基于Ad-Sim算法的代碼克隆檢測方法
2019-06-11 08:18:50
浙江工業大學學報 2019年4期
關鍵詞:檢測
(浙江工業大學 計算機科學與技術學院, 浙江 杭州 310023)
隨著互聯網高速發展及軟件需求的不斷增加,代碼克隆和代碼復用頻繁地出現在軟件快速開發和重構過程中。研究數據表明:一般的軟件開發過程中包含5%~20%的重復代碼,在很多知名的軟件系統中也包含大量的代碼復用,如Linux核心代碼中就存在15%~25%的復用代碼,而在開源項目中更是有超過50%的代碼被復用[1]。隨著開源項目的不斷發展、代碼復用不斷擴大,代碼復用的廣泛程度可以作為代碼質量的評判標準和選擇所復用的代碼模塊的參考依據[2]。代碼復用也存在兩面性:一方面,重用高質量的代碼不僅可以提高開發效率,而且能規避編寫新代碼帶來的風險;另一方面,惡意或濫用低質量的代碼則會導致系統出現大量Bug、軟件運行效率低下以及影響系統安全[3]等問題,且克隆代碼給軟件維護帶來影響,當克隆代碼出現Bug時,其他相似代碼則存在相同Bug。通過代碼克隆檢測可以判斷應用系統中是否存在克隆代碼,若存在克隆代碼則對其進行重構,從而提高代碼質量。因此,對于軟件開發項目的代碼克隆檢測就顯得十分必要。代碼克隆檢測有很多不同種類的檢測技術及應用場景,主要分為5 類:基于Text(文本)方法[4]、基于Token(詞法)方法[5]、基于AST(抽象語法樹)方法[6]、基于PDG(程序依賴圖)方法[7]和基于Metrics(度量值)方法[8]。基于Text檢測方法通常是對源代碼之間的字符串進行比較,對代碼文本布局、注釋進行規范化處理外不進行其他形式轉換。基于Token方法首先使用詞法或語法分析工具把源代碼的每一行都轉換成token序列,并將所有序列連接成token串;接著掃描這個token串并找到相似的token子序列即為克隆代碼。基于AST方法使用語法分析器將檢測代碼轉化為抽象語法樹,再使用子樹匹配算法檢測。基于PDG方法是將檢測代碼轉換為程序依賴圖,再使用檢測子圖同構方法進行檢測。基于Metrics方法是通過提取檢測代碼的度量值間接對代碼中可能存在的類似代碼進行檢測[9]。
經過對以上克隆檢測方法的研究:一方面,基于AST,PDG等方法有較高的準確率及召回率,但算法復雜,實現較為困難,消耗過多的計算資源,并且可擴展性有限,不適用于大量代碼的克隆檢測;另一方面,基于Text,Token,Metrics等方法有較快的檢測速度,但檢測準確率和召回率較低。因此,提出了基于Simhash[10]算法的代碼克隆檢測方法,并在Simhash指紋簽名的計算過程中使用TF-IDF[11]及馬爾科夫模型優化關鍵詞權重分配,計算出L位二進制01串代碼指紋簽名。文檔相似度計算存在很多不同的方法和應用[12],筆者采用漢明距離[13]來計算待檢測代碼的相似度。
1 Simhash算法
Simhash算法由Google公司的Charikar等在2007年第一次提出,是一種降低維度的算法,其核心是將一篇文檔離散化轉換成高維的特征向量再映射成唯一的L位二進制指紋簽名,進而比較所產生的指紋簽名,得出各文檔之間的相似度。指紋越接近,則表明文檔越相似。Simhash算法計算步驟描述如下:
步驟1初始化:待檢測代碼作為輸入,輸出為L位的二進制指紋簽名S,初始化為0;定義L維向量V,初始化為0。
步驟2預處理:對代碼文件進行分詞處理,將文檔轉化為一組特征。
步驟3指紋計算:對于每一項特征,使用Hash算法得出L位的簽名b,在Hash值得基礎上,給所有特征向量進行加權,即w=Hash×Weight,如果b的第i(1≤i≤f)位為1,則向量V的第i個元素加上該特征的權重;否則V的第i個元素減去該特征的權重。
步驟4輸出簽名:如果向量V的第i個元素大于0,則簽名S的第i位為1,否則為0,輸出指紋簽名S。
具體計算步驟如圖1所示。
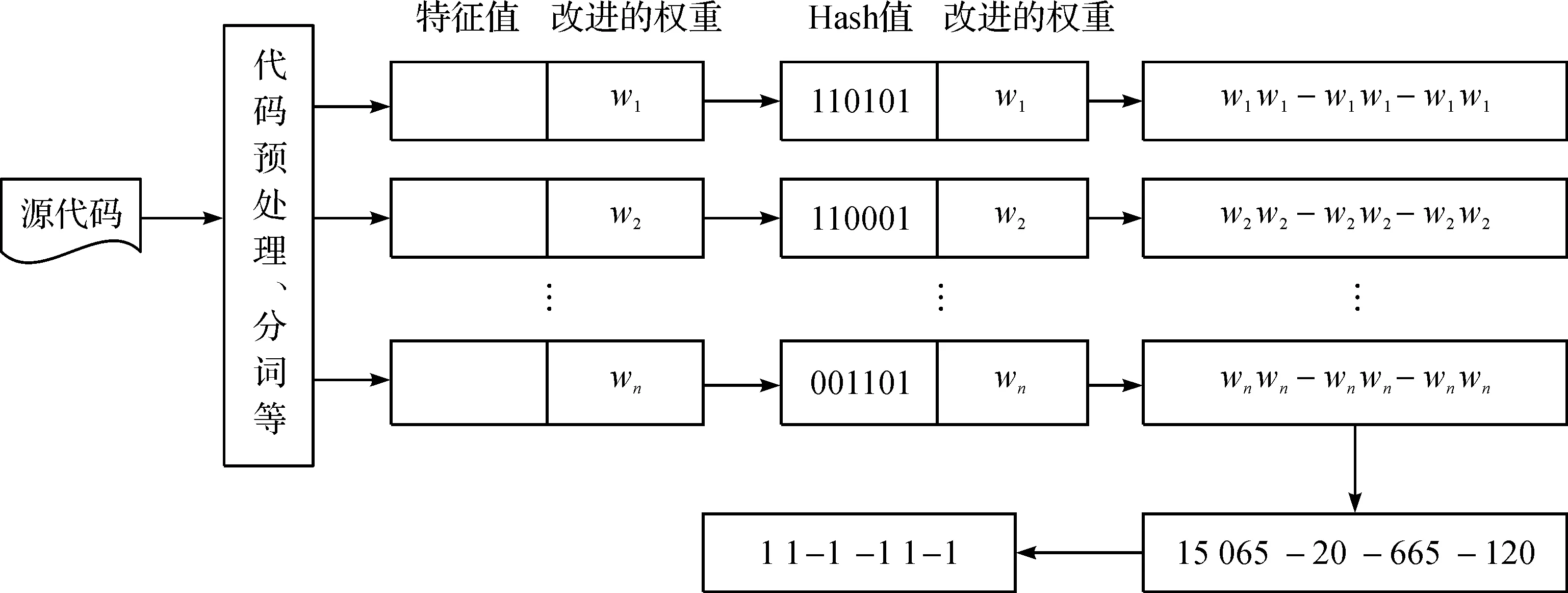
圖1 Simhash算法流程圖Fig.1 The flow chart of Simhash algorithm
Simhash算法的核心優勢在于可以將一篇高維特征的文檔轉換為二進制指紋簽名,提高相似度檢測速度,但該算法是將代碼中的所有單詞作為關鍵詞,代碼中單詞出現的次數作為關鍵詞的權重,以此作為衡量標準計算得到的權重準確度不高,計算得到的指紋簽名準確度也會降低。此外,Simhash算法是基于大量網頁文檔的查重技術,在少量文檔的情況下,檢測準確率較低。結合Simhash算法的優缺點,并針對Simhash算法中權重計算準確度等問題,提出了一種結合TF-IDF及馬爾科夫模型的Simhash優化算法Ad-Sim。
2 Simhash算法研究與改進
2.1 代碼預處理
為了提高代碼檢測的準確率,剔除代碼中一些無關特征或者毫無意義特征對代碼的影響,需要在指紋計算前進行代碼歸一化預處理。Ad-Sim算法中歸一化處理過程主要包括:去除引用代碼、詞法分析和轉換。
實驗中代碼克隆檢測的測試用例代碼使用的語言為Java,首先去除項目代碼中參考引入或開源項目的部分代碼;其次利用Java本身的詞法規則對待檢測代碼進行詞法分析,將每行代碼解析成關鍵詞序列。在經過詞法分析后得到的關鍵詞序列,為了提高檢測準確率,還需要對關鍵詞序列進行必要的添加、刪除或修改,具體規則如下:
1) 刪除單行注釋、塊注釋以及文檔注釋等無關內容。
2) 刪除package包名與類導入語句、數字和字符串等常量的無關代碼。
3) 替換變量名、方法名和類名關鍵詞為VARIABLE。
4) 替換各符號關鍵詞為SYMBOL。
2.2 基于TF-IDF的關鍵詞權重計算
(1)
用IDF表示逆向文件頻率,即該關鍵詞在所有文件中出現的頻率。假設代碼庫中文件總數為M,包含關鍵詞i的文件數為Ni,那么關鍵詞i的逆向文件詞頻IDF為
(2)
關鍵詞i對這份代碼文檔的重要程度為
(3)
Ad-Sim算法中采用TF-IDF計算代碼中關鍵詞的權重,優勢在于可以過濾掉代碼中對代碼克隆檢測沒有用處的關鍵詞。在計算IDF時,假設關鍵詞序列中的代碼文件總數以及包含某一關鍵詞的代碼文件總數相等,從而計算出該關鍵詞IDF值為0,即表明該關鍵詞在克隆檢測中不起作用。例如在Java代碼中,幾乎所有的Java文件都會出現“public”“class”等關鍵詞,利用TF-IDF去掉這些詞后使得相對重要的關鍵詞得到保留,從而提高指紋簽名計算的精確度。
2.3 基于馬爾科夫模型的關鍵詞權重優化
如果把代碼中出現的關鍵詞作為一個狀態來看的話,那么馬爾科夫模型的狀態轉移矩陣恰好彌補TF-IDF的缺點。TF-IDF的缺點在于它只是記錄單個關鍵詞對代碼文檔相似度計算方面的影響,即TF-IDF關注的是個體,而馬爾科夫模型則主要研究的是鏈,僅僅將TF-IDF值作為權重,還是會降低檢測的準確度,于是將兩者有機的結合起來以達到更好的檢測效果。根據Java代碼語義、語法規范可知:代碼中所有關鍵詞存在較強的相關性,如Java關鍵字之間的先后關系等,并據此在Ad-Sim算法中引入馬爾科夫模型。首先建立源代碼的關鍵詞的馬爾科夫鏈;其次計算馬爾科夫鏈中前一關鍵詞到后一關鍵詞之間的馬爾科夫轉移概率,得出所有代碼中所有關鍵詞的馬爾科夫概率轉移矩陣;最后結合TF-IDF計算待檢測代碼中關鍵詞的權重。
馬爾科夫模型描述的是具有一定規律的離散狀態隨時間變化而不斷轉移的過程的模型化[14]。馬爾科夫過程是指具有馬爾科夫性的隨機過程,而參數集與狀態集均為離散的馬爾科夫過程稱為馬爾科夫鏈[15]。
在關鍵詞轉移概率矩陣的構建中,轉移概率通過代碼庫關鍵詞各種狀態轉移出現的概率來獲得,即每種關鍵詞狀態轉移占代碼庫中所有狀態轉移百分比。利用馬爾科夫狀態轉移矩陣計算方法求算出現有代碼庫部分關鍵詞狀態轉移概率如表1所示,表1中行為前一個關鍵詞,列為后一個關鍵詞。
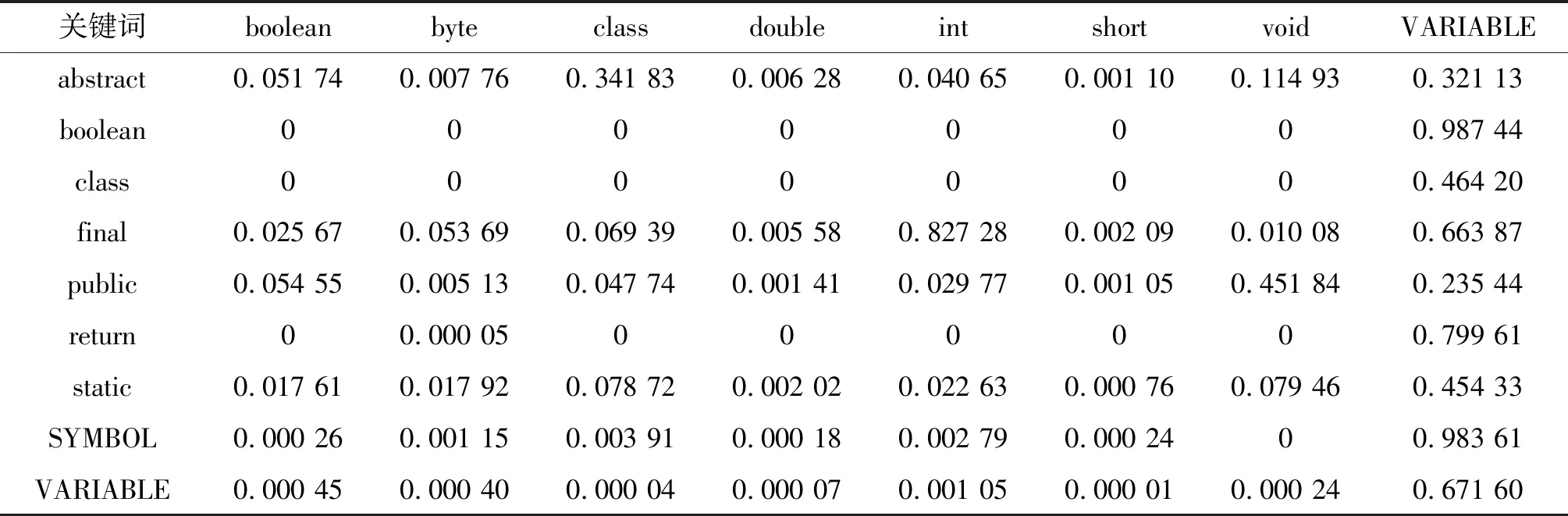
表1 代碼庫中部分關鍵詞狀態轉移概率Table 1 State transition probability of part keywords in code library
通過對關鍵詞TF-IDF以及馬爾科夫模型的研究,在結合TF-IDF以及馬爾科夫模型兩者計算待檢測代碼中每個關鍵詞的權重時,需要符合以下原則:
原則1權重的計算公式要體現出馬爾科夫模型的作用,考慮代碼中關鍵詞的前后關系,利用馬爾科夫轉移矩陣來表示代碼上下文對關鍵詞權重的影響。
原則2與關鍵詞的IDF值相結合,利用關鍵詞的IDF值來表示關鍵詞的稀有程度對權重的影響,使之能夠繼承TF-IDF的優點。
原則3在條件允許的情況下適當考慮算法的時間和空間復雜度的影響。
根據以上原則,權重計算式為
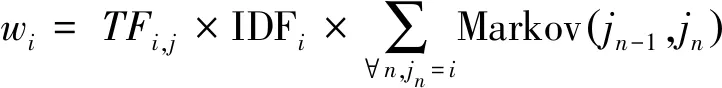
(4)
式中:i為第i個關鍵詞;jn為原代碼中第n個詞。
2.4 代碼克隆檢測步驟
根據上述算法基本思想,給出結合基于漢明距離、TF-IDF及馬爾科夫模型的代碼克隆檢測流程如圖2所示,具體步驟如下:
輸入:待檢測代碼
輸出:是否存在克隆代碼
1) 對實驗樣本代碼進行歸一化預處理,消除對克隆檢測無關的代碼。
2) 對實驗樣本代碼進行分詞處理,建立代碼關鍵詞序列,并使用mmh 3計算關鍵詞Hash值。
3) 利用TF-IDF計算代碼中所有關鍵詞權重,并結合使用馬爾科夫模型優化關鍵詞權重,使用式(4)。
4) 在Hash值的基礎上進行加權累加、合并和降維得出指紋簽名。
5) 使用漢明距離計算待檢測代碼的相似度,根據閾值判斷是否存在克隆代碼。
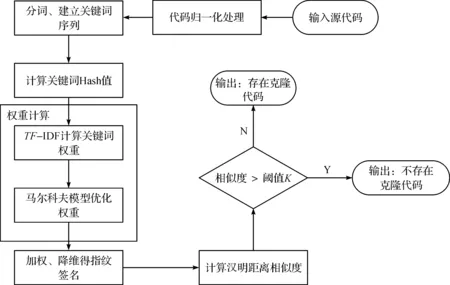
圖2 優化算法代碼克隆檢測流程圖Fig.2 The flow chart of optimized code clone detection
3 實驗結果及分析
3.1 實驗數據及評價方法
實驗選取100 組Java代碼作為測試用例,測試用例均取自開源項目的不同迭代版本。測試用例代碼庫中代碼總量在150 萬行以上,代碼數量上保證了足夠的測試樣本用例,其中包含算法、框架、設計模式和應用系統,在代碼復用和擴展等方面都具有代表性。
基于改進的Simhash算法代碼克隆檢測方法通過準確率、召回率及F-Measure值等3 方面來綜合性評價。
1) 準確率:用于衡量代碼克隆檢測方法的查準率,通過算法檢測出正確的組數與檢測出克隆的所有組數的比值來計算。計算式為
(5)
2) 召回率:用于衡量代碼克隆檢測方法的查全率,通過算法檢測正確的結果數與人工檢測出克隆的所有組數的比值來計算。計算式為
(6)
3)F-Measure值:用于綜合評價準確率及召回率,因為單一的準確率或召回率高并不能綜合算法檢測效果,F-Measure值通過準確率和召回率的調和平均值來計算。計算式為
(7)
3.2 實驗對比
3.2.1 不同K,L值下Simhash及Ad-Sim算法F-Measure比較
根據相似度判斷源代碼是否是克隆代碼,而指紋簽名長度L及漢明距離K對實驗最終結果的影響比較大,因此需要分析不同的K,L對克隆代碼檢測效果的影響,分別取不同的K,L值對Simhash算法及優化后Ad-Sim算法進行分析,計算克隆代碼檢測的F-Measure值。使用Simhash及Ad-Sim算法下,不同K值情況下的F值如圖3,4所示。
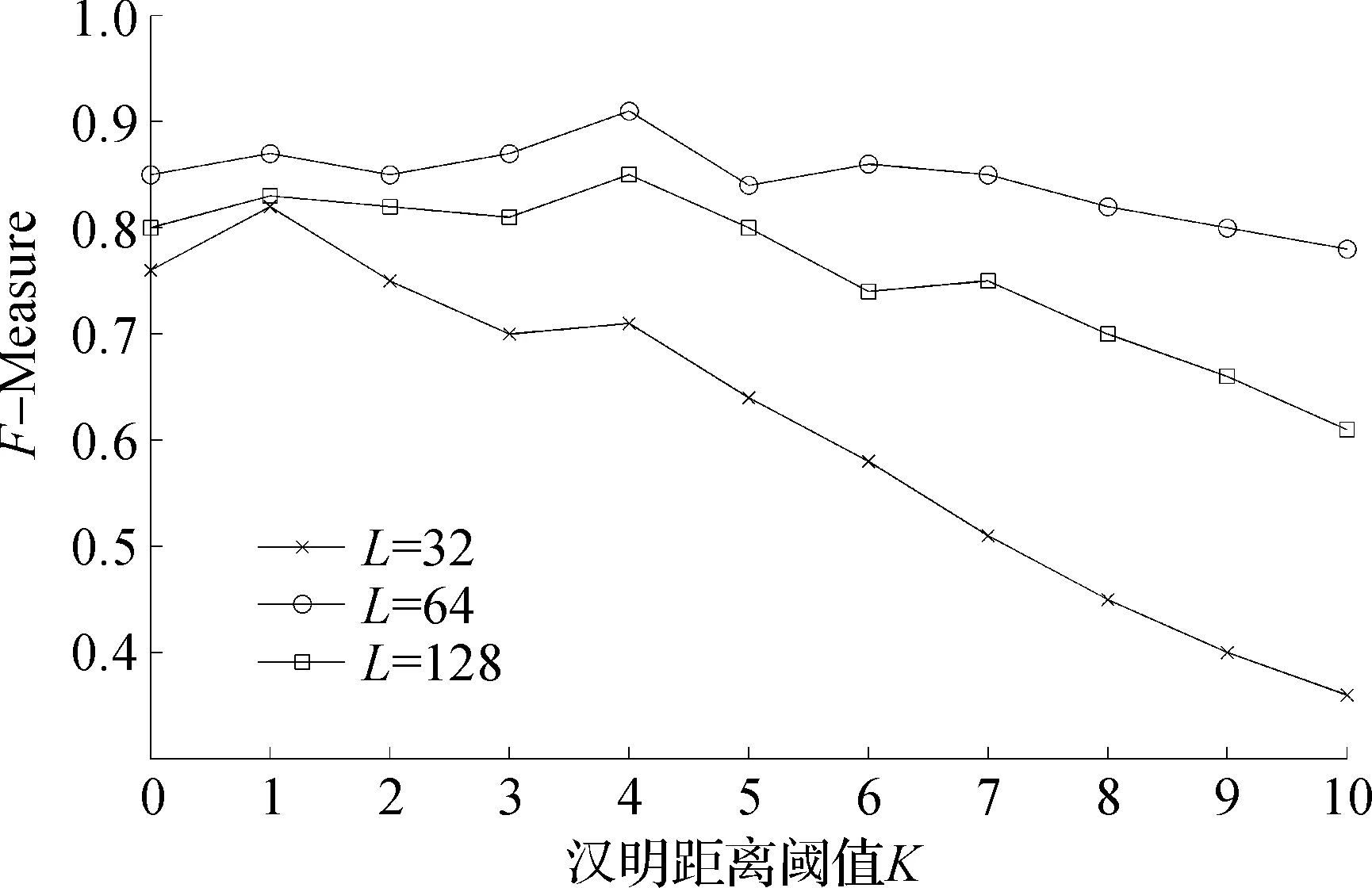
圖3 Ad-Sim算法下不同K,L值下F-Measure值情況Fig.3 F-Measure of Ad-Sim algorithm with different K,L
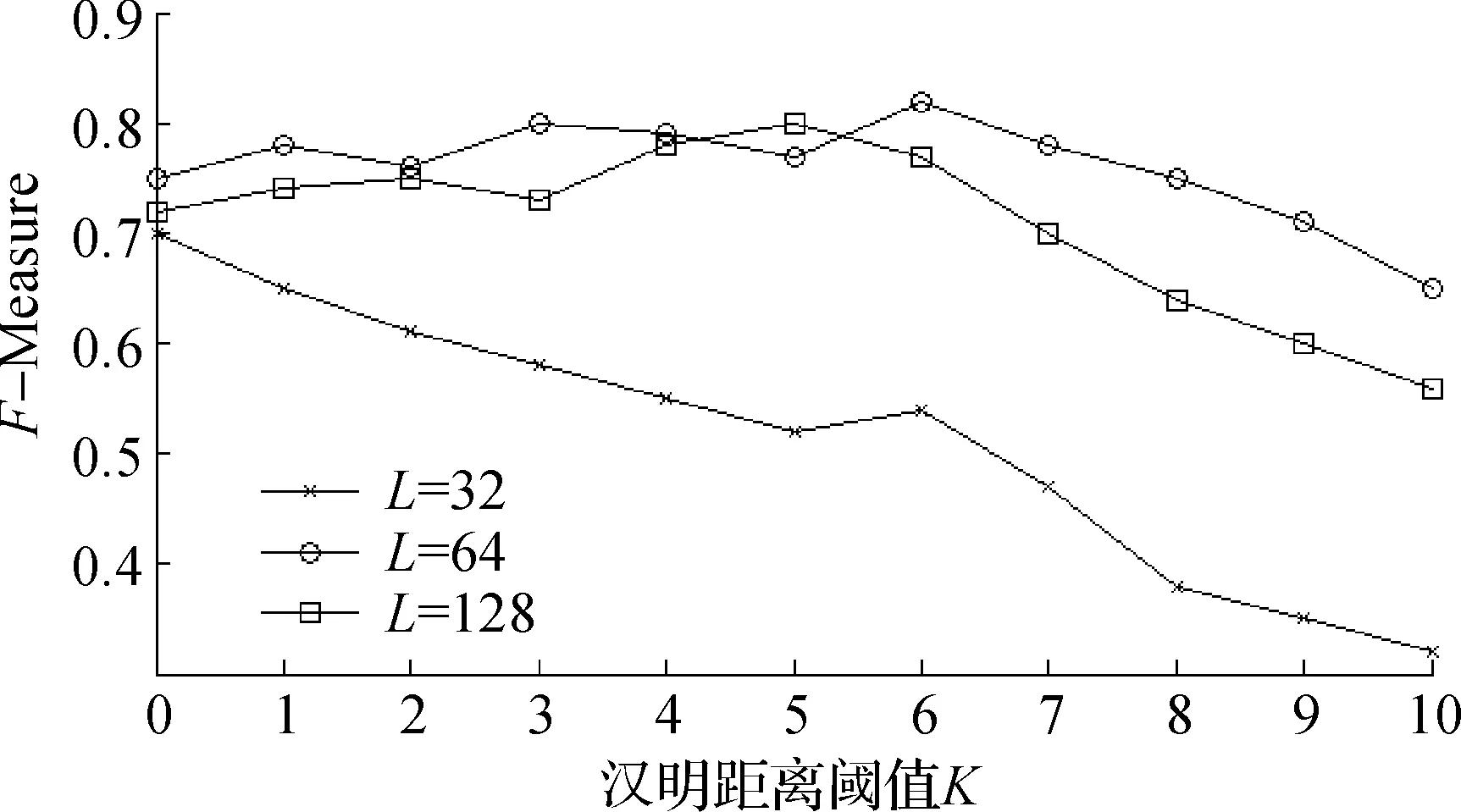
圖4 Simhash算法下不同K,L值下F-Measure值情況Fig.4 F-Measure of Simhash algorithm with different K,L
當K取值較小時,有較高的準確率但召回率很低,而K取值較大時,會導致檢測準確率較低,此外不同位數的二進制指紋簽名也會影響檢測準確率,不同位數的指紋簽名能代表源代碼的關鍵詞信息不同。從圖3,4可知:當K=4,L=64時,優化后Ad-Sim算法克隆檢測的F-Measure值最大;當K=6,L=64時,Simhash算法克隆檢測的F-Measure值最大。
3.2.2 Ad-Sim算法與Simhash,Dup,CCFinder的準確率比較
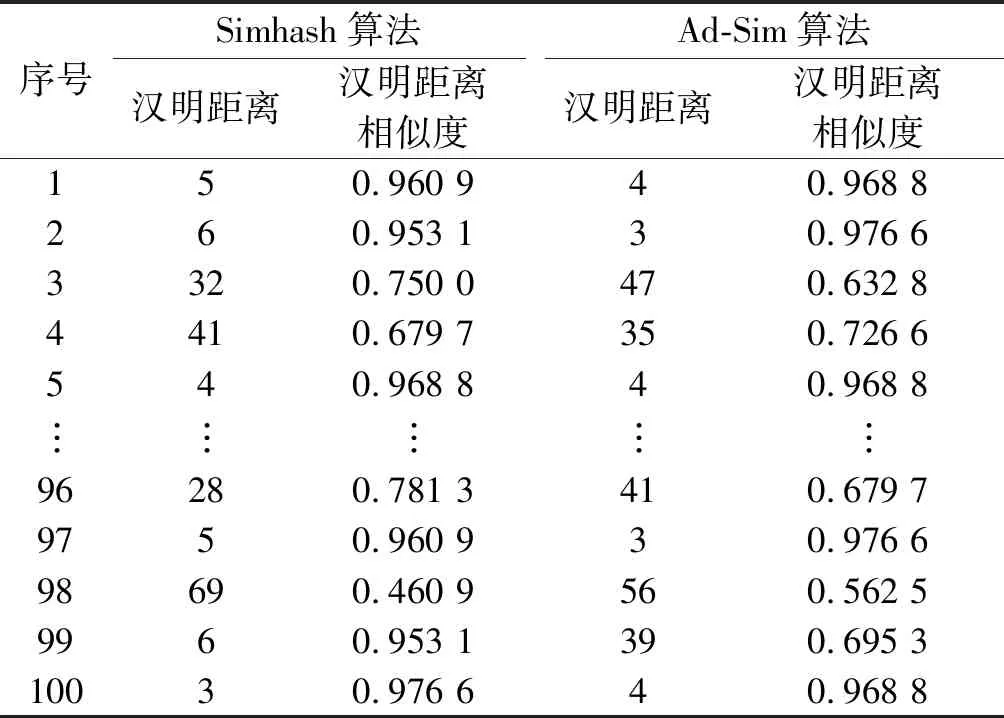
確定Ad-Sim,Simhash算法K,L值后,對Simhash及Ad-Sim算法的準確率及召回率進行測試,使用Simhash算法及優化后Ad-Sim算法計算100 組測試用例的64 位指紋簽名,并比較每組測試用例的漢明距離及相似度,漢明距離及其相似度使用文獻[12]中的公式計算,Simhash算法及優化后Ad-Sim算法部分測試結果如表2所示。
表2 原算法與優化算法漢明距離及相似度結果
Table 2 Results of Simhash and Ad-Sims’ Hamming distance and similarity
序號Simhash算法漢明距離漢明距離相似度Ad-Sim算法漢明距離漢明距離相似度150.960 940.968 8260.953 130.976 63320.750 0470.632 84410.679 7350.726 6540.968 840.968 8?????96280.781 3410.679 79750.960 930.976 698690.460 9560.562 59960.953 1390.695 310030.976 640.968 8
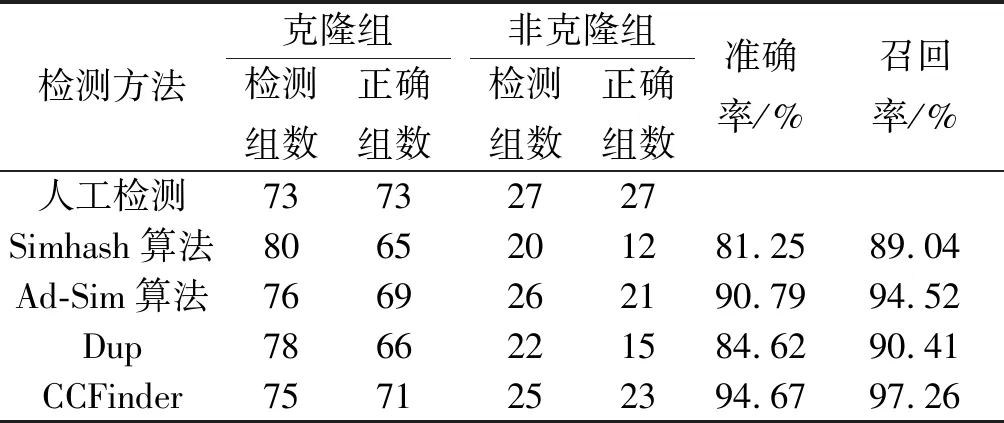
由表2可知:100 組實驗中,每組實驗的漢明距離及其相似度的原算法以及優化后Ad-Sim算法的克隆檢測結果。表2第99 號數據中,Ad-Sim算法計算得到的漢明距離大于Simhash算法,進一步分析發現該組的2 份源代碼關鍵詞詞頻接近,使用Simhash算法出現誤檢現象,而Ad-Sim算法很好地解決了該問題。將筆者提出的Ad-Sim算法與Simhash算法、Dup[3]及CCFinder[4]代碼克隆檢測工具進行對比實驗,表3為人工檢測與各種算法檢測的對比結果,從表3可以看出:優化后的Ad-Sim算法在代碼克隆檢測準確率及召回率相比較Simhash算法有所提高,且Ad-Sim算法相較于基于Text方法的Dup有更高的檢測準確率,因為基于Text的方法在檢測對源代碼進行修改后的檢測準確度、召回率較低,但相對于基于Token的CCFinder的檢測準確率和召回率相對較低。
表3 Simhash算法與優化Ad-Sim算法檢測結果準確率及召回率對比表
Table 3 Results of original and optimized algorithm’s precision and recall rate
檢測方法克隆組檢測組數正確組數非克隆組檢測組數正確組數準確率/%召回率/%人工檢測73732727Simhash算法8065201281.2589.04Ad-Sim算法7669262190.7994.52Dup7866221584.6290.41CCFinder7571252394.6797.26
3.2.3 不同代碼量下Ad-Sim算法與Simhash算法比較
為測試代碼量對Simhash算法及優化后Ad-Sim算法的影響,實驗選擇代碼量大小從50 kB到800 kB,以50 kB為區間,對Simhash及Ad-Sim算法進行準確率測試。圖5為不同代碼量對各算法準確率的影響,可以看出:優化后Ad-Sim算法合適的測試代碼量范圍為250~700 kB,準確率達到90%以上,代碼克隆檢測范圍優于Simhash算法,且優化后Ad-Sim算法的代碼克隆檢測準確度更趨于穩定。此外,在實驗中當代碼量小于200 kB時,由于源代碼中關鍵詞數量較少,僅通過詞頻作為權重使得Simhash算法生成的指紋信息準確度不高,導致Simhash算法的檢測準確率明顯低于Ad-Sim算法。
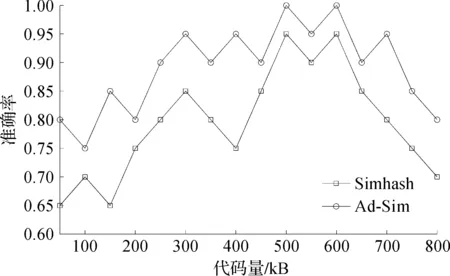
圖5 原算法與優化算法隨代碼量變化下準確率對比圖Fig.5 Results of original and optimized algorithm with change of code amount
4 結 論
在Charikar提出的大量網頁文檔查重的Simhash算法基礎上,提出了一種結合TF-IDF及馬爾科夫模型的改進Simhash代碼克隆檢測算法Ad-Sim。首先對代碼進行歸一化預處理,并進行分詞、Hash、加權以及降維;其次在加權過程中對關鍵詞權重計算時引入TF-IDF及馬爾科夫模型;最終通過計算待檢測代碼指紋簽名與代碼庫中代碼的指紋簽名的漢明距離相似度判斷是否存在克隆代碼。通過理論分析及實驗驗證,與Simhash算法相比,優化后Ad-Sim算法在檢測準確率及召回率上更高,并且在少量代碼的檢測準確率提升更明顯。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
