基于顯著性語義區域加權的圖像檢索算法
2019-08-01 01:35:23陳宏宇鄧德祥顏佳范賜恩
計算機應用 2019年1期
陳宏宇 鄧德祥 顏佳 范賜恩
摘 要:針對計算視覺領域圖像實例檢索的問題,提出了一種基于深度卷積特征顯著性引導的語義區域加權聚合方法。首先提取深度卷積網絡全卷積層后的張量作為深度特征,并利用逆文檔頻率(IDF)方法加權深度特征得到特征顯著圖;然后將其作為約束,引導深度特征通道重要性排序以提取不同特殊語義區域深度特征,排除背景和噪聲信息的干擾;最后使用全局平均池化進行特征聚合,并利用主成分分析(PCA)降維白化得到圖像的全局特征表示,以進行距離度量檢索。實驗結果表明,所提算法提取的圖像特征向量語義信息更豐富、辨識力更強,在四個標準的數據庫上與當前主流算法相比準確率更高,魯棒性更好。
關鍵詞:圖像檢索;卷積神經網絡;深度特征顯著性;語義區域加權;特征聚合
中圖分類號: TP391.413; TP18
文獻標志碼:A
Abstract: For image instance retrieval in the field of computational vision, a semantic region weighted aggregation method based on significance guidance of deep convolution features was proposed. Firstly, a tensor after full convolutional layer of deep convolutional network was extracted as deep feature. A feature saliency map was obtained by using Inverse Document Frequency (IDF) method to weight deep feature, and then it was used as a constraint to guide deep feature channel importance ordering to extract different special semantic region deep feature, which excluded interference from background and noise information. Finally, global average pooling was used to perform feature aggregation, and global feature representation of image was obtained by using Principal Component Analysis (PCA) to reduce the dimension and whitening for distance metric retrieval. The experimental results show that the proposed image retrieval algorithm based on significant semantic region weighting is more accurate and robust than the current mainstream algorithms on four standard databases, because the image feature vector extracted by the proposed algorithm is richer and more discerning.
Key words: image retrieval; Convolutional Neural Network (CNN); deep feature saliency; semantic region weighting; feature aggregation
0 引言
近二十多年來,由于信息時代的到來和發展,各種類型的數據爆炸式地增長,圖像數據也隨之大量積累。為了方便人們對圖像數據的直觀獲取,基于內容的圖像檢索(Content-Based Image Retrieval, CBIR)[1]技術應運而生,給定一個描述特定對象、場景、體系結構的查詢圖像,目的是檢索包含相同對象、場景、體系結構的圖像,這些圖像可能在不同的視角、光照或遮擋下被獲取。
2003年詞袋(Bag-of-Words, BoW)[2]模型被引入圖像檢索領域,這種方法依賴于尺度不變特征變換(Scale-Invariant Feature Transform, SIFT)等傳統特征描述符[3]。“BoW模型”開始在檢索領域發揮著重要的作用,在過去的十多年里,人們提出了許多改進意見。進入2012年,Krizhevsky等[4]與AlexNet在ILSVRC(ImageNet Large Scale Visual Recognition Competition請補充ILSRVC的英文全稱)競賽中取得了最優秀的識別精度,大幅度超過了之前的最佳結果。之后,圖像實例檢索的研究重點開始轉向基于深度學習的方法,特別是卷積神經網絡(Convolutional Neural Network, CNN)。這是一種分層結構,在許多視覺任務中,它的表現優于人工特征,如圖像分類[5]、目標檢測[6]以及語義分割[7]等。在檢索任務中,即使是短的CNN向量,也擁有能夠與BoW模型相競爭的性能。基于CNN的檢索模型通常計算獲取緊湊的表示,并使用Euclidean距離或一些近似最近鄰(Approximate Nearest Neighbor, ANN)[8]搜索方法進行檢索。有些方法是基于全連接層特征生成全局表示[9],例如Neural Codes算法[10]使用降維后的全連接層特征向量,用于圖像檢索。與這些方法不同的是,研究人員開始對全卷積層后的特征更感興趣[11],例如CroW(Cross-dimensional Weighting for aggregated deep convolutional features)算法[12]對全卷積層張量進行加權聚合得到全局表示特征向量,并取得了更好的效果。最近的一些方法通過收集地標建筑物數據集,重新訓練圖像表示端到端的圖像檢索任務[13],例如Deep presentation算法[14]使用孿生網絡結構對圖像通用網絡進行微調提取圖像全局表示。微調過程顯著提高了對特定任務的適應能力;然而這些方法需要收集標記的訓練數據集,性能嚴重依賴于收集到的數據集,并且不同檢索任務需要不同訓練數據集,例如基于地標的微調模型不適用于標識檢索。
最近有多篇論文開始研究CNN特征圖的含義,發現卷積特征圖中的不同通道可以表示為全卷積網絡不同類別的像素級標簽掩碼。Xu等[15]提出PWA(Part-based Weighting Aggregation請補充PWA的英文全稱)算法選擇一些具有鑒別力的深度卷積層的通道作為與固定語義內容相對應的濾波器,稱之為“概率建議(probabilistic proposals)”。“概率建議”將輸入對象各個部分的空間布局編碼為各種語義內容,并表達了屬于固定語義像素的概率。
受到Xu等[15]的啟發,本文提出了一種通過深層卷積特征獲得圖像顯著性區域,優化方差排序的通道選取方法,并通過顯著性區域引導獲取更優的“概率建議”。通過增加無監督顯著性約束,使算法獲取更集中可靠的“概率建議”,從而排除一些復雜背景對于圖像特殊語義信息獲取的干擾,實驗證明針對檢索任務,使用“概率建議”進行區域加權聚合的全局表示更加有效可靠。
1 研究現狀
隨著深度學習領域的火熱,研究人員不再將卷積神經網絡當成一個黑匣子,轉而開始研究卷積神經網絡的真正意義,Zeiler等[16]通過反池化、反激活、反卷積等方法將特征圖(feature map)還原映射到原始輸入圖像空間上來進行特征圖意義的解釋,證明了不同的模式(pattern)可以激活不同的特征圖。Grad-CAM感覺英文全稱不太對,哪幾個單詞的首字符縮寫為CAM的,請明確(Gradient-weighted Class Activation Mapping)[17]使用最后卷積層的梯度信息生成熱力圖,顯示了用于分類等任務下輸入圖像中的重要像素。同樣地在語義分割領域也證明了特征圖可以表示不同標簽的像素級掩碼。在目標檢測領域,SPPNet[18]也通過可視化卷積層的特征圖發現卷積特征中仍舊包含了位置信息,證明了特征圖中不同通道信息被特定的語義信息所激活,這些特殊通道可以作為特定區域檢測子。
隨著目標檢測研究的深入發展,圖像實例檢索任務開始引入目標檢測方法輔助提取前景信息和抑制背景噪聲,BING(BINarized normed Gradients for objectness estimation at 300fps)[19]、Faster R-CNN(Faster Regions with Convolutional Neural Network feature請補充Faster R-CNN的英文全稱)[6]等輔助圖像檢索算法,通過框定原始圖像中的目標信息再進行特征提取和距離檢索。Mask R-CNN[20]研究表明,在目標檢測任務中,應當使用不規則的檢測框替代矩形框,擬合原始目標的形狀。
受上述研究的啟發,本文通過選取卷積特征圖中具有特殊語義和判別力的通道作為圖像的區域檢測子,進而聚合生成與之對應隱藏語義信息的深度特征。這些選取的區域檢測子包含了原始輸入圖像的位置和語義信息,且在形狀上充分擬合了原圖中目標形狀。
2 基于特征顯著性引導的區域加權算法
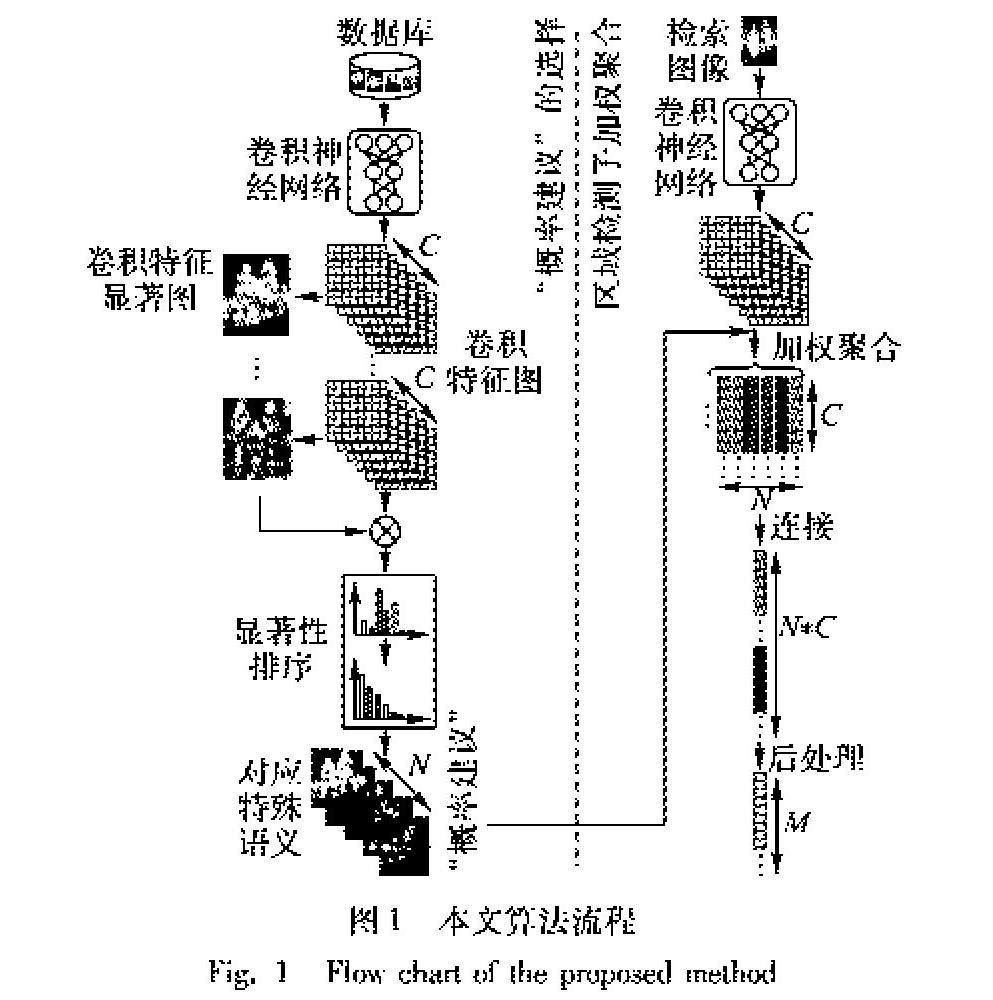
基于深度特征顯著性引導特征通道加權聚合的圖像檢索算法主要包含兩個部分:“概率建議”選擇、區域檢測子加權聚合,算法流程如圖1所示。
1)“概率建議”選擇:
2.1 “概率建議”的選擇
本文通過非監督的方法,對數據庫中所有圖像的深度卷積特征通道進行排序,并選取排序靠前通道作為深度特征的“概率建議”,這些通道對應的特殊語義信息激活圖,作為特征聚合階段的區域檢測子。
2.1.1 深度卷積特征表示
通過將圖像I輸入一個預先訓練好的深度神經網絡或一個經過微調(fine-tuning)后的網絡,提取卷積層的激活圖作為圖像的深度特征,表示為非負三維張量F∈Rh×w×c,其中w和h表示空間分辨率(寬度、高度),c是特征通道的數量。使用Fpj表示深度特征F中對應位置p∈([h],[w])和通道j∈[c]的元素,用F·j表示深度特征F中通道j∈[c]的2D特征圖。
2.1.2 生成深度特征顯著性圖
受到CroW算法的啟發,本文加權深度特征F獲取深度特征顯著性圖。根據逆文檔頻率(IDF)[21]加權的思想,簡單來說不同通道特征圖表現得越稀疏,那么對應位置的非零激活值就越重要。由此得到不同通道對應的F·j權重為:
其中對于通道j∈[c],a=1wh∑p∈P1[Fp·]∈Rc表示為每個通道下平均非零激活值的數目,通過對每個通道求加權和,最終得到深度特征顯著性圖(如圖2):
2.1.3 區域檢測通道選取
每一個“概率建議”對應著原始輸入圖像的特定的語義信息,有一些代表著塔頂信息、建筑底部信息、整體輪廓信息、特定的弧形形狀信息等,這些區域信息包含在深度特征F的特定通道F·j中,本文在離線階段采取一種無監督的方法選取。
PWA算法考慮具備較大方差響應的通道則具有更大的區分性,且各種物體之間的差異越大對應的響應差異越大,所以PWA使用一種簡單的方式來進行區域檢測子的選擇,即通過統計數據庫深度特征對應通道F·j的方差信息并進行排序,選取方差較大的F·j作為“概率建議”。
這種方差排序方法容易受到背景復雜差異大圖片的干擾,導致選取“概率建議”區域檢測子激活原圖的背景信息。為了排除背景信息的干擾,本文改進了方差排序的選取方法,通過得到的深度特征顯著性圖Sf來進行通道顯著性加權和排序。考慮到顯著性圖Sf在某些顯著性區域的激活效果相對于其他顯著性區域過于明顯,為防止顯著性圖和深度特征加權后只激活了部分顯著性區域,影響區域特征的豐富性,需要對顯著性圖Sf進行二值化以區分圖像中的前景區域和背景區域。為了激勵前景信息、抑制背景噪聲信息,二值化顯著性區域為正值v∈R+,非顯著性區域為負值t∈R-:
得到二值后的深度特征顯著性圖Sfb,需要對數據庫中的所有樣本圖片進行深度特征加權求和,并統計歸一化后的深度特征通道重要性。統計單幅圖像深度特征F的通道顯著性加權和:
將數據庫的所有N張樣本圖片進行通道顯著性統計得到通道顯著性向量In=[T0,T1,…,TC-1],并對所有的通道顯著性向量進行2范數歸一化。得到歸一化后的通道顯著性向量后,按通道對所有樣本進行通道顯著性統計疊加:
最后對得到的通道顯著性統計向量Vj=[v0,v1,…,vC-1]的向量進行降序排序,由此可以無監督獲取到顯著性通道,作為“概率建議”以用來進行區域檢測。得到包含特定復雜語義信息的“概率建議”后,利用它們進行深度特征的加權聚合。
圖3可視化了4組排序靠前的“概率建議”,可以觀察到419通道在建筑物窗戶弧形區域有較高的激活、430通道重點激活了建筑物的頂部,相應地486通道則對應建筑物底端,而360通道反映了圖片中建筑物的整體輪廓。算法選取的其他通道同樣地代表著圖像中特殊的結構語義信息。
“概率建議”提取深度特征特定語義信息區域,強化了對應語義的特征信息,挖掘了物體的形狀紋理信息,從而提升了全局表示的判別力及魯棒性。通過大量圖像數據訓練得到的深度卷積網絡,其卷積層包含的不同卷積核可激活特定的圖像模型。本文選取的“概率建議”區域檢測子是根據不同語義信息而生成出的各種不規則區域候選框。對比算法R-MAC(Regional Maximum Activation of Convolution請補充R-MAC的英文全稱)[22]提取的矩形區域,本文使用的“概率建議”區域檢測子對真實物體的形狀更加貼合,且根據語義概率提取的區域位置比R-MAC使用網格切割定位的更加準確,形狀和尺度也都更多樣。本文使用的選取“概率建議”方法,特征顯著引導排序,可以約束選取在重要且豐富語義信息顯著性區域下的“概率建議”。顯著性激活值加權排序算法在顯著性區域中,充分地考慮了不同語義區域的特征,豐富了特征的多樣性。通過對選取通道的大量數據觀察,選取的區域檢測子分別蘊藏了屋頂、塔尖、窗戶、建筑底部、柵欄、石柱等特殊語義信息。
深度特征的聚合需要選取數量合適的“概率建議”作為區域檢測子。如果區域檢測子數量過少,聚合不到足夠豐富的區域特征;如果區域檢測子數量過多,會引入低級(例如梯度、顏色等)特征信息干擾檢索,降低檢索精度。算法最終選取“概率建議”的數量將通過實驗確定。
2.2 區域檢測子加權聚合
將這些通過深度顯著性約束排序算法得到的“概率建議”,作為特殊語義區域特征檢測子,對原始深度特征進行加權,利用全局平均池化聚合得到更加豐富的局部區域特征表示,拼接所有區域特征表示并降維得到最終的全局圖像表示向量,利用距離度量完成檢索任務。
2.2.1 深度特征聚合池化方法
早期利用深度特征的圖像檢索算法,主要使用卷積神經網絡中全連接層后的向量作為圖像全局表示進行檢索,隨著對卷積神經網絡研究的深入,深度特征提取的研究重點則轉向全卷積層后的深度卷積張量上。全卷積結構可以對任意尺寸比例的圖像進行特征提取,保留了原圖特定區域的位置特征屬性。
不同于傳統特征編碼常使用的費舍爾向量(Fisher Vector, FV)編碼和局部聚合描述符(Vector of Aggregate Locally Descriptor, VLAD)編碼,對深度卷積特征的聚合一般使用全局平均池化(Global Average Pooling, GAP)全局最大池化(Global Max Pooling, GMP)[22-23]和全局最大池化(Global Max Pooling, GMP)全局平均池化(Global Average Pooling, GAP)[24]等。
全局平均池化:
全局最大池化:
全局平均池化聚合盡可能地保留了原始深度特征圖的整體信息,弱化了個體的激活信息;相應地全局最大池化則保留特殊的個體激活信息,損失了整體信息。通過區域檢測子加權后的深度特征張量,已經提取了原始深度特征中不同的個體區域激活信息,本文的特征聚合方法只需盡可能保留深度特征的整體信息,因此選取全局平均池化方法進行特征聚合。
2.2.2 區域加權的深度特征聚合
使用選取的W×H維2D“概率建議”對C×W×H維的深度卷積特征進行加權并使用全局平均池化方法聚合特征:
φn=1W×H此處原來為小寫的w×h,為與上面保持一致,改為大寫的,符合表達吧?∑Wx=1∑Hy=1(ωn(x,y)F(x,y))(8)
因子ωn(x,y)原來此處是ωn,感覺不對,為與式(8)中的書寫保持一致,修改為現在,符合表達吧?為根據本文選取“概率建議”對應位置(x,y)激活值vn(x,y)的歸一化權重:
將不同“概率建議”區域檢測子加權聚合得到的局部區域特征向量連接起來作為全局深度特征表示,選取N個“概率建議”區域檢測子,得到對應的局部區域深度特征聚合向量φn,維度為c,簡單地將這些局部區域深度特征聚合向量連接成為用于后續處理需要的全局深度特征聚合向量Φ=[φ1,φ2,…,φN],針對不同的檢索任務可調整選取的“概率建議”個數來平衡算法執行效率和檢索精度。
2.2.3 全局深度特征向量降維白化
全局深度特征向量是通過多個區域檢測子加權聚合的局部深度特征向量連接而來,維度為N×C,鑒于圖像檢索任務的特殊性,需要提取和保存數據庫中所有樣本圖像的全局特征向量,這使得后續相似性度量以及擴展查詢階段的計算效率低、內存消耗代價巨大,因而需要對提取的全局深度特征向量進行主成分分析(Principal Component Analysis, PCA)降維和白化處理[25]。
作為一種常見的降維手段,PCA的思想是將n維特征映射到k維上,且這k維為正交特征,即主元特征。具體地,先尋找方差最大方向作為第一個坐標軸,接著尋找與第一個坐標軸正交且方差最大的坐標軸,依此類推最后得到這k個坐標軸,將原始特征向量投影到這k個坐標軸即得到降維后的k維特征向量,將得到的k維特征向量進行白化,得到最終的檢索特征向量:
其中:Vpca是PCA矩陣,σ1,σ2,…,σk為相關奇異值。
PCA降維舍棄一些冗余維度信息,提高了總體的檢索效果,深度卷積特征聚合中會產生很多不利于圖像檢索的噪聲信息,PCA降維產生去噪的效果,從而提高最終特征向量的判別力和魯棒性。
2.3 拓展查詢
為進一步提升最終檢索精確度,本文增加了拓展查詢(Query Expansion, QE)[26]步驟,在第一次查詢階段,通過計算數據庫中待檢索圖像深度特征向量Φ0與數據庫中所有圖像深度特征向量的空間距離,得到數據庫中排名前t的圖像深度特征向量{d1,d2,…,dt}。對這t個深度特征向量進行均值求和,重新歸一化處理得到新的待檢索圖像深度特征向量表示davg:
將新待檢索圖像深度特征向量davg在數據庫中再進行一次空間驗證查詢,得到最終圖像檢索結果列表。拓展查詢進行了兩次空間驗證,在提升最終檢索準確率的同時帶來了算法時間成本上的開銷。
3 實驗結果
本文將算法在4個標準的實例檢索數據庫上進行:
均值平均精度(mean Average Precision, mAP)[29]作為圖像檢索中重要的評價指標,遵循Oxford數據庫中給出的計算方式。不同檢索圖像對應的數據庫ok和good真值文件中標記的數據庫樣本作為正樣本。對算法得到的檢索序列與正樣本集進行召回率(Precision)和準確率(Recall)的計算,最終計算PR曲線對應的下面積作為AP值,平均所有檢索圖像的AP值得到作為信息檢索評價指標的mAP:
3.1 實驗設置
采用預先訓練好的VGG16[30]網絡進行特征提取,直接將pool5層輸出的feature map作為后續算法使用的深度卷積特征,其中通道數c為512。為證明算法的廣泛性和可靠性,對比實驗了微調后的ResNet101[30]網絡深度特征,通道數為2048。由于只需要網絡的特征提取即全卷積層,輸入原始圖像不需要對尺寸進行縮放或裁剪,直接以原始尺寸進行輸入。對算法參數和算法部件的對比實驗展示均是采用VGG16原始網絡進行特征提取。深度特征顯著圖二值化過程中v取值為1,t取值為-0.6。
3.2 算法參數影響
本文算法包含影響算法效果的超參數,主要體現在選取“概率建議”的個數N、降維的最終特征表示維度M。通過實驗來觀察和討論這些超參數的影響和作用。
本文根據深度特征顯著性約束的通道重要性排序了深度特征的c個通道,這些重要性靠前的通道激活值與原始圖像的特殊語義信息有關,選取前N個通道“概率建議”作為區域檢測子來加權聚合深度特征,實驗結果如表1。
實驗使用全局平均池化聚合,并通過PCA降維至4096維。觀察表1,根據兩個數據庫的整體效果,選擇“概率建議”的個數在20~25效果最佳,僅選取通道重要性前1/20的通道“概率建議”作為區域檢測子,算法達到最佳狀態,與選取所有通道作為區域檢測子相比在兩個標準數據庫上提升2.6個百分點,且計算復雜度也僅為選取所有通道的1/20,證明了排序算法的優異效果。在達到最優狀態后隨著選取的區域探測子增多效果反而下降,由于深度卷積特征中不同的通道不僅含有一些有利于圖像檢索的圖像前景特殊語義信息,也具有例如背景光照、背景紋理等一些冗余甚至是不利于圖像實例檢索的語義內容,這也驗證了通道排序算法篩選了圖像前景中高判別力的語義區域。只需選取1/20的“概率建議”進行區域檢測加權聚合,這極大地節省深度特征提取階段的計算量和內存消耗。
針對全局平均池化和全局最大池化方法在第2章進行了理論上的分析,考慮到區域檢測子提取了深度特征的個體區域信息,算法選擇使用全局平均池化方法,并與全局最大池化方法進行對比,檢索效果如表2所示。
觀察表2結果,使用全局平均池化方法要比全局最大池化的檢索效果更優秀。實驗選取25個區域檢測子并通過PCA降維至4096維度。使用全局平均池化方法的mAP相比全局最大池化方法在Oxford和Paris數據庫上可以總體帶來8.15個百分點的提升分別有4.43和3.72個百分點的提升。
在圖像實例檢索任務中,數據庫圖像對應的最終圖像表示Φpca是檢索系統的最終端,在實際應用中,需要存儲數據庫中每一幅圖像的全局表示,檢索過程中也是對圖像的全局表示進行相似性度量,所以圖像檢索任務的內存消耗和效率都直接與最終圖像表示Φpca的維度M有關。表3是本文選取不同PCA最終降維維度的結果。
觀察表3不難發現在維度128~4096中保持維度越大圖像檢索的效果越好的特點,即檢索效果與內存消耗成反比。這可以理解為維度越大在經歷PCA降維后留下來的主成分分量越多,包含具有分辨力的特征信息就越多,最終的檢索效果就越好。與早期使用傳統特征的詞袋模型上萬維度相比,這樣是深度特征模型的優勢,深度特征代表了更高層次的語義信息而不是圖像底層的顏色、梯度等圖像基本特征。對于Paris6K數據庫的實驗結果,2048維度的mAP值與4096維相比更高一些,一定程度上反映了PCA降維算法的作用以及本文“概率建議”通道選取的可靠性。與其他固定維度的深度特征算法相比,本文算法提供了最終PCA降維維度的選擇,可以根據不同數據庫、不同任務需求來選擇最終圖像表示維度,具有很大的靈活性。
區域檢測子選取數量N與維度M的最佳狀態是相互影響的,特征維度M越小,對區域檢測子的語義顯著性要求越高,最佳“概率建議”通道數N也越小;反之,特征維度M越大,對區域檢測子的語義多樣性要求越高,最佳“概率建議”通道數N也就越大。
3.3 與主流算法對比
在現有未進行任何微調的VGG16卷積神經網絡框架下,本文算法與當前一些主流算法結果進行比較,對比全局特征向量維度為512維下的結果(如表4~5),本文算法的mAP值,與當前的主流算法PWA[15]“主流算法”指代不清晰,需指明哪個文獻算法?是“PWA[15]算法”嗎?請明確。相比在Oxford5K上提升了1.4個百分點,在Paris6K上提升了0.5個百分點。本文算法維度提升至4096維度,最終在Oxford5K上提升了0.5個百分點,在Paris6K上提升了0.8個百分點。與Tri-embedding、FAemb、RVD-W這些傳統的“BoW模型”方法相比,本文算法在提升檢索的準確率的同時,對空間和時間消耗也大幅度降低。本文算法的深度特征語義加權聚合與R-MAC、SPoC、CroW等算法相比,充分考慮了語義區域的不規則性以及顯著性區域的重要性。
算法通過加入擴展查詢等后處理手段來提升整體算法效果,本文算法在QE=10時檢索效果有了大幅度提升。512維度情況下在Oxford5K和Paris6K數據庫上共提升了3.3個百分點分別提升了1.6和1.7個百分點這個描述不清晰,需指明是分別提升了哪兩個百分點(需兩個數值)。,對比PWA算法,本文算法通過改進該算法的通道排序算法和深度特征聚合算法在四個主流數據庫上的表現均有明顯提升。在維度較低情況下,Paris106K數據庫上的表現在使用擴展查詢前后相比當前主流算法效果稍差一些,考慮是由于加入的10K100K數據庫中的圖像背景較為豐富,算法在選取顯著性語義區域而忽略了背景信息,導致在顯著前景特征維度不足的情況下,背景信息特征也具有較強的分辨力。
本文對使用微調后的ResNet101網絡進行相同的對比實驗,比較當前主流算法使用微調或端到端訓練的圖像檢索網絡的檢索效果。與文獻[15]中使用的方法一致,本文也根據文獻[14]端到端訓練的方法對ResNet101進行微調,并提取res5c_relu層的輸出最為原始圖像的深度特征,其中通道數c=2048。對比當前主流算法NetVLAD(Network with Vector of Locally Aggregated Descriptors layer)、CNNBoW(CNN image retrieval learns from BoW)、DeepRepresentation(learning Deep Representations for image search請補充NetVLAD、CNNBow、DeepRepresentation的英文全稱)等,本文算法在進行過微調后的網絡結構中效果同樣要優于這些主流的進行過訓練的方法。
4 結語
本文在PWA算法的基礎上提出了全新無監督基于深度卷積特征顯著性約束的通道重要性排序算法,優化選取“概率建議”步驟。本文使用的區域探測子更加符合語義顯著性,所提取聚合的特征向量更加豐富,在特征維度被降到較低維度時效果也十分優秀。在特征聚合階段使用全局平均池化相比全局最大池化提高了聚合后特征向量的判別力,在各種維度情況下效果均提升明顯。本文提出的無監督算法不依賴于深度神經網絡的狀態,不論基于現有的通用圖像特征提取網絡,還是基于特殊環境和任務微調后的網絡,都可以進行語義加權的特征聚合以供圖像檢索使用。
參考文獻 (References)
[1] ZHENG L, YANG Y, TIAN Q. SIFT meets CNN: a decade survey of instance retrieval [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(5): 1224-1244.
[2] 董健.基于加權特征空間信息視覺詞典的圖像檢索模型[J].計算機應用,2014,34(4):1172-1176.(DONG J. Visual vocabulary with weighted feature space information based image retrieval model [J]. Journal of Computer Applications, 2014, 34(4): 1172-1176.)
[3] LOWE D G. Distinctive image features from scale-invariant key-points [J]. International Journal of Computer Vision, 2004, 60(2): 91-110.
[4] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [C]// Proceedings of the 25th International Conference on Neural Information Processing Systems. New York: ACM, 2012: 1097-1105.
[5] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 770-778.
[6] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 39(6): 1137-1149.
[7] 姜楓,顧慶,郝慧珍,等.基于內容的圖像分割方法綜述[J].軟件學報,2017,28(1):160-183.(JIANG F, GU Q, HAO H Z, et al. Survey on content-based image segmentation methods [J]. Journal of Software, 2017, 28(1): 160-183.)
[8] ARYA S, MOUNT D M, NETANYAHU N S, et al. An optimal algorithm for approximate nearest neighbor searching fixed dimensions [J]. Journal of the ACM, 1998, 45(6): 891-923.
[9] 劉兵,張鴻.基于卷積神經網絡和流形排序的圖像檢索算法[J].計算機應用,2016,36(2):531-534.(LIU B, ZHANG H. Image retrieval algorithm based on convolutional neural network and manifold ranking [J]. Journal of Computer Applications, 2016, 36(2): 531-534.)
[10] BABENKO A, SLESAREV A, CHIGORIN A, et al. Neural codes for image retrieval [C]// Proceedings of the 2014 European Conference on Computer Vision. Berlin: Springer, 2014: 584-599.
[11] RAZAVIAN A S, AZIZPOUR H, SULLIVAN J, et al. CNN Features off-the-shelf: an astounding baseline for recognition [C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2014: 512-519.
RAZAVIAN A S, SULLIVAN J, CARLSSON S, et al. Visual instance retrieval with deep convolutional networks [J]. ITE Transactions on Media Technology and Applications, 2016, 4(3): 251-258.
[12] KALANTIDIS Y, MELLINA C, OSINDERO S. Cross-dimensional weighting for aggregated deep convolutional features [C]// Proceedings of the 2016 European Conference on Computer Vision. Berlin: Springer, 2016: 685-701.
[13] RADENOVIC F, TOLIAS G, CHUM O. CNN image retrieval learns from BoW: unsupervised fine-tuning with hard examples [C]// Proceedings of the 2016 European Conference on Computer Vision. Berlin: Springer, 2016: 3-20.
[14] GORDO A, ALMAZN J, REVAUD J, et al. Deep image retrieval: learning global representations for image search [C]// Proceedings of the 2016 European Conference on Computer Vision. Berlin: Springer, 2016: 241-257.
[15] XU J, SHI C, QI C, et al. Unsupervised part-based weighting aggregation of deep convolutional features for image retrieval [C]// AAAI 2018: Proceedings of the 35th AAAI Conference on Artificial Intelligence. Menlo Park, CA: AAAI, 2018: 7436-7443.
[16] ZEILER M D, FERGUS R. Visualizing and understanding convolutional networks [C]// Proceedings of the 2014 European Conference on Computer Vision. Berlin: Springer, 2014: 818-833.
[17] SELVARAJU R, COGSWELL M, DAS A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2017: 618-626.
[18] HE K, ZHANG X, REN S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition [C]// Proceedings of the 2014 European Conference on Computer Vision. Berlin: Springer, 2014: 346-361.
[19] CHENG M M, ZHANG Z, LIN W Y, et al. BING: binarized normed gradients for objectness estimation at 300fps [C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2014: 3286-3293.
[20] HE K, GKIOXARI G, DOLLR P, et al. Mask R-CNN [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2017: 2980-2988.
[21] BEEL J, GIPP B, LANGER S, et al. Paper recommender systems: a literature surveyResearch-paper recommender systems: a literature survey [J]. International Journal on Digital Libraries, 2016, 17(4): 305-338.
[22] TOLIAS G, SICRE R, JGOU H. Particular object retrieval with integral max-pooling of CNN activations [EB/OL]. (2016-02-24) [2018-05-21]. https://arxiv.org/abs/1511.05879.
[23] RAZAVIAN A S, SULLIVAN J, CARLSSON S, et al. Visual instance retrieval with deep convolutional networks [J]. ITE Transactions on Media Technology and Applications, 2016,4(3): 251-258.
RAZAVIAN A S, SULLIVAN J, MAKI A, et al. A baseline for visual instance retrieval with deep convolutional networks [EB/OL]. (2016-05-09)[2018-05-21]. https://arxiv.org/abs/1511.05879.
[24] BABENKO A, LEMPITSKY V. Aggregating local deep features for image retrieval [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2015: 1269-1277.
[25] JGOU H, CHUM O. Negative evidences and co-occurences in image retrieval: the benefit of PCA and whitening [C]// Proceedings of the 2012 European Conference on Computer Vision. Berlin: Springer, 2012: 774-787.
[26] CHUM O, MIKULIK A, PERDOCH M, et al. Total recall II: query expansion revisited [C]// Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2011: 889-896.
[27] PHILBIN J, CHUM O, ISARD M, et al. Object retrieval with large vocabularies and fast spatial matching [C]// Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2007: 1-8.
[28] PHILBIN J, CHUM O, ISARD M, et al. Lost in quantization: improving particular object retrieval in large scale image databases [C]// Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2008: 1-8.
[29] EVERINGHAM M, GOOL L V, WILLIAMS C K I, et al. The Pascal Visual Object Classes (VOC) challenge [J]. International Journal of Computer Vision, 2010, 88(2): 303-338.
[30] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [EB/OL].(2015-04-10)[2018-05-21]. https://arxiv.org/abs/1409.1556.
[31] JGOU H, ZISSERMAN A. Triangulation embedding and democratic aggregation for image search [C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2014: 3310-3317.
JGOU H, ZISSERMAN A. Triangulation embedding and democratic aggregation for image search [C]// Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2014: 3310-3317.
[32] DO T T, TRAN Q D, CHEUNG N M. FAemb: a function approximation-based embedding method for image retrieval [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2015: 3556-3564.
[33] HUSAIN S, BOBER M. Improving large-scale image retrieval through robust aggregation of local descriptors [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39 (9): 1783-1796.
[34] XIE L, ZHENG L, WANG J, et al. Interactive: Inter-layer activeness propagation [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 270-279.
[35] ARANDJELOVIC R, GRONAT P, TORII A, et al. NetVLAD: CNN architecture for weakly supervised place recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 5297-5307.
