基于深度差異性網絡的真假面癱識別
2019-04-15 05:17:30管子玉許鵬飛辛曉瑜
西北大學學報(自然科學版) 2019年2期
管子玉,劉 杰,謝 飛,許鵬飛,辛曉瑜
(1.西北大學 信息科學與技術學院,陜西 西安 710127;2.上海交通大學 醫學院 附屬瑞金醫院,上海 200025)
面癱是一種常見病,發病范圍很廣,不受年齡限制,不僅會對患者的生活造成一定的影響,同時也會對其內心造成一定的打擊,嚴重影響著患者的身心健康。隨著面癱發病率的不斷增加,越來越多的學者開始關注面癱識別研究。
為實現面癱的自動識別,目前國內外諸多學者已對該方面進行了研究。他們通過關注靜態面部不對稱和動態面部變化、跟蹤面部關鍵點的運動差異、利用深度學習方法對關鍵點進行定位、利用深度卷積神經網絡(deep convolutional neural network, DCNN)提取特征等方法對面癱進行識別[1-6]。然而,這些方法均根據人臉的面部異常或不對稱情況進行判定,比較武斷地將面部不對稱或異常確定為面癱。現實中存在一些面部異常但并非是面癱患者的人,這種情況我們稱之為假面癱現象。由于研究者們忽略了假面癱現象的存在,使得現有的面癱識別方法存在誤判情況,從而在一定程度上降低了面癱識別的準確率。因此,針對上述存在的假陽性問題(稱為“假面癱”),目前的面癱識別研究領域需要一種更魯棒的自動化識別方法對真假面癱進行識別。
通過對真假面癱的圖像和視頻數據進行分析發現,面癱患者在重復做一個面部動作(如閉眼)時,患者每次所做動作幾乎無明顯差異,而讓假面癱對象在不同時刻重復做相同的面部動作(如正常人模仿面癱患者的動作)時,其動作前后往往會出現明顯差異,如圖1所示。

(a1)與(a2)表示面癱患者的兩次閉眼動作;(b1)和(b2)表示正常人兩次閉眼動作圖1 真假面癱不同時刻動作圖像對比Fig.1 Comparison of the facial states between a facial paralysis patient and a normal person at different times
根據以上情況,我們認為識別真假面癱的一個重要依據為不同時刻動作的前后差異,當前后動作差異較大時,存在較大概率為假面癱,當前后動作差異較小時,較大概率為真面癱患者。以往基于傳統的機器學習方法,人們提出了面癱識別和評價的方法[1,7-8],它們需要執行多個預處理步驟,并且提取的面部特征不包含多次重復相同面部診斷動作時的面部狀態差異信息。近年來,學術界對于神經網絡的結構有了更深入的研究,例如孿生網絡使用雙通道CNN分別提取兩幅圖像的特征,并計算兩個特征向量之間的歐式距離以評估兩幅圖像的相似性[9-10]。本文面癱的識別主要基于不同時刻做同一面部診斷動作時面部狀態的不同。受孿生網絡思想的啟發,我們設計了一個新的神經網絡模型,稱為深度差異性網絡(DDN)。它以兩張面部圖像作為輸入,代表不同時刻同一面部診斷動作幅度達到最大時的面部狀態。不同于傳統的孿生網絡,我們的目標是測量能夠區分真假面癱病例的“差異”,總體思路如圖2所示。
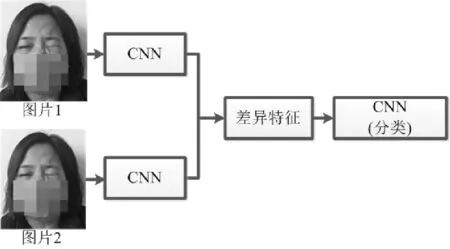
圖2 總體解決方案Fig.2 The overall solution scheme
DDN通過一個雙數據流卷積神經網絡(two-stream CNN)提取不同時刻的同位狀態圖像的深層特征,并根據所提取特征計算兩張圖像間的特征差異;再利用單分支CNN提取深層差異特征的特征,實現真假面癱識別。在DDN中,two-stream CNN提取的是一對圖像的深層特征圖,特征圖的提取保留了圖像的紋理、形狀、面部器官位置等特征信息;通過計算兩張圖像的特征圖差異(稱為“差異特征圖”),可獲得面部紋理、形狀、面部器官位置等特征的差異;通過CNN提取差異特征圖的特征(即自動提取對判斷真假面癱有益的高層特征),使得網絡著重關注于面部圖像之間差異信息的特征。
1 相關工作
現如今由于面癱發病率的不斷增高,高效、自動化的面癱識別方法成為臨床診斷的迫切需要,目前,國內外諸多學者已對面癱識別進行了相關研究,提出了各種基于不同算法的面癱識別方法,這些識別方法為臨床診斷提供極為高效、便利的診斷途徑,克服了主觀因素對診斷結果的影響,并且在一定程度上達到了較高的識別率。
1)基于關鍵點檢測和邊緣檢測算法的面癱識別研究:Liu Li′an等人在2010年提出利用SUSAN邊緣檢測算法,通過關注特定面部區域的表面積變化對面癱進行識別[11];Wang Ting等人在2016年的面癱研究中提出,利用主動形狀模型(ASM)的關鍵點定位算法,結合患者面部靜態特征與動態變化,根據靜態面部不對稱和動態面部變化自動評估面部麻痹程度[1];Nishida等人同樣利用關鍵點檢測算法,選擇左頰點和右頰點作為一對關鍵點進行定量分析,首先計算出關鍵點移動距離,然后根據關鍵點之間的運動差異對麻痹程度進行定量測量[2]。
2)基于紅外熱成像和濾波器算法的面癱識別研究:Liu Xulong等人利用一種紅外熱成像算法,以獲得面部相關區域的溫度分布特征,實現面癱的自動化評估[12];Ngo等人提出利用同心調制濾波器,對濾波后的圖像進行臉部兩側對稱性和不對稱性的測量,根據測量信息對面癱進行評估分析[13]。
3)基于深度學習方法的面癱識別研究:Yoshihara等人提出了基于深度CNN的面癱特征點自動檢測方法,先利用主動外觀模型(AAM)進行關鍵點檢測,之后將中心帶有檢測點(特征點)的區域作為DCNN輸入,實現關鍵點精確定位[5];Guo Zhexiao等人提出利用DCNN算法對面癱進行客觀評估,將整張圖像作為輸入,捕捉臉部區域并通過DCNN提取特征[6]。
這些基于不同算法的面癱自動化識別方法雖然能在一定程度對面癱癥狀進行識別,但仍存在一些問題:①在基于邊緣檢測與關鍵點檢測的識別算法中,首先,邊緣檢測與關鍵點檢測大多依賴于檢測模板,模板的質量會對其準確性產生一定的影響;其次,一些方法根據圖像區域計算表面積差異,或根據關鍵點位置距離計算面部不對稱性,這類方法不能體現其較好的適用性,且計算方法復雜、計算量大;再者,傳統的特征提取方法只能提取紋理形狀等單方面特征,不能對其進行有效的結合。②基于紅外熱成像和濾波器的識別方法的缺點在于,利用紅外熱成像技術形成的圖像對比度低,分辨細節的能力較差;利用濾波器方法對圖像濾波后進行測量同樣依賴于測量模板。此外,這些算法均針對單張圖像的面部異常情況作出評估,比較武斷地將面部異常的圖像確定為面癱圖像。③基于深度學習的識別方法對于特征的學習有了較好的效果,一定程度上提高了面癱識別的準確率并減少了計算量,但與以上非深度學習方法一樣,均存在一個問題:將單幅人臉圖像呈現異常者判定為面癱患者。可見,現有的面癱識別算法最為突出的問題是,忽略了正常未患病的人(假面癱)亦可能存在面部異常和不對稱,無法很好地區分真假面癱。當假面癱數據存在時,識別結果存在一定的誤判。因此,本文希望通過設計一個新的網絡結構來實現對真假面癱的較好識別。
2 基于深度差異特征的面癱識別方法
2.1 關鍵幀的選擇和面部區域的定位
對于實驗數據中的視頻數據,我們需要提取視頻動作的關鍵幀,用于DDN的訓練與測試。針對這個問題,我們利用multi-stage CNNs方法定位視頻中動作的起始與結束位置[14-17],獲取動作發生的連續幀,并選取這些動作連續幀的中間幀(即動作幅度最大時的幀)作為實驗所用數據,關鍵幀獲取過程如圖3所示。
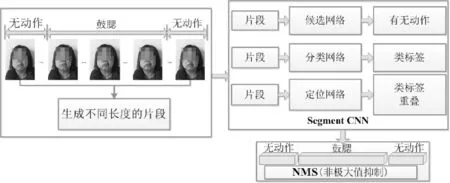
圖3 利用multi-stage CNNs獲取視頻動作關鍵幀Fig.3 The key frames obtained by multi-stage CNNs from videos
在實驗過程中,由于數據采集的環境不同,導致數據間存在不同的背景信息,而DDN的重要依據為圖像特征的差異性,因此,這些背景信息一定程度上干擾了實驗效果,降低了識別的準確率。為了盡可能地降低背景信息對實驗結果的干擾,對于實驗數據,需要最大程度去除圖像的背景信息。本文利用Faster R-CNN進行區域檢測[18-20],提取圖像中臉部區域,去除與臉部信息無關的背景信息,盡可能地避免因背景不同而產生的圖像之間的差異信息對實驗結果所造成的影響,如圖4所示。
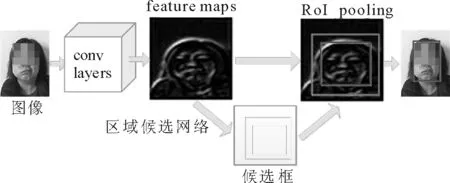
圖4 Faster R-CNN目標檢測Fig.4 Object detection with Faster R-CNN
2.2 深度差異性網絡模型
本文根據真假面癱的識別依據——不同時刻同一診斷面部動作間的差異,設計了一套基于DDN的面癱識別算法。該網絡模型的基本原理是通過two-stream CNN提取深層特征的差異性信息,再利用CNN從該差異性信息中進一步提取差異的特征,最終根據深度差異特征對面癱的真假性進行識別。
根據DDN的設計原理,可將網絡分成兩部分。前半部分為two-stream CNN,用于深度特征圖提取。我們將被測對象在不同時刻所做同一動作的兩張圖像輸入two-stream CNN,分別得到兩張圖像的輸出特征圖序列,然后,將兩個特征圖序列分別進行融合(256個特征圖融合成一張),形成一對特征圖,進而構造一個特征圖差異度量,作為兩張圖片的差異性特征的計算函數,得到差異特征圖。后半部分用于提取差異特征圖的特征,將網絡前半部分獲取的差異特征圖輸入一個深層CNN,提取差異特征(特征圖間的差異)的特征,并利用softmax函數進行分類,得到真假面癱識別結果。
根據孿生網絡原理[9-10],two-stream CNN采用同一網絡相同參數的模型:包含7個卷積層和兩個池化層,同時提取兩張圖片的深層特征。由于在提取差異特征時,需要關注的是人臉圖像的紋理及器官位置、形狀等信息,根據這些信息的差異來識別面癱的真假性,因此,在two-stream CNN部分,需要通過多個卷積層提取圖像的深層特征圖。通過利用不同深度的網絡模型提取特征圖,我們發現7個卷積層可以將圖像的紋理特征等信息較好地提取出來,并且為差異特征函數提供較為清晰且適用的數據信息。
通過實驗分析,我們將two-stream CNN訓練模型最終確定為有7個卷積層與兩個池化層組成的CNN:
(conv+ReLU)+
(conv+ReLU+pooling)+
(conv+ReLU)+
(conv+ReLU+pooling)+
(conv+ReLU)×3
(1)
網絡卷積層的卷積核大小均為3×3,步長默認為1,池化層池化大小均為2×2,步長為2,激活函數均采用ReLU函數[21],通過多層卷積和池化最終獲得256個深層特征圖。這樣,就通過7層卷積和兩層池化,最終從每對人臉圖像數據中分別獲取包含256個特征圖的序列F(Im),Im表示輸入的圖像,m為圖像序號,m=1,2。
F(Im)=(fm,1,fm,2,fm,3,…,fm,256)。
(2)
其中,fm,i表示第m個圖像的第i個特征圖,i=1,2,…,256。
DDN的核心是特征的差異性特征。孿生卷積網絡通過計算圖像特征的歐式距離來判定相似度,而DDN關注于圖像的紋理差異,眼、鼻子、嘴等器官的位置與形狀差異等信息,這些差異作為真假面癱的判定依據。因此,我們希望獲取人臉圖像數據的特征圖之間的差異,通過提取差異特征圖的特征來判定面癱的真假性。
為了獲取由two-stream CNN提取的特征圖之間的差異,在網絡中需要構造一個度量函數,用于計算深度特征的差異特征圖。
由于CNN提取的特征圖為一個序列,為了方便計算圖像特征圖之間的差異,把由two-stream CNN提取的特征圖序列F(I1)和F(I2)分別進行融合,
Fm=(fm,1+fm,2+fm,3+…+fm,256)/256。
(3)
其中,Fm表示融合后的特征圖。每對圖像數據得到融合后的特征圖F1和F2,然后構造一個用于獲取差異特征的度量函數,
DF=F1-F2。
(4)
我們發現,通過這個簡單的差異特征度量函數可以有效提取兩個特征圖的差異信息,得到差異特征圖。
DDN后半部分的主要作用是通過提取深度差異特征的特征以實現真假面癱識別。研究表明,CNN可在其頂層加上一個softmax作為分類器,廣泛應用于圖像分類,并達到了極高的分類準確率。我們在網絡結構后半部分連接一個二元分類器,以進行真假面癱識別。通過模型訓練測試發現,一個深度為8的CNN可以實現較好的分類效果,因此,我們將網絡后半部分的CNN結構設置為
(conv+ReLU+pooling+LRN)×2+
(conv+ReLU)×2+
(conv+ReLU+pooling)+
(fc+ReLU)×2+softmax
(5)
網絡第1層卷積層采用大小為11×11、步長為4的卷積核,第2層卷積核大小為5×5,步長默認為1,前兩層在進行卷積和池化的同時,利用LRN(Local response normalization)技術進行歸一化。第3,4,5層卷積核大小均為3×3,步長默認為1,網絡中池化大小均為3×3,步長為2。該單分支網絡利用多層卷積與池化,提取深度差異特征的高層特征,再通過2層全連接層,送入softmax層輸出最終分類結果。網絡整體設計框圖如圖5所示,圖6顯示了DDN在特定示例下的內部狀態。
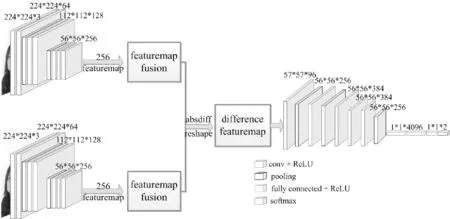
圖5 深度差異性網絡(DDN)Fig.5 Deep differentiated network (DDN)

圖6 特定例子中深度差異性網絡的內部狀態Fig.6 The intermediate results of the DDN for a specific sample instance
我們用two-stream CNN提取圖像深層特征,然后用差異特征函數計算特征差異,最后用單分支CNN提取深度差異特征的特征并進行分類。這些組件共同組成了深度差異性特征網絡DDN,實現了對真假面癱的分類識別。綜上所述,DDN是一個根據差異性特征的特征進行分類的深度神經網絡模型。
3 實驗與分析
3.1 實驗計劃
為驗證提出的方法能夠有效識別真假面癱,我們采集了面癱患者和正常人在做面部動作時的視頻進行實驗,并針對訓練過程及測試結果對比現有幾種識別方法進行討論。
在數據采集過程中,我們借鑒Kihara等人提出的動態面部表情數據庫的建立方法和臨床醫生的面癱診斷流程[22],建立了一個視頻數據庫,記錄了健康志愿者和面癱患者的面部動作。其中面癱患者的數據包括微笑、示齒、聳鼻、皺眉、抬眉、閉眼、鼓腮等動作數據;健康志愿者的面部數據包括正常人模仿面癱患者各類動作的數據。對于數據的要求:每位動作數據提供者需針對同一動作在不同的時刻隨機重復做兩次。通過這種采集方式,我們收集了57例面癱患者和106例正常人的面部運動錄像。經過視頻編輯,共有2 282個視頻片段(163×7×2)作為實驗數據,即1 141對。從這些視頻中提取的一些面部圖像或幀記錄了相應的面部動作的最大面部狀態,如圖7和圖8所示。圖7(a)和圖8(a)分別是真假面癱閉眼的面部動作,圖7(a1),7(a2)和圖8(a1),8(a2)是在不同時間出現的最大面部狀態,圖7(b),7(c)和圖8(b),8(c)展示的是另外兩種面部動作的結果。可見,面癱患者在不同時刻做同一診斷動作時所出現的最大面部狀態非常相似,但正常人的面部狀態卻存在一定的差異。
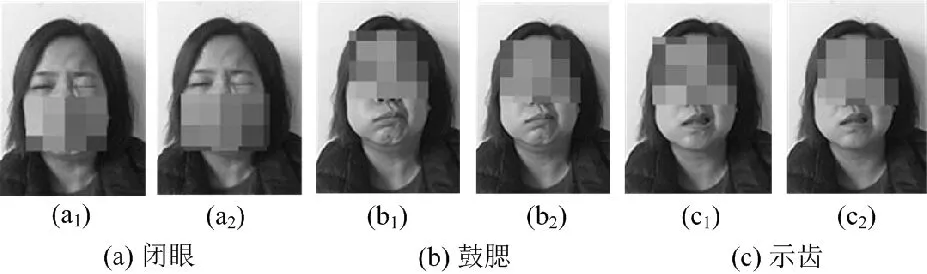
圖7 面癱人臉部分動作圖像Fig.7 Partial movement images of a facial paralysis patient face

圖8 假面癱人臉部分動作圖像Fig.8 Partial movements images of false facial paralysis face
在模型訓練之前,對采集到的原始視頻進行一些預處理,利用Multi-stage CNNs從視頻中提取記錄最大面部運動的關鍵幀[14-16],并通過Faster RCNN檢測主要面部區域,以去除大部分無關的背景信息[18-20],如圖9所示。

圖9 對圖像數據進行預處理去除背景信息Fig.9 Image data preprocessing by Faster RCNN to remove background information
3.2 實驗結果
在DDN的訓練過程中,使用疑似患者的兩幅記錄了同一面部動作在達到最大幅度面部運動狀態時的面部圖像作為DDN的輸入數據,實現對面部癱瘓的識別。在實驗中,700對人臉圖像用作訓練數據,剩下的441對人臉圖像用作測試數據。將該過程重復10次,并對實驗結果的平均值進行分析。
對于實驗數據,需要說明的是,由于數據采集是個不連續的過程,所有的視頻片段都是在任意地點和隨機時間拍攝的,因此造成部分數據存在背景不同、臉部發生偏轉等現象,使得數據存在由外部因素產生的較大差異;此外,由于不同的人對于臨床診斷面部動作有不同的理解,這導致疑似患者在重復相同的診斷面部動作時,其面部狀態是不同的。基于上述情況,我們的識別結果在一定程度上依賴于所選數據,識別任務難度較大。
由于本文的任務是識別真假面癱,假面癱中包括了自然不對稱的人臉數據以及正常人模仿面癱病人的表情動作數據。而現有的面癱識別方法關注點均為面部異常或不對稱,且大多以面部不對稱性作為識別依據,造成將假面癱現象誤識別為面癱的情況。這些現有方法不具備識別假面癱的能力,無法達到識別真假面癱的效果,因此,本文中我們不再與這些方法進行實驗比較。
針對真假面癱的識別任務,根據現有方法的識別原理,我們選取了幾種具有代表性的神經網絡模型進行實驗并觀察效果:LeNet,AlexNet和VGG,這些方法均利用一個單一的卷積神經網絡進行面癱識別,將帶有標簽的單一的實驗數據直接輸入網絡,通過網絡提取特征,并利用softmax實現二分類得到分類結果,實驗結果如表1所示。從表1可以看到,這些傳統方法的面癱識別效果并不太好,DDN在多個評價指標方面比這些傳統方法具有更好的性能。平均起來,DDN比VGG,AlexNet和LeNet在準確率方面提高了26.17%,16.5%和15.67%;在精確度方面提高了25.74%,14.29%和15.73%;在召回率上提高了26%,20.33%和14%,在F1值上提高了25.77%,17.69%和15.24%。此外,DDN的優點也在圖10中得到了證實,圖10將這些評價指標以直方圖的形式輸出顯示。
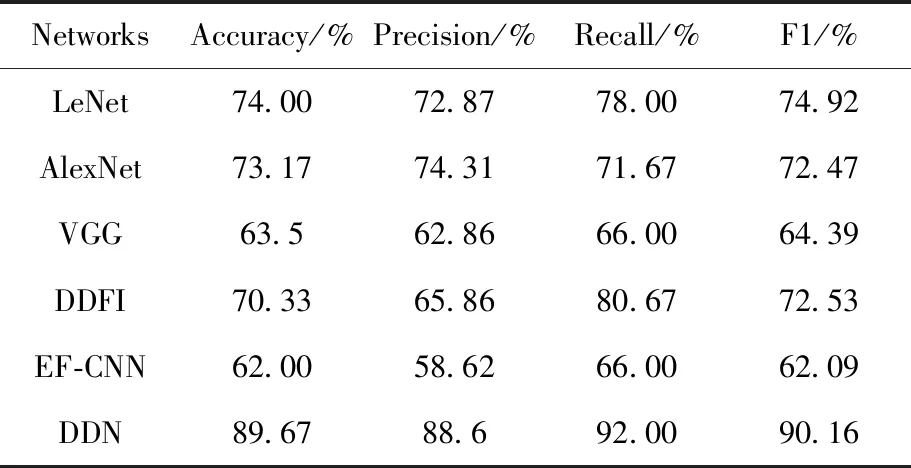
表1 不同方法的實驗結果Tab.1 Experimental results on different methods
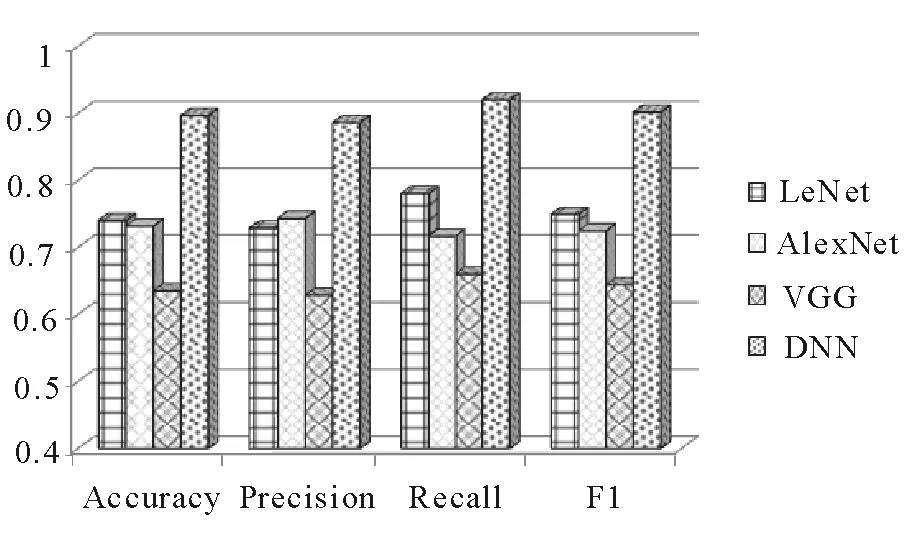
圖10 DDN模型與傳統神經網絡模型在準確度、精確度、召回率和F1值上的比較Fig.10 Comparison of DDN and traditional neural network models in accuracy, precision, recall and F1-measure
本文提出了利用面癱患者在不同時間做面部動作時面部狀態的差異進行面癱識別的思想。那么,對基于人臉圖像直接進行作差(DDFI)后提取的人臉特征或基于兩個卷積神經網絡(EF-CNN)直接提取特征差異的面癱識別方法進行性能測試,其效果如何呢?在這里,我們將DDFI,EF-CNN和DDN這3種方法進行比較,實驗結果如表1所示。從表1可以看出,DDFI比EF-CNN具有更好的性能,但與DDN相比其各性能指標還是要低很多,其中準確率低19.34%,精確度低22.74%,召回率低11.33%,F1值低17.63%。因此,這兩種方法不能取得更好的結果。這是因為DDFI是基于圖像本身的差異來進行判斷的,但是,這些面部圖像在背景、光線、拍攝角度等因素上存在很大差異,而這些差異不是面部狀態的差異。EF-CNN是基于孿生網絡的識別方法,利用函數對圖像特征進行映射,通過差值(歐式距離)損失函數進行類別匹配,忽略了部分面部紋理、形狀、面部器官位置等差異信息,例如,面部器官向左或右兩個方向歪斜而形成的差異,這使得該方法無法達到理想的結果。相比之下,DDN具有最好的性能,這主要歸因于DDN在提取特征之間的差異的特定能力。此外,圖11清楚地顯示了DDN在4個評價指標中一般優于DDFI,EF-CNN這兩個比較方法。
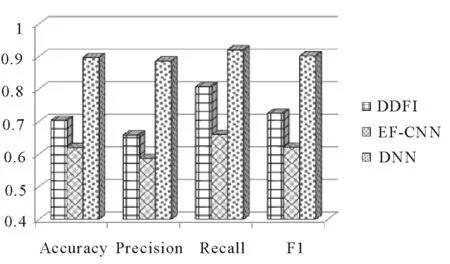
圖11 DDFI, EF-CNN在準確率、精確度、回歸率以及F1值上與DDN的比較Fig.11 Comparison of DDFI, EF-CNN and DDN in accuracy, precision, recall and F1-measure
4 結 論
本文提出了一個面癱識別中存在的新問題:假面癱數據導致的面癱誤判,并且為了解決此問題,在孿生神經網絡基礎上,設計了一種新網絡:深度差異性神經網絡,為真假面癱的識別奠定了基礎。對于真假面癱的識別,解決了自動化面癱識別中由于假面癱數據的存在而導致的誤判現象,進一步提高了面癱識別的準確率。此外,DDN采用two-stream CNN與單一深層CNN相連的網絡,該網絡關注人臉五官的紋理形狀、位置、肌理等特征差異,通過提取差異性特征的高層特征進行分類,很好地解決了真假面癱識別問題,并達到了較高的準確率。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
