MGSC:一種多粒度語(yǔ)義交叉的短文本語(yǔ)義匹配模型
2019-06-06 06:17:48吳少洪彭敦陸苑威威
小型微型計(jì)算機(jī)系統(tǒng) 2019年6期
吳少洪,彭敦陸,苑威威,陳 章,劉 叢
(上海理工大學(xué) 光電信息與計(jì)算機(jī)工程學(xué)院,上海 200093)
1 引 言
語(yǔ)義理解在自然語(yǔ)言處理任務(wù)中具有十分重要的地位,早期的研究表明,無(wú)論在語(yǔ)法結(jié)構(gòu)上做何種深入研究,都難以達(dá)到理想的效果.后來(lái)發(fā)現(xiàn),一個(gè)完整的自然語(yǔ)言處理任務(wù)繞不開(kāi)語(yǔ)義理解這個(gè)環(huán)節(jié)[1].隨著人工智能和深度學(xué)習(xí)的發(fā)展,智能化文本應(yīng)用正在深入人們生活的方方面面,而語(yǔ)義匹配問(wèn)題廣泛存在于這些應(yīng)用之中.例如,智能檢索和智能問(wèn)答,這兩種應(yīng)用中最基本的問(wèn)題就是如何進(jìn)行文本的正確匹配,那么如何更好地理解用戶的語(yǔ)義(意圖)就顯得格外重要.在智能檢索中,用戶給出目標(biāo)檢索文本,然后系統(tǒng)通過(guò)智能算法在大量數(shù)據(jù)中查找、排序并將最合理的結(jié)果返回給用戶,其中就涉及用戶檢索文本匹配的問(wèn)題;在智能問(wèn)答系統(tǒng)中,需要在答案列表中匹配到和用戶意圖相近的答案.
如表1所示,一個(gè)問(wèn)題及其所對(duì)應(yīng)的若干回答.我們需要在答案列表中找出和問(wèn)題最匹配的答案.
傳統(tǒng)的匹配方法沒(méi)有考慮語(yǔ)義信息,一般從詞、句式、語(yǔ)法結(jié)構(gòu)出發(fā),依賴于人工設(shè)定的特征和規(guī)則,這種硬性的匹配不僅很難達(dá)到滿意的效果,還需要花費(fèi)大量人力物力.而采用機(jī)器學(xué)習(xí)方法,特別是基于深度神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)方法,能夠?qū)崿F(xiàn)文本特性的自動(dòng)提取,因而避免了硬性匹配的缺陷[2].一個(gè)成功的匹配算法需要對(duì)語(yǔ)言對(duì)象的內(nèi)部結(jié)構(gòu)以及它們之間的相關(guān)語(yǔ)義進(jìn)行充分建模.基于這一目標(biāo),本文提出了一種用于匹配兩個(gè)短文本語(yǔ)義的深度神經(jīng)網(wǎng)絡(luò)模型——多粒度語(yǔ)義交叉模型,來(lái)解決諸如信息檢索中信息匹配或者問(wèn)答系統(tǒng)中問(wèn)答匹配的問(wèn)題.實(shí)驗(yàn)發(fā)現(xiàn),多粒度語(yǔ)義交叉模型不僅能夠捕獲不同層次上豐富的匹配模式,而且能夠獲取不同粒度語(yǔ)義的交互特征,在相關(guān)任務(wù)上具有突出的表現(xiàn).

表1 問(wèn)答匹配的例子Table 1 Example of QA matching
2 相關(guān)工作
文本匹配是自然語(yǔ)言處理中一個(gè)基礎(chǔ)性問(wèn)題,而語(yǔ)義匹配是文本匹配研究的重要方向,從根本上解決文本匹配問(wèn)題.在許多任務(wù)中都有應(yīng)用場(chǎng)景.比如,在信息檢索中,要求在文本庫(kù)中找到與用戶檢索目標(biāo)相匹配的信息;在問(wèn)答系統(tǒng)或問(wèn)答機(jī)器人應(yīng)用中,需要實(shí)現(xiàn)問(wèn)題和答案的智能匹配;在機(jī)器翻譯中,需要進(jìn)行兩種語(yǔ)言表達(dá)的匹配.
目前,關(guān)于文本匹配問(wèn)題的解決方案已經(jīng)從傳統(tǒng)的基于統(tǒng)計(jì)的方法轉(zhuǎn)移到基于深度神經(jīng)網(wǎng)絡(luò)的方法上.例如,傳統(tǒng)的匹配方法中,兩個(gè)文本中出現(xiàn)相同詞的個(gè)數(shù)越多,詞序列的排序越接近,則相似度越高.但是,這樣的方法越來(lái)越難以滿足日益提升的用戶使用體驗(yàn).而基于深度神經(jīng)網(wǎng)絡(luò)的方法,是將文本映射到一個(gè)語(yǔ)義空間,數(shù)字化地來(lái)表示文本.一般的做法是采用詞向量表示文本中的詞,即分布式表示[3].文本分詞后,將得到的詞語(yǔ)分別進(jìn)行向量表示,并組合成矩陣來(lái)表示文本.然而,簡(jiǎn)單的詞向量組合難以聯(lián)系文本的上下文信息,丟失了文本的許多語(yǔ)義信息,同時(shí)也忽略了詞語(yǔ)之間的內(nèi)在聯(lián)系.于是,一些模型引入循環(huán)神經(jīng)網(wǎng)絡(luò)的方法捕獲文本上下文信息,如2015年ShengxianWan等人提出的MV-LSTM模型[4].
總體來(lái)看,目前關(guān)于深度文本匹配模型主要有三種類型.第一種是基于單文本的,即用一個(gè)向量表示文本,再對(duì)文本向量做相似度計(jì)算,比如2015年Baotian Hu,Hang Li等人提出的ACR-I模型[5]、DSSM模型[10].第二種是在單文本上做多語(yǔ)義表示,通過(guò)不同粒度的語(yǔ)義計(jì)算文本相似度,如MultiGranCNN模型[6]和MV-LSTM模型[4].第三種則認(rèn)為更早地讓兩文本交互,再提取深層次的交互信息更有利于解決文本匹配問(wèn)題,比如Baotian Hu,Hang Li等人提出的ACR-II模型[5]、Pang L 等人提出的MatchPyramid模型[14]等.
多語(yǔ)義方法和直接建模方法在許多實(shí)驗(yàn)中被證明比基于單文本的方法效果好,但兩者在不同的匹配任務(wù)中表現(xiàn)得各有優(yōu)勢(shì).本文提出多粒度語(yǔ)義交叉模型,對(duì)兩文本進(jìn)行建模匹配.該模型結(jié)合了多語(yǔ)義和直接建模兩種思想:首先通過(guò)兩個(gè)方向的循環(huán)神經(jīng)網(wǎng)絡(luò)分別獲取文本的上下文信息,得到不同粒度的語(yǔ)義表示,再由這些不同粒度的語(yǔ)義信息兩兩進(jìn)行語(yǔ)義信息交互,進(jìn)一步獲得含有語(yǔ)義交互信息的交互矩陣,對(duì)交互矩陣進(jìn)行一系列的卷積和池化操作后,再由一個(gè)多層感知機(jī)輸出兩個(gè)文本的匹配度.實(shí)驗(yàn)表明,本文的模型具有出色的競(jìng)爭(zhēng)力.
3 多粒度語(yǔ)義交叉模型
3.1 問(wèn)題定義與分析
對(duì)于給定的樣本數(shù)據(jù)sample={score,s1,s2},其中s1,s2表示給出的兩個(gè)短文本(例如問(wèn)答系統(tǒng)中的一問(wèn)一答),score表示相應(yīng)兩個(gè)文本s1、s2的匹配度(例如問(wèn)答系統(tǒng)中問(wèn)答的相關(guān)程度),目標(biāo)是訓(xùn)練一個(gè)匹配模型,能夠合理地評(píng)估任意兩個(gè)短文本間的匹配程度,使得M(s1、s2)?score.例如,給出問(wèn)答對(duì):
s1:長(zhǎng)頸鹿吃什么?
s2:它吃樹(shù)葉和嫩枝.
通過(guò)模型,判斷s1、s2是否匹配,匹配度有多少.
考慮文本上下文的信息關(guān)聯(lián),可通過(guò)兩個(gè)方向的長(zhǎng)短期記憶模型LSTM(Long Short-Term Memory)[7]來(lái)獲取文本上下文信息,將文本的詞向量嵌入矩陣定義為該文本的原語(yǔ)義,那么將原語(yǔ)義通過(guò)正向的LSTM得到正向的語(yǔ)義表示,稱為正語(yǔ)義,將原語(yǔ)義通過(guò)反向的LSTM得到反向的語(yǔ)義表示,稱為反語(yǔ)義.如圖1所示,每個(gè)語(yǔ)義矩陣由三個(gè)向量組成,向量代表的語(yǔ)義的粒度是不一樣的,例如在正語(yǔ)義中“長(zhǎng)頸鹿/吃”就包含了“長(zhǎng)頸鹿”和“吃”兩個(gè)部分的語(yǔ)義信息,而有的向量只表示一個(gè)詞語(yǔ)的語(yǔ)義信息,如原語(yǔ)義中的三個(gè)向量.

圖1 “長(zhǎng)頸鹿吃什么”三種語(yǔ)義的矩陣表示Fig.1 Three kinds of semantic matrix representation of “What Giraffe Eats”
考慮兩個(gè)短文本語(yǔ)義之間的交互信息.很明顯,兩個(gè)文本語(yǔ)義之間的交互信息越多,則兩個(gè)文本語(yǔ)義的匹配度也越高,一個(gè)簡(jiǎn)單有效的做法是直接對(duì)兩個(gè)文本語(yǔ)義矩陣做余弦相似度計(jì)算.
考慮不同粒度語(yǔ)義之間的交互.前人對(duì)于文本匹配的研究一般只考慮兩個(gè)待匹配文本原語(yǔ)義之間的交互信息,或者只考慮多種語(yǔ)義(比如,原語(yǔ)義、正語(yǔ)義和反語(yǔ)義)串聯(lián)之后的交互信息,例如MV-LSTM模型[4].本文試圖考慮不同粒度的語(yǔ)義之間的交互信息來(lái)幫助計(jì)算匹配度.
如圖2所示是s1的正語(yǔ)義和s2的正語(yǔ)義的交互圖,其中兩個(gè)文本中重要的匹配信息用粗線表示,類似“長(zhǎng)頸鹿—它”和“長(zhǎng)頸鹿/吃/什么—它/吃/樹(shù)葉/和/嫩枝”這兩種匹配關(guān)系的匹配粒度是不一樣的.所以考慮不同粒度語(yǔ)義之間的交互,以獲得更多文本間的匹配信息.
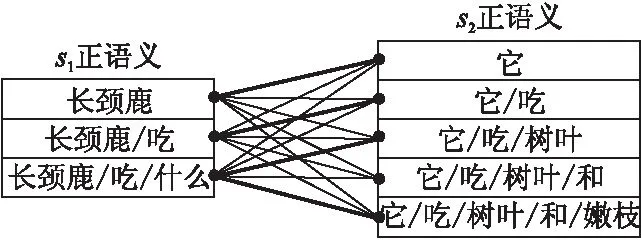
圖2 不同粒度語(yǔ)義交互Fig.2 Semantic interactions with different granularities
考慮所有交互信息特征的融合和提取.本文嘗試采用張量和卷積神經(jīng)網(wǎng)絡(luò)的方法來(lái)融合和提取交互信息中重要的特征表示.最后根據(jù)所提取到的特征,通過(guò)多層感知機(jī)計(jì)算兩個(gè)短文本的匹配度.
3.2 模型
基于以上分析研究,本文提出了多粒度語(yǔ)義交叉模型來(lái)解決文本匹配的問(wèn)題,模型如圖一所示.模型主要包括四個(gè)部分:
a)多粒度語(yǔ)義,包括原語(yǔ)義、正語(yǔ)義和反語(yǔ)義的準(zhǔn)備;
b)語(yǔ)義交叉,包括語(yǔ)義交叉和交互張量的計(jì)算過(guò)程;
c)卷積和池化,包括若干個(gè)卷積層和池化層的計(jì)算;
d)多層感知機(jī),用于計(jì)算匹配度.
3.2.1 多粒度語(yǔ)義
模型的輸入是預(yù)先訓(xùn)練好的詞向量.目前已有一些現(xiàn)存的詞向量訓(xùn)練工具,如Word2vec[3]或者Glove[8]等基于大量文本無(wú)監(jiān)督生成的詞向量.已有研究表明,利用這些工具所得的詞向量具有普適性(或通用性),在很大程度上能夠給模型帶入更多知識(shí).對(duì)于短文本,其詞向量嵌入表示為:
S=[x1,x2,…,xi,…,xn]T
(1)
其中,xi表示文本中第i個(gè)詞的詞向量,詞向量的維度為d,文本中詞的個(gè)數(shù)為n,文本的原語(yǔ)義Sr=S,Sr,即為文本的原語(yǔ)義.
在此,模型利用正向LSTM和反向LSTM來(lái)獲短得文本上下文不同粒度的語(yǔ)義信息,即正語(yǔ)義和反語(yǔ)義.
在LSTM中包含有三個(gè)門控單元:遺忘門、輸入門以及輸出門,分別用ft、it和ht分別來(lái)表示.它們的計(jì)算過(guò)程如下:
ft=σ(Wf·[ht-1,xt]+bf)
(2)
it=σ(Wi·[ht-1,xt]+bi)
(3)
(4)
Ct=ft*Ct-1+it*Ct
(5)
Ot=σ(WO·[ht-1,xt]+bo)
(6)
ht=Ot*tanh(Ct)
(7)
其中,·表示點(diǎn)乘,*表示點(diǎn)對(duì)點(diǎn)的乘法,xt是輸入層的值;Wf,Wi,WC,Wo是權(quán)重矩陣.σ是sigmoid激活函數(shù),tanh是雙曲正切激活函數(shù).ht表示t時(shí)刻LSTM單元的輸出.
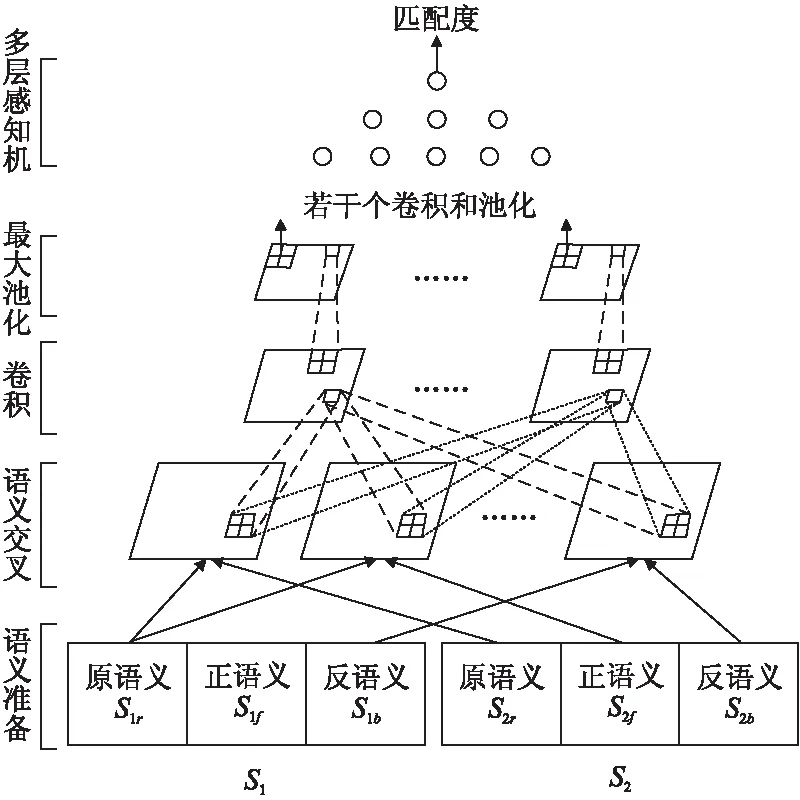
圖3 多粒度語(yǔ)義交叉模型Fig.3 Multi-granularity semantic cross model
以文本的原語(yǔ)義作為輸入,通過(guò)正向的LSTM,模型可以得到文本的正語(yǔ)義表示Sf:
Sf=[hf1,hf2,…,hft,…,hfn]T
(8)
類似地,以文本的原語(yǔ)義作為輸入,通過(guò)反向的LSTM,得到反語(yǔ)義表示Sb:
Sb=[hb1,hb2,…,hbt,…,hbn]T
(9)
這里,hft表示t時(shí)刻正向LSTM的輸出,hbt表示t時(shí)刻反向LSTM的輸出,令
len(hft)=len(hbt)=len(xt)=d
(10)
即hft、hbt的維度和詞向量的維度一致,都為長(zhǎng)度d.
3.2.2 語(yǔ)義交叉
語(yǔ)義交叉層的主要工作是將兩個(gè)文本的信息進(jìn)行融合形成交互特征張量.模型將兩個(gè)待匹配的文本的三種語(yǔ)義信息(原語(yǔ)義、正語(yǔ)義、反語(yǔ)義)進(jìn)行兩兩交互,重組之后,得到交互張量Sc:
SC=[c1,c2,…,cp]
(11)
其中,c為文本語(yǔ)義的交互矩陣,p表示交互矩陣的數(shù)量.在圖3中,p=9,即語(yǔ)義交叉層包含9張交互特征圖.例如c2表示圖3中S1的原語(yǔ)義和S2正語(yǔ)義的交互矩陣,其計(jì)算方式為:
(12)
其中,S1r表示第一個(gè)文本的原語(yǔ)義,S2f表示第二個(gè)文本的正語(yǔ)義.我們把語(yǔ)義之間的這種交互稱為語(yǔ)義交叉.
3.2.3 卷積池化
卷積層的工作主要是利用卷積核過(guò)濾提取特征,每個(gè)卷積核相當(dāng)于一個(gè)“過(guò)濾器”,可以過(guò)濾掉相關(guān)程度較低的匹配信息,使得相關(guān)程度高匹配特征突顯出來(lái).卷積層對(duì)融合層得到的張量表示Sc進(jìn)行卷積計(jì)算,即以Sc作為卷積層的輸入.對(duì)于卷積層的每個(gè)輸出z,有
(13)
其中,卷積核W={w1,w2,…,wk},k為卷積核權(quán)重?cái)?shù)量,b為偏置;xij表示Sc中的元素,f為ReLu激活函數(shù).
最大池化層,其作用是對(duì)卷積層卷積出來(lái)的特征值進(jìn)行篩選,保留每個(gè)池化區(qū)域最大的特征值,忽略池化區(qū)域較小的特征值.保留較大的特征值往往能夠體現(xiàn)交互矩陣中較重要的交互信息.池化層,其輸入為卷積層的輸出,對(duì)于池化區(qū)域?yàn)?×2的池化層,其輸出Rt可表示為:
Rt=maxt({z2i-1,2j-1,z2i-1,2j,z2i,2j-1,z2i,2j})
(14)
其中,Rt表示池化層第t個(gè)池化區(qū)域的輸出,z表示卷積層的輸出.
3.2.4 多層感知機(jī)
模型的最后使用多層感知機(jī)來(lái)計(jì)算匹配度,對(duì)卷積層和池化層篩選保留的重要交互特征進(jìn)行計(jì)算.其輸出為兩個(gè)短文本的匹配度.其計(jì)算公式為:
U=fu(WuR+b),score=fscore(WscoreU+b)
(15)
其中,Wu和Wscore為權(quán)重矩陣,R為池化層的輸出,b為偏置項(xiàng),fu為ReLu激活函數(shù),fscore為sigmoid激活函數(shù).當(dāng)目標(biāo)只需要判斷匹配與不匹配時(shí),匹配問(wèn)題可以視為匹配與不匹配的二分類問(wèn)題.對(duì)于分類問(wèn)題,激活函數(shù)fscore設(shè)為softmax激活函數(shù),預(yù)測(cè)每個(gè)類別的概率值P,P的計(jì)算表達(dá)式為:
(16)
其中,Pj表示預(yù)測(cè)第j類的概率,xj表示第j類的數(shù)值,共有(m+1)個(gè)類別.
4 實(shí)驗(yàn)與分析
我們?cè)趦蓚€(gè)公開(kāi)的數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn),涉及兩個(gè)任務(wù),分別是問(wèn)題去重和問(wèn)答匹配.實(shí)驗(yàn)通過(guò)模型在兩個(gè)任務(wù)上的表現(xiàn)以及和其他模型的比較來(lái)驗(yàn)證模型的有效性,在兩個(gè)不同類型的任務(wù)上的表現(xiàn)不僅可以證明模型的競(jìng)爭(zhēng)性,也可以在一定程度上驗(yàn)證模型在語(yǔ)義匹配任務(wù)上的通用性.
4.1 實(shí)驗(yàn)設(shè)置
實(shí)驗(yàn)環(huán)境為L(zhǎng)inux系統(tǒng),采用基于TensorFlow的Keras深度學(xué)習(xí)框架搭建模型.實(shí)驗(yàn)使用斯坦福大學(xué)公開(kāi)的Glove1https://nlp.stanford.edu/projects/glove
詞向量1,并將每個(gè)詞向量做歸一化的預(yù)處理.文本長(zhǎng)度取固定長(zhǎng)度,超過(guò)長(zhǎng)度截?cái)啵蛔阊a(bǔ)零.對(duì)于未登錄詞,采用在(-0.2,0.2)的均勻分布隨機(jī)生成的向量表示.模型中的參數(shù),包括LSTM、CNN以及多層感知機(jī)的參數(shù),都使用反向傳播訓(xùn)練學(xué)習(xí).
實(shí)現(xiàn)MGSC模型的基本設(shè)置:
實(shí)驗(yàn)1.問(wèn)句長(zhǎng)度取10,答案長(zhǎng)度取40,選用Adadelta作為優(yōu)化器,學(xué)習(xí)率0.1,向量維度50維.
實(shí)驗(yàn)2.兩個(gè)句子長(zhǎng)度均取20,選用Adam作為優(yōu)化器,學(xué)習(xí)率0.001,向量維度300維.
4.2 實(shí)驗(yàn)1:?jiǎn)柎鹌ヅ?/h3>
問(wèn)答系統(tǒng)實(shí)驗(yàn)采用WIKIQA[9]數(shù)據(jù)集,該數(shù)據(jù)集包含3047個(gè)問(wèn)題和29258個(gè)句子,其中有1473個(gè)句子是標(biāo)記為相應(yīng)問(wèn)題的答案.每個(gè)問(wèn)題對(duì)應(yīng)若干句子,當(dāng)句子被標(biāo)簽為0表示不是該問(wèn)題答案,被標(biāo)簽為1時(shí),則相反.
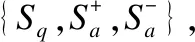
(17)
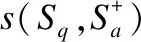
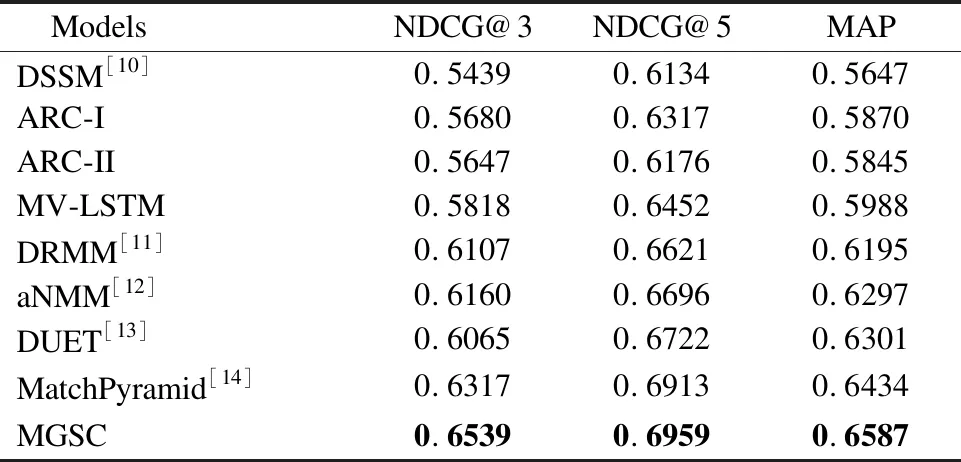
表2 WIKIQA數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果Table 2 Experimental results on the WIKIQA dataset
表2是各種模型在WIKIQA數(shù)據(jù)集上的表現(xiàn)結(jié)果.從實(shí)驗(yàn)結(jié)果可見(jiàn),MGSC模型與其它模型相比,具有較好的計(jì)算效果.在MAP、NDCG@3以及NDCG@5上,MGSC模型都顯示了最好的結(jié)果.不同于句子復(fù)述或者相似問(wèn)題去重的任務(wù),待匹配文本可能在用詞上就明顯存在相似性,而問(wèn)答的匹配,問(wèn)題和答案一般在用詞上的區(qū)別更大,甚至問(wèn)題和答案沒(méi)有出現(xiàn)一樣的詞語(yǔ).MGSC模型能夠在問(wèn)答數(shù)據(jù)上有優(yōu)異的表現(xiàn),體現(xiàn)出模型在語(yǔ)義上的匹配能力.
針對(duì)MGSC模型的四種變形,我們?cè)赪IKIQA數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn).這四種變形是通過(guò)在同等實(shí)驗(yàn)條件下,改變語(yǔ)義交叉特征圖的數(shù)量和種類而得到的.在圖4中,MGSC@1模型只用到兩個(gè)句子原語(yǔ)義的交叉,包括一張交叉特征圖;MGSC@3模型用到兩個(gè)句子的原語(yǔ)義與原語(yǔ)義、正語(yǔ)義和正語(yǔ)義、反語(yǔ)義和反語(yǔ)義交互形成的三張交叉特征圖;MGSC@4模型是兩個(gè)句子的原語(yǔ)義和正語(yǔ)義兩兩交互,形成四張語(yǔ)義交叉特征圖,不加入反語(yǔ)義;MGSC@9模型,即我們提出的MGSC模型,采用兩個(gè)句子的原語(yǔ)義、正語(yǔ)義、反語(yǔ)義之間兩兩交互形成的九張語(yǔ)義交叉特征圖.該圖表明,語(yǔ)義交叉是一種行之有效的語(yǔ)義匹配方法.比較MGSC@1模型和MGSC@4模型,可以看到模型中加入正向語(yǔ)義帶來(lái)明顯的效果提升;比較MGSC@1和MGSC@3兩個(gè)模型,同樣能說(shuō)明加入正向語(yǔ)義和反向語(yǔ)義的優(yōu)勢(shì);比較MGSC@1模型和MGSC@4、MGSC@9三個(gè)模型,實(shí)驗(yàn)結(jié)果表明,不同粒度的語(yǔ)義交叉能夠帶來(lái)效果的有效提升.

圖4 關(guān)于MGSC模型的幾種模式的比較Fig.4 Comparison of several variations of the MGSC model
4.3 實(shí)驗(yàn)2:?jiǎn)柧淙ブ?/h3>
在一些問(wèn)答平臺(tái)上,用戶往往會(huì)提出意圖相似的問(wèn)題,將這些意圖類似的問(wèn)題去重,能夠帶來(lái)更好地用戶體驗(yàn),是非常有意義的一件事,特別是像國(guó)內(nèi)知乎、國(guó)外Quora這樣大型的知識(shí)分享平臺(tái).比如Quora,每個(gè)月有超過(guò)一億的訪問(wèn)量,所以毫無(wú)疑問(wèn)的用戶會(huì)提出相似的問(wèn)題.許多問(wèn)題具有相同的意圖,用戶需要花許多時(shí)間在這些相似的問(wèn)題中尋找最想要的答案,回答問(wèn)題的用戶也不喜歡被同樣的問(wèn)題提問(wèn)多次.于是Quora在Kaggle發(fā)起了相似問(wèn)題去重的挑戰(zhàn).
Quora發(fā)布的訓(xùn)練數(shù)據(jù)集有404289個(gè)樣本,一共包含537933個(gè)問(wèn)題,每個(gè)樣本包括樣本編號(hào)、兩個(gè)問(wèn)題的編號(hào),兩個(gè)問(wèn)題的文本以及標(biāo)簽,標(biāo)簽為1表示兩個(gè)問(wèn)題表達(dá)同樣的意圖,標(biāo)簽為0則不同.
實(shí)驗(yàn)將404289個(gè)樣本隨機(jī)劃分為8:1:1的比例分別作為訓(xùn)練集、驗(yàn)證集和測(cè)試集.實(shí)驗(yàn)將該問(wèn)題定義為“意圖相同”和“意圖不同”的二分類問(wèn)題,以二分類交叉熵作為目標(biāo)函數(shù),計(jì)算公式定義為:
(18)
其中,θ表示模型中的參數(shù),m訓(xùn)練包括組已知樣本,(xi,yi)表示i第組數(shù)據(jù),xi及其對(duì)應(yīng)的類別標(biāo)記yi,yi取0或1,hθ(xi)表示模型的輸出.
實(shí)驗(yàn)從損失和正確率兩個(gè)指標(biāo)來(lái)評(píng)價(jià)測(cè)試模型,評(píng)測(cè)比較的模型包括本文提出的MGSC模型、ARC-I、MV-LSTM以及MatchPyramid[14]和MatchSRNN[15]模型.
如圖5、圖6所示,MGSC模型表現(xiàn)出色,相比其他模型,在損失Loss和正確率Accuracy兩個(gè)評(píng)價(jià)指標(biāo)上都取得了競(jìng)爭(zhēng)性的效果.在實(shí)驗(yàn)中發(fā)現(xiàn),對(duì)于短文本任務(wù),去除停用詞會(huì)嚴(yán)重破壞短文本的語(yǔ)義信息,對(duì)最后的評(píng)價(jià)指標(biāo)有大約2%~3%的影響.去除停用詞之后,MGSC模型的正確率大概有82%,MatchPyramid模型的大約有82.5%,而不去除停用詞,MGSC模型和MatchPyramid模型都差不多能達(dá)到85%左右的正確率.
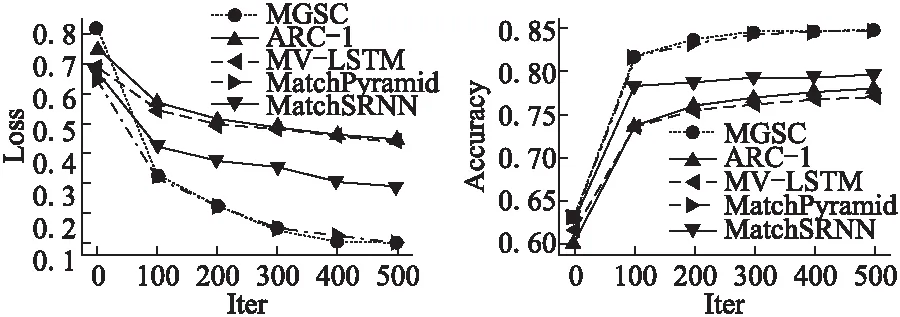

圖5 幾個(gè)模型在Quora數(shù)據(jù)集上的損失比較Fig.5 Compare the loss of several models on Quora dataset圖6 幾個(gè)模型在Quora數(shù)據(jù)集上的正確率比較Fig.6 Comparison of the accuracy of several models on Quora dataset
4.4 討論與分析
可解釋性一直是深度學(xué)習(xí)為人詬病的地方,許多深度神經(jīng)網(wǎng)絡(luò)模型雖然在各個(gè)方面取得了突破性的效果,但是并沒(méi)有給出嚴(yán)格的解釋.
已有的深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)模型,在應(yīng)用循環(huán)神經(jīng)網(wǎng)絡(luò)模型的時(shí)候,往往只提取循環(huán)神經(jīng)網(wǎng)絡(luò)的最后時(shí)刻的輸出.即使是使用了循環(huán)神經(jīng)網(wǎng)絡(luò)每一時(shí)刻的輸出,也是將生成的語(yǔ)義向量矩陣和詞嵌入矩陣做串聯(lián),形成新的向量矩陣表示(每個(gè)詞向量變長(zhǎng)),比如MV-LSTM模型.本文提出的多粒度語(yǔ)義交叉模型則拋棄以往的做法,將LSTM生成的語(yǔ)義向量矩陣和文本本身的詞嵌入矩陣分別利用,這樣可以最大程度地保留文本各個(gè)粒度的語(yǔ)義信息.
我們?cè)噲D這樣來(lái)解釋語(yǔ)義交叉.LSTM在時(shí)刻的輸出其實(shí)是包含了從零時(shí)刻到時(shí)刻的所有信息,以文本序列處理的狀況來(lái)說(shuō)就是包含了前個(gè)輸入的單詞的信息.所以簡(jiǎn)單地將LSTM在時(shí)刻的輸出和單詞原本的詞向量串聯(lián)后作為新的的做法顯然并不是很合理.本文將文本原語(yǔ)義、正語(yǔ)義和反語(yǔ)義獨(dú)立表示,作為文本不同粒度的語(yǔ)義表達(dá).再通過(guò)將兩個(gè)待匹配文本相同或不同粒度的語(yǔ)義進(jìn)行交互,獲取兩個(gè)文本的語(yǔ)義交叉特征圖.而不同語(yǔ)義之間的交互給出了兩個(gè)語(yǔ)句之間不同粒度的重點(diǎn)關(guān)注的交互信息.在特征圖中,對(duì)于比較重要的信息用較大的數(shù)值來(lái)表示,而對(duì)特征圖做卷積操作本質(zhì)上是為每張?zhí)卣鲌D分配權(quán)重的過(guò)程,以此來(lái)綜合考慮所有特征圖的匹配特征,從而判斷兩個(gè)文本是否匹配.
5 結(jié) 論
本文提出了多粒度語(yǔ)義交叉模型——MGSC模型,以此來(lái)解決類似文本復(fù)述、問(wèn)題去重、問(wèn)答匹配或者信息檢索排序的問(wèn)題.模型主要有兩個(gè)創(chuàng)新點(diǎn),一是對(duì)同一短文本采用不同粒度的語(yǔ)義表達(dá),二是通過(guò)兩個(gè)文本不同粒度的語(yǔ)義表示交互獲取兩個(gè)短文本的交互特征.通過(guò)分析驗(yàn)證,文本匹配模型引入多粒度的語(yǔ)義信息以及不同粒度的語(yǔ)義交叉信息能夠提高文本匹配任務(wù)的匹配準(zhǔn)確率.在Quora Duplicate Questions和WIKIQA兩個(gè)數(shù)據(jù)集上實(shí)驗(yàn)結(jié)果表明MGSC模型相比已有模型具有一定的優(yōu)勢(shì),且在語(yǔ)義匹配任務(wù)中具有一定的通用性.
猜你喜歡
開(kāi)放教育研究(2020年2期)2020-03-31 01:54:14
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
現(xiàn)代語(yǔ)文(2016年21期)2016-05-25 13:13:44
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
中外會(huì)展(2014年4期)2014-11-27 07:46:46
語(yǔ)文知識(shí)(2014年1期)2014-02-28 21:59:13
外語(yǔ)學(xué)刊(2011年1期)2011-01-22 03:38:33
