跨媒體深層細粒度關聯學習方法*
2019-05-20 06:56:06卓昀侃綦金瑋彭宇新
軟件學報 2019年4期
卓昀侃,綦金瑋,彭宇新
(北京大學 計算機科學技術研究所,北京 100871)
在大數據時代,互聯網數據以圖像、視頻、文本、音頻等多種媒體形式廣泛存在,它們是計算機感知和認知真實世界的重要載體.由于數據總量和媒體類型的迅猛增長,多媒體信息檢索[1]的相關研究得以迅速發展,其中跨媒體檢索[2-4]是最新的研究熱點之一.跨媒體檢索是指用戶通過輸入任意媒體類型的查詢數據,檢索出所有媒體類型中的語義相關數據,如圖 1所示,用戶可以輸入“飛機”的相關圖像作為查詢來檢索和飛機相關的圖像、視頻、文本、音頻和3D模型.相比傳統的單媒體檢索,例如圖像檢索[5]、視頻檢索[6]等,跨媒體檢索能夠更加靈活、全面地滿足用戶的檢索需求.然而,“異構鴻溝”問題導致不同媒體類型的數據分布和特征表示之間存在不一致性,因此難以直接度量多種媒體數據之間的相似性,使得跨媒體檢索面臨巨大挑戰.

Fig.1 An example of cross-media retrieval圖1 跨媒體檢索示例
事實上,認知科學的研究表明,人類大腦能夠通過多種感官信息的融合來認知外部世界[7],視覺、聽覺和語言等系統能夠很好地協同處理從外界接受的信息.因此,如何通過模擬人腦的認知過程,實現多媒體數據的語義互通與關聯理解,是跨媒體檢索需要解決的關鍵問題.對此,現有方法的解決思路通常是建立一個共同子空間,將不同媒體類型的異構數據映射到這個共同子空間中得到統一表征,然后通過常用的距離度量方法來直接計算不同媒體數據之間的相似性,實現跨媒體交叉檢索.
根據以上思路,已有一些工作[8-10]嘗試為不同媒體類型的數據學習統一表征,可以將其主要分為兩類:傳統方法和基于深度學習的方法.傳統方法通過統計分析學習線性映射矩陣,其中,最具代表性的是典型相關分析(canonical correlation analysis,簡稱CCA)[11],該方法通過最大化成對媒體數據間的關聯來優化映射矩陣.另有一些工作基于典型相關分析,嘗試引入其他信息提升其性能,例如語義類別信息[12]等.近年來,隨著深度學習在計算機視覺[13,14]等領域取得巨大進展,研究人員嘗試通過深度網絡的非線性建模能力來分析不同媒體類型數據間的復雜關聯關系.Feng等人[8]提出對應自編碼器(correspondence autoencoder,簡稱 Corr-AE)同時對關聯關系和重建信息進行建模.Peng等人[15]提出將媒體內和媒體間的關聯信息通過層次化網絡的方式進行聯合學習以提升檢索準確率.圖2給出跨媒體關聯學習方法的框架示意.
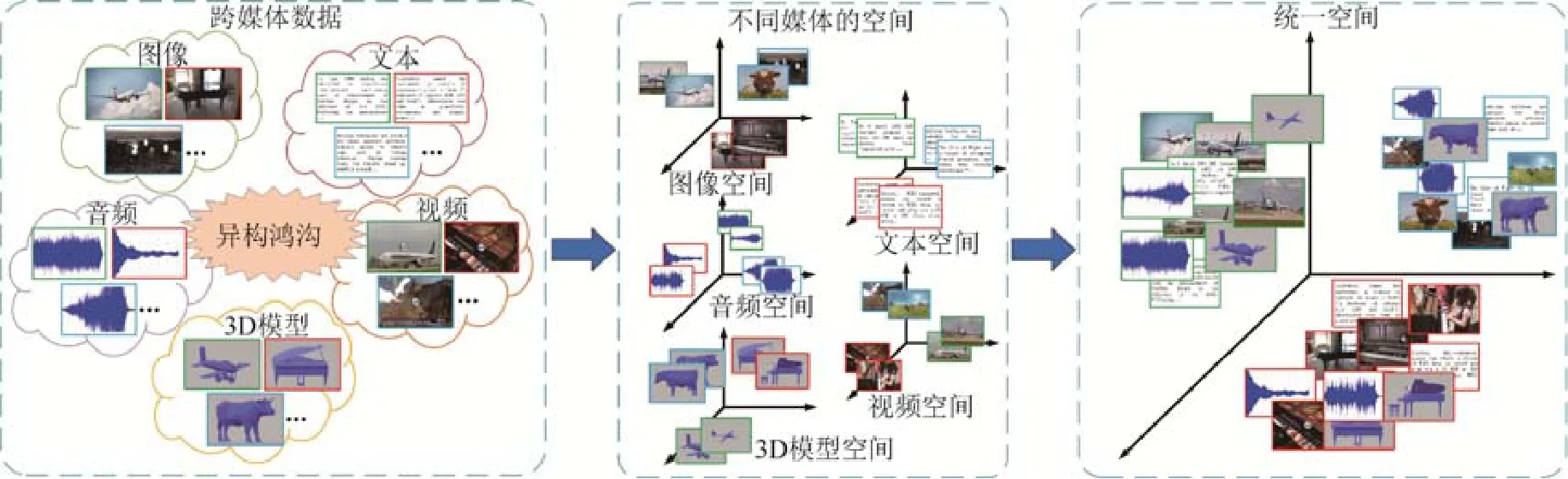
Fig.2 An illustration of the mainstream framework for cross-media correlation learning圖2 跨媒體關聯學習方法框架示意圖
然而,上述方法一般僅針對圖像和文本兩種媒體類型的跨媒體檢索任務,由于它們的泛化性能有限,很難將其擴展至更多種媒體類型的交叉檢索,如典型相關分析及其變種方法[16-18]旨在分析兩組變量之間的相關關系,盡管可以通過兩兩組合的方式來將這些方法擴充至多種媒體交叉檢索的場景,但不僅無法在一個模型內解決問題,算法復雜度高,而且忽視了多種媒體關聯的共存和互補性,導致關聯信息有限,降低了檢索的準確率.顯然,在多種媒體交叉檢索的場景下,挖掘不同媒體類型數據之間的語義關聯更加困難.由于任意兩種媒體之間都存在著異構鴻溝,而且不同媒體類型數據之間的關聯關系也有各自獨特的特性,現有方法很難將其同時建模在一個模型中.
事實上,描述同一語義的不同媒體類型數據存在天然的語義一致性,且數據內部蘊含著豐富的細粒度上下文信息.其中,細粒度指的是數據的局部區域或片段,上下文指的是這些區域或片段間的關聯關系,如圖像前景區域和背景區域之間的關系或前后視頻幀之間的關系,充分利用細粒度上下文信息能夠有效挖掘不同媒體數據之間的關聯.例如,在多種媒體交叉檢索的場景下,很可能文本的某一部分描述并未在圖像中體現,但卻和音頻或視頻的某一片段存在明顯的關聯.這表明,在多種媒體相互檢索的任務中,不同媒體數據之間存在著豐富的語義互補關系,能夠為跨媒體關聯學習提供充足的線索,而且挖掘其中細粒度信息之間的語義關聯尤為重要.然而,現有方法一般僅考慮了不同媒體數據的成對關聯,忽略了細粒度局部上下文信息之間的語義關聯.此外,現有方法一般僅使用語義類別信息來約束不同媒體數據之間的關聯學習,在多種媒體的場景下,其約束能力不足以彌補多種媒體數據間的分布差異.針對上述問題,本文提出了跨媒體深層細粒度關聯學習方法,同時在語義和分布兩個方面挖掘多達5種媒體類型數據(圖像、視頻、文本、音頻和3D模型)細粒度上下文信息間的關聯關系.本文主要貢獻如下.
(1) 提出了針對5種媒體的跨媒體循環神經網絡,構建統一的網絡結構聯合建模不同媒體數據內部的細粒度信息,并進一步挖掘不同媒體數據細粒度局部區域或片段之間的上下文關系,充分學習各種媒體內獨有的內在信息,為跨媒體關聯學習提供更加細粒度的線索.
(2) 提出了基于分布對齊和語義對齊的跨媒體聯合關聯損失函數.一方面,通過分布對齊彌補不同媒體類型數據之間的分布差異;另一方面,通過語義對齊增強關聯學習過程中的語義辨識能力.使分布對齊與語義對齊相互促進,實現對不同媒體數據的語義一致性表達,更好地在 5種媒體條件下實現細粒度跨媒體關聯分析與挖掘,提升跨媒體檢索的準確率.
為了驗證方法的有效性,本文在兩個包含5種媒體(圖像、視頻、文本、音頻和3D模型)的跨媒體數據集PKU XMedia和PKU XMediaNet上與現有方法進行實驗對比,結果表明,本文方法有效地提高了跨媒體檢索的準確率.
1 相關工作
1.1 針對兩種媒體的跨媒體檢索方法
現有方法往往旨在解決兩種媒體類型數據之間的異構鴻溝問題,通常是針對圖像和文本,將其映射至統一空間得到跨媒體統一表征.其中,傳統方法通過優化特定統計量來學習線性映射矩陣.典型相關分析(canonical correlation analysis,簡稱 CCA)[11]是第一個被廣泛使用的跨媒體模型,該方法通過最大化不同媒體類型成對數據之間的關聯來優化模型.一些后續工作基于典型相關分析進行了擴展,例如,Hardoon等人[17]提出核典型相關分析(kernel canonical correlation analysis,簡稱KCCA),利用核函數實現非線性典型相關分析.此外,Li等人[18]提出了跨媒體因子分析(cross-modal factor analysis,簡稱CFA)算法,通過最小化成對數據之間的Frobenius范數來優化跨媒體模型.
近年來,深度網絡在圖像識別[19,20]、視頻分類[21]等領域顯示出強大的學習能力.受此啟發,一些工作嘗試使用深度網絡來學習統一表征以實現跨媒體檢索.Andrew等人[22]提出深度典型相關分析(deep canonical correlation analysis,簡稱 DCCA)方法,通過兩個子網絡的輸出關聯來優化模型.Feng等人[8]構建對應自編碼器(correspondence autoencoder,簡稱 Corr-AE),通過中間層來鏈接兩路子網絡,同時對關聯關系和重建信息進行建模.Wei等人[23]提出的深度語義匹配(deep semantic match,簡稱Deep-SM)模型使用卷積神經網絡來建模圖像數據,從而進一步挖掘語義關聯信息.Peng等人[15]提出了跨媒體多網絡結構(cross-media multiple deep network,簡稱CMDN)模型,將媒體內和媒體間的關聯信息通過層次化網絡的方式進行聯合學習以提升檢索準確率.他們在此基礎上進一步提出了跨模態關聯學習(cross-modal correlation learning,簡稱CCL)方法[24],通過多任務學習的方式挖掘不同媒體類型數據的粗細粒度信息.Huang等人[25]提出了基于混合遷移網絡的跨媒體統一表征(cross-modal hybrid transfer network,簡稱CHTN)方法,實現了從單媒體源域到跨媒體目標域的知識遷移.此外,對抗式學習也被應用在跨媒體檢索中[26].
1.2 針對多種媒體的跨媒體檢索方法
目前僅有很少的工作針對多于兩種媒體的交叉檢索任務,其中,Zhai等人[27]嘗試構建圖模型來學習映射矩陣,首先將 5種媒體同時在傳統框架中建模,并進一步提出了聯合表示學習(joint representation learning,簡稱JRL)方法[10],加入語義信息和半監督規約來構建統一空間.此外,Peng等人[28]提出構建統一的跨媒體關聯超圖,同時利用了不同媒體的細粒度信息并結合半監督規約來學習跨媒體統一表征.然而,由于以上方法均使用傳統框架學習線性映射,難以充分挖掘多達 5種媒體類型數據之間的關聯關系.而某些基于深度學習的方法,如深度語義匹配模型,盡管可以通過增加子網絡的方式將其擴展至多種媒體,但其僅考慮了數據內部的語義類別信息,難以挖掘多種媒體之間復雜且多樣的關聯關系.
本文旨在彌補上述缺陷,聯合建模多達 5種媒體類型數據的細粒度上下文信息,同時實現不同媒體數據類型數據之間的語義對齊和分布對齊,從而提升5種媒體交叉檢索的準確率.
2 本文方法
本文方法的網絡結構如圖3所示.首先,構建針對5種媒體數據的跨媒體循環神經網絡,通過將不同媒體類型數據的局部區域或片段序列輸入到循環神經網絡中建模數據內部的細粒度上下文信息.然后,在循環神經網絡之上設計跨媒體聯合關聯損失函數,通過語義對齊和分布對齊相結合的方式,聯合優化異構數據到統一空間的映射,從而學習更加精確的細粒度跨媒體關聯.
首先介紹本文的形式化定義,其中,D={DI,DT,DA,DV,DM}為包含 5種媒體類型的跨媒體數據集,{xi,xt,xa,xv,xm}∈D分別代表數據集中圖像、文本、音頻、視頻和3D模型數據.此外,定義l∈{i,t,v,a,m}表示任意一種媒體類型,這樣,{xl,yl}∈D分別代表數據集中的任意媒體類型的數據及其類別標簽.跨媒體檢索旨在給定任意一種媒體類型的數據,返回與其語義相關的所有媒體類型的檢索結果.
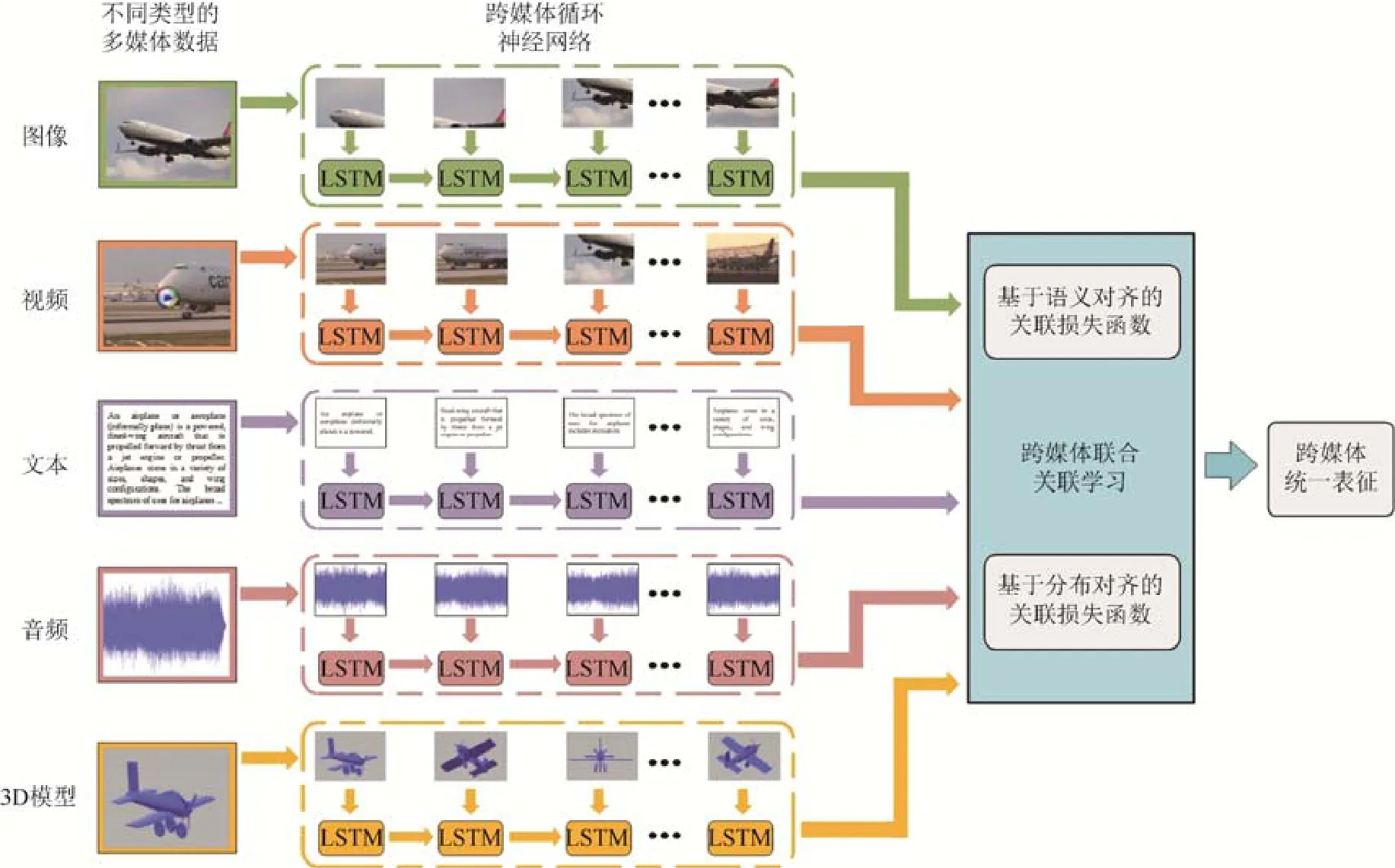
Fig.3 An overview of our proposed FGCL approach圖3 本文方法整體框架示意圖
2.1 跨媒體循環神經網絡
為了充分利用多種媒體類型數據中豐富的細粒度上下文信息,本文構建了多路循環神經網絡,將每種媒體類型數據的局部區域或片段的序列輸入到循環神經網絡來學習細粒度特征表示.對不同媒體類型數據分別進行分割并獲取細粒度特征序列的具體策略將在第2.3節中詳細加以介紹.
上述得到的每種媒體類型數據局部區域或片段的特征序列蘊含了豐富的細粒度信息,進一步將其輸入到循環神經網絡中來充分挖掘不同媒體類型數據內部的細粒度上下文信息.本文采用了長短時記憶(long short term memory,簡稱 LSTM)網絡[29],LSTM 網絡作為一種特殊的循環神經網絡,能夠利用記憶單元(cell)及門限(gate)的更新有效地學習序列數據中的長期依賴,并充分保存歷史時間步中的信息.本文將上述每種媒體類型數據的特征按照序列逐步輸入到LSTM網絡中,并根據如下公式逐步更新網絡:
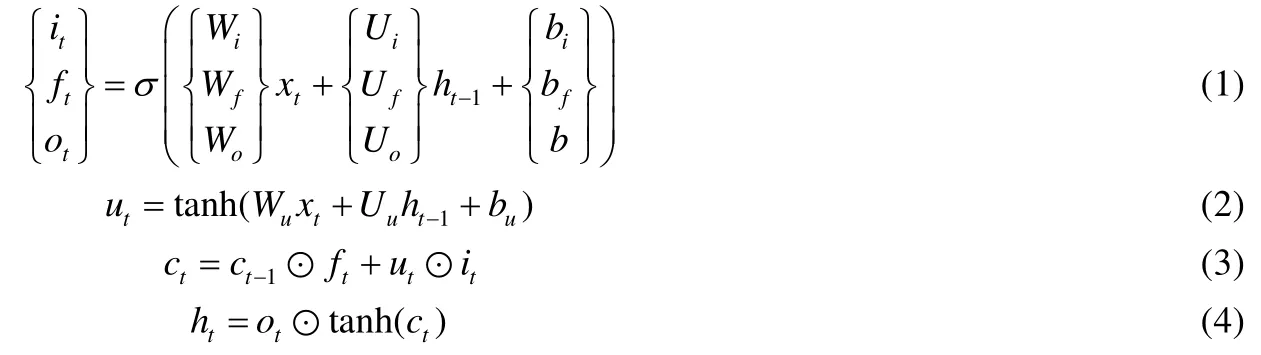
其中,x表示輸入序列,i,f,o和c分別表示輸入門、遺忘門、輸出門和記憶單元,⊙表示元素相乘,而σ表示Sigmoid激活函數,W和U為循環神經網絡中待學習的參數.將輸出序列通過全連接層就可以得到每種媒體數據固定維數的序列特征,隨后將序列特征取平均得到,其中,j為序列長度.這樣,每個任意媒體類型數據的特征hl都包含了豐富的細粒度上下文信息,為進一步挖掘跨媒體細粒度關聯關系提供了重要線索.
2.2 跨媒體聯合關聯學習
在得到包含細粒度上下文信息的不同媒體特征之后,如何更好地將其映射至統一空間中成為解決 5種媒體類型數據間交叉檢索的關鍵問題.具體地,本文在上述循環神經網絡頂層提出了基于分布對齊和語義對齊的跨媒體聯合關聯損失函數,通過彌補不同媒體類型數據之間的分布差異,同時充分利用了數據的語義類別信息增強關聯學習過程中的語義辨識能力,能夠更好地在5種媒體的條件下實現細粒度跨媒體關聯的分析與挖掘.
首先,我們設計了基于語義對齊的關聯損失函數.將第2.1節得到的不同媒體類型的數據表征hl通過全連接網絡(fully-connected network)映射到統一的語義空間中,并采用如下損失函數來約束不同媒體類型數據之間的語義關聯:
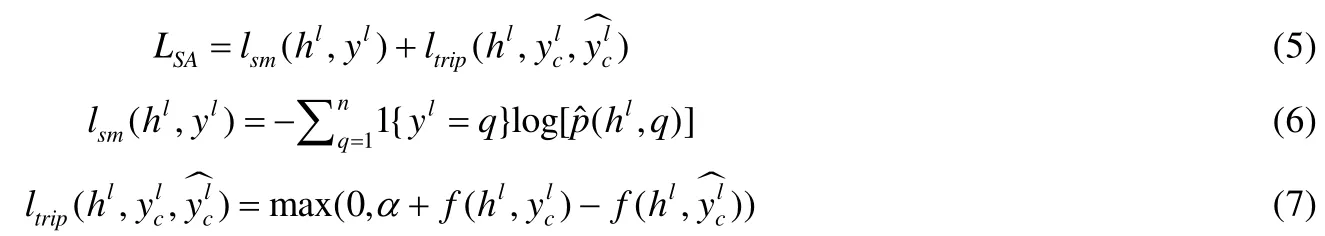
其中,lsm(hl,yl)為交叉熵損失函數項,yl為hl的語義類別標簽,共有n個類別.當yl=q時,1{yl=q}值為1,否則,其值為表示預測該樣本屬于第q個類別的概率.
通過三元組的形式,約束屬于相同語義類別的不同媒體類型數據,使其距離其對應類別的特征向量盡可能地近,同時距離其他類別的特征向量盡可能地遠.由于類別標簽通過 Word2Vec模型來映射,其映射后的特征向量本身帶有語義信息,通過將不同媒體數據映射到其類別向量周圍,使得不同媒體數據映射后的統一表征保留其對應類別的語義信息,同時保證它們的語義一致性.因此,通過基于語義對齊的關聯損失函數,能夠有效地增強統一表征的語義辨識能力,促進細粒度的跨媒體關聯挖掘.
進一步地,我們設計了基于分布對齊的關聯損失函數.具體地,我們采用最大均值差異(maximum mean discrepancy,簡稱 MMD)[31]損失函數來優化不同媒體類型數據之間的分布差異.最大均值差異被廣泛使用在遷移學習和域自適應中,是衡量兩個數據分布差異的重要標準.其基本原理是針對兩個不同分布的樣本,通過尋找在樣本空間上的連續函數,使不同分布的樣本在該函數上函數值均值的差值最大,從而得到最大均值差異MMD.通過最小化 MMD損失,可以減小不同分布之間的差異,達到對齊分布的效果.基于上述思想,我們定義了如下基于分布對齊的關聯損失函數:

其中,i,j表示任意兩種不同的媒體類型.而任意兩種媒體類型數據之間的MMD損失函數定義如下:
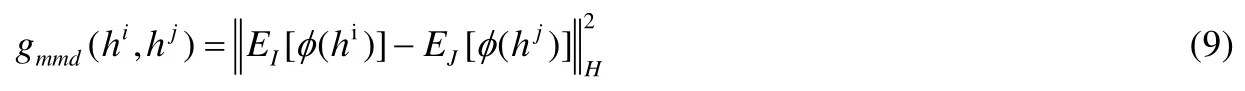
其中,MMD損失函數是在再生希爾伯特空間(reproducing kernel Hilbert space,簡稱RKHS)的平方形式.通過最小化上式,可以減小hi和hj之間的分布差異,達到不同媒體類型之間的分布對齊.綜上,基于語義對齊和分布對齊的跨媒體聯合關聯損失函數定義如下:

通過最小化上述損失函數,不僅可以增強跨媒體統一表征的語義辨識能力,在統一空間中將不同媒體類型的數據約束至其語義中心,同時可以減小 5種媒體之間的數據分布差異,從而有效學習不同媒體類型數據細粒度上下文信息之間的關聯關系,提高跨媒體檢索的準確率.
2.3 實現細節
本文提出的網絡在Torch框架上得以實現.具體地,對于每個圖像樣本xi,將其縮放后輸入VGG-19卷積神經網絡[32],通過最后一個池化層(pool5)來提取出49個不同區域的局部特征,每個特征維數為512維,然后按照人眼觀察的順序組成序列.對于每個文本樣本xt,首先按照段落或語句將其切分成片段,然后利用文本卷積神經網絡[33]對每個片段提取300維特征,最后按照文本片段本身順序組成序列.對于每個音頻樣本xa,按照固定時間間隔將其分割成片段,對每個片段分別提取128維Mel頻率倒譜系數特征(mel frequency cepstrum coefficient,簡稱MFCC)形成序列.對于視頻,對每一個視頻幀提取VGG-19網絡[32]全連接層(fc7)的4 096維圖像特征,然后按照其原本時間順序組成序列.對于 3D模型,我們采用 47個不同角度來觀察 3D模型數據,然后使用光場描述子(light field)[34]對每一個角度提取 100維特征,再依照文獻[28]將其組成序列.總的來說,針對特征選擇,本文旨在探究跨媒體關聯學習問題,特征選擇并非本文重點,且本文的模型可以支持多種輸入特征.針對序列選擇,對于帶有內在序列性質的媒體類型,如文本、音頻和視頻,我們按照其天然順序將區域片段組成序列.對于序列性質不明顯的媒體類型,如圖像和 3D 模型,我們按照固定順序組成序列,且其細粒度數據之間的順序對關聯學習的最終結果影響不大.使用上述固定切分方式不僅能夠有效地保留某些媒體數據的細粒度單元,也降低了模型的復雜度.此外,在實驗過程中,我們將跨媒體循環神經網絡的輸出,即統一表征的維數設置為 300維,語義對齊關聯損失函數(見公式(7))中的邊界參數α設置為1,網絡訓練的學習率固定為1e-4.
本文模型訓練過程需要 25個 epoch,時間復雜度和其他基于深度網絡的跨媒體檢索方法相當,并且由于算法充分挖掘了跨媒體細粒度數據之間的上下文關系,泛化能力較強,輸入特征可以直接使用預訓練的深度網絡或是傳統特征而不需要進行微調,這也縮短了算法的運行時間.空間復雜度上,一方面循環神經網絡的自身性質決定了不同時刻輸入循環神經網絡的數據經過同一個神經元,大大節省了參數量.另一方面,較低的統一空間維度(300維)也減少了模型的空間復雜度.
3 實 驗
本文在兩個具有挑戰性的跨媒體數據集PKU XMedia和PKU XMediaNet上進行了多種媒體的交叉檢索實驗,兩個數據集均包含多達5種媒體類型(圖像、文本、音頻、視頻和3D模型)的數據.為了更加全面地驗證本文提出方法的有效性,我們進行了兩大類的實驗對比,包括5種媒體的交叉檢索和2種媒體(圖像和文本)的相互檢索,與12種現有方法進行了對比.此外,本文還進一步通過基線實驗以驗證本文方法各個部分的效果.
3.1 數據集介紹
下面簡要介紹本文使用的兩個包含5種媒體類型的跨媒體數據集,每個數據集均劃分為訓練集、驗證集和測試集3個部分,具體劃分方式見表1和表2.
數據集網址為http://www.icst.pku.edu.cn/mipl/XMedia.
PKU XMedia數據集[2]是第一個包含5種媒體類型的跨媒體數據集.數據集共有20個常見的語義類別,比如自行車、鋼琴、昆蟲等,數據來源包括維基百科(Wikipedia)、Flickr、YouTube等.
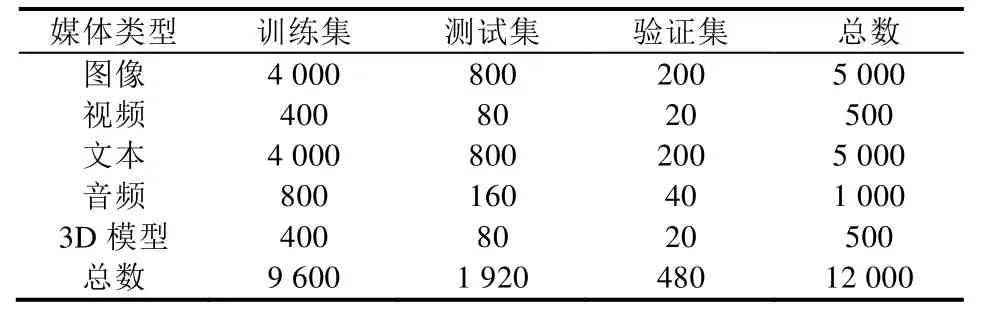
Table 1 The dataset partition on PKU XMedia表1 PKU XMedia數據集的劃分方式
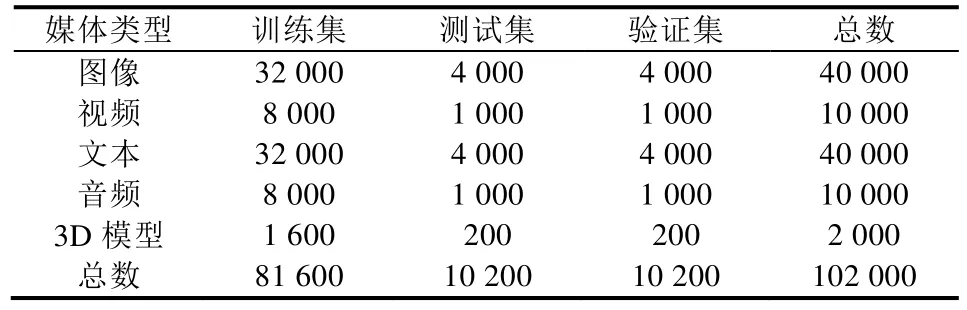
Table 2 The dataset partition on PKU XMediaNet表2 PKU XMediaNet數據集的劃分方式
PKU XMediaNet數據集[2]是目前國際上最大的包含5種媒體類型的跨媒體數據集,共包含超過10萬個數據樣本,其規模是XMedia的10倍.共包含了200個常見類別,主要分為動物和人造物兩大類.圖4展示了該數據集的部分樣例.數據來源包括Wikipedia、Flickr、YouTube、Freesound、Yobi3D等.

Fig.4 Quintuple-media examples from PKU XMediaNet dataset圖4 來自PKU XMediaNet數據集的5種不同媒體類型數據示意圖
3.2 評價指標和對比方法
不同媒體數據之間的相似度可以通過計算跨媒體統一表征之間的距離來得到,本文采用余弦距離來計算相似度,從而對檢索結果進行排序.為了全面驗證本文方法的有效性,我們分別設置了5種媒體交叉檢索和2種媒體相互檢索的實驗.
3.2.1 5種媒體交叉檢索
5種媒體交叉檢索是指將任意一種媒體類型的查詢樣例作為輸入,檢索所有5種媒體類型數據中與之語義相關的結果.舉例來說,將圖像作為查詢樣例輸入,檢索測試集中圖像、文本、音頻、視頻和 3D模型的樣本,表示為圖像檢索全部(Image?All).以其余 4種媒體類型作為查詢的檢索可以表示為:文本檢索全部(Text?All)、音頻檢索全部(Audio?All)、視頻檢索全部(Video?All)和3D模型檢索全部(3D?All).
本文采用平均準確率均值(mean average precision,簡稱MAP)作為評價指標,該指標能夠同時兼顧返回結果的排序以及準確率,在信息檢索領域被廣泛使用.具體地,首先計算查詢樣本所有返回結果的平均準確率(average precision,簡稱AP),然后計算所有查詢的AP結果的平均值得到最終的MAP值.
本文方法與3種支持5種媒體場景或可以擴展至5種媒體場景的現有方法進行了實驗對比,分別是JRL[10]、S2UPG[28]和Deep-SM[23],其中,前兩種是直接支持5種媒體的交叉檢索的傳統方法,而Deep-SM[23]是基于深度學習的方法,其本身僅針對兩種媒體相互檢索,但可以通過擴充另外 3路子網絡的方式來支持 5種媒體的交叉檢索.為了更加公平地與現有方法進行比較,所有方法在 5種媒體上都使用了與本文相同的深度網絡或描述子來提取輸入特征.具體地,對于圖像,我們采用在ImageNet數據集上預訓練,并在目標數據集上微調的VGG-19卷積神經網絡[32]提取4 096維全連接層特征(fc7).對于文本,我們依照文獻[33]中的方式通過文本卷積神經網絡對其提取300維的特征.對于音頻,我們對音頻幀分別提取Mel頻率倒譜系數特征(mel frequency cepstrum coefficient,簡稱MFCC),然后取平均獲得128維MFCC特征.對于視頻,我們通過平均每一個視頻幀的VGG-19網絡全連接層特征(fc7)得到4 096維特征.對于3D模型,我們將47個角度的光場描述子特征(light field)[34]拼接得到4 700維特征.
3.2.2 兩種媒體相互檢索
由于現有方法往往僅針對兩種媒體的跨媒體檢索任務,且以圖像和文本相互檢索為主,為了更全面地與現有方法進行實驗比較,本文也進行了圖像和文本相互檢索的實驗,包括兩個檢索任務:圖像檢索文本(Image?Text)和文本檢索圖像(Text?Image).實驗結果評估同樣采用了第3.2.1節中提到的MAP指標,這里需要說明的是,本文中的 MAP值通過計算每個樣例返回的所有檢索結果得到,與 Corr-AE[8]以及 ACMR[26]中僅使用前 50個返回結果的計算方式不同.圖像文本相互檢索的實驗對比了 12種現有方法,包括 6種傳統跨媒體檢索方法:CCA[11]、CFA[18]、KCCA[17]、JRL[10]、S2UPG[28]和LGCFL[9],以及6種基于深度學習的跨媒體檢索方法:Corr-AE[8]、DCCA[22]、Deep-SM[23]、CMDN[15]、CCL[24]和 ACMR[26].為了實驗的公平對比,如第 3.2.1 節中所述,所有對比方法的圖像和文本都使用了相同的輸入特征.本文代碼已經發布在https://github.com/PKU-ICSTMIPL,對比方法JRL[10]、S2UPG[28]、CMDN[15]和CCL[24]的發布代碼也在此目錄下.
3.3 與現有方法的實驗結果對比
3.3.1 5種媒體交叉檢索
5種媒體交叉檢索的實驗結果見表3和表4.從對比結果可以看出,本文提出的方法在兩個數據集上均超過了所有對比方法,跨媒體檢索的準確率有比較明顯的提升.以 PKU XMediaNet數據集為例,平均檢索準確率從0.303提升到0.366.對比方法中,基于深度網絡的Deep-SM方法未能超過另外兩種基于傳統框架的方法JRL和S2UPG,因為其只考慮了粗粒度的全局語義信息,沒有考慮不同媒體數據之間的分布差異.而本文方法充分挖掘了不同媒體數據內部的細粒度上下文信息,同時結合語義對齊和分布對齊來優化不同媒體數據到統一空間的映射,更好地克服了5種媒體之間的異構鴻溝問題.

Table 3 Results of cross-media retrieval with five media types on PKU XMedia dataset表3 PKU XMedia數據集上的5種媒體交叉檢索結果

Table 4 Results of cross-media retrieval with five media types on PKU XMediaNet dataset表4 PKU XMediaNet數據集上的5種媒體交叉檢索結果
3.3.2 兩種媒體相互檢索
圖像文本相互檢索的實驗結果見表5和表6,本文提出的方法在兩個數據集上同樣超過了12種對比方法,表明本文方法在兩種媒體相互檢索的場景下同樣具有很好的效果.對比方法中,傳統方法和基于深度學習的方法的檢索準確率并沒有很大的差異,一些傳統方法甚至超過了部分基于深度學習的方法,例如JRL[10]、S2UPG[28]和 LGCFL[22].另一方面,CCL[24]方法采用多任務學習的方式同時考慮粗細粒度的信息,在對比方法中取得了最好的結果.而本文方法不僅充分挖掘了數據內部的細粒度信息,還考慮到了它們之間的上下文關系,有效地學習了兩種媒體類型數據之間的關聯關系.
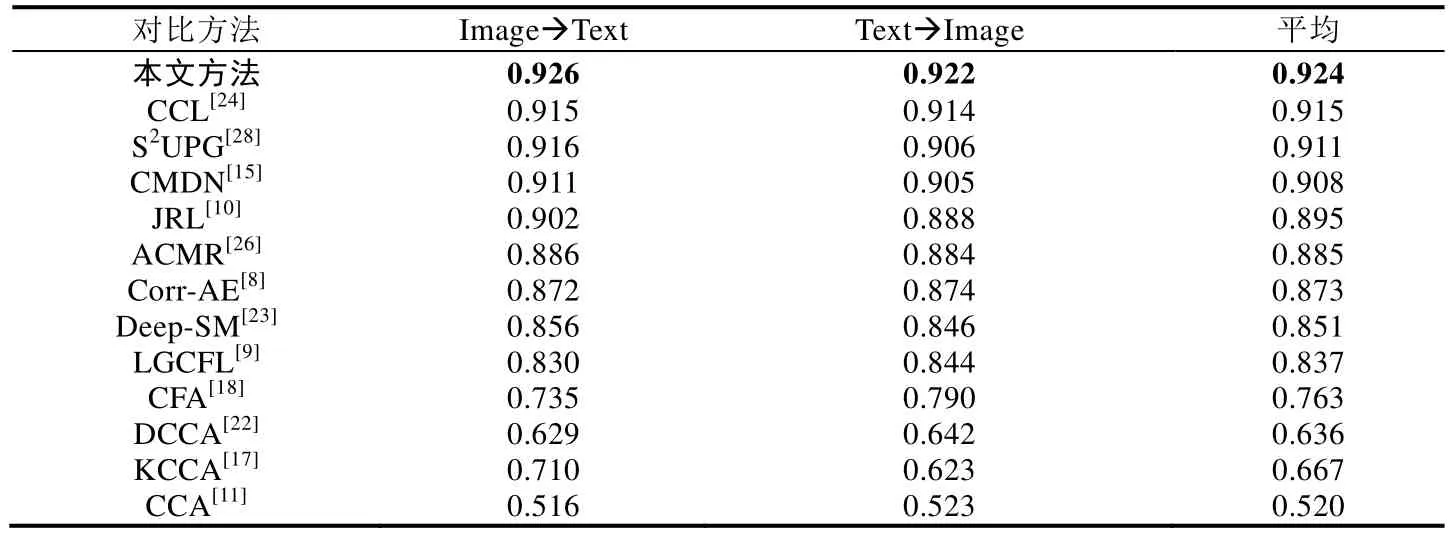
Table 5 Results of cross-media retrieval between image and text on PKU XMedia dataset表5 PKU XMedia數據集上的兩種媒體相互檢索結果
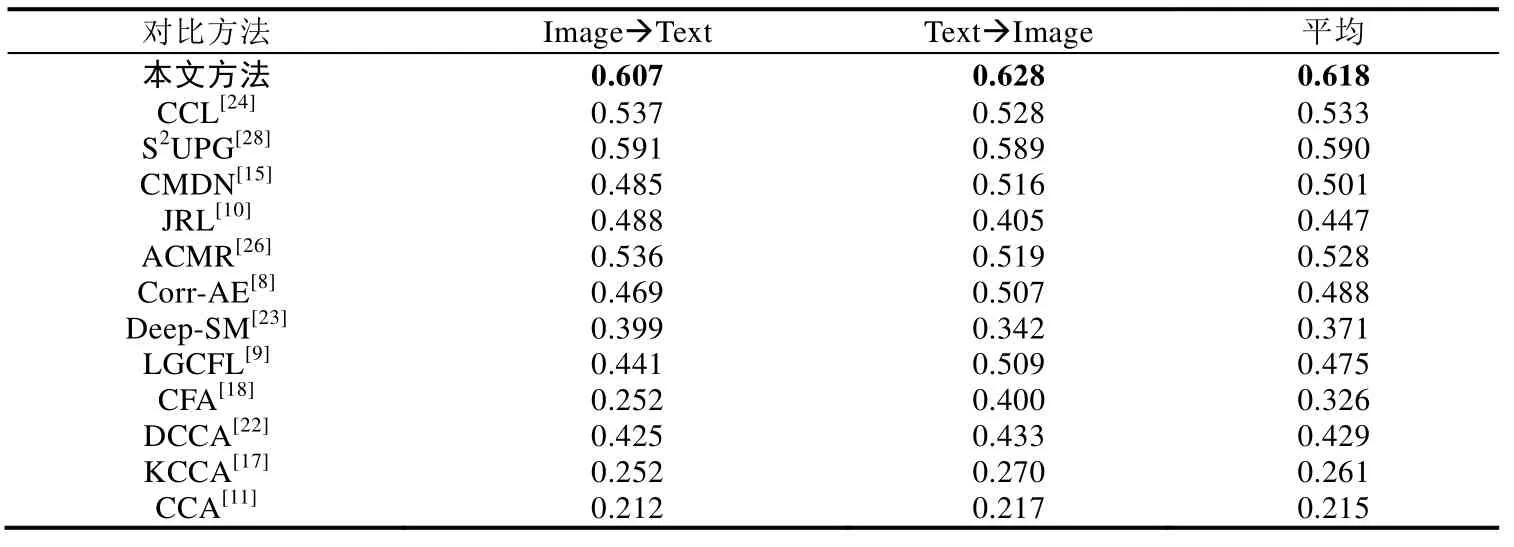
Table 6 Results of cross-media retrieval between image and text on PKU XMediaNet dataset表6 PKU XMediaNet數據集上的兩種媒體相互檢索結果
3.4 基線實驗結果分析
為了驗證本文方法各個部分的效果,我們進一步進行了基線實驗的對比,其中,“無三元組損失”表示去掉語義對齊關聯損失函數(見公式(5))中的三元組損失函數(見公式(7))部分,“無 MMD損失”表示去掉分布對齊關聯損失函數(見公式(8)),“基線方法”表示同時去掉上述兩個部分,僅使用語義類別信息(見公式(6))來約束不同媒體類型數據到統一空間的映射.從表 7和表 8可以看出,僅使用語義類別約束的平均檢索準確率也同樣高于 3種對比方法的結果,表明充分利用數據內部的細粒度上下文信息能夠更有效地建模不同媒體類型數據之間的關聯關系,而三元組損失函數和分布對齊損失函數能夠使模型在擁有語義辨識能力的同時,有效地將不同媒體類型數據的分布在統一空間內對齊,進一步提高了跨媒體檢索的準確率.

Table 7 Baseline experiments on PKU XMedia dataset表7 PKU XMedia數據集上的基線實驗結果

Table 8 Baseline experiments on PKU XMediaNet dataset表8 PKU XMediaNet數據集上的基線實驗結果
4 結 論
本文提出了跨媒體深層細粒度關聯學習方法,首先提出跨媒體循環神經網絡以充分挖掘多達 5種媒體類型數據的細粒度上下文信息,然后設計了跨媒體聯合關聯損失函數,將分布對齊和語義對齊相結合,在準確挖掘媒體內和媒體間細粒度關聯的同時,利用語義類別信息增強關聯學習過程中的語義辨識能力,有效提升了跨媒體檢索的準確率.通過在兩個包含多達5種媒體類型(圖像、視頻、文本、音頻和3D模型)的跨媒體數據集PKU XMedia和PKU XMediaNet上與現有方法進行實驗對比,表明了本文方法在多種媒體交叉檢索任務的有效性.
下一步工作將嘗試擴展現有框架,在不同尺度上挖掘跨媒體數據之間的關聯關系,同時充分利用無標注數據并結合外部知識庫以進一步提升跨媒體檢索的準確率.
猜你喜歡
當代陜西(2021年17期)2021-11-06 03:21:36
開放教育研究(2020年2期)2020-03-31 01:54:14
學苑創造·A版(2018年11期)2018-02-01 06:29:20
讀者(2017年5期)2017-02-15 18:04:18
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年2期)2011-01-23 06:39:12
