面向5G需求的人群流量預測模型研究
2019-03-13 08:17:18胡錚袁浩朱新寧倪萬里
通信學報 2019年2期
胡錚,袁浩,朱新寧,倪萬里
(北京郵電大學網絡與交換技術國家重點實驗室,北京 100876)
1 引言
隨著移動網絡技術的飛速發展,用戶對網絡的使用和需求無時無處不在,且數據業務量急劇增長,這一需求促進了5G技術的發展和5G網絡的商業化進程。
通過對小型蜂窩網絡的密集部署及移動邊緣計算的應用,可以大大增強移動網絡的帶寬和服務質量。然而如何真正提高大量小基站的效率,充分發揮邊緣計算的能力,是提升5G網絡服務質量的關鍵問題之一。
由于用戶數量和用戶的業務需求是影響基站緩存部署、資源分配和能耗管理的重要因素,通過準確預測基站覆蓋范圍內的用戶數量,對提高5G網絡性能具有重要意義,尤其是針對某些基站所覆蓋的特定的功能區域,如景區、辦公區、住宅區等,由于不同區域具有其特定的業務需求模式,對區域內人群數量的預測,將有利于區域內網絡資源的部署和分配。
首先,區域內人群流量預測有利于5G基站緩存部署及資源分配決策。靠近用戶接入側的5G小基站主要包括計算、存儲和通信等資源,但由于硬件資源受限,小基站可能無法為所有用戶提供足夠的計算和緩存服務[1]。由于網絡接入的用戶流量將直接影響基站的緩存決策及計算和通信資源的分配方式,因此,基于不同基站下的人群流量差異,利用呼叫詳單數據預測用戶下一時刻的地理位置[2],再從全局角度研究5G網絡中小基站和宏基站的最優緩存與資源分配策略,有望減小網絡端到端時延,有效提高網絡通信能力。
其次,人群流量預測有利于制訂5G基站活躍/休眠切換方案。雖然為支持高速率移動通信服務和提供無縫覆蓋的大量 5G基站功率較低,但總的 5G基礎設施所消耗的能量將是顯著的[3]。在維持移動用戶服務質量的同時,關閉或休眠5G網絡中未充分利用的小基站將是一種高效的節能方法。因此,從環保和經濟效益的角度出發,準確的人群流量預測結果將為5G基站的活躍/休眠切換機制提供有力的參考依據和行動準則。
人群流量預測還有利于 5G基站密集部署規劃。在5G時代,面對急劇增長的移動流量,小型蜂窩網絡的部署可以提供巨大的網絡容量,但 5G基礎設施的大面積高密度部署將會帶來高昂的建設成本和運營成本[4],因此,在保障用戶流量需求的前提下,為最小化移動網絡運營商的資本支出,需要通過對人群流量的預測來有效規劃5G基站的部署位置與數量。
此外,區域人群流量預測本身還可以作為改進城市規劃、實現特定區域如景區的監控和管理、進行交通流量管理、防范人群聚集的突發事件的重要依據。
隨著位置信息獲取技術的發展,大量標識用戶時空位置的數據可以被用來實現區域的流量預測。基于移動網絡的呼叫詳單記錄數據可以獲取以基站位置標注的用戶時空位置信息,因而可以作為表征全域覆蓋范圍內的區域人群流量的數據。基于該時空位置信息進行各種尺度的區域人群流量預測可以為5G基站的緩存部署及資源分配等應用提供重要的決策支撐。
基于用戶位置信息的人群流量預測已有不少研究[5-16],文獻[13-16]提出了基于深度時空學習的模型來實現對區域間依賴關系的自動提取,然而,人群移動使不同區域之間的流量存在一定的空間相關性,而流量在時間上存在連續性和周期性,且與短時流量密切相關,因此如何準確地對復雜的時空依賴關系進行建模是流量預測過程中的巨大挑戰。其次,各種外部特征,如下雨、空氣污染等的異常變化會給流量帶來影響,其影響方式、程度和時間可能不同,因此如何將多維度的外部特征添加到預測模型中也是流量預測過程中需要解決的問題。此外,為了實現對短時間內流量的準確預測,需要利用臨近時間的流量信息。為了降低對全局流量數據實時傳輸的需求,如何只利用局部實時數據,再結合較長期全局數據完成區域流量預測 也是流量預測面臨的挑戰。
基于上述分析,本文提出了一種基于時空殘差網絡和長短期記憶網絡(LSTM, long short term memory)建模流量時空依賴關系,并融合各種外部影響因素,對短時流量信息僅依賴局部實時信息進行建模的深度時空網絡流量預測模型。該模型在降低全局實時信息傳輸的同時,提高了預測精度,為后期基站資源部署和分配提供依據。
2 相關工作
2.1 5G網絡部署與資源分配需求
5G具有基站大面積密集部署、微基站覆蓋范圍小等典型特征,這在給網絡帶來如提升數據速率、支持泛在接入等好處的同時,也給網絡帶來了新的挑戰和要求,如小基站的部署選址問題、能效問題以及資源管理問題。為支持下一代移動服務的需求,5G網絡的部署必然會涉及新基站設備的安裝問題,因此,為最小化目標資本支出,5G網絡規劃本身就是一個復雜的問題,尤其是在人口密集的城市地區,這一問題更加凸顯。Oughton等[4]提供了一個基于場景和移動流量增長的5G網絡基礎設施供需評估,而移動流量的直接生產者就是基站的接入用戶,因此預測基站的人群流量密度能有效地降低運營商的部署成本。
為了滿足熱點場景下大規模聚合數據速率的需求,密集部署的5G基站具有一定的冗余,因此,在低功耗基站較多的情況下,需要關閉/休眠大量空閑基站來實現節能,但關閉/休眠基站會增加附近多個基站的流量負載,即不同基站之間的開關狀態和用戶服務質量存在高度依賴關系。Feng等[3]研究了5G網絡中開關基站的有效方法與所面臨的挑戰,如根據用戶的流量類型調整基站的運行模式,進而提高系統性能。
近年來,在移動設備上部署計算密集型的應用日益增多,超低時延已成為實現高用戶體驗的重要需求保障。為解決這個問題,能有效節省網絡帶寬和降低端到端時延的最優緩存與網絡資源分配策略受到了廣泛關注。Chen等[1]提出了一種高效收集全局可用資源信息的移動網絡架構,并設計了一個由小基站和宏基站組成的最優緩存策略以最小化網絡時延。不同的人群流量將會帶來文件流行度與計算任務卸載的差異,在網絡邊緣考慮人群流量密度可以為進一步提高緩存命中率與制定卸載決策提供有效依據。
2.2 人群流量預測
近年來,城市范圍的人群流量預測受到了研究人員的廣泛關注,無論是傳統的時間序列模型,還是近來廣為流行的深度學習框架,都在人群流量預測領域有所建樹。
基于時間序列模型進行流量預測,主要考慮的是流量數據的時間依賴關系,比如Kumar等[5]提出了一種基于卡爾曼濾波技術的預測方案,可以僅使用較少的歷史數據來實現流量預測;而Li等[6]則提出了一種改進的自回歸移動平均模型(ARIMA,autoregressive integrated moving average)來預測熱點地區的流量變化;類似地,Matias等[7]同樣提出了一種出租車乘客短期空間分布預測方案,將數據聚合成直方圖時間序列并結合3種時間序列預測技術進行預測。近年來,在時間序列預測模型的基礎上,研究人員也開始進一步探究空間依賴關系以及相關外部影響特征的建模,比如Tong等[8]提出了一種具有2億多個特征維度的線性回歸模型,結合了時間、空間、外部特征等多個維度的大量特征,實現了出租車需求預測;Wu等[9]結合了興趣點(POI,point of interest)、天氣、地理標記等多域數據,從不同視角對出租車需求進行了分析與預測。然而,即便充分結合了各種附加因素,預測結果仍難很好地反映復雜的非線性時空相關性[10]。
隨著深度學習技術的不斷發展和完善,并考慮到流量預測的時空建模的復雜性,利用深度學習的模型進行流量預測受到了更多研究人員的青睞。Liu等[11]提出了一種新的端到端深度學習體系結構,基于 Conv-LSTM(convolutional long short-term memory)模塊提取流量的時空特征,從而實現了良好的流量預測性能;Polson等[12]針對由異常特征導致的急劇的異常流量變化問題,提出了一種深度學習的框架,證明深度學習架構可以捕捉這些非線性時空效應,此外,Zhang等[13-14]充分考慮不同歷史時間層的影響分別建模,并結合天氣、元數據等外部特征,搭建了復雜的深度學習網絡 DeepST和ST-ResNet(spatio-temporal residual network),得到了明顯的性能優化和提升;最近,Huang等[15]提出了一種新的犯罪預測框架——DeepCrime,該框架可以揭示犯罪數目的動態的變化模式,探索其隨時間的演變模式以及與其他信息的動態關聯,在犯罪預測上取得突出的效果。
上述研究工作為區域人群流量預測提供了基礎,本文將主要針對復雜的時空依賴關系、外部因素的影響以及為5G網絡資源分配提供決策依據時所需的短時流量預測等問題進行人群流量預測的建模。
3 區域人群流量預測模型
3.1 系統模型
考慮到同一類功能區如景區、住宅、商業區等具有相似的人群流量模式和業務需求模式,本文在進行整個城市范圍的流量預測時,首先對城市進行基于興趣點(POI,point of interest)分布的分區。目前的城市分區方案[10,12-14]更多考慮的是城市的規模、范圍等,但缺少對分區過程的約束,可能導致不同功能區之間的混疊。以景區為例,景區覆蓋范圍內一般包括多個基站,如果隸屬于不同景區的基站被劃分至同一網格,由于基于移動網呼叫詳單數據的用戶位置信息是由其連接的基站所定位,這種混疊自然會影響景區間空間依賴關系的建模與景區流量的計算和預測。因此,在本文中,為了避免這種混疊的出現并盡可能減少后續預測的復雜度,在分區過程中加入以下約束:1)避免將不同功能區的基站映射到同一個網格;2)盡可能減少城市分區的數目。基于此,可以將城市劃分為I×J的網格圖。而要預測的區域(功能區)可以視為相鄰網格的聚合。如圖1所示,該模型可運行在區域中的宏基站或具有相應計算和存儲資源的基站上。
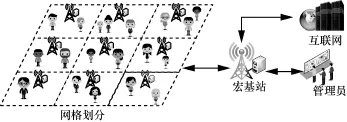
圖1 面向5G需求的基站接入人群流量預測系統模型
本文涉及的符號及其含義如表1所示。

表1 符號標記及其含義
定義1 流量。在第t個時間段,網格(i, j)內的流量定義如式(1)所示。
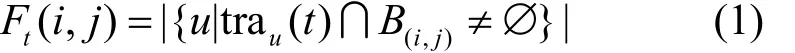
其中,|?|表示集合內元素的數目,trau(t)表示用戶 u在時間段 t內通信的基站集合。B(i,j)表示區域(i, j)內的基站集合。在第t個時間段,所有I×J個區域的流量可以表示為矩陣 Ft∈RI×J,也可用時間段 t的流量圖表示。類似地,在第t個時間段,第i個區域的流量可以定義為其中,Mi表示第i個區域內的基站集合。在第t個時間段,所有p個區域的流量可以表示為區域流量向量。
3.2 基于深度時空網絡的人群流量預測模型
基于區域流量預測問題,本文提出的流量預測模型的整體框架如圖2所示,主要包括3個模塊,分別是外部特征模塊、時空模塊和圖嵌入模塊,圖中分別用虛線框標識的a、b、c指出這3個模塊。該模型從3個不同的角度對區域流量預測問題進行建模。
外部特征模塊提取預測所需的所有歷史時段的各類外部特征,包括天氣、空氣質量、節假日、時間等元數據特征,并將這些外部特征按照時間順序拼接為矩陣的形式,送入全連接層1中,進行特征的提取與優化。
時空模塊將時間軸劃分為3個層次,即臨近層、周期層和趨勢層,分別表示臨近時間、較近和較遠的歷史時間,在不同時間層內,按照一定周期取相應時間長度的歷史流量數據作為輸入。由于臨近層輸入為短時間內的流量數據,為降低實時數據傳輸需求,本模型中僅需要局部流量數據,即通過當前預測區域的宏基站提供的區域內短時的流量向量。而周期層和趨勢層的輸入為長時間的流量,這部分數據不需要實時的數據傳送,故取對應時段的全局流量圖。
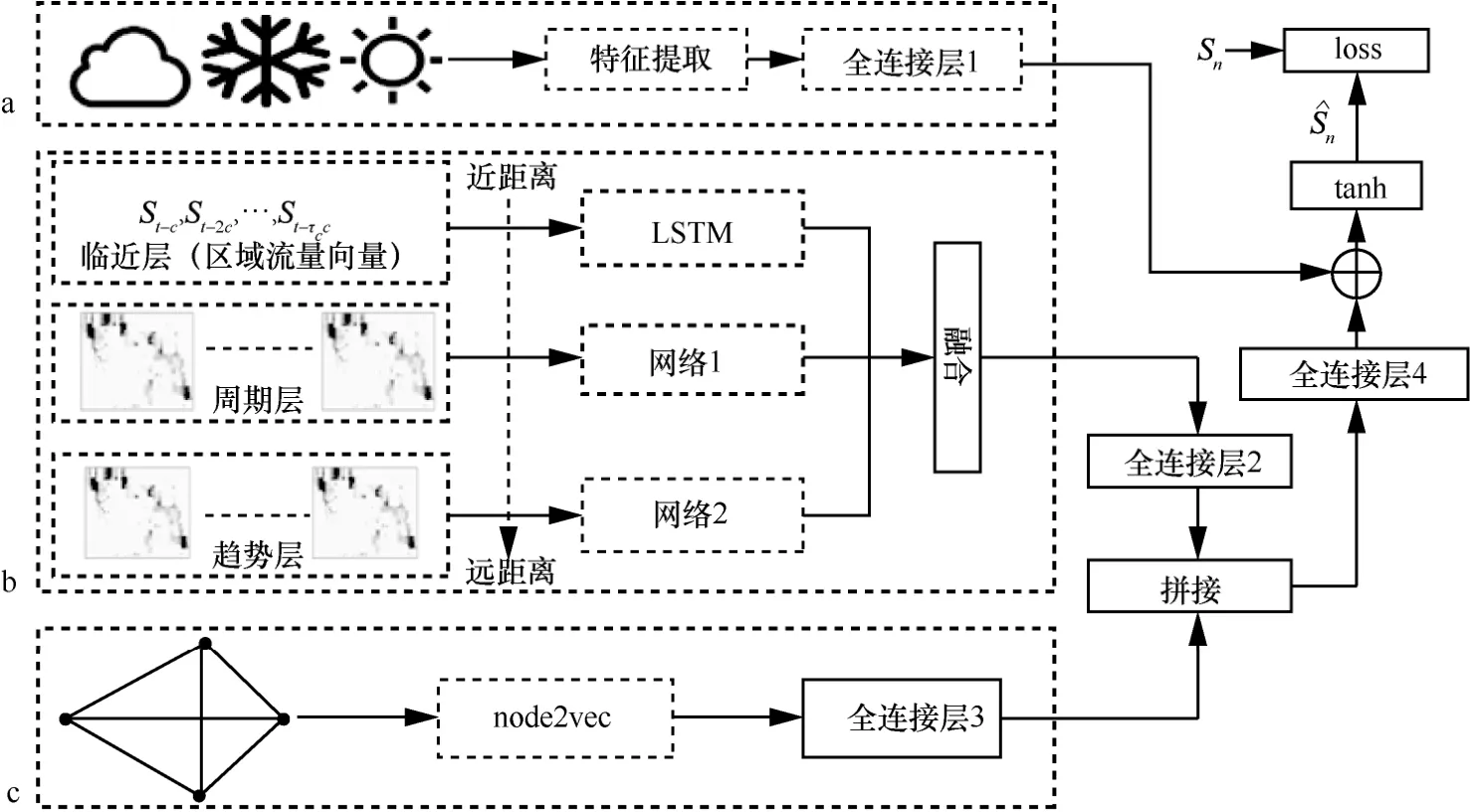
圖2 基于深度時空網絡的區域流量預測模型
3個層次的流量輸入分別送入相互獨立的3組神經網絡,對不同時間層的影響進行建模,其中,針對臨近時間層,利用LSTM模塊捕捉其時間上的相關性;周期層與趨勢層則構建殘差神經網絡來對時空依賴關系協同建模。最后,針對圖嵌入模塊,為要預測的區域之間構建區域距離圖,并利用node2vec將其抽取為向量,通過全連接層3進行特征提取,作為另一視角的流量預測結果。
在預測輸出部分,將3個時間層的輸出進行基于參數矩陣的融合,并通過全連接層2優化預測結果,作為時空模塊的預測輸出SST。然后,將其與圖嵌入模塊的輸出進行拼接,并將拼接的結果送入全連接層 4,進行特征的提取與優化。最后,將輸出結果與外部特征模塊的輸出疊加,并通過tanh函數將結果映射到[-1,1],以便在訓練過程中得到更快的收斂速度。
3.2.1 外部特征模塊
外部特征(如天氣、空氣質量、節假日信息等)對相關區域的流量可能產生巨大的影響,例如,在下雨天或空氣質量差的情況下,前往景區的人數一般都會明顯下降,如何衡量這種由于外部特征所帶來的流量波動,如何準確地對多維外部影響特征建模,是進行區域流量預測時需要重點考慮的問題。本文針對時空模塊預測中涉及的所有歷史時段,對每個時段t分別提取一組特征向量Et,具體如表 2所示。將不同時段的特征向量拼接為矩陣的形式,送入全連接層1進行特征提取,得到p維的區域預測向量,即為外部特征模塊的預測輸出,記為SEX。

表2 外部特征描述
3.2.2 時空模塊
時空模塊主要包括3個相互獨立的處理單元以及融合輸出部分。在3個時間層中,以一定的周期c, pr, tr選取一定長度(lc,lpr,ltr)的歷史流量數據作為輸入,分別表示臨近時間、較近和較遠的歷史時間,其中,臨近層的輸入為對應時間區域流量向量,而周期層以及趨勢層都是以多組流量圖作為輸入。
對于臨近層,可以通過宏基站獲取實時的預測區域的流量數據。然而僅依據局部區域的流量數據難以對流量的空間依賴關系準確建模,因此臨近層采用如圖3所示結構的時間序列模型LSTM建模,充分考慮臨近時間段內區域流量數據的時間依賴特性。
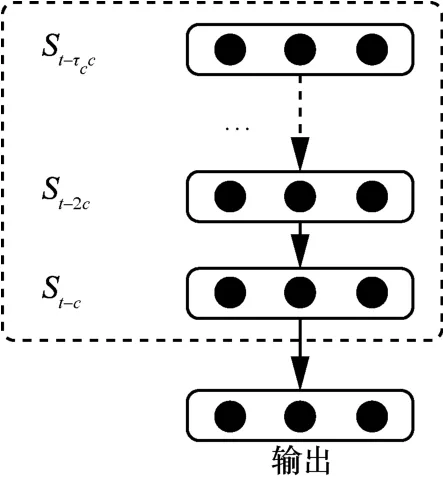
圖3 LSTM模塊的基本結構
LSTM 模塊共包括lc個時間單元,每個單元的輸入為對應該時段的區域流量向量,該模塊的最終輸出即為下一時段的p維區域流量向量,記為Xc。
而在周期層和趨勢層中,利用較遠的歷史時間的全局流量信息(即整個城市范圍的流量數據)挖掘更為豐富的時空依賴關系。對每個時間層,將多個歷史時段的流量圖組合為類似視頻形式的多通道輸入信息,并通過結構完全一致的2個并行的殘差網絡1和殘差網絡2進行后續的時空依賴關系的建模,其結構如圖4(a)所示。
多通道的輸入信息通過卷積層1進行初步的特征提取。輸出的特征映射被送入2個連續的殘差單元(殘差單元1和殘差單元2),殘差的基本結構如圖4(b)所示,即用卷積層來擬合的不是直接的映射關系,而是殘差映射。相比于卷積層的堆疊,殘差學習的優勢在于隨著網絡深度的加深,模型至少可以保證性能不會變差,這樣就通過殘差單元的堆疊實現了對遠距離的空間依賴關系的建模。
最后,殘差單元2的輸出被送至全連接層,將其映射到p維的輸出向量,從而得到該時間層的預測輸出。周期層和趨勢層的輸出分別記為Xpr和Xtr。
通過LSTM模塊、殘差網絡1和殘差網絡2,可以實現從3個不同的時間尺度上挖掘豐富的時空信息。但不同時間層的影響程度很難直觀給出判斷,因此參考論文文獻[16],為了將 3個時間層的輸出以更為恰當的權重進行融合,本文采用基于參數矩陣的融合方式,如式(3)所示。
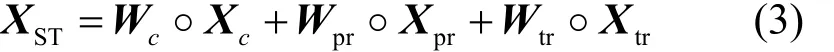
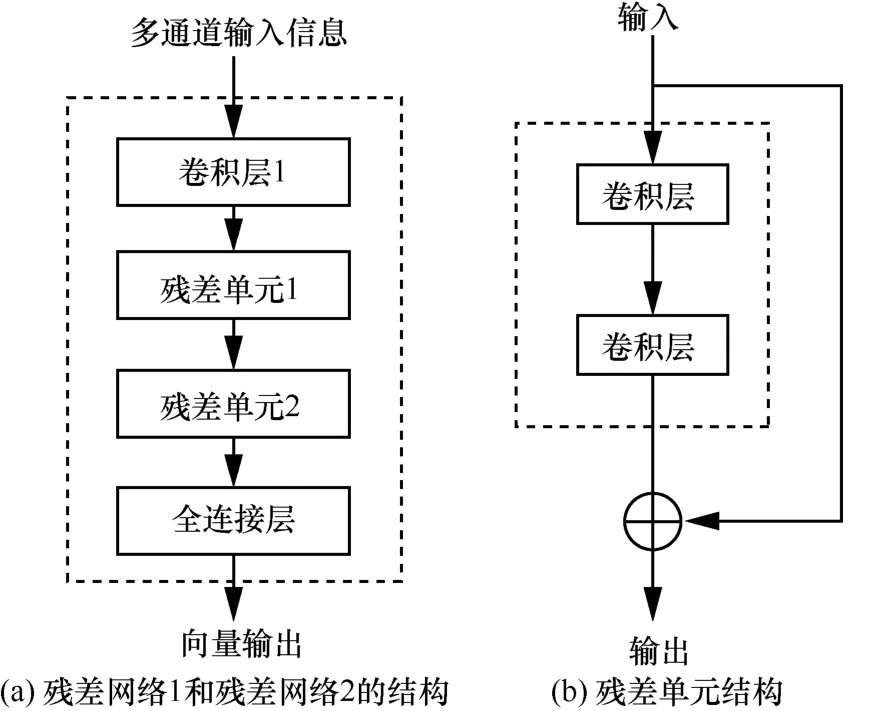
圖4 殘差網絡1和殘差網絡2的結構
其中,?表示哈達瑪積,即2個矩陣的元素對應位置相乘,最終可以得到同維度的輸出矩陣。Xc、Xpr、Xtr分別表示3個時間層的輸出,而Xc、Wpr、Wtr則表示不同時間層的權重矩陣,即在網絡訓練中要學習的參數,來調整不同部分對結果預測的重要程度。
得到融合向量后,經由全連接層2進一步優化預測結果,最終得到時空模塊的預測向量輸出SST,如式(4)所示。
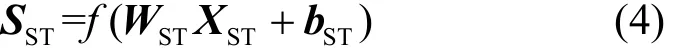
其中,WST和bST分別表示模型需要學習的參數,f(?)表示該全連接層的激活函數,在本文中,除特殊說明外,激活函數均選用relu函數。
3.2.3 圖嵌入模塊
除了歷史流量數據的影響,人群移動模式信息也可能反映出區域之間的某種內在相關性,例如人們更傾向于在相距較近的區域之間轉移,尤其是在一段較短的時間內,這種普遍的人群移動規律就會使得近距離的區域之間會有較強的流量相關性。捕捉這種人類移動模式視角上的空間依賴關系,可以從另一個角度對區域間的相關性進行建模,從而為流量預測提供有價值的信息。因此,本文提出的模型添加了區域距離圖的嵌入模塊,從而更為直觀地構建區域之間與空間距離相關的流量相關性。
具體來說,即為要預測的p個區域之間構建轉移距離圖G=(V,E,D),其中,V表示待預測的區域,E∈(V×V)表示邊的集合,wij表示邊的權重,即區域i和區域j之間的距離量度。考慮到距離越近的區域之間可能有更大的流量相關性,以負指數距離來表示邊的權重,如式(5)所示,以保證更大的邊權重對應于更強的流量相關性。

其中,λ表示距離的衰減系數,本文中取λ=-0.1;dis(i,j)表示區域i和區域j之間的地理距離(單位為km),通過計算兩區域中心點之間的距離而得到。
為了將圖中的信息與深度神經網絡協同訓練,本文考慮了一種圖嵌入方案,即在不破壞圖結構的前提下,以向量的形式提取出每個節點的信息。本文選擇 node2vec模型[17],通過一個二階的隨機游走來平衡廣度優先搜索和深度優先搜索,從而更好地保留圖的結構和連通性。通過node2vec得到不同節點的嵌入向量輸入全連接層3進行特征提取與優化,輸出一個包含p列的矩陣,記為SSE,作為圖嵌入模塊的輸出。
3.2.4 模型訓練與預測輸出
為了將外部特征模塊、時空模塊以及圖嵌入模塊進行協同訓練,首先將得到的p維行向量SST和包含p列的矩陣SSE進行按行拼接,即

然后將XET送入全連接層4,如式(7)所示。
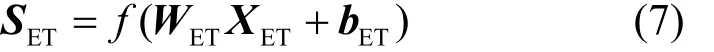
其中,WET和bET表示需要學習的參數,f(?)表示全連接層4的激活函數。
最后將SET與外部特征模塊的輸出SEX疊加后,送至tanh層,如式(8)所示。
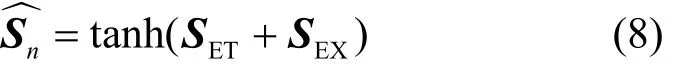
其中,tanh函數用于將預測結果映射至[-1,1]。最終得到的是維度為p的向量,對應下一時段p個區域的流量預測結果。完整的算法流程如算法1所示。
算法1模型訓練過程
輸入臨近層、周期層、趨勢層的周期c、pr、tr,
臨近層、周期層、趨勢層的序列長度lc、lpr、ltr
景區距離圖G
歷史流量圖{Ft|t=0,1,2,…,n-1}
歷史外部特征向量{Et|t=0,1,2,…,n-1}
景區歷史流量向量{St|t=0,1,2,…,n-1}
輸出訓練得到的景區流量預測模型
1) begin
2) D=(/)
3) 在圖G 上,基于node2vec 計算得到矩陣ZSE
4) for all available t (1≤t≤n-1) do
5) ZE=[(Et-c,… ,Et-lec),(Et-pr,… ,Et-lprpr),(Et-tr,… ,Et-ltrtr)]
6) ZC=[St-c,… ,St-lec,St-pr,… ,St-lprprSt-tr,… ,St-ltrtr]
7) ZPR=[Ft-pr,Ft-2pr,… ,Ft-lprpr]
8) ZTR=[Ft-tr,Ft-2tr,… ,Ft-ltrtr]
9) ((ZC,ZPR,ZTR,ZE,ZSE),St)→D
10) end
11)//模型訓練
12)初始化模型中的所有參數θ
13)repeat
14)從D中隨機選取batchDb
15)基于Db,通過最小化損失函數來找到最優化的θ
16)until 滿足停止條件
17)end
模型訓練首先遍歷所有可能的時間段,生成基于每個時間段的訓練樣本(即步驟2)~步驟10)),然后對訓練集提取batch,并運用反向傳播算法優化模型參數(即步驟12)~步驟16))。其中,損失函數定義如式(9)所示。

其中,θ表示所有需要訓練參數的集合。模型訓練的過程即最小化L的過程。
4 實驗結果與性能分析
4.1 實驗設計
本文應用某旅游城市的移動網絡運營商提供的一個月的呼叫詳單數據來驗證人群流量預測模型的效果和性能。考慮到景區作為該城市重要的網絡服務區域,景區人群流量預測的準確性將會影響到部署在景區的基站的服務質量,因此本文選擇景區人群流量預測作為實驗對象。數據包括超過百萬個匿名用戶的上億條呼叫詳單記錄,每條數據包含匿名的用戶ID、時間戳、接入基站編號及經緯度信息。為了應對大規模的數據處理,采用了 Apache Spark集群計算框架。此外,還從氣象網站上爬取了該數據對應的時間段的天氣、空氣質量等數據,用于外部特征的建模。
首先對呼叫詳單數據進行預處理,剔除無效數據、異常和漂移數據,并處理了基站間反復切換的乒乓效應[18-19]。此外,考慮到在輸出端利用tanh函數作為最終的激活函數,為了將輸出數據與標簽數據匹配,在輸入端基于最小最大歸一化對流量數據進行了歸一化處理,將輸入數據均映射到[-1, 1],用于神經網絡的訓練。在后續的模型評估中,再將預測值重新調整回正常值,與真實值進行對比,從而得到準確的預測誤差。
模型基于TensorFlow實現。實驗共選取了25個景區作為預測區域(功能區),并將全市劃分為85×110的網格圖。首先對臨近層、周期層和趨勢層的周期分別選定為30 min、1 d和1 w,而每個時間層中的時間序列長度,分別選擇lc=6、lpr=2、ltr=1。實驗預測的是未來30 min各景區的人群流量。
在神經網絡參數的設置方面,臨近層的LSTM單元選擇6個時間單元,分別對應過去的6個臨近時間段周期層和趨勢層共享同樣的網絡結構,其中,卷積層1選擇5×5大小的32個卷積核,殘差單元中的所有卷積層均選擇3×3大小的32個卷積核。最終3個時間層均輸出25維的向量,經過融合和全連接層的特征優化,時空模塊的最終輸出同樣為25維行向量。
在圖嵌入模塊,經過node2vec,每個景區節點生成10維向量,將其拼接為10×25的矩陣,經過全連接層處理得到4×25的輸出矩陣。
在外部特征模塊,每個時間層構造一組如表 2所示的 10維外部特征向量,將所有時空模塊涉及的歷史時段的外部特征向量送入全連接層,輸出為25維的景區預測向量。具體訓練過程中,選取的batch數目為64,選擇數據集80%的樣本作為訓練集,剩余的20%作為測試集。實驗中應用早停法來選擇最優的模型參數。
本文選用均方根誤差(RMSE, root mean sguard error)作為模型的評價指標,其定義如式(10)所示。
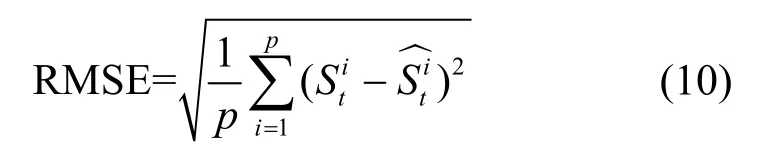
4.2 對比算法
為了驗證模型的預測效果,將本文提出的預測模型與以下8組模型進行了對比,其中涉及的實驗數據、損失函數、評價指標等都與本文模型相同。
HA模型即直接平均算法,根據歷史同一時段的流量數據進行預測。比如要預測周二上午10:00的流量數據,即選擇歷史數據中所有的周二上午10:00的流量平均值作為預測值。
ARIMA模型簡單的線性模型,根據周期性關系,建立預測數據與歷史數據之間的線性關系,可以在一定程度上進行擬合。
VAR模型是一種高級的時空預測模型,可以捕捉不同輸入流量之間的相關性,由于參數量的龐大,計算復雜度非常高。
卡爾曼濾波模型[5]借鑒卡爾曼濾波的基本思想且只需要短時間的歷史數據,利用歷史數據生成連續時間之間的流量轉移比,并應用到要預測的時間上。
ST-image模型[20]一個基于深度學習的短時交通速度預測模型。該模型以圖片的2個維度分別表示空間和時間,以時空圖片作為輸入。
LSTM模型一種特殊的RNN模型,能夠學習長距離的時間依賴關系。這里在2組不同的參數上進行了實驗,即LSTM-12和LSTM-48。
DeepST模型[14]一個基于DNN的時空流量數據預測模型,對時間、空間和外部特征進行了協同建模,在城市范圍內的流量預測上取得了較好的性能。
ST-ResNet模型[13]相比于DeepST,在網絡中應用了殘差學習的思想,取得了相比于DeepST更好的預測效果。
與此同時,本文還研究了本文模型的各類變種的性能,具體如下。
本文模型變種1將臨近層的LSTM單元修改為一個全連接層,其余結構不變。
本文模型變種2將臨近層的輸入調整為多時間段的具有全局信息的流量圖,并將LSTM單元修改為同殘差網絡1和殘差網絡2同樣的結構,其余不變。
本文模型變種 3將景區距離圖嵌入模塊移除,最終的流量預測結果僅取決于時空模塊以及外部特征模塊的預測結果,來探究景區距離圖嵌入模塊的作用。
4.3 結果對比與分析
本節將通過與多組對比算法以及模型自身變種的性能比較,評估了本文提出的模型性能。考慮到景區在工作日和周末可能有明顯的流量差異,實驗分為工作日和周末兩部分進行,對比結果如表3所示。
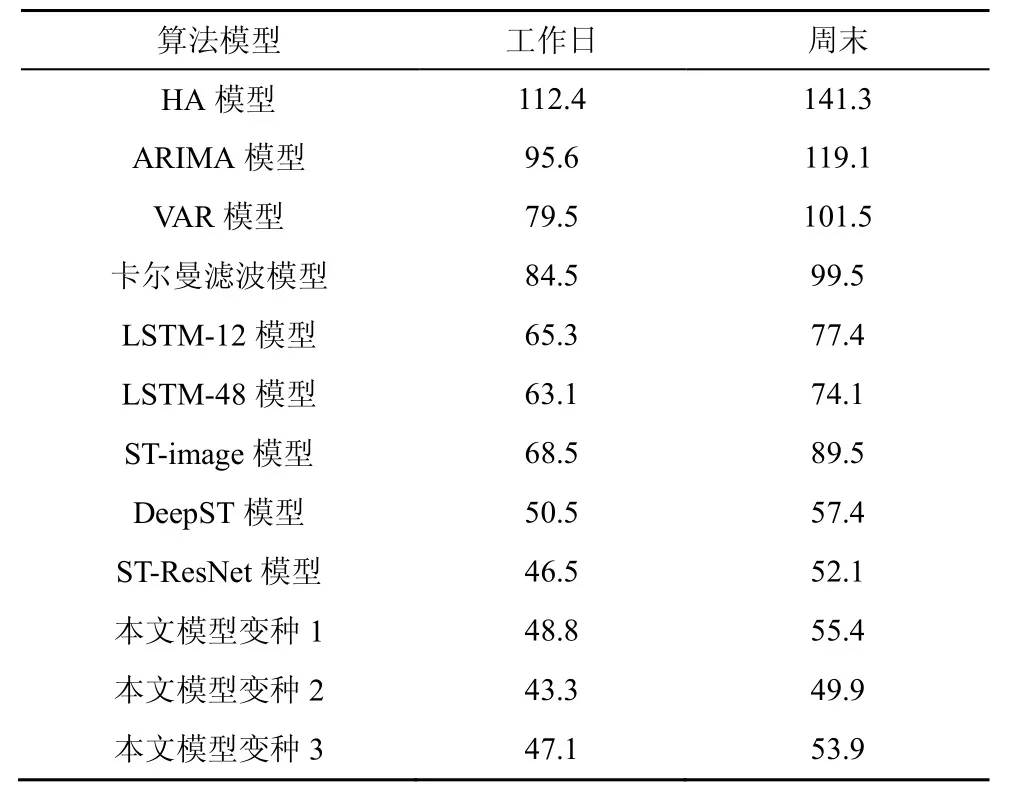
表3 不同模型的預測誤差(RMSE)的對比
本文將對比模型劃分為3類,即時間序列模型、時空深度學習模型、本文提出的模型及其變種。針對工作日的模式,從結果可以看出,本文提出的模型優于全部的時間序列預測模型,即使是相比于基于深度學習的LSTM模型,本文的模型也取得了28%~30%的性能提升,這充分說明了空間依賴關系在人群流量預測問題上的重要性;而相比于時空深度學習的對比模型,本文的模型依舊表現最佳,相比于 ST-image模型有接近34%的性能提升,即便是相比于利用所有時段的全局流量信息的DeepST模型和ST-ResNet模型,本文的模型也能得到 1%~10%的預測效果的提升,這說明在臨近層通過LSTM建模并結合景區距離圖的信息,可以實現對臨近時間全局信息的近似建模。也就是說,在不需要全局實時流量信息的情況下,依然可以取得良好的預測性能。
通過對本文模型得3個變種的分析可以看出,變種1性能相比于本文的模型下降約6%,證明了LSTM模型在臨近時間建模上的明顯優勢,因為其可以對較長間隔的時間依賴進行建模;變種2中將全局流量圖應用于臨近時間時,可以獲得4.6%的性能提升,證明了全局流量信息的價值;變種3則由于景區距離圖的移除,性能有所下降,說明景區距離圖的嵌入為景區流量預測提供了一定的支持。圖5直觀給出了各模型的性能排序結果。
針對周末的模式,從結果可以看出,其在預測誤差上都明顯大于工作日模式。對于結合了外部特征的模型,如本文模型、ST-ResNet模型、DeepST模型等,相比于工作日模式的誤差增加幅度較小,且在性能上明顯優于其他模型,證明了外部特征在流量預測問題中的巨大作用。而本文模型依舊在所有對比模型的表現最優。圖6直觀給出了各模型在周末模式的性能對比結果。
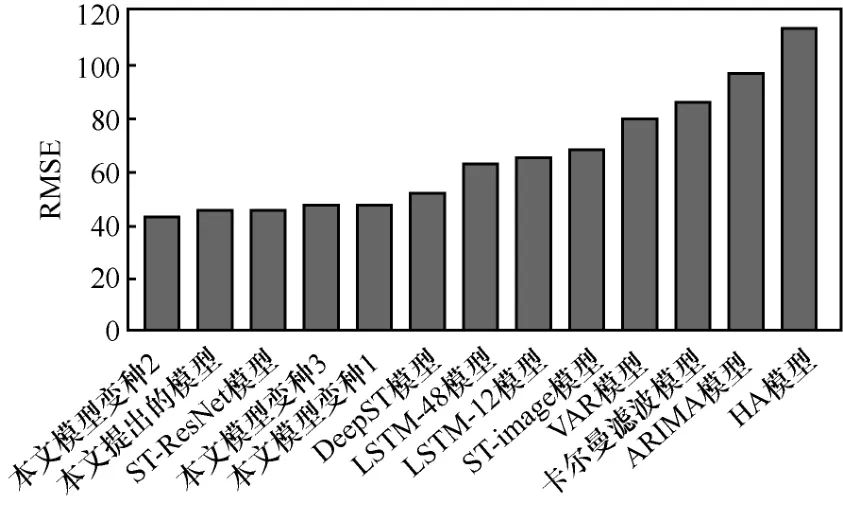
圖5 各模型測試結果對比(工作日)

圖6 各模型測試結果對比(周末)
4.4 參數分析
本文提出的模型在時間建模中選擇了 3組參數,分別是lc、lpr、ltr,表示不同時間層的取樣長度,即利用過去多長的時間來對未來的景區流量進行預測。下面分別調整3組參數的大小,來測試不同參數取值下的測試誤差RMSE。
首先測試lc的取值,將另外 2組參數固定為lpr=2、ltr=2,將lc的取值從2變化至8,RMSE的變化如圖7所示。從圖7可以看出,當lc=6時,預測性能最好,這說明預測的性能并不是隨著歷史數據的增多而不斷變好的,當增加到一定程度時,預測性能可能會變差。
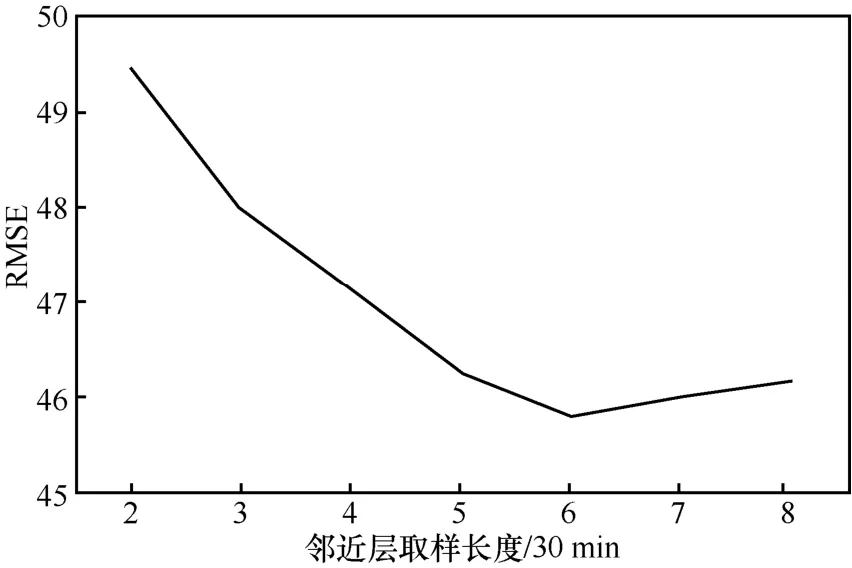
圖7 臨近參數lc的取值測試
然后測試lpr的取值,將另外 2組參數固定為lc=6,ltr=2,將lpr的取值從0變化至4,其中0表示不添加周期。RMSE變化如圖8所示。從圖8可以看出,當不添加周期層時,預測誤差明顯增大,證明了周期層數據的作用。而當lpr=2時,預測性能最優。

圖8 周期參數lpr的取值測試
最后,測試ltr的取值,將另外2組參數固定為lc=6、lpr=2,將ltr的取值從0變化至3,其中0表示不添加趨勢層。RMSE的變化如圖9所示。同樣地,不添加趨勢層時網絡性能最差,說明較長間隔的歷史時間也會給流量預測提供有價值的信息。對于參數ltr,當其取值為1時,預測誤差最小。綜合以上分析,選擇3組的取值為lc=6、lpr=2、ltr=2。
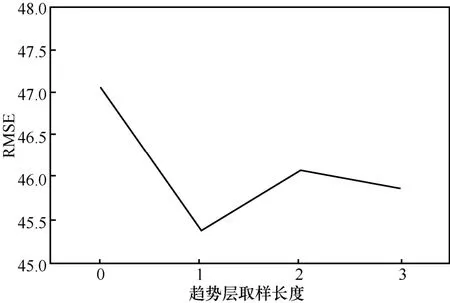
圖9 趨勢參數ltr的取值測試
5 結束語
5G網絡服務質量的保證,要基于其資源分配、緩存策略、能耗管理等諸多策略執行的優劣。而準確預測各區域用戶數量對提高 5G網絡這方面的性能具有重要意義。本文提出了一種移動網絡覆蓋范圍內的區域人群流量預測的深度時空網絡模型,通過融合各種外部特征信息,對不同尺度的時空依賴關系建模,對短時流量信息僅依賴于區域內局部實時信息,在降低對實時信息傳送需求的同時,也保障了預測的準確性。通過基于呼叫詳單數據進行的景區人群流量預測,驗證了本文提出的模型對工作日和周末的流量預測精度都比已有流量預測模型有顯著提升。在下一步工作中,可以將基站的人群流量預測應用于 5G網絡資源配置與流量分析的應用中。同時,隨著5G網絡基站大規模部署的開展,基于本文研究工作進行基站活躍/休眠的集群策略研究也將具有重要意義。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
核科學與工程(2015年4期)2015-09-26 11:59:03
電測與儀表(2015年5期)2015-04-09 11:30:52
