一種基于迭代的關系模型到本體模型的模式匹配方法?
2019-06-11 07:40:10王亞沙趙俊峰
軟件學報 2019年5期
關鍵詞:特征
王 豐,王亞沙,趙俊峰,4,崔 達
1(高可信軟件技術教育部重點實驗室(北京大學),北京 100871)
2(北京大學 信息科學技術學院,北京 100871)
3(軟件工程國家工程中心(北京大學),北京 100871)
4(北京大學(天津濱海)新一代信息技術研究院,天津 300450)
語義網(semantic Web)作為下一代互聯網規范,在促進數據交互和知識共享等方面具有重大意義.本體是語義網的核心,是特定領域共享概念模型的形式化規范說明,被廣泛地用于刻畫特定領域的知識模型[1,2].但是在實際的語義網應用中,常常面臨本體實例匱乏的問題,考慮到現有的城市系統中,大量的實例數據的主流存儲方式仍然是關系型數據庫[3],將關系數據庫中結構化數據轉化為本體實例能夠有效地對領域本體實例進行擴充.為了實現這種轉化,首要任務是建立關系數據源中的模式到本體中概念的映射關系;此外,建立這種映射關系的需求,還廣泛存在于數據集成、數據語義標注、基于本體的數據訪問等多個與本體密切相關的領域.
關系數據模式到本體映射關系的建立,是一類典型的模式匹配問題[4-6].所謂模式匹配問題,指的是在不同的數據模式中找出語義相同或相似的元素對,并構造映射關系的一類問題[7,8],即建立數據庫表到本體中類的映射以及數據庫表中字段到本體類的屬性的映射.圖1所示是一個關系數據庫模式到本體的模式匹配示例.

Fig.1 Example of schema matching圖1 模式匹配示例
人工地進行模式匹配工作過于費時費力,且容易出現誤差.為了降低人力成本,提高模式匹配的準確率,研究者們提出了許多自動化方法和框架,通過利用模式本身的元信息或者元素所含實例特征等信息,計算得到不同模式之間元素對的相似度,來輔助人工來進行模式匹配.根據所利用的信息的不同,可以劃分為若干種基本模式匹配算法,例如使用元素標簽信息的基于字符串的匹配算法、使用實例統計特征的基于統計的匹配算法等.單一的模式匹配算法只考慮元素在某個特征上的相似度,在應用時可能會出現匹配不準確的情況,所以現有的模式匹配框架往往會使用多種模式匹配算法,綜合考慮元素對在多個特征上的相似性,來獲得更為全面準確的結果,然而,這種做法并未從本質上分析導致匹配準確率不高的原因,當多種模式匹配算法均存在較大偏差時,仍然無法得到準確的綜合結果.
針對以上問題,本文從數據源本地化特征的角度分析了單一模式匹配算法匹配不準的原因.數據源的本地化特征,主要體現在兩個方面.
· 一方面是由各數據源模式獨立、自主設計而導致的模式結構的本地化.
例如在關系數據庫模式設計時,設計者一般不會參照同領域中其他數據源的模式,也不會刻意使用領域中標準化的專業術語來建立數據字典,而是根據其對業務的理解獨立完成數據庫模式設計.而本體與某個特定的數據庫模式不同,是表達了領域共性知識的規范化說明.數據庫模式與本體這一本質區別,必然導致了本體和實際的關系數據模式存在差別,而在術語的使用上體現得尤為明顯.為了解決術語使用的差異化問題,現有的基于字符串的模式匹配算法常常需要同義詞詞典來解決這個問題.而特定業務領域的術語和同義詞,并不一定包含在已有的通用的同義詞詞典中,故而匹配準確率低.
· 本地化特征的另一方面是由于業務特征差異導致的數據實體統計特征的本地化.
真實數據源中,其實例的統計特征往往與其服務的業務相關.以餐飲領域的收銀管理相關數據為例,主營商務宴會的餐飲品牌,其每單金額的均值和方差都遠遠高于主營地方小吃的餐飲品牌.本體模型中包含的實例,往往是由多個數據源中的數據轉化而來,其實例數據的統計特征反應了不同餐飲品牌的綜合平均值,與主營商務宴會或地方小吃的餐飲品牌的實際數據,其實例統計特征都存在存在較大差異,從而導致基于數據實例統計特征的匹配算法失效.
綜上所述,數據源的本地化特征是導致數據源在模式和實例上與本體存在較大差異的重要原因,而由于在進行模式匹配前無法預先確悉數據源的本地化特征,直接應用模式匹配算法時則必然導致匹配不準確的情況.
針對數據源存在的本地化特征的客觀情況,本文提出一種迭代優化的模式匹配方案,其基本思想是:利用在模式匹配過程中得到的一部分匹配的元素對來對各單一模式匹配算法進行優化,從而提高單一算法的準確性,最終提高整個模式匹配過程的準確率.具體地,本文對兩種典型的模式匹配算法——基于字符串的模式匹配算法以及基于實例的模式匹配算法進行優化.對于已經得到匹配的元素對,其標簽可以看作是一對同義詞,自動加入到同義詞詞典中,基于字符串的模式匹配算法利用該自動生成的同義詞詞典,就能夠兼容數據源在術語使用上的本地化;已經得到匹配的元素對,其實例統計特征可以作為一種匹配知識,作為訓練集進行訓練,得到一個分類模型,該分類模型由于吸納了先前匹配的經驗,故而可以很好地兼容數據源在實例上的本地化特征.
本文以餐飲信息管理領域的一個實際案例開展模式匹配實驗,并與現有的相關工作進行對比,證明了本文模式匹配算法的有效性和準確性.本文的主要貢獻如下.
(1) 以餐飲系統為例對數據源的本地化特征進行了分析,分析了本地化特征的種類與其產生的原因.
(2) 提出一種迭代優化的模式匹配方法IOSMA(iterative optimization schema matching algorithm),算法在迭代過程中,利用已經匹配成功的元素對優化模式匹配算法,使模式匹配算法隨著迭代可以逐漸取得更好的匹配效果.
(3) 在餐飲數據集上進行了測試,結果顯示,本文提出的迭代優化的模式匹配算法效果優于基線算法.
本文第1節介紹現有的模式匹配算法與模式匹配框架.第2節詳細分析數據源本地化特征的原因和對模式匹配算法的影響.第 3節詳細介紹本文的模式匹配方案.第 4節介紹實驗設計和實驗結果.第 5節對本文進行總結.
1 相關工作
1.1 模式匹配算法
模式匹配算法衡量不同數據模式的元素對在某種特征上的相似性,對輸入的兩個來自不同數據模式中的元素,輸出一個[0,1]區間上的實數值作為相似程度.經過調研,本文對基本的模式匹配算法的分類進行總結,如圖2所示.
模式匹配算法按照所利用的信息的不同,可以分為基于模式信息的模式匹配算法和基于實例的模式匹配算法兩個大類.
· 基于模式信息的模式匹配算法關注于數據模式的元信息,數據模式的元信息包括組成數據模式的基本元素以及這些基本元素之間的關系.基于元素的模式匹配算法利用元素本身的信息來判斷元素的相似性,例如通過字符串的編輯距離來計算元素標簽的相似性[9,10],通過數據類型的兼容性判斷元素對匹配的可能性.基于結構的模式匹配算法利用數據模式中元素之間的關系來判斷元素的相似性,例如通過子節點相似度計算父節點相似度的子節點匹配算法[9,10],或者將輸入的源模式轉換為有向圖或者樹的形式,然后利用路徑匹配[11]、圖匹配[12-14]等已經成熟的圖算法計算元素對的相似度.
· 基于實例的模式匹配算法關注元素所含實例的特征,分為基于語言學的實例匹配算法和基于統計的實例匹配算法.
? 基于語言學的實例匹配算法主要面向數據類型為字符串的元素,通過抽取實例文本的關鍵詞[9,10,15],然后比較關鍵詞的相似性;或者以一個現有的知識庫為基礎,在其中尋找與該元素最符合的概念作為映射[15],然后比較元素對所映射概念之間的相似性.
? 基于統計的實例匹配算法主要有兩種:一種利用兩個元素實例上的重合度作為相似度,極易造成漏判;另一種更為主流,主要通過實例的各種統計量上的相似度,例如平均值、最大值、最小值、方差等,來計算元素對的相似度[16,17].
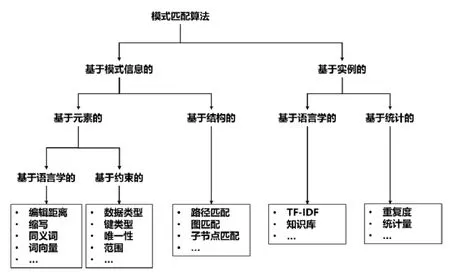
Fig.2 Classification of schema matching algorithm圖2 模式匹配算法分類
由于用于匹配的數據源在模式信息和實例上存在一定程度的本地化特征,單一地利用模式信息或者實例來進行相似度的計算必然會出現匹配不準確的情況.此外,這些模式匹配算法雖然具有一定程度上的通用性,但是不具備自學習能力,且難以兼容數據源的本地化特征.本文借鑒了傳統的模式匹配算法,綜合并優化了多種已有的模式匹配算法,在迭代的過程中,利用已匹配的信息來優化傳統的模式匹配算法,在不斷的迭代中,提高傳統匹配算法在具有本地化特征的數據上的正確率.
1.2 模式匹配框架
上一節討論了多種利用單一特征的模式匹配算法,這些模式匹配算法單獨使用極易引起誤差,因而現有的模式匹配框架往往采用多種模式匹配算法相結合的方式,例如 SEMINT[17]、COMA++[9]、RONTO[3]等,其中,COMA++、RONTO支持關系模型到本體模型的匹配.本文對一般的關系模型到本體模型的模式匹配框架進行總結,其一般流程如圖3所示.該流程對于輸入的兩個異構數據模式中的元素對的處理,主要包含3個階段.
(1) 相似度計算階段:在這一階段,調用多種模式匹配算法,對輸入的來自于兩個不同數據模式的元素對,計算其在多個特征維度上的相似度.所選的模式匹配算法和執行的先后順序可以由人工來進行配置.
(2) 相似度綜合階段:上一階段得到了一個元素對的多種相似度,分別來自于所使用的各個模式匹配算法,為了對元素對的匹配進行排序、判定、篩選,還需要對這些相似度進行綜合,具體的綜合方式可以是加權平均,也可以是人工定義的其他規則.
(3) 相似度判定階段:在這一階段,兩個異構模式中各個元素對的綜合相似度已然計算完畢,按照一定的規則對這些元素對進行是否匹配的事實判定,可以人工地按相似度大小排序后審閱并選擇,也可以根據人工設定的規則,例如閾值,來自動地加以判定.
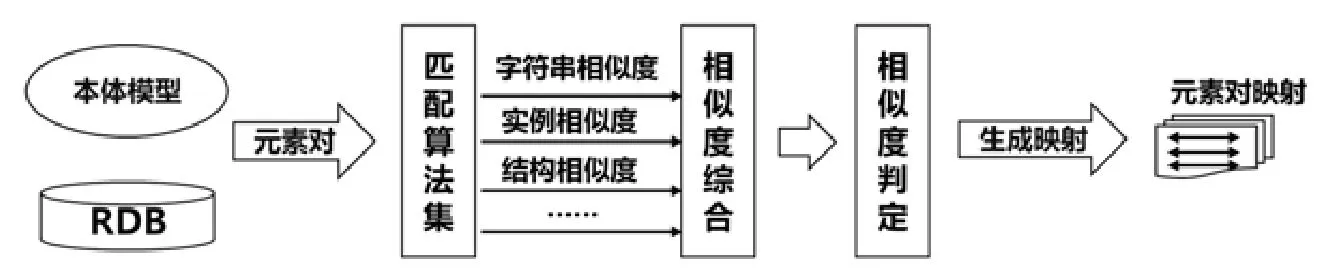
Fig.3 General process of schema matching framework圖3 模式匹配框架的一般流程
現有的模式匹配框架通過綜合利用多種模式匹配算法的結果來緩解單一模式匹配算法匹配不準確所產生的誤差,但它們沒有對單一模式匹配算法匹配不準確的問題進行分析與解決,因而仍然存在匹配準確率低下、需要較多人工參與等問題.本文算法利用迭代的方法對元素對進行匹配,每一輪匹配借鑒了現有的模式匹配框架的思路,在每一輪匹配完成后,部分元素得到匹配,利用已匹配的元素對可以優化模式匹配算法,通過迭代可以自動地使模式匹配框架適應具有本地化特征的數據,使一些難以匹配的元素對在迭代過程中得到匹配.
2 數據源本地化特征分析
本體被設計用于規范化地表達領域的知識模型,包含領域中概念以及概念之間的關系.由于語義網仍然處在發展階段,在很多領域中只有本體的定義而缺乏本體的實例.而真實存在的數據源往往用來為特定的應用提供數據,對于數據存取性能方面要求較高,大多采用關系數據模型作為存儲方式.
根據應用環境的不同,實際的數據源可以按照應用場景、應用系統這兩個維度進行劃分,見表1.
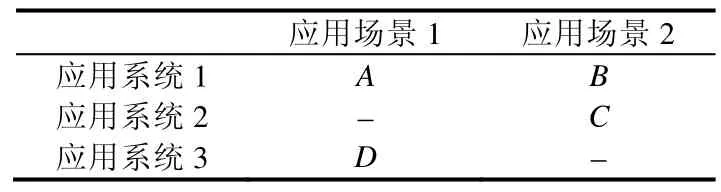
Table 1 Partition of data sources表1 數據源的劃分
如表1所示,A,B,C,D分別是4個數據源,它們均屬于某個特定的應用場景,例如在餐飲信息管理領域,應用場景可以是“宴會”“特色小吃”“自助”等,屬于同一個應用場景的這些數據源,表達相同概念的元素,其實例特征具有高度的相似性.而屬于不同應用場景的數據源,語義相同的元素,其實例特征可能差別很大,如圖4所示,左側是主營宴會餐飲的北京宴品牌,其某個門店數據源中訂單應收金額和訂單應收服務費的平均值(單位:元),右側是主營特色小吃的熱河食府品牌,其某個門店數據源中訂單應收金額和服務費的平均值(單位:元).通過比較我們發現:這兩個數據源中同為表示應收金額的數據元素,其平均值相差 10倍以上.這種不同應用場景下實例特征上的差異,本文稱之為實例的本地化特征.
同樣地,領域中存在多個不同的應用系統,例如在餐飲信息管理領域,有“餐行健”“品智”“軒亞”等多個餐飲信息管理系統,屬于同一應用系統的這些數據源,由于采用相同的數據定義,所以表達相同概念的元素,無論是元素的標簽還是元素的組成結構,都完全相同.而術語不同應用系統的數據源,其所使用的數據定義可能差別很大,如圖5所示,左側是餐行健餐飲信息管理系統,關于“用餐區域”這一概念,其使用“section(英文)/桌臺區(中文注釋)”這樣的術語;而右側的品智餐飲信息管理系統,同樣的概念,使用“business_loc(英文)/營業區(中文注釋)”這樣的術語.在預先不知道它們描述的均是“用餐區域”這一概念的條件下,機器甚至人都無法僅憑字符串判斷出“section”和“business_loc”“桌臺區”和“營業區”表達的含義相同這一結論.這種不同應用系統下使用術語上的差異,本文稱其為術語的本地化特征.

Fig.4 Instance feature under different application scenarios圖4 不同應用場景下的實例特征

Fig.5 Concept definition under different application systems圖5 不同應用系統下概念定義
實例和術語的本地化特征,其根源來自于不同數據源在應用場景和應用系統上的劃分不同,而這種本地化特征會導致通用的模式匹配算法——基于實例統計特征的模式匹配算法和基于字符串的模式匹配算法出現匹配不準的情況.如何在領域知識本體模型無法預先明晰這種本地化特征的情況下,兼容關系型數據源所存在的本地化特征,提高模式匹配的準確度,是本文所需要解決的主要問題.
3 迭代優化的模式匹配算法
3.1 方案概述
本文針對現有的關系模型到本體模型的模式匹配框架在處理數據源的本地化特征時存在的不足,提出了一種迭代優化的模式匹配方法IOSMA,如圖6所示.

Fig.6 Iterative optimization schema matching algorithm圖6 迭代優化的模式匹配算法
算法對于異構的元素對的基本匹配流程和現有的模式匹配框架相似,包含了相似度計算、相似度綜合和相似度判定這 3個階段:在相似度計算階段,本文采用了包含基于模式的相似度計算和基于實例的相似度計算,可以計算得到表與本體中類的相似度以及列與本體中的屬性的相似度;在相似度綜合階段,也分為表相似度綜合和列相似度綜合,即對前一步得到的多種相似度進行加權平均,可以得到每個元素對之間的綜合相似度;在相似度判定階段,對與一個待匹配的數據庫模式信息,會利用其和本體中所有待匹配的類或屬性之間的相似度計算信息熵,利用熵來衡量匹配的不確定性,這里,人工可以設置閾值,當不確定性小于閾值,即認為匹配成功,選擇相似度最高的一組匹配作為匹配結果.當一輪匹配結束后,算法會得到匹配的元素對和不匹配的元素對.
與現有模式匹配框架不同的是,本文在相似度判定環節后引入了算法優化,并將算法流程改為迭代式的.本文方案的主要思想是:利用模式匹配過程中已經判定匹配的元素對,對原有的模式匹配算法進行優化,從而達到提高單一模式匹配算法準確率,進而提升整體的匹配準確率.原有的低于相似度閾值而無法得到匹配的元素對,重新進入匹配流程.由于模式匹配算法的改進,可以正確地得到匹配,因而得到了更多的匹配元素對用于算法優化,形成一個良性循環.而已經判定匹配的元素對能夠對原有的模式匹配算法進行優化的原因在于:該元素對蘊含了本體概念和數據源元素的等價關系,數據源元素具有的本地化特征可以用本體進行標注與衡量,之后遇到具備相似本地化特征的元素時,能夠更好地加以判斷.
具體地,為了兼容數據源術語的本地化特征和在實例的本地化特征,本文利用已匹配的元素對,對基于字符串的模式匹配算法以及基于實例的模式匹配算法進行一定的優化.
3.2 優化:基于字符串的模式匹配算法
已經形成匹配的元素對,其語義是相同的,故而其元素標簽是同義的,而同一種應用系統中,為了避免混亂,對于同一個概念,往往傾向于使用相同的標簽進行表述.因而一旦能夠獲得一組同義詞,就意味著所有包含該同義詞所含字符串的元素對的相似度可以進一步優化.如圖5所示,關于用餐區域的表述,如果在綜合了多種模式匹配算法之后,能夠得出兩個系統中以section為標簽的節點和以bussiness_loc為標簽的節點表達相同含義的話,則可以將“section”和“bussiness_loc”作為一組同義詞,添加到同義詞詞典中.之后,在進行“section_id”和“bussiness_loc_id”的匹配時,基于字符串的模式匹配算法能夠給出更為準確的結果.
傳統的針對英文字符串的模式匹配算法有編輯距離法、詞向量距離法等方法.本文在傳統的編輯距離法上結合了同義詞詞典,首先利用詞典對字符串進行同義替換,然后消除標簽對的同義部分,最后計算剩余部分的編輯距離,得出字符串的相似度.
編輯距離指的是兩個字符串之間由一個轉成另一個所需的最少編輯次數,編輯操作包括增加、刪除、替換.與傳統的編輯距離計算不同的是,對于替換操作,除了原本的字符替代以外,本文系統還允許代價為0的同義詞替換.顯然,兩個字符串的編輯距離最大值即為二者長度的最大值.根據編輯距離,可以計算出兩個字符串的相似度.例如,對于字符串“bill_tabls”和“order_table_cnt”,已知 bill和 order是同義詞,將 bill替換為 order,并且添加4個字符_cnt,所以編輯距離為4,而最大編輯距離為較長字符串的長度,即 order_table_cnt的長度 15,那么字符串的相似度為1-5/15=0.66.
算法1.考慮同義詞的英文字符串匹配算法.

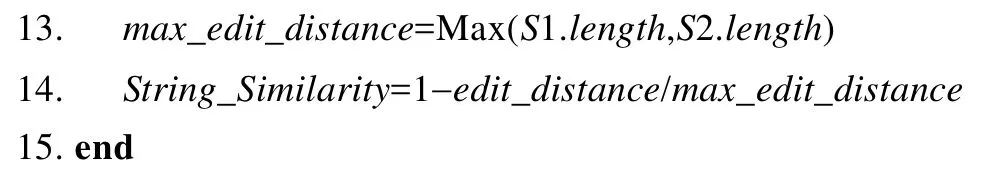
對于中文字符串的匹配,不能使用類似英文字符串中求編輯距離的辦法,因為表達同樣信息的中文字符串長度遠小于英文,稍有偏差就會差距很大.本文使用 Word2Vec訓練出領域相關的詞向量模型,詞向量的夾角即為兩個詞的相似度,夾角的大小通常使用余弦函數來衡量.
兩個單詞Wi和Wj,其對應的詞向量分別為Vi=〈vi1,vi2,…,vin〉和Vj=〈vj1,vj2,…,vjn〉,則單詞Wi和Wj的相似度為
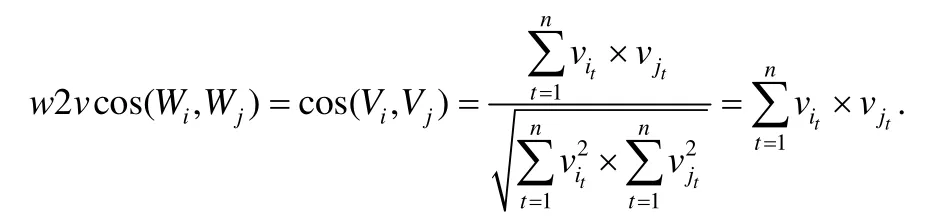
為了衡量任意兩個中文字符串的相似度,首先要將兩個字符串切分成一個個單詞,通過計算單詞間的相似度,得到整體字符串的相似度.分詞工具切分出的兩個單詞集合分別為TokenList1和TokenList2,對于TokenList1中的每個單詞,在TokenList2中找相似度最大的那個單詞,將該相似度進行累計,最終除以TokenList1集合的大小,即得到字符串相似度大小.
算法2.考慮同義詞的中文字符串匹配算法.

3.3 優化:基于實例的模式匹配算法
傳統的基于實例的模式匹配算法常常假設兩個具有相同語義的元素,在實例的統計特征上具有較高的相似性,例如平均值、方差、中位數等數學統計量,對于兩個待匹配的元素,計算各個數學統計量的值,為每個元素生成統計特征向量,然后比較統計特征向量之間的距離,作為衡量相似度的標準.
本文主要關注了最大值、最小值、中位數、平均數、區間范圍、DC(distinct count:不同值數量)、變異系數、DC占比、非空值占比,這些信息可以作為區分不同列的統計特征.
以M種不同類型的統計量作為不同的特征維度,為數據庫中的每個表列,生成M維的向量,記為實例統計向量,由于本體中的每一個屬性都會映射到至少 1個數據庫中的表列,因此其實例統計向量的計算方法與數據庫表列相同.
在計算得到實例統計向量之后,一種直觀的相似度計算方法是使用向量間的歐氏距離衡量元素對實例層次上的相似度,對于兩個向量Vi=〈vi1,vi2,…,vin〉和Vj=〈vj1,vj2,…,vjn〉,歐氏距離為
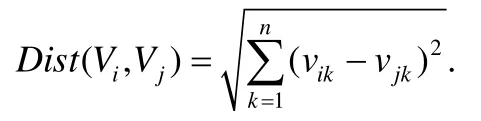
n維向量的歐氏距離最大值為,使用線性映射法將歐氏距離映射到[0,1]區間上作為相似度.因此對于兩個數據庫列Ai和Aj,其對應的向量分別為Vi和Vj,得到它們的相似度:
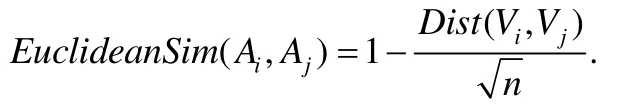
根據第 2節的分析,實際的數據源可能存在實例本地化特征,即其數學統計量可能明顯偏離于其他數據源或者本體實例相對應元素的統計量,這時,應用上述方法得到的相似度是不準確的.
本文利用已經形成匹配的元素對,加上由匹配排他性所推導出的不匹配元素對作為訓練數據,生成一個分類模型,分類模型的輸入是兩個元素的統計特征向量,輸出是這兩個元素是否形成匹配的概率.分類模型隨著已匹配元素的增多,訓練集也不斷增加,分類效果也不斷增強,對實例本地化特征的兼容性也越來越好,其基本思想如圖7所示.
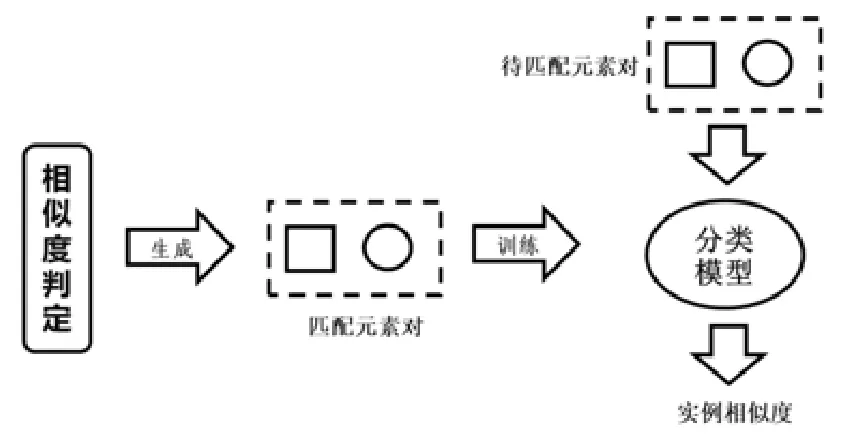
Fig.7 Classifier-based instance schema matching algorithm圖7 基于分類器的實例模式匹配算法
但模式匹配的前期沒有足夠的訓練集可用,因此前期主要依賴歐氏距離計算實例相似度,大致能夠區分不同列即可;在匹配的過程中,元素對不斷得到匹配,也給分類器提供了訓練數據.匹配的后期由于擁有大量的訓練數據,分類模型的準確度也得到了提升,因此得到的相似度也更為可信.因此,我們設置了參數δ來調整兩種算法得到的相似度的比例.假設當前有δ比例的列得到了匹配,EuclideanSim表示歐拉距離給出的相似度,MLSim表示分類器給出的相似度,則最終的實例相似度為
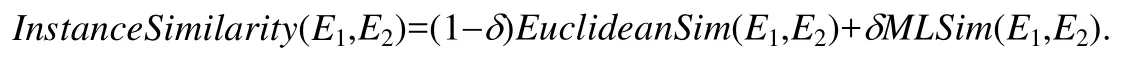
以餐飲信息管理為例,假設當前本體中的實例數據來自于某些特色小吃餐飲品牌,而待匹配數據源的數據來源于主營宴會的餐飲品牌,起初,基于實例的模式匹配算法并不能反映出這種差異,但隨著匹配元素對越來越多,分類模型獲取足夠多的訓練數據之后,就能夠對兩個數據模式之間存在的差異進行學習,之后,在利用實例統計特征進行相似度判定時,就會變得更加準確.
4 實驗驗證
4.1 實驗設定
本節對本文迭代優化的模式匹配算法進行實驗驗證,本體選用的是基于餐行健餐飲信息管理系統構造出的本體模型,待匹配數據源為品智餐飲信息管理系統,本體模型和關系模型中所含元素數量的統計見表2.
模式匹配的主要目標是尋找本體中的類和關系模式中表的映射關系、本體中的數據屬性和關系模式中列的映射關系.本文的評估標準采用精確率(precision)、召回率(recall)、F值(F-measure),其中,F值為精確率與召回率的調和平均值,統一度量精確率與召回率.記TP為判斷正確的匹配,FP為判斷錯誤的匹配,FN為沒有判斷出來的正確匹配.3個評估標準的計算方法如下:


Table 2 Statistics of schema elements表2 待匹配模式元素統計
實驗分為 3組:第 1組是現有的模式匹配框架 COMA++,第 2組是未進行迭代的本文算法 NSMA(noniterative schema matching algorithm),第3組是本文的迭代優化的模式匹配算法IOSMA.在模式匹配的過程中,完全依靠機器自動完成,無任何專家參與.
4.2 匹配結果
實驗結果如圖8所示.由于沒有利用已匹配元素對來對模式匹配算法進行優化,COMA++無法很好地兼容數據源的本地化特征.COMA++使用的不帶優化的字符串匹配算法,沒有根據已形成匹配的元素對對其自身進行改進,從而導致很多原本可以借助同義詞轉化提高相似度的元素對,達不到匹配閾值,從而得不到匹配.COMA++使用的基于實例的匹配算法單一地考慮統計量上的近似程度,而沒有利用已經匹配的元素對所提供的知識,訓練分類模型,無法很好地應對相同語義的元素對,其實例特征有較大差異的情況.相反地,IOSMA 較好地考慮了數據源的本地化特征,并對匹配算法進行迭代式的改進,ISOMA利用已匹配的元素對在迭代過程中可以不斷提高匹配效果,在實驗數據集上達到了 91%的精確率、83%的召回率和 87%的F值.相對于 COMA++,分別取得了 39.8%、59.6%、50.1%的提升;相對于非迭代版本的算法,分別取得了 24.7%、33.9%、29.9%的提升.
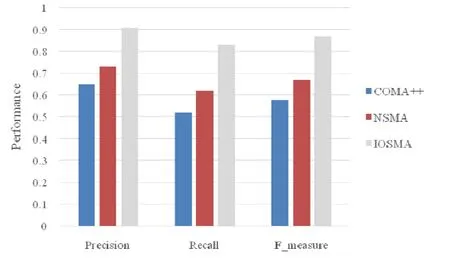
Fig.8 Result of schema matching experiments圖8 模式匹配實驗結果
4.3 案例分析
為了更好地展示本文的匹配效果,表3展示了利用ISOMA得到的已匹配的數據庫表名和本體類名.在這些已匹配的元素對中,某些字段具有顯著的本地化特征,在迭代過程中,這些元素對也得到了匹配.本節通過兩個方面分別舉例說明ISOMA在迭代過程中兼容數據源本地化特征的做法.
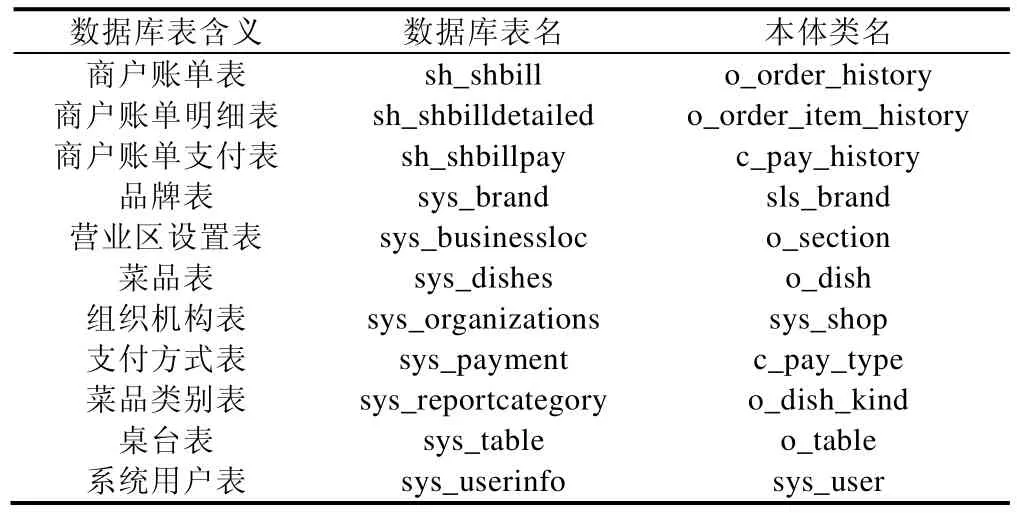
Table 3 Schema maching instance表3 模式匹配示例
4.3.1 處理模式結構的本地化特征
在第1輪匹配過程中,商戶賬單表得到匹配,算法可以提取出order和bill的同義詞關系,形成該數據源的同義詞典.同義詞典可以有效地改善基于字符串的模式匹配算.例如數據庫中的訂單金額的名稱是 bill_total,本體中的訂單金額為order_total_amount,在確定bill和order為同義詞后,訂單金額的相似度會得到明顯的提升.從而使訂單金額字段得到匹配.
4.3.2 處理實例信息的本地化特征
數據庫和本體中相同含義數據的統計特征也存在一定的差異,在實驗中,基于餐行健系統生成的本體模型中多為高端餐飲企業,而品智餐飲系統中則是中小餐館居多,因此兩個系統中表述相同含義的元素的統計特征(最大值、平均值、標準差等)存在較大差異(見表4).在匹配過程中,商戶賬單支付表在兩個系統中模式結構相似度較高,得到了匹配,利用這個信息可以得到很多匹配的元素對,利用已匹配的元素對的統計特征生成樣本并訓練分類器.隨著分類器的訓練樣本增加,分類器更容易識別出數據庫和本體中的統計特征差異,可以把具有類似差異的相同概念進行匹配.在本例中,商戶賬單明細表數據庫和本體的匹配通過這種方式得到了提升.也體現ISOMA基于迭代更好地兼容了數據源的本地化特征.
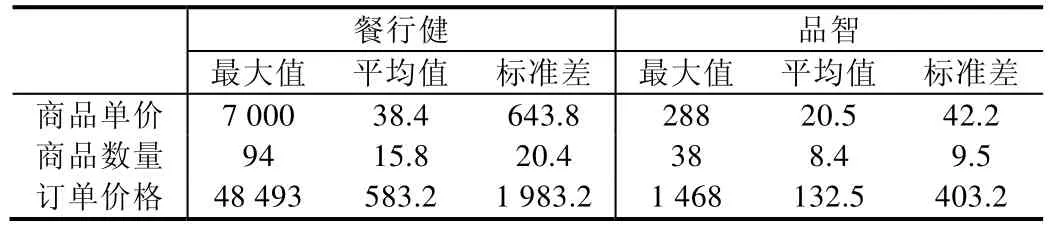
Table 4 Difference of statistical features表4 統計特征差異
5 結 論
本文研究一類關系模型到本體模型的模式匹配問題,在充分調研了現有模式匹配相關研究工作的前提下,對實際數據源具有的本地化特征進行了深入分析和論證,并指出本地化特征是導致現有模式匹配框架中單一模式匹配算法匹配失效的深層次原因;然后提出一種迭代優化的模式匹配算法,該算法利用已經得到匹配的元素對,對傳統的基于字符串的模式匹配算法和基于實例的模式匹配算法進行優化,使之更好地兼容數據源的本地化特征,從而提高了模式匹配的準確率;最后,以餐飲信息管理領域的一個實際案例開展相關實驗,證明本文算法的有效性和準確性.
本文未來有以下研究方向.首先,探究如何更加科學地綜合不同匹配算法的結果.目前主流的方式都是由用戶來制定相似度的綜合方式,然而在很多情況下,用戶也很難給出一個準確的綜合相似度計算公式.為此,需要分析不同模式匹配算法的特性,例如基于實例的模式匹配算法的可信度是否高于基于字符串的模式匹配算法的可信度,根據匹配算法的可信度為其賦予相應的權重是一種簡單的解決方法.而根據已經得到匹配的元素對來進行學習,利用表示學習的方式挖掘匹配元素對的深層次特征,可以得到更好的匹配結果.其次,對于匹配錯誤的元素對的糾錯機制也是一個值得探討的方向,首先需要進一步提高模型的準確率,其次可以加入群智,利用人機協作來對機器出現的錯誤進行糾正.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
