基于數據內在特性和LSTM的用電數據異常檢測算法研究
2019-08-06 13:48:19吳剛
無線互聯科技 2019年10期
吳剛


摘? ?要:為解決現有用電數據異常檢測算法準確率低的問題,首先,文章分析了用戶用電數據具有時間關聯特性、高維度特性,且容易受外部因素影響等特性。其次,基于數據內在特性和LSTM理論,提出了基于數據內在特性和LSTM的用戶用電數據異常檢測算法。該算法采用有放回的構造數據集策略,構造K個數據集合,采用4層LSTM網絡,實現高維數據特征提取,利用兩層全連接的隱含層組成的神經網絡,實現用戶特征數據匹配,采用大概率事件將K個數據集的結果中出現最多的分類作為該節點的分類。通過實驗,驗證了文章算法比傳統算法好,提高了準確率,降低了誤報率。
關鍵詞:大數據;異常檢測;深度學習;LSTM
1? ? 大數據和人工智能背景下的電力數據采集
隨著社會經濟快速發展,電力資源在人民群眾的日常生活中發揮的作用越來越重要。但是,個別用戶為了減少電力資源費用的支出,通過竊電、欺詐等欺騙手段進行偷電,給電力公司造成了嚴重的經濟損失。為解決此問題,電力公司已經采取了較多的措施進行檢查和整改,并且取得了一定的效果[1-2]。智能電網技術的快速發展,為用電數據異常分析提供了新的研究手段。在大數據電力設備采集下的用戶用電數據更加豐富、數據量更加龐大[3]、存儲設備和網絡通道的資源更加豐富[4]。例如,史玉良等[5]提出了傳統數據庫和MongoDB數據庫相融合的電力用戶數據存儲體系架構,實現了電力用戶數據的可擴展性存儲。
在此背景下,基于大數據和人工智能技術的用電數據異常檢測研究已成為當前的研究熱點和研究趨勢。根據研究采用的工具和方法不同,可以分為以下3類。(1)基于統計學理論知識進行異常用電數據挖掘研究,盛立锃等[6]將多項式擬合技術應用到異常用電數據檢測當中,有效地解決了用電量預測效率低的問題。Bianco等[7]分析了用電數據的內在特點和關聯關系,將用戶用電數據檢測問題轉換為線性回歸問題進行求解,提高了用戶用電數據檢測的準確率。Pappas等[8]、Wang等[9]分析了時間序列理論和自回歸理論,提出了自回歸移動模型,有效解決了季節變化對用戶用電異常檢測產生的負面影響。(2)基于數學建模與專家系統相結合的用電異常檢測研究,Arisoy等[10]基于電力公司長期運營的專家知識,對用電數據的時間關聯關系進行了數學建模,實現了用戶異常用電量的檢測,并通過仿真實驗,驗證了算法提高了檢測效率和性能。李亞等[11]將電力數據建模為聚類模型,基于專家知識分析,提出改進K-means聚類和反向傳播(Back Propagation,BP)神經網絡的臺區線損率算法,有效提高了用戶用電數據的線損率分類性能。石幫松等[12]從經濟學的視角,將電力用戶數據建模為博弈模型,從經濟學理論方面,研究了用電數據的特性。(3)基于深度學習等人工智能理論進行數據分析。Zhang等[13]、趙文清等[14]基于循環神經網絡理論和長短期記憶網絡理論,提出基于深度學習的用戶用電數據分析,有效提高了數據分析結果的準確率。許元斌等[15]分析了單一聚類算法在電力用戶數據分析時性能低的問題,提出了基于K-means和Canopy的雙聚類智能檢測算法,并通過實驗驗證了算法的運行效率。
基于上述分析可知,用戶用電數據異常檢測研究已經取得了較多研究成果。但是,當前研究主要集中在解決異常用電數據檢測的性能方面的問題。隨著電力用戶數據和用電設備地快速增長,用戶用電數據的維度和數據量也快速增加,導致現有用電數據異常檢測算法性能低的問題。為解決此問題,本文分析了用戶用電數據具有時間關聯特性、高維度特性,提出了基于數據內在特性和長短期記憶網絡(Long Short-Term Memory,LSTM)的用戶用電數據異常檢測算法。通過實驗,驗證了本文算法比傳統算法好,提高了算法性能。
2? ? 電力公司目前面臨的問題
在大數據環境下,電力公司可以通過網管系統采集和存儲的數據類型更加多樣,數據保存時間更長。這對于用戶用電異常數據檢測提供了豐富的數據資源。通過對長時間段內數據的關聯關系進行分析可知,不同用戶電力數據之間存在相似性,同一用戶在不同時間段內的數據也存在相關性。例如,某一個居民在未來幾天的用電量與當前時間的用電量類似和相關。居民的用電數據也具有一定的周期性和規律性。例如,每個月的用電數據量與之前月份或往年同期月份具有一定的相關性。此外,用戶的用電量與天氣、節假日等外部環境關系也比較緊密。
從上述分析可知,在進行用電量分析時,如果能夠同時對一個長時間段內的數據進行分析,將有助于通過用戶用電量的關聯關系,分析用戶用電數據之間的時序關系,有效挖掘用戶用電的異常數據。本文以378天為時間周期,選取了某省電力用戶的用電數據進行異常數據檢測。數據信息包括用戶ID、年月日、用電量等字段數據。
3? ? 數據準備和優化
3.1? 數據預處理
為提高數據質量,減少數據重復和數據缺失等錯誤導致的檢測算法性能低的問題,在執行檢測算法之前,對數據進行了預處理。其中,對于重復數據,采取刪除策略進行處理。對于缺失數據和錯誤數據,首先,建立數據字段的上限值和下限值。其次,從上下限區間采用隨機選擇的辦法進行填補。最后,對所有數據字段進行歸一化處理,避免不同字段取值范圍的區別導致的數據質量問題。歸一化處理采用公式(1)進行處理。其中,X={x1,x2,…,xn}表示包含n個數據的向量。mean(X)表示求解X的平均值。max(X)表示X的最大值。min(X)表示X的最小值。X'i表示對Xi執行歸一化之后得到的數據。
3.2? 生成K個數據集合
隨著存儲設備和存儲技術的豐富和成熟,電力公司存儲的用戶用電數據量爆發式增長,這些數據資源對用電異常檢測提供了豐富的資源。通過對已有的用電異常檢測研究分析可知,過擬合問題是一個常見問題。為了減小過擬合問題對檢測結果的影響,本文在生成測試集和訓練集的過程中,采用有放回的構造數據集的策略,構造K個數據集合,提高數據集合的隨機性。在選取K個數據集合之后,將其中90%的數據作為訓練集進行訓練,將剩余的數據作為測試集進行測試。
如果同時對一個較長時間段內的數據進行分析,需要檢測算法具備處理高維數據的能力。針對此問題,下一步將基于LSTM理論,提出能解決高維數據的異常數據檢測算法。充分挖掘隱含在高維數據中的關鍵特征,挖掘出的關鍵特征越多,檢測算法的檢測性能越好,將越有利于提出更加優化的檢測算法。
4? ? 基于數據內在特性和LSTM的用電數據異常檢測算法
4.1? 算法流程
基于數據內在特性和LSTM的用電數據異常檢測算法流程如圖1所示,包括5個過程。
(1)數據預處理:對于重復數據、缺失數據和錯誤數據進行清洗,采用歸一化處理方法,對數據實現歸一化處理。
(2)生成K個數據集合:采用有放回的構造數據集的策略,構造K個數據集合,提高數據集合的隨機性。
(3)對K個數據集進行特征提取:對于每個數據集,基于用電特性的4層LSTM算法,從378個特征中提取32個數據的內在關鍵特征。
(4)對K個數據集進行特征匹配:對于每個數據集,采用3層全連接層進行竊電識別,直到損失函數達到閾值,輸出2維的數據分布。
(5)求解數據集中數據的最佳分類:采用大概率事件,將K個數據集的結果中出現最多的分類作為該節點的分類。
4.2? 特征提取
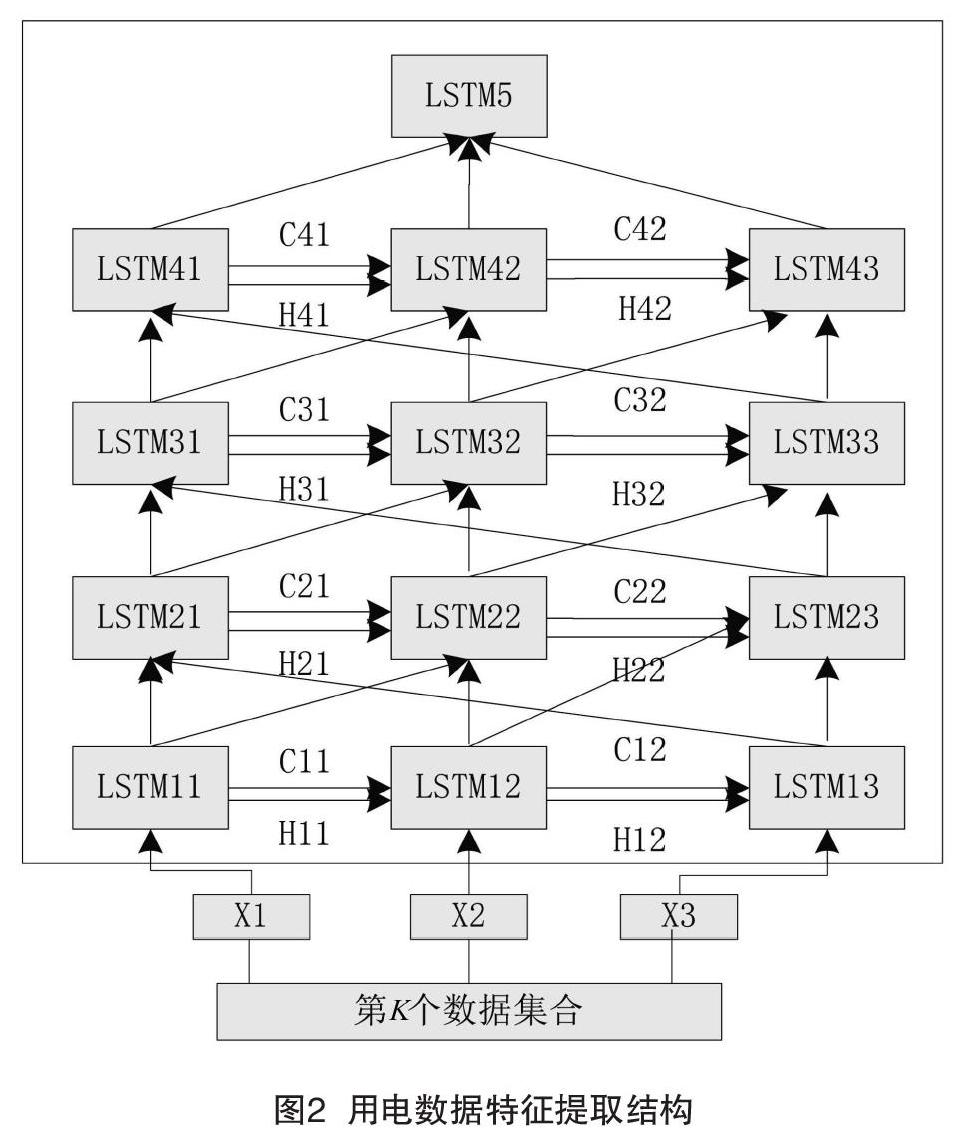
由于LSTM網絡具備記憶功能,可基于時間關系關聯電力用戶數據,本文的特征提取模塊由多個長短期記憶塊連接組成,其結構如圖2所示。首先,將第K個數據集合劃分為3個數據子集作為輸入。其次,4層LSTM構成的特征提取模型對特征進行提取。
從用電特性角度分析可知,用電與溫度、節假日影響較大,考慮到春、夏、秋、冬4個季節,清明節、中秋節、端午節、元旦、五一、國慶節、春節7個關鍵節日,所以,本文在4層LSTM網絡實現特征提取時,將用電特征設置為32。對于每個LSTM網絡模塊,包括輸入門、遺忘門、輸出門3種門。其中,輸入門用于接收用戶用電數據xt和上一個時刻的輸出ht-1,輸入值z使用公式tanh(Wz[ht-1,xt])計算。輸入門的取值i使用sigmoid(Wt[ht-1,xt])進行計算。遺忘門的取值f使用公式sigmoid(Wf[ht-1,xt])進行計算。輸出門的取值o使用公式sigmoid(Wo[ht-1,xt])進行計算。基于此,LSTM網絡模塊的新狀態取值ct使用公式(2)進行計算,每個LSTM網絡模塊的輸出值ht使用公式(3)進行計算。
4.3? 特征匹配
為完成數據類型的標注,本文利用一個由2層全連接的隱含層組成的神經網絡實現用戶特征數據的匹配工作。該特征匹配模型中,輸入層輸入數據為特征提取獲得的32維數據。為提高算法的性能,本文使用均方差損失函數,對神經網絡的參數進行調整。均方差損失函數使用公式(4)進行計算。其中,yi表示特征匹配模塊的分類結果,表示用戶用電數據的真實分類結果,N表示特征匹配模塊分類的用電數據的數量。
4.4? 求解數據集中數據的最佳分類
考慮到K個數據集的特征配匹結果存在差異,不便于決定最優的分類結果。本文基于隨機森林算法求解數據最佳分類的方法,最終的分類結果采用概率事件進行計算,即對于每個用電用戶數據,將K個特征配匹結果中相同分類最多的類型作為最終的分類。
5? ? 性能分析
為了生成數據集,本文選取某省95 389個用電用戶的378天的電量數據,其中,異常數據3 528條,其余為正常數據。本文算法中K取值為[3,9],步長為2。在進行實驗時,為了防止正常數據和異常數據不均衡影響算法性能,在構造訓練數據時,對正常數據進行欠采樣,減小正常數據與異常數據的不均衡差距。實驗中,共生成10個數據集,每個數據集進行10次實驗,最終結果取平均值。
實驗中,首先,分析了K取值對算法性能的影響。其次,為了驗證本文所提模型的有效性,與傳統的機器學習算法支持向量機(ADoSVM)、使用單個數據集合算法(ADoIL-oneD)進行對比實驗。
首先,K取值為3,5,7,9時算法性能如圖3—4所示。隨著K取值增加,算法的準確率逐漸增加,誤報率逐漸降低。當K取值為9時,算法性能出現下降。實驗結果說明,K取值為7時,算法性能比較優化。
下面以K取值為7的情況下,與傳統的機器學習算法支持向量機(ADoSVM)、使用單個數據集合算法(ADoIL-oneD)進行對比實驗。算法性能如圖5—6所示。算法ADoIL-7和算法ADoIL-oneD兩種算法的準確率都高于算法ADoSVM,誤報率都低于算法ADoSVM,說明本文算法提出的異常檢測算法優于傳統的機器學習算法。另外,算法ADoIL-7的性能優于算法ADoIL-oneD,說明多數據集減小了過擬合問題對算法性能的影響,有助于求解最佳的分類結果,提高了異常檢測算法的檢測性能。
6? ? 結語
電力資源在人民群眾的日常生活中發揮的作用越來越重要。但是以竊電、欺詐等欺騙手段進行的偷電行為給電力公司造成了嚴重的經濟損失。用戶用電數據異常檢測研究對于電力公司的正常運營變得更加重要。為解決此問題,本文分析了用戶用電數據具有時間關聯特性、高維度特性,提出了基于數據內在特性和LSTM的用戶用電數據異常檢測算法。通過實驗,驗證了本文算法比傳統算法提高了算法性能。下一步工作中,將對該模型進行優化,基于遷移學習理論,生成通用性較強的模型,降低模型對運算環境的要求,提高算法的實用性。
[參考文獻]
[1]雷煜卿,李建岐,侯寶素.面向智能電網的配用電通信網絡研究[J].電網技術,2011(12):14-19.
[2]ULUDAG S,LUI K S,REN W,et al.Secure and scalable data collection with time minimization in the smart grid[J].IEEE Transactions on Smart Grid,2016(1):43-54.
[3]屈志堅,陳閣.容錯存儲的電力系統監測數據查詢優化技術[J].電網技術,2015(11):3221-3227.
[4]葛磊蛟,王守相,瞿海妮.配用電大數據存儲架構設計[J].電力自動化設備,2016(6):194-202.
[5]史玉良,王相偉,梁波,等.基于MongoDB的前置通信平臺大數據存儲機制[J].電網技術,2015(11):3176-3181.
[6]盛立锃,曾喆昭,李莎.基于代數多項式模型的用電量預測研究[J].電力科學與技術學報,2015(1):34-40.
[7]BIANCO V,MANCA O,NARDINI S.Linear regression models to forecast electricity consumption in Italy[J].Energy Sources Part B Economics Planning&Policy,2013(1):86-93.
[8]PAPPAS S S,EKONOMOU L,KARAMOUSANTAS D C,et al.Electricity demand loads modeling using Auto Regressive Moving Average(ARMA)models[J].Energy,2008(9):1353-1360.
[9]WANG Y,WANG J,ZHAO G,et al.Application of residual modification approach in seasonal ARIMA for electricity demand forecasting:a case study of China[J].Energy Policy,2012(3):284-294.
[10]ARISOY I,OZTURK I.Estimating industrial and residential electricity demand in turkey:a time varying parameter approach[J].Energy,2014(4):959-964.
[11]李亞,劉麗平,李柏青,等.基于改進K-means聚類和BP神經網絡的臺區線損率計算方法[J].中國電機工程學報,2016(17):4543-4551.
[12]石幫松,張靖,何宇,等.基于動態博弈的配電網單相電力用戶用電行為分析[J].電力系統自動化,2017(14):87-91,139.
[13]ZHANG J,ZHENG Y,QI D.Deep spatio-temporal residual networks for citywide crowd flows prediction[J].AAAI,2016(5):25-29.
[14]趙文清,沈哲吉,李剛.基于深度學習的用戶異常用電模式檢測[J].電力自動化設備,2018(9):34-38.
[15]許元斌,李國輝,郭昆,等.基于改進的并行K-means算法的電力負荷聚類研究[J].計算機工程與應用,2017(17):260-265.
猜你喜歡
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
軟件工程(2016年8期)2016-10-25 15:47:34
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
