NDN中一種基于節點的攻擊檢測與防御機制
2019-03-17 09:36:34趙雪峰王興偉易波黃敏
網絡空間安全 2019年9期
趙雪峰 王興偉 易波 黃敏
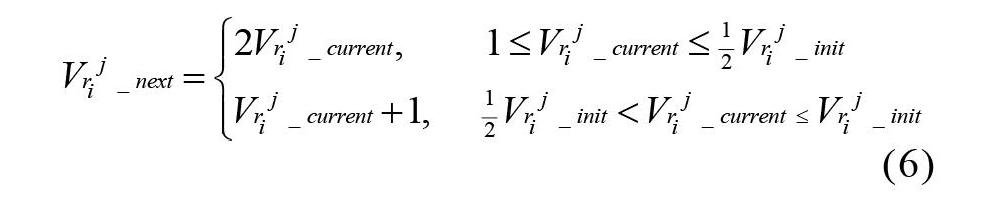
摘? ?要:為了解決命名數據網絡(Named Data Networking,NDN)中由興趣洪泛攻擊(Interest Flooding Attack,IFA)導致的資源浪費和服務安全等問題,文章根據IFA發生時NDN網絡流量的特征提出了針對分布式低速率攻擊的基于節點的檢測與防御機制,將其部署在可能受攻擊影響最大的網絡中心節點。首先設計了異常檢測觸發機制以減少傳統周期性檢測帶來的資源浪費;其次攻擊檢測部分通過選取重要特征屬性、計算信息熵以及利用K均值聚類算法訓練好的模型檢測異常點,避免了攻擊檢測的滯后性;最后通過概率替換的方法和“緩解-阻斷”的方式對IFA進行防御,準確識別并刪除惡意興趣請求,快速恢復被攻擊節點的服務功能,并從源頭阻斷后續IFA攻擊。
關鍵詞:命名數據網絡;興趣洪泛攻擊;信息熵;K均值聚類
中圖分類號:TP393.0? ? ? ? ? 文獻標識碼:A
Abstract: In order to solve the problems of resource waste and service security caused by Interest Flooding Attack (IFA) in Named Data Networking (NDN), this paper proposes a node-based detection and defense mechanism of distributed low-rate attacks based on the characteristics of NDN network traffic when IFA occurs, and deploys it in the network center node which may be most affected by attack. Firstly, the anomaly detection trigger mechanism is designed to reduce the waste of resources caused by traditional periodic detection. Secondly, the attack detection part includes selecting the important feature attributes, calculating the information entropy and using the K-means clustering algorithm to detect the abnormal points, which avoids the lag of the attack detection. Finally, the method of probability substitution and the "mitigation-blocking" are used to defend the IFA, it identifies and deletes the malicious interest requests accurately, restores the service function of the attacked node quickly, and blocks the follow-up IFA attacks from the source.
Key words: named data network; interest flooding attack; information entropy; K-means clustering
1 引言
隨著互聯網用戶和數據的爆炸式增長以及互聯網主要職能的轉變[1],以內容為中心的網絡應用逐漸增多[2],相對于信息的存儲位置而言,用戶更加關心信息的內容本身[3]。與此同時,命名數據網絡(Named Data Networking,NDN)架構的成熟,使得基于NDN的各項研究也不斷地引起大家的廣泛關注。在安全方面,其屏蔽了傳統網絡下的拒絕服務攻擊(Denial of Service, DoS)的同時,卻引入了新型的安全問題興趣洪泛攻擊[5],其是針對NDN中包轉發機制存在的安全漏洞進行攻擊。
目前,關于興趣洪泛攻擊(Interest Flooding Attack,IFA)的檢測與防御問題已經引起學術界的廣泛關注,陸續出現了相關的解決方案,但是在準確識別,快速防御等方面仍有待改進。首先,當前研究中大多數對IFA的檢測主要是基于路由器節點的PIT異常狀態進行統計分析判斷,該類檢測方案具有滯后性。其次,目前的方案可能容易對正常流量波動過度反應,比如當有突發的正常流量時,也會對PIT表的統計特征造成影響。再者,目前幾乎所有的方案都是針對網絡中所有的節點進行檢測,不具有針對性,檢測粒度有待優化。基于上述原因,IFA的應對機制仍具有進一步研究的意義。
此外,目前的方案中很少研究如何準確識別惡意興趣請求,這在后續的防御效果中有著至關重要的作用,精確的識別可在一定程度上減少對正常突發流量的誤判以及更好的進行攻擊防御,這一部分也迫切需要進行進一步的研究。
針對目前IFA攻擊面臨的問題挑戰[6]以及一些解決方案所存在的如檢測滯后性、檢測粒度不具有針對性、資源浪費等問題,本文選擇分布式低速率攻擊,在網絡中心節點設計并部署了一種基于節點的檢測與防御機制,減少了周期性檢測帶來的資源浪費問題,避免了滯后性問題,并且能夠準確識別惡意興趣請求,從源頭阻斷IFA攻擊,以快速恢復被攻擊節點的服務功能。具體研究工作主要包括設計了以下機制:異常檢測觸發機制、基于信息熵和K均值聚類的攻擊檢測機制、基于概率替換的惡意興趣請求識別機制、“緩解-阻斷”防御機制,并對所提機制進行仿真實現以及性能評價。
2 興趣洪泛攻擊原理
NDN中的興趣包基于內容名稱前綴進行路由,并通過內容名稱獲取數據,因此攻擊者無法輕易地直接針對特定中間節點或者終端發起攻擊。但是,攻擊者可以針對特定的命名空間發起攻擊,在興趣包尋路過程中造成網絡中間節點拒絕服務[7]。IFA正是一種針對特定命名空間發起攻擊的方式。
IFA基本工作原理如圖1所示。如果內容提供者是“/Root/good”命名空間的獨占所有者,則路由器B和內容提供者都將收到“/Root/good/ ...”的所有興趣,且無法被網內緩存滿足。大量此類惡意興趣通過造成網絡擁塞或耗盡路由器節點上的資源造成合法興趣請求和數據包丟包,從而破壞網絡整體的服務質量。而且,由于NDN中的興趣包既不攜帶源地址也不需進行簽名認證,很難立刻確定攻擊源并采取相應的應對措施,因此會對網絡造成非常大的攻擊力和破壞力[8]。
IFA將會造成網絡服務質量下降甚至是網絡服務癱瘓,其有兩種主要原因。第一,與傳統網絡中的數據包類似,NDN中的興趣包也會消耗一部分網絡容量。因為NDN中的路由基于名稱前綴,通過針對一個特定的命名空間可將大量攻擊流量集中在網絡的某些段中,大量惡意興趣包可能會導致擁塞并導致合法興趣包被丟棄,影響網絡服務性能。第二,由于NDN路由器維護每個轉發興趣的每個數據包狀態,即其存儲在未決興趣請求表(Pending Interesting Table,PIT)中的信息,過多的惡意興趣請求可能造成節點的內存被耗盡,從而使得該節點無法繼續為傳入的興趣請求創建新的PIT條目,導致合法興趣包被丟棄,影響為合法用戶提供網絡服務。
3 基于節點的攻擊檢測與防御機制
本文基于節點的IFA攻擊檢測與防御機制主要是針對分布式低速率的興趣洪泛攻擊情形。在這種攻擊情形下,由于流量的匯聚,靠近內容提供者或者中心位置的網絡節點的PIT條目數增長迅速,最先使得PIT緩存溢出,從而造成中心節點拒絕服務,造成合法興趣請求丟包,影響巨大。
本節首先分別介紹了該機制包含的四大模塊即異常檢測觸發、基于信息熵和K-means聚類算法的攻擊檢測、惡意興趣請求的識別以及攻擊防御。該方案的具體實現過程有四個步驟。
(1) 首先通過監控PIT的占用率來觸發攻擊檢測。
(2) 一旦IFA檢測觸發,則計算PIT屬性內容名稱前綴、入口編號和興趣請求條目的被訪問頻次的信息熵值,輸入到已經訓練好的分類器中,進行異常點識別。
(3) 利用概率替換方法識別出具體的惡意興趣請求前綴,通過分析攻擊流量的特征篩選特征屬性的值,識別出具體的惡意興趣請求條目。
(4) 當檢測出具體條目后,立即刪除并生成與其具有相同內容名稱的報警數據包,該報警數據包將回溯到攻擊者終端,沿路限制接口速率阻斷攻擊。
本文根據NDN中包處理機制,結合本文提出的方案,設計了基于節點的IFA檢測與防御機制下的包處理流程。
3.1 異常檢測觸發機制
為了避免現有方案中周期性收集PIT表項時間間隔太短和太長帶來的大量計算資源消耗和檢測滯后問題,在對PIT表項進行收集并檢測之前應添加異常檢測觸發機制,當滿足檢測觸發條件時才收集PIT條目進行分析檢測。而且,這種觸發機制應該滿足易檢測并且容易實施的條件,盡量減少路由器節點的負擔。
IFA最顯著的影響就是占用路由器節點大量的PIT緩存資源,造成PIT溢出,此觀點已有多篇文獻指出并驗證,故本文采用PIT條目占用率作為異常觸發的指標,PIT占用率的計算如公式(1)所示。其中表示PIT條目的占用率,用于表示其閾值。表示PIT現有的PIT條目數,表示PIT中可緩存的條目總數。
(1)
3.2基于信息熵和K-means聚類的攻擊檢測機制
本節詳細介紹了基于節點流量統計的IFA攻擊檢測機制的設計。首先,分析了特征選擇、信息熵的引入和計算。其次,通過實驗數據驗證了引入信息熵進行處理的合理性和可行性,并且利用K-means算法對原始數據進行多次迭代訓練,得到攻擊檢測的分類器模型。最后,將進行多組實驗對比得到的分類器模型進行檢驗和分析,并且對基于信息熵和K-means聚類算法的IFA檢測方案的優勢、缺陷以及產生的原因進行分析與說明。
(1)特征屬性選擇
IFA發生時,惡意興趣請求填滿PIT,此時,PIT中的條目分布必然呈現出異常狀態,因此本文涉及的屬性主要指PIT表項中的各屬性值。PIT是用于記錄已從該節點轉發出去但還未獲得數據響應的興趣包的入口接口等屬性的集合。
由于針對不存在的內容進行攻擊時,攻擊者可利用完全偽造的內容名稱,也可利用前綴合法后綴隨機的內容名稱,這將導致PIT中內容名稱項的隨機性增加。與此同時,惡意興趣請求大都來源于特定的某些端口,使得PIT中各條目的入口分布變得集中。再者,PIT中興趣請求條目的匹配次數幾乎都為1,因為攻擊發生時,PIT中充斥大量的惡意興趣請求,根據惡意興趣請求的唯一性,該請求條目大多只被訪問并匹配一次。綜上所述,本文選擇內容名稱、入口以及PIT條目的匹配次數三個屬性作為后文聚類分析的特征屬性。
(2)信息熵的計算
本文的聚類算法主要是分析IFA發生前和發生后PIT條目各屬性的變化趨勢,而非PIT條目各屬性的內容值。本文引入已被廣泛應用在異常檢測[9-12]的信息熵表征流量變化趨勢,這有利于從根本上反應IFA對網絡的影響。而且,本文所采用的K-means算法更適用于數值型數據,引入信息熵將各類型數據轉化為數值型,這有利于提升IFA檢測的準確率,下文首先對信息熵計算進行介紹,然后從信息熵的角度,通過實驗數據分析以上三個屬性在攻擊前后的熵值變化情況,以論證方案的可行性。
給定一個集合X=(X1, X2,… XN),表示采集的PIT中各個特征屬性下的內容數據的集合。每個屬性中包含個類,表示屬性中類的概率,其中,,, 則信息熵的定義如公式(2)所示。本文實驗中,每100條PIT條目計算一次熵值。
(2)
以上三個特征屬性即內容名稱、入口以及PIT條目的匹配次數的信息熵計算如公式(2)所示,其中概率計算公式如式(3)所示,表示PIT中一組興趣請求條目的總數,本文將該值設為100, 表示具有某相同特征屬性的興趣請求條目的數量。
(3)
內容名稱前綴屬性:IFA發生前,因為PIT中內容名稱前綴分布相對均勻,隨機性較高,熵值較高。當IFA發生時,攻擊者短時間內發送大量內容名稱前綴相同且后綴為隨機產生的字符串的惡意興趣請求。惡意興趣請求的注入使得內容名稱前綴的分布突然變得集中,不確定性下降,相應地信息熵急劇下降。此外,如果攻擊者發送大量含有完全偽造的內容名稱的惡意興趣請求時,此時的內容名稱前綴分布更加隨機。相比攻擊前來說,不確定性上升,相應地信息熵將急速上升。也就是說,不論以任何一種方式發起攻擊,熵值的突變是必然的,而本文所需要的也只是熵值突變帶來的差異而不是依賴具體的熵值大小。因此,不論熵值急速上升亦或是下降本文的方案均可適用。
如圖2所示,為內容名稱前綴信息熵的變化。圖中0-100s以及200-300s沒有攻擊,200-300s發起興趣洪泛攻擊,惡意Interest的內容名稱采用的是內容名稱前綴合法而后綴為偽造的隨機字符串。由圖1可知,在100-200s之間發生攻擊時,PIT內容名稱前綴的熵值的確迅速降低,而且,在攻擊期間都維持在較低值。
入口屬性:當IFA攻擊發生時,對于每個節點而言,如果假設接口一定,惡意興趣請求的入口id一致,此時入口的隨機性較低,信息熵值較低;如果假設接口數量不一定,即發生攻擊后,惡意興趣請求可能來自多個全新的接口,入口屬性的隨機性較高,信息熵值增大。本文更多關注的是熵值變化引起的熵值檢測點之間的差異性,而非依賴具體的信息熵值的大小。此外,本文假設對每個內容名稱前綴所采取的轉發和路由策略一致,則出口和入口屬性值的分布一致,熵值變化一致,所以,本文只討論入口屬性的熵值變化。
如圖3所示,在接口數量不一定的情況下,IFA攻擊前后入口屬性信息熵值的變化情況由圖可得,在100-200s期間發生IFA攻擊時,信息熵值直線上升,并且,在攻擊期間,熵值一直處于較高水平。
匹配次數屬性:由于惡意興趣請求是唯一的,故惡意興趣請求記錄在PIT條目后將只被訪問一次,而合法的興趣請求條目可能被不同的合法用戶多次訪問。因此,當發生攻擊時,大量惡意興趣請求條目緩存在PIT中,導致大多是PIT條目的匹配次數屬性值為1,這將導致匹配次數屬性值隨機性會迅速下降,信息熵值也因此迅速減小,并且,在攻擊期間信息熵值一直維持在較低水平。
如圖4所示,為PIT中匹配次數屬性的信息熵值的變化趨勢。當發生IFA攻擊時,熵值迅速下降,在100-200s攻擊期間,熵值維持在較低值。
綜上,可分別計算出一段時間內三個屬性的信息熵值、和,表示為點,下一步的K-means聚類檢測分析將針對這些熵值點進行異常檢測分析。
(3)K-means聚類檢測分析
本文實驗模擬了300s,其中100-200s為攻擊發生時間。首先收集了各個特征屬性下的PIT條目,然后對每100條條目進行信息熵的計算,生成一系列熵值點 ,由于在發生攻擊時,三個屬性的信息熵值均發生明顯變化,通過三個特征屬性的相互作用,發生攻擊時和沒有攻擊時的熵值點差異較大。經過信息熵值處理的原始數據可明顯分為兩類,數據簇呈凸型分布且距離特征明顯,非常符合K-means應用條件。
基于K-means聚類檢測的原理是通過對原始數據進行訓練得到分類器。在實際檢測中,當異常檢測觸發后,收集PIT表項,計算熵值點并輸入到分類器模型中進行異常檢測。在訓練與檢測時,通過歐幾里得距離判斷熵值點之間的相似性。假設被檢測點為 ,簇心為 ,則可通過兩點之間的歐幾里得距離判定點 是否歸為點 所在的簇,歐幾里得計算如公式(4)所示。為了訓練得到可靠的分類器模型,本文收集Node1上的流量數據迭代1000次進行K-means聚類。
(4)
通過分析攻擊前后PIT屬性值的變化規律,對PIT條目進行信息熵值的處理以及利用K-means對數據進行熵值聚類的效果較為理想,雖然仍然存在一些離散點,但是離散點數量很小,這些離散點的存在可能是因為在攻擊前期PIT屬性值的分布特征不明顯或者某一時刻惡意請求超時刪除所致。
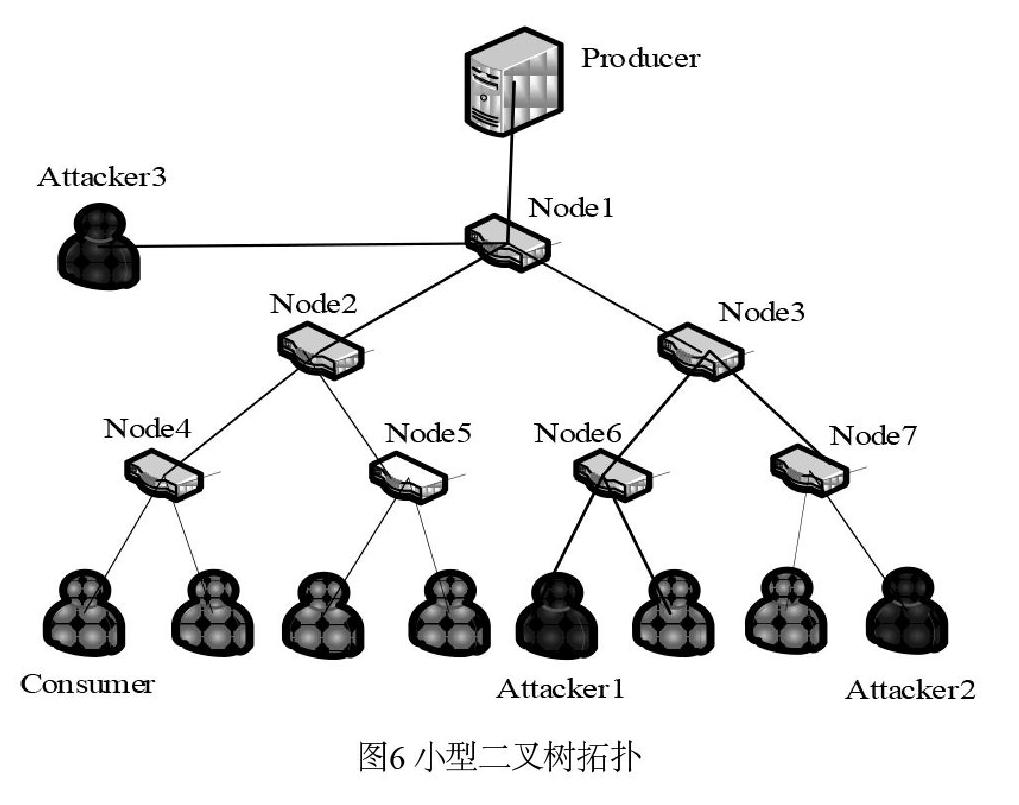
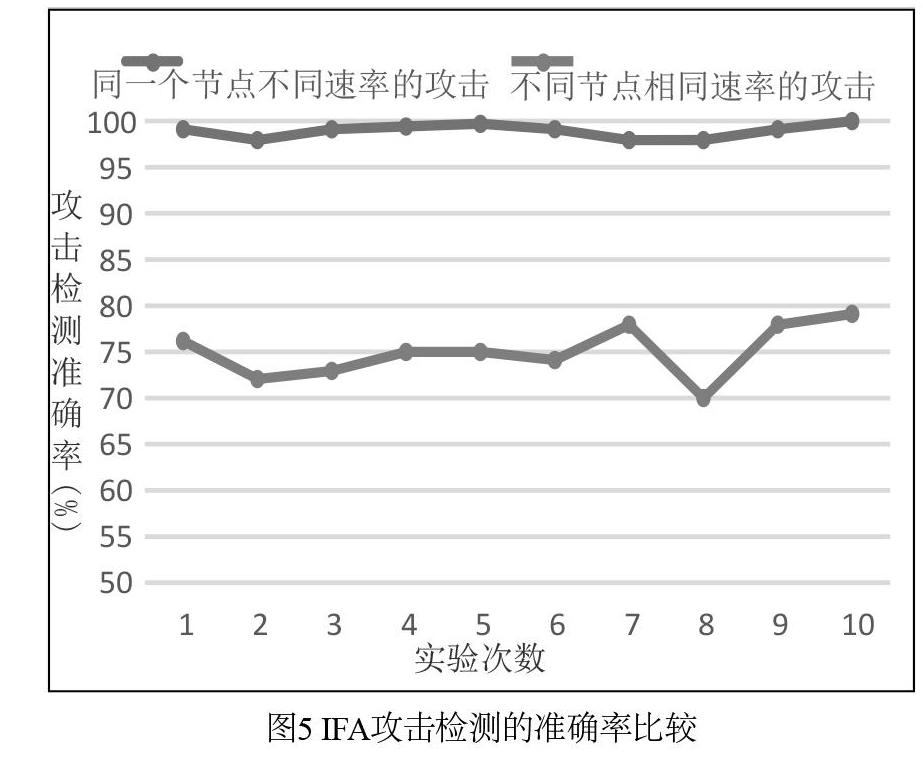
此外,為驗證模型的可靠性和應用廣泛性,本文進行了兩組對比實驗。對比實驗一:調整攻擊者和消費者的發送速率且仍在Node1上部署檢測方案。對比實驗二:在不同節點上(本文實驗采用圖6拓撲中節點Node3中的流量數據)部署檢測方案。每組對比實驗分別進行10次實驗,統計兩組不同方式下的攻擊檢測準確率,檢測結果如圖5所示。其中,對比實驗1的結果如圖中上方曲線所示,對于同一個節點,改變攻擊速率,利用得到的模型進行攻擊檢測,效果較好,根據MCR參數統計,檢測準確率基本分布在99%左右;對比實驗2的結果如圖中下方曲線所示,攻擊檢測的準確率較低,檢測準確率主要分布在72%左右。
為了尋找上述結果產生的原因,本文多次收集了Node3上的流量數據進行分析并訓練得到分類器模型。分析發現不同節點上的熵值變化一致,均可根據熵值差異在該節點高準確率的檢測出IFA,但是,同樣地,該分類器模型并不適用于Node1。根據Node1和Node3中統計的熵值的分析得出造成上述結果的原因:雖然相對于一類節點而言,攻擊前后熵值變化明顯,但是每一個PIT特征屬性下的類別多樣性不同(如:中心節點內容名稱前綴的類別可能較多,而邊緣節點的內容名稱前綴的類別可能就較少)造成了信息熵值量級的不同。但是,這也是由于實驗規模的限制造成了節點之間的差異性,在真實網路環境中,隨著網絡規模的增大,流量數據的多樣性增加,這種差異性將會減小。
3.3 惡意興趣請求識別機制
需要注意的是,為了針對特定命名空間發起有效的攻擊,攻擊者發布的興趣請求需滿足兩個條件。
一是發起的興趣請求應盡可能地傳遞給生產者,而不是被網內緩存滿足。這要求興趣請求不能被中間路由器的網內緩存滿足,因為如果興趣請求可以從中間路由器的內容存儲區滿足,則被請求的內容從中間路由器返回給請求者,興趣包將不向上游轉發興趣請求,無法發生IFA。
二是保證每個惡意興趣請求都能創建一條新的PIT條目,并保證其以盡可能長的時間存儲在中間節點的PIT中。這要求每個惡意興趣包請求唯一的且相互不同的內容信息,否則所有請求相同內容的興趣請求將在節點被聚合成一個PIT條目,無法發生IFA。
考慮到以上必須滿足的條件,攻擊者必須請求流行度較低的(即未在路由器中緩存)或不存在的唯一內容,這兩種情形的實現難易程度不同,前者維持一段持續的大規模IFA攻擊難于實現,故本文專注于第二種影響范圍廣且易于發起的IFA攻擊模式,并且選擇內容名稱前綴合法而后綴隨機的形式進行攻擊實現,因為它不僅最大化了攻擊的影響,而且易于發起并廣泛適用于針對所有命名空間的攻擊。
以下將針對檢測到的IFA進行惡意興趣請求識別,首先基于信息熵識別出惡意的興趣請求前綴,然后從中進一步的識別惡意請求條目。
(1)識別惡意興趣請求前綴
一旦基于信息熵的檢測機制檢測到IFA,將觸發基于信息熵的惡意興趣請求識別過程以保護合法流量不受影響,因此,本文NDN路由器記錄幾個連續時間間隔的興趣請求前綴分布,以便分析識別惡意興趣請求前綴。當觸發惡意興趣請求識別機制時,分別在集合S1和S2中記錄檢測到攻擊時和攻擊發生之前PIT中的興趣前綴。計算S1和S2中每個興趣前綴i的概率,分別表示為P1(i)和P2(i)。首先利用P2(i)計算H(S2)。然后,對于S2中的每個興趣前綴i,通過用P1(i)代替其概率P2(i),得到新的概率分布P2,從而得到新的信息熵表示為Hi(S2)。之后,使用公式(5)來計算興趣請求內容名稱前綴i引起的信息熵變化。
(5)
通過迭代每個前綴,可以獲得一系列的 。由于惡意興趣請求前綴的注入使得S2中原始前綴的分布更加集中,因此加入了新前綴的原始集合的信息熵值將會變小。綜上所述,使得 成立的前綴被認為是惡意前綴。
(2)識別惡意興趣請求條目
為了后續攻擊防御時生成偽造的報警數據包Data,需知道惡意興趣請求的內容名稱。但是,當檢測出惡意興趣請求前綴后并不能確定惡意興趣請求條目,因為本文的IFA場景是利用合法的興趣請求前綴和偽造的隨機后綴字符串發起攻擊,所以在檢測出的惡意興趣請求前綴中可能混合了合法的興趣請求,因此,為了避免對合法興趣請求的過度防御,必須篩除合法的興趣請求。因此,我們必須在識別出的惡意前綴的基礎上做進一步的篩選。
據此,本文同樣利用PIT條目屬性的分布特征來解決這一問題。惡意興趣請求條目的匹配次數屬性均為1,而合法興趣請求因為可能有不同用戶請求相同的內容,該值可能不為1。根據這一特性,本文通過篩選匹配次數的值來排除大部分的合法興趣請求,即若PIT條目的匹配次數為1,則為惡意興趣請求,否則為合法興趣請求。在此,需要提到的是對于一些冷門或者一次性的內容如郵件,雖然其匹配次數屬性也為1,但對于不帶惡意前綴的條目則在第一步驟可能就被篩選過了,不會進入此步。對于此種特殊情況,也可能會存在部分誤判。
3.4 基于節點的攻擊防御機制
基于節點的IFA防御機制的主要思想“緩解-阻斷”。其中,緩解的主要目的是當發生IFA后,及時識別出惡意興趣請求條目并刪除,以迅速恢復網絡中的節點功能,阻斷的主要目的是切斷攻擊源,從根本上阻斷后續攻擊,其通過偽造報警包回溯攻擊者實現。
根據NDN中對稱路由的特性,偽造的報警包會按照惡意興趣請求的路徑原路返回,追溯到攻擊者。當偽造的Data到達中間路由器時,將刪除PIT中與其匹配的大量惡意請求,及時恢復網絡功能。同時,根據傳統網絡中擁塞控制的思想,調整出口的速率,限制惡意興趣請求繼續轉發擴散。
當定位到具體的被攻擊接口后,引入傳統TCP/IP網絡中控制網絡擁塞的加性增乘性減(Additive Increase Multiplicative Decrease,AIMD)思想進行接口速率限制。假設路由器節點i的接口j的初始速率為,當檢測到攻擊時,將接口接收速率迅速減少為1,然后如公式(6)的上半部分所示,隨著時間的推移,接口的速率按指數規律增長即速度值依次為1、2、4、8等。當速率達到初始速率的一半時,如公式(6)的下半部分所示,接口的接收速率按“加性”增長進行加一操作,直至接口的速率恢復到初始速率。
(6)
3.5 算法描述
由于在NDN中,只支持興趣包和數據包兩類報文,數據的傳送過程首先由消費者發送興趣包,然后數據包沿著相反的方向、相同的路徑返回,其轉發機制相對IP網絡是智能轉發,弱化了路由作用。
因此本文將所提出的基于節點的攻擊檢測和防御方案應用在NDN中智能的包轉發機制上,設計了基于節點的IFA檢測與防御機制下的包轉發和處理過程。該過程涉及到對合法興趣包、惡意興趣包、合法數據包以及報警數據包的處理,在對各個包的處理過程中包含了本文基于節點的攻擊檢測與防御機制的具體策略。算法3.1為在包轉發和處理過程中基于節點的攻擊檢測機制,包含了異常觸發機制、攻擊檢測機制、惡意興趣請求識別機制,算法3.2為基于節點的攻擊防御機制。
基于節點的IFA檢測與防御機制下的包轉發和處理過程如下:
(1)節點判斷接收報文并判斷是否是興趣請求包。若是,則轉向對興趣包的處理。即首先查看CS表中是否有對應的內容信息,若存在,則興趣包是合法的,直接將內容信息返回給消費者;若不存在,則查PIT中是否有與之相對應的條目,若有,則需要將入口添加到對應的PIT條目的入口列表中,防止興趣包的重復發送,否則插入新PIT條目,并更新PIT占用率。當PIT占用率 超過閾值時,執行攻擊檢測機制,包括數據篩選、信息熵的計算、以及異常點的判斷。如果通過分類器模型檢測到異常點,則進一步執行惡意興趣請求前綴的識別并篩選出惡意PIT請求條目,從而執行算法3.2的攻擊防御策略。
(2)若不是,則轉向對數據包的處理,即接收該數據包的數據并查找PIT表,若在PIT中未找到匹配的條目,則將數據包作為重復數據包而丟棄。如果匹配條目中列出了多個接口,首先判斷是否是用于攻擊防御的偽造的數據包,若不是,則作為合法的數據包進行處理,若是,則轉向步驟(3)對偽造的報警數據包的處理。
(3)由于偽造的報警數據包的內容名稱字段和惡意興趣請求的內容名稱相同,則將其作為惡意興趣包按照算法3.2進行處理。
算法3.1 基于節點的攻擊檢測算法
輸入: 節點接收的報文 msg ;
輸出: 得到統計信息, 如PIT條目中出/入興趣包、出/入數據包、丟棄的興趣包數量;
1. 初始化Ρ;? ? // Ρ為閾值
2. IF msg 是興趣請求包 THEN
3. ? ? IF CS表中存在對應的內容信息
4. ? ? 興趣包合法,直接將內容信息返回給消費者;
5. ? ? ELSE
6. ? ? IF 查找PIT中有對應的條目? ?THEN
7. ? ? ? ?將入口添加到對應的PIT條目的入口列表中;
8. ? ? ELSE
9. ? ? ? 插入新PIT條目;
10. ? ? ? 根據公式(1)計算并更新PIT占用率ρ;
11. ? ? ? IF ρ>Р THEN? ?//PIT占用率超過閾值
12. ? ? ? ?篩選PIT條目的特征屬性數據;
13. ? ? ? ? 根據公式(2)(3)計算信息熵記為 (x1,y1,z1);
14. ? ? ? ? 輸入(x1,y1,z1) 到訓練好的用于異常點檢測的? ? ?分類器中;
15. ? ? ? ? IF (x1,y1,z1) 屬于異常點 THEN
16. ? ? ? ? 得到,并據公式(2)計算熵值 ? ? ? ,;
17. ? ? ? ? ?;
18. ? ? ? ? ? IF? ?THEN
19. ? ? ? ? ? ? ? 得到惡意前綴i ;
20. ? ? ? ? ? ? ? IF 前綴i 的PIT條目的匹配次數屬性? ? ? ? ? ? ? ? ?為1? THEN
21. ? ? ? ? ? ? ? ?識別為惡意興趣請求;
22. ? ? ? ? ? ? ? ?惡意興趣請求條目作為輸入執行算 ? ? ? 法3.2;
23. ? ? ? ? ? ? END IF
24. ? ? ? ? ? ?END IF
25. ? ? ? ? ? END IF
26. ? ? ? ? END IF
27. ? ? ? END IF
28. ? ? END IF
29. ELSE IF msg 是合法數據包THEN
30. ? ? 接收該數據包的數據并查找PIT表;
31. ? ? IF PIT中有請求該數據的興趣請求 THEN
32. ? ? ? ? CS 中緩存數據信息;
33. ? ? ? ? 找到PIT中對應的興趣請求入口,將數據從該 ? ? ? ? 接口轉發給消費者;
34. ? ? ELSE
35. ? ? ? ? 丟棄數據包;
36. ? ? END IF
37. END IF
38. ELSE IF msg 是報警數據包
39. ? ? 提取報警數據包的內容名稱;
40. ? ? FOR PIT中的每個條目 Do
41. ? ? ? IF 報警數據包的內容名稱匹配用于攻擊防御 ? ? ? ? ? ? ? ? ? ? ?的偽造數據包的內容名稱 THEN
42. ? ? ? ? 報警數據包的條目信息作為輸入執行算法3.2;
43. ? ? ? END IF
44. ? ? END FOR
45. END IF
算法3.2 基于節點的攻擊防御算法
輸入:惡意興趣請求條目的信息;
1. 初始化 Δt, Flag[];? //Δt表示執行限速策略時速率的調整周期,Flag[]用于標記接口是否正處于防御狀態
2. 獲取惡意興趣請求的內容名稱以作為報警數據包的內容名稱字段;
3. 獲取惡意興趣請求條目入口列表中的入口編號i;
4. 向接口 i 返回報警數據包回溯攻擊者;
5. IF? THEN? //不在防御狀態,執行限速策略
6. ;
7. ? ? 將接口速度迅速減為1
8. ? ? FOR 每個調整周期 Δt? Do
9. ? ? ? ? IF? < THEN
10. ? ? ? ? ? ? ?;
11. ? ? ? ? ELSE IF
12. ? ? ? ? ? ? ;
13. ? ? ? ? ELSE
14. ? ? ? ? ? ? ?;//正處于限速,不做處理
15. ? ? ? ? ? ? ?break;
16. ? ? ? ? END IF
17. ? ? ?END FOR
18. END IF
19. 刪除惡意興趣請求條目
4 性能評價
本文對基于節點的攻擊檢測與防御機制進行了仿真實驗和性能評價。先介紹了實驗的仿真環境,包括實驗平臺、興趣洪泛攻擊場景以及實驗拓撲;其次給出評價指標的定義,并借此驗證本文設計方案的有效性;最后與現有IFA攻擊應對方案進行比較分析,驗證了本文方案的優勢。
4.1 仿真環境
由于命名數據網絡還處于探索和研究階段,目前還未正式投入使用,因此本文所提出的方案目前只能在模擬環境中實現。本文的網絡模擬主要基于ndnSIM平臺,采用版本ndnSIM2.1,運行在ubuntu14.04之上。
為了模擬影響范圍較廣而且最易實現的IFA,本文通過合法的內容名稱前綴和偽造的后綴來偽造惡意興趣請求的內容名稱,從而發起攻擊,模擬IFA場景。
本文實驗采用的拓撲為小規模二叉樹拓撲,如圖6所示,其中深色用戶表示攻擊者,本文在不同位置總共設置三個攻擊者,可用于模擬分布式低速率的IFA攻擊,淺色用戶表示合法用戶。此外,拓撲圖中還包括一個內容提供者以及7個內容路由器。在路由器節點中,在中心節點Node1處部署本文設計的IFA攻擊的檢測與防御機制,使其解決的是IFAs攻擊影響最嚴重的情況。
4.2 有效性分析
本文根據有無攻擊以及有無防御策略劃分了三種情景,并從PIT占用率、合法興趣請求滿足率以及合法興趣請求丟包率三個指標分析本文方案的有效性。
(1)評價指標
1)PIT占用率
PIT占用率可從根本上反應IFA攻擊對節點的影響程度.計算公式如式(7),其中表示PIT條目的占用率,表示PIT中可緩存的條目總數,表示節點中PIT當前緩存的PIT條目數。
(7)
2)合法興趣請求滿足率
合法興趣請求滿足率可表征當前節點對用戶請求的響應能力。計算公式如式(8)所示,表示節點收到的合法興趣請求總數,表示節點收到的合法數據包總數。
(8)
3)丟包率分析
合法興趣請求丟包率可反映當前節點的狀態,其計算公式如式(9)所示。其中,表示節點收到的合法興趣請求總數,表示節點丟棄的合法興趣請求總數。
(9)
(2)性能評價
1)PIT占用率
如圖7所示Node1的PIT占用率變化趨勢。由藍色曲線變化趨勢可知,當沒有攻擊發生時,PIT條目占用率基本維持在15%左右。NDN中興趣請求內容名稱的聚合機制、數據包返回后合法興趣請求條目將被刪除的機制以及超時機制等因素都將使PIT的緩存將維持一個穩定的值域內,而且該值不會過高,屬于正常現象。由紅色曲線變化趨勢可知,當在100s發起分布式低速率的IFA時,PIT的占用率幾乎呈直線迅速上升平均達到100%。當200s停止攻擊時,PIT占用率將快速恢復常態,這是因為PIT條目超時會自動刪除,也體現了NDN中節點的自恢復能力。由圖中綠色曲線變化趨勢可知:當安裝了本文的防御方案之后,即使發生攻擊,在PIT緩存未溢出時便迅速下降至20%,這避免了PIT因為緩存溢出而丟棄合法用戶的興趣請求包而無法提供正常服務。由此可見,本文基于節點的策略是有效的。
[6] 李楊,辛永輝,韓言妮等.內容中心網絡中DoS攻擊問題綜述[J].信息安全學報,2016,2(1):91-108.
[7] Pang B, Li R, Zhang X, et al. Research on Interest Flooding Attack Analysis in Conspiracy with Content Providers[C]. The 7th IEEE International Conference on Electronics Information and Emergency Communication (ICEIEC). Macau, China: 2017. 543-547.
[8] Choi S, Kim K, Roh B H, et al. Threat of DoS by Interest Flooding Attack in Content- centric Networking[C]. The International Conference on Information Networking. Bangkok, Thailand: 2013. 315-319.
[9] Lee W, Xiang D. Information-theoretic Measures for Anomaly Detection[C]. IEEE Symposium on Security and Privacy. Oakland, USA: 2001. 130-143.
[10] Yuan Z, Zhang X, Feng S. Hybrid Data-driven Outlier Detection Based on Neighborhood Information Entropy and its Developmental Measures [J]. Expert Systems with Applications, 2018, 112: 243-257.
[11] Chen Z, Yeo C K, Lee B S, et al. Power Spectrum Entropy Based Detection and Mitigation of Low-rate DoS Attacks [J]. Computer Networks, 2018, 136: 80-94.
[12] Koay A, Chen A, Welch I, et al. A New Multi Classifier System Using Entropy-based Features in DDoS Attack Detection[C]. IEEE International Conference on Information Networking (ICOIN). Chiang Mai, Thailand: 2018. 162-167
作者簡介:
趙雪峰(1996-),女,漢族,新疆哈密人,東北大學,碩士;主要研究方向和關注領域: 軟件定義網絡、網絡安全。
王興偉(1968-), 男,漢族,內蒙包頭人,東北大學,博士,教授;主要研究和關注領域:未來互聯網、云計算、網絡空間安全。
易波(1988-),男,漢族,湖北天門人,東北大學,博士,講師;主要研究方向和關注領域:網絡功能虛擬化和服務鏈。
黃敏(1968-),女,漢族,遼寧沈陽人,東北大學,博士,教授;主要研究方向和關注領域:智能算法設計與優化、調度理論與方法。
