面向中亞地區的多語種專業領域術語庫及本體知識庫構建
2019-01-30 02:22:12原偉
中國科技術語 2019年6期
摘 要:針對目前烏茲別克語、哈薩克語等中亞語種急缺專業領域詞典、術語庫及知識本體庫的問題,文章以安全領域為例,利用現有術語作為種子詞,自動采集維基百科及雙語專業詞典中的術語對,人工校對后構建了中型中、俄、烏、哈多語種專業領域術語庫。以此術語庫為基礎,搭建了包含人員、組織、地域、技術、設備、活動、文件7大類及35個子類的領域本體,最后討論了該專業術語庫及領域本體庫的擴展潛力和應用前景。本成果是一項重要的基礎性工作,對中亞語種的術語詞典編撰、術語學、自然語言處理和語言教學研究均有較大現實意義。
關鍵詞:中亞;術語;本體;俄語;烏茲別克語;哈薩克語
中圖分類號:H059; H083文獻標識碼:ADOI:10.3969/j.issn.1673-8578.2019.06.002
Abstract: Studies on languages of Uzbek, Kazakh and other Central Asian are facing a problem of lack of professional domain dictionaries, terminology and knowledge ontology. For solving this problem, we take the military field as an example, and use the existing terms as the seed word to automatically collect bilingual terminology pairs from Wikipedia and professional dictionaries. Based on manual proofreading, we built a medium-sized Chinese, Russian, Uzbek, and Kazakh term base. Based on this term base, the military domain ontology has built, which includes 7 categories (person, organization, region, technology, equipment, activity and document) and 35 sub-categories. We also discussed the potential and application prospects of the term base and ontology library. This achievement is an important basic work, and it has great practical significance for the compilation of terminology dictionary, terminology, natural language processing and language teaching in Central Asian languages.
Keywords: Central Asia; terminology; ontology; Russian; Uzbek; Kazakh
收稿日期:2018-01-01修回日期:2019-11-01
基金項目:國家社會科學基金項目“基于本體的俄漢可比語料庫構建與評估”(14CYY051);國家社會科學基金項目“基于可比語料庫和本體的俄漢網絡新聞話題監測與情感識別研究”(18BYY235)
作者簡介:原偉(1981—),男,博士,副教授,主要研究方向為計算語言學和語料庫語言學。通信方式:yw5811827@126.com。
引 言
建立多語種術語庫是基于系統論整合語言數據資源的一種思維方式和實踐手段,其根本目的是收集并高效利用多語言數據,以實現語言資源的優化配置。在“一帶一路”倡議深入推進的大背景下,構建以漢語為中心的多語言互動術語資源庫,可以提供更好的術語檢索、分析、利用及共享平臺,使其服務于社會科學和自然科學研究,契合了國家的宏觀發展戰略。中亞五國(烏茲別克斯坦、哈薩克斯坦、吉爾吉斯斯坦、塔吉克斯坦和土庫曼斯坦)是“一帶一路”建設的重要支點,而對象國語言的教學、研究與資源建設工作以前在國內長期未予以足夠重視,語言教學和人才培養剛剛在國內拓寬展開,語種教材編寫、辭書編撰、資源建設等各方面工作都存在較大缺失與不足。針對上述問題,本研究嘗試開展一些基礎性工作,構建以中文為核心、涵蓋中亞通用語種(俄語、烏茲別克語和哈薩克語)的多語種領域術語庫,并以此為基礎構建領域本體用于術語調用與知識共享,以期為后續研究工作拋磚引玉。
一 研究現狀
通常來說,術語數據庫是“存儲在電子計算機中啟示概念和術語的自動化詞典”[1]。術語數據庫的研究與開發,是術語學與術語標準化工作的重要內容之一,也是術語信息管理與使用的重要手段[2]。多語種術語庫,即包含多種語言并相互關聯的術語數據庫。在國外,多語種術語庫的建設已有悠久歷史,如1959年德國國防部投入開發的LEXIS術語庫(LEXIS terminological databank)包含德語、英語、法語、俄語、波蘭語、荷蘭語和意大利語7種語言,年均收錄術語3.5萬條;1963年建立的歐洲共同體委員會術語庫(Eurodicautom)至1976年收錄40萬條術語,從法、德、意、英、荷、丹麥等6種語言逐步擴展到11種語言;1967年由西門子公司投入建設的多語種術語庫TEAM有英、法、西、俄、意、葡、荷、德等語種,目前術語規模達到200余萬條;20世紀80年代建立的聯合國術語庫UNTERM(The United Nations Terminology Database)包含英語、阿拉伯語、漢語、法語、俄語和西班牙語,外加德語和葡萄牙語,目前收錄有29萬條名詞詞目;2004年投入使用的歐盟IATE互動型術語庫(Inter Active Terminology for Europe)涵蓋歐盟24種語言、870萬條術語。1989年以來,國內多個機構陸續建立不同類型的專業術語庫。經過多年的發展,除全國科學技術名詞審定委員會建立的術語庫外,國內其他的重要術語庫有:機械工程術語庫,于1988 年建立,隸屬于機電部科技司科技情報所的機電術語信息中心;中國百科術語數據庫,以《中國大百科全書》為基礎,建立于1993年,隸屬于中國大百科全書出版社;中國漢英英漢科技術語庫,于1995年建成,隸屬于中國科學技術信息所,主要用于科技翻譯工作[3]。相比而言,國內術語庫建設無論從語種還是規模上來看都存在較大缺失:僅機械工程術語庫有英、俄、德、日、法5種語言,其他大多僅包括漢英兩種語言,而針對非通用語種以及中亞語種的術語詞典以及術語庫建設研究,目前鮮有學者涉及。
本體是概念模型的明確的規范說明[4],是一種系統性表示某一領域知識框架的手段,通過對概念、術語及其相互關系的規范化描述,可以勾畫出特定領域的知識體系,為領域知識提供形式化依據[5]。根據本體中使用語種的多少,可以將本體分為單個語言和多語言兩類本體。多語種本體是指本體中存在不同語種中的表示形式,相當于使用不同語言建立的語義框架,可以作為跨語言信息檢索的重要工具。多語種本體中不同語種的實例可以通過共同的概念類相互聯系,相當于跨語言同義詞規范,不同語種的本體框架對應的概念內涵是統一的。在使用多語言本體進行跨語言信息檢索時,由于跨語言同義詞規范的存在,不同語種的概念及概念實例能夠相互映射。在多語言本體中,擁有相同概念內涵的類可以不用任何一個語言的詞匯來體現,只要明確其定義與所指,用編碼、符號或者數字也能夠標示。當前世界上諸多跨語言本體均是以WordNet為基礎或采用與其相同的框架系統搭建的,例如歐語詞網(Euro WordNet)、英俄雙語本體(Russian WordNet),還有中國的CCD、HowNet和中國臺灣中英雙語知識本體詞網(The Academia Sinica Bilingual Ontological WordNet)等。建立這些多語言本體其主要目的就是為跨語言信息處理奠定基礎,使這些本體能夠應用于信息檢索、信息抽取、機器翻譯、知識檢索等工作中。
二 術語庫構建
1. 總體設計
本研究多語種術語庫構建的基本思路是:首先,選定特定專業領域開展實驗研究,通過使用現有的術語資源構建以中文為核心的領域詞表;其次,使用該領域詞表依據維基百科網頁命名規則、借助多語言鏈接獲取對應的多語種詞條網頁;最后,使用網頁分析技術抽取網頁條目名稱,依據維基百科詞條的已有對應建立多語種術語對齊。
2. 初始領域詞表建立
本文初始領域詞表參考了烏茲別克語漢語專業領域詞典[6],結合收集補充的術語資源處理加工后,最終領域詞表包含漢烏對應術語對共1.71萬對,作為下一階段獲取維基百科俄語、哈薩克語的基礎資源。維基百科作為多語種術語來源具有諸多優勢,如詞目主題性強、規模較大、格式規范、信息完整、免費公開、下載便捷等,提供的多語言鏈接確保可通過技術手段自動獲取天然對齊的術語對。然而,維基百科多語種網頁資源存在不對稱性,即條目沒有做到完全對應,存在對應缺失,中、俄、烏、哈網頁的數量比例約為1∶1.5∶0.2∶0.1(2019年4月16日統計),這就要求需要使用漢語、俄語、烏茲別克語和哈薩克語術語獲取的鏈接相互補充,盡可能完善術語的多語言對齊關系。
3.基于維基百科多語言術語獲取
從維基百科中獲取多語種術語的網頁,可以利用網址命名規則來實現。維基詞條的網址命名中通常會使用與語種及詞條相關的字符串,例如中文術語“火箭”的網址為“http://zh.wikipedia.org/zh-cn/火箭”,其中“http://zh.wikipedia.org/zh-cn/”部分一般稱為網址的“pathname”,而字符串“火箭”為網址的“basename”,相應的俄文網頁網址“http://ru.wikipedia.org/wiki/ракета”。可以看出維基百科網站詞條的命名規則較為簡易規范,如果將領域詞作為“basename”依次添加至相應語種的“pathname”之后,就會得到相應詞條的維基百科網址。通過對多語言鏈接的源碼的分析可以發現,所需要的多語言超鏈接可從網頁源文件中得到。獲取網頁中超鏈接的技術方法有很多,在這里將介紹本文使用的正則表達式的方法。從形式上來說,正則表達式就是用來刻畫符號串集合的代數表達式。對于維基百科多語言鏈接的獲取任務來說,可以將其當作一個從眾多字符串中篩選匹配字符串的任務。在此,本文為獲取維基詞條網頁對應的中文、俄文、烏茲別克文、哈薩克文鏈接所設計的正則表達式如下:
中文網頁鏈接獲取的正則表達式:
·(?is)
俄文網頁鏈接獲取的正則表達式:
·(?is)
烏茲別克文網頁鏈接獲取的正則表達式:
·(?is)
哈薩克文網頁鏈接獲取的正則表達式:
·(?is)
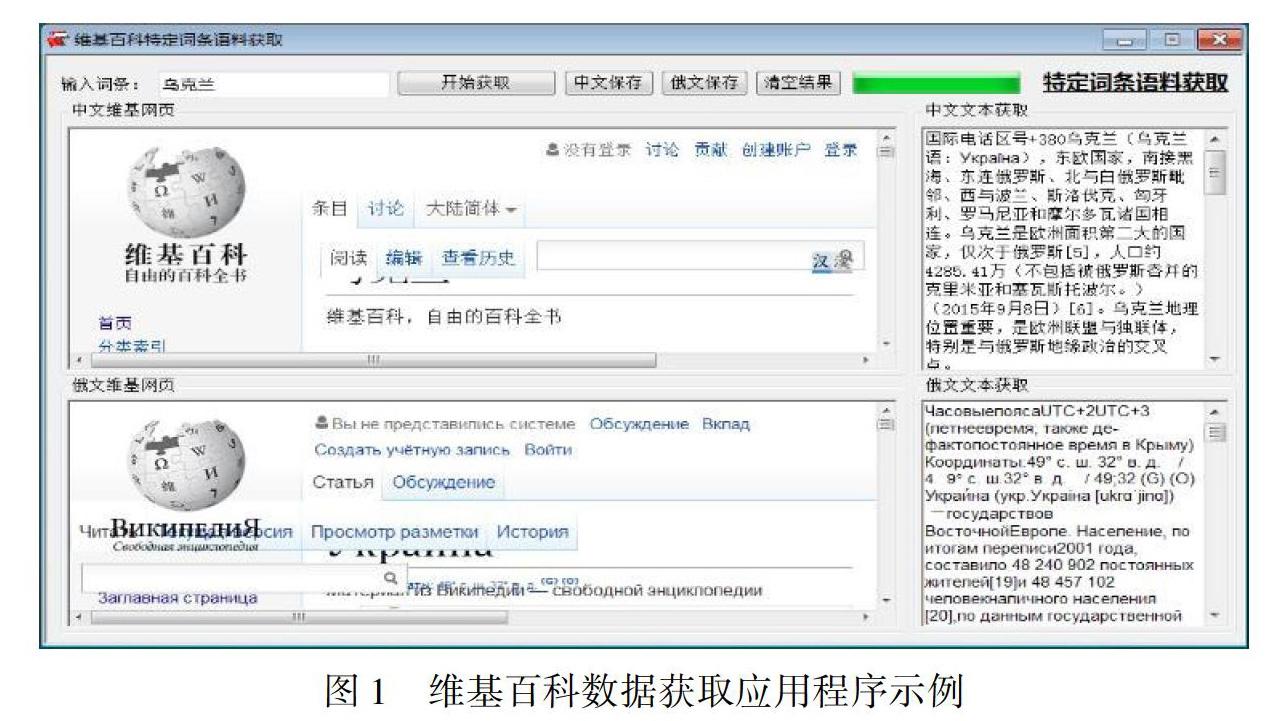
這樣一來,通過分析維基網址的命名規則使用領域詞表獲得了對應的詞條網址,之后使用一種語言的詞條網址得到其網頁源碼,通過對網頁源碼使用正則表達式搜索匹配到了另一種語言對應詞條的網址鏈接。隨后,我們研制開發了俄漢維基百科語料獲取應用程序,包括單詞目和多詞目術語獲取模塊,初步實現了通過領域詞表獲取俄漢維基百科語料的自動化。該系統不僅能獲取網頁的術語詞目,還可獲取術語解釋的正文內容。圖1是中、俄文程序界面。
最終,針對自動采集的術語,進行了人工校對與加工,以保證其準確性。在術語條目存儲格式方面,在錄入建庫之后,為了保證后期能夠將多語種詞目及對應關系順利導入本體知識庫,所有詞目均以XML格式表示,并存儲入MySQL數據庫,方便使用Java的OWL(本體表述語言)應用接口Jena進行調用。最終構建的術語庫包含術語總計7.2萬余條(中文2.1萬余條、烏茲別克文1.9萬余條、俄文2萬余條、哈薩克文1.2萬余條)。
三 本體構建
本體在系統開發中較多應用于構建領域知識模型,它提供了領域建模所需的基本概念并明確了概念間的關系。一般來說,領域知識包括領域概念、概念的性質、概念之間的關系、概念之間的一般規律等。領域本體在構建時根據概念之間的隸屬關系顯式地建立聯系,清晰定義每個概念的具體屬性,屬性的取值范圍、約束關系、相互關系等,使概念及概念實例之間的通用規律、核心聯系和基本假設等都能被顯式地描述出來。由于本體通常面向特定領域,是描述領域知識的概念模型,所以本體模型中的類或概念至少在該特定領域或者某個范圍內是有共識或公認的。正因如此,領域本體在一定范圍內可以共享復用,能夠提供特定領域的概念定義和概念關系,提供該領域中主要公理和基本規律等。本文使用的本體構建工具是美國斯坦福大學醫學院信息中心(Stanford Medical Informatics, SMI)開發研制的Protégé 4.3,是可擴展的、跨平臺的、開放源代碼的開發環境,數據庫支持完善,支持將本體導入并輸出為所需的文件格式(TXT、XML、RDFS、OWL等)。由于Protégé對英文編碼支持較為完善,在構建本體時類和關系的命名采用英文,而實例保留中、俄、烏、哈4種語言。
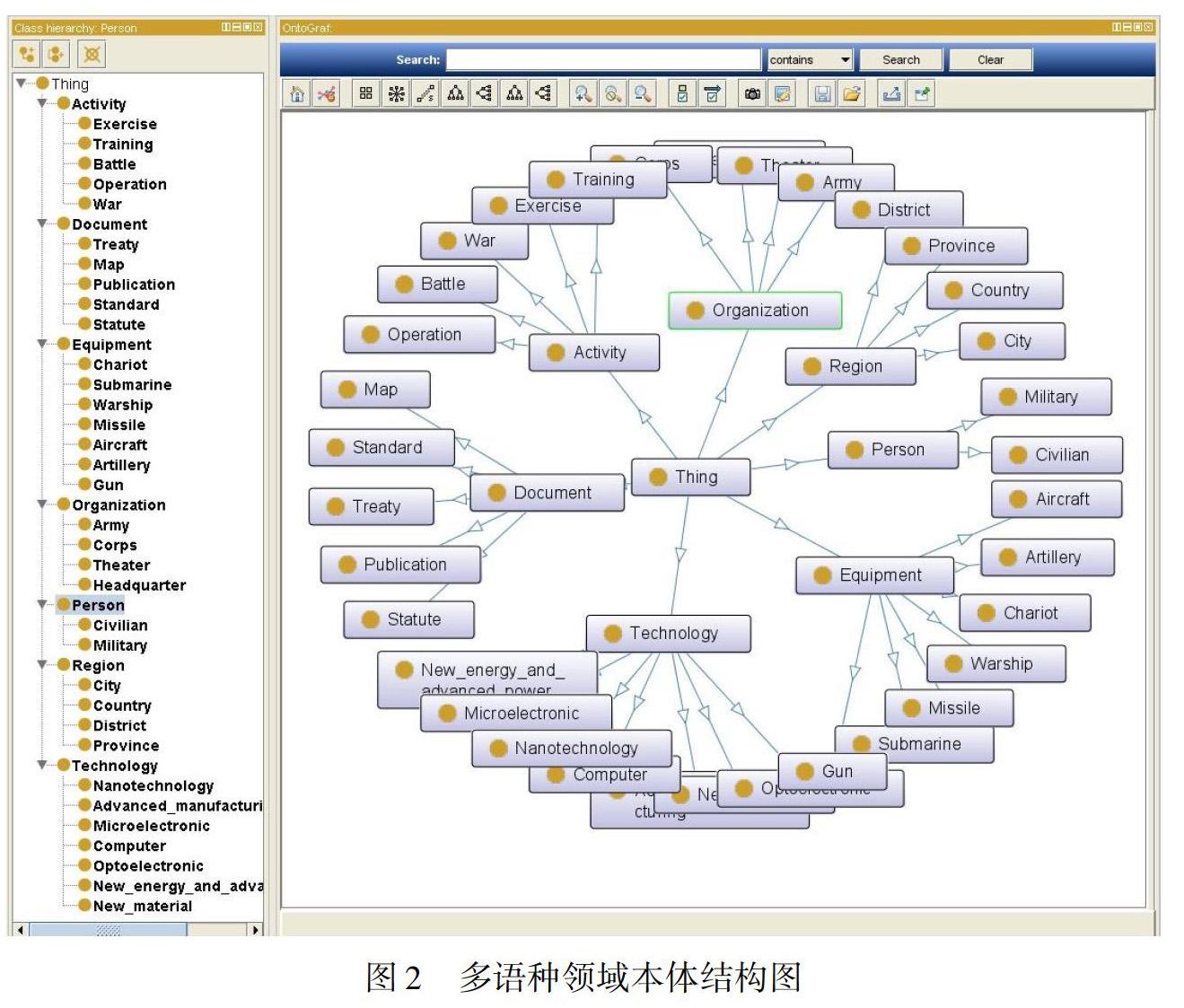
首先,建立本體類。領域內的概念在本體中以類的形式展現,類及類的層級體系是本體知識庫的核心框架,定義類和層次時需要注意的是要確保類層次的正確性,分清類的相互關系。現有三種開發方法可以選擇:由下而上的方案,即先定義領域中代表性子類,之后把這些概念歸類為概況性父類;由上而下的方案,即首先定義領域中概括性父類,隨后細化定義下分的子類;由內向外的方法,即最初定義最明顯的種類,接著對這些類進行泛化和特殊化。基于所構建的中、俄、烏、哈多語種術語庫,本文按照自上而下的方案,將本體知識庫設計為包含人員、組織、地域、技術、設備、活動、文件7大類及35個子類的領域本體。領域本體結構見圖2。
其次,添加本體實例。添加實例的過程是為本體中的概念類加入現實世界中的具體對象物,即領域中的具體對象。對于本文來說,添加實例的過程就是將多語種術語歸類錄入本體知識庫的過程。按照上述本體知識的分類規則,我們對術語表中每一個術語進行了分類標注,并體現在對術語描述XML文件中,以便于后期術語作為本體中的實例順利導入本體庫中。中、俄、烏、哈多語種術語導入的XML文件示例如下:
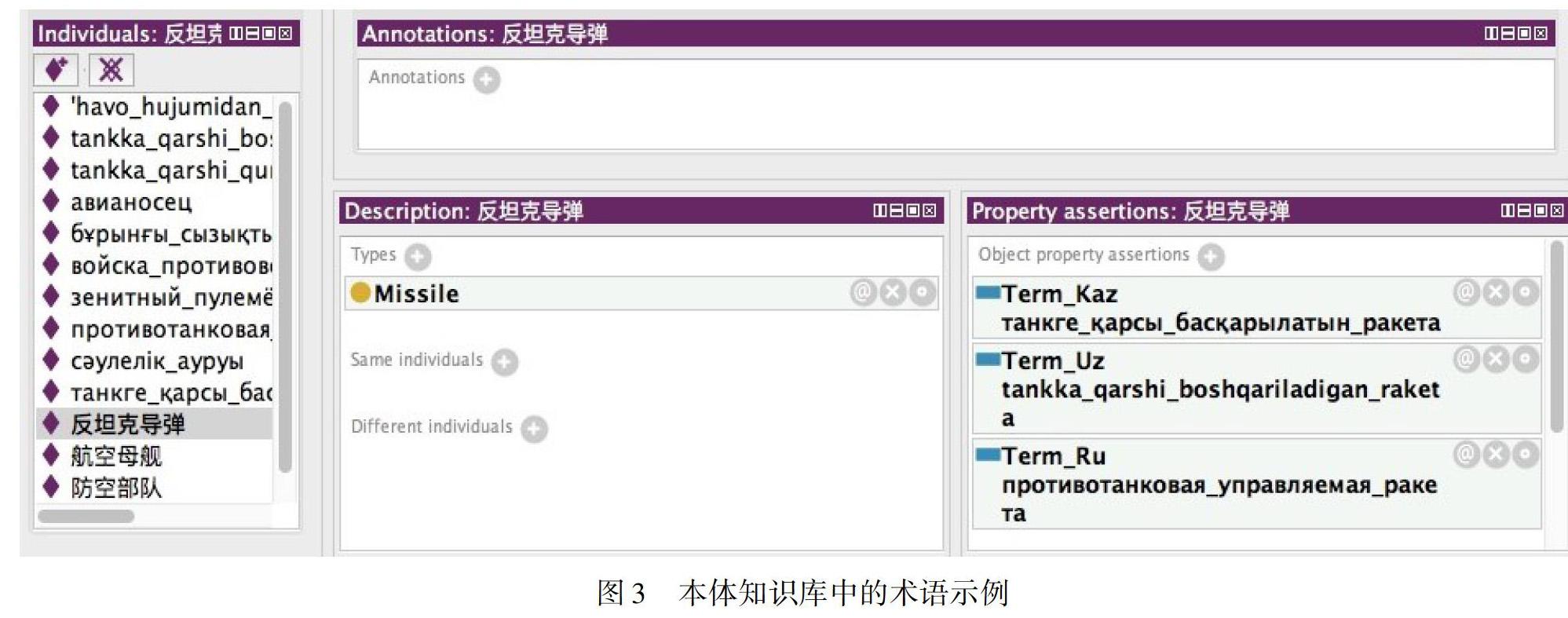
最后,建立實例關系。屬性一般包括數據屬性和對象屬性。通常來說,數據屬性是類和實例的固有屬性、外在屬性和局部屬性,而對象屬性體現了類和實例之間的關系。根據本體中使用語種的多少,可以將本體分為單語言和多語言兩類本體,由于本文構建的本體為多語種本體,那么通過對象屬性建立類、實例間的多語種關聯映射尤其關鍵。多語言本體中不同語種的實例可以通過共同的概念類相互聯系,相當于跨語言同義詞規范,不同語種的本體框架對應的概念內涵是統一的。在使用多語言本體進行跨語言信息檢索時,由于跨語言同義詞規范的存在,不同語種的概念及概念實例能夠相互映射。在多語言本體中,擁有相同概念內涵的類甚至可以不用任何一個語言的詞匯來體現,只要明確其定義與所指,用編碼、符號或者數字也能夠標示。根據當前學界的研究成果,本文將多語言本體的構建方法分為衍生拓展法、中介語映射法和關系注釋法三種:(1)使用衍生拓展的方法構建多語言本體,就是在原有單語言本體的基礎上,進行多語言拓展;(2)使用中介映射的方法構建多語言本體是指使用中間語言、編程語言,甚至數字編碼的方式,為多個語種建立統一的映射鏈接,以達到跨語言信息處理的目的;(3)使用關系注釋的方法構建多語言本體主要采用添加多語言注釋、構建等價類或對象屬性的方法建立語言間的鏈接與映射,這種方法一般針對特定領域和信息處理任務。本文采用的方式即為關系注釋法,具體來說就是通過對7大類的35個子類設置對象屬性“Term_Zh”(中文術語)、“Term_Ru”(俄文術語)、“Term_Uz”(烏茲別克文術語)和“Term_Kaz”(哈薩克文術語)四個屬性來建立子類多語種實例間的映射關聯,而該關系的建立可以在術語的XML文件映射到本體庫時自動添加。具體術語示例見圖3。
四 討 論
第一,中亞語種的專業領域術語特點考察。通過構建多語種術語庫和本體知識庫,我們發現:在詞匯層面,中亞語種專業領域術語體系中普遍存在大量俄語借詞、部分英語借詞以及突厥語體系中的共有詞,這些借詞有益于中亞語種術語漢譯的規范化和統一化,但翻譯標準的制定目前仍舊缺失;在語法層面,中亞語種語法體系的典型共性特征包括詞類體系、黏著詞尾、動詞體態式范疇等,同時在術語的句法關系和語義表述上也存在諸多共性,這就為找尋規則自動抽取和處理多語種術語提供了積極線索;在語音層面,雖然烏茲別克語同哈薩克語的顯著不同在于不存在元音和諧現象,但不可否認其相互之間在音韻、語調、音節類型等方面均存在較大相似性,也存在大量音節轉換規律,為中亞語種術語在語音層面的自動處理提供了契機。
第二,拓展潛力與應用前景。首先,在該術語庫和本體的拓展潛力方面,可在語種上增加吉爾吉斯語、土庫曼語、塔吉克語以及英語,以便更好地考察中亞語種的專業領域術語特點,并建立寶貴的語言數據資源;在數量和規模上進一步擴大術語庫的收詞范圍和涉及領域,如政治、外交、經濟、法律、醫學等,以適用于更多場景和應用需求;在知識體系上,進一步關系細化本體的概念類劃分,增加屬性關系,豐富術語實例,使其能真正體現領域特征并代表領域知識,為語義檢索和智能應用奠定基礎。其次,在該術語庫和本體的應用前景方面,可為語言教學和辭典編撰工作提供積極幫助,為自然語言處理研究提供實驗樣本、初始數據和參照規則,為語言學、術語學和翻譯學研究提供鮮活語料和豐富案例。
第三,本研究存在的不足和亟待解決的問題。首先,所構建術語庫規模還比較小,本體知識庫的概念分類體系還需優化,實例數量還需增加,屬性關系還需優化。其次,在術語采集、加工處理和校對審定方面,還需制定更加嚴格的標準和規范,以保證術語的準確性、可靠性和權威性。最后,后續研究還應積極探索新技術和新手段,將智能化和自動化的自然語言處理方法有效地融入術語的加工生產整個過程中,做到擴大規模、提高效率并兼顧準確。
五 結 語
總之,本研究是中亞多語種領域術語庫和本體知識庫構建的基礎性工作,在研究內容上嘗試了新的研究方向以期為中亞語種的領域術語研究拋磚引玉,在研究方法上嘗試將傳統研究方法同自動化方法相結合,在研究結果上發現了中亞語種術語的一些共性特征并指出后續研究的方向,可以說本成果對中亞語種的術語詞典編撰、術語學、自然語言處理和語言教學研究具有一定的價值和現實意義。希望本成果能吸引更多的研究同人加入這一研究方向,在后續的工作中將相關工作推向新的臺階。
參考文獻
[1] 馮志偉.現代術語學引論[M].增訂本.北京:商務印書館,2011:244.
[2] 劉青.中國術語學研究與探索[M].北京:商務印書館,2010:538.
[3] 顧春輝,溫昌斌.聯合國術語庫建設及其對中國術語庫建設的啟示[J].中國科技術語,2017(3):5-9,34.
[4] Gruber T R.A translation approach to portable ontology specifications[J].Knowledge Acquisition,1993,5(2):199-220.
[5] 原偉,易綿竹.俄語計算語言學領域本體知識庫的構建[J].解放軍外國語學院學報,2012,35(1):41-47,125.
[6] 原偉.烏茲別克語-漢語·漢語-烏茲別克語軍事術語詞典[M].北京:軍事誼文出版社,2013.
