主題詞法和自然語言法探測文獻主題新穎性對比分析
2019-06-13 08:02:18
中華醫學圖書情報雜志 2019年1期
關鍵詞:方法
文本新穎性探測是指按時間順序在給定的一些相關文獻集中,比較新到相關文本與已有文本之間內容的冗余度,確定新到文本內容是否新穎[1]。對于科技文獻質量的創新性、新穎性的分析評價,目前沒有統一的標準,可以通過以下方法進行。一是基于文獻計量學的引文分析法。該方法利用科學文獻間的引用關系反映科技成果的學術價值以及學術地位,說明科學知識和情報內容的繼承和利用,評價推薦出新穎性文獻[2],其最大缺點是時間的滯后性。二是基于向量空間模型的相似度計算方法。應用最廣泛的是向量夾角余弦值。Salton[3]提出TFIDF算法進行權重賦值,該方法體現的主要思想是當一個詞語在特定文獻中出現的頻率越高,說明它在區分文獻內容屬性方面的能力越強;一個詞語在特定文獻中出現的范圍越廣,說明它在區分文獻內容屬性方面的能力越低。當前文本和以前文本之間的相似度越大,則新穎性越小[1]。三是基于關鍵詞詞頻分析的方法。關鍵詞是作者根據文章的主要內容、理論、方法、觀點,通過概括、總結提煉出來用于揭示文章主題信息的自然語言,關鍵詞數量通常少于自然語言詞和醫學主題詞。不同作者因地域、時代的差異,對于事物、觀點的稱謂不盡相同。關鍵詞具有一定主觀性,無法做到表述一致,對文獻新穎性分析存在不同程度的影響。因此,在文獻新穎性分析之前,應對關鍵詞進行規范化預處理,降低同義詞、近義詞、上下位詞對分析結果產生的影響。四是基于創新型生物醫學文獻學術評價系統F1000的評價方法。F1000是生物醫學領域同行評議的數據庫,F1000專家對世界頂級的生物、醫學雜志最新發表的文章從創新性、重要性、合理性、方法學等方面進行同行評定,選取最有價值文獻給予推薦,幫助生物學及醫學領域的研究人員掌握本學科領域的最新研究進展。同行評議是專家根據個人的態度對文獻本身學術成就給予的評價,主觀性大。五是突發詞監測算法。根據詞頻變化率統計出低頻但具有情報意義的突發詞,探測新興研究熱點和研究趨勢,適用于某研究領域前沿趨勢的探測[4]。
近年來,國內多位學者進行了文獻主題新穎性探測的相關研究。如徐爽[4]通過突發詞監測算法研究了全身炎癥反應綜合征治療藥物,根據詞頻變化率統計出低頻但具有情報意義的突發詞,探測該領域新興研究熱點;楊建林[5]運用基于關鍵詞對逆文檔頻率的方法進行主題新穎性的度量;陳斯斯[6]應用詞重疊法和基于共詞的逆文檔頻率量化法對比分析探測評估醫學文獻主題新穎性,得出詞重疊法更優的結論。
有研究通過自然語言詞對方法(以下簡稱“自然語言法”)計算了文檔主題新穎度,探討了文檔主題新穎度與F1000推薦文獻、引用情況分屬于科技論文評價的不同維度、不同范疇,不可一概而論[7]。本文在此基礎上提出了基于醫學主題詞詞對法的文獻主題新穎性探測方法(以下簡稱“主題詞法”),運用兩種方法對同一文獻集進行文檔主題新穎度的計算并進行比較分析,探討兩種方法計算文檔主題新穎度結果的一致性和差異性,以及兩種方法的優缺點和與F1000推薦文獻的關系。
1 研究方法與工具
1.1 研究方法
醫學主題詞詞對逆文檔頻率原則(Inverse Document Frequency of Mesh Pair,MPIDF),即一對共現的醫學主題詞詞對在量化某文檔的主題新穎度時的價值隨著在該文檔之前發表的、包含該對共現醫學主題詞詞對的文檔數量的增加而降低[5]。
醫學主題詞時間逆文檔頻率是指若t為文檔D中的一個已標引的主題詞,在文檔D之前發表的所有文檔中包含已標引主題詞t的文檔數為N,則稱N+1為以文檔D為參照的主題詞t的文檔頻率,記為MT-IDF(D,t),稱N+1的倒數為以文檔D為參照的主題詞t的時間逆文檔頻率,記為MTIDF(D,t)。
醫學主題詞詞對時間逆文檔頻率是指若t1、t2為文檔D中共同出現的兩個已標引的醫學主題詞,在文檔D之前發表的所有文檔中同時包含已標引醫學主題詞t1、t2的文檔數為N,則稱N+1為以文檔D為參照的醫學主題詞詞對t1、t2的文檔頻率,記為MPT-IDF(D,t1,t2),稱N+1的倒數為以文檔D為參照的醫學主題詞詞對t1、t2的時間逆文檔頻率,記為MPTIDF(D,t1,t2),得到MPTIDF(D,t1,t2)≥(MPTIDF(D,t1),MPTIDF(D, t2))。
主題詞法文檔主題新穎度是指文檔D中所有以自身為參照的醫學主題詞詞對的時間逆文檔頻率的平均值稱為文檔D的主題新穎度,記為NOV(D,M)。計算公式為:
式中,ti、tj為文檔D中已標引的第i和第j個醫學主題詞,顯然NOV(D,M)∈(0,1)。
1.2 研究工具
1.2.1 F1000
F1000是近年來生物醫學領域同行評議的文獻評價數據庫,每年對全球文章總數不足2‰的優秀精品醫學論文進行推薦和點評,給出F1000得分,依據學術貢獻和科學價值挑選出優秀論文推薦給全世界的生物學和醫學研究者[8],幫助生物學及醫學領域的研究人員掌握本學科領域的最新研究進展。研究人員發表的論文被F1000收錄并獲得推薦,是對該論文和研究人員的高度認可。
1.2.2 MeSH
《醫學主題詞表》(Medical Subject Headings,MeSH)由美國國立醫學圖書館編制而成,主要目的是提供一個分層組織的術語,用于MEDLINE/PubMed和其他NLM數據庫中生物醫學文獻信息的索引和編目以及檢索利用[9-10]。MeSH由主題詞(Descriptors,亦稱“敘詞”)、副主題詞(Qualifiers,亦稱“限定詞”)和增補概念構成[9]。副主題詞指主題詞所論述的重點課題的自然范疇或通常發生的某一方面,對主題概念起限定作用[9];副主題詞與主題詞進行邏輯組配,專指性更高,可以提高查全率和查準率,是實現智能化檢索的重要途徑。
本文選取自然語言法相同文獻集,在同篇共現基礎上計算主題詞法文檔主題新穎度,提取PubMed中已標引的MeSH詞匯代表文章的主要內容。該文獻集內含401篇文獻(其中F1000推薦文獻33篇),具有MeSH標引的文獻346篇(其中F1000推薦文獻30篇),從中提取MeSH標引詞匯7 021條記錄,組合成詞對后共計約8萬條記錄。根據主題詞法文檔主題新穎度公式計算出每篇文章的新穎度值,結合自然語言法新穎度結果進行對比分析。
2 實驗結果和結論
2.1 文檔主題新穎度分區
文檔主題新穎度值及分區情況統計見表1和表2。
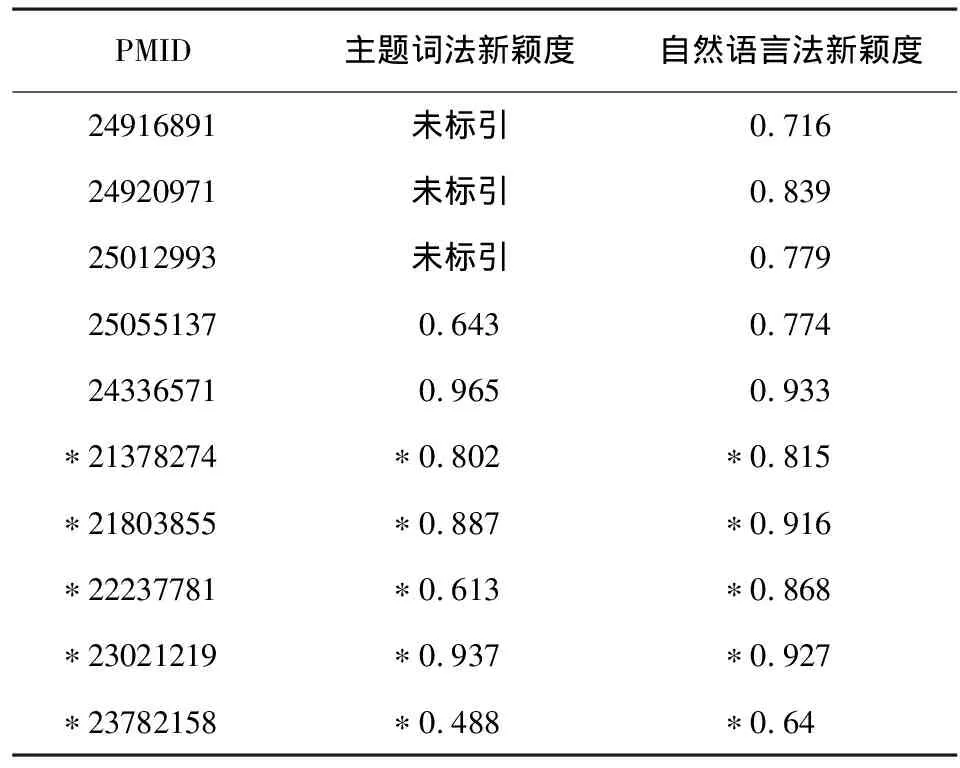
表1 兩種方法計算的文檔主題新穎度值(部分)
注:* 代表F1000推薦文獻
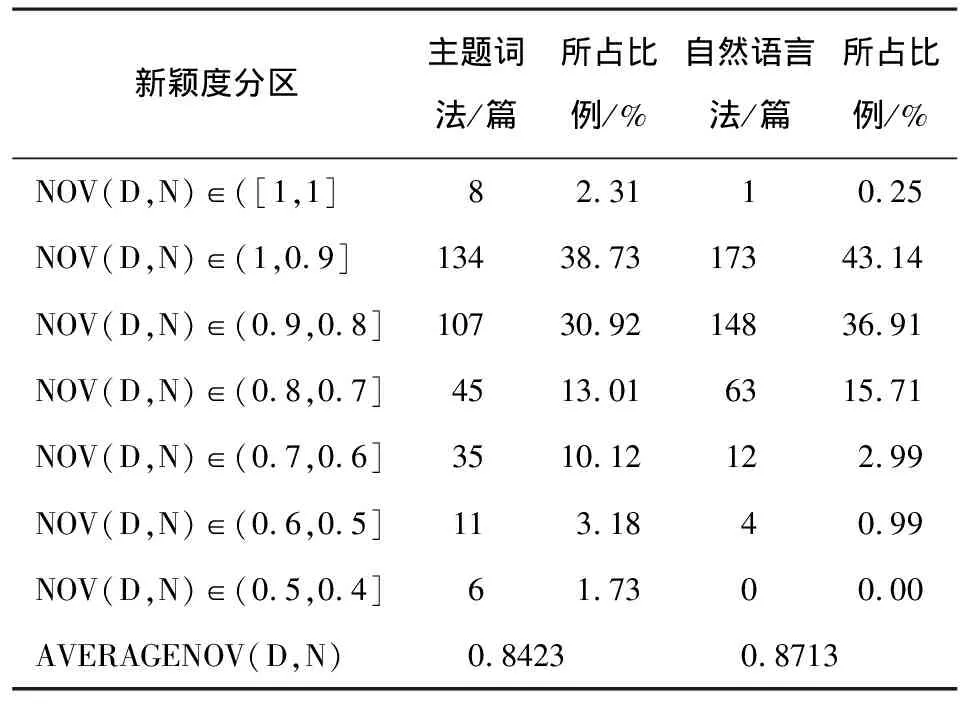
表2 主題詞法和自然語言法文檔主題新穎度值分區
對主題詞法和自然語言法獲得的文檔主題新穎度值進行Spearman相關性比較顯示,兩種方法在計算文檔主題新穎度之間呈正相關,相關系數為0.593,P=0.000,可見主題詞法和自然語言法在計算文檔主題新穎度方面有相對等效的價值。
主題詞法計算新穎度的范圍為PubMed中已有MeSH標引的346篇文獻,未標引的55篇文獻主要是因下載文獻過新而尚未進行標引。主題詞法計算出的新穎度最高值為1,共有8篇,說明其在區分最高級別、最卓越文獻方面不是特別理想;該方法計算出的最低值為0.439。新穎度值相差0.1分為一個區間,計算結果可分為7個區間,平均新穎度值為0.8423,大于平均新穎度值的文獻有212篇,占統計文獻總數的61.27%。
2.2 F1000推薦文獻文檔主題新穎度分區情況
兩種方法計算的F1000推薦文獻文檔主題新穎度分區見表3。用主題詞法計算該文獻集中MeSH標引的364篇文獻中,F1000推薦文獻30篇;用自然語言法計算該文獻集全部的401篇文獻中,F1000推薦文獻33篇。
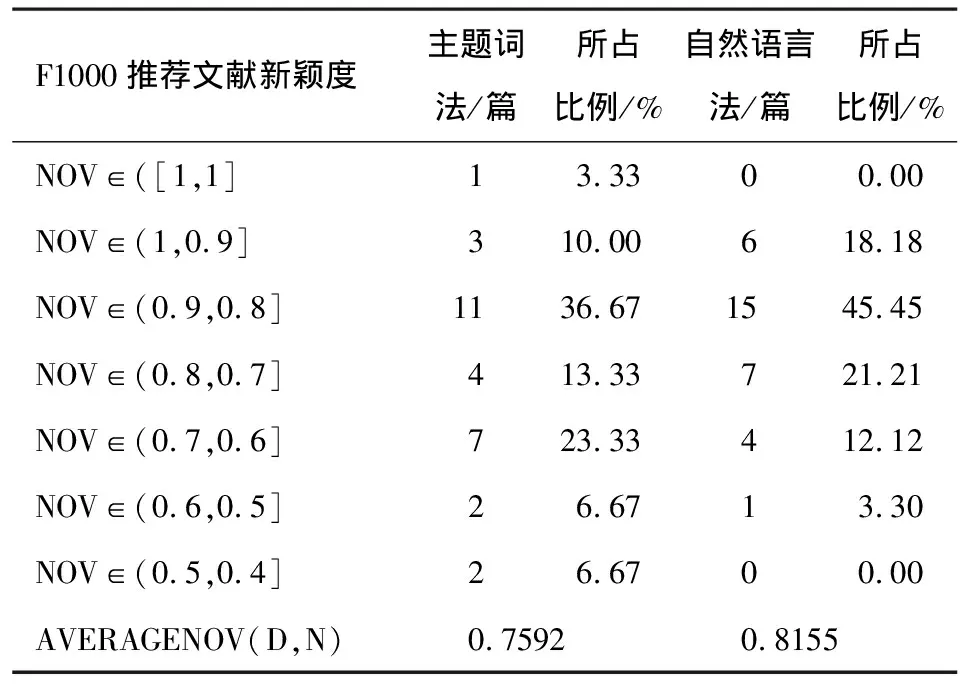
表3 主題詞法和自然語言法計算的F1000推薦文獻文檔主題新穎度分區
用主題詞法計算的F1000推薦文獻中的新穎度最高值為1,最低值為0.448,計算結果共分為7個區間。該方法計算出的平均新穎度值為0.7592,大于平均新穎度值的文獻有18篇,占統計文獻總數的60%,與自然語言法占比等同,說明在識別高質量文章情況下,兩種方法計算結果基本一致。
2.3 兩種方法計算結果分布的一致性比較
兩種方法計算結果分布的一致性是指主題詞法和自然語言法計算出的文檔主題新穎度值均分布在某區間的文獻數占統計文獻的比例。Meet/min方法是目前被公認的一種簡單有效的評估協同程度的方法[11],運用Meet/min方法將兩種方法計算出的新穎度值分區在同一區間內的共同文獻數量可定義一致率的概念,公式如下。結果見表4和圖1。

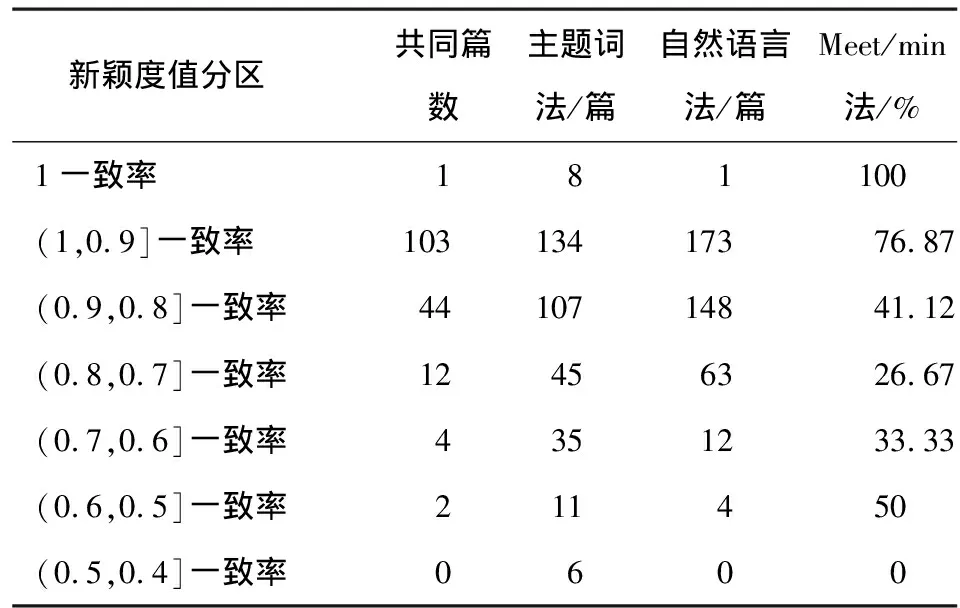
表4 主題詞法與自然語言法計算的新穎度值一致率
從表4可以看出,隨著新穎度值的增加,分布在同一區間內的文獻篇數也在增加。新穎度值在0.5~0.8之間的一致率呈下降趨勢,可能由于統計文獻的樣本數量較少所致;新穎度值在0.7~1之間的一致率呈上升趨勢,說明新穎度值越高,主題詞法和自然語言法在計算文檔主題新穎度方面越能獲得相同的預測效果。
圖1是對346篇主題詞法新穎度值和401篇自然語言法新穎度值做成的散點圖,橫坐標為文獻序列號,縱坐標為新穎度值,其中346篇文獻中每個序列號分別對應圖中兩個顏色的點以及它們分布的位置,所對應的兩個點的距離就是兩種算法新穎度值的差距。
從圖1可以看出,新穎度值越高,兩種顏色點的分布越密集,主題詞法和自然語言法計算出的文檔主題新穎度值分區越一致。
2.4 兩種方法計算結果分布差異性比較
兩種方法計算結果分布差異性是指同一篇文獻經主題詞法和自然語言法兩種方法計算后得到的新穎度值之間的差值。結果見表5和圖2。
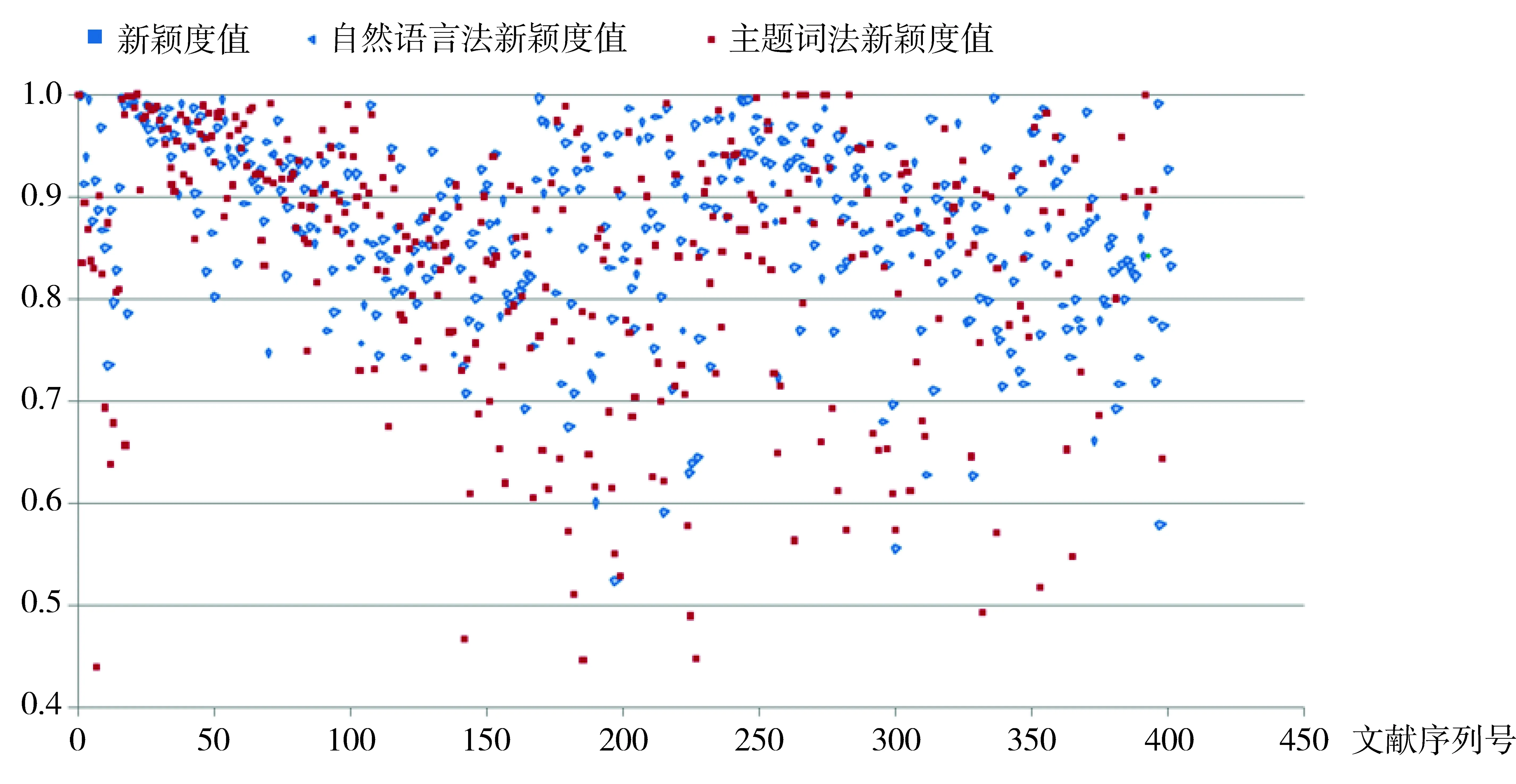
圖1主題詞法和自然語言法新穎度一致性的分布散點圖
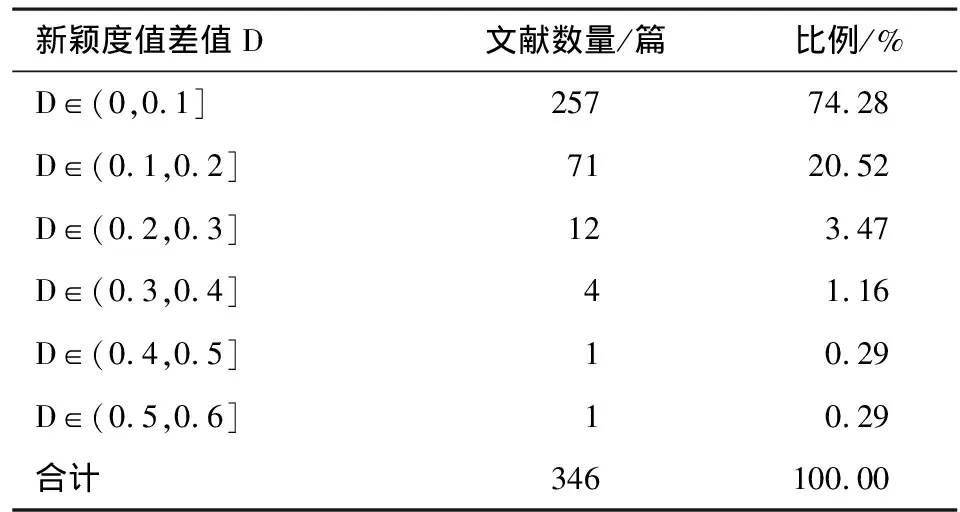
表5 主題詞法和自然語言法計算的新穎度值差異
從表5可以看出,同一篇文獻經主題詞法和自然語言法兩種方法計算得到的新穎度值之差在0~0.1的最多,為257篇,占統計文獻總數的74.28%;差值在0.1~0.2的文獻為71篇,占統計文獻總數的20.52%;差值在0.2~0.3的文獻為12篇,占統計文獻總數的3.47%;差值在0.3~0.4的文獻為4篇,占統計文獻總數的1.16%;差值在0.4~0.5的文獻和在0.5~0.6的文獻均為1篇,分別占統計文獻總數的0.29%。
說明絕大多數文獻經兩種方法計算得到的新穎度差值在0.1以下。
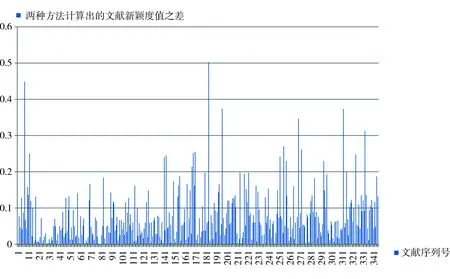
圖2 主題詞法和自然語言法新穎度差異
圖2是根據用兩種方法對346篇進行計算得到的每篇文獻新穎度差值做成的一個柱狀圖,橫坐標代表文獻序列號,縱坐標代表兩種方法計算的新穎度差值。從圖2可以看出,同一篇文獻經主題詞法和自然語言法計算出的新穎度值之差在0~0.1之間分布最多,差值在0.1~0.2之間的文獻數量次之,說明兩種方法在計算文檔主題新穎度值方面差異不大,在探測文檔主題新穎度方面具有等同的效果。
2.5 F1000推薦文獻新穎度與其他指標比較
兩種方法計算的F1000推薦文獻文檔主題新穎度值與其他指標的比較見表6。

表6 主題詞法和自然語言法計算的F1000推薦文獻文檔主題新穎度情況及其他指標比較(部分)
上述表格各列數據經過統計學方法判斷均沒有統計學意義,自然語言法新穎度值、IF值及F1000得分都不存在相關性,主題詞法新穎度值和F1000得分弱相關,說明相比自然語言法而言,主題詞法計算新穎度值與同行評議結果趨于一致。
圖3表示兩種方法計算的文檔主題新穎度值與F1000得分的關系,橫坐標表示F1000得分,縱坐標表示新穎度值,中間的橫線代表兩種方法計算的新穎度中值,兩者距離越相近,說明兩種方法計算出的新穎度值越靠近。從圖3可以看出,隨著F1000得分的增高,兩種方法計算的新穎度越相關。兩種方法計算得到的新穎度值的高低與文獻所在期刊的IF值并無明顯相關性。
3 討論
3.1 兩種方法優缺點對比分析
從計算層次來看,兩種方法均是從文本層出發進行的主題新穎性探測,不同之處在于主題詞法是在同篇共現基礎上進行的計算,能將整個文獻集內經過MeSH標引的文獻進行計算獲得新穎度值;自然語言法是在同篇同句共現基礎上進行計算,將提取的自然語言詞匯經公式計算后獲得的新穎度值[7]。
從計算范圍來看,主題詞法計算了文獻集內經MeSH標引的346篇文獻,自然語言法計算了文獻集內的全部文獻401篇,計算范圍比主題詞法廣泛。
相比較而言,主題詞法具有不可替代的自身優勢,它將自然語言轉換成規范化名詞術語,在揭示文章主要內容、表達主旨含義上更加科學、準確,在計算新穎度值上更加準確,與同行評議結果符合度更高;自然語言法通過MetaMap提取自然語言詞匯,在進行計算時可以不受時間的限制而將整個文獻集內的全部文獻進行計算得到不同的新穎度值,在一定程度上代表主旨含義,在揭示新興主題概念方面具有更高的價值[7]。
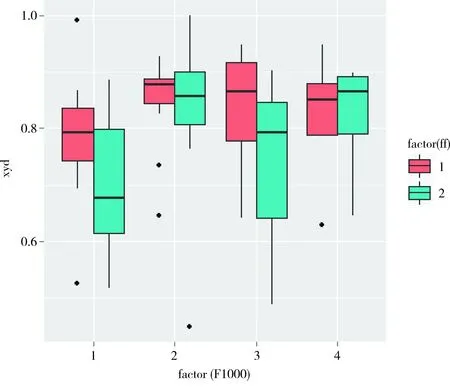
圖3 兩種方法新穎度值與F1000得分關系
雖然MeSH每年都在更新,但仍然滯后于科學技術的發展。新的科技詞匯要在出現一段時間后才會經過專家學者推薦核準為正式的主題詞用于文章標引,這在體現最新科技研究成果方面會受到制約。同時最新發表文獻因尚未進行MeSH標引,在進行計算時有一定限制,早年發表的文獻也存在缺失標引或者未標引的情況。而自然語言法因受MetaMap自由度影響,隨其詞匯源不斷更新,MetaMap提取新興科技詞匯的效果好則結果好,反之亦然[7]。
本文兩種文檔主題新穎度的計算方法,對評價量化文獻主題新穎性提出了全新指標,兩者在一定程度上有著等效價值,隨著計算的文檔主題新穎度值的增高,兩種方法計算出的新穎度值越相近。
3.2 論文不同層面評價指標分析
本文兩種方法計算的文檔主題新穎度是從文本層面出發而進行的客觀量化分析評價,分別從文中提取詞對進行計算,通過發現對比之前文獻集中尚未出現的詞對情況來證明文獻的新穎程度,對文獻集中每一篇文章給出評價,相對更加客觀。同行評議指標F1000評分相對簡單,僅將各位專家評分累積求和即可獲得F1000得分。F1000是基于同行評議的論文評價,難以保證評價的絕對客觀性,同時也存在運用范圍不夠廣泛、全面的情況。
本文發現F1000得分與主題詞法新穎度值存在弱相關,表明該方法通過提取代表主旨含義的醫學主題詞詞對進行計算后得到的新穎度值與專家同行評議在一定程度上一致,也就是從論文評價的不同層面給出相對一致的結論。這也與劉春麗發現不同類型計量指標對同一組論文影響力的評估具有一致性的結論相符[12]。
3.3 文獻提取和計算過程中的不足
PubMed數據庫中記錄的錯誤對于結果有一定的影響,如自然語言法提取文獻已經限定PT為非Review,而主題詞法在提取已標引MeSH詞匯時有Review的出現,PubMed數據庫在錄入方面存在不一致情況,會對結果產生一定影響。
主題詞法在進行計算時,選取只保留“主題詞”“主題詞/副主題詞”一致即可,把加權符號去除,不考慮加權標引。因考慮到文獻集內不同文章進行加權標引一致情況較少,所以只要文章出現同樣的標引詞即認為一致,可能會對計算結果產生影響。
4 結語
主題詞法和自然語言法可從文本層面計算文檔主題新穎度,兩者各有優勢,自然語言法在計算范圍和最新發表的文獻推薦方面要略優于主題詞法,主題詞法在揭示文章主旨含義方面優于自然語言法。
根據相關性比較,主題詞法和自然語言法在計算文檔主題新穎度方面具有相對等效的價值。新穎度值越高,兩種方法計算出的文檔新穎度值分區越一致。
主題詞法文檔主題新穎度與F1000得分呈弱相關,說明主題詞法的文檔主題新穎度準確性更接近于專家同行評議。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
