Apriori算法在個性化學習中的應用研究
2019-01-22 06:54:50周顯春肖衡高華玲
現代計算機 2018年35期
關鍵詞:學生
周顯春,肖衡,高華玲
(三亞學院信息與智能工程學院,三亞 572022)
0 引言
隨著大數據技術、人工智能、互聯網技術和教育信息化技術的飛速發展,學習資源也呈現爆發式增長,造成學習者很難從浩如煙海的資料不能快速有效地找到適合自己個性化學習資源,甚至會出現認知超載、網絡迷航[1]等異常現象。于是,個性化學習順勢而生,并已經成為教育技術領域的研究熱點[2-3]。然而,在近兩年的新媒體聯盟地平線報告(高等教育版)[4]中,個性化學習被定義為是一項“了解但解決方案尚不清晰的困難挑戰”,并且認為目前個性化學習最大的障礙就是如何把紛繁復雜的方法和技術轉變成一套精簡的策略,開發出有教學理論指導的個性化網絡學習系統。
現在是大數據、人工智能時代,一切以數據為基礎,用數據說話。通過獲取學生個性特征、學習行為軌跡數據,利用機器學習算法能夠精準識別學習中的個性化特征、推薦優秀的學習資源、學習路徑,預測未來的學習行為、學習結果。對于預測結果欠佳的學習,需要盡早給予個性化學習強制干預、有效指導,讓學習者能克服時空的限制實現自我導航,避免認知過載,提高學習者的學習興趣,激化學習中潛在的學習潛能,最終達到最優的學習效果。
當前,國內外利用機器學習算法對個性化學習研究多集中在個性化學習路徑推薦、個性化學習系統、個性化教學方法、個性化學習評價模型等幾個方面。姜強等[5]基于大數據背景下以AprioriAll算法分析并通過實驗驗證群體信息挖掘個性化的學習路徑。周海波[6]提出根據學生個性特征推送個性化的學習資源。牟智佳[7]為了對學習效果有效評價,采用基于聚類的層次性個性化化評價體系,有助于個性化評價系統的實現。以上研究都忽視一個關鍵內容,即學生的學習特征,包括學習風格,與知識點內容之間是有本質區別的。學生特征沒有時序性,而知識點之間大多數是有時序性的。根據學生風格、特征使用Apriori進行聚類,都不能產生符合時間序列的資源或者學習路徑推薦。
在海量的教育教學數據環境下,為了更好改善個性化學習效果,本研究主要從兩個方面對以前的研究成果進行改進。一是對Apriori算法在Spark分布式計算框架并行化,改善算法的實時性;二是利用學習目標和知識點修改Apriori方法推薦的知識點序列,讓學習內容或路徑更有針對性,改善個性化學習的質量。
1 Apriori算法研究
Apriori算法是R.Agrawal用于解決關聯規則問題的數據挖掘方法[8],得到廣泛的應用。隨著數據規模、維度的不斷增大,造成該算法在實際場景運用中也存在時間延長、內存不足的問題。為了改善其挖掘的效率,利用分布式架構Hadoop、Spark,大量的學者并行化Apriori算法研究,可以大幅度提升數據挖掘的效率。對比Hadoop平臺,Spark的效率更高[9-10]。
1.1 基于Spark的Apriori算法優化
Spark引入彈性分布式數據集RDD數據模型,集成了節點集群內存,適合迭代計算,不需要訪問磁盤。相對于Hadoop,Spark更適合分布式處理場景。Trans?actions、Action是Apriori算法并行化迭代計算實現的核心[8]。Apriori在Spark上實現分為兩個階段,第一階段迭代求出每個項集,第二階段針在第j個項集前提下求出第i+1項集的候選集。
輸入:數據源 DataSet,最小支持度閾值Count_min_sup。
輸出:K-項頻繁集。
#頻繁集合生成偽代碼
(1)采用并行化得到分區的RDD,分發給worker;#每個worker節點可以獨立工作;
(2)flatMap()作用于數據集中的 Transaction,讀取每個中的Item;
(3)map()轉換 Item 成鍵值對(Item,1);
(4)reduceByKey()用于計算每個Item的出現的次數,filter()對于Item的次數小于Count_min_sup的進行剪枝;
(5)最后,把剪枝后的Item轉換成Set中保存。#規則生成偽代碼
(1)轉換Item的Set為候選項集Set(T);
(2)頻繁集合的元素進行自連接,產生K+1候選集;
(3)重復頻繁集生成過程。
1.2 基于學習目標和知識點的Spark的Apriori算法優化
經典或并行化的Apriori算法首先要從Transaction中獲得Item出現的次數,再根據次數閾值過濾、自連接生成規則。基于學習目標的并行化Apriori,針對學習目標,先過濾Transaction,即Transaction的Item不包含學習目標的關鍵詞(知識點關鍵詞)直接刪除,可以大幅提升其推薦的效率。
相對于其1.1并行化Apriori偽代碼,需要修改兩句一是頻繁集生成的第二句為:flatMap()作用于數據集中的Transaction,filter讀取每個中的Item,過濾掉沒有學習目標關鍵詞的Transaction;二是把規則生成偽代碼的第二句修改為:頻繁集合的元素進行自連接,然后根據知識點、知識點的關系排列Item順序,產生有序Item的K+1候選集。
1.3 基于Spark的Apriori算法性能比較
目前,Spark支持四種運行模式。本地單機模式、集群模式,而集群模式又分為基于Mesos、基于YARN、基于EC模式。本文的Spark分布式集群基于YARN,即Hadoop2[11]。
(1)實驗條件
軟件:Ubuntu Server 17.10,Hadoop 2.7,JDK 1.8。硬件:6臺聯想商用機,CPU是主頻3.4GHz的Intel酷睿i5,硬盤容量512G,內存8GB。
實驗數據:數據量大小為2G,Transaction平均長度為38MB,共120個Item項集,包括約500萬條Trans?action記錄。
實驗計劃:首先,采用經典Apriori算法以及保持10個節點的集群環境下的并行化MapReduce-Apriori、Spark-Apriori算法,在處理不同數據集的情況下,不同的算法運行時間關系如圖1所示;其次,采用200萬條數據集,從一臺機器開始,以2的倍數遞增機器數、節點數。MapReduce-Apriori、Spark-Apriori算法分別在1、2、4、8節點時完成任務的運行時間結果如圖2所示。基于學習目標和知識點的Spark-Apriori簡稱為改進的Spark-Apriori。
由圖 1可知,無論是 MapReduce-Apriori還是Spark-Apriori算法都比經典Apriori算法的完成相同任務執行時間短、效率高。隨著數據量的增加,分布式算法優勢更加明顯,而且Spark-Apriori比MapReduce-Apriori更適合大數據環境,原因是Spark-Apriori算法是基于內存進行迭代計算,大大減少數據需要I/O讀取時間,而且因為簡化運算,改進的Spark-Apriori比Spark-Apriori的運行時間更短。由圖2可知,隨著worker節點數增多,改進 Spark-Apriori、Spark-Apriori、MapReduce-Apriori算法執行時間越來越短,說明計算節點worker節點越多越能提高算法效率。
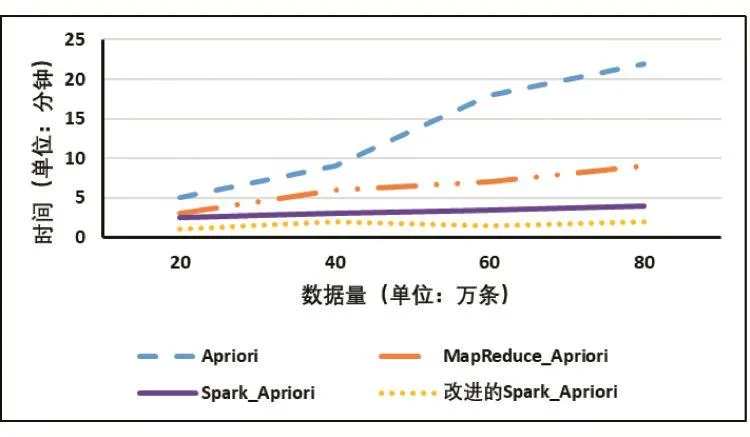
圖1 三種算法不同數據量的運行時間圖
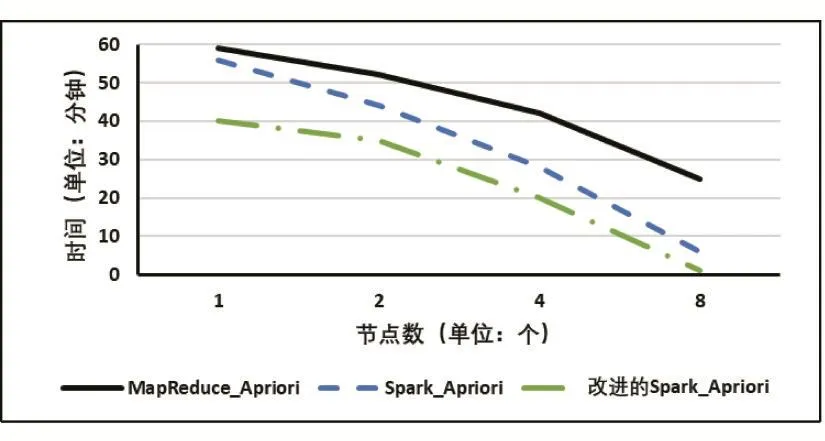
圖2 兩種算法在不同節點數的運行時間
2 基于Spark并行化Apriori的學習規則分析與挖掘
Apriori可以不僅應用在學生的成績分析上[12],如知識點與學生能力[13]之間的相關性,而且還可以與學生風格相結合。本研究在個性化學習的應用中最大的創新點是根據學習目標,即需要掌握的知識逆推學習過程。如果要完成該學習目標,需要掌握那些知識點序列。知識點之間不僅有時間順序,而且還可以根據學生的風格和學習能力可以動態調整,以最優的路徑掌握知識點。
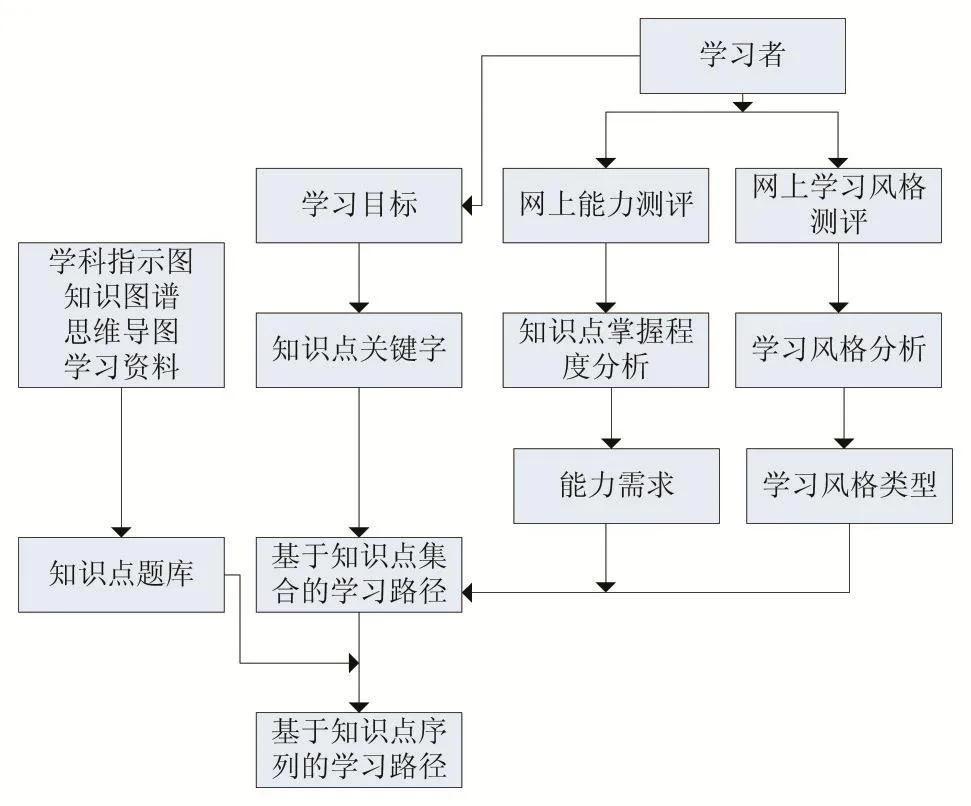
圖3 基于學習目標的個性化學習推薦路徑生成架構
2.1 基于并行化Apriori的知識點題庫系統構建
以教育教學的布魯姆認知目標為依據,構建學科知識點模型、知識思維導圖,然后利用jieba+Apriori方法完成知識點、知識點關系的提取和集成。例如,利用閔宇鋒[14]等提出方法可以生成進制二和字符表示知識點及關系如圖4。
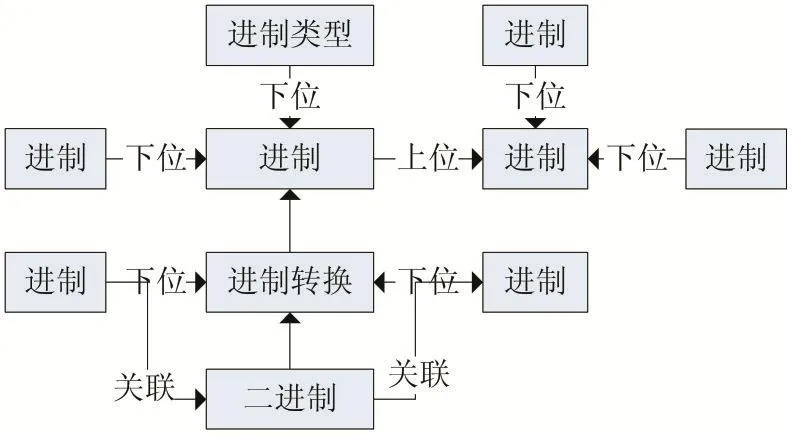
圖4 進制、字符表示知識點及關系圖
2.2 基于并行化Apriori的知識點與能力、學習風格之間規則的分析
(1)收集數據
在學生確定學生目標之后,要求學生填寫基本特征的調查表,涉及內容有學生姓名、性別、學號、學習風格、學習時間等內容,接著學生參加基于學習目標的知識點題目測試,測試結果能夠動態調整學習路徑。
(2)基于學習目標和知識點的Spark的Apriori算法的知識點推薦
在基于學習目標的并行化Apriori算法完成學習路徑推薦后,使用知識點對學習路徑進行修正。例如,中文字符表示知識點的學習。
①根據學習風格、學生特征[4]可以獲取Transac?tion,但是通過中文字符、漢字、字符表示等關鍵詞篩選后剩下少量的 Transaction;如:{進制,字符表示},{進制,西文,漢字},{十進制,二進制,西文,漢字輸入,漢字存儲,漢字輸出},……
2.3 基于學習目標和知識點的個性化學習推薦路徑學習績效評測
為了體現本研究的效果,以物流專業50名學生作為研究對象,講授《計算機應用基礎》課程。按照學號計算機隨機均等分組,每組25人,一組自主學習,另外一組按照推薦學習路徑學習,采用靈活的在線和翻轉課堂方式開展一個學期的學習。期末考試后,隨機挑選4位學生,從網上平臺提取學習數據和學習成績對已完成學習績效進行客觀分析,如圖5、6所示。
由圖5知,自選學習路徑的學生所花費學習時間要多于按照個性化推薦路徑學習的學生;由圖6知,使用個性化推薦路徑學習的學生成績要好于自選學習路徑的學生。因此,學生按照個性化學習路徑學習時,無論花費的學習時間還是產生的學習效果的效率都自選學習路徑要好。
3 結語
在海量的教育教學數據環境下,為了更加改善個性化學習的效果,本研究以學習目標為核心,利用在Spark平臺上并行化Apriori方法逆向推薦基于有序知識點的學習內容或學習路徑。經過教學實踐驗證,基于學習目標的個性化學習推薦路徑能夠大幅提升學習者學習效率,可以解決認知超載、網絡迷航等問題,也為該類平臺的實現提供研究思路。

圖5 不同學習組的學習時間比較
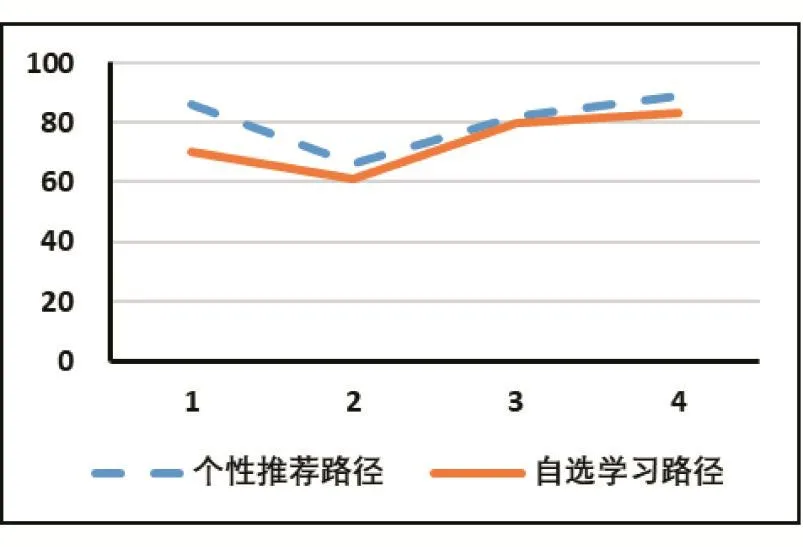
圖6 不同學習組的學習成績比較
猜你喜歡
作文大王·笑話大王(2021年4期)2021-04-26 19:00:35
英語文摘(2020年9期)2020-11-26 08:10:12
甘肅教育(2020年6期)2020-09-11 07:45:16
甘肅教育(2020年22期)2020-04-13 08:10:54
甘肅教育(2020年20期)2020-04-13 08:04:42
當代陜西(2019年5期)2019-11-17 04:27:32
電影(2018年9期)2018-11-14 06:57:21
作文世界(小學版)(2018年4期)2018-10-16 17:13:34
快樂作文·低年級(2016年12期)2017-01-03 20:52:44
快樂作文·低年級(2016年6期)2016-06-24 18:58:40
