數據流安全查詢技術綜述
2019-03-17 09:36:34李軍于靈凡田斌李犇李曄康海燕
網絡空間安全 2019年9期
李軍 于靈凡 田斌 李犇 李曄 康海燕

摘? ?要:隨著基于數據流安全查詢(網絡流監控、股票數據在線分析、物聯網中的分布式數據流查詢、云計算下的數據流處理等)為背景的應用越來越普遍,學術界關于數據流上的安全分析、查詢、管理已經成為當前數據庫領域的一個很重要的研究熱點。在數據流應用中,數據流的實時到達和元組的突變性使得數據流模型同傳統數據庫模型有本質上的區別。因此,許多基于傳統數據庫模型下的查詢優化技術無法適應于數據流模型。以多媒體數據流安全檢測和查詢的視角,討論的核心內容是數據流上的過濾器排序、數據流之間的連接計算以及自適應優化這三個子問題。文章針對以上子問題分別介紹了國際上關于數據流上自適應查詢的一些主流研究思路和研究成果,并給出了下一步的研究思路。
關鍵詞:數據流;過濾器排序;自適應查詢
中圖分類號:TP311? ? ? ? ? 文獻標識碼:A
Abstract: With the application of data flow security query (network flow monitoring, online analysis of stock data, distributed data stream query in the Internet of Things, data stream processing under cloud computing, etc.), the application is more and more popular. Security analysis, query and management have become a very important research hotspot in the current database field. In data flow applications, the real-time arrival of data streams and the abruptness of tuples make the data flow model essentially different from traditional database models. Therefore, many query optimization techniques based on traditional database models cannot be adapted to the data flow model. From the perspective of multimedia data stream security detection and query, the core content of the discussion is the three sub-problems of filter sorting on the data stream, connection calculation between data streams and adaptive optimization. In view of the above sub-problems, some international research ideas and research results on adaptive query on data streams are introduced.
Key words: multimedia data Stream; adaptive query processing; filter ordering
1 引言
數據流作為數據庫發展的一個重要分支,在20世紀末作為一種新型的應用的模式被提出,數據流具有廣泛的應用前景,包括網絡流監控、股票數據流分析、異常數據流挖掘和物聯網分布式數據流協同處理等。因此,數據流環境下的查詢[19, 1]、管理[3, 17]、過濾[1, 2]、挖掘[5, 6, 7]是當前數據庫領域的研究熱點。數據流模型是區別于以往數據庫模型的新型數據應用模式。主要區別為:(1)數據流模型中數據是實時到達的,查詢是相對“靜止”的。相反,在數據庫模型中,數據是相對“靜止”的,查詢是不斷的變化;(2)數據流模型中數據一旦被處理以后即丟棄。相反,數據庫模型中,查詢一旦被處理以后即丟棄。數據流模型中數據到達的速度和規模具有不可預測性。
以上是數據庫模型和數據流模型的本質區別,使得數據流模型和數據庫模型對查詢的處理技術差別很大。主要體現在傳統數據庫模型中,查詢是不斷變化的,每次提交的查詢之間互不相關。查詢一旦執行完畢就可以丟棄。在數據流模型中,查詢是常駐于系統,一旦注冊就要求一直“在線”,而數據是在不斷的變化。數據一旦處理完畢就可以丟棄。這兩種數據模型下對查詢處理模式的差異性導致了傳統數據庫模型的查詢處理技術已經無法適用于數據流領域。同時,在數據流環境下,由于數據流的速率和規模的隨機性和不可預測性,自適應變化的查詢處理策略變得更加重要。綜上,本文以一種基于數據流實時查詢的視角,重點關注了近年來對數據流安全計算尤其是流查詢的研究成果。
如圖1所示,數據流系統通常注冊大量“在線”的查詢來完成數據流的實時查詢處理。每個查詢是多個過濾器(謂詞)的“與”運算。每個過濾器的計算開銷通常是比較昂貴的,特別是在日益普遍的多媒體數據流環境中。因此,數據流查詢的目標就是通過計算盡可能少的過濾器來決定所有查詢的結果。例如,假設在當前數據流上注冊了四個查詢,這些查詢間共享的過濾器的數量是四個。對于當前數據流元組e,過濾器最優排序順序A = F1;F2;F3;F4。也就是說順序A的開銷可能遠遠小于其他排序順序如B = F2;F4;F1;F3。由于數據流上元組存在突變性,對于下一個數據流元組e,排序順序B 的開銷可能就優于排序順序A。因此,在不斷變化的數據流環境中,如何自適應的調整過濾器的排序順序是關鍵問題。
近年來,數據流上的處理技術發展很快,主要側重于數據流查詢的處理和數據流上的深度內容挖掘技術。也出現了很多數據流管理系統,例如Tapestry[9]是構建在只支持添加模式的數據庫系統上面的在線查詢處理引擎,用來完成基于內容的過濾。這個系統可以說是數據流系統的雛形。
XFilter[11]將不同用戶對XML 文檔的“偏好”注冊到系統中,將這些“偏好”作為查詢以XPath[12]語言的形式來表示,進而實現了基于內容的過濾系統。Xyleme[13]是一個和XFilter[11]很類似的基于內容的過濾系統,只是使用的規則描述語言不同而已。Tribeca[14]系統是真正意義上的數據流管理系統,用來完成對網絡數據流的在線查詢,只不過提供查詢的能力非常有限。OpenCQ[15]和NiagaraCQ[16]系統都是監視Web數據流的數據流管理系統。支持側重點不太相同:OpenCQ[15]重點關注查詢處理的算法。NiagaraCQ[16]側重于支持的查詢數量規模。Telegraph[19, 18, 20, 50]是比較有特點的數據流管理系統,具有較好的擴展性和移植性。其最大的特點是設計了一種稱為Eddy[19]的機制,通過這個機制來完成對每個元組的自適應路由。Madden[20]重點討論了在傳感器網絡環境中Telegraph[19]系統的查詢執行策略。Madden[20]主要討論了在Telegraph系統中如何自適應的處理多查詢。Aurora[21]系統是側重于網絡管理應用的數據流管理系統,Aurora的核心是由操作符組成的觸發器網絡。每個觸發器是由一個或者多個操作符組成的有向無環圖。
對于每個使用了Aurora[21]系統的數據流管理應用中,管理員只需要創建一個或者多個觸發器,并將這些觸發器添加到Aurora觸發器網絡中。Aurora在執行計劃編譯時和運行時都進行了優化,Aurara在系統運行時通過檢測資源負載情況結合注冊服務的QoS進行“甩負荷”。STREAM[3]是一種基于關系模型的數據流管理系統。提出了一種數據流查詢語言CQL[38]。所有操作算子和算子的優化都是在同一個進程中,調度算法按照時間片進行簡單切割。STREAM 系統對查詢的優化也非常有限,只是對單查詢進行了選擇下推,對多查詢只是在數據共享方面做了一些優化工作。STREAM 基于關系模型進行數據流建模,給出了數據流環境下查詢的較完備的形式化定義。另外還有其他一些數據流項目,例如COUGAR[22]是Cornell大學的一個傳感器網絡環境中的數據庫項目,支持一種面向對象的查詢語言,將傳感器產生的數據定義為一個抽象數據類型,這樣傳感器輸出的就是一個時間序列的數據流。StatStream[23]是紐約大學的跨多個數據流計算統計值的實時數據流統計系統。
結合上述研究成果,對提出的問題進行分析和總結。本文試圖克服以上文獻中的片面性,以一種全新的數據流實時處理的視角來重點介紹數據流查詢領域的重點研究問題和解決辦法。傳統數據庫模型對查詢的精度、準確性有較高的要求,相反數據流模型對詢計劃執行的實時性和自適應調整這兩個方面要求比較高。正是基于數據流模型和數據庫模型在數據流查詢領域的差異性,引出了三個重要子問題。
(1)在越來越多的數據流應用場景中,數據模態越來越多,例如文本、圖片、音頻、視頻等。針對不同數據模態下的“操作算子”的屬性也千差萬別。將針對不同數據模態下的“操作算子”稱為過濾器。這樣,在數據流環境下的各種過濾器的屬性(開銷,選擇性……)就各不相同,如果將開銷較小的過濾器優先計算,那么對同一個元組的處理速度就要比其他策略要快。這就是過濾器的排序問題。過濾器排序問題是數據流處理領域最重要的問題之一。
(2)在很多數據流應用場景中,由于數據流之間的相關性越來越大,不同數據流之間通過各種屬性(如網絡流中四元組、時間戳、模態內容相似性)進行關聯,這樣就需要跨多個數據流進行融合過濾、分析、查詢、管理,將這個問題稱為多數據流融合計算。多數據流融合計算問題的核心是設計高效的多數據流之間的連接算子(Join operator)。多數據流的連接算子的設計是數據流領域的熱點問題之一。
(3)自適應查詢優化在數據流查詢系統中,執行引擎通常將查詢解析成執行計劃,執行計劃的單元是操作算子[1]。隨著數據流中數據時刻變化,同一個操作算子在不同時刻所需要的資源也是時刻變化,在有限存儲計算資源的情況下,如何自適應的優化執行計劃以高效的處理實時數據流是數據流查詢領域中一個很重要的研究熱點。這個問題稱為自適應查詢優化[33]。
在余下的章節,按照以上列出的數據流查詢領域的主要問題分別進行具體介紹:第二部分主要介紹共享過濾器排序問題;第三部分主要介紹數據流領域的主要連接算子研究進展情況;第四部分主要介紹自適應查詢優化問題以及目前的進展,最后對本文工作進行總結。
2 共享過濾器排序
為了有效地過濾數據流中特定信息,人們常常在數據流上注冊大量的查詢,同時訓練大量的過濾器。在數據流環境中,查詢和過濾器常常是一種“多對多”的連接,也就是說對于單個過濾器的判斷可能會同時給出多個查詢的結果。在這種情況下,如何排序所有的過濾器來獲得最小的過濾代價變得非常重要。對于過濾器的排序一般依賴于三個指標:過濾器本身的執行代價(c)、過濾器連接的查詢數目(p)以及過濾器對于隨機樣本判斷為真的概率(s)。針對過濾器的排序問題一般分為相關過濾器排序和獨立過濾器排序兩個子問題。其中,相關過濾器排序是指過濾器之間存在概率關系的情況下對過濾器進行排序。相反,獨立過濾器排序問題則是相對比較理想的情況下,假設所有的過濾器都是相互獨立。后者在數據流領域被廣泛關注。
2.1 獨立共享過濾器排序問題
獨立共享過濾器排序是指所有數據流系統中所有過濾器之間都是相互獨立的,一個過濾器的計算結果不會對其他過濾器的計算結果產生任何影響。在數據流環境中,查詢和過濾器常常是一種“多對多”的連接,即一條查詢中包含多個過濾器,一個過濾器可以同時出現在多條查詢中,這樣對于單個過濾器的判斷可能會同時給出多個查詢的結果。也就是說,查詢間有共享的過濾器,每個查詢都是過濾器的“聚合”,過濾器之間是“與”關系。在每個過濾器計算開銷已知的情況下,如何排序所有的過濾器來獲得最小的過濾代價變得非常重要。尤其是在多數據流環境中,能否自適應的調整計算順序來使得代價最小化。這就是本文關注的“獨立共享過濾”問題。下面給出共享過濾問題的描述。如圖1所示,用Q1;Q2;Q3;Q4來表示注冊的四條查詢。用F1;F2;F3;F4 來表示連接的過濾器。目標就是以最小的代價來完成所有查詢的計算。在圖 1 中如果F2返回為“假”,那么Q1和Q2的結果就是“假”。其他相關的過濾器就不需要再計算,只需要去關注與Q3相關的過濾器即可。這個問題就是共享過濾問題。最先由文獻[1]提出。
解決共享過濾問題需要考慮的因素如下:過濾器本身的執行代價(c),過濾器連接的查詢數目(p)以及過濾器對于隨機樣本判斷為“真”的概率(s)。一般來講,s 越小的過濾器計算次序越應該靠前,因為s 越小,表示其返回為“假”的概率越大,一旦這個過濾器返回為“假”,能排除所有包含這個過濾器的查詢。同樣,p 越大的過濾器越應該首先被計算,如果這個過濾器的計算結果為“假”,由于包含它的查詢數量較多,這樣就能排除較多的查詢。同樣,也應該首先計算c 值較小的過濾器。綜上,共享過濾問題的復雜性就在于如何以一種統一的策略來綜合考慮三個因素來實現計算開銷最小化的目標,以自適應的調整計算次序來處理實時的數據流。共享過濾問題是由A. Kemper[24]最先提出。他們不僅證明了這是NP難問題。這實質上暗示著在多項式時間解決這類問題的有效算法不存在,如何在多項式時間內得到這類問題的近似解是努力的方向。Liuzhen[8] 提出了近優算法來解決共享過濾問題并從理論證明了相似解的可求性,同時他們通過實驗結果論證了近優算法的性能提升。以上工作都是結合先驗知識來固定過濾器的參數s 顯然無法適應網絡數據流內容不斷變化的環境,同時以前的工作只是簡單的將三個指標融合成一個代價函數進行排序,而沒有深入分析各個指標之間的關系。
2.2 相關過濾器排序問題
相關過濾器排序問題一直是過濾器排序問題中的難點。相關共享過濾器排序的問題更加貼近于真實的數據流過濾情況。相關共享過濾器排序同樣是NP難問題。國外對相關過濾器排序的研究進展情況為:文獻[25] 嘗試用一種全面搜索來選擇下一個要計算的過濾器。文獻[26] 則提出了一種啟發式算法。文獻[27, 28, 29] 則提出了一些近似算法來解決這個問題。文獻[1] 將共享過濾器排序映射為并行集合覆蓋問題。在文獻[29] 中提出了線性規劃框架作為共享集合覆蓋問題的近似解決辦法。文獻[8] 所做的工作都是在假設所有過濾器都是相互獨立的情況下開展,論文不止一次提到相關過濾器的排序是非常有挑戰性的工作。
3 數據流上的連接運算
傳統的數據庫引擎主要側重基于磁盤IO的優化,這樣可以支持高速率的數據讀寫。數據庫查詢操作通常有多層嵌套的循環節點比較操作實現,所以數據庫優化的目標是盡量減少查詢操作中的循環次數。這種優化目標顯然不適應于較新的數據流領域。本文主要是介紹數據流領域的查詢優化,所以在這部分重點介紹了三個比較重要的連接操作算子(Join operator)。在3.1節中重點介紹對稱哈希連接算子。實現對兩個數據流的并行連接運算。在3.2節中重點介紹多數據流(大約等于2)上的連接算子—多路連接(M-join[36])。
3.1 對稱哈希連接
首先解釋了傳統哈希連接不適用于自適應查詢[33]的原因。傳統的哈希連接運算可以簡單分為兩個過程:構建(Build)和探測(Probe)。這兩個過程不能并行,必須構建過程完成后才能開始探測過程,這顯然不適用于數據流連接運算。由于,在數據流環境下元組并不是全部達到的,同時傳統的哈希連接也不適用于分布式數據源處理的場景中,當數據源分布在異處的情況下,是不可以一次性獲取到所有元組的。在數據流領域中,元組是持續到來的,優先想持續獲得元組的計算結果。文獻[30,31]首先引入了對稱哈希連接這個概念。
如圖2所示,當數據流A或者數據流B中任意一個元組進入對稱哈希連接算子以后,會存儲到對應的哈希表中,這個過程相當于原來的構建過程,然后去探測對稱的哈希表。算法 1 詳細描述了對稱哈希連接的處理邏輯。基于對稱哈希連接處理數據流的思想,后來出現了很多類似的連接算子:文獻[32]提出了XJoin主要是在原來對稱哈希連接的基礎上解決了內存有限的情況,將數據緩存到磁盤。文獻[34]將連接算子移植到一個多線程框架中,將數據流處理看成是一種生產者——消費者模型,同時也考慮了當內存空間不足的情況下將溢出流緩存到磁盤中的情況。
3.2 多路連接運算
將多路連接(M-join[36])看成是對稱哈希連接向多數據流的自然擴展。文獻[35, 36] 首先提出了多路連接的概念:將對稱哈希連接推廣到多數據流(大于2)的情況,允許數據流中的元組按照任意順序到達。同時,文獻[35, 36] 說明了多路連接比由二叉連接算子構建的樹結構具有的優勢,并證明了多路連接非常適合于數據流處理和自適應查詢,如圖4所示。圖3是一個典型的三路連接算子實例。多路連接算子通過在每個連接相關屬性上構建哈希索引。如圖 3 所示,基于表B 的兩個哈希索引共享著數據流B上的元組。其他數據流表A,C 上分別構建了一個哈希索引。路由器作為一個輕量級的調度算子,完成所有數據流上元組的調度,這個調度算子和Eddy框架[35]中的調度算子非常類似。當任意一個數據流中有元組到達時,首先是要將該元組插入到所屬的哈希表中,然后按照一種特定的順序去依次探測其他的相關數據流,探測順序的選擇和共享過濾器排序問題非常相似,可用相同的思路來解決。
4 查詢優化
查詢優化的過程就是自適應查詢處理的過程。在傳統的數據庫領域,查詢的處理策略是:先計劃,再執行。也就是,查詢引擎首先決策出一個開銷最小的查詢執行計劃,然后查詢執行器來完成計劃的執行。鑒于數據流查詢中,數據流在速度和內容上具有不可預測性。因此,數據元組突變性可能會使得優化本次選擇的執行計劃在下一個數據元組的查詢中會引起性能驟降[50, 37],這樣就使得自適應查詢處理在數據流領域被廣泛關注[38]。自適應查詢的主要研究動機是:
(1)由于數據流的突變,可能會導致本次的最優查詢計劃在下一次元組處理中的開銷增加。自適應查詢處理需要及時發現這種不適應并采取一些糾正措施;
(2)自適應查詢處理可以及時探知數據源的未知屬性并選擇最優查詢計劃;
(3)鑒于數據流系統的資源限制條件,自適應查詢處理要能夠及時的根據當前系統資源和輸入條件的限制做出最優計劃的決策。
自適應的查詢處理可以避免因為死板的查詢計劃帶來的性能抖動,使得數據流系統的查詢性能趨于穩定[45, 37]。在自適應的查詢處理模型中,查詢的執行被嚴格的劃分為優化階段和執行階段。這兩個階段相互獨立。這樣可以使得查詢的處理過程中可以及時的糾正因為優化策略帶來的性能顛簸。自適應查詢處理在過去幾年中的進展情況為:
(1)所有自適應查詢處理的工作集中在最近的十年內;
(2)在自適應查詢處理領域的主要研究工作具有很大的差異性,這些差異性主要體現在查詢語義的不同,不同的數據源,開銷度量方式的差異,優化框架的差異以及不同的自適應定義;
(3)自適應查詢處理的框架主要包括三個重要的組成部分。
1)優化器:選擇一種開銷最小的執行計劃;
2)執行器:按照當前選擇的執行計劃來完成查詢的執行操作;
3)統計跟蹤器:統計在查詢執行過程中的系統資源信息,查詢開銷信息等。以供優化器在優化過程中使用。
文獻[38]第一次對數據流系統按照查詢執行策略進行了分類并對系統的性能表現進行了詳細的對比。對主流的數據流系統按照查詢執行的策略分為三類。
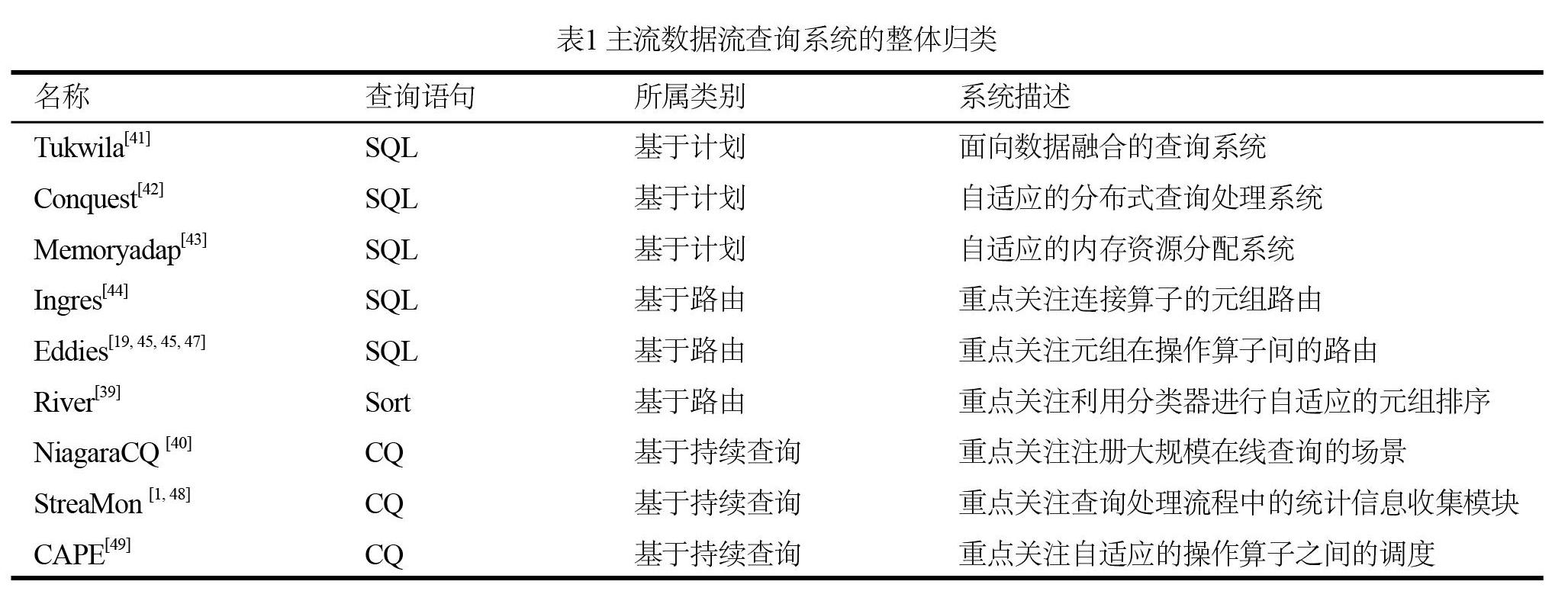
(1)基于計劃的系統:傳統“先計劃,再執行”的查詢執行模式的擴展。主要的擴展體現在增加了統計跟蹤器、自適應查詢,如圖5所示。統計跟蹤器用來收集查詢執行過程中的系統信息來作為優化器重新優化的重要數據參考。
(2)基于路由的系統:以Eddy[19]和River[39]作為這個分支的經典代表。核心思想是將數據流上的元組的查詢過程看成一個個的數據包在操作算子間的路由。因此,所有的優化策略都是基于數據流元組級別。自適應查詢處理的流程如圖6所示。
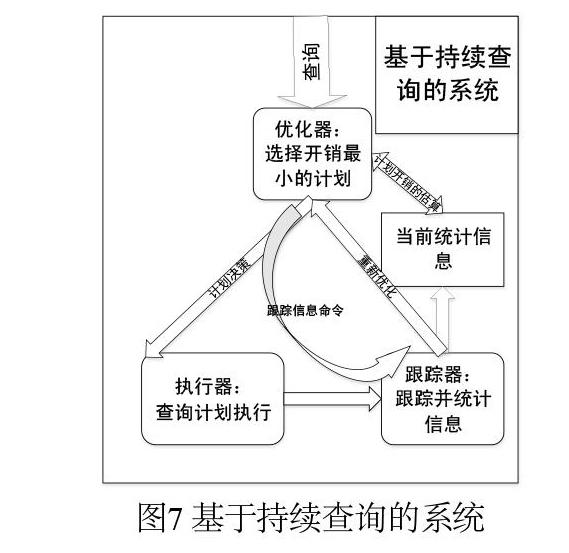
(3)基于持續查詢的系統:以CAPE[17]、NiagaraCQ[40]、StreaMon[49]作為這個分支的經典代表,是數據流領域查詢處理的主要模型。重點考慮大量查詢在線注冊的情況下,將查詢和數據流元組的變化常態化,重點關注優化器自適應的調整操作算子的順序來完成查詢的執行過程。自適應查詢處理的流程如圖 7 所示。
依據上面的分類,對近年來主流的數據查詢處理系統進行簡單的歸類和簡單說明,如表1所示。
5 結束語
本文回顧了數據流領域的國內和國際上在該領域的主要研究成果,從數據流過濾的視角重新審視自適應查詢的問題,綜述了在數據流模型中自適應查詢出現的主要問題(過濾器排序、數據流連接、查詢優化),并結合大規模數據流安全檢測背景,形成了下一步的研究思路。
(1)過濾器排序:在數據流環境下的各種過濾器的屬性(開銷、選擇性、窗口等)差異較大,以往工作均是結合自身過濾器屬性構建簡單的排序算法,普遍不具備自適應調整能力。下一步的工作重點是普適性的過濾器度量模型和自適應排序算法。
(2)數據流連接:隨著大數據和高通量計算需求日益旺盛,跨多數據流進行融合過濾、分析、查詢、管理歸類為多流融合計算問題。多流融合計算問題的關鍵是設計高效的多數據流間的連接算法和環境感知關聯模型。通過研究發現,當前工作中對連接算法普遍采用數據庫連接計算方法,缺乏對數據流和大數據環境下的環境感知能力,下一步重點考慮構建具備環境感知能力的數據流關聯計算模型。
基金項目:
1.國家自然科學基金聯合基金(項目編號:U1936111);
2.北京信息科技大學校基金項目(項目編號:5221910933)。
參考文獻
[1] S. Babu, R. Motwani, K. Munagala, I. Nishizawa, and J. Widom:Adaptive ordering of pipelined stream filters. In SIGMOD04: Proceedings of the ACM SIGMOD International Conference on Management of Data, pp. 407-418 ( 2004)
[2] Chris Olston , Jing Jiang , Jennifer Widom, Adaptive filters for continuous queries over distributed data streams, Proceedings of the 2003 ACM SIGMOD international conference on Management of data, June 09-12, 2003, San Diego, California
[3] A. Arasu, B. Babcock, S. Babu, M. Datar, K. Ito, I. Nishizawa, J. Rosenstein, J. Widom. STREAM: the stanford stream data manager, in: Proceedings of the SIGMOD, 2003, p. 665.
[4] H.-H. Lee, E.-W. Yun and W.-S. Lee, Attribute-based evaluation of multiple continuous queries for filtering incoming tuples of a data stream, Information Sciences 178 (11) (2008), pp. 2416–2432
[5] Moses Charikar , Kevin Chen , Martin Farach-Colton, Finding Frequent Items in Data Streams, Pro-ceedings of the 29th International Colloquium on Automata, Languages and Programming, p.693-703, July 08-13, 2002
[6] J. Feigenbaum , S. Kannan , M. Strauss , M. Viswanathan, An Approximate L1-Di?erence Algorithm for Massive Data Streams, Proceedings of the 40th Annual Symposium on Foundations of Computer Science, p.501, October 17-18, 1999
[7] Anna C. Gilbert , Yannis Kotidis , S. Muthukrishnan , Martin Strauss, Surfing Wavelets on Streams: One-Pass Summaries for Approximate Aggregate Queries, Proceedings of the 27th International Conference on Very Large Data Bases, p.79-88, September 11-14, 2001
[8] Zhen Liu , Srinivasan Parthasarathy , Anand Ranganathan , Hao Yang, Near-optimal algorithms for shared filter evaluation in data stream systems, Proceedings of the 2008 ACM SIGMOD international conference on Management of data (2008)
[9] D. Terry, D. Goldberg, D. Nichols, and B. Oki. Continuous queries over append-only databases. In Proc. of the 1992 ACM SIGMOD Intl. Conf. on Management of Data, pages321–330, June 1992.
[10] M. Altinel and M. J. Franklin. E?cient filtering of XML documents for selective dissemination of information. In Proc. of the 2000 Intl. Conf. on Very Large Data Bases,pages 53–64, Sept. 2000.
[11] Xml path language (XPath) version 1.0, Nov. 1999.W3C Recommendation available at http://www.w3.org/TR/xpath.
[12] B. Nguyen, S. Abiteboul, G. Cobena, andM. Preda.Monitoring XML data on the web. In Proc. of the 2001 ACM SIGMOD Intl. Conf. on Management of Data, pages437–448,May 2001.
[13] M. Sullivan. Tribeca: A stream databasemanager for network tra?c analysis. In Proc. of the 1996 Intl. Conf. on Very Large Data Bases, page 594, Sept. 1996.
[14] L. Liu, C. Pu, andW. Tang. Continual queries for internet scale event-driven information delivery. IEEE Trans. on Knowledge and Data Engineering, 11(4):583–590, Aug.1999.
[15] J. Chen, D. J. DeWitt, F. Tian, and Y. Wang. NiagraCQ: A scalable continuous query system for internet databases. In Proc. of the 2000 ACM SIGMOD Intl. Conf. on Management of Data, pages 379–390,May 2000.
[16] S. Babu and J. Widom:Continuous queries over data streams. SIGMODRec., vol. 30, no. 3, pp. 109–120, 2001.
[17] J. Hellerstein, M. Franklin, et al. Adaptive query processing: Technology in evolution. IEEE Data Engineering Bulletin, 23(2):7–18, June 2000.
[18] R. Avnur and J. Hellerstein. Eddies: Continuously adaptive query processing. In Proc. of the 2000 ACM SIGMOD Intl. Conf. on Management of Data, pages 261–272,May 2000.
[19] S. Madden andM. J. Franklin. Fjording the stream: An architecture for queries over streaming sensor data. In Proc. of the 2002 Intl. Conf. on Data Engineering, Feb. 2002. (To appear).
[20] D. Carney, U. Cetinternel, M. Cherniack, C. Convey, S. Lee, G. Seidman,M. Stonebraker,N. Tatbul, and S. Zdonik. Monitoring streams –a new class of dbms applications. Technical Report CS-02-01, Department of Computer Science, Brown University, Feb. 2002.
[21] P. Bonnet, J. Gehrke, P. Seshadri. Towards Sensor Database System. In Proc. Int. Conf. On Mobile Data Management, 2001, pages 3-14.
[22] Y. Zhu, D. Shasha. StatStream: Statistical Monitoring of Thousands of Data Streams in Real Time. In Proc. Int. Conf. On Very Large Data Bases, 2002, pp. 358-369.
[23] K. Munagala, U. Srivastava, and J. Widom.Optimization of continuous queries with shared expensive filters. In PODS07: Proceedings of the 26th ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, pp. 215-224 (2007)
[24] A. Kemper, G. Moerkotte, and M. Steinbrunn. Optimizing boolean expressions in object-bases. In Proc. of the 1992 Intl. Conf. on Very Large Data Bases, pages 79–90, Aug. 1992.
[25] K. Ross. Conjunctive selection conditions in main memory. In Proc. of the 2002 ACM Symp. on Prin-ciples of Database Systems, June 2002.
[26] E. Cohen, A. Fiat, and H. Kaplan. E?cient sequences of trials. In Proc. of the 2003 Annual ACM-SIAM Symp. on Discrete Algorithms, Jan. 2003.
[27] U. Feige, L. Lov′asz, and P. Tetali. Approximating min-sum set cover. In Proc. of the 5th Intl. Workshop on Approximation Algorithms for Combinatorial Optimization (APPROX), Sept. 2002.
[28] K. Munagala, S. Babu, R. Motwani, and J. Widom. The pipelined set cover problem. Technical report, Stanford University Database Group, Oct. 2003. Available at http://dbpubs.stanford.edu/pub/2003-65.
[29] L. Raschid and S. Y. W. Su, “A parallel processing strategy for evaluating recursive queries,”in VLDB 86: Proceedings of the 12th International ConReferences ference on Very Large Data Bases, pp. 412–419, Morgan Kaufmann Publishers Inc., 1986.
[30] A. N. Wilschut and P. M. G. Apers, “Dataflow query execution in a parallel main-memory environ-ment,”in PDIS 91: Proceedings of the First International Conference on Parallel and Distributed Information Systems, Fontainebleu Hilton Resort, Miami Beach, FL, pp. 68–77, IEEE Computer Soci-ety, 1991.
[31] T. Urhan and M. J. Franklin, “XJoin: a reactively-scheduled pipelined join operator,”IEEE Data Engineering Bulletin, vol. 23, no. 2, pp. 27–33, 2000.
[32] Amol Deshpande , Zachary Ives , Vijayshankar Raman, Adaptive query processing, Foundations and Trends in Databases, v.1 n.1, p.1-140, January 2007
[33] Z. G. Ives, D. Florescu, M. Friedman, A. Levy, and D. S. Weld, “An adaptive query execution system for data integration,”in SIGMOD 99: Proceedings of the 1999 ACM SIGMOD international conference on Management of data, (New York, NY, USA), pp. 299–310, ACM Press, 1999.
[34] V. Raman, A. Deshpande, and J. M. Hellerstein, “Using state modules for adaptive query process-ing.,”in ICDE 03: Proceedings of the 19th International Conference on Data Engineering, Bangalore, India, pp. 353–364, 2003.
[35] S. Viglas, J. F. Naughton, and J. Burger, “Maximizing the output rate of multi-way join queries over streaming information sources,”in VLDB 03: Proceedings of the 29th International Conference on Very Large Data Bases, Berlin, Germany: Morgan Kaufmann, September 9–12 2003.
[36] R. Avnur and J. M. Hellerstein, “Eddies: continuously adaptive query processing,”in SIGMOD 00: Proceedings of the 2000 ACM SIGMOD international conference on Management of data, (New York, NY, USA), pp. 261–272, ACM Press, 2000.
[37] S. Babu and P. Bizarro, ”Adaptive query processing in the looking glass,” in CIDR 05: Second Biennial Conference on Innovative Data Systems Research, pp. 238-249, Asilomar, CA, 2005.
[38] N. Kabra and D. DeWitt. E?cient mid-query reoptimization of sub-optimal query execution plans. In Proc. of the 1998 ACM SIGMOD Intl. Conf. on Management of Data, pages 106–117, June 1998.
[39] R. Arpaci-Dusseau. Run-time adaptation in river[J]. ACM Trans. on Computer Systems, 21(1):36–86, 2003.
[40] J. Chen, D. DeWitt, F. Tian, and Y. Wang. NiagaraCQ: A scalable continuous query system for internet databases. In Proc. of the 2000 ACM SIGMOD Intl. Conf. on Management of Data, pages 379–390, May 2000.
[41] Z. Ives, D. Florescu, M. Friedman, A. Levy, and D. Weld. An adaptive query execution system for data integration. In Proc. of the 1999 ACM SIGMOD Intl. Conf. on Management of Data, pages 299–310, June 1999.
[42] [45] K. Ng, Z. Wang, R. Muntz, and S. Nittel. Dynamic query re-optimization. In Proc. of the 1999 Intl. Conf. on Scientific and Statistical Database Management, pages 264–273, July 1999.
[43] B. Dageville and M. Zait. SQL memory management in Oracle9i. In Proc. of the 2002 Intl. Conf. on Very Large Data Bases, pages 962–973, Aug. 2002.
[44] E. Wong and K. Youssefi. Decomposition - a strategy for query processing[J]. ACM Trans. on Database Systems, 1(3), 1976.
[45] A. Deshpande and J. Hellerstein. Lifting the burden of history from adpative query processing. In Proc. of the 2004 Intl. Conf. on Very Large Data Bases, Aug. 2004.
[46] S. Madden, M. Shah, J. Hellerstein, and V. Raman. Continuously adaptive continuous queries over streams. In Proc. of the 2002 ACM SIGMOD Intl. Conf. on Management of Data, pages 49–60, June 2002.
[47] V. Raman, A. Deshpande, and J. Hellerstein. Using state modules for adaptive query processing. In Proc. of the 2003 Intl. Conf. on Data Engineering, Mar. 2003.
[48] S. Babu, K. Munagala, J.Widom, and R. Motwani. Adaptive caching for continuous queries. In Proc. of the 2005 Intl. Conf. on Data Engineering, 2005. (To appear).
[49] S. Babu and J. Widom. StreaMon: An adaptive engine for stream query processing. In Proc. of the 2004 ACM SIGMOD Intl. Conf. on Management of Data, June 2004. Demonstration proposal.
[50] S. Christodoulakis. Implications of certain assumptions in database performance evaluation[J]. ACM Trans. on Database Systems, 9(2):163–186, 1984.
[51] 孟小峰, 周龍驤, 王珊. 數據庫技術發展趨勢[J]. 軟件學報, 2004(12):74-88
作者簡介:
李軍(1983-),男,漢族, 山東滕州人,北京郵電大學,博士, 高級工程師,北京信息科技大學,教師;主要研究方向和關注領域:網絡信息安全、數據挖掘。
于靈凡(1998-),女,漢族,北京信息科技大學,本科;主要研究方向和關注領域:網絡流挖掘和管理。
田斌(1983-),男,漢族,北京郵電大學,博士,中國信息安全測評中心,高級工程師;主要研究方向和關注領域:網絡空間安全。
李犇(1986-),男,漢族,山東濟寧人,中國科學院大學,碩士,北京市公安局朝陽分局,副科級警察;主要研究方向和關注領域:網絡空間安全。
李曄(1986-),男,漢族,河北保定人,北京郵電大學,碩士,河北移動網絡管理中心,工程師;主要研究方向和關注領域:網絡安全和管理。
康海燕(1971-),男,漢族,河北石家莊人,北京理工大學,博士,教授,北京信息科技大學,副院長;主要研究方向和關注領域:網絡空間安全。
