變體上下文窗口下的詞向量準確性研究
2019-04-04 03:17:40胡正楊志勇
現代電子技術 2019年6期
關鍵詞:深度學習
胡正 楊志勇
關鍵詞: 詞向量; 詞嵌入; 上下文窗口; 自然語言處理; 神經網絡; 深度學習
中圖分類號: TN912.34?34; TP391.1 ? ? ? ? ? ? 文獻標識碼: A ? ? ? ? ? ? ? ? ?文章編號: 1004?373X(2019)06?0146?03
Abstract: The word vector accuracy affects the operation of natural language processing tasks considerably. Word vectors are generated by the means of word embedding. In word embedding methods, the target words and their contexts are treated as inputs of the training. As a result, context determination has an important influence on word embedding. Therefore, the influence of variant context windows on word embedding accuracy is studied by using the word2vec word embedding method in this paper. A series of experiments were carried out according to the context windows with variant widths, offsets and weights. The experimental results show that, the variations of the context windows do not have a significant effect on the overall accuracy of training results, but have a significant effect on various specific words, so it is concluded that quite many words have their own demands in suitability of context windows, so it is difficult for a unified context window to implement the optimal training for all words.
Keywords: word vector; word embedding; context window; natural language processing; neural network; deep learning
0 ?引 ?言
近年來,深度學習在自然語言處理領域取得了諸多進展。在這些自然語言處理任務中,都將詞向量作為其基礎。詞嵌入(Word Embedding)是一類語言建模技術,通過詞嵌入可將詞匯表中的單詞和短語映射到n維詞向量上(維度一般遠小于詞匯表)。2000年Bengio等人采用詞嵌入并結合機器學習取得了較為突出的研究成果[1]。將詞向量作為輸入,可以很好地實現語法分析[2]、語義分析[3]、命名實體識別[4]等任務。詞嵌入的實現方法有若干種,包括用神經網絡產生[5?6]、對詞共生矩陣降維[7?9]、通過概率模型計算[10]以及顯式上下文表征[11]等。其共同點都是依據目標單詞與上下文單詞的出現概率或次數來構建詞向量的。
其中word2vec是目前被廣泛應用的基于神經網絡的詞嵌入方法,其特點是借由神經網絡隱含層來發現數據特征,即產生詞向量各個維度中的數據,這是一種在非監督學習中常用的特征取得方式。word2vec包含兩個可選算法:Skip?gram和CBOW[5,12],所得到的詞向量不僅可以表征單詞之間的相似性,亦能表征單詞對之間的關系、對應關系[5]。如“man,woman”和“king,queen”,其詞向量的關系可表示為:[Vecking-Vecman≈Vecqueen-Vecwoman,]即進行[Vecking-Vecman+Vecwoman]的詞向量運算后,其結果最為接近的詞向量是[Vecqueen]。
這種向量運算(稱其為類比運算)可以在單詞的類比關系、對應關系上得到很好的驗證[13],一般來說其結果的正確率[11,14]可以達到40%~60%。類比運算是否正確體現了詞向量表征語義是否準確。通過在各種變體上下文窗口下進行詞嵌入,并使用類比運算研究其所得到的詞向量的影響。
1 ?詞向量及類比運算

2 ?上下文窗口
詞嵌入將目標單詞及其上下文作為訓練的輸入,上下文所在的連續文本區間也就是上下文窗口。在訓練中,一般對各個上下文詞向量賦予一個權值[p∈0,1],且權值隨著距離目標單詞的距離變大而變小。目標單詞一般位于窗口的中心,設目標單詞的上文或下文單詞數[w]為上下文窗口寬度。則包括目標單詞在內,上下文窗口內的單詞數為[2w+1]。在word2vec中,窗口內單詞的權值[p]與其距離[d]的關系為:[p=w-dw],且[d∈[0,w-1]]。當它與目標單詞相鄰時:[d=0,p=1;]而距離最遠時[d=w-1]且[p=1w],這樣的窗口稱為遞減權值窗口,如果權值不變則稱為固定權值窗口。
在詞嵌入中,確定了語料庫和上下文窗口也就確定了訓練的輸入,因此上下文窗口的選擇將對詞嵌入的結果起到至關重要的影響。在各種變體窗口下,詞嵌入訓練結果的變化是主要研究內容。本文在一系列不同的上下文窗口寬度和形態的條件下進行了詞嵌入訓練,并且通過類比測試來評價詞向量的準確性。
3 ?測試內容
本文使用目前廣泛采用的維基百科英文語料庫進行詞嵌入,其開放性使得相關研究的可重復性較好。語料庫是在對維基百科英文頁面備份進行文本無關信息篩除得到,其文件大小為12.1 GB,包含2 113 849 195個單詞。
使用基于Python語言的word2vec來進行實驗,詞匯表為語料庫中出現次數不小于10 000的單詞所構成。采用的測試數據為word2vec項目的類比數據集,共19 545個類比。該數據集是詞向量中廣泛被使用的一個測試數據集,其中的類比關系包含:首都與國家(如:“Athens,Greece與Beijing,China”),角色關系(如:“boy,girl與brother,sister”),形容詞與副詞(如:“amazing,amazingly與happy,happily”)等14個類型。
4 ?測試結果
本文測試了在不同窗口寬度下的詞向量準確性。采用遞減對稱窗口時,詞向量的準確性隨著窗口寬度的增加而增加,且增幅逐漸減小直至逐漸下降見圖1。這主要是由于距離越遠的單詞與目標單詞逐漸失去關聯。
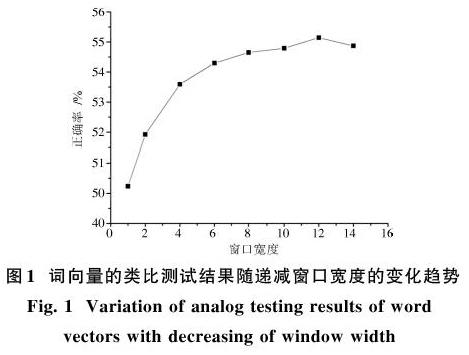
而采用定值窗口與遞減窗口相比,它在較快增加后更快地進入下降過程,如圖2所示。這主要是因為距離過遠的單詞與目標單詞之間關聯度過低,而較高的權值加大了噪聲信息。如果考慮窗口寬度無限大這一極限情況,每個單詞的訓練輸入將是其他所有單詞,詞向量將失去意義。
本文還進行了非對稱窗口下的測試,對于不同寬度和不同偏移量的窗口進行測試,偏移量大于0代表窗口向下文偏移,反之向上文偏移,實驗結果如圖3所示。在采用非對稱窗口時,詞向量的準確性在相對偏移量較小時沒有明顯變化,而相對偏移量較大時略微降低。例如在窗口單邊寬度為8,偏移為0時,正確率約為54.649%。而窗口偏移為-7時,其正確率約為52.960%;窗口偏移為7時,其正確率約為52.769%,兩者略低于偏移量為0的情況且彼此非常接近。從實驗結果可以看出:訓練結果的好壞與輸入的文本內容本身基本無關,而與偏移量的絕對值有關。例如,在窗口偏移分別為-7和7時,窗口內容僅有12.5%是相同的,而兩者的訓練效果相近。

以上的測試觀察和對比了詞向量準確性的高低。對于類比測試的具體差異,本文進一步觀察了7種不同寬度對稱窗口的測試結果與寬度為1窗口的測試結果的具體比較,如圖4所示。
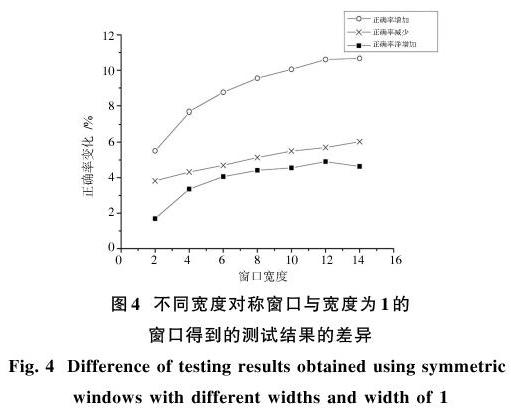
通過測試可知:結果的正確率并非隨著窗口寬度的增加而單純的增加,而是在增加大量正確測試結果的同時,也增加了大量的錯誤結果。可見,在以上過程中并非對于所有單詞有一致的上下文窗口尋優方法。
5 ?結 ?論
通過測試可知,上下文窗口的選擇對于詞嵌入的結果有較大影響:遞減窗口能夠得到的詞向量準確性高于定值窗口;在合理的范圍內(上下文窗口包含的單詞與目標單詞可能存在相關性的范圍),窗口越大得到的準確性越高;窗口偏移量較小時的訓練效果比偏移量較大時得到的準確性更高。通過進一步的測試發現各種上下文窗口只對詞匯表中某些單詞有更好的訓練結果,即大量的單詞擁有各自不同最優上下文窗口。
參考文獻
[1] BENGIO Y, DUCHARME R, VINCENT P, et al. A neural probabilistic language model [J]. Journal of machine learning research, 2003, 3: 1137?1155.
[2] SOCHER R, BAUER J, MANNING C D, et al. Parsing with compositional vector grammars [C]// Proceedings of 51st Annual Meeting of the Association for Computational Linguistics. [S.l.: s.n.], 2013: 455?465.
[3] SOCHER R, PERELYGIN A, WU J Y, et al. Recursive deep models for semantic compositionality over a sentiment treebank [J/OL]. [2017?03?13]. https://nlp.stanford.edu/~socherr/EMNLP2013_RNTN.pdf.
[4] SIEN?NIK S K. Adapting word2vec to named entity recognition [C]// Proceedings of the 20th Nordic Conference of Computational Linguistics. Vilnius: Link?ping University Electronic Press, 2015: 239?243.
[5] MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality [J]. Advances in neural information processing systems, 2013, 26: 3111?3119.
[6] BARKAN O. Bayesian neural word embedding [J/OL]. [2016?03?21]. https://arxiv.org/ftp/arxiv/papers/1603/1603.06571.pdf.
[7] L?BRET R, COLLOBERT R. Word embeddings through Hellinger PCA [J/OL]. [2017?01?04]. https://arxiv.org/pdf/1312.5542.pdf.
[8] LEVY O, GOLDBERG Y. Neural word embedding as implicit matrix factorization [J]. Advances in neural information processing systems, 2014, 3: 2177?2185.
[9] LI Y T, XU L L, TIAN F, et al. Word embedding revisited: a new representation learning and explicit matrix factorization perspective [C]// Proceedings of 24th International Conference on Artificial Intelligence. Buenos Aires: AAAI Press, 2015: 3650?3656.
(上接第148頁)
[10] GLOBERSON A, CHECHIK G, PEREIRA F, et al. Euclidean embedding of co?occurrence data [J]. Journal of machine learning research, 2007, 8(4): 2265?2295.
[11] LEVY O, GOLDBERG Y. Linguistic regularities in sparse and explicit word representations [C]// Proceedings of Eighteenth Conference on Computational Natural Language Learning. [S.l.: s.n.], 2014: 171?180.
[12] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space [J/OL]. [2013?09?07]. https://arxiv.org/pdf/1301.3781.pdf.
[13] ZHILA A, YIH W, MEEK C, et al. Combining heterogeneous models for measuring relational similarity [C]// Proceedings of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. [S.l.: s.n.], 2013: 1000?1009.
[14] MIKOLOV T, YIH W T, ZWEIG G. Linguistic regularities in continuous space word representations [C]// Proceedings of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Atlanta: Association for Computational Linguistics, 2013: 746?751.
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
