基于點云數據的三維目標識別和模型分割方法
2019-05-14 07:36:12牛辰庚劉玉杰李宗民
圖學學報 2019年2期
牛辰庚,劉玉杰,李宗民,李 華
?
基于點云數據的三維目標識別和模型分割方法
牛辰庚1,劉玉杰1,李宗民1,李 華2,3
(1. 中國石油大學(華東)計算機與通信工程學院,山東 青島 266580; 2. 中國科學院計算技術研究所智能信息處理重點實驗室,北京 100190; 3. 中國科學院大學,北京 100190)
三維模型的深度特征表示是三維目標識別和三維模型語義分割的關鍵和前提,在機器人、自動駕駛、虛擬現實、遙感測繪等領域有著廣泛的應用前景。然而傳統的卷積神經網絡需要以規則化的數據作為輸入,對于點云數據需要轉換為視圖或體素網格來處理,過程復雜且損失了三維模型的幾何結構信息。借助已有的可以直接處理點云數據的深度網絡,針對產生的特征缺少局部拓撲信息問題進行改進,提出一種利用雙對稱函數和空間轉換網絡獲得更魯棒、鑒別力更強的特征。實驗表明,通過端到端的方式很好地解決缺少局部信息問題,在三維目標識別、三維場景語義分割任務上取得了更好的實驗效果,并且相比于PointNet++在相同精度的情況下訓練時間減少了20%。
點云;深度學習;原始數據;三維目標識別;三維模型分割
近年來,隨著三維成像技術的快速發展, 像微軟Kinect,英特爾的RealSense和谷歌的Tango等低成本小型化三維傳感器都可以很好的捕獲場景的三維信息,幫助智能設備更好的感知、理解世界的同時很大程度上也降低了人們以三維的方式獲取真實世界信息的門檻。另一方面,伴隨著GPU計算能力的迭代更新和大型三維模型數據的出現,深度學習的思想在三維模型分類、檢索等任務范圍逐漸占據了絕對主導地位。這就使高效、準確并且直接處理三維數據的技術成為廣泛的需求,并且成為自動駕駛、虛擬現實以及遙感測繪發展的關鍵。
然而,通過便攜式三維掃描設備獲取的原始三維數據通常是點云的形式,區別于傳統的圖像和體素結構,屬于不規則的三維形狀數據結構。深度學習中傳統卷積結構為了實現權值共享和核函數優化需要以規則化的數據結構作為輸入,所以之前對于點云數據的處理通常轉換為多視圖或者體素的形式再輸入到深度網絡中去。但該數據處理形式的轉換往往會帶來幾何結構損失、分辨率下降等問題,由此產生識別精度低,模型錯誤分割的實驗結果。
之前利用深度學習在點云上提取特征的工作有PointNet[1]和PointNet++[2]。PointNet以記錄空間坐標的原始點云數據直接作為網絡的輸入,學習點云模型的空間編碼后轉換為全局特征描述子用于目標分類和模型分割任務。PointNet++為了學習到模型更多的局部結構信息,首先通過最遠點采樣和球查詢的方式提取包含模型局部結構的點集,并利用PointNet學習帶有局部特征的點集串聯為全局特征用于模型分割任務。
本文方法在PointNet直接處理原始點云模型的深度網絡基礎上,以端到端的方式完成輸入到高層特征表示的映射。且利用多層感知機網絡單獨地提取每個點的深度特征,然后引入與二維圖像上處理仿射變換不變性的空間轉換網絡(spatial transformer networks,STN)[3]相似的結構學習模型的拓撲結構信息,同時利用雙對稱函數對點集特征進行編碼,消除點序對全局特征的影響并且進一步產生更有鑒別力和穩健性更強的深度特征。相比于PointNet,本文通過構建端到端的深度網絡模型學習帶有模型拓撲結構的全局信息,以更小的時間代價達到了更高的目標識別精度,網絡結構更加簡單并且易于訓練。
本文直接處理點云數據的深度網絡關鍵在于轉換網絡和對稱函數的設計,理論分析及實驗證明本文方法產生的特征蘊涵更多的模型信息以及具有更好的穩健性,其充分解釋了網絡對于存在缺失和擾動的點云模型具有一定魯棒性的原因。從函數逼近的角度看,由于避免了最遠點采樣等提取局部結構信息的模型預處理模塊,本文的網絡可以對任意連續的集合進行函數逼近。
1 相關工作
基于點云模型的特征提取自上世紀90年代開始至今已有20余年的發展,以2012年為分界線總體可以分為2個階段:手工設計特征階段和基于深度學習的特征階段。而基于深度學習的三維模型特征提取依據不同三維形狀數據的表示方法又可以分為:基于手工特征預處理的方法,基于投影圖的方法,基于體素的方法和基于原始數據的方法。
手工設計特征階段通常通過提取三維形狀的空間分布或直方圖統計等方法得到,典型代表如Spin Image、FPFH、HKS (heat kernel signature)、MsheHOG、RoPS等[4]。這類模型驅動的方法在前一階段中占據著主導地位,但是依賴于研究者的領域知識,并且獲取的特征在不同屬性數據集中的區分力、穩定性和不變性都不容易得到保證,可拓展性差。
2012年普林斯頓大學建立了大型三維CAD模型庫項目ModelNet[5],伴隨著深度學習算法在圖像領域取得了巨大的成功,三維形狀數據結合深度網絡提取特征并應用于目標分類、模型分割、場景語義解析任務也取得了很好的結果,三維領域中數據驅動方法開始發展起來并逐漸在各項三維領域的任務中取得重要地位。
由于初期三維模型庫較小以及深度網絡由二維到三維的復雜性,最先發展起來的是基于手工特征預處理的方法。該方法首先在三維模型上提取手工特征,然后將手工特征作為深度網絡的輸入從而提取高層特征。典型的工作有BU等[6]首先在三維模型上提取熱核和平均測地距離特征,利用詞包轉換為中級特征輸入到深度置信網絡中提取高層特征。XIE等[7]首先提取三維模型的熱核特征構建出多尺度直方圖,然后在每個尺度上訓練一個自編碼機并將多個尺度隱含層的輸出串聯得到三維模型描述子,并在多個數據集上測試了該方法用于形狀檢索的有效性。KUANG等[8]利用嵌入空間下局部特征和全局特征融合的方法得到三維模型描述子,用來解決非剛體三維模型檢索任務。這類方法可以充分利用之前的領域內知識作為先驗指導并且能夠很好的展現手工特征和深度網絡各自的優勢。但是依賴于手工特征的選擇和對模型參數的調整、優化,一定程度上削弱了深度網絡高層特征的表達能力。
文獻[9]首先嘗試通過多視圖表示三維模型,然后輸入到深度網絡提取高層特征,在三維模型分類、檢索任務上取得了很好的表現。即給定視點和視距將三維模型投影為12或20幅視圖輸入到卷積神經網絡提取每幅圖像的特征,然后經過相同位置最大池化處理輸入到第二個卷積神經網絡提取模型特征。文獻[10]充分考慮多視圖之間的關系,在輸入網絡前按照視點重要程度對相應視圖進行預排序。之后文獻[11]又提出沿三維模型主軸投影為全景圖并通過卷積神經網絡提取深度特征的方法。該方法的優點為可以充分利用二維圖像領域中成熟的深度網絡架構及充足的圖像數據完成深度網絡的訓練、調整。但是投影的方式損失了三維模型的幾何結構,一定程度上損失了特征的鑒別力,并且往往需要三維模型沿軸對齊。
基于體素的方法通過將三維模型體素化,仿照二維圖像上的卷積操作利用深度網絡直接在體素上提取深度特征。WU等[5]將三維模型用32×32×32的二值化體素表示,采用深度卷積置信網絡學習三維數據和標簽之間的聯合概率分布。QI等[12]發現基于體素的深度網絡存在過擬合問題,通過在網絡中加入用局部三維形狀信息預測類別標簽的輔助任務很大程度上避免了過擬合問題。但是文獻[13]指出,隨著體素分辨率的提高,數據稀疏性和計算復雜度問題難以處理。由于傳統深度網絡只對模型邊緣體素信息敏感,文獻[14]提出用八叉樹的方式組織體素模型然后提取深度特征的O-CNN,在保證模型精度的前提下提高了數據利用率。
丟失幾何結構信息和數據稀疏性問題限制了基于多視圖和基于體素的深度網絡的發展,那么最優的發展方向就是調整深度網絡適應原始三維數據作為輸入[15]。文獻[16]提出基于面片的卷積受限波茲曼機(MCRBM),實現了三維形狀的無監督特征學習。文獻[17]提出使用KD樹組織點云數據,規則化深度網絡輸入結構。文獻[18]將激光點云數據劃分為若干體素塊,然后利用體素特征編碼模塊(voxel feature encoding, VFE)進行局部特征提取,并通過三維卷積實現高層特征的抽象。QI等[1-2]提出基于點云數據的深度網絡PointNet,通過多層感知機提取每個點的深度特征并利用對稱函數轉換為對點序不變的全局特征向量,在三維模型分類、語義分割任務上取得了很好的效果。之后借鑒于文獻[19]和文獻[20]中的方法,為了學習點云模型局部拓撲結構特征提出PointNet++,首先通過最遠點采樣和球查詢聚集的方法對點云模型進行處理,然后通過PointNet映射成帶有局部信息的高層特征。PointNet++進一步拓展了PointNet獲得了更精細的模型局部特征,在模型分割和場景語義分割任務上取得了更高的精度。文獻[21]通過自組織映射(self-organizing map,SOM)聚類算法得到點云模型關鍵點并建立與周圍模型點的聯系,并使用PointNet模塊得到帶有空間信息的模型描述子。文獻[22]利用圖像目標檢測方法將三維模型檢測范圍縮小到視錐中,然后利用PointNet提取深度特征用于目標分類和包圍盒估計。
2 本文工作
本文通過設計直接處理點云數據的深度網絡,提取三維模型深度特征應用于三維模型識別和三維模型分割任務。提取模型全局特征的網絡結構如圖1所示(卷積核大小除第1層為1×3,其余均為1×1,且步長均為1,同層卷積權值共享。對于目標識別任務,輸入點云序列只記錄空間坐標信息,大小為×3;對于三維模型語義分割任務,輸入點云序列記錄空間坐標、顏色、法向信息,大小為×9)。網絡以點云數據為輸入,經過5個卷積層,差異性對稱函數和姿態變換子網絡處理,將池化特征和姿態特征串聯得到最終的全局特征。對于類三維目標識別任務,深度網絡以記錄空間信息{,,}的點云數據直接作為輸入,對每個模型上的點做單獨處理,輸出對應所屬類別概率的維向量。對于有個語義標簽的三維模型語義分割任務,深度網絡以從每個場景目標模型中采樣得到的個點的點云模型作為輸入,輸出對應每個點語義標簽的×維特征矩陣。本文所使用的深度網絡可以分為3個部分:深度卷積神經網絡單獨提取每個點的深度信息,差異性雙對稱函數提取模型不同顯著性特征,空間轉換網絡預測出姿態變換矩陣融合為帶有局部信息的全局特征。
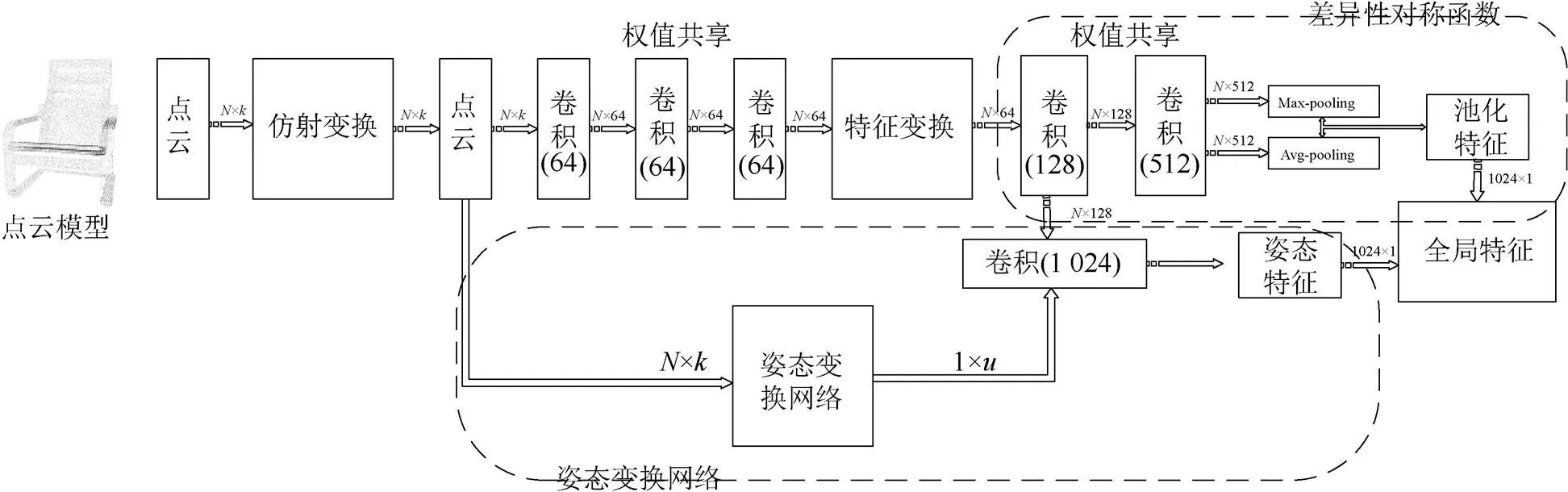
圖1 本文網絡結構圖
2.1 深度卷積網絡
由于集合中的點以記錄空間坐標信息、顏色和法向信息的點集形式存在,所以是一種不規則形式的三維數據,不能直接輸入到傳統卷積深度神經網絡。此外,在點云上提取模型特征時還需要考慮到點序對最終特征的影響,避免模型在仿射變換之后產生錯誤識別,或者模型上的點對應的語義標簽發生改變的情況。這里通過調整深度卷積網絡適應點云數據的輸入形式,先對模型上的每個點進行處理,然后在得到的特征層面進行點序的處理。
深度卷積神經網絡結構的設置類似于傳統的多層感知器網絡,本文通過設置卷積核大小為1×1來實現對表示模型的點集的特征提取,即對于點云模型上記錄空間坐標等信息的個點,深度卷積網絡單獨將其每個點映射為中層特征,為接下來局部拓撲信息處理和全局特征提取做準備。實驗表明,相比于模型表示形式的轉換和先對點集進行排序預處理的方式,本文方法可以充分發揮點云數據本身的優勢,同時避免了排序預處理情況下需要考慮種不同的組合情況。
2.2 差異性對稱函數
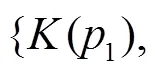

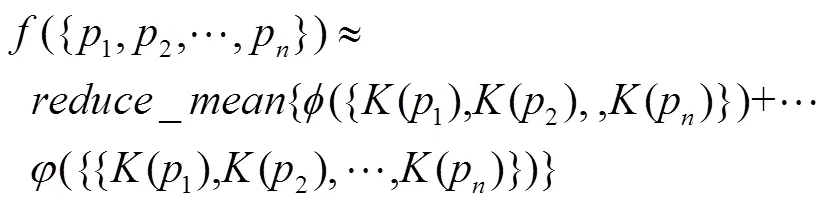
其中,為點集映射得到的高層全局特征。用于分類任務的網絡結構如圖2所示,通過3個全連接層將得到的模型深度特征轉換為k維概率矩陣。其結果表明融入了更多不同顯著性信息的全局特征,在模型分類任務精度上相較于PointNet有一定的提高。
2.3 姿態對齊網絡
PointNet中使用模型全局特征和網絡中間層的點特征進行串聯用于進行后續的分割任務,但是由于特征不夠精細且缺少局部上下文信息,容易產生失真的情況,并且在細粒度模式識別和復雜場景的識別問題上效果不佳。后續的工作增加模型輸入到深度網絡前的預處理步驟來解決缺少局部上下文信息的問題。但是重復進行最遠點采樣、采樣點聚集和調用PointNet網絡提取特征,一定程度上增大了問題復雜度,同時在不同尺度、不同密度下非端到端地使用PointNet網絡提取高層特征也增加了時間開銷。
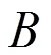
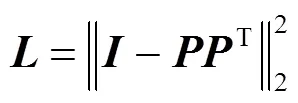
其中,P為姿態對齊網絡輸出對齊矩陣。正交陣不會損失輸入信息,并且損失中增加正則項提高優化速度的同時也帶來了一定程度上精度的提升。

圖4 全局特征用于模型語義分割任務網絡結構圖
3 實 驗
3.1 三維目標識別任務實驗
對于三維目標識別任務,本文方法充分利用端到端的深度網絡學習到具有不同顯著性的模型特征,并在ModelNet40模型分類數據集上進行測試。ModelNet40模型庫包含40類12 311個CAD模型,其中訓練集有9 843個模型,測試集有2 468個模型。2017年之前的大部分工作是轉換模型表達方式,以視圖或者體素化的三維模型作為處理對象,本文是基于點云數據進行實驗。
本文對于所有模型在表面按照面積的不同均勻地采集1 024個點,每個點記錄空間坐標信息,且為了便于訓練將所有點的坐標標準化到單元球中。在訓練階段,為了增強網絡對模型仿射變換的特征不變性以及增加訓練數據,對訓練集模型進行隨機角度的沿軸旋轉以及添加均值為零,方差0.03的高斯噪聲。實驗中設置dropout參數為0.7,實驗結果對比見表1。

表1 ModelNet40數據集目標識別任務實驗對比
本文方法同之前基于體素的基準方法有了4.5%的精度提升,取得了最佳的結果。并且由于本文采用端到端的方式對模型進行處理,網絡主要結構為處理點云空間坐標信息的卷積,雙對稱函數映射模塊和全連接,可以通過GPU進行高效的并行計算。相比于在點云數據上提取手工特征(點云密度,測地線距離等)再利用多層感知器提取深度特征的方式(表1MLP方法)以及通過PointNet提取模型全局特征的方法,本文的方法取得了最佳的效果。
3.2 三維模型語義分割任務實驗
相比于模型分類任務,三維模型語義分割需要輸入更為精細的點特征,因此是一項更具有挑戰性的細粒度任務。本文方法中結合姿態估計網絡和多層感知器網絡對原始點云數據進行處理,同目標識別任務采用相似的方法在每個三維模型表面均勻地采集4 096個點,并且將每個點對應的RGB值和法向信息同空間坐標統一作為本文深度網絡的輸入。
本文在斯坦福大學三維語義分割標準數據集上進行實驗。該數據集包含了6個區域271個房間的Matterport掃描數據,其中所有的點標注為桌子、地板、墻壁等13個類別。在網絡訓練階段,將所有點按照房間編號分開,并且將每個房間劃分為棱長1 m的小區域。語義分割網絡將整個區域的點云數據作為輸入,輸出每個區域中點的類別信息。
將本文語義分割結果與其余3種方法分割結果通過平均交并比和整體精度的評價指標進行比較,見表2。其中MLP方法為首先在點云數據上提取手工特征,然后通過多層感知器網絡獲得語義分割特征。本文方法相比于MLP方法在平均交并比和整體分類精度指標上產生了巨大的提升。并且相比于PointNet,由于更好的融入了局部拓撲信息,精度提高了6.64%。同PointNet++相比,由于本文采用端到端方式的處理,在訓練時間上縮短了20%。

表2 語義分割任務結果比較
3.3 對比實驗以及魯棒性測試
三維目標識別任務中,差異性對稱函數的組合會影響最終全局特征的識別精度。為了達到深度網絡的最佳的性能,本文結合3種對稱函數進行對比實驗,實驗結果見表3。
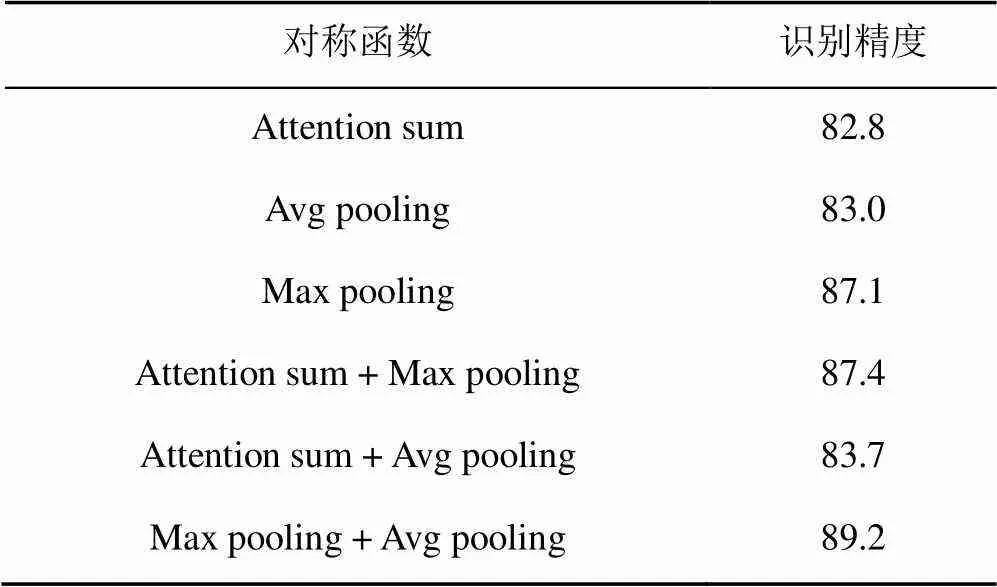
表3 差異性對稱函數組合比較
為了驗證本文深度網絡對于模型采樣點個數的魯棒性,隨機丟棄測試集50%,75%,87.5%的采樣點,最終在ModelNet40上測試結果如圖5所示。即在只保留256個采樣點的條件下本文深度網絡依然可以達到85.3%的識別精度。
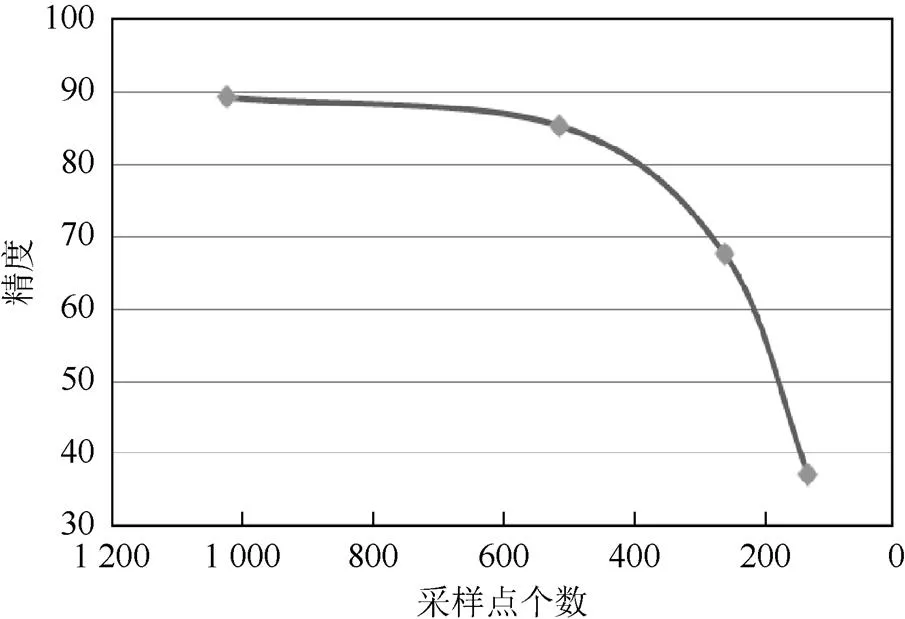
圖5 深度網絡對采樣點個數魯棒性測試
3.4 可視化結果以及實驗分析
為了定性分析實驗結果以及通過實驗效果分析本文方法,本文給出幾種典型的誤分類模型的可視化結果,以及部分空間語義分割結果。圖6模型為2種鏡子,網絡分類結果為書架。圖7中2種錯誤情況為將沙發分類為床,XBOX模型分類為書架。由此可知,點云的稀疏性導致網絡單純的依靠空間坐標信息不能很好的區分出幾何相似的模型。通過增加模型采樣點的法向信息以及RGB信息可以一定程度上解決此問題。

圖6 誤分類情況模型可視化(鏡子模型)

圖7 誤分類情況模型可視化
圖8為4組空間語義分割結果可視化效果圖,不同顏色代表不同類別信息,左欄為人工標注結果,右欄為網絡預測結果。
4 結束語
本文借助已有的可以直接處理點云數據的深度網絡進行改進,針對產生的特征缺少局部拓撲信息問題,提出一種利用差異性雙對稱函數和空間轉換網絡來獲得更魯棒、鑒別力更強的特征。在ModelNet40數據集上分類任務以及在S3DIS數據集語義分割任務上實驗表明,本文設計的網絡和對應的特征有更好的表現。下一步工作重點是在點云模型全局特征中融入更多局部拓撲信息,進一步提升語義分割精度以及提高模型識別精度。

圖8 語義分割模型可視化
[1] QI C R, SU H, MO K, et al. Pointnet: Deep learning on point sets for 3D classification and segmentation [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 77-85.
[2] QI C R, YI L, SU H, et al. Pointnet++: Deep hierarchical feature learning on point sets in a metric space [C]//The 24th Annual Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2017: 5105-5114.
[3] JADERBERG M, SIMONYAN K, ZISSERMAN A. Spatial transformer networks [C]//The 22th Annual Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2015: 2017-2025.
[4] GUO Y, BENNAMOUN M, SOHEL F, et al. 3D object recognition in cluttered scenes with local surface features: a survey [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(11): 2270-2287.
[5] WU Z, SONG S, KHOSLA A, et al. 3D shapenets: A deep representation for volumetric shapes [C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2015: 1912-1920.
[6] BU S H, LIU Z, HAN J, et al. Learning high-level feature by deep belief networks for 3-D model retrieval and recognition [J]. IEEE Transactions on Multimedia, 2014, 16(8): 2154-2167.
[7] XIE J, DAI G, ZHU F, et al. Deepshape: Deep-learned shape descriptor for 3D shape retrieval [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(7): 1335-1345.
[8] KUANG Z, LI Z, JIANG X, et al. Retrieval of non-rigid 3D shapes from multiple aspects [J]. Computer-Aided Design, 2015, 58: 13-23.
[9] SU H, MAJI S, KALOGERAKIS E, et al. Multi-view convolutional neural networks for 3D shape recognition [C]//2015 IEEE International Conference on Computer Vision. New York: IEEE Press, 2015: 945-953.
[10] LENG B, LIU Y, YU K, et al. 3D object understanding with 3D convolutional neural networks [J]. Information Sciences, 2016, 366: 188-201.
[11] SHI B G, BAI S, ZHOU Z, Et al. DeepPano: Deep panoramic representation for 3D shape recognition [J]. IEEE Signal Processing Letters, 2015, 22(12): 2339-2343.
[12] QI C R, SU H, NIE?NER M, et al. Volumetric and multi-view cnns for object classification on 3D data [C]// 2016 IEEE conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 5648-5656.
[13] LI Y, PIRK S, SU H, et al. FPNN: Field probing neural networks for 3D data [C]//The 23th Annual Conference on Neural Information Processing Systems. Cambridge: MIT Press,2016: 307-315.
[14] WANG P S, LIU Y, GUO Y X, et al. O-cnn: Octree-based convolutional neural networks for 3D shape analysis [J]. ACM Transactions on Graphics (TOG), 2017, 36(4): 72.
[15] VINYALS O. Order matters: Sequence to sequence for sets. (2015-05-05). [2019-03-21]. https://arxiv.org/abs/1506. 02025.
[16] HAN Z, LIU Z, HAN J, et al. Mesh convolutional restricted Boltzmann machines for unsupervised learning of features with structure preservation on 3D meshes [J]. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(10): 2268-2281.
[17] KLOKOV R, LEMPITSKY V. Escape from cells: Deep kd-networks for the recognition of 3D point cloud models [C]//2017 IEEE International Conference on Computer Vision (ICCV). New York: IEEE Press, 2017: 863-872.
[18] MATURANA D, SCHERER S. Voxnet: A 3D convolutional neural network for real-time object recognition [C]//2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). New York: IEEE Press, 2015: 922-928.
[19] KAMOUSI P, LAZARD S, MAHESHWARI A, et al. Analysis of farthest point sampling for approximating geodesics in a graph [J]. Computational Geometry, 2016, 57: 1-7.
[20] RODOLà E, ALBARELLI A, CREMERS D, et al. A simple and effective relevance-based point sampling for 3D shapes [J]. Pattern Recognition Letters, 2015, 59: 41-47.
[21] LI J, CHEN B M, HEE LEE G. So-net: Self-organizing network for point cloud analysis [C]//2018 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 9397-9406.
[22] QI C R, LIU W, WU C, et al. Frustum pointnets for 3D object detection from rgb-d data [C]//2018 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 918-927.
3D Object Recognition and Model Segmentation Based on Point Cloud Data
NIU Chen-geng1, LIU Yu-jie1, LI Zong-min1, LI Hua2,3
(1. College of Computer and Communication Engineering, China University of Petroleum, Qingdao Shandong 266580, China; 2. Key Laboratory of Intelligent Information Processing, Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China; 3. University of Chinese Academy of Sciences, Beijing 100190, China)
Deep representation of 3D model is the key and prerequisite for 3D object recognition and 3D model semantic segmentation, providing a wide range of applications ranging from robotics, automatic driving, virtual reality, to remote sensing and other fields. However, convolutional architectures require highly regular input data formats and most researchers typically transform point cloud data to regular 3D voxel grids or sets of images before feeding them to a deep net architecture. The process is complex and the 3D geometric structure information will be lost. In this paper, we make full use of the existing deep network which can deal with point cloud data directly, and propose a new algorithm that uses double symmetry function and space transformation network to obtain more robust and discriminating features. The local topology information is also incorporated into the final features. Experiments show that the proposed method solves the problem of lacking local information in an end-to-end way and achieves ideal results in the task of 3D object recognition and 3D scene semantic segmentation. Meanwhile, the method can save 20% training time compared to PointNet++ with the same precision.
point cloud; deep learning; raw data; 3D object recognition; 3D model segmentation
TP 391
10.11996/JG.j.2095-302X.2019020274
A
2095-302X(2019)02-0274-08
2018-09-03;
2018-10-10
中央高校基本科研業務費專項資金項目(18CX06049A);國家自然科學基金項目(61379106,61379082,61227802);山東省自然科學基金項目(ZR2015FM011,ZR2013FM036)
牛辰庚(1993-),男,河北衡水人,碩士研究生。主要研究方向為三維目標識別。E-mail:niuchengeng@foxmail.com
劉玉杰(1971-),男,遼寧沈陽人,副教授,博士。主要研究方向為計算機圖形圖像處理。E-mail:782716197@qq.com
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
