基于聚類算法的模板匹配信號識別改進算法
2019-06-12 05:55:30李靖超張之蕾
上海電機學院學報 2019年1期
李靖超, 張之蕾
(上海電機學院 電子信息學院, 上海 201306)
早期的信號識別主要用于軍事領域,當時的通信系統中,采用人工手動調制方式識別,即依靠人工計算測到的參數,判斷信號源。如今民用的信號監測、信號確認、干擾識別、頻譜管理、軟件無線電和衛星通信等諸多領域中,都需要進行信號自動識別。目前國內外已發表的有關調制識別的文獻中,信號調制識別的方法大致上可以分為兩大類:基于特征提取的統計模式識別方法[1-3]和基于決策理論的最大似然假設檢驗方法[4-5]。李迅等[6]提出了一種基于多相濾波的數字正交變換技術提取信號瞬時特征的方法,此算法下的分類器可以有效估計信號的瞬時特征,將其運用于信號調制體制識別,取得了較好的效果;謝曉東等[7]提出了一種調制信號盲檢測算法,為實現調制信號的盲識別提供了理論基礎。羅利春[8]用準對數似然函數比(Quasi-logarithmic Likelihood Function Ratio, QLLR)方法構造檢測多進制數字相位調制(Multiple Phase Shift Keying, MPSK)信號的假設檢驗及其QLLR,并求其數學期望,進而實現對信號的分類,取得了較好的效果。
信號識別[9]是信號處理的一個基本問題,其主要目的是從噪聲信號中提取有用的特征數據庫并對有用的信息進行識別。模板匹配[10]是一種最原始、最基本的模式識別方法,研究某一特定對象物的特征位于對象物的什么地方,進而識別對象物。它是信號處理中最基本、最常用的匹配方法。模板匹配具有自身的局限性,主要表現在它只能進行平行移動,若原信號中的匹配目標發生變化,該算法無效。模板匹配是信號識別中最具代表性的方法之一[11],它從待識別信號中提取若干特征向量與模板對應的特征向量進行比較,計算圖像與模板特征向量之間的距離,用最小距離法判定所屬類別[12-13]。因此,為了提高識別率,本文從識別精度較高的模板匹配法入手,對標準模板匹配算法進行改進,可使識別率有不同程度的提高。
1 改進模板匹配算法
模板匹配法是根據已有的經驗和對未知信號類型的把握,建立通信信號樣本的多維特征數據庫。當接收機截獲到某一信號時,首先提取該信號的特征,然后與數據庫中樣本信號特征匹配,計算與數據庫中每一樣本的特征距離,距離最小的即為待識別的通信信號所屬的類型。
聚類算法又稱群分析,它是研究(樣品或指標)分類問題的一種統計分析方法,同時也是數據挖掘的一個重要算法。聚類分析以相似性為基礎,在一個聚類中的模式之間比不在同一聚類中的模式之間具有更多的相似性[14-16]。聚類就是按照某個特定標準(如距離準則)把一個數據集分割成不同的類或簇,使得同一個簇內的數據對象的相似性盡可能大,不在同一個簇中的數據對象的差異性也盡可能大,即聚類后同一類的數據盡可能聚集到一起,不同數據盡量分離[17]。因此,當接收機截獲到未知信號時,只需利用已建立的特征數據庫,提取相應的特征向量,用模板匹配法,計算未知信號的特征向量與數據庫中信號的特征距離,根據特征距離判斷未知信號。
通信信號識別流程圖如圖1所示。
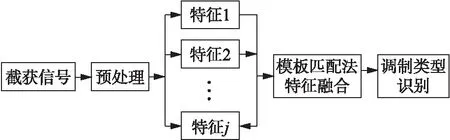
圖1 信號識別流程圖
假設識別系統有N類不同類型信號的特征數據庫,定義未知通信信號的第j類信息特征Ej與已知的第i(i=1,2,…,N)類信號的第j類信息特征Aij的距離為
dij=|Ej-Aij|
(1)
式中,dij為測得的未知信號的第j類信息特征值。
待識別信號與第i類通信信號的信息特征距離為
(2)
待識別信號與第i類樣本的貼近度計算公式為
(3)
式中,0≤Ni≤1。
對信號的誤差值進行開根的計算,進而得出信號的貼近度,即定義待識別信號與第i類樣本的貼近度為
(4)
通過改進的模型能更清晰地判斷出未知信號所屬的類型,更為精確地計算出待識別信號與已知信號之間的貼近度,從而達到更精確地對信號進行識別的目的。
2 仿真結果與分析
假設多維特征向量E=(E1,E2,E3,E4)分別為6種類型的通信信號對應的特征值,對于每一種調制類型,在信噪比為-10~20 dB之間每隔1 dB產生200個特征值樣本,進而形成不同信噪比下樣本信號的特征數據庫。
假設不同信號的多維特征向量值如表1所示(以6種不同通信信號的小波熵值特征為例)。
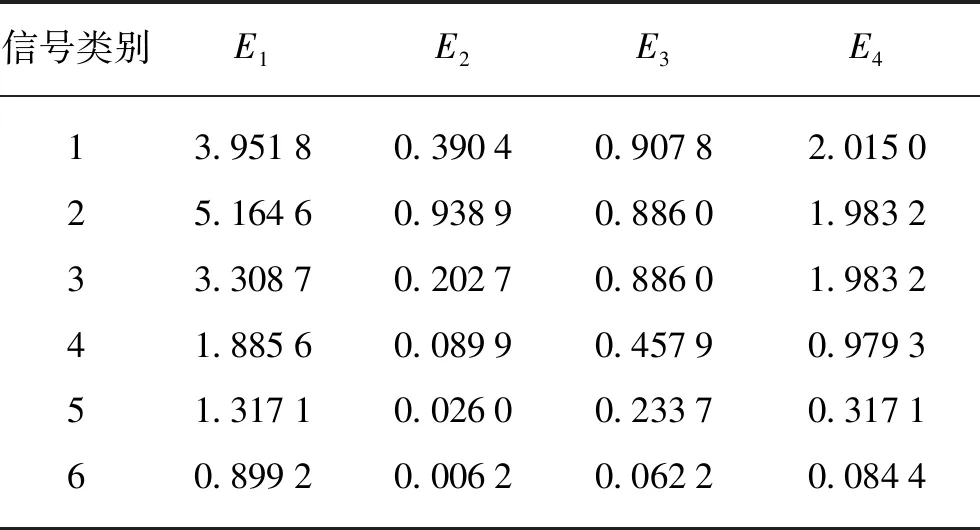
表1 多維特征向量值
利用傳統貼近度算法,在信噪比為5 dB時計算得到的貼近度值如表2所示,從計算結果中可知,傳統的貼近度計算公式得到的貼近度與信號5、6的貼近度很接近,差異較小,這在更低的信噪比環境下會影響系統的識別率。利用改進算法計算信號貼近度數值如表3所示。
從表3可以很清晰地看出,改進后的貼近度模型中每個信號之間的差異都較大,未知待識別信號與信號4貼近度值接近1,與其他類型樣本的貼近度都小于0.8,通過改進的模型能更清晰地判斷出未知信號所屬的類型。為了對比改進算法與傳統算法的貼近度差異,貼近度值對比如圖2所示。
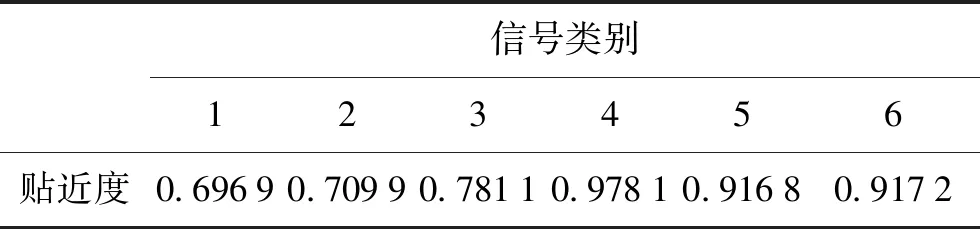
表2 傳統算法的貼近度數值
利用特征數據庫中的特征,進行訓練、測試,判決貼近度最大值所對應的模板信號的類別為待識別信號的類別,進而計算不同信噪比(Signal to Noise Ratio, SNR)下的多維特征識別結果如圖3所示。
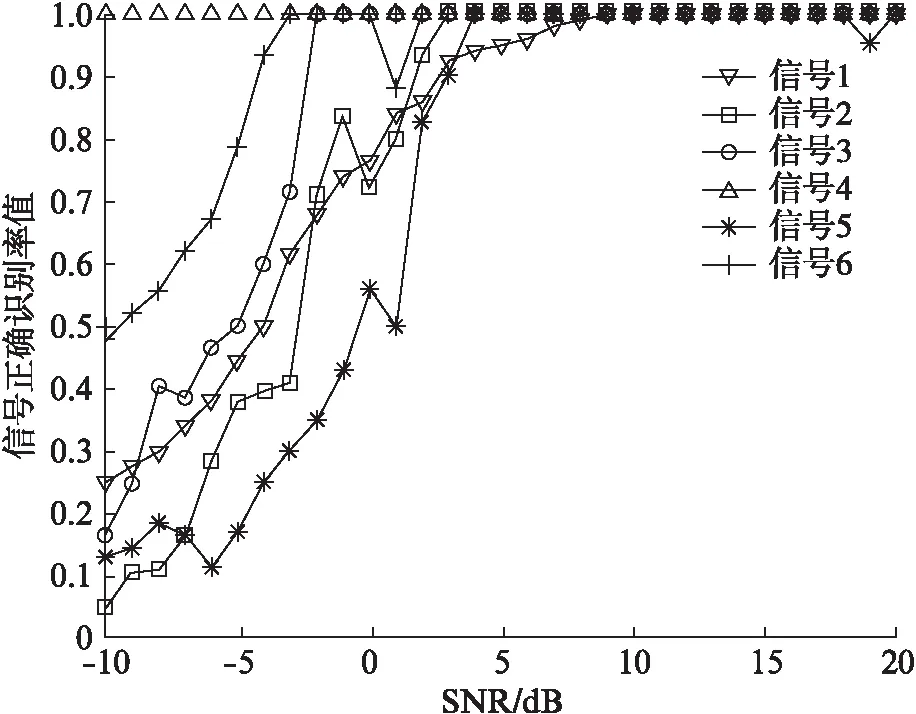
圖3 基于模板匹配各信號正確識別率
信息融合理論表明,多特征的識別效果要優于單一某個特征的識別效果,這是因為不同的特征從不同的角度表現信號的復雜度和奇異性特征。信號1~6代表任意通信信號,通過仿真幾種不同通信信號的多維特征,建立特征數據庫進行分類,驗證分類器的效果。當SNR>3 dB時,幾種通信信號的識別率為95%以上,當SNR>10 dB時,這些信號的正確識別率為100%,可以實現較高SNR環境下對不同信號特征的準確識別。
3 結 語
針對信號識別中分類器設計這一環節,提出了改進的基于聚類算法的模板匹配信號識別方法。在傳統的模板匹配識別算法的基礎上,對計算方法進行改進,提高該算法在較低SNR環境下的識別能力。仿真結果表明:即使在SNR為5 dB的環境下,仍能夠實現對不同信號特征的準確識別。這為模板匹配方法在信號識別、視頻跟蹤、工件精定位等領域的廣泛應用提供了重要的理論依據。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年11期)2018-08-04 03:25:42
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
