母語為韓語的漢語學習者加工“V+N1+的+N2”歧義結構的眼動研究
2019-03-12 07:45:34鹿士義逯芝璇匡柳興鄧彧君
心理與行為研究 2019年1期
趙 帥 鹿士義 陳 婧 逯芝璇 匡柳興 鄧彧君 付 宸
(1 北京大學對外漢語教育學院,北京 100871) (2 大連外國語大學法語系,大連 116044)
1 引言
第二語言認知加工研究領域的一個中心問題是,在加工L2句子時,L2學習者與母語者在多大程度上使用相似的認知加工機制。對這一問題的回答不僅有助于洞察二語者句子加工的機制,而且有助于從二語語言認知的角度揭示大腦功能的可塑性。Dussias(2003)指出,在L1研究領域,句法分析得到了較多關注,但從L2的角度對句法分析進行考察的研究并不多。Gregg(2001)認為,二語習得理論不僅包含具體的語言知識理論,還包含能夠闡釋L2學習者語言系統狀態發生改變這一認知過程的過渡態理論(transition theory)。
Steinhauer(2014)認為,在二語認知領域,L1加工和L2加工之間存在以下三種關系:差異假設(difference hypothesis)認為L2加工不同于L1加工,大腦可塑性在青春期后發生了改變,晚期學習者(late learner)可能無法達到母語者水平。在關鍵期之后,L2學習者的語言學習效率會顯著下降,使得L2學習者的腦激活機制不同于母語者。與差異假設不同的是,相似假設(similarity hypothesis)認為L2加工與L1加工在很大程度上是一致的(Hernandez, Li, & MacWhinney, 2005)。原則上說,沒有理由認為L2加工和L1加工具有系統性的差異。L1和L2使用相同的神經認知系統,并且競爭相同的認知資源的假設能夠解釋為什么L2學習者具有不同的學習軌跡(learning trajectory)。而會聚假設(convergence hypothesis)則認為,神經認知系統處于一種動態發展變化的狀態之中,會隨著語言練習次數的增加和語言水平的提高,使得L2加工模式與L1加工模式趨同。該假設認為即使是成人L2學習者,其L2流利度水平以及腦激活模式也能夠達到母語者水平(Steinhauer, White, & Drury, 2009)。
目前來看,L2句子加工研究主要涉及L2學習者與母語者的加工區別(如Jackson & Dussias,2009; Hopp, 2017; Jacob & Felser, 2016; Leikin, 2008;Marinis, Roberts, Felser, & Clahsen, 2005; Omaki &Schulz, 2011; Papadopoulou, 2006; Papadopoulou &Clahsen, 2003; Ravi & Chengappa, 2015; Roberts &Meyer, 2012),以及單純的句法語義加工(如Friederici, 2002; Juffs, 1998)。這些研究主要是基于印歐語系的語言進行的,大都以句法歧義結構作為研究對象來考察L2句子加工,但漢語作為第二語言的句子加工研究并不多(戴運財, 2010; 戴運財, 王同順, 余樟亞, 2013; 牛萌萌, 吳一安, 2007)。
本文選取漢語中常見的“V+N1+的+N2”潛在句法歧義結構(馮志偉, 1995)作為研究對象(實驗語料中的“V”、“N1”和“N2”均為雙音節),考察母語為韓語的漢語學習者在加工這類句法歧義結構時的加工機制。之所以選擇母語為韓語的漢語學習者作為研究對象,主要基于以下考慮:漢語和韓語是兩種不同類型的語言。前者屬于孤立語,幾乎沒有外顯的形態手段來標記句法范疇,而后者屬于黏著語,會使用外顯的形態手段來標記句法范疇,如“格”標記(徐英紅,2009)。母語為韓語的漢語學習者由于母語背景的影響,其對漢語的句法歧義結構加工可能敏感,與漢語母語者存在差異,因此可以利用此類句法歧義結構作為切入點來考察L2句子的加工機制。
本文研究的問題包括:
(1)漢語母語者與母語為韓語的漢語學習者在加工漢語句法歧義結構時對語義和語境的敏感程度是否不同?
(2)母語為韓語的漢語學習者在閱讀漢語句子時是屬于序列加工模式,還是并行加工模式?與母語者的加工模式是否一致?
2 方法
2.1 被試
28名北京大學在讀的韓國留學生,其漢語水平為高級,漢語水平考試(HSK)成績均為6級(最高級別)。28名漢語母語者為北京大學的本科生或研究生。
2.2 實驗設計
實驗采用2×2×2因素設計。三個因素分別為(1)實驗句前一部分“V+N1+的+N2”結構的歧義性:分為有歧義和無歧義兩個水平;(2)續接語境后“V+N1+的+N2”結構可以解讀的結構類型:分為偏正結構和述賓結構兩個水平;(3)被試語言類型:分為漢語和韓語兩個水平。其中,語言類型為被試間變量,續接語境和短語的歧義性為被試內變量。無歧義組為控制組。
2.3 實驗材料
從北京語言大學漢語語料庫(BCC)中選取42條“V+N1+的N2”歧義短語。然后對這些短語的結構相對合理性和事件典型性進行評定,分別由20個不參與正式實驗的漢語母語者完成,以驗證實驗材料的有效性。
在相對合理性評定中,每條短語之后給出其可能存在的兩種結構分析。例如,對于歧義結構“擁護小李的朋友”,給出“擁護朋友”和“擁護小李”兩種不同的分析。隨后,將42條短語產生的84個事件隨機打亂,生成3種不同隨機順序的版本,以平衡位置效應,采用7點量表的方式進行評定。
短語事件典型性評定是考察歧義短語的不同結構所對應的意義在日常生活中的典型性或合理性。在事件典型性評定中,每條歧義短語按兩種不同結構轉化為兩個不同的事件,并以短語的形式表現出來。以歧義短語“擁護小李的朋友”為例,其偏正結構對應的事件為“朋友擁護小李”,其述賓結構對應的事件為“某人擁護小李的朋友”。隨后,將42條短語產生的84個事件隨機打亂,生成3種不同隨機順序的版本,以平衡位置效應。在進行事件典型性評定時,被試依據已有的日常生活中的經驗和常識,按照事件普遍性程度的高低,在7點量表上,對每條短語所代表的事件的普遍程度進行評定。根據設定,分數越低,表明述賓結構越合理;分數越高,表明偏正結構越合理。
利用SPSS 20.0對相對合理性和事件典型性進行相關性檢驗,詳見表1。
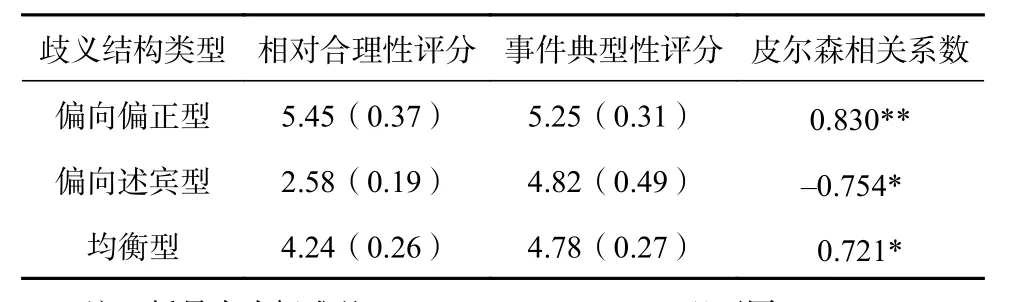
表 1 歧義結構相對合理性與事件典型性相關性檢驗(n=14)
根據分析結果,偏向偏正型和均衡型的相對合理性與事件典型性高度正相關,即相對合理性值越大,事件典型性程度越高;偏向述賓型的相對合理性與事件典型性呈高度負相關,即相對合理性值越大,事件典型性程度越小。
根據這兩項評定后接語境生成實驗句子材料,實驗例句見表2。
42個歧義結構按照四種條件生成168個句子,采用拉丁方將句子分成四組,每組填加32個填充句(Dussias, 2010),填充句均為語義通順的句子,且填充句與實驗句嵌入實驗程序后經過偽隨機處理進行排列,每個被試只閱讀其中的一組句子。同時,又隨機插入37個判斷題,以確保被試認真閱讀句子。此外,在正式實驗前,被試還將閱讀6個練習句,以熟悉實驗流程。這樣,每個被試會閱讀80個句子。實驗句、填充句和判斷題中出現的漢字均為HSK 6級以下的詞匯,句子長度在15-20字之間。每個句子占一行。
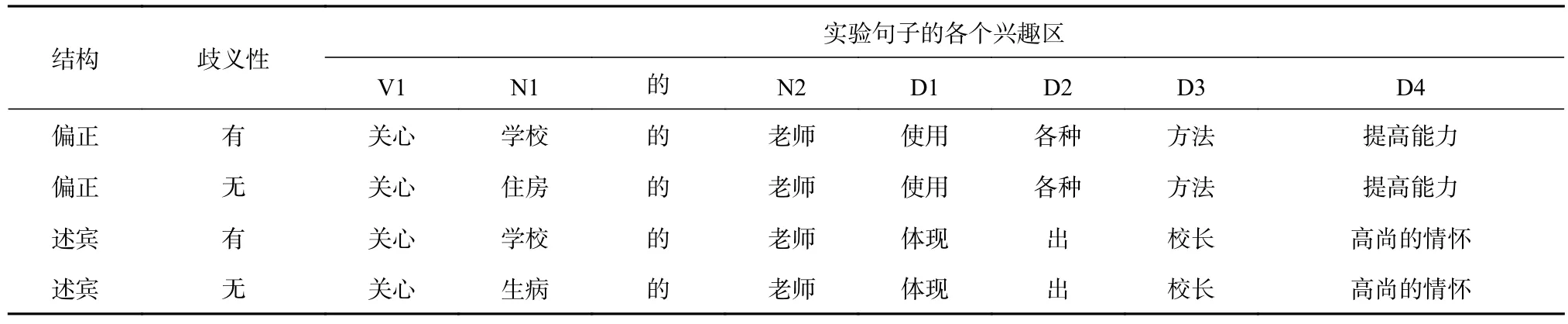
表 2 均衡型結構四種條件下的實驗句子材料
2.4 實驗儀器與程序
本實驗采用SR EyeLink 1000 Plus型眼動儀呈現實驗材料,并記錄被試眼動數據。EyeLink 1000 Plus的采樣頻率為每秒1000次。被試進入實驗室,坐在距離電腦屏幕70 cm的位置,對被試進行3點校準,之后在電腦屏幕上呈現指導語,并向被試簡要說明。正式實驗前有6個練習句,確認被試完全理解整個實驗流程后,開始正式實驗。
3 實驗結果與分析
28名中國被試眼動數據正常,正確率均高于80%,平均為96%。28名韓國被試中,1名被試數據異常,進行剔除;2名被試判斷正確率為60%,低于80%,其數據不參與統計分析,其余被試判斷正確率均高于80%,平均為92.31%。5次以上眨眼以及在緊靠興趣區前、興趣區中間或緊靠興趣區之后有眨眼的數據也予以剔除。此外,還剔除了三倍標準差以外的數據。總剔除數據占總數據的10.54%。
將實驗句按照詞語排列的順序依次劃分為8個興趣區(Area of Interest, AOI),分別為A1、A2、A3、A4、D1、D2、D3、D4。其中 A1 到A4 分別對應“V”、“N1”、“的”和“N2”,興趣區D1到D4是解歧區。
實驗數據利用R語言(version3.3.3)的lme4程序包(version1.1-12, Bates, M?chler, Bolker, &Walker, 2015),采用混合效應模型進行被試分析和項目分析。具體來說,對于興趣區A1至D4的首次注視時間(FFD)、第一遍閱讀時間(FRDT)和總閱讀時間(DT),采用線性混合效應模型進行統計分析。
3.1 首次注視時間
在興趣區A1上,歧義性與續接語境交互效應顯著(estimate=-0.26,SE=0.12,t=-2.15,p=0.037),續接語境與語言類型交互效應顯著(estimate=-0.23,SE=0.11,t=-2.16,p=0.035)。
在興趣區A2上,續接語境主效應顯著(estimate=0.19,SE=0.09,t=2.17,p=0.034)。在興趣區A3上,續接語境主效應邊緣顯著(estimate=0.09,SE=0.05,t=1.79,p=0.075)。在興趣區A4上,歧義性主效應顯著(estimate=0.09,SE=0.04,t=2.10,p=0.037),語言類型主效應顯著(estimate=0.12,SE=0.05,t=2.28,p=0.024),歧義性與續接語境交互效應顯著(estimate=-0.11,SE=0.06,t=-2.05,p=0.041),歧義性與語言類型交互效應邊緣顯著(estimate=-0.10,SE=0.06,t=-1.71,p=0.089),歧義性、續接語境與語言類型交互效應邊緣顯著(estimate=0.14,SE=0.08,t=1.74,p=0.084),二交互效應圖如圖1所示。中韓被試在興趣A4上的平均首次注視時為MChinese=exp(5.34)=208.51 ms,MKorean=exp(5.34+0.12)=235.10 ms。統計結果如表3所示。
在興趣區D1上,續接語境主效應顯著(estimate=-0.16,SE=0.05,t=-3.35,p<0.001),語言類型主效應顯著(estimate=0.12,SE=0.07,t=2.03,p=0.045)。中韓被試在興趣區D1上的平均首次注視時間為:MChinese=exp(5.44)=230.44 ms,MKorean=exp(5.44+0.12)=259.82 ms。
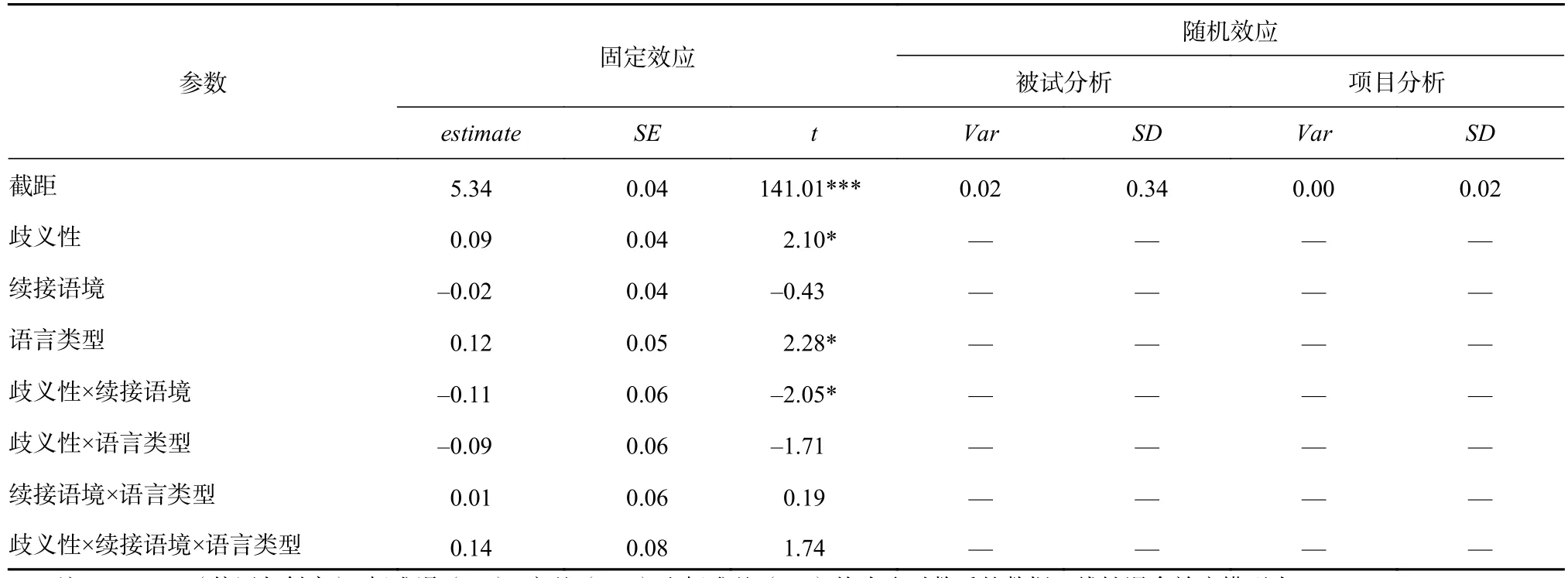
表 3 興趣區A4首次注視時間的線性混合效應模型結果(取自然對數后)
在興趣區D2上,語言類型主效應顯著(estimate=0.08,SE=0.04,t=2.08,p=0.042)。在興趣區D3上,續接語境與語言類型交互效應邊緣顯著(estimate=-0.15,SE=0.08,t=-1.88,p=0.067)。在興趣區D4上,歧義性主效應顯著(estimate=0.13,SE=0.06,t=2.22,p=0.031),語言類型主效應邊緣顯著(estimate=0.14,SE=0.07,t=2.02,p=0.050),中韓被試在興趣區D4上的平均首次注視時間為:MChinese=exp(5.32)=204.38 ms,MKorean=exp(5.32+0.14)=235.10 ms。
在眼動指標首次注視時間上:在興趣區A4和D4上出現了歧義性主效應,且在偏正續接的情況,無歧義的控制組加工時長長于有歧義的,這一點可能是由于中國被試的加工策略所導致的。在興趣區A2、A3和D1上出現了續接語境主效應,中韓被試在興趣區A2和A3上是按照偏正結構來加工的,在D1上是按照述賓結構來加工的。在興趣區A4、D1和D2上出現了語言類型主效應,韓國被試加工時間長于中國被試。
3.2 第一遍閱讀時間
在興趣區A1上,續接語境主效應顯著(estimate=-0.15,SE=0.06,t=-2.60,p=0.013),語言類型主效應顯著(estimate=0.25,SE=0.07,t=3.64,p<0.001)。
在興趣區A2上,續接語境主效應顯著(estimate=0.21,SE=0.11,t=2.00,p=0.049),語言類型主效應顯著(estimate=0.32,SE=0.99,t=3.20,p=0.002<0.01)。中韓被試在興趣區A2上的平均閱讀時間為:MChinese=exp(5.46)=235.10 ms,MKorean=exp (5.46+0.32)=323.76 ms。
在興趣區A3上,續接語境與語言類型交互效應邊緣顯著(estimate=-0.13,SE=0.07,t=-1.77,p=0.076)。在興趣區A4上,語言類型主效應顯著(estimate=0.39,SE=0.07,t=5.27,p<0.001),歧義性與語言類型交互效應邊緣顯著(estimate=-0.12,SE=0.07,t=-1.65,p=0.09)。中韓被試在興趣區A4上的平均閱讀時間為:MChinese=exp(5.41)=223.63 ms,MKorean=exp(5.41+0.39)=330.30 ms。
在興趣區D1上,續接語境主效應顯著(estimate=-0.16,SE=0.07,t=-2.28,p=0.025),語言類型主效應顯著(estimate=0.45,SE=0.08,t=5.87,p<0.001),續接語境與語言類型交互效應顯著(estimate=-0.26,SE=0.10,t=-2.69,p=0.008),歧義性、續接語境與語言類型交互效應邊緣顯著(estimate=0.22,SE=0.11,t=1.95,p=0.051)。中韓被試在興趣區D1上的平均閱讀時間為:MChinese=exp(5.53)=252.14 ms,MKorean=exp(5.53+0.45)=395.44 ms。
在興趣區D2上,語言類型主效應顯著(estimate=0.43,SE=0.07,t=5.78,p<0.001),歧義性與語言類型交互效應顯著(estimate=-0.17,SE=0.08,t=-2.05,p=0.041),歧義性、續接語境與語言類型交互效應顯著(estimate=0.26,SE=0.13,t=-2.05,p=0.041),如圖2所示。中韓被試在興趣區D2上的平均第一遍閱讀時間為:MChinese=exp(5.50)=244.69 ms,MKorean=exp(5.50+0.43)=376.15 ms,如表 4。
在興趣區D3上,語言類型主效應顯著(estimate=0.30,SE=0.08,t=3.84,p<0.001),續接語境與語言類型交互效應顯著(estimate=-0.19,SE=0.09,t=-2.06,p=0.043)。中韓被試在興趣區D3上的平均第一遍閱讀時間為:MChinese=exp(5.59)=267.74 ms,MKorean=exp(5.59+0.30)=361.41 ms。
在興趣區D4上,歧義主效應顯著(estimate=0.24,SE=0.11,t=2.20,p=0.030),續接語境主效應邊緣顯著(estimate=0.20,SE=0.11,t=1.90,p=0.064),語言類型主效應顯著(estimate=0.58,SE=0.11,t=5.38,p<0.001)。中韓被試在興趣區D4上的平均第一遍閱讀時間為:MChinese=exp(5.44)=230.44 ms,MKorean=exp(5.44+0.58)=411.58 ms。

表 4 興趣區D2第一遍閱讀時間的線性混合效應模型結果(取自然對數后)
在眼動指標第一遍閱讀時間上:在興趣區D4上出現了歧義性主效應,由于是解歧后區產生的歧義性主效應,所以對實驗分析的參考性作用不大。在興趣區A1、A2、D1和D4上出現了續接語境主效應,中韓被試在興趣區A1和D1上是按照述賓結構來加工的,在A2和D4上是按照偏正結構來加工的。在興趣區A1、A2、A4、D1、D2、D3和D4上出現了語言類型主效應,韓國被試加工時間長于中國被試。
3.3 總閱讀時間
在興趣區A1上,語言類型主效應顯著(estimate=0.42,SE=0.08,t=5.37,p<0.001)。在興趣區A2上,語言類型主效應顯著(estimate=0.32,SE=0.11,t=2.82,p=0.006)。中韓被試在興趣區A2上的平均總閱讀時間為:MChinese=exp(6.00)=403.43 ms,MKorean=exp(6.00+0.32)=555.57 ms。
在興趣區A3上,續接語境主效應顯著(estimate=0.27,SE=0.07,t=3.76,p<0.001),語言類型主效應邊緣顯著(estimate=0.16,SE=0.08,t=1.96,p=0.052)。歧義性與續接語境交互效應顯著(estimate=-0.33,SE=0.11,t=-3.07,p=0.003),續接語境與語言類型交互效應顯著(estimate=-0.25,SE=0.10,t=-2.49,p=0.017),歧義性、續接語境與語言類型交互效應顯著(estimate=0.34,SE=0.15,t=2.35,p=0.024),如圖3所示。中韓被試在興趣區A3上的平均總閱讀時間為:MChinese=exp(5.46)=235.10 ms,MKorean=exp(5.46+0.16)=275.89 ms。統計結果如表5所示。
在興趣區A4上,續接語境主效應顯著(estimate=0.14,SE=0.06,t=2.20,p=0.031),語言類型主效應顯著(estimate=0.38,SE=0.11,t=3.44,p<0.001),歧義性與續接語境交互效應邊緣顯著(estimate=-0.16,SE=0.09,t=-1.85,p=0.069)。中韓被試在興趣區A4上的平均總閱讀時間為:MChinese=exp(5.81)=333.62 ms,MKorean=exp(5.81+0.38)=487.85 ms。
在興趣區D1上,續接語境主效應顯著(estimate=-0.18,SE=0.08,t=-2.28,p=0.024),語言類型主效應顯著(estimate=0.43,SE=0.10,t=4.16,p<0.001),續接語境與語言類型交互效應顯著(estimate=-0.23,SE=0.09,t=-2.48,p=0.013)。中韓被試在興趣區D1上的平均總閱讀時間為:

表 5 興趣區A3總閱讀時間的線性混合效應模型結果(取自然對數后)
MChinese=exp(5.88)=357.81 ms,MKorean=exp(5.88+0.43)=550.04 ms。
在興趣區D2上,續接語境主效應顯著(estimate=-0.14,SE=0.05,t=-2.71,p=0.008),語言類型主效應顯著(estimate=0.44,SE=0.08,t=5.46,p<0.001)。中韓被試在興趣區D2上的平均總閱讀時間為:MChinese=exp(5.73)=307.97 ms,MKorean=exp(5.73+0.44)=478.19 ms。在興趣區D3上,語言類型主效應顯著(estimate=0.25,SE=0.10,t=2.46,p=0.016)。中韓被試在興趣區D3上的平均總閱讀時間為: MChinese=exp(5.89)=361.41 ms,MKorean=exp(5.89+0.25)=464.05 ms。
在興趣區D4上,歧義性主效應顯著(estimate=0.23,SE=0.12,t=1.99,p=0.049),續接語境主效應顯著(estimate=0.29,SE=0.11,t=2.60,p=0.011),語言類型主效應顯著(estimate=0.69,SE=0.12,t=5.98,p<0.001)。中韓被試在興趣區D4上的平均總閱讀時間為:MChinese=exp(5.63)=278.66 ms,MKorean=exp(5.63+0.69)=555.57 ms。
在眼動指標總閱讀時間上:在興趣區D4上出現了歧義性主效應,由于是解歧后區產生的歧義性主效應,所以對實驗分析的參考性作用不大。在興趣區A3、A4、D1、D2和D4上出現了續接語境主效應,中韓被試在興趣區A3、A4和D4上是按照偏正結構來加工的,在D1和D2上是按照述賓結構來加工的。在興趣區A1、A2、A4、D1、D2、D3和D4上出現了語言類型主效應,韓國被試加工時間長于中國被試。
4 討論
4.1 語義與語境對句子加工的作用
總體上來說,從反映早期加工的首次注視時間和第一遍閱讀時間來看,實驗句在A4和D4(首次注視時間),以及D4(第一遍閱讀時間)上出現歧義性主效應,產生花園路徑效應;在A2和D1(首次注視時間),以及A1、A2、D1和D4(第一遍閱讀時間)上出現語境主效應。歧義性效應和語境效應的存在說明,中韓被試在句子加工的早期階段,語義信息就對被試的句法分析產生強烈的制約,這種制約被即時用于指導句子的加工,影響句義的建構,本文的研究結果一定程度上支持句子加工的相互作用模型和基于制約的模型。
依照花園路徑模型中的最小附加原則,被試會以最少的節點數把新的語言輸入成分架構在句法樹上。為了減少認知加工負荷,被試在加工歧義結構時,會建構相對簡單的句法結構。對于“V+N1+的+N2”歧義結構來說,分析成偏正義和述賓義的節點數是一樣的。也就是說,從句法的角度來看,這兩種結構的復雜程度是一樣的,所帶來的認知加工負荷也是一樣的。但從實驗結果中語境主效應的偏回歸斜率既存在正值,也存在負值的現象,可以得知,中韓被試在加工過程中并不是單一按照一種句法結構關系來理解的,這也就說明最小附加原則不能夠解釋被試的“V+N1+的+N2”句法分析加工過程。從花園路徑模型中的遲關閉原則來考慮,中韓被試會將新成分N2附著到最鄰近的結構上,也就是“N1+的”上,這樣與V組合在一起以述賓義的結構呈現。但在實驗結果中,A2、A3和A4首次注視時間和第一遍閱讀時間的語境主效應的偏回歸斜率為正值,這說明中韓被試在這些區段是按照偏正義來理解的,因此遲關閉原則不能解釋被試的加工過程。
根據L2句子加工中的時近原則,為了提高加工效率,減少加工負荷,加工器會選擇低位掛靠,這與遲關閉原則相似,但謂詞鄰近原則認為,語法上允許的話,加工器會將新成分高位掛靠到謂詞的中心詞組上(Gibson, Pearlmutter, Canseco-Gonzalez, & Hickok, 1996)。對應到“V+N1+的+N2”歧義結構,并結合實驗結果,可以得知,中韓被試在加工過程中整體上是將歧義區段A2、A3和A4按照偏正義進行加工的。也就是說,他們將新成分N2掛靠在動詞V上,遵循了高位掛靠的原則,這從側面說明了在漢語句子加工中高位掛靠原則強于低位掛靠。但同時,由實驗結果中的續接語境和語言類型的交互效應,可以得知,在具體的興趣區A3和D3上,韓國被試選擇了述賓義加工,而中國被試選擇了偏正義加工,且韓國被試加工時間明顯長于中國被試,這說明韓國被試在加工過程中的句法表征是粗顆粒的(coarse grained)。但考察解歧區D1的第一遍閱讀時間和總閱讀時間,我們發現,續接語境和語言類型存在著交互效應,中韓被試都選擇述賓義進行加工,韓國被試的加工時間長于中國被試,這又說明有著不同語言背景的中韓被試的語言認知系統并不存在本質差異(Dekydtspotter, Schwartz, &Sprouse, 2006)。
此外,雖然漢語和韓語是兩種完全不同的語言類型,分別屬于孤立語和黏著語,前者幾乎沒有外顯的形態手段來標記句法范疇,而后者會利用外顯的形態手段來標記句法范疇。但從實驗結果來看,歧義性和語言類型存在的交互效應,韓國被試對漢語句法歧義結構加工較為敏感。從解歧區存在著續接語境和語言類型存在著交互效應也可以發現,韓國被試在解歧區的加工模式與中國被試相類似。在本實驗中,韓國被試的漢語水平已經達到近似母語者(native-like)的水平,再結合實驗數據分析,可以得知韓國被試L2(漢語)水平和認知加工模式也能夠達到漢語母語者水平,在L2句子加工晚期與漢語母語者趨于一致,這從一定程度上證明了Steinhauer(2014)所提出的二語者L2加工的會聚假設。
本質上說,語境效應和掛靠傾向性都是L2句子加工時被試對句法結構的語義傾向性的選擇,體現了L2句子加工的加工策略和心理機制(Dussias,2010)。在本實驗結果中,歧義區段出現的語境主效應,表明語境和語義信息在早期加工階段相互影響,共同作用于句子加工。
4.2 限制性并行加工模型
從實驗結果來看,在早期加工階段,A4和D4(首次注視時間),以及D4(第一遍閱讀時間)上出現歧義性主效應;在晚期加工階段,D4(總閱讀時間)上出現歧義性主效應,也即產生了花園路徑效應,這說明歧義性給中韓被試增加了加工負荷,中韓被試最后輸出的句法表征是單一的,符合序列加工機制。其他大部分興趣區在早期加工階段和晚期加工階段均沒有出現歧義性效應,說明中韓被試最后輸出的句法表征不是單一的,符合并行加工機制。
被試的句子加工模式可以由被試在遇到句法歧義時所構建和維持的句法表征數目來確定(Hsiao& Gibson, 2003)。在序列加工理論框架中,如果新成分不能夠被整合到當前結構中,那么加工器就會重新進行句法分析,以將新成分納入。這種重新分析會產生額外的加工負荷,導致加工時間增加。序列加工的核心爭論點在于在很多實驗過程中句法歧義結構并沒有導致明顯的加工困難出現,而重新分析理論也從一定程度上證明并不是所有的重新分析都會產生顯著的花園路徑效應(Frazier& Rayner, 1982)。在實驗結果中,歧義性主效應出現在興趣區A4和D4上,但解歧區D4上的歧義性主效應只能作為參考,不能有效地說明歧義性對句子加工的作用。我們發現,興趣區A1在早期加工階段存在著歧義性與續接語境的交互效應(estimate=-0.26,SE=0.12,t=-2.15,p=0.037),偏正語境下,有歧義的加工時長短于無歧義的加工時長,這不符合純粹的序列加工模式。
在并行加工理論框架中,加工器會在句法歧義區段建構并維持多個結構。以本文研究的焦點“V+N1+的+N2”為例,加工器在句法歧義區段就能夠建構并維持偏正和述賓兩種句法表征。在加工過程中,句法復雜度、詞頻、語義信息和語境等因素會影響句法表征的激活水平、排序和選擇(Hsiao & Gibson, 2003)。Tabor和 Hutchins (2004)提出可計算的自組織句子加工模型(computational self-organized parse)認為在句子加工中每一個新出現的成分都盡可能并行地激活與自身相匹配的附加結構(attachment),匹配后可供選擇的句法結構由加工器依據詞匯化的句法知識相互競爭,直到其中一個結構達到穩定狀態(stabilisation)。根據這一加工模型,加工器在加工“V+N1+的+N2”時,在新成分“的”出現時,就會同時激活偏正結構和述賓結構,然后根據加工器已有的詞匯化的句法知識來進行選擇。在實驗結果中,興趣區A3(“的”)在晚期加工過程中出現了歧義性與續接語境的交互效應(estimate=-0.33,SE=0.11,t=-3.07,p=0.003),反映了中韓被試根據自身已有的句法知識并行地激活了偏正結構和述賓結構,并在加工晚期依靠解歧區的語境消息輸出穩定狀態的句法結構,這在一定程度上符合可計算的自組織句子加工模型。
可計算的自組織句子加工模型從本質上來說是一種限制性并行加工模型(limited parallelism,Hsieh & Boland, 2015)。依據限制性并行加工模型,并結合實驗結果,可以得知,中韓被試在最初并行激活兩種結構后,會出現短暫的花園路徑效應,不受期待的結構(dispreferred alternative)的激活水平快速降低,然后單一的句法表征被選定。中韓被試雖然快速選定的具體句法表征有所差異,但加工模式總體上是一致的。
總的來說,中韓被試句子加工是限制性并行的,是基于制約的。在歧義區段“V+N1+的+N2”,被試同時激活偏正結構和述賓結構,得到更多語境和語義支持的結構激活水平更高,不受期待的結構激活水平快速弱化。在重新分析的過程中,由于不受期待的結構在早期加工過程中得到較多激活,所以加工時間并未顯著增加。
5 結論
本文發現,在句法歧義加工過程中,中韓被試的語言認知系統并不存在本質差異,語境和語義信息在句子加工的早期階段即相互影響,共同作用于句子加工,句子的晚期加工二者也趨于一致。這在一定程度上證明了Steinhauer等人(2009)所提出的二語者L2加工的會聚假設。母語為韓語的學習者漢語句子加工是限制性并行的,符合相互作用模型和基于制約的模型。
猜你喜歡
核科學與工程(2021年4期)2022-01-12 06:30:26
中華詩詞(2021年3期)2021-12-31 08:07:22
大連民族大學學報(2021年2期)2021-07-16 05:41:42
今日農業(2020年19期)2020-12-14 14:16:52
文苑(2020年4期)2020-05-30 12:35:30
中華詩詞(2018年3期)2018-08-01 06:40:40
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
中華詩詞(2018年11期)2018-03-26 06:41:32
中學物理·高中(2016年12期)2017-04-22 11:53:03
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
