基于項目協同過濾的電視產品營銷推薦模型
2019-01-30 12:53:10檀亞寧金澤明陳輝
科技資訊 2019年32期
關鍵詞:數據處理
檀亞寧 金澤明 陳輝


摘? 要:互聯網技術的快速發展和應用拓展使我們迎來了三網融合的時代,為傳統廣播電視媒介帶來了發展機遇。節目數據的劇增一方面豐富了電視節目的內容,另一方面卻為用戶選擇帶來了困難,這就要求電視運營商建立合理的個性化推薦模型。該文采用基于物品的協同過濾的個性化推薦算法,通過分析用戶觀看收視信息數據、電視產品信息數據,同時考慮到目前傳統的互聯網資源推薦系統大都是針對個體推薦,在對家庭不同成員的推薦時可能會出現適得其反的情況,綜合考慮整個家庭成員的點播集合,構成了家庭用戶完整的歷史觀看記錄,分析每個家庭成員的偏好,建立電視產品營銷推薦模型,做出節目的個性化推薦。同時對不同節目的標簽進行組成分析,以數據圖的形式更加直觀地展示在結果中,用以了解不同時期標簽的熱度與關注度,從而進一步得出影視作品的熱度,對不同時期的推薦偏好做出指導性建議。
關鍵詞:基于物品的協同過濾? 個性化推薦? 節目標簽? 數據處理
中圖分類號:TP31 ? ?文獻標識碼:A 文章編號:1672-3791(2019)11(b)-0214-03
Abstract: The rapid development and application of Internet technology has ushered in the era of triple play, which has brought opportunities for the development of traditional broadcast and television media. The dramatic increase of program data has on the one hand enriched the content of television programs and on the other hand brought difficulties to user selection. This requires television operators to establish a reasonable personalized recommendation model. This article adopts a personalized recommendation algorithm based on item-based collaborative filtering, and analyzes users' viewing information data and TV product information data, taking into account that the current traditional Internet resource recommendation systems are mostly for individual recommendations, and are recommended for different family members. There may be counterproductive situations in which the on-demand collection of the entire family member is taken into account, constitutes a complete historical viewing record of the family user, analyzes the preferences of each family member, establishes a television product marketing recommendation model, and makes a personalized recommendation of the program.At the same time, the composition of the labels of different programs is analyzed and displayed in the results in the form of data graphs more intuitively to understand the heat and attention of the labels in different periods, thereby further obtaining the popularity of film and television works and recommending preferences for different periods. Make guidelines.
Key Words: Collaborative filtering based on items; Personalized recommendation; Program labels; Data processing
協同過濾推薦系統[1]是個性化信息服務的重要組成部分,可以實現主動精準地為用戶推薦感興趣的信息。隨著互聯網上信息的增長和用戶個性化需求的提高,推薦系統的應用日益廣泛,成為電子商務、社會網絡、視頻和音樂點播等個性化服務的核心技術。
基于此,該文圍繞電視產品的營銷推薦系統及其若干關鍵模型與推薦算法實現了基于項目協同過濾的電視產品營銷推薦的工作,并且經過一些對比分析實驗,證明了基于項目協同過濾算法在推薦系統上具有一定優勢,并總結歸納了該文的優缺點,提出了改進方向。
1? 相關工作——數據預處理
1.1 用戶及節目特征
將所給數據進行處理和分析,分析其中用戶特征即觀看時長、資源熱度以及資源關注度;分析其中節目特征即節目地區、節目語種、節目類型。
1.2 正則表達式
原本數據中存在如:“【】”,“(高清)”,“(10)”等附加信息,對于直接獲取到節目原本的名字造成了一定程度的干擾,該文利用Python中的正則表達式來去除存在于原節目名稱中的干擾字符串。如寄生獸(高清)經過正則表達式除去干擾后為寄生獸。
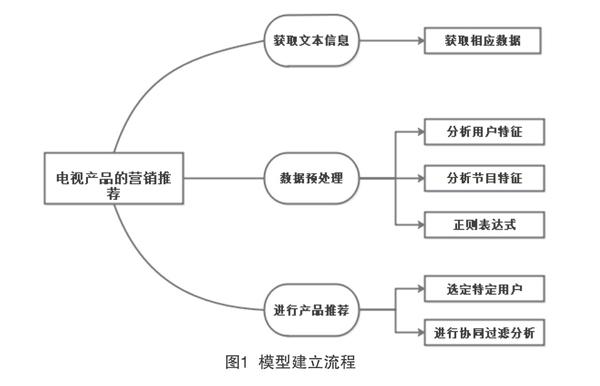
2? 模型建立
模型建立流程如圖1所示。
2.1 基于項目的協同過濾算法
基于項目的協同過濾通過分析項目之間的相似性進行推薦,算法假設:對于一些資源,如果很多的用戶對它的打分比較類似,那么當前用戶對它的打分也會比較類似。算法將尋找與當前資源評分最相似的資源作為此資源的最近鄰居,通過當前用戶對當前資源最近鄰居的評分來預測他對此資源的評分。
這里只以皮爾森相關系數為例。
設Uab為對資源a和b都評價過的用戶的集合,那么相關相似性的皮爾森系數可表示為:
(1)
上式中,ru,a、ru,b代表用戶u對資源a和b的打分,和表示是大量用戶對資源a和b的打分的均值[2]。
接下來對用戶評分進行預測:
(2)
2.2 協同過濾推薦
將經過上述清洗的數據用作模型的原始數據,按照觀看的時間順序將每個用戶的觀看數據平均分為2份,其中較早的數據作為模型的訓練數據,較晚的數據作為模型的驗證數據[3],用來計算推薦結果的準確率及召回率。
首先剔除數據的異常值,剔除異常值的數據按照時間順序排序,然后將排序后的數據讀入到列表中,對每一個用戶編號的觀看數據進行均分處理。然后獲取訓練數據,導入到模型中進行訓練,輸出推薦的節目及推薦指數(見圖2)。
3? 實驗及結果分析
3.1 實驗數據與評估指標
3.1.1 實驗數據
此次實驗所采用的是“泰迪杯”數據挖掘挑戰賽平臺的數據,共計445278條數據,其中包括了用戶收視信息、電視產品信息數據和用戶基本信息3個方面。
3.1.2 評估指標
精確率(precision)的公式是,它計算的是所有“正確被檢索的item(TP)”占所有“實際被檢索到的(TP+FP)”的比例。
召回率(recall)的公式是,它計算的是所有“正確被檢索的item(TP)”占所有“應該檢索到的item(TP+FN)”的比例。
3.2 實驗結果
采用基于項目的協同過濾算法,根據上述分成的前期訓練數據以及后期的評判數據,此用戶的推薦準確率為20.000%,召回率為16.000%。
4? 結論與展望
該文通過對用戶觀看收視信息數據、電視產品信息數據等進行基于項目協同過濾的算法處理,實現了單個家庭的個性化節目推薦,同時考慮了單個家庭不同用戶偏好不同的情況,實現了推薦結果的標簽豐富性,同時綜合標簽的數據圖結果,在推薦結果中考慮了熱度偏好,較好地實現了個性化推薦。
在實際調查后,我們還發現目前存在著用戶不愿過多對接收的資源評分、打標簽等致使資源提供者需要花費更多的精力分析用戶對資源的使用情況、用戶性別年齡、地區等基本屬性缺失,且難以從觀看節目準確判斷等問題。因此,在系統的用戶交互上應采取觀看后星級打分手段,有償積分長評短評等策略,進一步完成標簽補全,同時在用戶進行賬號注冊時可完成對性別年齡這些基本特征的補全。在分析過程中應意識到電視賬號不具有手機號碼的普及性,一個家庭可以共用一個電視賬號,因此賬號注冊只能獲取家庭成員之一的基本特征,故不應僅局限于此基本特征推薦,而應從此基本特征出發,適時適量地對其家庭成員進行刻畫與內容推薦,并根據反饋機制調整推薦系統。
參考文獻
[1] 肖潔.面向網絡電視的推薦系統框架及算法研究[D].華東師范大學,2012.
[2] 喻玲.面向家庭用戶的互聯網電視資源推薦模型研究[D].華中師范大學,2015.
[3] 沈建軍.面向互動電視的影視節目推薦系統研究與實現[D].復旦大學,2012.
猜你喜歡
中學生數理化·自主招生(2022年9期)2022-05-30 10:48:04
心理學報(2022年4期)2022-04-12 07:38:02
水泵技術(2021年3期)2021-08-14 02:09:20
電子測試(2018年4期)2018-05-09 07:28:12
當代化工研究(2016年9期)2016-03-20 16:22:13
中國慣性技術學報(2015年1期)2015-12-19 13:12:17
計算機工程(2015年4期)2015-07-05 08:28:04
西華師范大學學報(自然科學版)(2015年3期)2015-02-27 15:31:22
聯合國青年技術培訓(2014年7期)2014-04-12 00:00:00
中國質量與標準導報(2014年7期)2014-02-28 22:24:35
