SQM:基于Spark的大規模單圖上的子圖匹配算法
2019-08-01 01:35:23李龍洋董一鴻施煒杰潘劍飛
計算機應用 2019年1期
李龍洋 董一鴻 施煒杰 潘劍飛
摘 要:針對大規模數據圖下基于回溯法的子圖查詢算法的準確率低、開銷大等問題,為提高查詢準確率,降低大圖下的查詢開銷,提出一種基于Spark的子圖匹配(SQM)算法。首先根據結構信息過濾數據圖,再將查詢圖分割成基本查詢單元;然后對每一個基本查詢單元分別匹配后進行Join操作;最后運用并行化提高了算法的運行效率,減小了搜索空間。實驗結果表明,與Stwig、TurboISO算法相比,SQM算法在保證查詢結果不變的情況下,速度提高了50%這個“最多”應用的不好,與兩種算法相比,需分別寫明確提高了多少。英文摘要處作相應修改。
關鍵詞:子圖匹配;圖分割;大規模單圖;并行化;Spark
中圖分類號: TP392
文獻標志碼:A
Abstract: Focusing on low accuracy and high costs of backtracking-based subgraph query algorithm applied to large-scale graphs, a Spark-based Subgraph Query Matching (SQM) algorithm was proposed to improve query accuracy and reduce query overhead for large graphs. The data graph was firstly filtered according to structure information, and the query graph was divided into basic query units. Then each basic query unit was matched and joined together. Finally, the algorithms efficiency was improved and search space was reduced by parallelization. The experimental results show that compared with Stwig (Sub twig) algorithm and TurboISO algorithm, SQM algorithm can increase the speed by 50% while ensuring the same query results.
Key words: subgraph matching; graph segmentation; single large-scale graph; parallelization; Spark
0 引言
現實生活中,作為一個重要的數據結構,圖挖掘在社交網絡、Web圖和生物化學領域都有廣泛的應用。子圖匹配是圖挖掘中一個重要的分支,用于從社會網絡中尋找頻繁子圖以揭示節點間的關聯信息,也可以通過計算三角形個數,判定社交網絡的聚集程度。隨著互聯網行業的飛速發展,圖結構的規模不斷擴大。根據國家互聯網信息中心統計[1],截止到2016年12月,中國網民規模7.31億,網站總數為482萬,網頁數達到了2360億,網頁長度總字節數達到了13PB。如何對大規模的單圖模型中的子圖匹配進行有效的分析和處理是目前面臨的嚴峻挑戰。
大量的子圖匹配研究,集中在圖規模較小的數據單圖或圖集[2],大規模單圖上的子圖匹配問題被證明是一個NP(Non-deterministic Polynomial)-hard問題。最經典的算法為Ullmann[3]提出的Ullmann算法,采用深度優先搜索方法依次找出同構子圖,Cordella等[4]提出了VF2算法,該算法在Ullmann算法的基礎上增加了剪枝操作和搜索匹配,提高了算法的運行效率。GraphQL(Graph Query Language)算法[5]根據鄰接狀態和深度信息進行剪枝操作提高算減小法的時間開銷,GADDI(an index based graph matching algorithm in a single large graph請補充GADDI的英文全稱。回復:對于文中GADDI的英文全稱修改為GADDI(an index based graph matching algorithm in a single large graph))算法[6]通過構建鄰接辨別子結構距離來過濾備選節點,兩者都是基于回溯法得到候選子圖來完成子圖匹配工作。張碩等[7]提出的COPESl(COmmon PrEfix tree Subgraph Isomorphism)算法中,提出一種圖集壓縮組織方法,將多個圖結構化地組織起來,并給出一個基于圖挖掘的索引特征生成方法。TurboISO(Towards ultraFast and robust subgraph ISOmorphism)[8]算法通過將查詢圖構建成NEC-Tree(Neighborhood Equivalence Class-Tree)結構形式來減小候選節點范圍,通過進行深度優先搜索匹配,并行性差。這些方法都僅適用于小規模的單圖或圖集,無法滿足大規模數據圖的子圖匹配需求。
近年來,文獻[9-10]使用Map-Reduce思想并行化子圖進行匹配工作,將查詢圖按邊劃分為基本單元,在匹配過程中大量的Join操作以及大規模數據圖的分布不均都導致算法無法在并行環境有效運行。Stwig(Sub twig)[11]運行在微軟圖形數據庫Trinity上,將查詢圖分割為Stwig作為基本查詢單元,然而,大量的Join操作和大規模數據圖的劃分不均勻依然是目前并行算法的瓶頸。
為了克服解決單機算法無法處理大規模單圖,而并行化處理大規模單圖所遇到的大量Join操作和無效匹配的缺點問題,本文提出了一種基于Spark的大規模單圖的子圖匹配(Spark-based Subgraph Query Matching, SQM)算法,主要貢獻如下:1)傳統的子圖匹配算法隨機對查詢圖進行劃分,本文則根據查詢圖節點的度以及各節點在數據圖上的出現頻次,劃分為SubQ(Subgraph Query子查詢)查詢單元進行子圖匹配,同時對原始數據圖進行剪枝操作,過濾不滿足條件的數據圖頂點和邊,并對SubQ查詢單元匹配順序和Join順序進行優化,減少了網絡通信和無效匹配,提出了一種基于Spark的大規模單圖的子圖匹配算法。2)對比實驗顯示,針對不同的查詢圖,在不同的數據集上,SQM算法運行效率都是最高。
1 相關工作
在社交網絡中,實體和實體之間的關系可以使用圖結構表示:對具有特定關系的人或團體的查詢可以轉換為在一個大規模單圖上節點查詢或子圖匹配問題;在生物領域,可以通過已知性質的蛋白質結構的查詢,快速地找出未知結構的蛋白質和基因的結構和性質,為研究生物醫學領域提供技術支持[12]文后的文獻[2]與文獻[12]是同一個文獻,請作相應調整,因為在正文中的引用文獻的順序是依次進行的,所以建議將文獻[2](或[12])改為另外一條文獻,注意彼此間不要再重復了。特別要注意正文中的引用順序和語句調整。。已有的子圖匹配工作可以歸納為四類[12]。
1)無索引結構。最基本的子圖匹配算法Ullmann[23]此處應該是文獻3吧?請明確和VF2[34]這個是指代哪個文獻,請明確。都是無索引結構的子圖匹配算法。Ullmann算法使用深度優先搜索算法進行匹配,而VF2算法在此基礎上增加了剪枝和匹配順序的優化,兩者只適用于規模很小的數據圖。TurboISO[7]算法則是通過使用廣度優先搜索將查詢圖構造成NEC-Tree,在匹配的過程中,使用深度優先搜索的方式進行查詢圖的匹配;但是并行性較差,無法滿足大規模單圖的子圖匹配查詢需求。并行化算法Stwig[11],運行在微軟圖形數據庫Trinity上,將查詢圖劃分為Stwigs基本查詢單元,對每一個Stwigs基本單元分別匹配,最后將其中間結果進行合并操作,GaoZou等[913]文獻9的作者不是Gao,請依照引用順序進行依次調整。提出了并行化解決top-k子圖查詢問題,對數據圖進行近似圖模擬的同時對查詢圖各頂點進行并行化匹配后進行連接操作,大量的Join操作導致算法開銷大,在大規模單圖上無效有效處理。
2)邊/節點索引結構。為了能夠用SPARQL查詢RDF(Resource Description Framework請補充RDF的英文全稱)數據,RDF-3X(for RDF Triple eXpress)[1314]和BitMat (Bit-Matrix)[1415]等算法使用邊作為索引,SPARQL查詢將查詢圖分解為邊,各自匹配后進行連接操作。大量的連接操作使得算法運行效率差,且SPARQL只能表示為查詢圖的子結構,后期仍需合并操作。Hong等[1516]提出了對查詢圖和數據圖節點進行索引,通過節點集合相似和結構相似進行剪枝,而對頂點和結構構建索引時空開銷大,后期需合進行大量的Join操作,無法有效進行匹配。
3)頻繁子圖索引。為了避免大量的Join操作,Yan等[1617]找出頻繁子圖或頻繁查詢子結構后進行頻繁結構索引操作。該類方法的缺點在于找出頻繁子圖的過程是一個時間開銷非常大的操作,而且頻繁子圖數過多,也會帶來索引太大,同時不能進行非頻繁子結構的查詢圖的子圖匹配操作。
4)鄰居索引。GraphQL[4]和GADDI[6]等算法通過找出全局或者局部鄰接來構建索引。對于每一個節點v,GraphQL算法對其構建以v為圓心、半徑為r的子圖索引結構,而GADDI算法則是通過對最短路徑長度小于L的節點進行兩兩組合,構建出索引結構。該類算法需要構建一個復雜的數據結構,時間開銷大,無法在大規模圖上使用。
2 基本概念
3 基于Spark的大規模單圖子圖匹配算法——SQM算法
3.1 內存分布式計算框架——Spark
Spark[1718]是UC Berkeley AMP lab開源的類Hadoop通用的并行計算框架,基于Hadoop MapReduce算法實現分布式計算,核心為彈性分布式數據集(Resilient Distributed Dataset, RDD),是一個容錯的、并行的數據結構,可以讓用戶顯性地將數據存儲到磁盤和內存中,并能控制數據的分區。RDD上主要有Transformation和Action兩種類型的操作,并且當前的RDD都與前一個RDD有依賴關系,Spark在運行作業的過程中會將多個RDD串聯起來形成一個有向無環圖(Directed Acyclic Graph, DAG),可以很好地高效運行,擁有Hadoop所具有的優點;但不同于Hadoop將Job中間輸出和結果保存在HDFS(Hadoop Distributed File System),而將其直接保存在內存中,且除了能夠提供交互式查詢外,它還可以優化迭代工作負載,因此Spark能更好地適用于數據挖掘與機器學習等需要迭代的MapReduce算法[1819]。
3.2 子圖匹配算法—SQM
SQM算法是基于RDD設計,首先將給定的查詢圖分解,劃分為基本查詢單元SubQ的同時對數據圖進行剪枝操作,通過依次匹配得到各自的匹配結果,最后進行Join操作,得到最終的結果。
1)剪枝。
在大規模單圖上進行子圖匹配是一個NP-Hard問題,因此,需要對查詢圖和數據圖作處理才能更好地滿足匹配要求,對于數據圖,根據查詢圖各頂點標簽的度與數據圖相同標簽的頂點的度的對比,將數據圖上相同標簽的頂點的度小于查詢圖上各頂點的度的頂點過濾,并去除頂點標簽不在查詢圖的頂點標簽中。
例1查詢圖如圖1(b)所示,一共有5個標簽:a、b、c、d、e,度分別為2、4、1、2、4。數據圖如圖1(a)所示,包含a、b、c、d、e、f共6個標簽,標簽f對應頂點1006在匹配過程中無效,將其去除,同時,1002頂點對應的標簽b的度為3,而在查詢圖上標簽b所對應的標簽為4,因此1002頂點在匹配過程中無效,將其去除。通過過濾不存在的頂點和數據圖頂點度比查詢圖對應標簽的頂點度更小的頂點,圖2為經過剪枝的數據圖。
2)查詢圖分解。
當查詢圖的頂點數過多,不論深度優先搜索還是廣度優先搜索,時空復雜度都非常大,在大數據集上無法完成。將查詢圖分解,分解成多個子結構,每一個子結構的頂點數少,匹配時時空復雜度則會大幅度降低,因此,對于給定的查詢圖,可以考慮對其進行分割,劃分為多個基本查詢單元SubQ,將其劃分為SubQ的結果如圖3所示。
每一個查詢圖的分解有多種方式,如何制定好的分解策略決定了匹配的時空開銷。給定的查詢圖q,對于每一個頂點v,頂點標簽在數據圖上出現越頻繁,則該節點選擇概率則越低,同時該頂點的鄰接節點數量越多,則該節點優先匹配的概率越大。
根據其在數據圖上的頻率freq(v.tag)和節點的度Deg(v),可以計算出各節點被選擇的概率s(v)=Deg(v)/freq(v.tag)。根據節點選擇概率,找出max(s(v))作為基本查詢單元SubQ的root節點,找出其鄰接節點,將root節點和鄰接節點之間的邊去除,在剩余的節點中找出選擇概率最大的節點u重復以上操作,直到查詢圖中的所有頂點和邊都去除,則分解完成。
對于圖2給定的剪枝后的數據圖G和圖1(b)給定的查詢圖q,首先計算出查詢圖q的各節點(1001,a),(1002,b),(1003,d),(1004,c)和(1005,e)的度分別為Deg(1001)=2,Deg(1002)=4,Deg(1003)=2,Deg(1004)=1,Deg(1005)=1;然后再分別計算出q中各節點的標簽a,b,d,c,e在數據圖中出現的頻繁度freq(a)=2, freq(b)=1, freq(d)=2, freq(c)=1, freq(e)=1。查詢圖q中每一個節點的選擇概率根據計算公式s(v)=Deg(v)/freq(v.tag)分別為1、4、1、1、1,可以看出(1002,b)選擇概率最大,則選擇(1002,b)作為第一個SubQ的root節點,同時得到鄰接節點為(1001,a)、(1003,d)、(1004,c)和(1005,e),將其作為SubQ的child節點,并從查詢圖中去除對應邊(1002,1001),(1002,1003),(1002,1004)和(1002,1005),查詢圖剩余邊為(1001,1003)。1001,1003的選擇概率分別為1,1,則隨機選擇節點(1001,a)作為下一個SubQ的root節點,同時得到其鄰接節點(1003,d)。此時查詢圖q剩余邊為空,劃分完成。最終劃分的結果如圖4所示。
3)匹配操作。
該算法基于RDD操作。在匹配的過程中,對于每一個SubQ,分別在不同的分區上同時匹配。在每一個分區上,不同的查詢單元SubQ之間的匹配順序采用啟發式方法,其原則為:1)如果該SubQ中的某一條邊的兩個節點已被匹配,則優先匹配該邊;2)如果都未匹配,則選擇概率最大的root節點優先匹配。
其偽代碼表示如下。
在匹配過程中,根據各SubQ的產生順序,設置其SubQ的索引為SubQ(i)。首先,根據各SubQ的root節點的選擇概率找出最大的SubQ(i)查詢單元進行匹配,當root節點匹配完成后,再分別匹配其child節點,匹配child節點時根據之前計算的選擇概率從大到小選擇,進一步減少中間結果的計算。當Sub(i)查詢單元匹配完成后,下一個選擇的SubQ(j)優先考慮其root節點在之前的匹配過程中已匹配完成,然后分別匹配其child節點。如此繼續,直到所有SubQ都匹配完成,最終每一個SubQ查詢單元都可以得到其匹配集合。
4)Join操作。
對于每一個查詢基本單元SubQ,通過以上操作完成各自的匹配結果。如果當前結果為中間結果,需要將中間結果進行Join操作,最終得到查詢圖q在數據圖G中的匹配結果。采用不同的Join順序,算法運行時間和空間的不同,需要尋找出一個合適的Join順序來提高算法的運行效率。
采用的Join操作順序如下:
a)計算出每一個基本查詢單元SubQ的匹配個數matchCount和每一個SubQ的child節點的個數chdCount,SubQ的匹配數量越少,剪枝越早,則后期匹配時匹配次數越少,基本查詢單元SubQ的child節點的個數越多,匹配越早。
b)對于SubQ的匹配順序可以按照matchCount/chdCount的比值從小到大進行匹配,匹配時使用Spark的mapPartitions操作使各SubQ的Join過程在各自的分區同時運行,避免了分區之間的通信,提高了算法的運行效率。
4 實驗結果與分析
實驗使用普通PC 14臺,其中1臺為主節點,其余13臺機器為從節點,每臺機器的配置相同:CPU為Core i5,內存為6GB,操作系統為CentOS 6.5,集群環境為基于Hadoop 2.6.5上構建的Spark 1.6.3,運行模式為Spark on Yarn,scala版本為2.10.6,jdk版本為1.8。
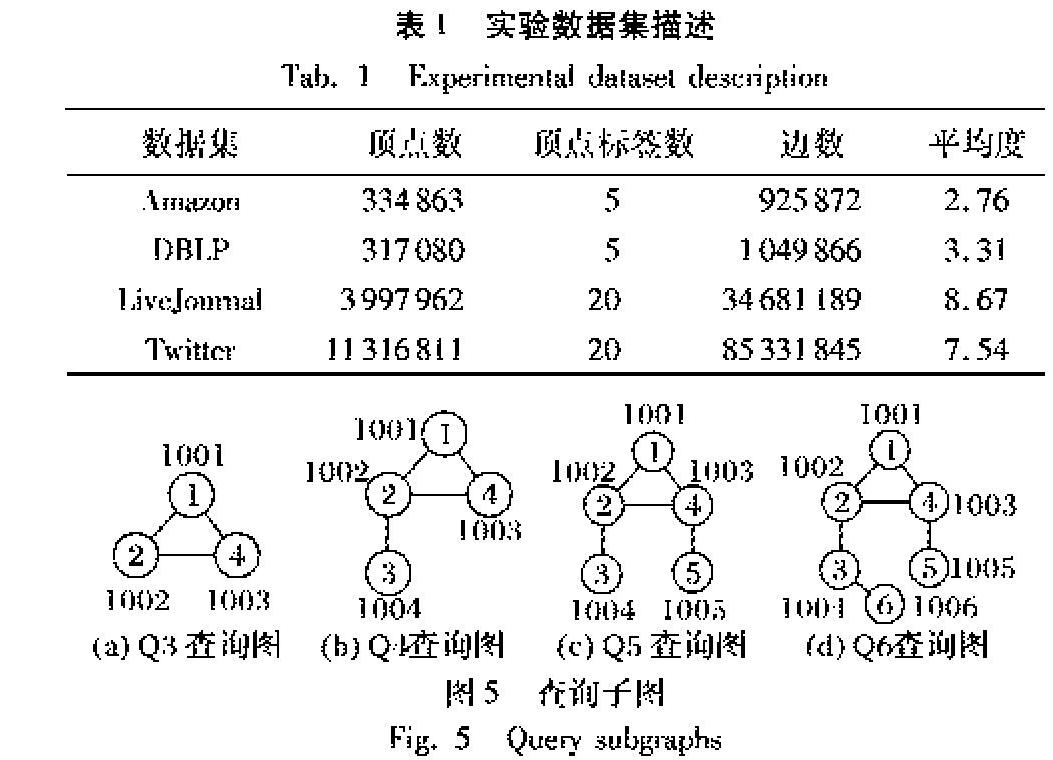
數據集采用的是真實數據集,來自于SNAP[1920]描述信息如下。
Aamzon 亞馬遜上的商品信息,節點表示商品,用邊表示某購物商購買商品u的同時購買商品v,頂點標簽分別表示商品類別,由于原始數據集上并不含有頂點的標簽且圖規模不大,故用5個標簽隨機對頂點進行標記,標簽分布服從高斯分布,為非冪率數據集。
DBLP 該數據集來自于論文作者合作信息,頂點表示作者信息,而頂點標簽則表示作者所屬研究領域,邊則表示某兩個作者之間有過合作,該數據集為冪率數據集,頂點規模不大,頂點的標簽則是通過使用滿足高斯分布的5個隨機數進行標記。
LiveJournal 該數據集來自于LiveJournal社交網絡,頂點表示社交網絡中的人的信息,頂點的標簽則表示為社交網絡中人所屬行業,該數據集中邊的信息表示為社交網絡中兩個人之間有關系。由于原始數據集沒有頂點標簽信息且頂點規模大,用少量的頂點標簽表示所得到的結果過多,因此對其使用服從高斯分布的20個隨機數填充其頂點標簽。
Twitter 該數據集來自于Twitter社交網絡,頂點表示現實生活中的人,頂點標簽表示人所屬類別,而邊則表示兩個人之間有關系,原始的數據集并不包含頂點標簽且頂點規模為千萬級,故使用服從高斯分布的20個隨機數來填充頂點標簽。
數據圖使用表1所示的數據集,查詢圖使用邊數為3,4,5,6的查詢圖,例如圖5所示。
圖5共有4種查詢子圖,邊數分別為3,4,5,6。對于每一個數據集,分別使用這4種查詢圖,每一個都有5個相同邊數的查詢圖,一共20個查詢圖進行實驗,最后運行時間使用平均值。
4.1 SQM算法與其他算法的性能比較
為了評估SQM算法的性能,實驗部分選擇與下列算法進行比較:
1)Stwig算法是文獻[11]中提出的分布式子圖匹配算法,該算法將數據圖保存在微軟Trinity圖數據庫中。
2)TurboISO算法是文獻[7]中提出的算法,該算法為單機子圖同構算法。
本文將這兩種算法都改造成Spark版本,以保證平臺一致性。
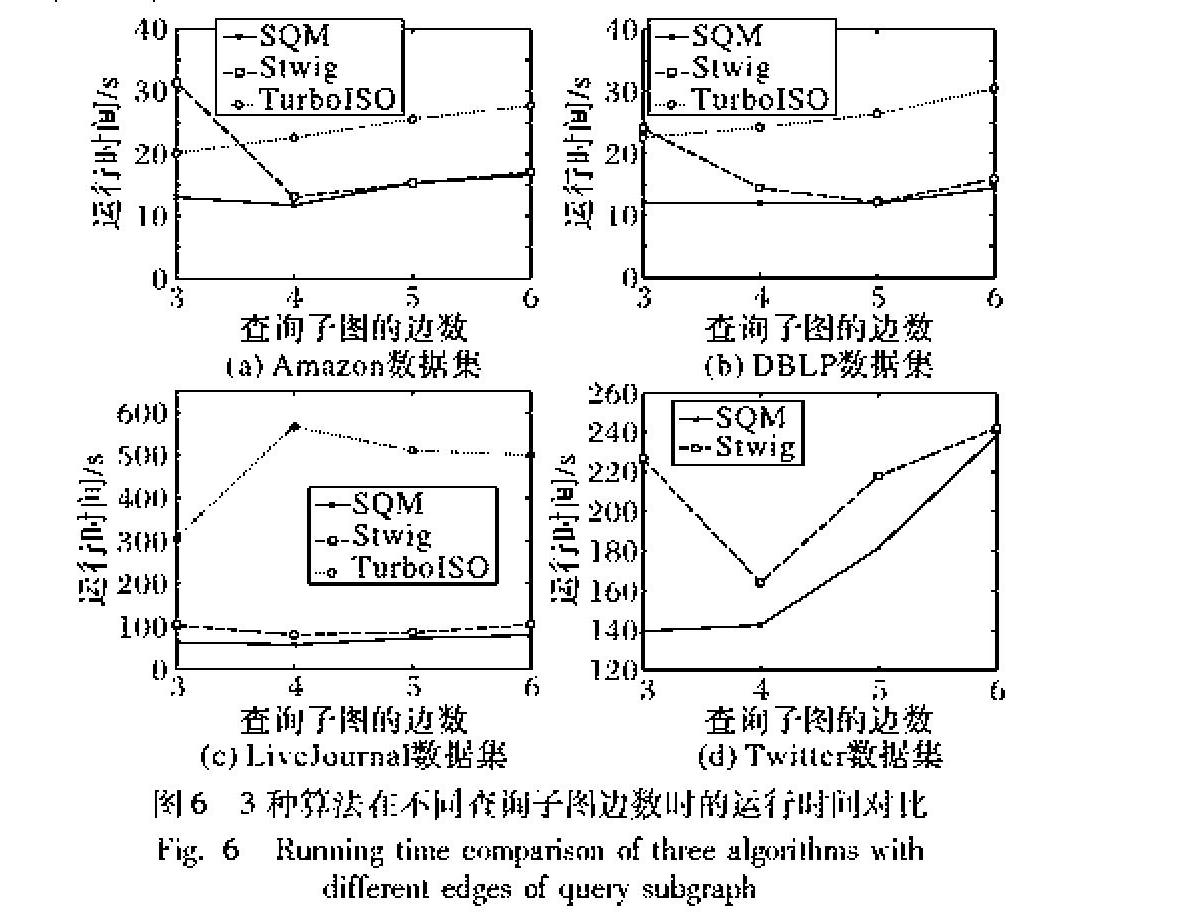
SQM與Stwig算法在不同的數據集上,對比實驗結果如圖6所示。
SQM算法、Stwig算法與TurboISO算法都運行在14臺PC組成的集群上,并行度都設置為14。圖6顯示了SQM算法的運行效率,橫坐標為圖5所示的查詢子圖,橫坐標值為圖5所示的查詢子圖的邊數,縱坐標是算法運行時間。圖6顯示:在Amazon數據集和DBLP數據集上,由于數據量并不是很大,3個算法的運行時間相差不大,SQM算法和Stwig算法運行時間相近,而TurboISO算法運行時間則較長;而在LiveJournal數據集,三種算法運行時間相差大,SQM算法時間開銷最低,Stwig算法次之,TurboISO算法運行效率最低;最后,在Twitter數據集上,TurboISO算法已經無法運行出結果,SQM算法比Stwig算法運行效率高。實驗顯示本文提出的SQM算法運行效率最高,這是因為SQM算法采用了合理的分解機制,將查詢圖分解為基本查詢單元,并進行Join順序優化,減少網絡通信開銷和無效匹配,大幅度提高了查詢的速度。
4.2 不同并行度下SQM算法的性能
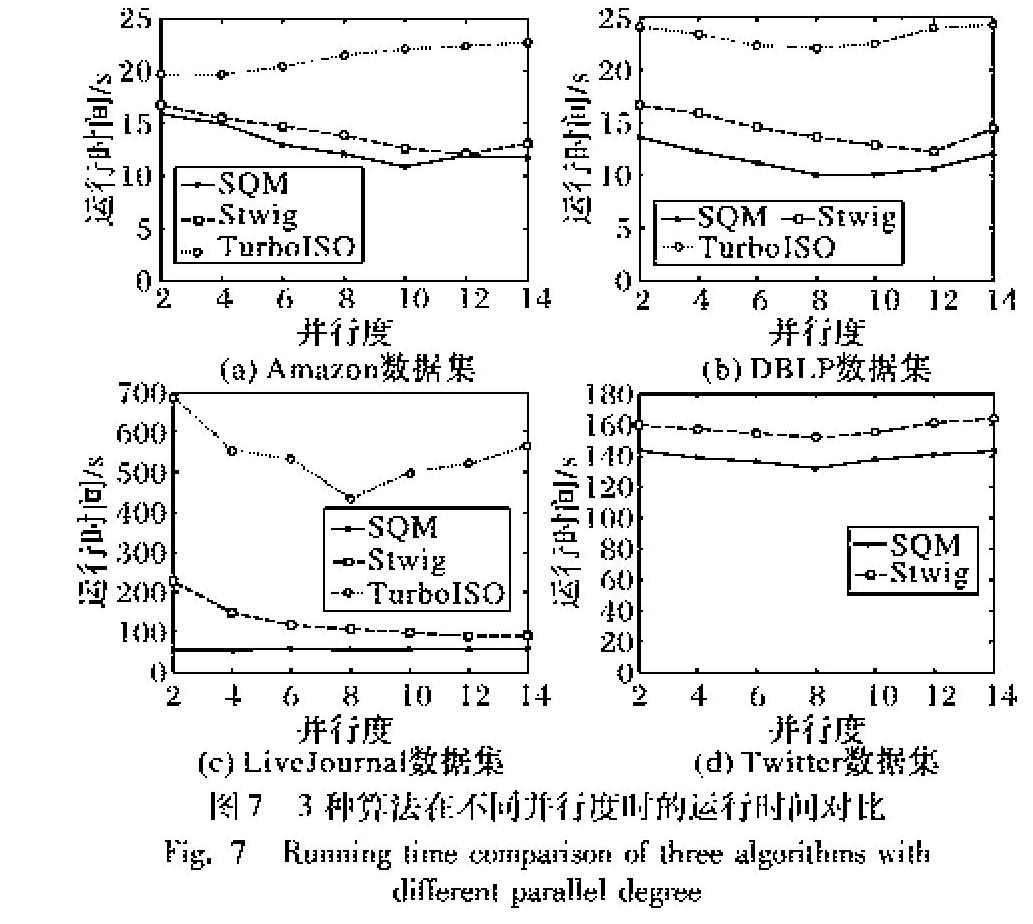
除了比較各查詢圖在不同的數據集下運行時間的對比,本文采用的是基于Spark的分布式環境下子圖匹配算法,需要比較在不同的并行度下各數據集的運行情況來制定一個最優的并行度進行子圖匹配,結果如圖7所示。
圖7中,橫坐標表示并行度,縱坐標表示運行時間。可以看出隨著并行度的增加,在不同的數據集上運行時間都有一個減少到增加的過程,其中的原因是隨著并行度的增加,算法運行效率不斷提高;但是隨著并行度不斷增加,各節點之間的通信開銷也不斷增加。因此,對于每一個數據集,選擇一個合適的并行度可以為多種查詢圖匹配時間進行優化,在子圖匹配過程中先運行一個子圖同構來選擇出最優的并行度,之后針對不同的查詢圖,都使用該最優并行度作為算法運行并行度,使得算法能夠比之前更加優化。圖7中,橫坐標表示并行度,縱坐標表示運行時間,可以看出隨著并行度的增加,在不同的數據集上運行時間都有一個減少到增加的過程,其中的原因是隨著并行度的增加,算法運行效率不斷提高;但是隨著并行度不斷增加,各節點之間的通信開銷也不斷增加,因此,對于每一個數據集,選擇一個合適的并行度可以為多種查詢圖匹配時間進行優化,在子圖匹配過程中先運行一個子圖同構來選擇出最優的并行度,之后針對不同的查詢圖,都使用該最優并行度作為算法運行并行度,使得算法能夠比之前更加優化。
5 結語
本文提出了一個在大規模單圖上進行子圖匹配(SQM)的算法,該算法運行在基于Spark的分布式環境上,可以處理大規模單圖,對于數據圖優先進行一個剪枝操作后根據查詢圖的結構將其分割為基本查詢單元SubQ,各查詢子單元分別匹配后進行Join操作,在進行Join操作時優化了Join操作順序以最大化減小匹配次數,大幅度提升了算法的運行效率。通過真實數據集與其他算法進行了實驗比較,驗證了本文算法的性能。子圖匹配問題作為頻繁子圖挖掘中重要的解決步驟,好的子圖匹配算法可以有效提高頻繁子圖挖掘效率。通過對未知蛋白質和化學結構與已知結構進行比對,可以用于未知蛋白質和化學物質的發現。
參考文獻 (References)
[1] 中國互聯網信息中心.中國互聯網絡發展狀況統計報告[EB/OL].(2017-02-03)[2018-05-20]. http://www.cac.gov.cn/2018zt/cnnic41/index.htm.(China Internet Information Center. Statistical Report on the Development of Chinas Internet. [EB/OL]. (2017-02-03)[2018-05-20].http://www.cac.gov.cn/2018zt/cnnic41/index.htm.)
[2] 于靜,劉燕兵.大規模圖數據匹配技術綜述[J].計算機研究與發展,2015,52(2):391-409.(YU J, LIU Y B. Summary of large-scale graph data matching technology [J]. Journal of Computer Research and Development, 2015, 52(2): 391-409.)
KATSAROU F, NTARMOS N, TRIANTAFILLOU P. Performance and scalability of indexed subgraph query processing methods [J]. Proceedings of the VLDB Endowment, 2015, 8(12): 1566-1577.
文獻2與文獻12是同一個文獻,請作相應調整,因為在正文中的引用文獻的順序是依次進行的,所以建議將文獻2(或12)改為另外一條文獻,注意彼此間不要再重復了。特別要注意正文中的引用順序和語句調整。
[3] ULLMANN J R. An algorithm for subgraph isomorphism [J]. Journal of the ACM, 1976, 23(1): 31-42.
[4] CORDELLA L P, FOGGIA P. A (sub)graph isomorphism algorithm for matching large graphs [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26(10): 1367-1372.
[5] HE H, SINGH A K. Graphs-at-a-time: query language and access methods for graph databases [C]// SIGMOD 2008: Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2008: 405-418.
[6] ZHANG S, LI S, YANG J. GADDI: distance index based subgraph matching in biological networks [C]// EDBT 2009:Proceedings of the 12th International Conference on Extending Database Technology: Advances in Database Technology. New York: ACM, 2009: 192-203.
[7] 張碩,李建中,高宏,等.一種多到一子圖同構檢測方法[J].軟件學報,2010,21(3):401-414.(ZHANG S, LI J Z, GAO H, et al. A multi-to-one subgraph isomorphism detection method [J]. Journal of Software, 2010, 21(3): 401-414.)
[8] HAN W S, LEE J, LEE J H. TurboISO: towards ultrafast and robust subgraph isomorphism search in large graph databases [C]// ICMD 2013: Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2013: 337-348.
[9] AFRATI F N, FOTAKIS D, ULLMAN J D. Enumerating subgraph instances using Map-Reduce [C]// ICDE2013: Proceedings of the 2013 IEEE International Conference on Data Engineering. Piscataway, NJ: IEEE, 2013: 62-73.
[10] PLANTENGA T. Inexact subgraph isomorphism in MapReduce [J]. Journal of Parallel & Distributed Computing, 2013, 73(2): 164-175.
[11] SUN Z, WANG H Z, WANG H X, et al. Efficient subgraph matching on billion node graphs [J]. Proceedings of the VLDB Endowment, 2012, 5(9): 788-799.
[12] 于靜,劉燕兵,張宇,等.大規模圖數據匹配技術綜述[J].計算機研究與發展,2015,52(2):391-409.(YU J, LIU Y B, ZHANG Y, et al. Survey on large-scale graph pattern matching [J]. Journal of Computer Research and Development, 2015, 52(2): 391-409.)
[13] ZOU L, CHEN L, LU Y. Top-k subgraph matching query in a large graph[C]// PIKM 2007: Proceedings of the ACM first Ph. D. Workshop in Sixteenth ACM Conference on Information and Knowledge Management. New York: ACM, 2007: 139-146.
[14] NEUMANN T, WEIKUM G. The RDF-3X engine for scalable management of RDF data [J]. The VLDB Journal, 2010, 19(1): 91-113.
[15] ATRE M, CHAOJI V, ZAKI M J, et al. Matrix “bit” loaded: a scalable lightweight join query processor for RDF data [C]// IW3C2: Proceedings of the 2010 International World Wide Web Conference Committee. New York: ACM, 2010: 41-50.
[16] HONG L, ZOU L, LIAN X, et al. Subgraph matching with set similarity in a large graph database [J]. IEEE Transactions on Knowledge and Data Engineering, 2015, 27(9): 2507-2521.
[17] YAN X, YU P S, HAN J. Substructure similarity search in graph databases [C]// SIGMOD 2005: Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2005: 766-777.
[18] Apache. Spark [EB/OL]. [2018-02-03]. http://spark.apache.org.
[19] CHANG Z, ZOU L, LI F. Privacy preserving subgraph matching on large graphs in cloud [C]// ICMD2016: Proceedings of the 2016 International Conference on Management of Data. New York: ACM, 2016: 199-213.
[20] LESKOVEC J. SNAP [EB/OL]. [2018-03-03]. http://snap.stanford.edu /snappy.
