基于深度學習的粘蟲板儲糧害蟲圖像檢測算法的研究
2019-06-08 02:12:54苗海委周慧玲
中國糧油學報 2019年12期
苗海委 周慧玲
(北京郵電大學自動化學院,北京 100089)
蟲害是導致我國糧食產后儲藏損失的重要因素之一,不僅造成經濟損失,還容易導致食品安全問題。目前,采用不同形式捕獲器獲得糧倉內害蟲圖像信息的裝置已經逐漸開始在倉庫內應用,對儲糧害蟲圖像進行準確的數量檢測和正確的類別識別是做出正確保糧決策的重要依據。有研究表明,除少數害蟲分布在糧堆深層外,大部分害蟲最早是糧堆表層被發現的[1]。及早發現糧堆表層害蟲,做到早預警早防治,對于保障儲糧安全是十分必要的。
近年來數字成像技術的快速發展使得圖像識別檢測成為主要方法。關于儲糧害蟲圖像檢測方面,不少學者基于傳統機器學習和深度學習兩個方向做了很有意義的研究工作。傳統機器學習方法主要是通過提取顯式圖像特征然后將特征送入機器學習分類器進行分類或檢測。張洪濤等[2]和吳一全等[3]分別使用了面積、周長等形態特征和紋理特征送入支持向量機進行害蟲分類。Lu等[4]使用隱馬爾可夫模型在圖像像素數據和紋理特征上建模對害蟲圖像分類,其通過實驗驗證了不同姿態的害蟲圖像識別效果。因為傳統機器學習使用的特征大多是顯式的特征,特征提取過程煩瑣且表達圖像特征準確性不高,受背景雜質和光照影響較大[5]。Hu等[6]為了提高提取特征的有效性,將蟻群算法應用到儲糧害蟲特征提取中,該算法從17種儲糧害蟲特征集中選取7種特征子空間,其實驗證明了自動特征提取算法在儲糧害蟲特征提取任務上的有效性。近幾年,基于深度學習方法的抽象特征自動提取成為儲糧害蟲圖像識別特征提取的主流方法。程尚坤[7]和程曦等[8]分別基于深度學習技術進行了甲蟲類害蟲圖像和7種高清害蟲標本圖像的粗分類。Shen等[9]基于深度學習目標檢測框架Faster R-CNN對瓦楞紙板型誘捕器誘捕的害蟲圖像進行了種類識別,在實驗室模擬糧倉環境下平均識別率達到88%。
本研究基于單發多盒目標檢測器(Single Shot MultiBox Detector,SSD)[11],使用本實驗室基于粘蟲板誘捕器開發的儲糧害蟲在線圖像采集設備(Online Insect Trapping Device,OITD)[10]進行圖像采集,針對米象/玉米象、谷蠹、扁谷盜、鋸谷盜、擬谷盜和煙草甲六類儲糧害蟲設計了一套檢測算法。為了提高算法對粘蟲板圖像檢測的效果,在分析害蟲檢測與通用目標檢測異同點的基礎上,結合儲糧害蟲目標類間相似度較高、邊框比例與類別無關和圖像尺度相對固定的特點,通過改進SSD的目標框回歸策略、損失函數、特征提取網絡結構,設計適用于儲糧害蟲圖像定位和識別的算法,并對其有效性進行了評估測試。
1 圖像數據集建立及預處理策略
OITD是本實驗室開發的監控糧倉表面粘蟲板上害蟲的實時在線設備,可通過接入管理服務器實現粘蟲板圖像自動采集,其包括相機、支架和粘蟲板三部分,如圖1a所示。相機選用MindVsion-GE500C-T,具體參數如表1所示,可拍攝最大20cm×25cm的粘蟲板,拍攝的圖片如圖1b所示。數據集害蟲按六大種分類,粘蟲板圖像來源兩部分:實驗室拍攝的粘蟲板圖像和糧倉環境下拍攝的粘蟲板圖像。人工標記圖像中的所有害蟲目標邊界框(以下簡稱目標框),如圖1c所示。來自實驗室的粘蟲板害蟲圖像中的害蟲由國家糧食和物資儲備局科學研究院糧食儲藏研究室養殖,對每頭害蟲的種類鑒定是明確的,因此標注信息中包含類別信息和目標框信息。為了保證模型在實際糧倉中的檢測性能,本研究在訓練數據集和測試數據集中分別加入了1030張和100張來自實際糧倉的圖片,因為對這些圖片中的單頭害蟲進行類別鑒定難度較大,因此本研究只標注目標框。

圖1 OITD與拍攝圖片示例圖

表1 MindVsion-GE500C-T相機具體參數
OITD拍攝的圖像分辨率是1944×2592像素,由于高分辨率的圖像直接送入神經網絡會占用較高內存,增大訓練和推理所需的硬件配置要求。因此需要對大尺寸圖像進行處理,以獲小尺寸圖像,送入神經網絡。因為粘蟲板圖像中的單頭害蟲平均只有30×40像素,為保證單頭害蟲圖像信息盡量少的丟失,采用了劃窗采樣方式,將整張大圖劃分成若干小圖送入定位網絡。表2是來自實驗室的粘蟲板數據集中訓練集和測試集圖片的數量以及害蟲的頭數。表3是整體粘蟲板圖像數據集的統計,其中包含來自實驗室的粘蟲板圖像和來自實際糧倉粘蟲板圖像。
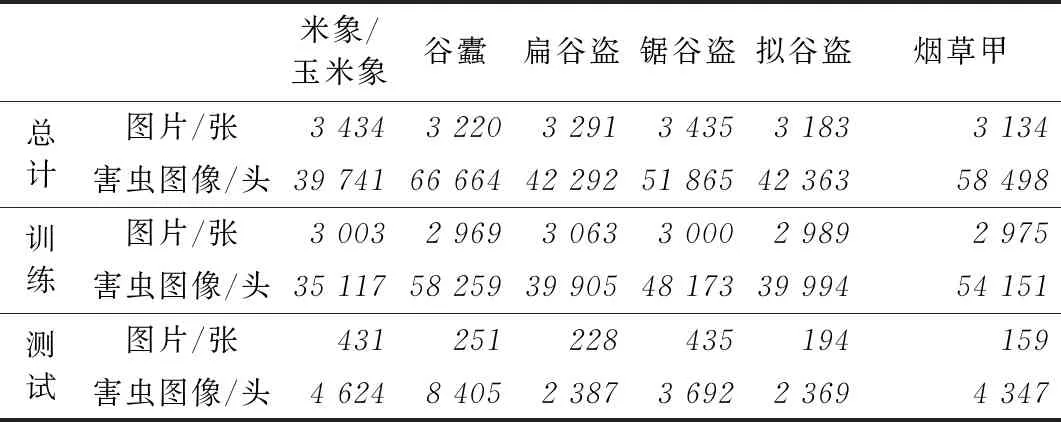
表2 來自實驗室的粘蟲板圖像數據集數量統計
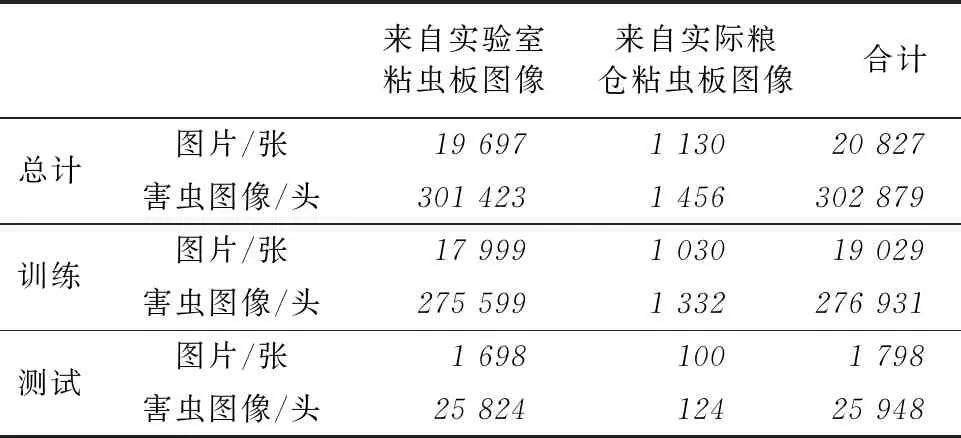
表3 粘蟲板圖像數據集數量統計
2 目標檢測算法
2.1 檢測過程的基本流程
粘蟲板圖像相比于其他的誘捕器圖像拍攝范圍較大,且害蟲較小,為了保留足夠多的圖像信息被送入神經網絡,需要先經過劃窗操作再送入網絡進行檢測,所以對檢測速度有要求。由于相機高度固定目標尺度變化小,因此對多尺度檢測需求較小,故本研究基于SSD進行算法改進。改進的SSD基本流程:1)通過劃窗采樣將分辨率為1944×2592像素的圖像切割成24張分辨率為512×512像素的圖像,采樣前的圖像如圖2a所示,采樣后單張圖像如圖2b所示;2)將切割后的圖像送入卷積神經網絡(Convolution Neural Network,CNN)進行特征提取,如圖2c所示;3)使用默認框生成器生成不同長寬比和不同尺寸的默認框,如圖2d所示;4)使用提取到的不同尺度的特征圖進行目標框與默認框偏移量的回歸和害蟲分類;5)使用默認框坐標和預測得到的偏移量可得到目標框的預測坐標和類別的預測數據,如圖2e所示;6)根據框的置信度和框的坐標應用非極大值抑制算法去除多余預測框得到最終框的坐標和類別如圖2f所示。
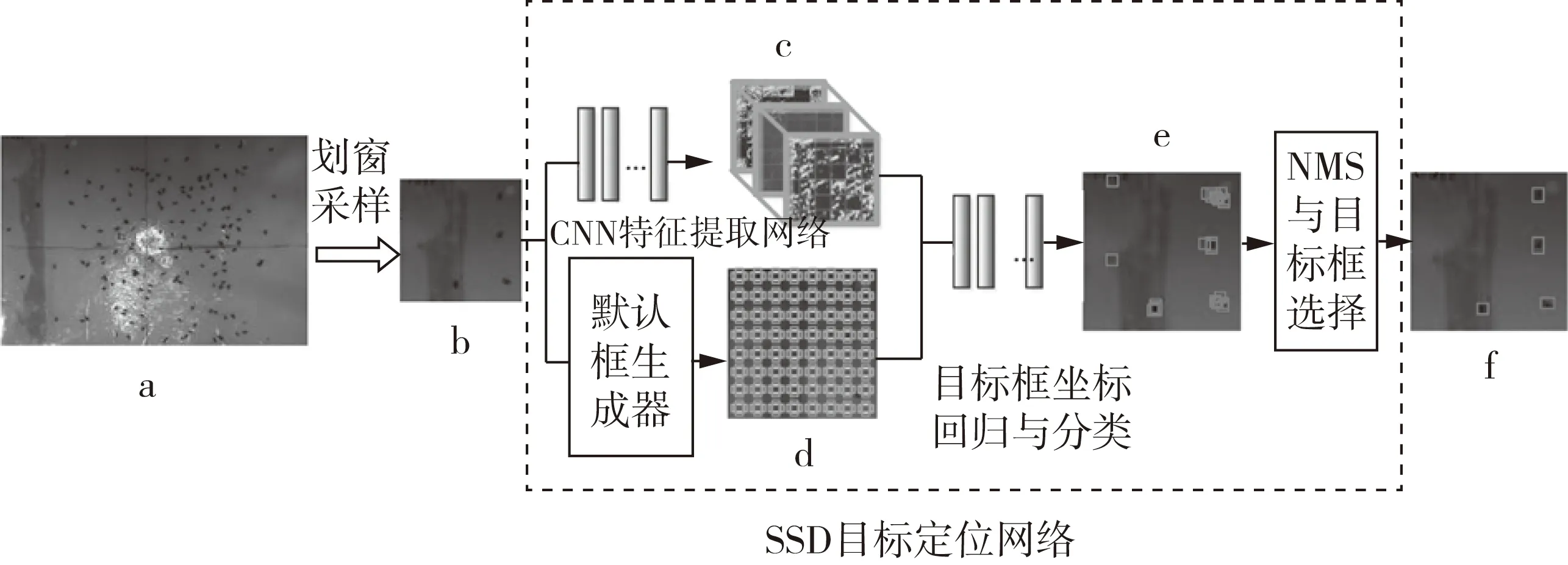
圖2 目標定位算法基本流程
2.2 默認框生成策略
為了提高對不同尺寸目標定位的效果,SSD 在不同尺度的特征圖上生成不同密度的默認框。由于淺層特征和深層特征分別對小目標和大目標有較好的檢測性能,所以在淺層特征進行回歸過程中使用生成較小的默認框,在深層特征進行回歸的過程中使用較大默認框,圖3a分別展現了不同大小的默認框。為了覆蓋所有不同長寬比的目標,同一層的特征圖中包含不同長寬比的默認框,可分別使用不同大小的默認框。通過將默認框與目標框坐標真值做交并比(Intersection over Union, IoU)判定每個默認框是正樣本還是負樣本,對于正樣本的默認框要標注其類別,對于負樣本默認框要標注為背景,如圖3b所示,有4組默認框與目標框匹配成為正樣本,如實線的橫框、正方形框、豎框代表不同的默認框,虛線框代表目標框。
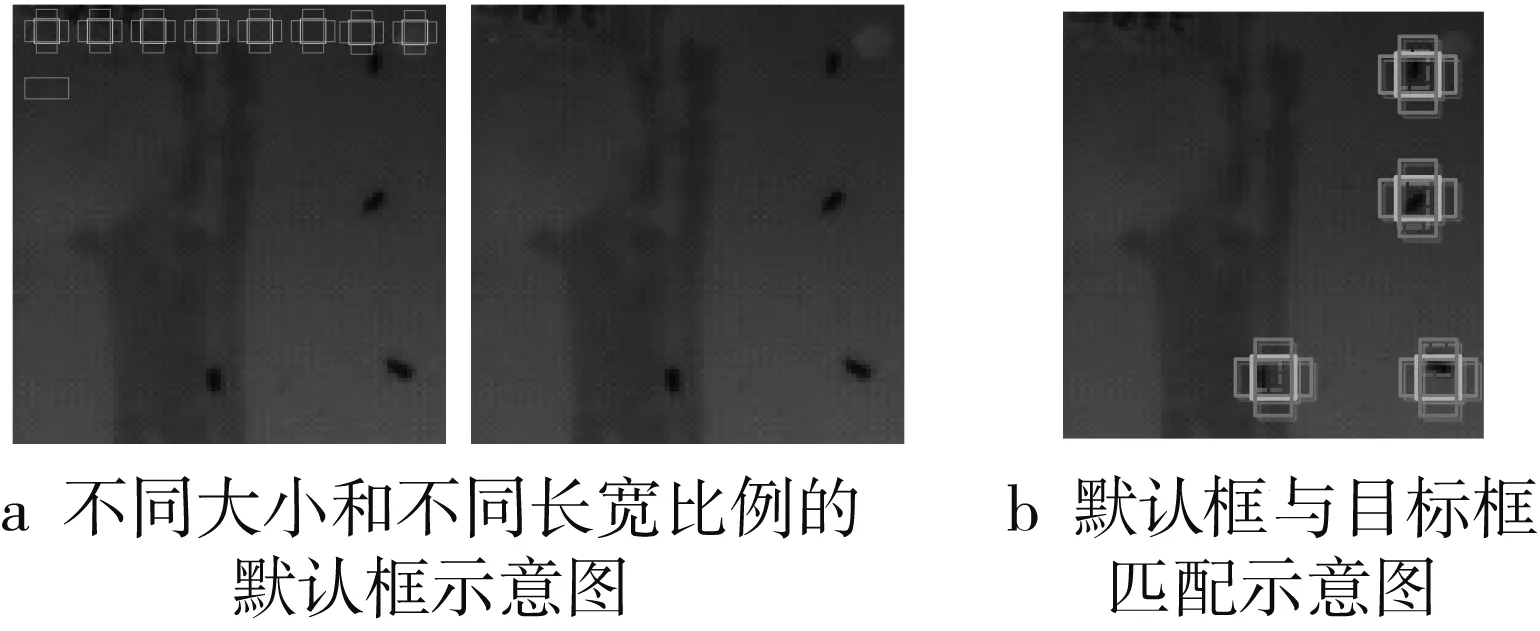
圖3 默認框生成示意圖
2.3 特征提取基礎網絡結構設計
本研究的特征提取網絡基于VGG16進行優化,通用SSD算法分別使用第4組卷積(conv.4)和第7組到第12組卷積(conv.7~ conv.12)共7組卷積后的特征進行目標框坐標的回歸和分類。特征的局部細節特征和全局語義特征對于定位任務來說同樣重要,使用單層特征分別進行回歸不能同時利用細節特征和全局語義特征,FPN[12]和FSSD[13]都是基于這個觀點進行改進的。由于害蟲目標較小,為了提高檢測算法對小目標定位和分類效果,將后3組的特征合并后分別加入到conv.4、conv.7和conv.8的3組特征中。為了增大后3組特征圖的分辨率以保證特征中含有足夠多的信息,在通用SSD基礎上,刪除了conv.9、conv.10和conv.113組中的池化層,全部網絡結構如圖4所示。
2.4 目標框回歸策略與損失函數設計
通用SSD算法沒有設置定位置信度,判別目標是否為害蟲、非極大值抑制等操作主要依賴類別標簽預測置信度,這是因為通用檢測任務有2個特點[14]:1)類與類之間差異性較大,類別標簽預測置信度與定位置信度有很大相關性;2)類別標簽預測與目標框坐標的回歸有一定相關性,如通用目標檢測任務中狗和人的目標框具有相對穩定的長寬比例。
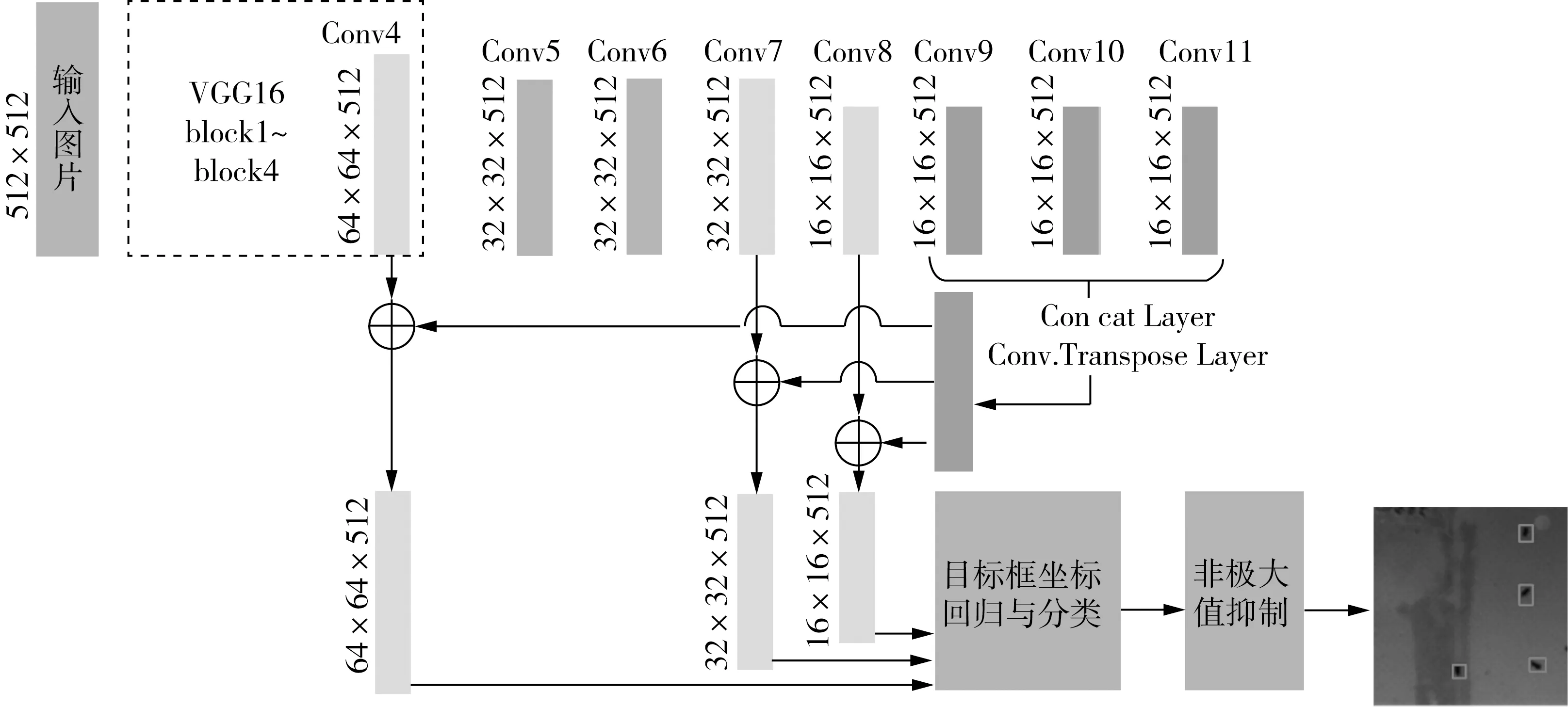
圖4 改進的SSD網絡結構
本研究的檢測任務不具上述通用檢測的2個特點,且類與類之間相似度較高,使用類別標簽預測置信度作為定位置信度會產生漏檢和誤檢。本研究做出改進:1)加入前景分類模塊,負責定位置信度的預測,且與負責類別標簽預測的類別分類模塊獨立;2)減小前景判別和坐標回歸的耦合性,在類別分類卷積模塊、坐標回歸卷積模塊和前景分類卷積模塊中分別加了一層非線性卷積層,卷積策略如圖5所示。
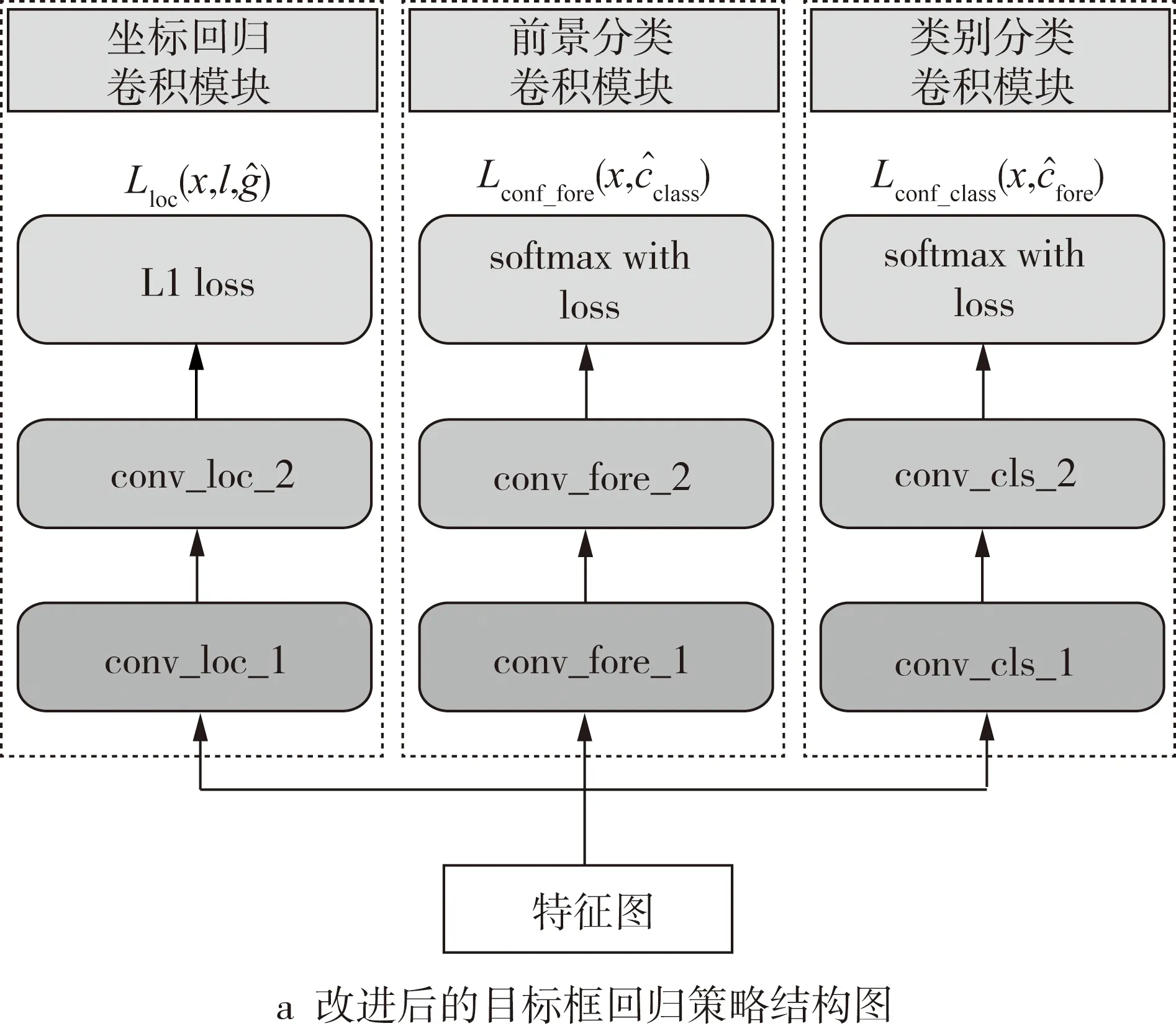
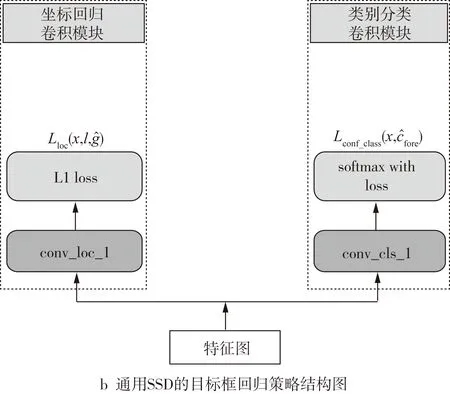
圖5 目標框回歸策略結構圖
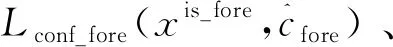
(1)
式中:x為標記當前位置默認框與目標框是否匹配的三維數據;xis_fore為前景指示數據;l為神經網絡對每個默認框與匹配目標框的偏移量的預測值,分為cx、cy、cw、ch四組,分別代表x坐標方向上的偏移值、y坐標方向上的偏移值、框的寬度偏移值、框的高度偏移值;α為控制目標框坐標回歸損失在總的損失函數中所占比重,設置為1;N為每個訓練批次的大小,選N=4。
(2)
式中:Pos、Neg分別為正樣本集合和負樣本集合;類別編號包括0~K,選K=6,0代表背景。
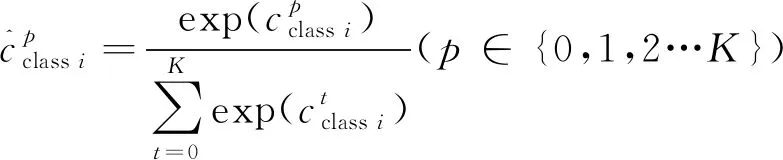
(3)
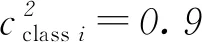
(4)
(5)
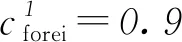
(6)
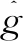
2.5 模型訓練與評估實驗
使用訓練數據集來訓練神經網絡,以4張圖片為一批送入神經網絡進行訓練。采用Adam算法[15]進行更新網絡權重,Adam優化算法結合了去除擺動方差和動量的思路,可以加快網絡訓練收斂,是目前最好的神經網絡優化算法之一。使用conv.4、conv.7、conv.8的特征與conv.9、conv.10和conv.11合并的特征進行回歸,3層特征的默認框大小分別設置為20、50、133,默認框長寬比使用3種比例:1∶2、1∶1和2∶1。訓練時統計3個損失值,分別為前景分類器損失、類別分類損失和目標框坐標回歸損失,3個損失值之和如圖6所示。

圖6 迭代70萬次的損失函數下降曲線
測試時,將前景置信度閾值設置為0.7,非極大抑制閾值設置0.45,使用各類的平均正確率(average precision,AP)作為驗證指標。平均精度(mAP)為各個類別的平均正確率的平均值,召回率(recall),準確率(precision)以及AP的計算公式為:

(7)

(8)
(9)
為了評估改進的SSD的方法對于儲糧害蟲的檢測能力,訓練通用SSD與本算法進行對比(見表4和表5)。圖7展現的是改進的SSD與通用SSD對粘蟲板圖像害蟲檢測效果對比,其中每個預測的目標框上分別標注預測的類別編號、前景置信度和類別置信度,類別編號范圍為1~6,分別代表玉米象、煙草甲、擬谷盜、谷蠹、鋸谷盜、扁谷盜,改進的模型可以有效改善漏檢和多檢的情況。為了測試模型在實際糧倉內的表現情況,對一些糧倉的圖片進行測試(見圖8),可以看到本研究提出的模型要比通用SSD模型對復雜背景抗干擾性更強,如圖8中第一列實際糧倉圖片中包含較多書虱、第二列和第四列的麥粒陰影等背景、第三列第五列中的圓圈背景,改進的模型可以有效避免誤檢和漏檢。相比瓦楞紙型誘捕器中害蟲的識別算法[9],本數據集中包含實際糧倉的測試數據,在實際糧倉應用時泛化性能更強,在采用相同相機設備的情況下,識別的誘捕面積更大,算法識別難度更高。

表4 通用SSD與改進的SSD在實驗室粘蟲板圖像測試集上的分類AP
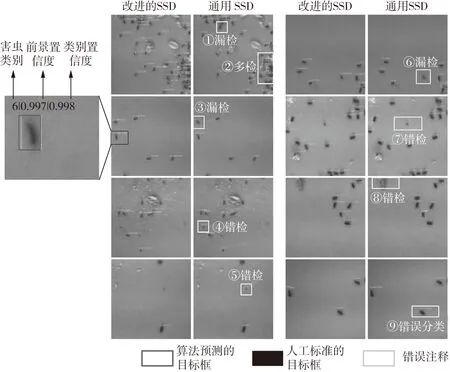
圖7 兩種定位模型在粘蟲板圖像上的表現

圖8 各定位模型在實際糧倉圖像上的表現

表5 通用SSD與改進后SSD在全部測試集上的定位AP、運行時間和模型大小
3 結論
本研究將SSD目標檢測算法應用于儲糧害蟲檢測領域,并且提出了改進的SSD模型,能夠有效檢測糧倉內放置的粘蟲板上的害蟲,并為小目標檢測、類別間相似度較大的檢測任務提供了思路。改進的SSD模型已應用在本實驗室設計開發的儲糧害蟲檢測系統中,該系統已成功部署在全國11個糧庫內運行使用,目前共收集共19000張圖片,其中包含9600張粘蟲板圖像,但系統對粘蟲板的拍攝環境有一定要求,后續研究中將不斷增加糧倉的典型負樣本數據,以提高模型在實際糧倉粘蟲板圖像上的泛化能力。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
