基于半參數模型的風險度量方法及其應用
2019-03-28 05:50:34胡宗義唐建陽
統計與決策 2019年5期
關鍵詞:模型
胡宗義,唐建陽,萬 闖
(湖南大學 金融與統計學院,長沙 410012)
0 引言
尋找合適的風險度量工具是風險測度工作的第一步也是重要的一步。在度量風險的眾多方法中,在值風險(VaR)因其概念直觀、計算簡單等特點逐漸成為度量風險的主要工具。但VaR存在一些缺陷而飽受爭議,如不滿足風險可加性條件、無法有效利用分布總體信息以及對極端損失不敏感。鑒于VaR種種缺陷,Artzner等(1999)[1]提出使用預期不足(ES)代替VaR。ES定義為超出VaR部分資產損失的平均值,即ES(τ)=E(Y|Y>VaR(τ))。與 VaR 相比,ES充分利用了資產損益分布的尾部信息,其大小也與損失的規模緊密相關,重要的是Rossi等(2009)[2]證明了ES為一致性的風險度量工具。
盡管ES從定義上來看克服了VaR的有關缺陷,但是測度ES卻并不是一項容易的工作。現有度量ES的模型大多為參數模型,該類模型的一般步驟為首先假定收益序列服從某種分布,然后計算給定水平下的分位數作為VaR的估計值,根據VaR估計值對尾部的分布求積分。然而參數ES模型至少存在兩點不足:第一,收益序列的分布隨著時間的變化而變化,因此很難用一個合理的假設來刻畫其分布類型;第二,在參數模型中,ES計算往往會涉及到積分運算,而在很多分布假定下,ES的積分運算不存在閉形式,因而會帶來很大計算壓力。
本文采用兩種半參數模型度量ES,兩種模型都是基于Engle和Mangnelli(2004)[3]提出的條件自回歸在值風險(CAViaR)模型基礎上得到。本文將兩類模型引入到我國滬深股市中,實證分析兩種模型在度量ES的效果上的優劣,進而總結兩者模型的異同、優缺點等,為相關金融從業人員提供一種新的度量ES的手段,從而完善并發展我國股市風險度量技術。
1 模型構建
1.1CAViaR模型
CAViaR模型是由Engle和Mangaelli(2004)[3]提出,該模型是以分位數回歸為基礎,根據市場沖擊特點來調整自回歸形式,直接得到VaR的估計值。鑒于CAViaR模型的種種優點,使其迅速成為度量VaR的常用方法之一。CAViaR模型的一般形式如下:

其中ft(β)表示t時刻收益率的條件分位數(即VaRt),l(xt-j;Ωt)表示t-j時刻有限階滯后可觀測變量的函數并且是關于Ωt-j是可測的,它可以是收益率觀測值或其他影響VaR大小的因素。VaR的滯后項βift-i(β)可以確保分位數更平滑的隨著時間變化。Engle等給出了4種CAViaR模型形式,但是黃大山和盧祖帝(2004)[4],劉新華和黃大山(2005)[5]分別用Chow檢驗和Hansen檢驗已經證明了Engle力薦的四種CAViaR模型不能很好地刻畫中國股票市場特征。鑒于此,后來不斷有國內學者提出各種改進的特征模型,用以豐富國內股票市場風險度量的研究,如王新寧和宋學峰等(2008)[6]提出的間接TARCH-CAViaR模型、張穎和孫和風(2012)[7]提出的GJR-CAViaR模型。結合國內外學者研究成果,本文選取以下四種模型形式為最終的實證模型。
非對稱斜率(Asymmetric Slope,AS)—CAViaR:
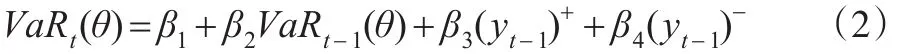
間接GARCH(Indirect GARCH(1,1),IG)—CAViaR:

間接TARCH(Indirect TARCH,IT)—CAViaR

GJR-CAViaR模型:

其中 (yt-1)+=max(yt-1,0),(yt-1)-=-min(yt-1,0),yt為金融資產收益序列。
1.2CARES模型
同樣,ES作為特殊的條件VaR,也應該存在自相關的特征,因此可以用自回歸方程刻畫ES的變化過程,其一般形式為:
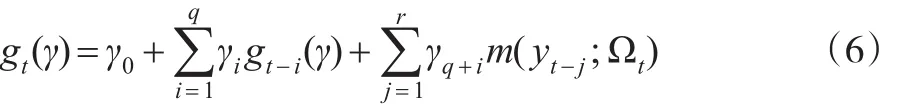
其中γ為模型參數,γigt-i(γ)為 ES 的自回歸項,m(yt-j;Ωt)表示t-j時刻有限階滯后可觀測變量的函數并且是關于Ωt-j是可測的。CARES模型的估計ES分為兩步。
第一步:估計給定水平θ下的VaR值,即VaRt(θ)=ft(β),即計算與該CARES模型具有相同形式的CAViaR模型。對于CAViaR模型采取分位數回歸的方法估計參數,其目標函數為:

從第一步結果可以獲得β和VaRt(θ)的估計值
第二步:估計ES。ES定義為超出VaR部分的均值,因此在第二步中,只需對收益率的觀測值超出相應的VaR部分進行建模。但是與式(7)中目標函數采用絕對值距離之和不同,在參數模型中,ES大小與收益率的波動率呈明顯的平方關系。由此類推,在第二步中,用模型(6)估計ES,即gt(γ)=ESt(θ),模型(6)參數估計采用平方損失函數:

1.3CARE模型
條件自回歸expectile(CARE)模型是Taylor在2008年提出來,CARE模型是在Engle和Mangnelli(2004)[3]的CAV-iaR模型的基礎上稍作改進得到,兩者之間既相似但不完全相同。主要區別在于模型參數的估計方法上,CAViaR模型主要是基于Koenker和Bassett(1978)[8]提出的分位數回歸的基礎上得到,而CARE模型則是在Newey和Powell(1987)[9]提出的expectile回歸得到的。用expectile度量VaR和ES的一個重要原理是分位數與expectie之間存在著一一對應的關系。既然VaR可以看作某一分位數的估計值,因此可以用相對應水平下的expectile估計值度量VaR,進而獲得ES估計值。
本文首先來介紹expectile與ES之間的關系。與分位數回歸考慮絕對值偏差不同,expectile回歸考慮如下非對稱平方損失函數:

其中,ω∈(0,1)反映了邊際損失的非對稱程度,稱為謹慎性水平(prudentiality level)。最小化式(9)得到的估計值稱為Y的ω-expectile,令其一階導數等于0可以推導出:

其中,F為金融時間序列收益y的累積概率密度函數,在大多數情形下,收益均值為0。Efron(1991)[10]證明expectile與分位數之間存在著一一對應的關系,即m(ω)=q(θ),這里ω要求滿足低于m(ω)的觀測值占比為θ。q(θ)為VaR的估計值,因此可以用m(ω)度量VaR大小。Yao和Tong(1996)[11]證明來謹慎性水平ω與θ之間代數關系。q(θ)為分布的θ分位數,因此得到F(q(θ))=F(m(ω))=θ。式(10)左邊即為ES定義表達式,因而expectile與ES之間的關系為:

CARE模型與CAViaR模型具有相同的結構,但與式(6)中CAViaR模型用分位數回歸求解參數不同,CARE模型通過ALS回歸求解參數,其表達式為:
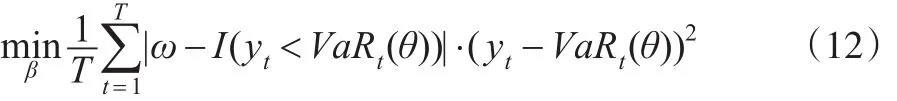
求解式(12)即可求得CARE模型參數β?以及VaR的估計值。利用式(11)expectile與ES之間的關系可以直接得出ES估計值:
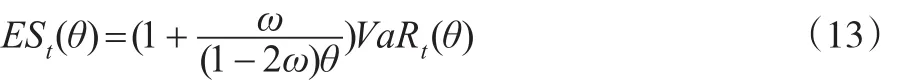
這里ω滿足對于給定的θ,其對應的ω-expectile的估計值落在該值下方的樣本比例為θ。
1.4 ES評估檢驗
CARE和CARES模型不僅可以刻畫ES的動態波動序列,而且可以預測樣本ES值,但是其預測效果需要采取特定ES檢驗。為了評估ES估計行為,本文采取McNeil和Frey(2000)[12]提出一種評估樣本外ES行為的假設檢驗,該檢驗方法主要關注超出VaR的收益率觀測值部分,其原假設為該部分觀測值與相應的ES之間的標準偏差是服從零均值且獨立同分布的。但CARE與CARES模型一個顯著特征是模型不做任何分布性假設,因而只能通過Bootstrap方法來構造檢驗統計量,有關ES檢驗的Bootstrap方法的詳細內容可以參考Efron和Tibshirani(1993)[13]。需要指出的是該方法只適用于樣本外的ES檢驗,并且可以通過R軟件實現,讀者只需加載rugarch包中ESTest函數即可得到檢驗結果的p值。
2 實證分析
2.1 數據選取以及描述性統計
本文選取中國股市上最具代表性的上證綜合指數(SSEI)和深證成份指數(SZSEI)兩個指數每日收盤價作為本文研究對象。這是因為上證綜指和深圳成指幾乎涵蓋了大部分的上市公司,其中深交所有1524家,上交所有944家。這兩類指數充分考慮了國民經濟的各個行業,具有很強的代表性。將兩種指數100倍的每日對數收益率作為研究對象,其計算公式為:ri,t=100×(lnpi,t-lnpi,t-1),其中pi,t表示第i種指數第t期的每日收盤價。選擇的時間跨度從2007年1月4日到2016年12月30日,共計2431組數據。其中前1931組作為訓練樣本,后500組數據構成測試樣本。
本文數據來源于銳思數據庫,表1概括了兩種指數基本統計信息。由峰度和偏度指數可以看出,兩種指數樣本數據都呈現明顯的高峰厚尾特征,并且都是左偏的。Ljung-Box Q(10)統計量表明在1%顯著性水平下,兩種指數存在顯著的序列相關性。兩種指數的ADF檢驗表明其為平穩時間序列,可以進行建模。

表1 兩種指數收益率的描述性統計
2.2 模型參數估計結果
給定置信水平為95%和99%,分別用CARE和CARES模型對上證綜指和深證成指樣本內數據建模,模型的形式采用前文給定的式(2)至式(5)形式。但是對于CARE模型,必須首先確定θ=5%,1%對應的謹慎性水平ω,ω滿足低于ω-expectile值的樣本占總體得比例為θ,以得到水平為θ的ES估計值,便于與CARES模型得在同一水平下得到結果做比較。由于本文提出的ES模型一個顯著特征是不對收益做任何分布性假設,即收益分布類型未知,因此使用Yao和Tong(1996)[11]中給出的公式確定ω是行不通的。鑒于此,本文采用三次樣條插值法來確定兩種指數在不同CARE模型下的ω值,結果見表2所示。

表2 給定α分位數水平下對應的ω(×100)
分別用上證綜指和深圳成指的樣本內1931組數據作為訓練集合,時間區間為2007年1月4日到2014年12月15日,這其中中國股市先后經歷了2008年金融危機以及2009年歐債危機,股市收益率也呈現明顯的波動率聚集現象。而后500組數據作為預測樣本,在預測時間內中國股市經歷一次較大的波動,可以用于評估CARE和CARES模型預測行為的優劣。
2.3 ES預測績效評估
通過訓練樣本可以獲得模型的參數,進而可以獲得樣本外ES的估計值。為了評估模型對樣本外ES預測行為,本文采取前文提出的檢驗ES的Bootstrap檢驗方法,得到的p值越大說明越不能拒絕原假設,因而該模型刻畫ES預測行為的效果就越好。此外ES的預測效果還應與估計結果的失敗率有關,即實際觀測值超出ES的比率。良好的ES預測行為要求模型的失敗率越小,而Bootstrap檢驗的p值越大。

表3 模型對比檢驗結果
從表3不難發現,對于上證指數,CARES模型的Bootstrap檢驗的p值均大于相應的CARE模型p值,而且其失敗率均小于或等于CARE模型的失敗率。這說明就上證指數而言,無論水平是1%還是5%的樣本外ES估計值,CARES模型預測效果均優于CARE模型。對于上證指數水平為1%的ES估計,四類模型檢驗p值均遠遠大于0.05,反映出四種類型的模型均可以較好地刻畫中國股市的未來變動情形。而對于5%的ES估計,只有GJR-CARE(S)模型通過Bootstrap顯著性檢驗,因而在此情形下,可選擇GJR模型作為最終的預測模型。
而對于深證成指,CARES模型預測結果表現得與CARE模型不相伯仲。以深證成指1%ES結果為例,ITARCH、GJR-CARES模型的Bootstrap檢驗和失敗率兩項指標均優于對應的CARE模型類型,因而可以選擇ITARCH和GJR-CARES模型作為深證成指最終預測模型。同理,對于深證成指5%ES估計而言,綜合考慮,選擇IGARCH-CARES模型作為最終的預測模型。
2.4CARE與CARES模型對比分析
從CARE和CARES模型的建模到實證分析整個過程,本文可以總結出這類半參數ES模型的優點:第一,CARE和CARES模型均為半參數模型,避開了對收益分布做出的任何假設,從而克服了參數模型中可能設置的不合理的假設。這對于當前中國股市而言尤為重要,因為隨著我國利率市場化的推進以及資本項目的開放,我國股市的發展面臨的風險將日益復雜,各種政策性和人為因素的影響使得股市風險度量很難找到合理分布假設。第二,模型的條件自回歸方程設置比較靈活,可以針對不同問題研究背景,選擇合適的風險度量模型。例如本文的四類模型在刻畫上證綜指5%ES序列時,結果表現得都不是很理想,因而可以繼續研究,發掘出更適合的模型使得兩項指標都達到最優,這是本文的進一步工作。
從前文的結果可以得出,就我國滬深股市而言,CARES模型刻畫股市預測的效果要明顯優于CARE模型。這是由于CARE模型的建模過程決定的。CARE模型主要通過expectile回歸求解模型參數,利用expectile與ES之間存在代數關系,從而得到ES的估計值。從建模的方式來看,該模型是通過間接方法獲取ES估計值,導致了建模過程中存在兩處明顯缺陷,會直接影響最終ES預測結果。第一,為了估計模型參數,首先要選定θ=1%,5%水平下對應得謹慎性水平ω,本文利用樣本內收益率通過三次樣條插值法得到ω的估計值。但是當預測樣本外的ES大小,CARE模型的謹慎性水平ω往往會隨著時間的變化而變化,因此對最終預測結果產生影響。第二,CARE模型利用式(13)估計ES,為了得到ES估計值,必須首先估計VaR。而在VaR的估計中,隨著時間變化的ω值同樣會影響VaR的預測結果,進而會導致ES估計誤差的增加。
而CARES模型則直接借鑒CAViaR模型的建模思想,將ES的波動序列視為一個條件自回歸過程,只需給定歷史收益率的觀測值和置信水平,通過一定的優化算法就可以得到ES的估計序列,避免了其他外生性因素使得ES估計產生誤差。此外,與CARE模型通過VaR的遞歸方程間接反映出ES波動特征不同,CARES模型直接刻畫ES預測行為,可以很好地解釋收益率序列中存在的波動率聚集現象和高峰厚尾特征。這對相關從業人員研究我國股市波動特征,考察市場風險的演化規律,具有重要的現實意義。
3 結論
本文詳細介紹了度量預期不足(ES)的兩種重要的半參數模型:CARE模型和CARES模型。兩種模型均與CAViaR模型存在關聯,并且都借鑒了CAViaR模型的建模優點,無需對收益分布做出假設等。通過將兩種模型代入到我國滬深股指2007年1月4日到2016年12月30日近十年的歷史數據中,得到樣本外ES預測序列結果。通過半參數ES模型的Bootstrap檢驗與失敗率兩種指標綜合分析,得出CARES模型對于中國滬深股市的風險度量效果要優于CARE模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
