視頻監控系統異常目標檢測與定位綜述
2019-03-21 12:53:48胡正平李淑芳孫德綱
燕山大學學報 2019年1期
胡正平,張 樂,李淑芳,孫德綱
(1. 燕山大學 信息科學與工程學院,河北 秦皇島 066004;2. 燕山大學 河北省信息傳輸與信號處理重點實驗室,河北 秦皇島 066004;3. 山東華宇工學院 電子信息工程學院,山東 德州 253000)
0 引言
隨著室內外監控攝像機數量的增加,在采用傳統人為視頻監督方法進行異常檢測時,常因為人們的疏忽和疲勞以及信息本身的復雜性,造成監視任務的低效和繁瑣。因此,采用智能視頻監控系統自動檢測異常行為對于確保公共安全和社會秩序管理具有至關重要的作用,同時視頻異常行為檢測作為人類行為識別的一個特殊問題引起國內外學者廣泛關注。
基于對智能監控系統的需求,2005年Valera和Velastin 歸納了基于自動異常檢測的監控系統的基本組成框架[1]。1997年美國國防高級研究項目署設立以卡內基梅隆大學為首麻省理工學院等高校參與的視覺監控重大項目VSAM(Visual Surveillance And Monitoring)用于戰場及普通民用場景監控的運動物體的檢測、定位和分類[2]。此外,歐盟也大力資助基于系統結構的公共交通行人監控項目來提高視頻監控異常檢測的效率,如CROMATICA (Crowd Management with Telematics Imaging and Communication Assistance)[3]和 PRISMATICA (Proactive Integrated Systems for security Management by Technological Institutional and Communication Assistance)[4]。在國內中科院自動化所學者發起的實時智能視頻監控預警系統已成功應用于北京地鐵13號線,大大提高效率的同時使場所犯罪率降低至新的標準[5]。
視頻異常檢測首先需要確定異常的含義,一般來說在不同的視頻中對于“異常”的定義各不相同,即異常的定義取決于視頻本身的內容,通常情況下將視頻場景中小概率事件視為異常行為。異常可以分為全局異常和局部異常,全局異常指整個場景的群體行為是異常的,這類異常是從視頻序列的某一幀開始就整個幀場景而言出現的異常,如UMN數據集中的人群恐慌四處逃散場景和Hockey Fight中的暴力行為場景[6]。而局部異常是指視頻中只有某一區域中的個體行為異于鄰近人群或整個場景中的絕大部分行為,如UCSD數據集中步行街中騎自行車的行為等。
視頻異常檢測就是從大量視頻中高效地檢測出異常事件,進而保障公共安全防止危險的情況發生。一般來說實現這一目標需要三個步驟,首先對視頻序列進行前景分割和提取,檢測出運動目標,然后進行特征的提取和篩選來表示基本事件,最后實現異常事件的識別和定位。智能視頻異常檢測系統流程如圖1所示,本文也將按照該流程分別進行闡述。

圖1 智能視頻異常檢測系統
Fig.1 Intelligent video anomaly detection system
1 前景提取與運動目標檢測
通常情況下監控視頻中的異常情況常為運動的物體或目標,然而視頻中大面積的背景或是靜止的物體使得異常檢測運算過程變得龐大復雜,同時大量的噪聲及冗余信息使得特征提取、行為表示變得困難,從而大大降低了異常檢測的效率和質量。因此,運動目標檢測是智能異常檢測系統中不可或缺的步驟。傳統運動目標檢測方法有幀間差分法(幀差法)、背景減除法和光流法。幀差法是通過相鄰幀之間的差分判定對應像素的灰度值的變化從而檢測出運動目標。背景減除法需要先對背景進行建模得到背景模型,再將每幀圖像和背景模型圖像進行對比。光流法是運動目標檢測中最常用的一種方法,在視頻分析中通常定義為一個視頻幀序列中的圖像亮度模式的表觀運動,即空間物體表面上的點的運動速度在視覺傳感器的成像平面上的表達,常用的光流方法有HS算法和金字塔HK算法。監控視頻異常檢測領域常用的前景提取與運動目標檢測方法框圖如圖2所示。在進行視頻異常檢測時常使用光流法配合元胞分割方法剔除背景信息并得到含有運動目標的二維圖像或三維時空興趣塊,例如Roberto Leyva等人通過對視頻幀進行運動目標檢測,得到含有運動目標的二維圖像,然后對這些二維圖像進行特征提取和行為表示[7]。Zhou Shifu等人采用光流法提取到含有運動信息的時空興趣塊,作為三維卷積網絡的輸入,該方法有效地減弱了背景信息的影響,提高了異常檢測速度和準確率[8]。
圖2 前景提取與運動目標檢測方法框圖
Fig.2 Block diagram of foreground extraction and moving object detection method
2 特征提取和行為表示
在視頻異常檢測的研究中,合適特征的高效提取對正常及異常行為的快速準確鑒別具有重要的作用,為此研究學者也提出各種方法進行特征提取和行為表示。特征提取從思路上可以分為兩大類:一類是采用手動設計方式提取人工設計特征,一類是直接對原始視頻幀進行學習得到深度特征,兩種特征提取方式都是基于生物神經理論實現的,不同之處在于手動設計方式提取的特征是模仿人類視覺框架得到的,而深度學習的特征提取方法重點在于對數據本身的分布規律進行學習。異常檢測中常用的特征提取方法如圖3所示。
圖3 異常檢測特征提取方法框圖
Fig.3 Block diagram of feature extraction method for anomaly detection
2.1 人工設計特征行為表示
人工設計特征是根據人類視覺對特征的敏感度從圖像中提取有區分能力的特征,因此提取出來的特征具有明確的物理含義。目前,常用于視頻異常檢測的人工設計特征有紋理特征、顏色、MoSIFT(Motion Scale Invariant Feature Transform)、光流特征、軌跡特征等。例如Li Weixin等人使用動態紋理混合(Mixtures of Dynamic Textures,MDT)對正常人群的行為建模,利用顯著性區分判別空間中的異常與正常事件將模型中的異常值視為異常事件[9-10]。在二維紋理的基礎上,Wang J基于時空視頻概念,提出具有豐富的人群模式特征的時空紋理模型,將提取到的監視記錄的人群紋理在基于冗余小波變換的特征空間進行行為模板匹配實現異常的檢測[11]。Aravinda S.Rao等人從統計的角度通過灰度共生矩陣(Gray Level Co-occurrence Matrix,GLCM)對異常事件或物體的對比度、相關性、均勻性等空間特征進行描述構建異常框架,并采用時空編碼檢測出人群中的異常游蕩行為[12]。從顯著性角度,中國科學院學者提出基于顯著性的異常事件檢測方法,一方面通過對比兩個連續的視頻幀之間特征點的運動構造時空異常顯著圖,另一方面基于顏色對比構造空間異常顯著圖,實驗結果顯示該方法在沒有訓練階段的情況下,對異常事件的檢測效果具有較高的準確率和魯棒性[13]。MoSIFT作為一種有效的特征描述符,不僅可以檢測到空間上具有一定運動的、區分性強的興趣點,并且能夠通過興趣點周圍的光流強度衡量興趣點的運動強度, 因此采用基于MoSIFT的行為表示方法進行異常檢測可以得到較好的效果,例如文獻[14]采用MoSIFT算法提取視頻的低級別的描述,并采用核密度估計(Kernel Density Estimation,KDE)對MoSIFT描述符進行特征選擇,消除特征干擾。基于Harris角點及興趣點算子文獻[15]在空間時間有顯著的局部變化的部分建立時空局部結構,并計算它們的尺度不變的時空描述符,如此將空間興趣概念擴展到時空域(Space-time Interest Points,STIPs)以獲得更好的異常檢測效果。此外針對彩色圖像的運動行為描述問題,Insaf Bellamine等人通過對圖像的色彩幾何結構成分和紋理成分分解得到色彩時空興趣點(Color Space-Time Interest Points,CSTIP),實現運動目標描述[16]。
異常事件常伴隨著目標的運動速度變化,光流作為一種有效的目標運動描述子被廣泛應用在異常檢測的研究中。文獻[17]基于光流采用運動粒子區分正常與異常行為從而實現擁擠場景下的異常行為檢測。光流加速度和光流梯度直方圖特征在文獻[18]中被用來檢測場景中存在的異常物體和速度違規現象。文獻[19]中所采用光流多尺度直方圖(Multistage Histogram of Optical Flow,MHOF)進行特征表示,MHOF不僅有傳統的HOF (Histogram of Optical Flow)表示運動信息的功能,也可用于空間相關信息的表示。為利用方向信息,文獻[20]采用具有更低維度的光流方向直方圖(Histogram of Optical Flow Orientation,HOFO)描述子來區分正常與異常事件,并在全局異常檢測中取得了較好的效果。為提取視頻幀中存在運動的局部區域特征,文獻[21]在對視頻序列進行時空網格分割后,采用概率主成分分析(Mixture of Probabilistic Principle Component Analyzers,MPPCA)得到每個時空網格內的光流信息,并用于時空MRF模型的建立從而檢測出視頻中的異常。基于光流方法,研究人員采用兩個新穎的局部運動視頻描述子SL-HOF(Spatially Localized Histogram of Optical Flow)和ULGP-OF(Uniform Local Gradient Pattern based Optical Flow)對視頻特征進行提取,SL-HOF描述符可以捕捉到時空興趣塊中三維局部區域變化的空間分布信息,ULGP-OF描述符融合了經典的2D紋理描述符LGP(Local Gradient Pattern)和光流算法,在定位視頻前景信息時較普通光流算法更為準確,然后采用OCELM(One-class Extreme Learning Machine) 對兩種描述符進行學習從而得到用于異常事件檢測的正常事件模型[22],這類基于特征塊的通用型框圖如圖4所示。
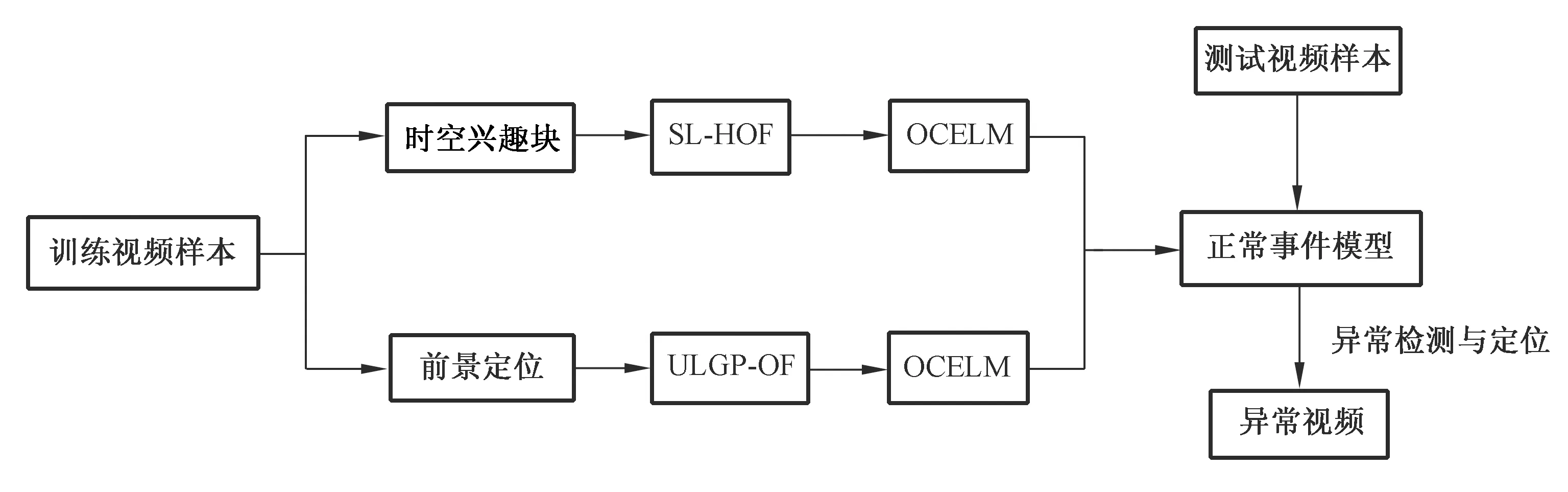
圖4 基于時空興趣塊進行特征提取框圖示例
Fig.4 Block diagram example for feature extraction for spatial-temporal interest blocks
為實現實時的視頻異常檢測,Roberto Leyva等人采用了二進制特征行為表示的異常檢測方法。首先對輸入視頻幀進行前景、時間梯度(temporal gradients)計算,利用時間梯度、目標快速分割 (Fast Accelerated Segmentation Test,FAST)檢測到時空興趣點(Spatial Temporal Interest Points,STIPs)并采用二進制小波差異(Binary Wavelets Differences,BWD)對時空興趣點進行編碼,采用GMM(Gaussian Mixture Model)分別對前景占用率、漢明距離和直方圖投票機制進行建模從而完成對異常的檢測與定位,該方法基本框圖如圖5所示[23]。
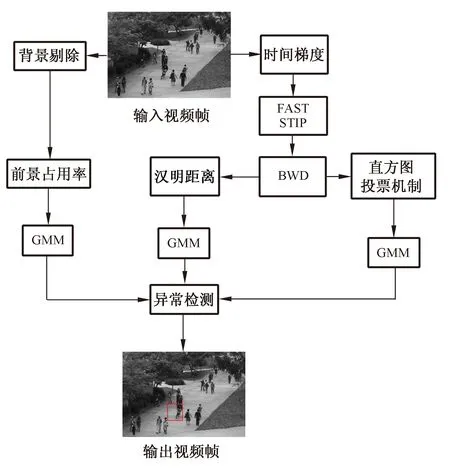
圖5 基于單幀特征框圖示例
Fig.5 Examples of feature method block diagram for single frame extraction
物體在運動時會產生運動的軌跡,而運動軌跡中包含運動物體的長度、像素、位置和運動程度等信息[23]。文獻[24]中將提取的不同長度、時間變化帶有噪聲的軌跡進行分層聚類,對每類進行建模從而表示正常異常事件。近年來基于目標時空軌跡的新穎異常檢測方法層出不窮,例如文獻[25]提出基于軌跡稀疏重構的異常檢測方法,在視頻場景中提取最小二乘三次樣條曲線近似值(the Least-squares Cubic Spline Curves Approximation,LCSCA)特征構成字典完成異常檢測任務。Coar S等人認為無論是基于軌跡的方法還是基于像素的方法都具有局限性,不可能檢測到所有的異常行為,軌跡特征可以檢測出速度和方向的異常,但是類似于跳躍或打斗這類與人的部分肢體運動相關的異常動作很難從時空軌跡的分析中發現,同樣,基于像素的方法可能無法探測到游蕩的恐怖分子或小偷這類與人的整體運動有關的異常,因此作者融合兩種方法采用斷開軌跡高效地高層次地表示軌跡,既可以檢測到物體的速度和方向也可以表示每個物體更為復雜的局部運動,在準確檢測異常事件的同時減少了計算負荷[26]。文獻[27]提出基于軌跡優化的異常活動檢測系統,系統結構分為兩層:在第一級低級別過程中,采用基于軌跡的方法產生軌跡信息進行實時異常處理,并對可疑事件進行實時檢測分析并實時報警;在第二級中,采用密集視頻分析算法檢測可疑事件是否由實際人觸發。
2.2 深度特征行為表示
通過手動設計提取的人工設計特征的方法盡管有眾多的理論依據但是人為因素太強,不能客觀地表示行為,其次通過這種方式提取的特征往往依賴于數據庫,也就是說手動特征可能只對某些數據庫表現較好而對其它的數據庫并不一定可以獲得同樣的效果。當采用直接對數據進行學習的方式進行深度特征提取時,只需設計特征提取的規則,例如神經網絡中通過人為設計網絡模型的結構及學習的規則獲得深度模型參數并提取深度特征,因此得到的特征往往無法解釋具體每一維的物理含義。近年來,深度學習和卷積神經網絡的快速發展為計算機視覺領域的各項研究提供了新思路,然而盡管普通的卷積神經網絡對二維圖像的特征學習有很好的效果,但是對于三維的視頻特征學習有一定的局限性。為打破這一局限,Simonyan Karen等人提出了采用并行的雙流網絡分別對RGB圖片的空間信息以及視頻序列的光流圖進行特征學習及行為判別,最后融合兩個網絡的判別結果得到最終的動作分類,實驗證明雙流網絡對于特征提取及行為表示具有一定的效果[28]。研究者基于雙流網絡也做了一系列的改良并得到了多種雙流網絡衍生算法,如convolutional two-stream network[29],temporal segment networks[30]以及基于加權融合的STN[31]等。基于雙流網絡是通過對單幀進行二維特征學習并采用光流表達幀間關系并作為時域信息的彌補,Tran Du等提出了深度3維卷積神經網絡(3 Dimension Convolution Network,C3D)將視頻的連續幀即視頻塊作為輸入簡單高效地獲得時域空域特征,將深度卷積網絡的方法引入解決視頻中的分類問題[32]。基于這一方法Zhou Shifu等人使用三維卷積神經網絡解決了視頻中的異常行為檢測和定位,將整個視頻中可能存在的時空興趣塊不經任何處理直接作為C3D的輸入進行特征學習[8]。同時,Sabokrou Mohammad等人采用級聯三維神經網絡的方法,由三維自動編碼器檢測出時空興趣塊送入C3D中進行訓練完成對異常進行快速的檢測和定位[33]。此外,目標檢測領域的深度學習經典方法如SSD[34]、Faster-RCNN[35]、YOLO[36]等實現了目標檢測定位與分類的同步完成,為異常目標檢測提供了新的思路。Xu Huijuan等人將Fater-RCNN的思路應用到時域的動作定位,并結合C3D網絡得到R-C3D網絡,該網絡通過共享Progposal generation和Classification網絡的C3D參數能夠以更快的速度針對任意長度視頻、任意長度行為進行端到端的檢測[37]。類似對C3D網絡進行改進的還有CDC網絡,該網絡首次將卷積、反卷積操作應用到行為檢測領域,在實現端到端學習的同時,做到了對每一幀的預測(per-frame action labeling),取得了較好的效果[38]。
3 異常行為識別分類方法
針對視頻監控中異常行為(全局異常,局部異常)的檢測問題作為計算機視覺中的具有挑戰性的任務近年來已有重要的進展,根據學習過程中需要用到的樣本類型,可將分類的方法歸納為監督、半監督和無監督三種方式,常用的異常行為識別分類方法如圖6所示。
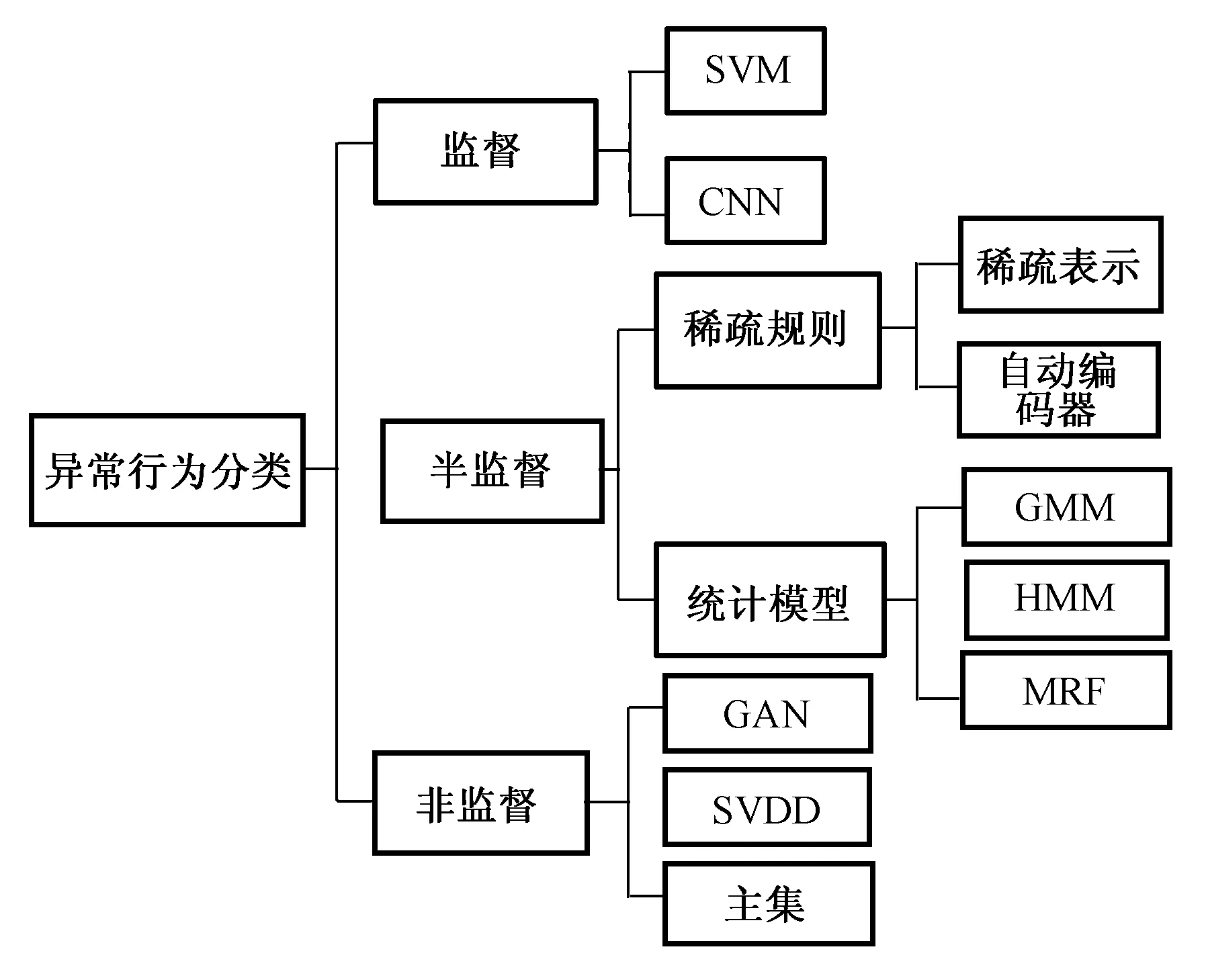
圖6 異常行為分類方法框圖
Fig.6 Block diagram of abnormal behavior classification
3.1 有監督異常行為分類方法
監督的分類方法需要在建模之前對所有的正常數據和異常數據都進行標簽標記,屬于傳統的分類問題,對于視頻異常檢測來說是二分類的問題,經典監督分類方法包括支持向量機(Support Vector Machine,SVM),例如文獻[39]提出的基于遺傳算法特征選擇與支持向量機(SVM)訓練混合優化模型。該方法為在短的時間內快速獲得最優特征子集和SVM參數,提高監控視頻異常檢測的準確性,采用自適應模擬退火遺傳算法(Adaptive Genetic Simulated Annealing Algorithm,ASAGA)進行特征選擇。ASAGA通過模擬退火算法(Simulated Annealing Algorithm,SA)的局部搜索能力大大改善了遺傳算法(Genetic Algorithm,GA)的慢收斂和復雜度高的問題。除此之外,Kim H等人基于測地線圖 (geodesic graph)和支持向量機(SVM)分類器對人體行為異常識別進行研究,該算法根據對人體關節的估測完成異常檢測,然而異常檢測效果對被檢測到的人體區域較為敏感[40]。近年,深度學習和云計算技術的飛速發展為計算機視覺領域取得突破性的發展,卷積神經網絡作為最新監督學習方法被廣泛應用于擁擠場景中的異常行為檢測研究,如文獻[8,33]都是采用監督的方法先對所提取的含有運動信息的時空興趣塊進行標簽標記,并作為三維卷積神經網絡的連續幀輸入進行訓練,最后由訓練得到的模型對測試集中的時空興趣塊進行異常判別,這種基于卷積神經網絡的視頻異常檢測方法很大程度上提升了異常檢測的速度和效率。
管棚灌漿孔封孔應采用“機械壓漿封孔法”或“壓力灌漿封孔法”,用濃漿(0.5:1)全孔一次性封孔。封孔壓力為該孔最大灌漿壓力。如該段灌漿結束為最濃一級水灰比(0.6:1)時,可不進行置換濃漿,直接封孔。
3.2 半監督異常行為分類方法
采用半監督方法進行訓練時只需要對正常的視頻數據進行標簽標記,根據分類原理半監督方法可分為基于規則和基于模型的方法。基于規則的半監督方法通過對只含有正常樣本訓練集進行規則學習,將測試階段任一不符合此規則的樣本判為異常,最常用的基于規則的半監督分類方法是稀疏表示,例如文獻[41]提出一種基于規則的稀疏編碼方法來檢測異常行為,雖然這種方法可在較短的執行時間(每秒150幀)內取得完成異常檢測,但其效果對閾值選擇過于敏感。Zhu Xiaobin 等人將稀疏重構代價引入正常字典衡量測試樣本中的異常,該方法在稀疏重構的每個主要成分引入先驗權重,與其他的方法相比有更好的魯棒性[42]。為了克服訓練樣本的缺乏,實現更精確的檢測,文獻[43]提出動態更新的雙稀疏字典表示方法,該方法從只包含正常樣本的訓練樣本集得到正常字典,然后通過稀疏表示方法和正常字典對測試樣本進行分類,如果分類結果是正常,則將這一特征加入到正常字典進行字典的動態更新,如果分類結果為異常,則將這一特征動態更新到異常字典中。目前大部分用于解決異常分類問題的稀疏表示方法在構造字典時并沒有將結構信息考慮在內此外,因此,Yuan Yuan等人通過正常數據訓練得到結構字典,并在測試階段根據所提出的參考事件的概念即當將正常事件作為參考事件進行訓練時,相較于異常事件,正常事件與參考事件具有更強的相似性,將無法用結構字典表示的行為判為異常行為[44]。基于模糊規則,Albusac等人通過自動動態地設置正態分量的權重提高異常檢測的效率[45]。Chen Zhengying等在視頻異常事件檢測研究中采用基于模糊聚類方法和多個自動編碼器的框架,該框架利用模糊聚類對運動目標的運動軌跡進行提取和分組并使用訓練階段聚類后的編碼實現了視頻中的異常行為檢測與定位[46]。
在基于模型的方法中,通常采用正常樣本進行模型構造,由于異常樣本總是偏離于由正常樣本構成的模型,因此在測試階段時通常將偏離于模型的樣本判為異常。常用的模型有:高斯混合模型(Gaussian Mixture Model,GMM)、馬爾可夫隨機場(Markov Random Field,MRF)、隱馬爾可夫模型(Hidden Markov Model,HMM)。如文獻[17]利用人群分布信息和人群速度信息估計由正常行為構建的高斯混合模型的參數,并對異常人群行為進行檢測。隱馬爾可夫模型作為標準馬爾可夫模型的擴展是在標準馬爾可夫模型基礎上添加了可觀測狀態集合以及這些狀態與隱含狀態之間的概率關系。Weiya R等人通過隱馬爾可夫模型,將提取的軌跡信息作為衡量標準來判別測試樣本中的時空信息塊是否存在異常[47]。文獻[21]中采用時空MRF模型完成對視頻的半監督異常檢測,該方法首先將視頻序列在時空內進行網格分割,并采用概率主成分分析(Mixture of Probabilistic Principal Component Analyzers,MPPCA)獲取網格的局部光流信息并對應到MRF圖的節點,通過MPPCA模型計算MRF模型參數對異常事件進行檢測,同時完成對MPPCA和MRF的參數更新。Hajananth N等人在訓練階段采用高斯混合模型進行聚類,在測試階段采用基于馬爾可夫的隨機場的高斯混合模型(GMM-MRF)對測試樣本進行判別,取得了較好的異常檢測效果[18]。此外,文獻[48]提出基于社會力模型的視頻異常行為檢測和定位方法為異常檢測研究提供了新思路。
3.3 無監督異常行為分類方法
無監督的檢測方法屬于典型的聚類問題,無需事先獲得任何的先驗知識,單獨依靠樣本數據之間的連接完成正常事件的聚類和建模,然后把小概率的或相似度非常低的事件看作異常事件,如此完成異常判斷。Alvar M等人采用主集(dominant set)的無監督學習框架實現了高效的異常行為檢測,這種方法與其他聚類方法相比具有更好的魯棒性[49]。此外,文獻[41,50]采用非負矩陣分解(Non-negative Matrix Factorization,NMF)對特征空間學習,并使用支持向量數據(Support Vector Data Descryiption,SVDD)在特征空間通過聚類程度檢測出異常。在深度學習方法中生成式對抗網絡可以實現無監督的學習,Mahdyar Ravanbakhsh等人通過生成式對抗網絡(Generative Adversarial Nets,GAN)中生成模型和判別模型之間的博弈實現監控視頻中的異常行為檢測與定位。該方法通過生成式對抗網絡對正常場景的幀圖像和對應的光流圖的訓練得到場景中正常行為的內部表示,并在測試階段將測試數據的外觀表示和運動表示與正常數據進行比較,由于存在異常的區域無論是外觀表示或是運動表示都與正常數據有很大的不同,通過計算局部符合程度檢測出異常所在區域[51]。
3.4 異常行為分類方法優缺點分析
基于監督的視頻異常檢測方法易于操作和理解,可以充分利用先驗知識控制訓練樣本的選擇,并通過反復檢驗訓練樣本提高異常檢測的精度如SVM[39]C3D[8,33]。然而這類基于監督的方法主觀因素較強,需要花費大量的人力和時間對訓練樣本進行選擇和評估,同時這種方法無法自動調整異常的數據并自適應的更新異常或者自動生成新的異常模式,因此往往對應用場景具有局限性即對于不同的場景需要重新設計檢測算法。基于規則的半監督檢測方法如稀疏表示[41-44]易于操作,但計算復雜且需要強大的內存。基于模型的半監督分類方法運算速度快、模型簡單容易建立,但是模型的分類效果對多個參數敏感,同時這種方法很容易將訓練中沒有出現過的正常數據錯判為異常[17-18,21,47-48]。無監督的檢測方式無需獲得任何先驗知識,運算快捷簡便,但需通過大量的分析和處理才能得到可靠的分類結果,例如GAN網絡盡管可以通過無監督的方式得到視頻場景中正常行為的內部表示,但是最終測試數據中異常目標的檢測與定位還需要靠與正常數據的符合程度分析來獲得[51]。
4 視頻異常檢測數據集
近年來最常用的數據集有UCSD行人異常數據集、UMN全局恐慌數據集、Hockey Fight暴力行為數據集[6]和LV數據集[52],本節將介紹這幾個標準實驗數據集,各數據集中正常及異常示例如圖7所示。
UCSD數據集分為兩部分Ped1和Ped2,二者都是由一個安裝在固定高度的攝像機俯瞰行人獲得的視頻,數據集中的人群密度隨著時間的推移不斷變化。Ped1中包含34個用于訓練的正常視頻序列及36個用于測試的含有異常的視頻序列,其中每個視頻序列的幀長都為200,每幀分辨率為158×238。Ped1主要描繪的是人群在視頻畫面中的垂直方向移動,人群走向主要為走向和遠離攝像頭,具有一定的透視畸變。Ped2描繪的是人群的水平移動,包含16個正常的訓練序列和12個包含異常的測試視頻序列,每個序列的幀長由120到170不等,每幀的分辨率為360×240。UCSD數據集中訓練樣本只含正常行為,測試集中的某一幀中可能不存在、存在一個或多個異常行為,其中異常類型主要有:自行車、滑冰、小型汽車,輪椅等。Ped1中的物體分辨率較低給識別造成一定的難度而Ped2中的遮擋問題比較嚴重,因此,UCSD是一個具有挑戰性的擁擠場景下的局部異常數據集。
UMN數據集中的異常屬于全局異常,主要表現為恐慌、四處逃散。UMN數據集總時長為4分17秒,幀速率大小為30幀/秒,每幀大小皆為320×240。UMN數據集含有室內室外三種場景下的11個視頻片段,包括兩個彩色草坪場景片段,六個黑白長廊視頻片段及三個彩色廣場場景片段,視頻內容皆為正常的行走或游蕩從某一幀忽然開始四處逃散直至消失在視頻畫面中。
Hockey Fight數據集[6]描述的是曲棍球比賽中的暴力斗毆異常行為,共分為兩個部分:暴力斗毆及正常的曲棍球比賽,兩部分分別含有500個獨立的視頻片段,每個視頻序列的幀速率為25幀/秒,每幀大小為360×288。




圖7 部分數據庫正常、異常幀示例
Fig.7 Examples of normal and abnormal frames in some databases
5 性能評估準則
異常檢測性能評估的目的是在衡量某一異常檢測方法效果的基礎上將這一方法與其他各類方法進行比較,如此驗證新方法的先進性和可靠性。關于視頻監控系統的評估項目有很多,例如,由美國國家標準與技術研究院(National Institute of Standards and Technology,NIST)發起的全球視頻內容分析比賽TRECVID(TREC Video Retrieval Evaluation)采用SED(Surveillance Event Detection)評估監控系統實時檢測的效果[53]。
在視頻異常檢測領域,兩個常用的異常檢測評估標準是等誤差率(Equal Error Rate,EER)和ROC曲線下的面積AUC(Area Under Curve)。這兩個標準來自于接收機操作特性曲線(Receiver Operating Characteristic Curve,ROC),該曲線非常適用于性能比較。等誤差率EER是ROC曲線上假陽性率FPR(False Positive Rate:正常行為被認定為異常)與假陰性率FNR(False Negative Rate:異常行為被認定為正常)相等的點即ROC曲線與ROC空間中對角線([0,1]-[1,0]連線)的交點。如果一個識別算法ROC曲線中的EER越小AUC越大,則表明這個方法的性能越好。
基于ROC曲線的評估標準分為三個級別:幀級準則(frame level criterion),像素級準則(pixel level criterion)及雙像素級準則(dual pixel level criterion)。異常檢測領域部分優秀方法在幀級和像素級的評估準則下UCSD Ped1的實驗效果比較如表1所示,對UCSD Ped2的實驗效果比較如表2所示。UCSD Ped1、Ped2中雙像素級EER(β=5%)比較如表3所示。
在幀級準則中,若檢測出某一幀至少含有一個異常行為則將這一幀記為異常幀,該標準僅關注異常行為的時間定位精度,不考慮異常的空間定位準確度。因此,當采用這一準則進行性能評估時可能發生假陽性的巧合預測,即在某一存在異常行為的幀中并未檢測出真實異常行為而是將某一正常行為錯判為異常,如此巧合地將檢測結果認定為檢測正確。
表1 UCSD Ped1中幀級和像素級EER、AUC比較
Tab.1 EER and AUC for frame and pixel level comparisons on UCSD Ped1%
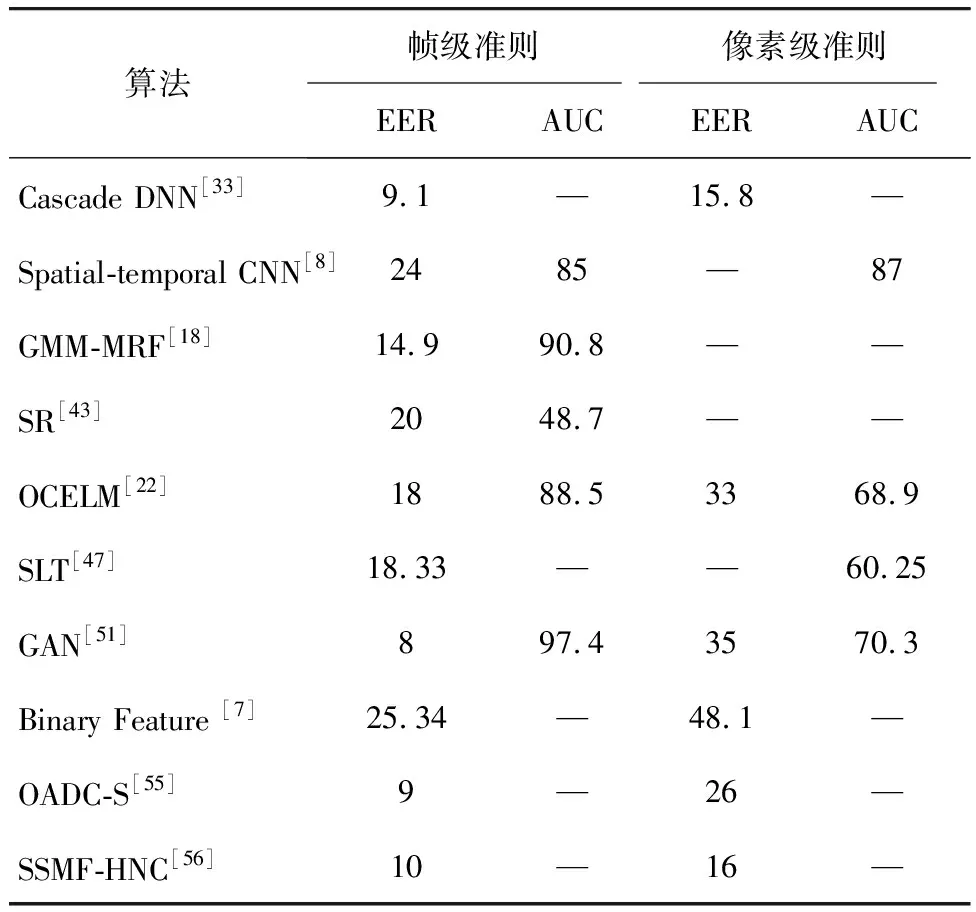
算法幀級準則像素級準則EERAUCEERAUCCascade DNN[33]9.1—15.8—Spatial-temporal CNN[8]2485—87GMM-MRF[18]14.990.8——SR[43]2048.7——OCELM[22]1888.53368.9SLT[47]18.33——60.25GAN[51]897.43570.3Binary Feature [7]25.34—48.1—OADC-S[55]9—26—SSMF-HNC[56]10—16—
表2 UCSD Ped2中幀級和像素級EER、AUC比較
Tab.2 EER and AUC for frame and pixel level comparisons on UCSD Ped2%
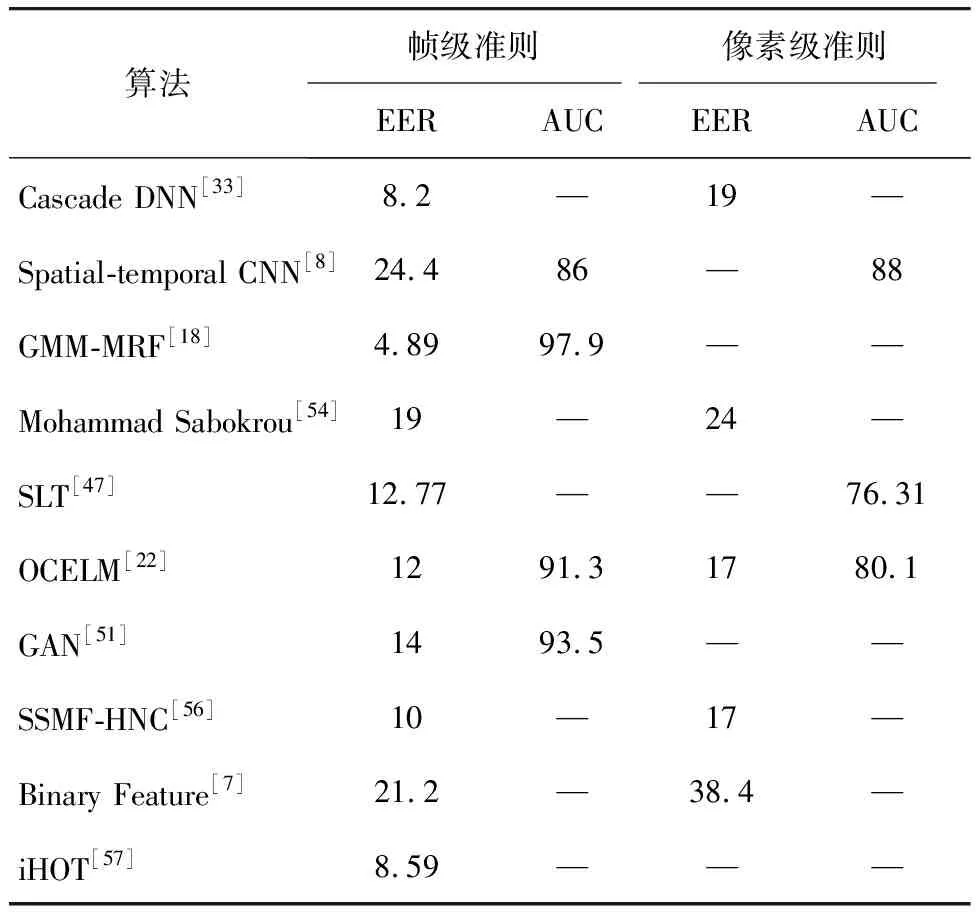
算法幀級準則像素級準則EERAUCEERAUCCascade DNN[33]8.2—19—Spatial-temporal CNN[8]24.486—88GMM-MRF[18]4.8997.9——Mohammad Sabokrou[54]19—24—SLT[47]12.77——76.31OCELM[22]1291.31780.1GAN[51]1493.5——SSMF-HNC[56]10—17—Binary Feature[7]21.2—38.4—iHOT[57]8.59———
表3 UCSD Ped1、Ped2中雙像素級EER比較
Tab.3 EER for dual level comparisons on UCSD Ped1 and Ped2%

算法UCSD Ped1UCSD Ped2Mohammad Sabokrou[54]—27.5Cascade DNN[33]24.523.8
在像素級準則中,只有將某一幀中所有真實異常行為所在像素塊的40%以上被正確檢測到,這一幀才可被認定為有效異常檢測的異常幀,否則視為判錯。像素級標準需要對異常檢測的時間和空間定位精度進行評估,因此更為嚴格和詳細,評估結果也更為可靠。在采用這一準則進行性能評估時,有研究人員采用異常檢測率(Rate of Detection,RD)代替EER對方法的異常檢測效果進行評估,異常檢測率越大方法的異常檢測效果越好。在實際評估時,若某一幀中被檢測到多處存在異常的區域,其中只有一處真實標簽為異常其他區域皆為幸運猜測的錯判,在采用幀級和像素級準則進行評估時依舊將這一判別視為檢測正確,因此,研究者引入了雙像素級評估準則[45,54]對異常檢測效果進行更為準確、嚴格的評估。
在雙像素級準則中若某一幀被視為異常幀需滿足:1)這一幀滿足像素級準則標準下的異常判定;2)被檢測為異常的區域至少β%(如10%)真實標簽為異常。這一準則不僅要求在時間和空間上對異常進行準確的檢測和定位對于假陽性錯判也十分敏感,相較于其他準則,該準則對異常事件檢測的準確度的檢測更為可靠。
6 結論
本文討論了視頻監控系統的不同層次,即運動目標檢測與前景提取、特征提取和行為表示以及異常行為識別分類方法,首先對運動目標檢測、特征提取與描述常用方法進行總結,然后針對行為建模的不同分類方法進行了歸納,最后討論了視頻異常檢測研究常用的數據集以及異常檢測性能的評估標準。
近年來,視頻異常檢測技術快速發展,取得不小的進展,但這項技術存在局限,主要的局限有以下四種:1) 在復雜場景下,選擇合適的運動目標的特征尤其是異常目標特征是一項十分重要且困難的任務。2) 相對于正常事件可用于訓練的異常事件數量較少。3)大多數異常行為識別算法只針對單個攝像機,與實際情況不符,因此研究人員將多個攝像機捕捉移動對象的不同視圖將組合起來進行下一步的研究,盡管這種方法效果較好,但是過于復雜耗時并不適合實時應用。4)某行為是否異常取決于運動發生的場景、動作的時間和地點,因此若將某方法應用到另一場景時需要重新進行訓練建模。隨著深度學習和云計算技術的發展,若將包括所有可能場景的大量數據投入訓練,得到具有強大學習能力以及場景適應力的模型,將會使異常檢測技術得到歷史性的突破。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
