融合多尺度信息的弱監督語義分割及優化
2019-02-25 01:27:26熊昌鎮智慧
通信學報 2019年1期
熊昌鎮,智慧
(北方工業大學城市道路交通智能控制技術北京市重點實驗室,北京 100144)
1 引言
語義分割是目前比較流行的一種視覺識別任務,其主要目的是給圖像中的每一個像素進行語義類別的劃分,在生物醫療圖像的分析[1-2],自動駕駛[3]、圖像搜索引擎[4]、人機交互[5-6]等各個領域都有著廣泛的應用。最近幾年基于深度卷積神經網絡(DCNN,deep convolution neural network)[7]法的語義分割任務在性能上有了較大提升,并且達到了在基準測試數據集上的最高水平。然而DCNN的學習過程需要大量的像素級標注訓練數據,制作此類像素級標注的過程比較耗時費力,導致現有數據集上的分割標注在質量和多樣性上仍然無法滿足需求。為了克服收集訓練數據標注的困難并設計一個更具有擴展性和通用性的語義分割模型,研究者們致力于弱監督學習的研究,通過更易獲得的較像素級標注更弱的監督信息來實現語義分割,如基于類標[8-11]及類標加輔助信息[12-14]、像素點[15]、邊界框[16-17]、涂鴉等[18]四大類弱標注的語義分割算法。其中類標是最容易獲取的標注,Pathak等[8]將語義分割看作是多實例學習的問題,利用最大池化操作強行限制每張圖像至少有一個像素屬于正實例目標類,但是因為監督信息缺失了目標的位置和形狀,導致分割結果不太平滑。隨后Pathak等[9]提出了嵌入位置信息,利用可辨識性定位自動識別出每個語義類的大體區域位置來提高分類的精度。Kwak等[10]利用超像素池化層生成初始語義分割需要的邊緣形狀信息。雖然這些方法可以粗略地定位目標,但是通常不能精確地推斷出像素信息,因為更傾向于聚焦目標的部分顯著信息,而不是目標的整個區域。Kolesnikov等[11]則提出將種子損失、擴張損失和約束邊界損失集成到一個網絡訓練分割模型進行訓練,并應用全局加權排序池化操作,約束目標邊界信息并聚焦目標顯著位置,但該算法對于背景相似的目標區域在定位上容易產生偏差,而且類別識別的效果不是太好。為進一步提升分割性能,研究者們開始以類標注為基礎擴增新的數據信息,Lin等[12]提出利用自然語言作為弱監督標注,Hong等[13]利用額外數據(非目標數據源)的像素標注輔助弱監督信息學習,但是需與實際目標數據的類別相互獨立,再依靠遷移學習捕獲目標類需要的像素信息。Hong等[14]以網頁視頻作為額外數據源,利用目標和背景的不同動態信息與三維結構信息區分出前景與周圍的背景信息,獲取更準確的目標邊界,使分割性能有了較大的提升,但整個網絡結構對小目標信息的捕獲比較欠缺。第二類以像素點為弱標注信息可提供目標粗略位置的方式,有助于提升分割效果。Bearman等[15]提出將分類損失和定位損失相結合,并增加了目標顯著性作為先驗知識來優化,但從其結果來看分割邊緣不完整。第三類以邊界框為弱標注信息可提供整個目標區域位置的信息,可進一步提升目標的分割效果。Papandreou等[16]利用最大期望(EM,expectationmaximization)來動態預測邊界框內的前景像素。Dai[17]沒有對邊界框內的像素進行直接評估,而是利用現成的候選區域(region proposals)迭代選取最佳區域,進而生成分割掩碼,分割性能與類標監督相比有了很大提升,但是相較全監督語義分割性能還有較大差距。第四類以涂鴉為標注信息即是在興趣目標上簡單勾畫一條線,它提供目標相對位置范圍內的一些稀疏像素信息。Lin等[18]利用圖模型優化交互式分割模型,即在訓練過程中循環利用當前的分割結果作為監督信息進行迭代直至模型收斂,性能相當于邊界框給出的分割結果。遺憾的是該標注在其他數據集上不可用。
以上各類弱監督語義分割算法在復雜背景及包含眾多小目標的場景下,對狹小目標及目標的形狀邊緣分割往往不理想,主要原因還是對目標尺度空間的信息學習不全面,然而目前在強監督語義分割任務中已有多種學習尺度空間特征的算法[19-21]。Chen等[19]將金字塔式輸入圖像送入到DCNN以提取不同尺度上的顯著度特征。Yu等[20]在原有網絡頂部級聯空洞卷積層來捕獲圖像不同尺度信息。Zhao等[21]利用空間金字塔式池化作用于最后一層卷積,進而獲取多種尺度分辨率的目標特征。這些多尺度算法在強監督語義分割中均可以獲得良好效果,證實了學習尺度空間信息的有效性。鑒于此,本文以遷移學習網絡[12]為基本框架,以金字塔式多尺度圖像為網絡的輸入,并增加一個新層對多尺度特征進行降維,構建多尺度的弱監督語義分割模型,提取目標的多尺度特征。語義分割通常包含圖像類別預測和像素分割兩部分內容,類別預測效果對最終分割結果起著至關重要的作用,因為錯誤的目標類別必然會導致像素分割的錯誤[11,13,16]。隨著深度學習技術的發展,以邊界框為監督信息的目標檢測技術也得到了很大的發展,檢測精度和速度都有很大提升[22-23]。為避免類別錯誤導致的分割失敗,引入文獻[23]中在同源數據集學習的檢測模型給出的圖像類別信息來提升分割的精度。現有算法中單模型分割算法對某些目標的分割效果好,但對另一些目標的分割效果差,無法學到所用類別的有效信息,導致無法對所有目標類都進行有效分割,會導致模型泛化能力差,不同分割模型的側重點不同,學習到的語義特征也不同,即每個模型都有各自的優勢[9-10],為充分利用不同模型的優勢,本文對多尺度分割模型進行優化,與原遷移學習模型進行集成,同時結合類別可信度和像素分割可信度進一步提升圖像分割的精度。
2 多尺度圖像分割
將應用于強監督語義分割算法的多尺度信息引入弱監督分割算法中,以遷移學習模型為基礎,輸入多個尺度的圖像,提取多個尺度上的圖像特征后歸一化成相同大小的特征圖再拼合在一起構造多尺度特征,然后對多尺度特征進行降維,利用遷移學習模型的注意力機制模型初始化新構造的多尺度模型,最后對多尺度分割模型進行訓練,學習多尺度特征的信息。該模型的基本框架如圖1所示,主要包括提取多尺度特征的編碼結構fenc、多尺度特征圖級聯與降維,聚焦目標顯著區域的注意力機制fatt和低維特征解碼至高維特征進行前景分割的解碼結構fdec。
2.1 學習圖像的多尺度信息
采用與遷移學習模型相同的編碼結構、注意力機制和解碼結構[13],用x表示來自源數據集S或目標數據集T的輸入圖像。首先將輸入圖像縮放成分辨率為330×330固定大小的圖像塊,經過隨機裁剪變成分辨率為 320×320的圖像,利用尺度因子s∈ {1,0.75,0.5}將裁剪后的圖像塊縮放成3種不同尺度,作為3組并行編碼器fenc的輸入,如式(1)所示。

其中,eθ為3組編碼器fenc的共享卷積層訓練參數,為編碼器最后一層卷積層輸出特征圖,w、h和d分別代表特征圖的寬、高和輸出維度。再將尺度因子為0.75和0.5對應的特征圖As按照雙線性插值進行放大,即保持與編碼器中輸入尺度因子為1的最后一層卷積層輸出特征圖相同大小,然后再將縮放后的特征圖沿維度方向進行級聯,同時在編碼器的末端增加一個新的卷積層,對融合的多尺度特征圖進行降維以生成固定的通道數,進而適應后續注意力機制的輸入要求,通過網絡訓練學習圖像的多尺度特征。
2.2 聚焦目標的顯著區域
當給出融合后特征圖A和對應目標類向量形式 ??時,注意力機制的作用就是學A中的對應目標類位置的正權重向量表示第l個目標類與對應特征位置的相關性。注意力機制的過程可表示為
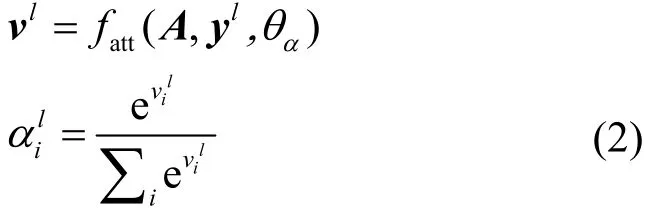
其中,αθ為注意力機制fatt的模型參數;表示第l類的類標向量,在訓練過程表示來自源數據與目標數據的真值類,在模型執行推斷時則表示分類器給出的目標預測類,即圖1的類別處。lv為非正則化的聚焦權重,通過softmax函數給出正則化后的權重lα,目的是鼓勵模型只聚焦圖像目標類的一個顯著區域[24]。遷移學習算法中所用的注意力機制fatt為
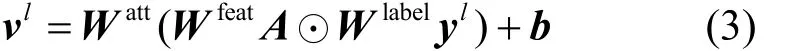

訓練注意力機制fatt的過程即是最小化分類損失的過程,用ec表示softmax函數,用于計算真值和預測類標的損失。
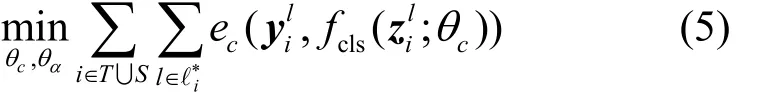
其中,θc為分類層的學習參數,表示來自源數據與目標數據第i張圖的類l顯著響應圖。
2.3 生成前景分割圖
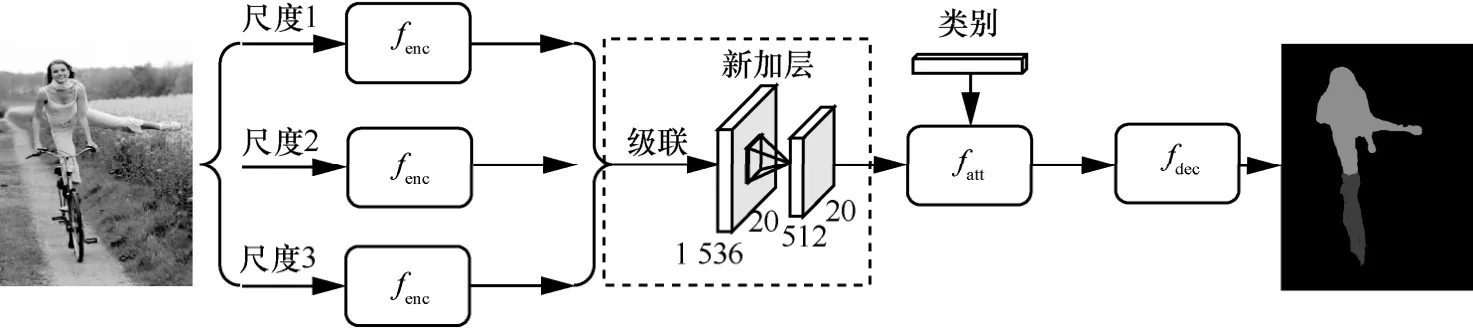
圖1 多尺度特征分割模型
當注意力機制給出興趣目標類的位置時,接下來便需要解碼器來重構相應聚焦目標的前景分割圖。由于經過softmax之后聚焦權重會變得比較稀疏,為此需要將式(4)獲得的特定目標類顯著圖lz作為解碼器輸入的系數,以獲取密集顯著圖,且與注意力機制聚焦的顯著圖lα具有相同大小,即表示為

訓練解碼器的過程為最小化分割損失,對應的目標函數es為softmax損失函數可表示為
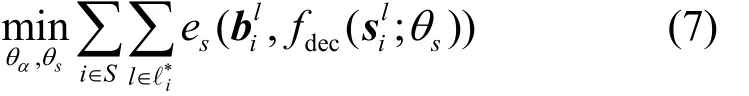
其中,θs表示解碼器fdec的學習參數,為源數據集 S的l類中的第i類目標的二值分割圖,i∈S表示目標函數的優化只對源數據集進行。但是學得的參數sθ對不同目標類是實現共享的,所以該結構能夠利用已學得的通用類的基本特征,如顏色、形狀、紋理等先驗知識遷移應用到其他多類場景。解碼器fdec的基本結構與編碼器fenc呈對稱形式,通過一系列的上采樣、轉置卷積及校正運算將低分辨的目標類特征圖重構為與輸入x相同大小的密集前景分割圖。
多尺度特征模型訓練對新增加的層及解碼器部分均使用零均值高斯分布初始化,學習過程中固定編碼器的權重,利用原遷移學習模型的對應層對編碼器、注意力機制進行初始化,并應用自適應矩估計算法(Adam,adaptive moment estimation),根據式(5)分類目標函數學習新層與注意力機制的參數,以及式(7)分割目標函數來學習解碼器部分的參數。
3 算法優化
將文獻[23]中同源數據集學習的檢測模型給出的圖像分類結果作為多尺度分割模型預測時的新分類器,只使用檢測模型給出的預測目標類及類別可信度;然后對類別優化后的多尺度模型與原遷移學習模型進行加權集成;最后利用新分類器的類別可信度優化集成模型輸出分割圖的像素可信度,以進一步提升分割的精度。
3.1 類別預測優化
語義分割任務實際包含圖像類別預測和像素分割這2類任務模型所用分類器的預測效果對最終像素級分割結果起著至關重要的作用,因為錯誤的目標類必然會導致像素分割的錯誤,而模型結構中添加的分類層fcls,只是為了學習目標數據集類別上的注意力機制,訓練過程結束后,需要引入一個單獨的分類器完成模型的預測。原遷移學習的分類器是基于 VGG16的全卷積神經網絡的類別預測,預測準確率不夠,影響分割效果,鑒于學習數據集(MS COCO(microsoft common objects in context)[25],VOC 2012(visual object classes challenge)[26])的考慮,選用在同源數據集上學習的檢測模型作為目標分割時的類別分類器,基于弱監督學習模式的衡量,不輸出檢測框位置信息,只將檢測結果的圖像目標類別l及類別可信度lP的信息保存下來,并于圖1所示的類別處給入到多尺度特征分割模型中,隨后模型自適應構建注意力權重即相應目標類的顯著區域。
3.2 模型集成優化
當假設空間較大時,單模型分割算法往往不能保證對所有目標類的有效性,導致模型泛化性能差。此時如果有多個假設在相同數據集上訓練并能達到同等性能,便可以將多個學習器進行結合,利用個體學習器間的差異性互補來有效規避單一模型的性能缺陷[27]。因此,將性能相近且同屬“神經網絡式”的多尺度特征模型與原遷移學習模型進行集成,并按照加權的方式進行模型融合,如式(8)所示。
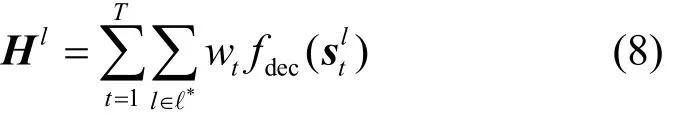
3.3 分割可信度優化
鑒于注意力機制只是給出興趣目標的粗略位置,對目標遮擋、復雜背景、噪聲混入等情況,模型輸出的分割圖包含所有預測目標類的像素信息,但是其中某些類的位置信息會有偏差,致使分割錯誤。研究發現引起錯誤的類通常在分類器預測的可信度與視覺顯著度上呈負相關。利用新分類器給出的預測類別可信度lP,調整相應類的概率圖響應像素值,即用低目標類概率值抑制錯誤響應的高像素值,用高預測類概率值提升輸出的低響應像素值,達到規避假正例區域及非預測目標的噪聲信息,同時強化正確類標的分割圖像的目的。預測類可信度優化分割概率圖如式(9)所示。

4 實驗結果與分析
多尺度分割模型使用MS COCO為源數據集S,VOC 2012為目標數據集T,其中源數據集S共含60類目標,與目標數據集T的20類目標相互獨立;目標數據集T僅提供類別監督信息。最后在VOC2012驗證集、測試集進行語義分割實驗,采用平均交并比(mIoU,mean intersection-over- Union)來衡量實際分割結果與分割真值(GT,groud truth)的差異。實驗中使用文獻[23]中的 PVANet模型進行目標檢測,將大于給定閾值的邊界框類標和最大概率作為分割圖像的類別及可信度,只使用類別信息,不使用邊界框的信息。實驗中所用的類別閾值為0.75,將檢測的類別結果和可信度保存下來,在圖像分割時只加載類別信息,不進行實際目標檢測操作。
4.1 多尺度分割模型和自身優化算法的對比實驗
將原遷移學習模型記為O,多尺度特征模型記為M。表1給出了多尺度特征模型、集成模型、預測目標類及其可信度優化在VOC 2012的驗證集上的性能對比。多尺度特征模型與原遷移學習模型集成時的個體學習器給定權重按w1:w2= 3:2的比例加權,后綴 c 表示引入新分類器后的結果,p是分類器給出的預測目標類可信度。從表中的數據可以看出,構建的多尺度特征模型M與原遷移學習模型O具有相似的分割性能,滿足同質型差異化模型集成的具有一定“準確性”要求。引入類別預測優化的圖像分割算法(M_c)同比多尺度特征模型利用的原遷移學習模型固有分類器在性能上提升了2.9%。經過雙模型的集成優化后M+O_c分割算法性能又提升了2.9%,證明單一學習器具有不可避免的性能缺陷,利用集成學習可以使同質型差異化模型實現互補,從而提升分割的效果。由于模型結構中的注意力機制只能給出目標的粗略位置,在出現目標遮擋、復雜背景、噪聲混入等情形時,分割往往容易出現錯誤,因此使用圖像類的預測可信度p對算法進行優化,同比集成模型提升了0.9%,驗證了本文算法的多尺度分割及不同優化策略引入都不同程度地提升了分割算法的精度。

表1 本文算法在VOC 2012的驗證集上的性能對比
表1數據中M+O_gt表示的是集成模型引入真值類標的分割性能,但比集成模型結合類及可信度優化算法M+O_c_p要低0.7%,說明分類真值并不能作為算法的上限。這是因為類別真值只是表示該圖像有這類目標,可信度為 100%,但不考慮目標的大小、位置等信息,同時圖像中又包含與此類目標相類似的其他信息,導致圖像分割結果中該類別的像素分割的可信度高,造成圖像分割錯誤,而目標的大小、形狀和位置信息對圖像分類都會造成影響。分類的可信度表示類別分類的難度,與分割可信度相結合可避免類別可信度低而分割可信度高造成的假正例現象。
圖2給出了基于不同形式的目標類分割效果對比圖,即直接引入真值圖像類別信息和預測的目標類別信息進行分割的結果。圖 2(a)是輸入圖像,圖 2(b)是真值分割圖,圖 2(c)是引入的真值目標類別分割圖,圖2(d)是引入預測目標類別及可信度優化的分割結果。對應上述實驗的M+O_c_p的結果,可以看出預測類別及可信度優化的分割效果明顯優于直接給定真值類的分割圖。其原因是復雜背景及包含有眾多小目標的情況下,注意力機制聚焦的興趣目標位置是稀疏的,當引入包含最完整信息的真值類時,在預測過程根據分割響應圖的像素值大小確定的最終分割圖時,往往會出現類正確但是位置錯誤的情況,弱化了分割精度。通過引入分類器預測目標類時輸出的類可信度,不僅可以強化正確目標類相應的像素響應值,還可以抑制錯誤定位的類響應值,進而改善分割的性能。

圖2 不同目標類別下的分割效果
4.2 與其他算法對比實驗
圖3顯示了部分測試圖像在驗證集上的語義分割結果圖。第一列是輸入圖像,第二列是原遷移學習模型O(TransferNet[13])的分割結果,對比本文第三列的多尺度特征提取模型M,可以看出模型M能夠給出尺度空間上更豐富的信息,但是因為原分類器的準確度不是太高,導致部分目標信息的丟失,而且由于注意力機制的粗定位,部分目標給出的顯著區域不合理,造成了單一的多尺度特征分割并不理想。第四列M_c是在模型M的基礎上更換新分類器 c,可以看出減少了目標信息的丟失,進而避免了因類預測失敗造成分割不理想的情況。第五列是引入新分類器的同質型集成模型分割效果圖,明顯可以看出通過模型間的互補性,目標的分割更準確,彌補了丟失的信息,去除了多余的噪聲信息。第六列是引入預測目標類可信度p優化后分割效果,發現正確目標類的有效分割區域更加完整了,同時有效地抑制了假正例區域,使得最終的模型分割信息更全面,邊緣輪廓更細致。
同時為了更加充分的驗證算法的性能,與目前采用各類弱監督信息(類標及類標加輔助信息、像素點、邊界框、涂鴉)實現語義分割的主流算法進行對比,包括目前單純以類標作為弱監督信息的最好算法 AffinityNet[28],為了對比的公正性,只給出了基于網絡VGG-16結構的性能對比。表2列出了各類算法在VOC 2012驗證集和測試集上的分割性能對比結果。其中,I指應用類別作為監督信息,P指應用像素點作為監督信息,S是簡筆涂鴉式監督信息方式,B是指利用邊界框為監督信息,*表示加入了強監督信息。從表2中可以看出多尺度分割及優化算法在驗證集上的結果比AffinityNet算法高0.4%,比基于相同遷移學習模型改進的CrawlSeg[14]算法提高了0.7%。AffinityNet算法提出利用親和網絡預測相鄰像素間的語義相似性,進而將局部響應擴散到同一語義實體的附近區域,最后通過預測的像素相似性隨機游走實現語義傳播,對目標的響應區域位置及類別預測效果都比較好,但是它的實際分割對目標的輪廓及細節信息處理不是太完整。多尺度分割及優化算法在測試集上的結果有些不盡如人意,但是比 TransferNet[13]提升了 6.3%。結果說明多尺度分割模型有效地提取了多尺度的空間信息,并與同質型原遷移學習模型進行集成,提高了泛化性能,對捕獲細節輪廓信息更有效; 同時利用預測目標類及其可信度優化注意力機制的定位,獲得了更好的分割效果。

圖3 VOC 2012 驗證集分割效果對比
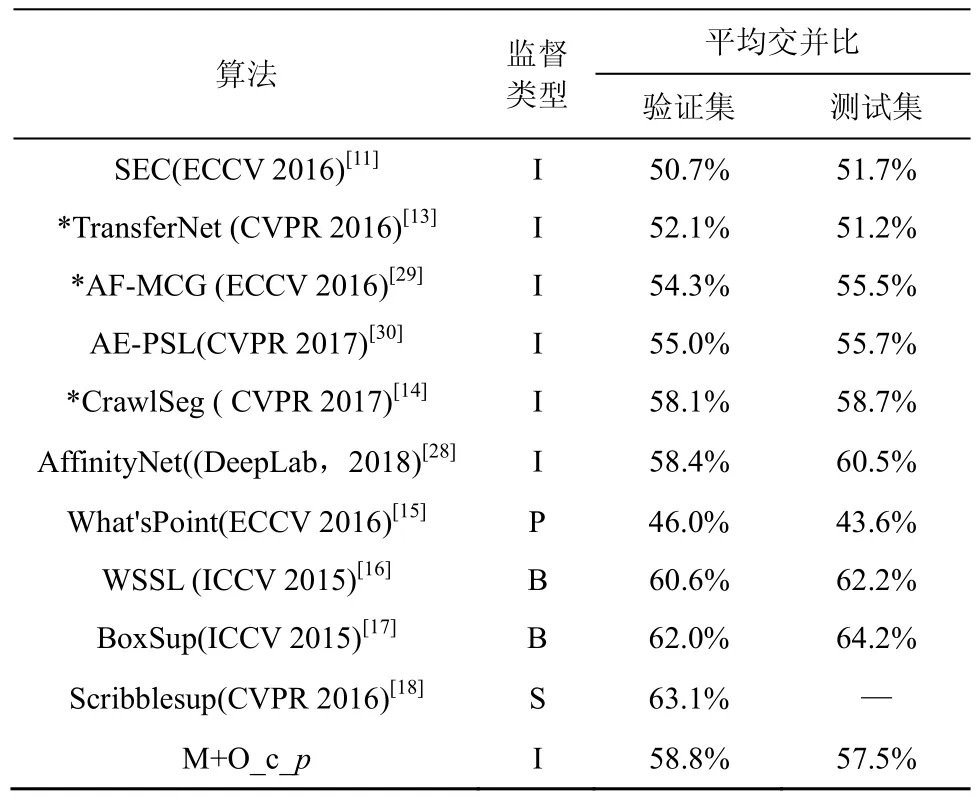
表2 VOC2012驗證集/測試集性能對比
圖4給出的是一些失敗案例,圖4(a)與圖4(d)是相應案例的原圖,圖 4(b)與圖 4(e)是對應原圖的真值分割圖,圖 4(c)與圖 4(f)是模型預測分割圖。作為弱監督的語義分割算法,因為監督信息缺失目標數據集圖像的位置和形狀關鍵信息,往往會在復雜背景或者眾多小目標的情況下出現錯誤。失敗案例表明,因為注意力機制對興趣目標的定位是粗糙的,難免會引入噪聲信息,縱使對目標的顯著性響應進行優化也不能完全解決,從而影響分割的準確性。后期可以考慮增加一些對目標顯著性精確定位的措施,強化興趣目標的整體響應區域。
5 結束語

圖4 一些分割失敗的例子
考慮到原遷移學習的單模型在復雜背景或目標類別比較多的情況下,往往對小目標形狀邊緣分割不理想,同時也因分類器的目標識別不準確導致分割對象出現錯誤,以及基于注意力機制的粗定位,簡單使用顯著性響應容易引入噪聲信息等問題,構建了可提取多尺度特征信息的圖像分割模型,提取圖像的多尺度信息,并引入3種優化策略對分割算法優化以提升分割精度。優化策略首先將同質型差異化的多尺度特征模型與原遷移模型進行模型集成,以彌補單模型的性能缺陷;然后引入新的圖像分類器改善預測目標類別的準確度提高圖像分割的性能;最后結合預測類可信度優化分割響應圖的像素可信度,避免類別可信度低而圖像分割可信高造成圖像分割錯誤。在目標數據集VOC2012測試算法,實驗給出了單尺度特征模型、雙模型集成、新類別分類器及類可信度優化的實驗結果,并與其他前沿算法進行了對比。結果表明,多尺度特征模型及優化算法,在VOC 2012驗證集上的平均交并比達58.8%,測試集上的平均交并比為57.5%,比原遷移學習算法提升12.9%和12.3%,在驗證集比目前以類標作為監督信息的最好語義分割 AffinityNet算法提升 0.7%,驗證了本文算法的有效性。由于使用的基礎網絡性能不夠及注意力機制的缺陷影響了分割效果的進一步提升,后續將考慮改善網絡結構和引入目標顯著性改善注意力機制來提高分割的效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中外會展(2014年4期)2014-11-27 07:46:46
外語學刊(2011年1期)2011-01-22 03:38:33
