基于Python的《水滸傳》中人物分析
2019-01-18 01:11:48楊旭東
網絡安全技術與應用 2019年1期
◆楊旭東
基于Python的《水滸傳》中人物分析
◆楊旭東
(重慶安全技術職業學院網絡與信息安全系 重慶 404020)
隨著大數據技術的應用領域不斷擴大,信息量也在日益膨脹,而有價值的信息是有限的,利用文本挖掘技術可以高效地獲取長文本文獻中的有價值信息,實現熱點追蹤。作為當前最流行的編程語言,Python能夠快速而準確地進行詞頻統計、獲取高頻詞,從而獲得文獻的主題思想。
Python語言;jieba庫;文本挖掘
0 引言
伴隨著計算機技術的發展,布朗語料庫作為世界上第一個機讀語料庫于1960年誕生,語料庫語言學在近些年得到迅速的發展和普及,并逐步趨于成熟。語料庫語言學的研究對象是真實語言使用中的語言事實,借助計算機技術和統計學方法,對語言數據進行定性定量的描寫和概括,從而全方位、多角度地揭示語言中的規律。大數據技術已經融入當今世界的各行各業,人工智能技術也得到了空前發展。自然語言處理( Natural Language Processing,NLP) 屬于人工智能的一部分,其技術的發展將使人與計算機之間的交流更加有效和便捷,也將促進以全新的理念和技術進行研究。
由于技術原因,使得我國對中文文本處理的研究起步較晚。英文單詞是以空格作為分詞標志,與中文的分詞標志、語義分析存在較大差異,英文語料庫語言學的技術不能被有效的借鑒,這也是國內在該領域落后的一個原因。但是隨著互聯網技術的普及,在知識全球化的今天,中文文本分詞技術已經日趨成熟,取得了很大的進步,已從最初的借助詞典查閱方式,到如今利用語言模型對文本進行分詞。
1 Python語言的文本處理背景
1.1 Python語言概述
Python語言的設計者是吉多·范羅蘇姆( Guido Van Rossum),第一個版本的發行時間是1990年,它是一種計算機高級程序設計語言、面向對象解釋型。在上百種流行的編程語言中,Python語言具有以下多方面的優勢:
(1)語法簡潔:實現相同功能,Python語言的代碼行數僅相當于其它語言的1/10~1/15。
(2)與平臺無關:作為腳本語言,Python程序可以在任何安裝解釋器的計算機環境中執行,用該語言編寫的程序可以不經過修改實現跨平臺運行。
(3)粘性擴展:Python具有優異的擴展性,體現在它可以集成C、C++、Java等語言編寫的代碼,通過接口和函數庫等方式將它們“粘起來”(整合在一起)。此外,Python語言本身提供了良好的語法和執行擴展接口,能夠整合各類程序代碼。
(4)開源理念:對于高級程序員,Python語言開源的解釋器和函數庫具有強大的吸引力,更重要的,Python語言倡導的開源軟件理念為該語言的發展奠定了堅實的群眾基礎。
(5)通用靈活:Python語言是一個通用的編程語言,可用于編寫各領域的應用程序,這為該語言提供了廣闊的應用空間。從科學計算、數據處理到人工智能、機器人,Python語言都能夠發揮重要作用。
(6)強制可讀:Python語言通過強制縮進來體現語句間的邏輯關系,顯著提高了程序的可讀性,進而增加了Python程序的可維護性。
(7)支持中文:Python 3.0解釋器采用UTF-8編碼表達所有字符信息。UTF-8編碼可以表達英文、中文、韓文、法文等各類語言,因此,Python程序在處理中文時更加靈活且高效。
(8)模式多樣:盡管Python 3.0解釋器內部采用面向對象方式實現,但Python語法層面卻同時支持面向過程和面向對象兩種編程方式,從而為使用者提供了靈活的編程模式。
(9)類庫豐富:Python解釋器提供了幾百個內置類和函數庫,此外,世界各地程序員通過開源社區貢獻了十幾萬個第三方函數庫,幾乎覆蓋計算機技術的各個領域,編寫Python程序可以大量利用已有的內置或第三方代碼,具有良好的編程生態。
1.2 與國內專用語料庫軟件的對比
Ant Conc、Tree Tagger作為國內語料庫研究使用較為廣泛的軟件,由于這兩個軟件在設計時考慮不周,以至于存在一些功能上的缺陷,不能對中文文本的研究提供精確有效的支持。Python作為一種被廣泛使用的高級通用腳本編程語言,擁有豐富的第三方庫,這為語料庫語言學的研究提供了一種全新的選擇。
(1)功能性和靈活性強
大部分語料庫軟件具有自己專門的應用范圍和領域:BFSU Colligator應用于類聯接分析領域;CLAWS應用于詞性賦碼領域;BFSU Collocator應用于搭配分析領域。以上軟件在自己各自領域功能強大,能完成文本的收集、整理、標注以及分析等特定功能,但是編程和使用過程繁瑣,大大影響研究效率。而Python語言借助于第三方庫,只需幾行代碼就能實現文本的分詞和統計,避免了因使用不同軟件而造成的編程語言切換和數據不兼容的問題。
(2)全面系統
過去的語料庫軟件在設計時只考慮分詞、分詞的原則,很少延伸至整句、整篇的層次,存在斷章取義的情況。Python語言不僅可用于中文文本的分詞、詞語過濾、自增語料庫,還可進行詞頻統計、句法分析、篇章分析。文本分析結果可通過Python語言的第三方Matplotlib 庫進行數據可視化處理,將分析結果以圖表的形式呈現,直觀明了。正則表達式檢索在Python語言中也得到了很好的利用。
(3)支持多種語言
國外的語料庫語言學研究也在突飛猛進,發展迅速,相關語料庫軟件隨之而面世。然而其它國家的語料庫軟件都是基于本土語言設計開發的,不能對中文文本進行處理,而Python語言下的第三方庫支持中文文本的處理,有效的解決了中文文本的研究問題。
2 Python語言在中文文本中的應用
2.1 數據源和方法
以網上下載的小說水滸傳為數據源,來進行文本分析,以統計出場最多的前十位人物。首先要將文本保存為txt格式,編碼選擇為“UTF-8”,要獲取文本中的高頻詞,需對文本進行分詞、詞頻統計,然后創建一個排除詞匯庫,在輸出結果中排除這個詞匯庫中的內容,對統計結果進行優化,最終得到的結果能直觀體現各人物的地位。編譯器選擇Python3.7版本,在https://www.python.org/downloads/網站上可以直接下載,并按提示完成安裝,安裝完成后需設置環境變量。
2.2 jieba分詞和詞頻統計
對于一段英文文本,如果希望提取其中的單詞,只需要使用字符串處理的split()方法即可。然而,對于一段中文文本,例如,“中國是一個偉大的國家”,獲得其中的單詞(不是字符)十分困難,因為英文文本可以通過空格或標點符號分隔,而中文單詞之間缺少分隔符,這是中文及類似語言獨有的“分詞”問題。
jieba是Python中一個重要的第三方中文分詞函數庫,由于其不是Python安裝包自帶的,使用時需要通過pip指令安裝:pip install jieba,在程序中用import命令來導入。jieba庫的分詞原理是利用一個中文詞庫,將待分詞的內容與分詞詞庫進行比對,通過圖結構和動態規劃方法找到最大概率的詞組。除了分詞,jieba還提供增加自定義中文單詞的功能。
jieba庫支持3種分詞模式:精確模式,將句子最精確地切開,適合文本分析;全模式,把句子中所有可以成詞的詞語都掃描出來,速度非常快,但是不能消除歧義;搜索引擎模式,在精確模式的基礎上,對長詞再次切分,提高召回率,適合用于搜索引擎分詞。
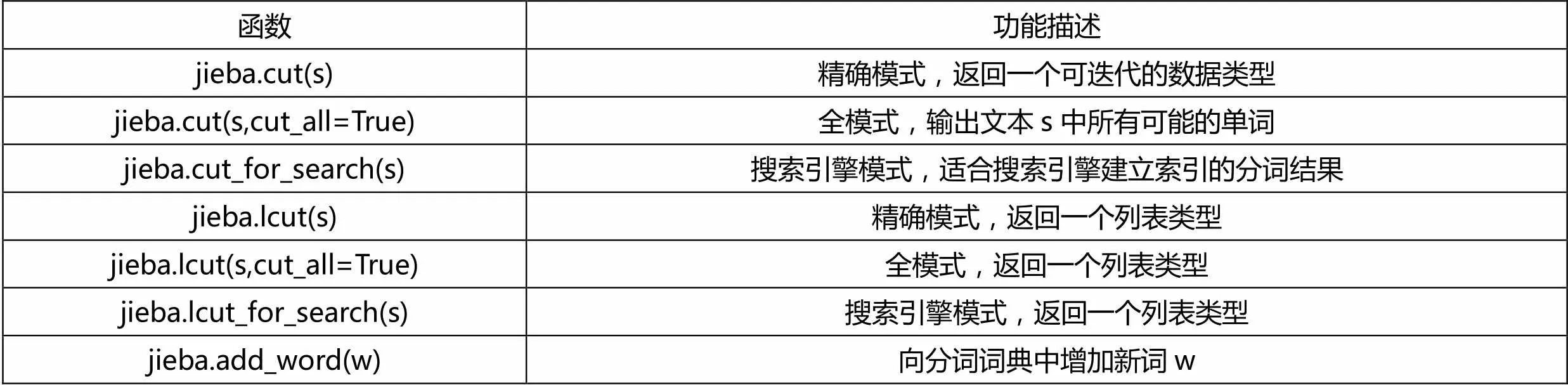
表1 jieba庫常用的分詞函數
2.3 《水滸傳》中人物出場統計
《水滸傳》是中國古典四大名著之一,作者是施耐庵。該書是第一部以描寫古代農民起義為題材的長篇小說,它在塑造人物形象方面積累了豐富的藝術經驗。作品能緊緊扣住人物的不同出身經歷,通過人物自己的語言和行動去表現其性格。作品同時也能夠很準確地把握住人物性格與身份、社會地位、生活閱歷之間的相互作用。
《水滸傳》是一本鴻篇巨著,里面出現了108位各具特色的主要人物。每次讀這本經典作品都會想一個問題,全書這些人物誰出場最多呢?一起來用Python解決這個問題。
人物出場統計涉及對詞匯的統計,中文文章需要分詞才能進行詞頻統計,分詞統計需要用到第三方庫jieba。先將《水滸傳》文本保存為“水滸傳.txt”,編碼選擇為“UTF-8”。Python語言實現代碼如下:
import jieba
excludes={"兩個","一個","只見","如何","那里","哥哥","軍馬","頭領","說道","眾人","這里","兄弟","出來","小人"}
txt=open("水滸傳.txt","r",encoding='utf-8').read()
words=jieba.lcut(txt)
counts={}
for word in words:
if len(word)==1:
continue
else:
counts[word]=counts.get(word,0)+1
for word in excludes:
del(counts[word])
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(10):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))
上述代碼是輸出出場最多的前10位人物,如需對更多的人物進行分析,只需修改代碼“for i in range(10)”中的數字10即可。統計結果如表2所示。
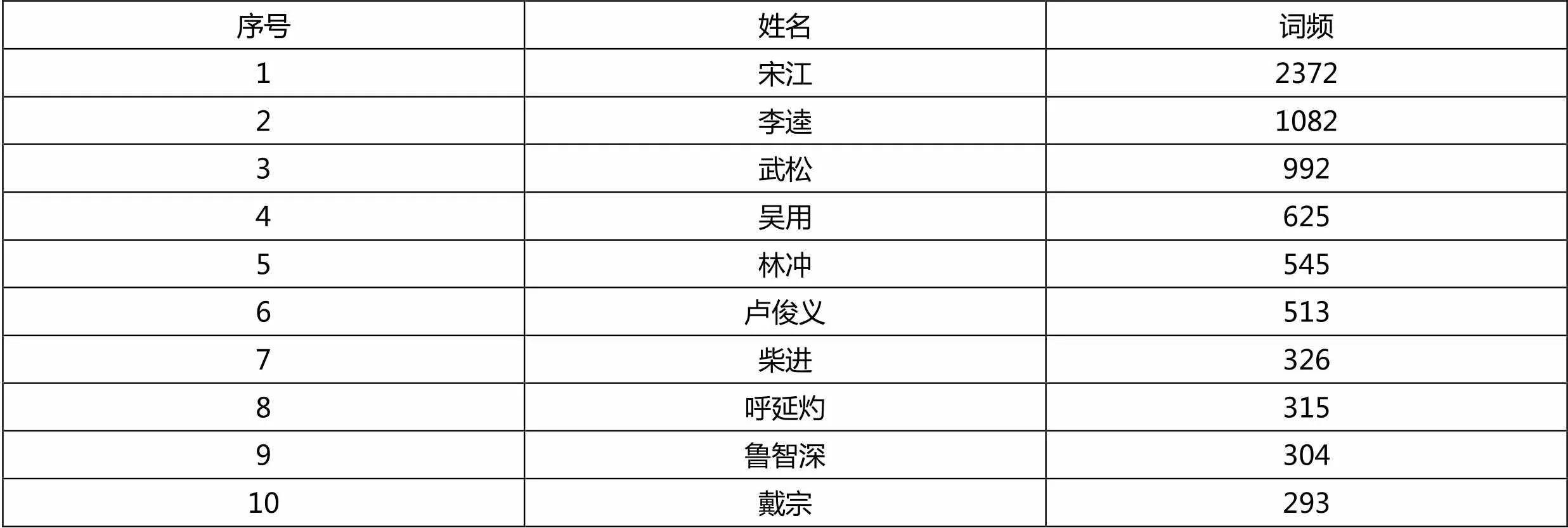
表2 人物詞頻統計表
從表2可以看出,小說《水滸傳》中宋江的出場次數最多,其次是李逵和武松,這和我們在電視劇中看到的劇情是相吻合的,利用Python的jieba庫可以幫助文學家對小說文本進行全方位地分析和研究。
3 結語
基于Python語言強大的庫功能,利用其第三方jieba庫對中文文本進行分詞、詞頻統計,準確快捷。經過詞頻統計,可以獲得文本的主旨思想。Python的源代碼編寫簡單,易于維護,從而有利于在使用過程中對代碼進行修改和優化,剔除冗余的數據。jieba庫為計算機技術在自然語言處理分析中提供了無限可能。
[1]王弘博,孫傳慶.Mark Summerfield. Python3程序開發指南[M]. 2版.人民郵電出版社,2015.
[2]李建文.計算機字符編碼—Unicode與Windows[M].科學出版社,2016.
[3]韓菲,金磊,戴文浩.基于Python的實時數據庫設計[J].儀器儀表用戶,2017.
[4]王麗杰.漢語語義依存分析研究[D],哈爾濱:哈爾濱工業大學,2010.
[5]劉旭.基于Python自然語言處理工具包在語料庫研究中的應用[J].昆明冶金高等專科學校學報,2015.
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
文苑(2020年4期)2020-05-30 12:35:30
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:24
電子制作(2018年18期)2018-11-14 01:48:06
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
山東工業技術(2016年15期)2016-12-01 05:31:22
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
小學教學參考(2015年20期)2016-01-15 08:44:38
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
