基于混合架構的高校多源異構數據集成系統
2019-06-11 09:54:08趙佳釤李坤倫徐江李院春
電子技術與軟件工程 2019年7期
文/趙佳釤 李坤倫 徐江 李院春
1 引言
高校早期信息化的過程中長期存在“數據孤島”的現象,校屬各部門只針對自身的業務需求建設信息系統,缺乏統一的信息標準和規范,導致各業務系統之間數據標準不一致、產生和沉淀的大量數據難以共享。構建公共數據庫,被認為是當前解決“數據孤島”問題最為有效的方法。校園公共數據庫匯集了各個業務系統沉淀的有效數據,并向所需業務系統共享數據。然而,傳統公共數據庫的構建,只處理個人信息、成績信息、消費數據等結構化數據,對半結構化和非結構化數據無能為力。
為此,研究人員提出構建高校大數據平臺的概念,用以采集、清洗、存儲高校中的多源異構數據,并通過大數據分析方法,為高校的教學、科研、管理提供幫助。李蘭友等提出了一種基于ODI的數字校園數據集成模式,吳振濤等提出了一種在數字化校園中基于數據倉庫技術的數據集成應用。這兩種架構均是基于傳統的數據集成架構,在數據量較大時性能較差,更是難以應對日志、輿情等大規模的半結構化、非結構化數據的處理分析。鄧涵元等提出了一種基于MPP-Hadoop混合架構高校數據集成系統,解決處理大數據、擴展性及非結構化數據等方面的問題。然而,這種架構忽略了核心數據的管理和共享功能。高校大數據平臺最主要的功能應該是按需為其他業務系統共享核心數據。這些核心數據的數據量不大,但應該便于管理、追溯,同時對數據同步的實時性要求很高,尤其是涉及學籍、財務等方面的數據。
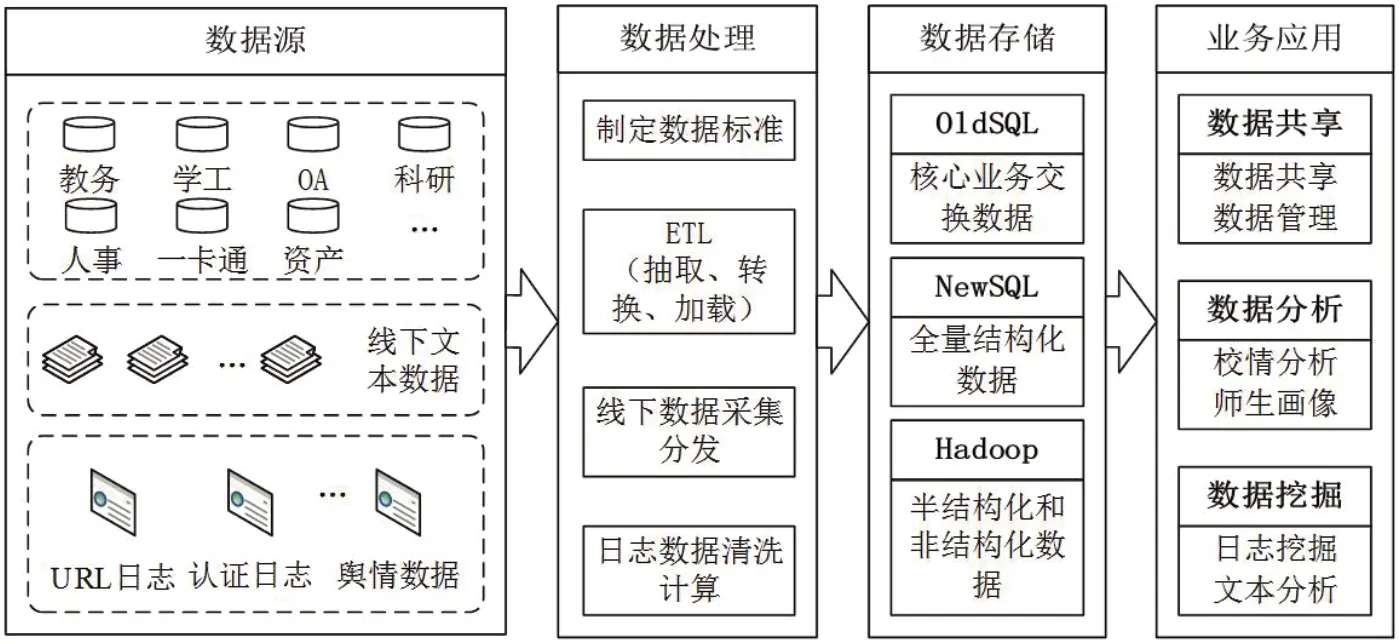
圖1:系統架構圖
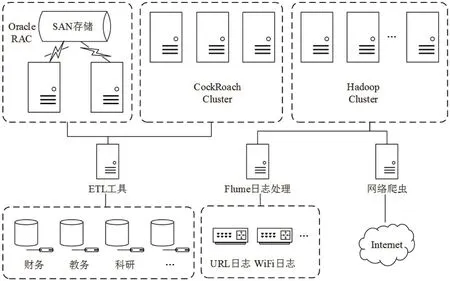
圖2:數據平臺的物理架構圖
本文提出了一種基于混合架構的多源異構數據集成平臺。平臺融合了OldSQL傳統關系型數據庫、NewSQL新型分布式數據庫和Hadoop開源生態系統,可適應多種業務場景模式。其中,OldSQL平臺用于存儲學校的核心業務數據,如教師數據、學生數據等,這部分數據的關聯關系復雜、對高并發、低延時的需求較高。NewSQL平臺作為數據倉庫匯總各業務系統的全量數據、過程數據、歷史歸檔數據等結構化數據,這部分數據主要作為校內的數據資產而存儲,并支撐平臺之上的數據關聯分析應用。Hadoop平臺用以提供批量數據計算,存儲半結構化和非結構化數據,如網絡日志數據、數據中心日志數據、學校輿情數據等。
2 平臺系統設計
教育行業信息化過程中產生積累的數據相對龐大復雜,即有人員、成績信息等結構化數據,也有日志、輿情數據等半結構化、非結構化數據。現有的高校大數據平臺并不能同時滿足海量異構數據的實時共享、處理、分析及存儲需求。
2.1 系統設計目標
為解決高校數據共享難、分析難、不完整的問題,本文從數據源出發,將高校數據資產分為三類。第一類是高校的核心業務數據,第二類是全量結構化數據,第三類是日志、輿情數據等半結構化、非結構化數據。各類數據的數據總量和特點不同,上層業務應用對不同種類數據的需求也不同。核心業務數據的數據量不大且相對穩定,但關聯關系復雜,對高并發、低時延的要求高,上游數據源數據做出更改時要求下游業務系統同步修改。全量結構化數據主要是作為全量數據資產而存儲,便于回溯數據、支撐上層數據分析類應用。這類數據的關聯關系復雜,數據量逐年增加,且增長較快,對數據的實時性有一定的要求。日志、輿情等半結構化和非結構化數據主要用以支撐上層的數據挖掘應用,相比于前兩類數據,這類數據的數據量龐大且增長快速。

表1:物理平臺的節點配置
2.2 系統總體架構
本文提出的基于OldSQL-NewSQLHadoop的大數據共享分析平臺,既能滿足當前業務的數據需求,又符合行業未來的數據發展規劃。其中,傳統關系型數據庫OldSQL存儲高校的核心業務數據,可消除長期信息化過程中的數據孤島現象,確保數據的權威性、有效性、實時性。NewSQL技術作為高校的數據倉庫存儲全量的結構化數據,如全量業務數據、過程數據等,確保數據的完整性。Hadoop平臺用以存儲和處理日志、輿情等半結構化和非結構化數據,為高校的數據挖掘、政策制定提供數據支撐。如圖1所示,根據數據來源及應用情況,大數據共享分析平臺的系統總體架構可分為四層,即數據源層、數據處理層、數據存儲層和業務應用層。
2.3 平臺業務流程
高校的信息化的程度相對完善,諸如教務系統,學工系統、OA系統、科研系統、人事系統等,每天都會積累大量的數據。同時,很多重要數據仍游離于信息系統之外,以文本的形式保存。這部分數據作為學校隱形的數據資產,其重要性不言而喻。除結構化數據之外,校內師生每天還會產生大量的半結構化和非結構化數據,如URL日志、認證日志以及校園輿情數據等。這些數據在研究學生日常行為和數據中心安全上有極大的價值。本文提出的數據集成系統中,數據源層包括高校的各個業務系統、線下文本數據、日志數據及輿情數據。
在獲取到數據源后,數據處理的第一步便是制定統一的數據標準,并梳理數據源、清洗數據源的數據質量。其中,ETL數據預處理完成數據的抽取、轉換、加載。數據抽取是針對不同業務系統數據進行全量或者增量的數據抽取。抽取完成后,需要對抽取的數據進行過濾清洗,并根據制定的數據標準轉換數據格式,生成新的數據,加載到目標數據庫。對于未采用信息化手段,以紙質形式或電子文檔存儲的數據,需要采用手工錄入或工具導入的方式清洗并加載到目標數據庫。在處理大量的日志和輿情數據時,預處理階段利用Hadoop平臺進行對數據進行簡單的清洗分類,將數據分析價值較高的數據留存在HDFS。
在數據存儲層,本文將高校的數據分成了三大類,即核心業務數據、全量結構化數據、半結構化和非結構化數據,并根據各類數據的特征和用途采用不同的數據存儲技術。數據在經過采集、預處理、分類存儲后,提供給上層業務應用展現才能發揮其最大價值。業務應用層可分為三類應用。第一類是數據共享類應用,主要負責數據的可視化管理和核心業務數據的共享。第二類是數據分析類應用,這類應用以三類數據為支撐,將校園大數據以不同維度的可視化方式展現出來。第三類是數據挖掘類應用,主要利用Hadoop平臺的大數據分析處理工具,挖掘半結構化和非結構化數據的潛在價值。
2.4 關鍵問題及解決思路
系統在建設過程中,面臨的主要的問題是數據標準的制定。高校的信息化起步早,校內各部門信息化的進程不同,這直接導致了各個系統之間的數據標準不統一,進而促使校內各系統直接的數據共享困難。因此,構建校內大數據平臺最重要的一環便是制定統一的校內數據標準,規范各類數據元素。數據標準的制定不僅要大而全,涵蓋學校當前的數據治理目標和對未來的數據規劃,而且要盡可能向國家標準和行業標準靠攏。于此同時,要從規章制度上規范各業務部門的數據格式,保障數據質量。
3 系統的部署與實現
3.1 平臺物理架構
核心業務數據的關聯關系復雜、對高并發、低延時的要求較高,因此本文選取穩定性、性能更優的Oracle數據庫來存儲。同時,采用Oracle RAC做雙機的負載均衡架構,避免單點故障。核心業務數據庫的后臺存儲采用全閃存集中式雙活存儲,以保障數據的高可用性。對于要求次之,數據量增長較快的NewSQL數據庫,本文采用開源的CockRoach數據庫,目前配置了3個節點的集群,每個節點服務器均配置2塊600GB的SAS硬盤,3塊240GB的SSD。Hadoop平臺采用6個節點規模的集群,每個節點服務器均配置2塊600GB的SAS硬盤和6塊6TB的SATA硬盤。平臺的物理架構如圖2所示。節點的具體配置如表1所示。
3.2 學生預警系統
業務應用以學生預警系統為例,學生預警本身包含兩方面,一方面是學業預警,另一方面是行為預警。涉及到的數據包括學生的成績信息、上課點名信息和學生上網日志,這三種數據分別存儲于核心業務數據平臺、全量結構化數據平臺和Hadoop平臺之上。其中,學生成績信息用于分析學生的學業完成情況。上課點名信息用于刻畫學生的課程出勤情況,對學生有一定的警示作用。通過對上網行為日志的挖掘,并綜合考慮目標網站的性質,可科學分析學生在思想、行為上是否異常,如是否牽涉校園貸等。學生預警系統面向的用戶主要分兩類,一類是學生,另一類是教學管理人員。對學業完成度較差或課堂出勤率較低學生,可利用短信、微信等信息接收終端向學生和輔導員自動推送警示信息。學生行為預警則主要面向教學管理群體,在保證學生基本隱私的前提下,向少數管理人員推送學生的網絡行為異常情況。
4 結束語
在構建校園大數據平臺的過程中,首先要根據不同業務和數據使用情況,劃分校內的數據資產。每種類型的數據特點各有不同,上層業務系統對各種類數據的需求也不同。因此需要根據每種類型數據的特點,采用不同的技術架構,對數據進行清洗存儲。本文結合OldSQL、NewSQL和Hadoop技術,采用一種基于混合架構的高校多源異構數據集成方案。從而消除了數據孤島,實現校內核心數據的實時共享,完善數據資產的整治,解決海量異構數據的分析難題。
猜你喜歡
作文大王·笑話大王(2021年4期)2021-04-26 19:00:35
電影(2018年9期)2018-11-14 06:57:21
作文世界(小學版)(2018年4期)2018-10-16 17:13:34
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
快樂作文·低年級(2016年12期)2017-01-03 20:52:44
快樂作文·低年級(2016年6期)2016-06-24 18:58:40
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
