征向量:按照非零特征值,從大到小的順序,將對應的特征向量排列。所組成的特征向量矩陣即為特征空間U,U的每一列為一個特征向量。
每一幅人臉圖像都可以投影到由張成的子空間中。因此每一幅人臉圖像對應于子空間中的一個點,同樣,子空間中的每個點對應于一幅圖像,下圖顯示的是所對應的圖像,由于這些圖像很像人臉,所以它們被稱為“特征臉”[5]。

圖1 特征臉
特征臉訓練圖像投影得到特征臉子空間 有了這樣一個由“特征臉”組成的降維特征子空間,任何一幅中心化后的人臉圖像都可以通過下面的式子投影到特征臉子空間并獲得一組坐標系數(shù)。
2 灰度化
將彩色圖像轉化成為灰度圖像的過程稱為圖像的灰度化處理。
灰度化,在RGB模型中,如果R=G=B時,則彩色表示一種灰度顏色,其中R=G=B的值叫灰度值,因此,灰度圖像每個像素只需一個字節(jié)存放灰度值(又稱強度值、亮度值),灰度范圍為0-255。
彩色圖像中的每個像素的顏色有R、G、B三個分量決定,而每個分量有255個值可取,這樣一個像素點可以有1600多萬(255*255*255)的顏色的變化范圍。而灰度圖像一個像素點的變化范圍為255種,所以在數(shù)字圖像處理種一般先將各種格式的圖像轉變成灰度圖像以使后續(xù)的圖像的計算量變得少一些。灰度圖像的描述與彩色圖像一樣仍然反映了整幅圖像的整體和局部的色度和亮度等級的分布和特征[3]。
一般有四種方法對彩色圖像進行灰度化處理:分量法、最大值法、平均值法、加權平均法。
圖像灰度化處理有以下幾種方式:
(1)分量法
將彩色圖像中的三分量的亮度作為三個灰度圖像的灰度值,可根據(jù)應用需要選取一種灰度圖像。
f1(i,j)=R(i,j)
f2(i,j)=G(i,j)
f3(i,j)=B(i,j)
其中fk(i,j)(k=1,2,3)為轉換后的灰度圖像在(i,j)處的灰度值。
(2)最大值法
將彩色圖像中的三分量亮度的最大值作為灰度圖的灰度值。
f(i,j)=max(R(i,j),G(i,j),B(i,j))
(3)平均值法
將彩色圖像中的三分量亮度求平均得到一個灰度值。
f(i,j)=(R(i,j)+G(i,j)+B(i,j)) /3
(4)加權平均法
根據(jù)重要性及其它指標,將三個分量以不同的權值進行加權平均。由于人眼對綠色的敏感最高,對藍色敏感最低,因此,按下式對RGB三分量進行加權平均能得到較合理的灰度圖像。[3]
f(i,j)=0.30R(i,j)+0.59G(i,j)+0.11B(i,j))
在Opencv中可以通過以上幾種方法的數(shù)值計算來得到灰度圖像也可以通過opencv提供的顏色空間轉換函數(shù)來得到。Opencv封裝灰度法將彩色圖轉為灰度圖[3]。
cv::cvtColor(rgbMat, greyMat, CV_BGR2GRAY);
3 利用PCA進行人臉識別
完整的PCA人臉識別的應用包括幾個步驟:人臉圖像預處理;讀入人臉庫,訓練形成特征子空間;把訓練圖像和測試圖像投影到上一步驟中得到的子空間上;選擇一定的距離函數(shù)進行識別。
PCA算法依賴于一個基本假設:一類圖像具有某些相似的特征(如人臉),在整個圖像空間中呈現(xiàn)出聚類性,因而形成一個子空間,即所謂特征子空間,PCA變換是最佳正交變換,利用變換基的線性組合可以描述、表達和逼近這一類圖像,因此可以進行圖像識別,PCA包含訓練和識別兩個階段。
本文采用matlab作為工具平臺, 實現(xiàn)了一個人臉自動識別的系統(tǒng)原型。人臉庫中有40個人,各隨機取出其10張圖像中的7張用作訓練集,剩余3張用作后續(xù)的測試。將280張train_imgs都拉伸成列向量并將所有列拼在一起,由于每張圖像的總像素數(shù)都為10304,這樣就得到了10304*280的矩陣X,X的每列再減去均值向量,從而中心化,求出X的轉置和X的矩陣乘積,并求出乘積40*40矩陣的特征向量[1],是matlab的eig函數(shù)。濾出前K大的特征值對應的特征向量W,再將X乘上W映射得到V,將V的每一列向量作為后續(xù)映射關系的一組基向量,共有K個基向量,也可以稱為K個特征臉。將X每一列都通過基向量矩陣V映射到對應的特征空間中。這樣相當于將每張圖像train_imgs都在新的空間中找到了對應的位置。對于每個測試圖像,也進行類似上述的變換:轉成列向量,減去均值向量而中心化,然后用基向量矩陣映射到特征空間中。要判斷測試圖像和40張train_imgs的哪張最匹配,只需對比測試圖像在特征空間的新坐標和40張train_imgs在特征空間的坐標直接的歐幾里得距離(或二范數(shù))的大小,找到二范數(shù)最小的對應的train_img,就找到了最匹配訓練圖像了。
這種算法的主要思想就是,去除部分無關的或者關系較小的向量,保留影響較大的向量作基,這樣即減少了基向量的數(shù)目從而減少了運算量,同時又減少了圖像細節(jié),能避免無關的向量和測試圖像主人公的表情、臉朝向和配飾等變化對測試準確性產(chǎn)生不良干擾。
Matlab代碼實現(xiàn)函數(shù)Training用來隨機讀取40*7張圖像并分別作平均產(chǎn)生訓練集
function [ imgs ] = Get_Training_Set( input_path, index, height, width, output_path )
imgs = zeros(length(index), height, width);
for i = 1 : length(index)
imgs(i, :, :) = uint8(imread([input_path '/' num2str(index(i)) '.pgm']));
end
end
函數(shù)Test_Case用來測試單張圖像,循環(huán)調用即可測試所有的測試集圖像
function [ found ] = Test_Case( V, eigenfaces, indexes, i, j, mean_img )
f = imread(['Faces/S' num2str(i) '/' num2str(indexes(i, j)) '.pgm']);
[height, width] = size(f);
f = double(reshape(f, [height * width, 1])) - mean_img;
f = V' * f;
[~, N] = size(eigenfaces);
distance = Inf;
found = 0;
for k = 1 : N
d = norm(double(f) - eigenfaces(:, k), 2);
if distance > d
found = k;
distance = d;
end
end
end
測試性能表格,Test_Case函數(shù)返回1-280之間的整數(shù),表示這一列最能匹配當前測試圖片。但還需要轉成1-40之間的整
數(shù)才能表示出匹配到了的是哪一個人。
found = Test_Case(V, eigenfaces, indexes, i, j, mean_img);
found = floor((found - 1) / 7) + 1;
修改代碼為初始不求40張平均臉,而用280張人臉直接訓練后再對每個K值測試10次,得到的測試折線圖如下,可以看到,測試準確度隨著K從50到100取值,大約在93%到95%間波動,并且大約在K取83的附近得到較穩(wěn)定的最大值[4]。
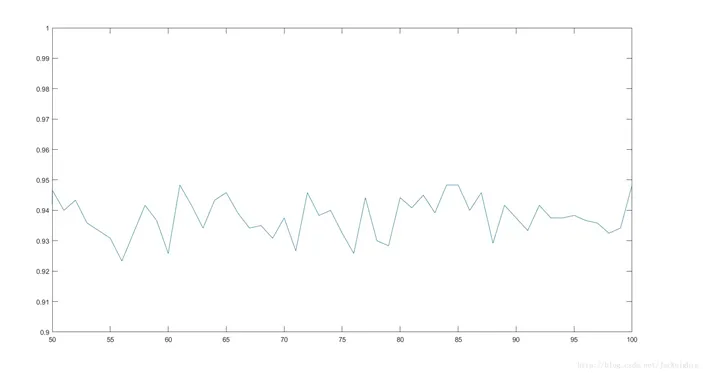
圖2 測試折線圖
圖3 測試結果表
4 結論與展望
人臉識別是目前較活躍的研究領域, 本文詳細給出了基于主成分分析的人臉特征提取的原理與方法。并使用matlab 作為工具平臺, 實現(xiàn)了一個人臉自動識別的系統(tǒng)原型。實驗結果表明, 該系統(tǒng)識別率為85%, 達到預期的效果。如果想進一步提高人臉識別率, 可以考慮與其他方法結合。
人臉識別的技術得到突破,準確率得到提升并普及用戶習慣后,其商業(yè)化應用前景是十分廣闊的,且有助于線下生物識別格局的改變,很有可能會成為下一個科技時代的商業(yè)爆發(fā)點。隨著人臉識別技術的革新,人臉識別效果的提升將打開前期受效果制約的應用場景。
總之,以人臉識別為代表的新一代技術驅動的產(chǎn)業(yè)革命已經(jīng)興起,學習研究人臉識別的組識會越來越多。但在實際應用中仍然面臨困難,不僅要達到準確、快速的檢測并分割出人臉部分,而且要有效的變化補償、特征描述、準確的分類效果及如何與其它技術相結合,提高識別率和識別速度、減少計算量。
[1] 楊瓊,丁曉青.鑒別局部特征分析及其在人臉識別中的應用[J].清華大學學報:自然科學版,2004.
[2]羅韻.用Matlab進行PCA人臉識別[N/OL].http://blog. 163.com/luoyun_dreamer/blog/static/215529070201331281538309/?suggestedreading.
[3]文尹習習.圖像處理:灰度化,二值化,反色[EB/OL]. https: //blog.csdn.net/liu1152239/article/details/73088182
[4]JacKnights.基于PCA的人臉識別[EB/OL].https: //blog. csdn.net/JacKnights/article/details/79439180?utm_source=blogxgwz6.
[5]xiaoshengforever.PCA的具體實現(xiàn)(Eigenfaces特征臉) [EB/OL].https://blog.csdn.net/xiaoshengforever/article/details/13041753.
猜你喜歡
數(shù)學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
作文中學版(2022年1期)2022-04-14 08:00:34
世界科學技術-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
學生天地(2020年31期)2020-06-01 02:32:06
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2017年17期)2017-12-18 06:40:55
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
電子制作(2017年1期)2017-05-17 03:54:46
計算機工程(2015年8期)2015-07-03 12:19:07
