基于多尺度融合CNN的惡意軟件行為描述語句抽取模型
2019-01-18 01:11:40陳文強周安民
網絡安全技術與應用 2019年1期
◆陳文強 周安民 劉 亮
?
基于多尺度融合CNN的惡意軟件行為描述語句抽取模型
◆陳文強 周安民 劉 亮
(四川大學網絡空間安全學院 四川 610065)
惡意軟件是網絡空間安全的重要威脅之一,安全廠商和從業人員發布了大量的惡意軟件分析報告。從報告中自動化識別并提取出惡意軟件行為與能力描述的相關文本語句,能夠幫助分析人員快速了解惡意軟件的關鍵信息。本文使用一種基于多尺度融合的卷積神經網絡模型抽取上述信息,該模型僅使用預訓練詞向量作為輸入,利用卷積層提取特征,減少對人工特征依賴。基于Phandi等人構建的數據集MalwareTextDBv2.0數據集進行測試,準確率為71.33%、F1值為66.48%。相對于該數據集上的其它識別方法,本模型具有更高準確率和F1值。
惡意軟件;信息抽取;卷積神經網絡
0 引言
隨著世界聯系越來越緊密和高度數字化,網絡攻擊也越來越普遍,這給社會帶來嚴重問題。2010年,破壞了伊朗核設施中離心機的Stuxnet蠕蟲病毒是世界上首例專門針對工業控制系統的破壞性病毒[1]。2017年,WannaCry勒索病毒在短時間內席卷全球,大量政府部門、企業單位及教育機構受到病毒侵害[2]。這些攻擊影響范圍從個人電腦到工業設施。
互聯網中存在大量與惡意軟件相關的文本,例如賽門鐵克和Cylance等各種安全機構發布的惡意軟件報告。研究人員可以方便地從此類文本中快速了解惡意軟件的行為能力信息,而不是手工對各個惡意軟件樣本進行分析。網絡安全研究人員經常收集這類文本,但是由于這些文本的龐大數量和多樣性使得研究人員難以快速獲得特定惡意軟件的行為或能力信息。因為不同安全機構會對同一樣本發布分析報告,一篇報告中也只有少數語句是包含惡意軟件行為或者能力信息,圖1是一文本示例,該段文本中僅有一句包含此類信息(圖示中加黑部分)。自然語言處理是網絡安全研究中的關鍵技術[3],可以幫助研究人員從惡意軟件報告中快速獲取這些信息。本文使用一種多尺度融合卷積神經網絡,僅使用詞嵌入作為輸入,從網絡安全相關文本中提取描述惡意軟件行為或者能力的語句。

The malicious DLL file that is dropped is hidden in a resource of the dropper binary. This is a relatively common technique used by malware dropper files to optimize the number of files required to infect a machine. The resource language of the malicious DLL is set to "Chinese (Simplified)", this is a compiler artifact which indicates the language setting on the compiler used by the person who built the binary was set to "Chinese (Simplified)" at the time the dropper was compiled.
1 相關工作
從惡意軟件報告中提取描述惡意軟件行為或者能力的語句可以看作是文本分類問題。
高明霞等人首先訓練維基百科語料庫并獲取word2vec 詞模型,然后建立基于此模型的短文本特征,通過SVM、貝葉斯等經典分類器對短文本進行分類[4]。任勉等人使用采用CBOW模型訓練詞向量,基于雙向長短時記憶循環神經網絡模型(Bi-LSTM),結合棧式自編碼深度神經網絡作為分類器[5]。Kim首次提出將卷積神經網絡應用在文本分類中[6],其模型使用詞嵌入層,卷積層,池化層和全連接層對輸出標簽類別進行預測。Sikdar等人通過構造詞性、是否為停用詞等特征使用樸素貝葉斯和條件隨機場對原始語句進行建模[7],訓練一個二元分類器,用于檢測當前語句是否與惡意軟件的行為和能力相關。Brew等人構造詞性、二元語法和詞干化處理等特征后使用一種在線學習算法對用于描述惡意軟件行為語句分類[8]。Padia等人使用詞袋模型訓練詞嵌入,然后使用一個多層感知機模型對此類文本分類[9]。Loyola等人使用在維基百科文本上訓練的Glove向量初始化詞嵌入,然后訓練一個BiLSTM從惡意軟件報告中提取包含惡意軟件能力的語句[10],取得較好的結果。
以上方法在使用詞性等額外特征時,容易造成誤差積累,降低文本分類的準確率。Loyola等人僅使用預訓練詞向量,大大減少特征工程難度,但通用領域與特定領域下詞分布存在差異,需要根據特定任務對詞分布微調。本文使用一種多尺度融合卷積神經網絡完成此文本分類任務。本方法僅使用在維基百科文本預訓練Glove向量初始化詞嵌入作為每個詞特征向量,并在學習過程中對詞向量微調,通過卷積層提取特征經池化操作由分類器輸出結果。卷積層有優秀的特征提取能力,減少對人工特征依賴性。通過融合不同窗口大小卷積結果使模型能夠關注不同距離詞匯信息。與其它方法比較,結果顯示本方法有更高準確率和F1值。
2 基于多尺度融合卷積神經網絡模型
模型結構如圖2所示,嵌入層將one-hot詞向量線性變換到詞特征向量,將稀疏且不相關的one-hot向量轉換到稠密且相關的詞特征向量,利于神經網絡特征提取。卷積層使用不同大小卷積核對整個語句滑動掃描,每個卷積核生成對應句子級特征向量。最大時序池化對每個卷積核生成的特征向量提取最大值,保留最重要特征值,池化層可在保留最重要信息同時減少時間復雜度。最后全連接層將所有特征向量池化結果拼接后采用全連接方式連接到輸出層,用以表示模型對當前語句分類的評分。
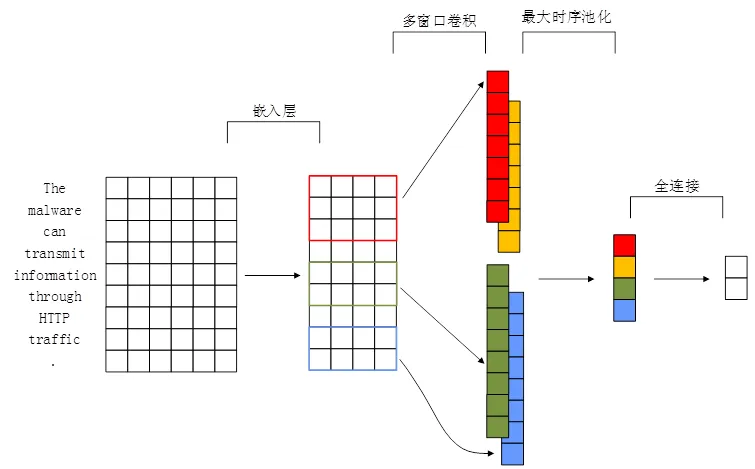
圖2 模型結構
2.1 嵌入層
深度學習進行文本分類第一步是文本向量化,利用詞向量表示文本。傳統文本表示方法采用one-hot表示方式,one-hot表示方式雖然簡單,但是忽略了詞與詞間相關性,并且當詞庫擴大時會面臨數據稀疏性和維度災難問題。
在使用卷積神經網絡提取文本特征前,嵌入層使用一個嵌入矩陣將one-hot向量線性轉換為另一空間下的詞特征向量,詞特征向量由嵌入矩陣與one-hot向量的乘積表示。這種轉換能對數據進行壓縮,將詞從高維稀疏one-hot向量轉換為低維稠密詞特征向量,并且語義相近詞語之間距離會更近,利于神經網絡特征提取和學習。
嵌入矩陣可隨機初始化或由預訓練生成詞特征向量初始化。采用隨機初始化方式,神經網絡可自動學習當前數據集下的詞分布。但詞庫過小時,隨機初始化嵌入矩陣在學習時可存在過擬合風險。預訓練詞特征向量通常在較大文本集下訓練生成,其詞分布泛化能力更好。因此本文使用維基百科文本語料上訓練的Glove[11]向量初始化詞嵌入矩陣。
2.2 卷積層
卷積過程使用卷積核掃描句中連續h個詞,得到這連續h個詞特征值,通過卷積核在整個語句滑動生成句子級特征向量。假定xi表示一句話中第i個詞,一個包含n個詞的語句表示為:
x = x1⊕x2⊕x3⊕…⊕xn(1)
其中⊕表示連接符號。假設xi:i+j表示句中第i個詞到第j個詞,卷積則通過卷積核在一個窗口大小為h的詞上操作產生一個新特征ci,
ci= f(w·xi:i+h-1+b) (2)
其中b表示偏置項,f是一個非線性函數。卷積核在語句上滑動產生特征向量c,
c=[c1,c2,c3,…,cn-h+1] (3)
使用多窗口大小和數量卷積核,用以從句中提取多種不同特征。
2.3 池化層
在卷積核生成特征向量上應用時序最大池化操作,將最大值
cmax= max{c} (4)
作為與該特定卷積對應特征。最大池化操作在每個特征向量中捕獲最重要信息,同時降低數據維度,提高計算效率。這種池化方式也使神經網絡能自然處理不同長度語句。
2.4 全連接層
采用最大池化操作后,每個特征向量僅保留一個特征值,將所有特征值連接成一個向量,采用全連接方式,連接所有特征值到輸出層,輸出層結果表示模型對該語句的分類評分。嵌入層、卷積層和池化層等操作是將原始數據映射到特征空間,全連接層則將學到的“分布式特征表示”映射到樣本標記空間。
3 對比實驗與結果分析
3.1 實驗數據
本文所使用來自Phandi等人構建的數據集MalwareTextDBv2.0[12],Lim等人首先選擇了39篇惡意軟件報告[13],對其中描述惡意軟件行為語句進行標注。Phandi等人在此基礎上,將標注報告數量擴充到85篇。實驗數據分布如表1所示,訓練集包含65篇文檔,共9424條語句,其中2204條語句是描述惡意軟件行為或者能力。

表 1 實驗數據分布
本文選擇訓練集所有數據以及驗證集和測試集的正樣本作為實驗數據,選擇其中80%作為實驗訓練數據,其余20%作為實驗測試數據。
3.2 超參數與訓練
實驗中使用rectified linear units(RELU)作為卷積操作中的非線性激活函數,卷積核窗口大小分別設置為3,4,5,卷積核對應數量分別為100,100,100。將各個特征向量池化結果連接成一個300維向量后隨機丟棄一半值,然后采用全連接方式連接到輸出層作為分類結果。為應對過擬合問題,設置l2正則系數為0.001。選擇adam優化器,設置學習速率為0.001,批量大小為64。在整個訓練數據上迭代訓練30次后停止,使用測試數據進行測試。采用多次實驗計算均值的方式降低誤差。
3.3 對比實驗與結果分析
(1)評價標準
現有評價文本分類方法是通過模型對文本標簽預測正確情況來判斷,本文分類效果評估主要是以精確率(precision),召回率(recall),F1值和準確率(accuracy)來衡量。表2是根據分類結果建立的矩陣,用來介紹評價標準的計算方式。這些評價標準計算方式如下。
precison = TP/(TP+FP) (5)
recall = TP/(TP+FN) (6)
F1 = 2*precison*recall/(precision+recall) (7)
accuracy = (TP+TN)/(TP+FP+FN+TN) (8)

表 2 評價指標介紹
(2)非靜態的嵌入層
預訓練詞向量是自然語言處理中常用方法。通常在訓練時固定詞向量不變,但是往往不同領域的語言表達有其特殊性,詞向量需要進行調整。本文在模型中初始化兩個相同詞嵌入層。在訓練中固定其中一層參數,即保持當前層的詞特征向量不變。另一層隨訓練進行微調,學習目標域下詞分布。
(3)預訓練詞向量維度的影響
向量維度增加造成模型復雜度成倍增長,因此,特征向量維度選擇對實驗結果有重要影響。本文對4種維度的GloVe詞向量[50, 100, 200, 300]進行實驗,結果如表3所示。不同維度GloVe初始化詞向量對本文分類任務的精確率,召回率以及準確率僅有較小影響。但是低維詞向量能較大提高模型訓練和推斷速度。使用300維詞特征向量訓練速度是50維3倍以上,因為處理高維數據需要消耗更多資源。

表 3 不同維度詞向量的結果
(4)與其它模型對比
如表4所示,本模型對識別關于惡意代碼行為的語句有更好性能,雖然召回率有所降低,但是大大提高了識別的精確率和F1值。卷積神經網絡具有優異的特征自提取能力,相較于人工選取特征具有明顯效率優勢。通過使用不同窗口大小的卷積核,模型能夠同時關注不同范圍詞匯,捕捉不同距離詞語之間的特征。

表 4 實驗結果及與其它模型比較
在不同領域下詞分布表示有偏差,非靜態的嵌入層能夠使詞分布表示向目標域微調。例如在源域中哈希和加密可能表示相近語義,但在網絡安全領域中,這兩個詞應該要有明顯區分,這在具體領域的分類任務下特別重要。對于未出現在訓練中(隨機初始化)的詞,這種微調方式允許模型學習更有意義的表示。
3.4 誤差分析
為了更好地理解模型的運作,對模型分類錯誤語句進行了抽樣。圖3是一些假陽性結果,即被模型誤判為相關語句,主要原因是模型無法有效分清語句是用于描述惡意軟件屬性還是行為或其能力。

This sample is a packed 32-bit kernel driver extracted by the aforementioned DLL with an MD5 hash of: de7500fc1065a081180841f32f06a537, this sample will only function on a Windows 32-bit kernel. The backdoor is also capable of elevating its privileges on win7 and above using a method similar to the one described here: http://www.pretentiousname.com/misc/win7_uac_whitelist2.html. CozyDuke may use multiple techniques for establishing persistence; the following is one technique used.
圖4是漏報結果抽樣,表現出網絡安全中專業術語特征或一些特殊命名實體,由此可假設模型不能有效處理這些特征,當這些特征出現頻率很少時這種影響更為嚴重。因此,模型需以其它方式或者額外信息來處理這種情況。

The configuration data for CozyDuke is stored as a separate RC4-encrypted file that is written to disk by the CozyDuke dropper during initial infection. In this context, DNS hijacking is done to subvert the resolution of Domain Name System (DNS) queries through modifying the behavior of DNS servers so that they serve fake DNS information. The encrypt method encrypts the data in the modified CBC-CTS-like mode .
4 總結
本文使用了一種卷積神經網絡的變體從網絡安全報告中進行信息抽取。試圖不以語言學或者網絡安全相關知識為背景構建信息抽取方法。相比其它模型,取得了一定的性能提升,但仍不能達到實用高度。在未來工作中,仍然試圖不斷提高模型性能,使其達到供研究人員可信賴程度。探索可以解決不同領域之間自適應問題的遷移學習也可能是一種處理標記數據不足的辦法。
[1]Langner R. Stuxnet: Dissecting a Cyberwarfare Weapon[J]. IEEE Security & Privacy, 2011, 9(3):49-51.
[2]馬也, 吳文燦, 麥永浩.從WannaCry勒索病毒事件談高校網絡安全[J].網絡安全技術與應用, 2018.
[3] Fu M, Zhao X, Yan Y. HCCL. An End-to-End System for Sequence Labeling from Cybersecurity Reports[C]// International Workshop on Semantic Evaluation. 2018:874-877.
[4]高明霞,李經緯.基于word2vec詞模型的中文短文本分類方法[J].山東大學學報(工學版),2018.
[5]任勉, 甘剛.基于雙向LSTM模型的文本情感分類[J]. 計算機工程與設計, 2018.
[6]Kim Y. Convolutional Neural Networks for Sentence Classification[J]. Eprint Arxiv, 2014.
[7]Sikdar, Utpal & Barik, Biswanath & Gamb?ck. Identifying and Classifying Malware Text Using Conditional Random Fields and Na?ve Bayes Classifiers[C]// International Workshop on Semantic Evaluation. 2018:890-893. 10.18653/v1/S18-1144.
[8]Brew, Chris. Using dependency features for malware NLP[C]// International Workshop on Semantic Evaluation. 2018:894-897. 10.18653/v1/S18-1145.
[9]Padia, Ankur & Roy, Arpita & Satyapanich. Understanding Text about Malware[C]// International Workshop on Semantic Evaluation. 2018:878-884. 10.18653/v1/S18-1142.
[10]Loyola, Pablo & Gajananan, Kugamoorthy & Watanabe. Semantic Extraction from Cybersecurity Reports using Representation Learning[C]// International Workshop on Semantic Evaluation. 2018:885-889. 10.18653/v1/S18-1143.
[11]Jeffrey Pennington, Richard Socher, and Christopher Manning. Glove: Global vectors for word representation[C]// In Proc. of EMNLP. 2014:1532– 1543.
[12]Peter Phandi, Amila Silva, Wei Lu. Semantic Extraction from Cybersecurity Reports Using Natural Language Processing (SecureNLP)[C]//Proceedings of the 12th International Workshop on Semantic Evaluation (SemEval-2018). 2018:697–706
[13]Kiat Lim, Swee & Muis, Aldrian Obaja & Lu, Wei. MalwareTextDB: A Database for Annotated Malware Articles[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics . 2017:1557-1567. 10.18653/v1/ P17-1143
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
