來華留學生課程作文用詞表現的階段性考察
2019-03-15 09:39:56張丁月唐興全
語文學刊 2019年1期
○ 張丁月 唐興全
(1.北京語言大學 人文社會科學學部,北京 100083;2.對外經濟貿易大學 中文學院,北京 100029)
近年來,計量語言學的發展推動了大量詞語領域的研究。隨著計算機技術的普及,各類統計方法與語言學現象的結合使定量分析方法走進語言學研究領域,彌補了定性分析的不足。目前對漢語教學領域的詞匯計量研究較多集中在教材詞匯分析、學習詞表的編制和詞匯產出統計等方面,涉及漢語作為第二語言學習者作文用詞的研究也主要考察學習者的詞匯偏誤及原因。黃立、錢旭菁、吳繼峰等對二語學習者漢語寫作中的詞匯豐富性的發展進行了研究[1][2];肖瀟、陳默、任揚等考察了二語學習者漢語口語中的詞匯豐富性發展情況。[3][4][5]但學界通過計量手段,對來華留學生在整個一學期內課程作文整體用詞表現與學習時長的關系進行的分階段考察研究較少。
因此,本文希望通過定量分析,從用詞豐富性、準確性兩個角度考察來華留學生一學期內在《漢語寫作》課程作文作業中的用詞表現,揭示學習時長與來華留學生作文用詞的內在規律,建立相關模型,為教師合理把握來華留學生寫作水平提供具體數據參考,并為教師開展漢語寫作課程教學提供相關建議。
一、概念界定
詞匯豐富性是學習者詞匯質量研究的重要指標。中外學者對它的概念也做出了界定。Nation & Webb 明確定義“詞匯豐富性是指文本中詞匯知識的質量”,可以測量詞匯運用的廣度和深度,是衡量口語或書面語整體水平的重要依據。[6]張艷、陳紀梁提出,詞匯豐富性就是指語言使用者在自由言語產出中使用詞匯的豐富程度。[7]中外研究者對詞匯豐富性概念的界定大體一致,在詞匯豐富性具體測量維度的劃分上雖存在爭議,但基本集中在“詞匯變化性、詞匯復雜性、詞匯密度、詞匯個別性、詞匯錯誤”等幾個維度。本文在詞匯豐富性的統計方面,主要依據的是不重復詞語(詞種)在作文中的比重,即:
詞匯豐富性=詞種數/詞語總數*100%
第二語言表達的準確性根據不同層次可分為詞匯準確性、句法準確性和語音準確性。對于準確性的度量,目前國內學界主要參照國外的做法,使用無錯T單位百分比和平均T單位長度來進行測量。本文主要關注詞匯準確性。由于國內目前對T單位的界定分歧較大,所以本文中主要采用詞匯偏誤數在作文用詞中所占的比重來測量,即:
詞匯偏誤率=用詞偏誤數/詞語總數*100%
二、研究對象與研究素材
(一)學習者信息
本文的研究對象為某大學經管類專業的一個班共17名來華留學生,學生屬性如下:

表1 《漢語寫作》課程學習者信息
(二)語料素材
1.語料來源。本研究所用語料全部為上述17名來華留學生本科生在大一下學期《漢語寫作》課上的課下作文。該課程開始時間為3月2日,因3月3日和3月7日同屬開學第一周,期間學生共寫作11篇作文,寫作間隔較小。為方便統計,將其合并為一組數據,學習時長記為3天。該學期的作文寫作可以分為以下七個學習階段:

表2 寫作課學習階段與時長
因為每個階段作文數量不一致,基本上在12-17篇,因此我們為保持一致,每階段隨機抽取10篇作文進行考察。
2.語料標注與處理。我們首先對七個階段70篇作文進行了格式規范化處理,然后對作文原文進行了詞匯偏誤標注。本次標注內容主要為詞語層面偏誤,主要包括:詞混淆、缺詞、缺詞素、詞多余、詞素多余、詞素順序錯誤、實詞詞序錯誤、虛詞詞序錯誤、生造詞、拼音詞、外文詞、離合詞錯用、詞重疊錯誤等。然后我們用北京理工大學張華平研制的ICTCLAS2015詞處理軟件對作文語料原文進行分詞與詞頻統計,用統計軟件Eviews 8.0構建回歸模型。
我們的研究思路如下:
①通過統計、分析作文所用詞種(不重復詞語)的數量,分析用詞豐富性。對比不同階段用詞信息差異、構建相關回歸模型,分析學生用詞豐富性的變化。
②通過統計、分析作文用詞偏誤數量、偏誤率,分析用詞準確性。對比不同階段用詞信息差異、構建相關回歸模型,分析學生用詞準確性的變化。
三、來華留學生課程作文用詞的豐富性分析
(一)學期各階段作文用詞量統計分析
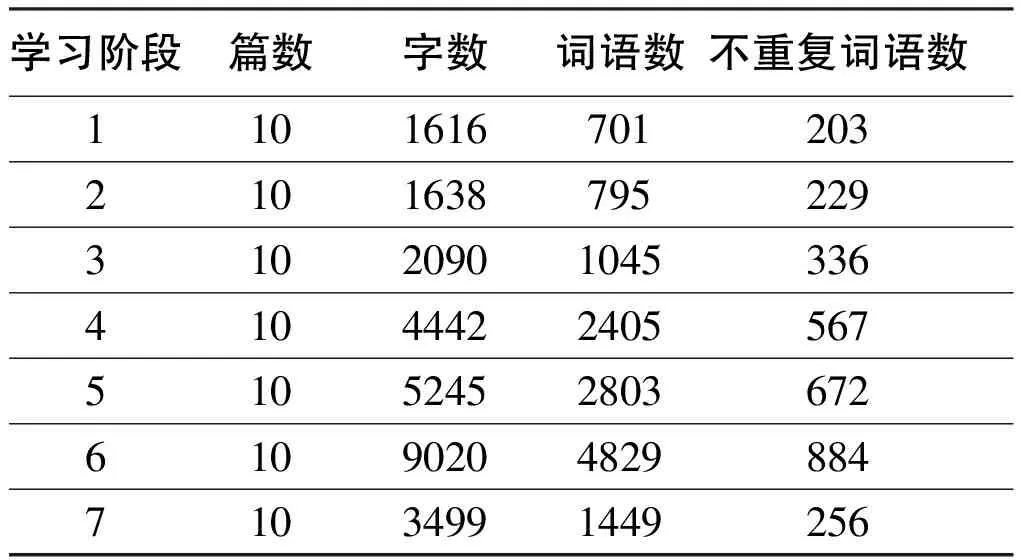
表3 學期各階段作文用詞量統計
因7月1日作文為期末考試作文,與學生其他時段的課下作文相比,寫作環境差異過大,因此本文暫不討論該階段作文表現。
(二)基于EViews的詞種數與學習時長相關性分析
(1)理論分析:在其他條件不變的情況下,隨著學習時間的延長,學生的語言水平會有所提高。在作文用詞豐富性上,表現為詞種數會增多,即學生掌握了更多樣復雜的詞匯。因此我們假設,詞種數與學習天數存在正相關關系。
(2)建立模型:Y=α1+α2X+μ,其中:Y為詞種數,X為學習天數,μ隨機擾動項。
(3)構建散點圖:
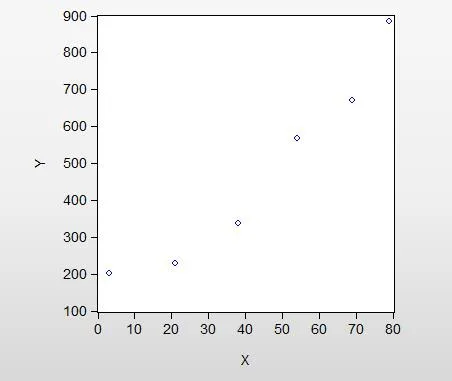
圖1 詞種數與學習時長相關性散點圖
由上圖可看出,隨X(學習天數)的增加,Y(不重復詞語數)增加,二者呈現正相關關系,符合初始假設。
(4)估計參數:利用EViews進行回歸分析,結果如下:Y=9.0095X+85.4139,t值=(7.0388)(1.2998),R2=0.92, F=49.5441。
(5)模型檢驗:
①擬合優度檢驗:
R2=0.92,說明模型整體上擬合很好,樣本回歸線能夠擬合、解釋92%的樣本數據。
②變量顯著性檢驗:
給定α=0.05,查t分布表[8],在自由度為n-2=4時臨界值為2.7764。其中,X的系數t=7.0388>2.7764,且其p值=0.0021<0.05,X通過顯著性檢驗,表明學習時長對不重復詞語數即用詞豐富性有顯著影響。
同理檢驗常數項C的t值,發現其p值=0.2635>0.005,且其t值未通過臨界值檢驗,因此常數項C未通過顯著性檢驗。
F檢驗衡量所有自變量對因變量的影響程度,該模型為一元模型,上述唯一自變量通過顯著性檢驗,即該模型通過F檢驗。
③實際意義檢驗:
上述結果表明,學習時長對用詞豐富性有顯著影響。根據統計結果,當學習時長每增加一天時,學生所掌握的不重復詞語數大約增加9個,這反映了該學期學生作文用詞豐富性隨學習時間而增加。
在變量檢驗時,模型方程常數項未通過顯著性檢驗,表明常數項不能很好地反映學生在進行學習前已掌握的基礎詞匯數量。因此我們不能利用該模型預測一定學習天數下的學生具體掌握的詞匯數量。這與學生個體基礎差異較大、每人起初掌握的詞匯數量不同有關。
四、來華留學生課程作文用詞的準確性分析
(一)學期各階段作文用詞偏誤率統計分析
隨著學習時間的增加,課程對學生的學習要求隨之提高,因此作文字詞數持續增加。而隨字詞數的增加,學生出現偏誤的數量往往也會增加。
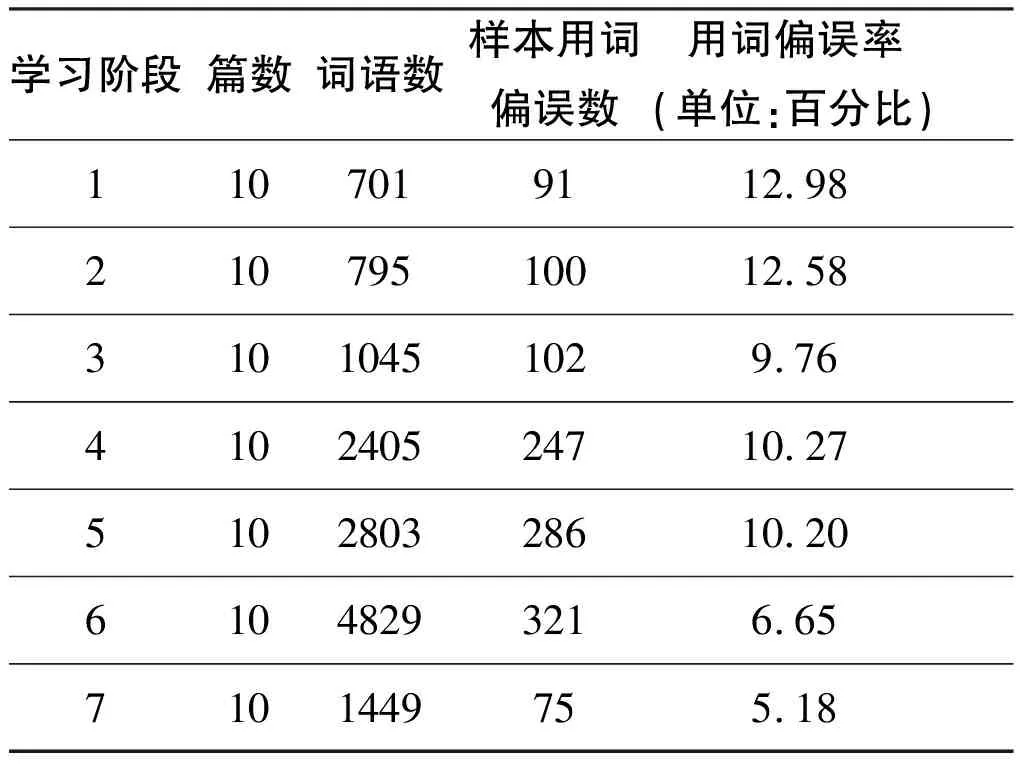
表4 學期各階段作文用詞偏誤率統計
這里我們暫不討論期末考試即第七階段的作文用詞表現。
(二)基于EViews的用詞偏誤率與學習時長相關性分析
(1)理論分析:在其他條件不變的情況下,隨著學習時間的延長,學生的語言水平會有所提高。在作文用詞準確性上,偏誤率會下降,即用詞準確性提高。因此我們假設,用詞偏誤率與學習天數存在負相關關系。
(2)建立模型:Y=β1+β2X+μ,其中:Y為偏誤數,X為學習天數,μ隨機擾動項。
(3)構建散點圖:
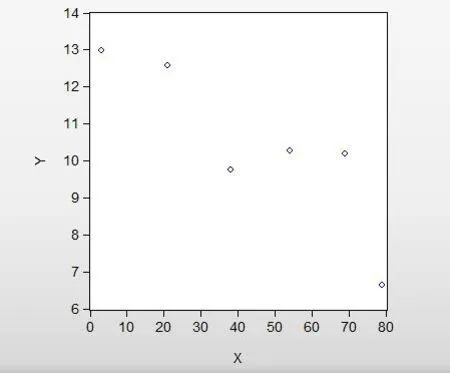
圖2 用詞偏誤率與學習時長相關性散點圖
由上圖可看出,除個別點外,隨學習天數X的增加,用詞偏誤率Y基本呈現階段下降的趨勢。二者基本呈現負相關關系,符合初始假設。
(4)估計參數:利用EViews進行回歸分析,結果如下:Y= -0.0690X + 13.4439,t值=(-3.6674)(13.9139),R2=0.77, F=13.4495。
(5)模型檢驗:
①擬合優度檢驗:
R2=0.77,說明模型整體上擬合較好,樣本回歸線能夠擬合、解釋77%的樣本數據。
②變量顯著性檢驗:
給定α=0.05,查t分布表,在自由度為n-2=4時臨界值為2.7764。其中,X的系數
│t│=3.6674>2.7764,且其p值=
0.0214<0.05,X通過顯著性檢驗,表明學習時長對偏誤率即用詞準確性有顯著影響。
同理檢驗常數項C的t值,C的│t│=13.9139>2.7764,其p值=0.0002<0.05,C通過顯著性檢驗。
F檢驗衡量所有自變量對因變量的影響程度,該模型為一元模型,上述唯一自變量通過顯著性檢驗,即該模型通過F檢驗。
③實際意義檢驗:
上述結果表明,學習時長對用詞準確性有較為顯著的影響。根據統計結果,當學習時長每增加一天時,學生作文用詞偏誤率約下降0.069個百分點,這反映了該學期學生作文用詞準確性隨學習時間而增加。同時,當學習天數為0時,回歸結果反映學生初始偏誤率為13.4439%。這是學生未開始本學期學習時,自身學習基礎的一個反映。此外,我們也可以利用該模型,大致預測一定學習天數下學生作文用詞偏誤率的數值。
五、研究結論及教學建議
通過統計分析,我們發現,隨著學習時長的增加,該班級留學生作文用詞表現如下:(一)在用詞豐富性方面,當學習時長每增加一天時,學生所掌握的不重復詞語數大約增加9個。(二)在用詞準確性方面,當學習時長每增加一天時,學生用詞偏誤率約下降0.069個百分點。在學習天數為0,即本學期開始時,本班級學生作文用詞初始偏誤率為13.4439%。以上兩方面都反映隨學生學習時長的增加,該班級學生作文水平有所提高。
此外,除以上兩方面,字數、詞語數的增加反映了課程對學生寫作要求的提高,一定程度也能反映學生寫作水平的提高。
因此,漢語寫作課教師在實際授課過程中,可以制定合適的寫作練習頻率,保證留學生得到充分、連續的寫作練習。
本次研究中,我們側重分析習得過程中學習時長對留學生作文用詞的影響。整體上只關注了其用詞豐富性中的不充分詞語數量和準確性中的偏誤率,側重數量上的分析,而沒有分析其具體表現,諸如作文中的用詞等級、偏誤種類等仍需要繼續細分、量化研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
作文評點報·小學五、六年級(2017年19期)2017-05-23 20:14:53
作文評點報·低幼版(2017年19期)2017-05-23 14:48:28
作文評點報·高中版(2017年15期)2017-04-15 18:54:11
作文評點報·高中版(2017年13期)2017-04-15 17:58:45
