基于蟻群算法的智能測評系統開發
2019-06-11 09:54:06蘇楠
電子技術與軟件工程 2019年7期
關鍵詞:融合
文/蘇楠
1 國內外智能測評系統的研究分析
國外研究現狀:西方教育對考試環節十分重視,測評系統的開發起源于國外,在90年代初,就制定了相關的測評規則與辦法,在測評系統開發領域中處于領先地位。在應用領域,國外的很多部門與機構都對測評系統給予關注,采用了在線測評的這種測試方式。被人們所熟知的有出國留學必須進行的語言水平測試(例如雅思)就是通過在線測試的方式進行的,計算機網絡技術架構師和思科認證也是通過設置相應考點,進行在線測評完成的。這些都對測評系統的發展起到了促進作用。在智能算法的測評系統開發過程中,國外也只經歷了不到二十年的發展時間,還存在著相應的發展空間。
國內發展現狀:國內的在線測評系統,主要應用于教育行業,尤其是在高等院校之中。高等院校受信息化技術影響,打造自身的網絡環境,并且實現了網絡平臺的教務工作管理和網絡平臺測試系統。高校每年都要進行多門課程的考核,在線測評系統能夠滿足大多數課程的考核需求,也能節約資源開銷。所以受到廣泛應用。但是在其它行業中,測評系統應用很少,在招聘中在素質選拔技能選拔中,通過測評系統來完成的,更是寥寥無幾。從應用領域來說有待加強。從實現水平來講,很多高校的測評系統只能滿足簡單的客觀化試題考試,沒有實現硬件擴展也很少使用算法來體現自動組卷的價值。
本文嘗試使用的蟻群算法和遺傳算法融合的方式,通過對試卷難度的控制,實現試卷的價值。同時利用建立區分度公式,來嘗試實現優秀以及中等和偏弱學生的學習情況區分。而兩種算法融合方法的目的,是利用兩種算法各自的優點,提升組卷速度提升成功率。因為蟻群算法在初期的路徑選擇中,缺乏有效的選擇方式,選擇速度慢,(后文詳細介紹)而利用遺傳算法可以提升路徑選擇速度。通過兩種算法的融合,提升組卷質量,實現組卷目標。
2 蟻群算法與遺傳算法融合思想闡述
2.1 算法在智能測評系統中的作用
本文算法在智能測評系統中主要針對試卷的自動生成產生作用,從淺入深的作用依次為:第一點,滿足試卷的最基本約束條件,也就是符合針對試卷而設計的總分、試題類型、分數數值、試題數量等等,最基本的設置要求。第二點,保證試題的難度覆蓋區域,使得試題難度更加具有價值,避免過于簡單或者難度過大的題目集中的出現。第三點,增強試卷的區分度,在保證題目難度偏移不集中現象出現基礎上,體現試題的區分度,讓優秀、中等、較差的學生通過智能測試,找到差距,教師對學生的學習狀態能夠很好的區分。第四點,保證試卷生成的成功率。
2.2 蟻群算法簡介
2.2.1 蟻群算法基本思想
蟻群算法思想借鑒于生物學,人們發現螞蟻在尋覓食物并搬運的過程中,總能找到相應的優選路徑,并且很少出現搬運擁塞的現象。經過研究發現,這是螞蟻可以分泌一種信息熵的緣故,這種特定的信息熵,具有特殊的氣味能夠被螞蟻所識別,同時這種信息熵會伴隨時間進行揮發。
如圖1:起點為A,M,N代表不同選擇的路徑集合,即為選擇M處會經過的所有路徑和從N處會經過的所有路徑。設置時間t,則M處通過時間為t1,N處通過為t2,我們會發現t1,t2中較小者會逐漸被選中。初始狀態根據概率分析,假設兩邊路徑集合通過的數量相同,但經過足夠長時間單位tC后,時間短的路徑集合通過的螞蟻數量不斷增多。一方面時間短,說明路徑短,多次循環通過的數量會形成倍數量級。另一方面,通過的螞蟻數量多,信息熵分泌多,揮發時間短會造成濃度的提升,從而成為優選解。
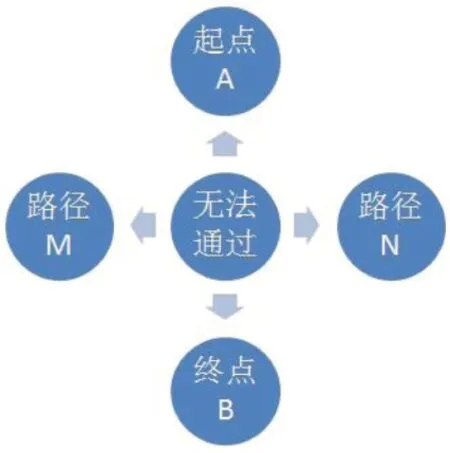
圖1
2.2.2 蟻群算法優缺點
從算法說明處可以分析出算法具有以下優點:第一點,從計算機算法實現角度來分析,蟻群算法優選解的計算是一種分布式算法,從前文圖例說明原理也可以看出。因此利于大規模運算的實現。第二點,收斂速度快,正反饋機制:蟻群算法從信息熵的濃度來進行辨別,濃度高,被選擇概率高,同時選擇概率高又不斷增強濃度,是一種正向的反饋機制。正反饋機制的特點就是收斂速度快。第三點,魯棒性能突出,這在蟻群算法在多個領域都得到應用就可以看出,模型適用性強,便于修改與應用。第四點,是以集合形式出現,利于求出優選集合,便于實現全局化算法。
缺點:從算法思想闡述我們也可以看出,算法要嘗試實現的話,在算法初期,信息熵濃度的積累需要較長時間,應用于算法中也就是初期的算法搜索時間長,算法時間復雜度高。同時也容易出現路徑選擇,問題優解針對個體難以區分,或者算法收斂過快,造成算法無法繼續。處于停止狀態。
從思想實例出發,說明可能存在的問題,假設圖1中對于路徑的選擇,信息熵選擇方法重要權值為X,新路徑啟發重要權值為Y。也就是說,當路徑選擇或者最優解中,X數值很高,則信息熵濃度為最重要。反之若Y數值高,則新路徑選擇優先。我們考慮臨界狀態。如果Y數值高而X數值是0,那么就代表無論信息熵濃度多高,某路徑經過多少螞蟻,這個解都會被放棄,而去尋求新路徑中,距離最近的解,這就等同于貪婪算法的實現。反之,如果X數值高,新路徑Y數值為0,那么就是一個完全的信息熵路徑選擇,高速的正反饋,極快的收斂,容易形成局部的錯解,不適用于全局優化的求解過程。
2.3 算法融合的分析
兩種算法進行融合的目的明顯,是兩用兩種算法各自的優點,實現降低試卷生成的時間復雜度,縮短試卷生成時間,并提升精度。蟻群算法的缺點是初期的信息熵的搜索時間長,而通過遺傳算法隨機性,縮短初期的積累時間,獲得一個相對的前期優解,再使用蟻群算法,發揮分布計算和正反饋機制的特點提升精度。
兩種算法都具有一定的融合性,那么融合位置的選擇較為重要,根據算法融合發揮的作用,可以用以下方法實現融合位置的計算。首先具體設置算法中的迭代次數臨界值(最大與最小),再進行子代群體的最小進化率的計算,并設置最小進化率。如果在算法應用過程中,發現實際進化率大于我們的最小進化率設置數值,則遺傳算法效率依然為較快,繼續進行迭代計算,如果出現多次的一直連續的小于設置值現象,則遺傳算法作用完成,切入蟻群算法,利用正反饋機制提升精度,進一步進行計算。
3 算法融合智能測評系統試卷指標
篇幅有限,這里進行重要試卷指標說明,并簡單介紹算法中的一些計算模型。
試卷難度指標:

從難度指標公式不難看出,這是每到試題的難度權值與分數的乘積,再除以分數和。其中,di為難度,si為分值,最終求得試卷的難度系數。
試卷區分度:試卷的區分度,體現試題的價值,通過學生對試卷的得分概率來體現,區分度用T代表:T=Hp-Lp,也就是高分成績獲得數量與低分成績獲得數量的得分率差值,一般情況下,區分度數值較大代表試卷區分度高,質量佳。
試卷信度:也就是通過算法生成的試卷的質量可信度,這是對算法生成的試卷能否穩定的組卷成功,試卷能夠滿足考試要求,試卷質量的一個總體評估指標:
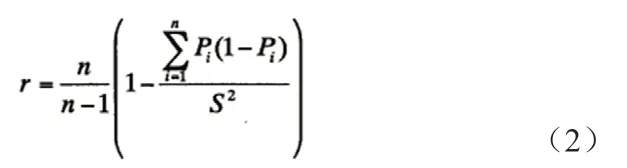
其中r為所求信度,n是具體的題目數量,P是該題得分率,s2為得分方差
4 算法融合組卷的算法模型與算法設計
4.1 蟻群算法數學模型

在蟻群算法模型中,P就是路徑選擇的相對概率,S就是引入的信息熵。從公式意義看出,S信息熵的數值決定了選擇新路徑的概率,也就是當數值大的時刻,那么下一個路徑被選擇的概率很大,反之,就很小。當螞蟻選擇的最優路徑趨向相同,同時信息熵達到一個很小的臨界數值的時候,也就說明了算法完成,解被求出。
4.2 遺傳算法與蟻群算法融合流程描述
初始化過程:確定試卷的基本約束條件以及簡單參數以及試題模型
采用遺傳算法對試題進行第一步優解,并不斷是否達到融合臨界點。(融合臨界點確定方法前文有明確介紹),當達到臨界點的時候,退出遺傳算法。
采用蟻群算法,并把遺傳算法的初步優解應用在初始信息分布中,解決初期信息熵搜素時間長的問題。
采用確定的蟻群算法模型,進行相應的數學運算
最終輸出:成功試卷。
4.3 算法設計過程
4.3.1 遺傳算法設計
編碼設計:采用二進制編碼模式,產生編碼矩陣,對染色體進行編碼0代表未曾選中,1代表選中
選擇算子、交叉算子與變異算子:可以說這三個算子的設計過程就是一個遺傳算法的簡單過程。選擇算子的含義就是對染色體進行挑選,選出適合算法的優秀個體。目前流行的算法毫無疑問是輪盤賭算法。這里不多做說明。交叉算子,通過染色體隨機交叉的方式,通過數學方法產生下一代的算子,也就是繁衍優秀下一代的方式。而算子交叉的方法很多,交叉算子的數值在0.5左右區間為適宜。變異算子,顧名思義,有遺傳就有變異,只有變異才可能發現更多的優秀下一代群體。那么針對二進制的染色體編碼方式,通過某些位置的邏輯反操作,可以實現變異。
參數考慮:也就是遺傳算法中各個參數的設置合理性。首先群體的數量,要根據題庫內試題數量而定。迭代次數要適中,過大會產生大量消耗,過小難以產生真正的初期優解。這里可以設置120次。同時設置交叉概率與變異概率。交叉概率建議為0.55。
4.3.2 蟻群算法設計
第一步,參數初始化。
第二步,將螞蟻分配到不同的路徑當中,產生列表。
第三步,進行螞蟻選擇下一路徑的概率計算,不同螞蟻對路徑的選擇不能重復。
第四步,群體走完路徑后,重新回到起點,通過蟻群算法數學模型進行信息熵公式計算。
第五步,再次進行第三步和第四步。
第六步,當符合信息熵條件終止條件后,獲得優解。
猜你喜歡
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
數學年刊A輯(中文版)(2022年4期)2022-02-16 08:17:34
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
無線電通信技術(2021年4期)2021-07-13 08:58:28
無線電通信技術(2021年3期)2021-06-08 03:33:48
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
無線電工程(2020年11期)2020-10-29 01:25:46
現代出版(2020年3期)2020-06-20 07:10:34
福利中國(2015年4期)2015-01-03 08:03:38
