東張水庫藍藻水華BP人工神經網絡模型演算研究
2019-03-04 06:05:22張明峰蘇玉萍陳楊鋒李赫龍陳宇昕
漁業研究 2019年1期
覃 苗,張明峰,洪 頤,蘇玉萍,4*,陳楊鋒,李赫龍,陳宇昕
(1.福建師范大學環境科學與工程學院,福建 福州 350007; 2.福建師范大學地理科學學院,福建 福州 350007; 3.法國巴黎高科路橋大學城市與水環境實驗室,法國 巴黎 77455; 4.福建師范大學,福建省污染控制與資源循環重點實驗室,福建 福州 350007)
社會的進步以及工、農業的迅速發展,給湖泊水庫的水質帶來了污染。在陸地上貧瘠的氮、磷等元素,在水中卻過多的存在,從而引起了一種有害的自然現象——水華暴發。水華暴發是一種由于水體富營養化等多種原因綜合影響而引發的自然現象,當氣候和水質有利于藻類生長和聚集時,藻類呈現暴發性繁殖和聚集,通常伴有水面變色[1]。水中存在的過多的氮、磷等營養物質是水華產生的主要原因,而諸如pH、氣候等條件也會對其暴發造成一定的影響[2-3]。本文的研究對象——福清市東張水庫為飲用水地表水源保護區,于2007—2017年的10年間在大壩區域多次暴發藍藻水華[4-7]。因此,通過一定的監測預警模型,預見性地提醒相關部門及時采取相應的防控措施,對有效防治水華的暴發就顯得尤為重要。
近年來,隨著人工智能的迅速發展,基于數理統計和人工神經網絡的預警模型系統在水華預警預報研究中得到了一定的應用。研究人員以BP模型作為手段,建立了各種水華預警模型,Maier等通過人工神經網絡建立了預測模型,預測了澳大利亞River Murray流域藍藻水華的暴發[8];Lee等則以ANN預測了香港沿海流域藻類水華的發生[9];仝玉華運用RBF/BP網絡藻類水華預測模型,分析運算了其研究流域中的水華分布時空規律,針對性建立了多元線性回歸預測模型[10]。
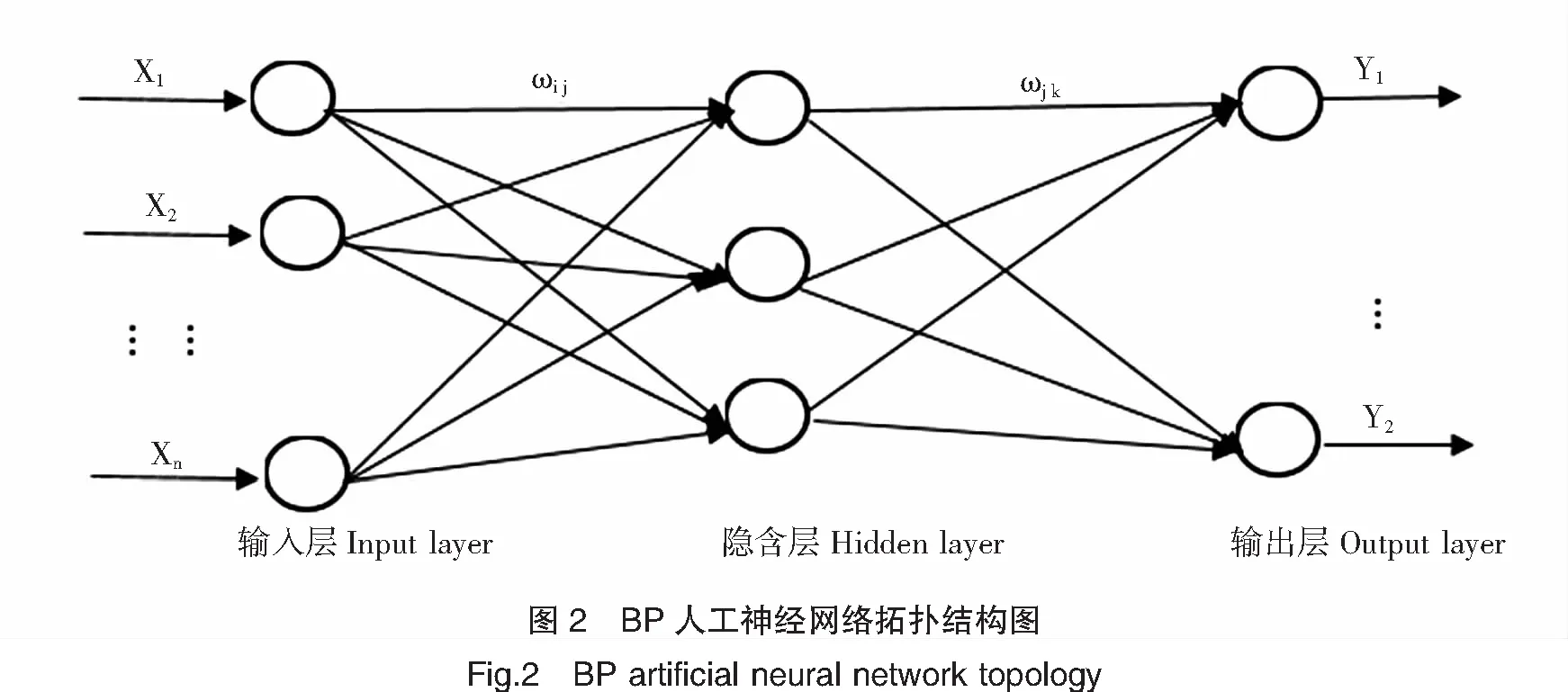
在建立水體富營養化和因其所致的水華暴發預警模型時,BP人工神經網絡作為一個十分合適的工具,具有許多獨有的優點,例如方法簡單、無需建立復雜的數學計算模型、具有很強的適應性和容錯性、具有較強的處理非線性問題的能力等。BP人工神經智能網絡作為一種以數據作為驅動的模型,其最大的特點是具有自學習、記憶聯想和判別功能。而這種學習、判別功能需要大量的環境參數和水質檢測數據。因此收集足夠數量的樣本數據成為BP人工神經網絡模型解決水華預測成敗的關鍵。本文通過長期對東張水庫的監測所獲取大量的數據,運用人工神經網絡模型進行運算,探討了預測藍藻水華暴發的可能性,旨在為藍藻水華暴發的預警提供新的方法,為相關部門在藍藻水華的防控提供參考。
1 材料與方法
1.1 數據來源
本研究數據來自福清市東張水庫(圖1,119°29′20″E、25°46′6″N)自動監測站2016—2017年水體大壩斷面數據,共295組有效數據,包括水溫、溶解氧、電導率等在線水質檢測數據(表1)。且該數據樣本包含大壩斷面水華期間的數據。
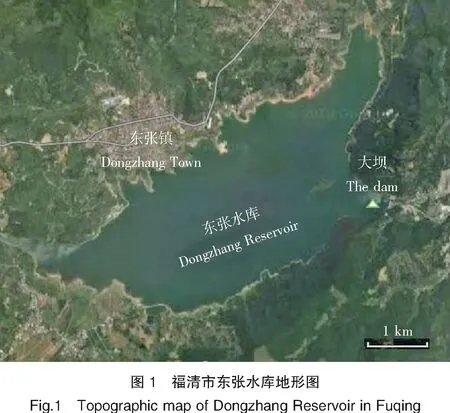

表1 主要的檢測參數和單位
1.2 BP建模方法
為建立BP人工神經網絡模型,將水質參數做交叉對比,選出輸出結果較好的水質輸入指標,綜合比對福清市的氣象數據(氣溫、風速),將水質參數與氣象數據組合作為自變量輸入模型,以葉綠素a濃度為因變量,通過BP人工神經網絡模型來探究水質與水華暴發之間的相關性,并選出輸出結果較好的輸入參數組合應用于后期水庫藍藻水華的預測。
在模型的構建過程中,采用的取樣方法是對295組樣本做隨機排序,抽取后80%的數據進行模型訓練,前20%作為測試數據進行檢驗。在模型訓練完成后,以測試數據檢測該模型的訓練結果,并輸出訓練擬合結果,且獲取訓練值與測試數據的誤差,獲得誤差比值,模型運行結束。
1.2.1 模型的建立和演繹過程
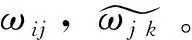
假設在模型中的任意一個節點輸入信號為xi,輸出信號為yi。
j=1,2,……,l;
hj=fvj,j=1,2,……,j;
因此,如果有n層,并且第n層指且僅指輸出層級,而第一層為輸入層級。則該模型的BP算法則由以下推演而出:
首先,初始化連接權重值ω1,同時初始化激活閾值(初始化偏置)a1、b1;接著,重復以下的過程直到輸出結果收斂:
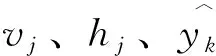
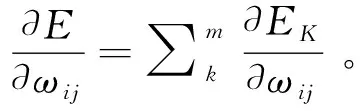
1.2.2 數據處理
采用SPSS 23.0軟件進行Spearman相關分析。利用 MATLAB R2016b 建立東張水庫藍藻水華BP 人工神經網絡模型。
2 結果與分析
2.1 Spearman相關性分析結果
對本次研究所用的295組數據進行了相關性分析。結果如表2所示。

表2 東張水庫各指標因子間的Spearman相關關系
注:*表示顯著相關(P<0.05,2-tailed),**表示極顯著相關(P<0.01,2-tailed)。
Notes:*indicates significant correlation(P<0.05,2-tailed),**indicates extremely significant correlation(P<0.01,2-tailed).
在淡水湖庫中,浮游植物的生長受多種環境因子的制約,而湖庫水中存在的葉綠素a則在一定程度上反映該流域內浮游植物的生長情況[11]。根據表2的相關性分析結果,可以知道,在東張水庫水體的水質檢測建模數據中,水溫、溶氧等在線監測指標數據與葉綠素a之間存在較好的相關性(P<0.05)。并且氣溫、風速等氣象指標對藻類的生長也存在著協同效應。因此葉綠素a數值會伴隨著各個相關數值的改變而變化。因此選取相關性結果較好的因子進行模型演算是合適的。
2.2 BP人工神經網絡樣本訓練與模型擬合結果
選取了可以在線監測、數值準確的水質指標,以不同的數據組合作為輸入參數,經大量的重復試驗運算,不同的數據組獲得的輸出結果如表3所示。從中篩選出最優的參數組合。從表3各參數組合指標輸出結果的誤差及擬合度的結果可以看出,以水溫和溶解氧(組合2)作為輸入參數,其輸出結果葉綠素a的預測值的均方根誤差(RMSE)為0.10 μg/L,均方根與實測值標準偏差比(RSR)為0.84,R2=0.34;而增加了電導率作為輸入參數(組合3),其輸出結果有了較大提升,均方根誤差(RMSE)為0.09 μg/L,均方根與實測值標準偏差比(RSR)為0.56,R2=0.74。但當再加入濁度作為輸入參數(組合4)時,輸出結果葉綠素a的預測值的均方根誤差(RMSE)為0.11 μg/L,均方根與實測值標準偏差比(RSR)為0.59,R2=0.68,誤差反而變大,擬合更低。因此選擇了指標數量較少且結果較好的水溫、溶解氧和電導率作為模型水質輸入參數(組合3)。由于在一般性認知中,認為藍藻水華的暴發與一定條件的氮、磷含量等水體理化性質、溫度和光照等氣象條件、水文條件和生態環境有關,是水體環境因素(如總氮、總磷、pH、溶解氧)和氣象因素(如氣溫、光照、風向、風速等)綜合作用的結果[12-13]。因此本研究將濁度、pH、氣溫和風速等因子逐步作為輸入參數加入模型,分別得出了組合4、5、6和7的數據結果。可以看出,模型的最優參數輸入組合為水溫、溶解氧、電導率、氣溫即組合6,該組合的輸出結果葉綠素a的預測值的均方根誤差(RMSE)為0.08 μg/L,均方根與實測值標準偏差比(RSR)為0.43,R2=0.83。
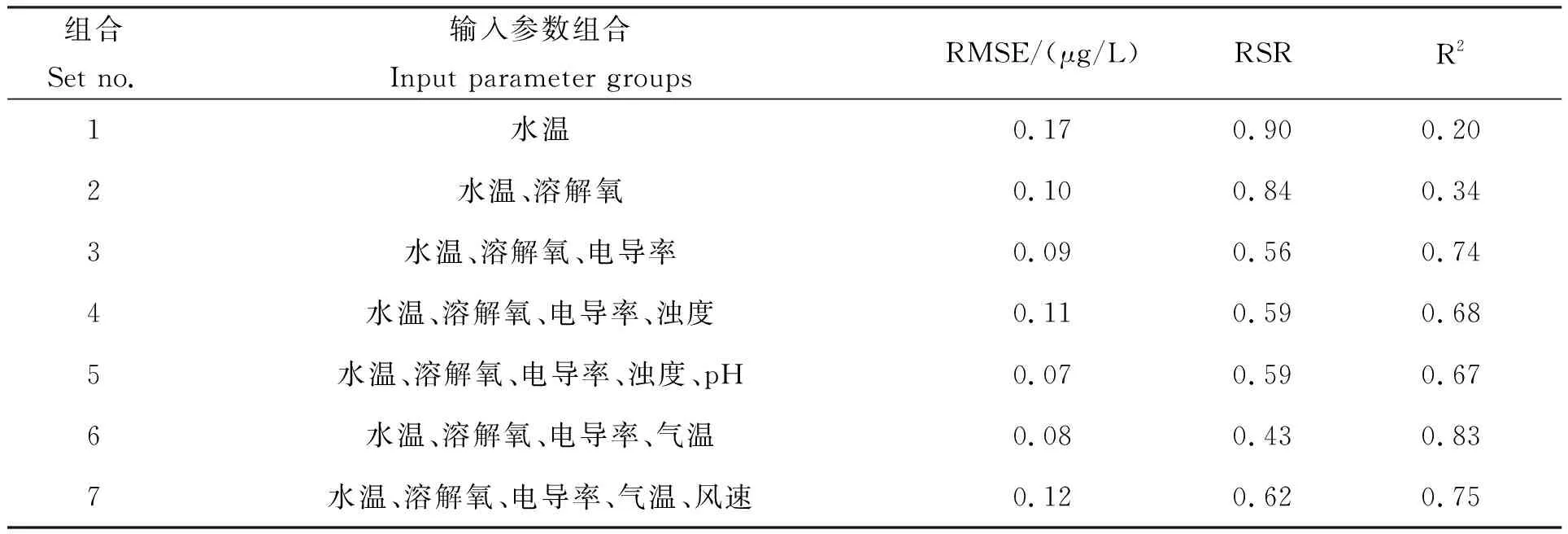
表3 各水質指標輸入參數組合的模型運算輸出結果的RMSE、RSR、R2
對各組合的結果中較有代表性的組合3、組合6和組合7做進一步分析,結果如圖3、圖4、圖5所示。

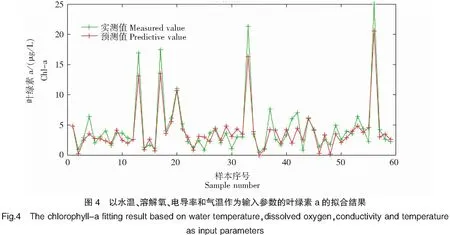

可以看出在三組葉綠素a的模擬結果中,預測值和實測值在數據的各個峰值與數據的趨向性上都具有一定的相似性。但組合6的擬合結果(圖4)是最好的,該組合的模擬結果不僅在各個峰值涵蓋了實際數據,并且在整體數據的相似度上與其他組合相比,數據更為接近。因此可以認為BP人工神經網絡模型在以東張水庫的水溫、溶解氧、電導率和氣溫這4個指標作為輸入參數時,模型的學習訓練結果可以提取有效的學習經驗,并做出具有針對性的預測。模型訓練的運行結果符合試驗訓練預期。
3 討論
從經過模型的模擬預算結果可以看出,輸入端因子經優化組合后輸出端的結果更好,并且結合氣象數據作為輸入因子后模型輸出結果的精度明顯高于僅以水質作為輸入因子的模型預測結果。但是所有組合的模型輸出結果均與傳統意義上較好的擬合度(R=0.999)存在著一定的差距,這可能是由于人工神經網絡模型的數據訓練量不足以及參數過多所致,并且許多參數并沒有絕對公認的最佳取值,僅僅只有相對最優值。在建模過程中,僅靠建模者的經驗和主觀判斷,在試驗的時候需要不斷地調整與試驗才能取得相對較為理想的結果。
從圖3、4、5可以看出,在三組模型輸出的數據結果中,有些點位呈現跳躍式增長,這是由于在2016—2017年水質檢測數據中,部分月份水華暴發,導致各個指標都呈現明顯的變化,尤其是總磷、總氮的數值增長更明顯,這種迅猛增長在其他月份是不存在的。由于本次模型的訓練樣本的有限性,對于模型的識別和預測造成了一定的局限。并且水華暴發時期一般為夏、秋季,庫區不同區域水深的水溫存在較大差異。此外,降雨等因素也對水體水質造成一定的影響。因此在后續的改進模型中,應著重對于輸入參數進行分類,將數據波動較大的數據與波動較為不明顯的數據分開,以增加模型預測的準確性。
不同氣象因子的輸入也對預測結果的擬合度有不同的影響,可能的原因是氣象數據不足,本次研究僅采用氣溫、風速這兩個參數,還缺風向、光照強度、日照時間、降雨量等對于水華有影響的氣象因子作為輸入數據供篩選。因此,在今后的模型改進中,應該盡量多地考慮其他氣象因子和環境影響因子,以減少模型運算誤差。
4 結論
本研究建立了一種可以應用于湖庫水華暴發的BP人工神經網絡預警模型。利用BP人工神經網絡理論,以福清市東張水庫為例,得到了以水溫、溶解氧、電導率和氣溫為輸入參數的指標組合,使得以葉綠素a為輸出指標的預測結果擬合度達到0.83,得到了較好的結果,符合試驗預期。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
環境(2023年5期)2023-06-30 01:20:01
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
當代水產(2019年1期)2019-05-16 02:42:04
當代水產(2019年3期)2019-05-14 05:42:48
電子制作(2018年14期)2018-08-21 01:38:16
光學精密工程(2016年6期)2016-11-07 09:07:19
水利規劃與設計(2016年7期)2016-02-28 15:06:27
核科學與工程(2015年4期)2015-09-26 11:59:03
