面向大數據應用的自適應帶寬分配策略
2019-08-07 00:46:30姜晶
兵器裝備工程學報 2019年7期
關鍵詞:分配
姜 晶
(徐州開放大學 信電學院, 江蘇 徐州 221116)
隨著移動設備的高速發展,海量數據(大數據)的應用日益劇增[1-3]。通常大數據具有3Vs特性:容量(Volume)、速度(Velocity)和多變(Variety)[4]。隨著大數據的不斷涌現,隨之而來的問題也難以避免,如大數據分析、大數據傳輸以及容量問題。其中,大數據傳輸問題尤為突出。為此,在滿足數據有效期的條件下,如何高效地傳輸大數據成為研究熱點。
節點產生的數據可能需要通過網絡傳輸至其他節點。在傳輸數據前,節點通常先傳輸數據請求。因此,如何可靠地傳輸請求并處理傳輸請求,對數據傳輸的成功起到關鍵作用。而有效地給傳輸請求(Request,Req)分配帶寬有利于快速地傳輸請求。然而由于海量數據和網絡的復雜性,有效地分配帶寬存在一些挑戰。
給請求分配寬的帶寬,可降低傳輸時延,但也消耗了寬帶資源。反之,若分配窄的帶寬,網絡可接收更多的請求,但增加傳輸時延,最終也可能加大了鏈路瓶頸的概率。因此,自適應地分配帶寬顯得尤為重要。即在有限資源下,滿足時限要求,盡可能給傳輸請求分配帶寬,進而高效地傳輸數據[5]。
為了克服現存帶寬分配的不足,提出自適應帶寬分配策略(Flexible Bandwidth Allocation for Big Data Transfer,FBA-BDT)。首先,建立優化規劃目標函數,其目的是在滿足所有傳輸請求的時限條件下,最大化地完成請求的傳輸。目標函數給每個已接收的請求分配了最優帶寬,使得能在截止日期前完成數據傳輸,進而提高帶寬利用率。
1 問題描述
本節針對大數據傳輸請求(Big Data Transfer Requests,BDTRs)建立最優規劃目標函數。
令G(V,E)表示網絡,其中V為頂點集、E為邊集。Cl表示鏈路l∈E的剩余帶寬[6]。最初,當網絡沒有準許任何請求時,所有鏈路均具有最大容量的帶寬。在時隙t,令R表示已準許的BDTRs集。對于每個請求r∈R,其可用一個元組〈sr,dr,Vr,tr〉表述,其中sr為源節點、dr為目的節點、Vr為需要傳輸的數據容量、tr為完成數據傳輸的截止時間。
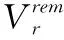
引用二值變量xr表示請求r是否被網絡準許,若xr=1,表示準許;若xr=0,表示拒絕。而引用二值變量yr表示選用了哪條路徑:Pr,1或Pr,2。而用zr表示給請求r分配的帶寬數。因此,自適應帶寬分配的優化規劃目標函數如下:
(1)
(2)
(3)
xrVr/tr≤zr, ?r∈R
(4)
(5)
xr,yr∈{0,1}, ?r∈R
(6)
由式(1)可知,目標函數的目的就是最大化已準許的BDTRs數,準許的BDTRs數越多,通過的數據量越大。而限制條件式(2)和式(3)確保了給已選的每個BDTR的路徑分配足夠的帶寬。如果一條鏈路用于多個請求,必須有剩余帶寬分配給這些請求。
限制條件式(2)應用于使用第一條路徑(Pr,1,?r∈R∪Rac)的BDTRs,而限制條件式(3)應用于使用第二路徑(Pr,2)的其他請求。注意當yr=1,表示請求r利用路徑Pr,1傳輸數據;而yr=0,表示請求r利用路徑Pr,2傳輸數據。而限制條件式(4)和式(5)給已準許的請求和正在進行的請求提供了最小的帶寬,并滿足它們的時限要求。
然而,由于目標函數的非線性特性[7],計算目標函數的運算量較大。即使對于少量的BDTRs和小型網絡,涉及的變量數仍過大,并且變量數隨請求數和網絡尺寸呈指數增長。因此,很難在短時間內,獲取最優解。為此,接下來,利用啟動算法求解目標函數,進而獲取可接收的次優解。
2 求解算法
利用FBA-BDT算法求解目標函數。求解過程由兩步構成,偽代碼分別如算法1和算法2所示。它們需解決的問題如圖1所示。從圖1可知,算法1的目的在于滿足請求的最基本要求(分配所需的最小帶寬),而算法2是將剩余帶寬重新分配給已準許的請求。
注意到,算法1和算法2均是周期地執行,即在每個時隙開始執行,且每個時隙的時長為ts。具體而言,在時隙t-1到達的所有BDTRs需在時隙t的開始時完成。
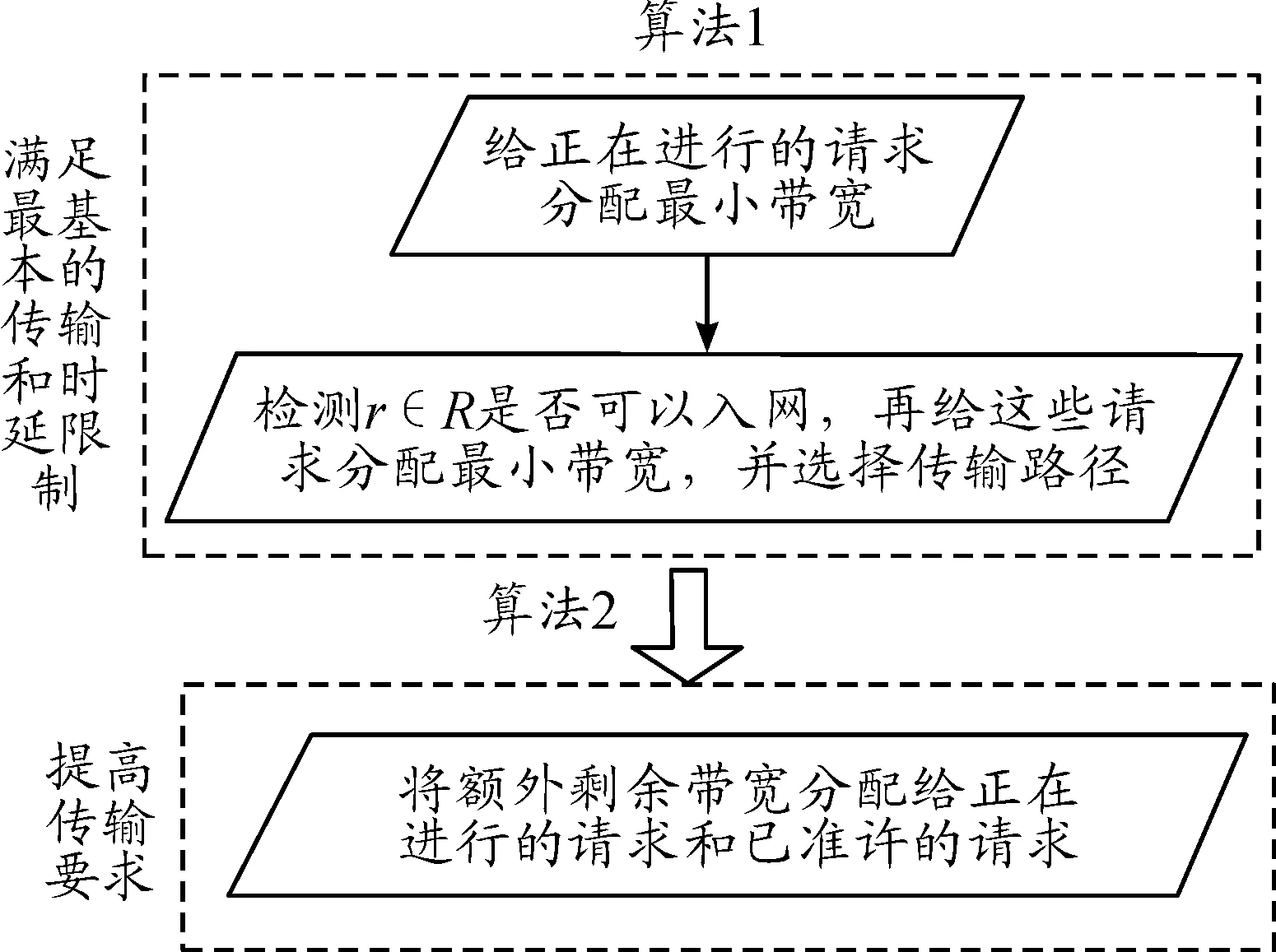
圖1 FBA-BDT算法的兩個子算法框圖
2.1 算法1
具體而言,在給定正在進行的傳輸請求數和網絡狀態時,算法1目的就是給每條準許的請求選擇一條合適的路徑,并分配最小的帶寬,進而完成數據的傳輸。
(7)
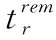
(8)
式(8)中,er表示請求r擁有的剩余時隙數;ts是時隙的時長。
然后給已準許的請求R中的每條請求決策傳輸數據的路徑,進而滿足截止時期tr,如算法1的Step5至Step14,為每個請求r的可選路徑計算最小剩余帶寬。假定可選路徑Pr,1、Pr,2的最小剩余帶寬分別表示為CPr,1、CPr,2。

圖2 算法1的偽代碼
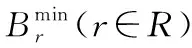
(9)
如果請求r能夠獲取更高帶寬的路徑,即滿足式(10),則準許請求r入網,并選擇更高帶寬的路徑Pr傳輸數據。否則拒絕r入網。
(10)
完成算法1后,就構成已準許的請求集Rad。綜上所述,算法1的執行流程如圖3所示。
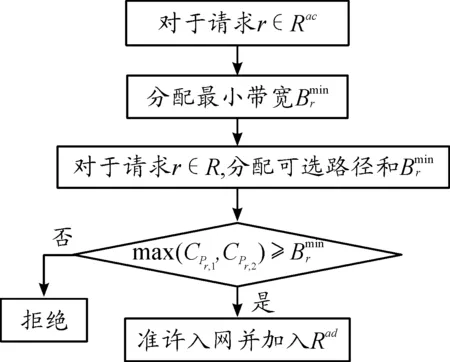
圖3 算法1的執行流程框圖
2.2 算法2
完成了第一階段后,基于可用的剩余帶寬[8-9],第二階段試著將額外的帶寬分配給已準許的Req和正在進行的Req,進而完成數據的傳輸,提高資源效率。
算法2的偽代碼如圖4所示。在給定Rad和Rac條件下,算法2就將額外帶寬分配給這些請求,使它們能夠在截止日期前完成數據傳輸。對于請求r,首先迭代計算路徑Pr上所有鏈路,進而完成在每條鏈路上能夠獲取的額外帶寬。對于鏈路l∈Pr,所分配的額外帶寬zr,其正比于每條請求所需要傳輸的數據量,表示為:
(11)
迭代完畢后就可計算分配請求r的帶寬,即:
(12)
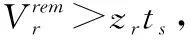
(13)

圖4 算法2的偽代碼
3 性能分析
3.1 仿真環境
仿真過程中引用ESnet拓撲[5]。網絡由58個節點組成,其中23個節點是流量Hubs,而余下的35個節點為流量產生節點。每個流量產生節點能夠以10 Gbit/s數據率產生數據。假定連接58個節點的所有鏈路具有10 Gbit/s的容量。每條請求所傳輸的數據量在[1,20]GB內隨機選取。每條請求的傳輸截止時限在[40,300]s。每個時隙的時長為40 s。此外,由于數據傳輸時延是秒量級,忽略傳播時延[10-11]。
為了更好地分析FBA-BDT算法的性能,選擇拒絕請求率、每個時隙傳輸的平均數據量和每個時隙每條請求所分配的平均帶寬[12-13]。其中拒絕請求率等于拒絕的BDTRs數與已準許的BDTRs數之比[14];每個時隙傳輸的平均數據量等于在總仿真時間內的總時隙內傳輸的平均數據量;每個時隙每條Req所分配的平均帶寬等于在總的時隙數、總的已準許的BDTRs內,給已準許的BDTRs所分配的帶寬。
此外,比較最小帶寬分配(Minimum Bandwidth Allocation,MinBA)、最大帶寬分配(Maximum Bandwidth Allocation,MaxBA)策略。MinBA策略在滿足時限要求下,給每條準許BDTRReq分配所需的最小帶寬,并維持此帶寬,直到數據傳輸完畢。而MaxBA策略是分配可用的最大帶寬。
3.2 數據分析
3.2.1 拒絕請求率
圖5顯示了拒絕請求率隨請求到達率的變化曲線。相比于MaxBA和MinBA算法,FBA-BDT算法的拒絕率得到了有效控制。即使在糟糕的情況,FBA-BDT算法的拒絕率比MaxBA和MinBA算法也分別提高82%、40%。換而言之,MinBA算法拒絕40%的Req被FBA-BDT算法接收。
FBA-BDT算法的最佳拒絕率比MaxBA和MinBA算法分別降低了88%和98%。這些數據表明給請求自適應分配帶寬比采用固定策略分配帶寬,能夠有效地降低拒絕請求率。
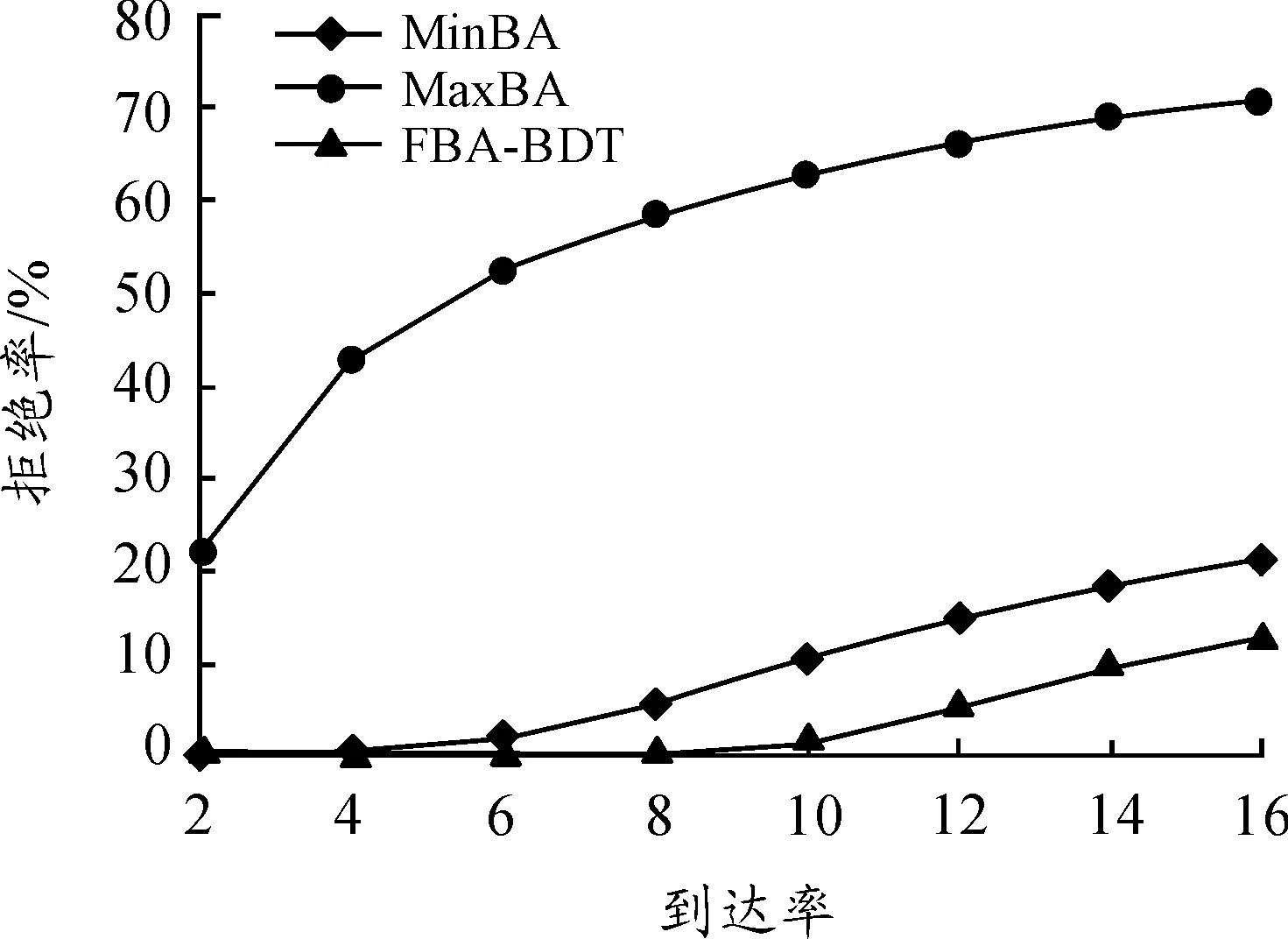
圖5 拒絕請求率
3.2.2 每個時隙傳輸的平均數據量
圖6顯示每個時隙傳輸的平均數據量隨請求到達率的變化曲線。從圖6可知,在每個時隙的請求到達率為16個BDTRs時,FBA-BDT算法能夠每時隙傳輸高達142 GB,而MaxBA和MinBA算法只能夠傳輸50 GB和125 GB。換而言之,利用FBA-BDT算法,網絡每天能夠傳輸和處理約300 TB的大數據,這幾乎是Large Hadron Collider的4倍。
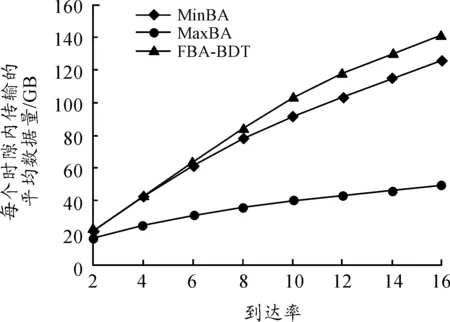
圖6 每個時隙傳輸的平均數據量
3.2.3 每個時隙每條請求所分配的平均帶寬
圖7顯示了每個時隙每條請求所分配的平均帶寬隨Req到達率的變化曲線。從圖7可知,MaxBA和MinBA算法在到達率變化期間給所有請求分配相同的帶寬。而FBA-BDT算法給請求分配的帶寬隨到達率的增加而逐漸減少。原因在于:當到達率低時,有額外可用帶寬分配給這些請求。而當到達率增加時,額外可用帶寬隨之下降。
此外,FBA-BDT算法可提高資源效率。在低到達率時分配更多帶寬給請求,可提高帶寬利用率,也使得請求在截止日期前完成數據的傳輸。
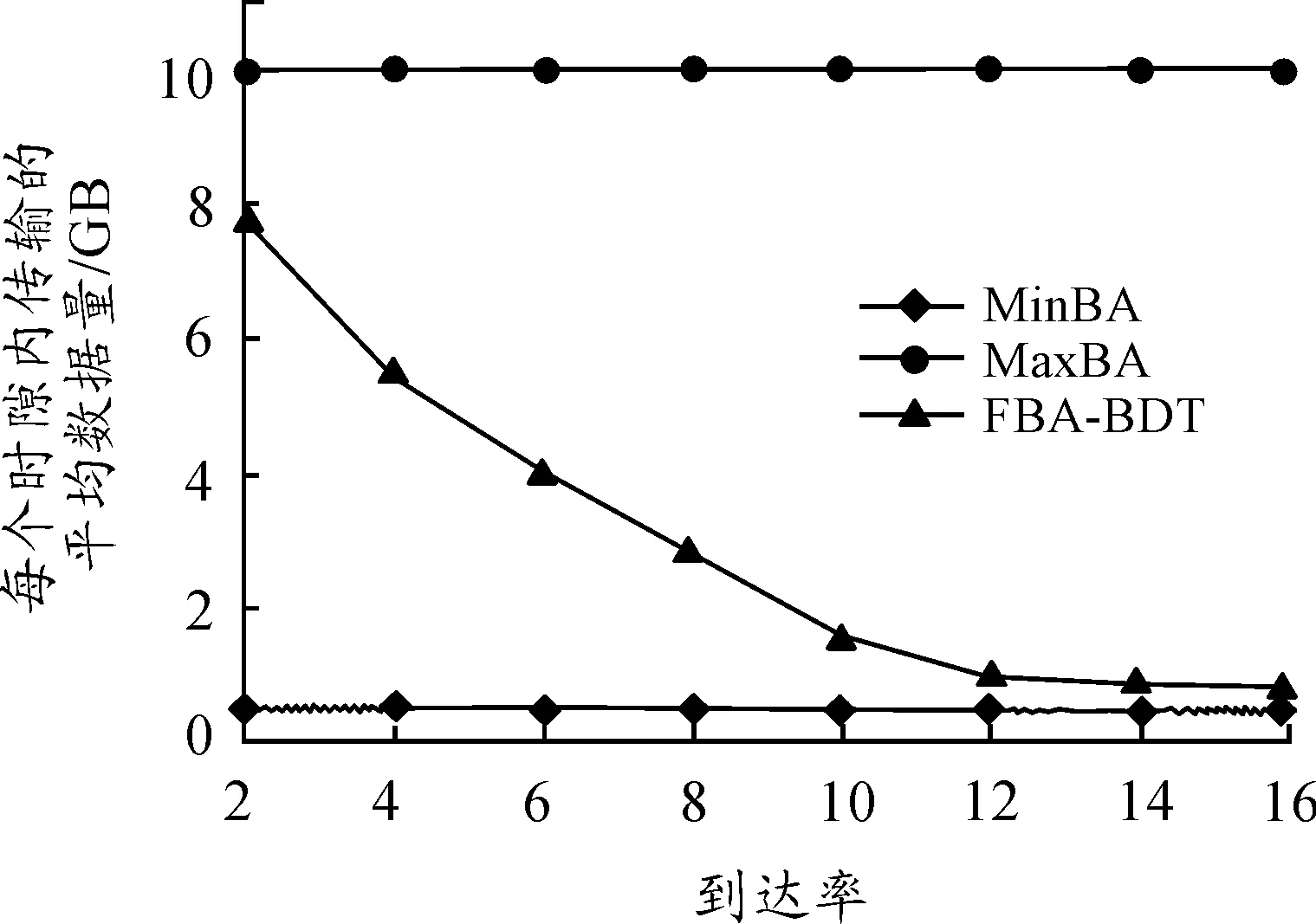
圖7 每個時隙每條請求所分配的平均帶寬曲線
4 結論
本文基于傳輸請求時限條件下,分析了利用自適應分配帶寬的大數據傳輸問題,進而最大化請求接收率。提出的FBA-BDT算法先建立目標函數,再利用啟發式算法求解目標函數。實驗數據表明,提出的FBA-BDT算法有效地降低了請求拒絕率,并提高了數據量。
猜你喜歡
天水行政學院學報(2022年4期)2022-11-18 09:02:36
艦船科學技術(2022年13期)2022-08-11 09:30:02
鐵道通信信號(2020年9期)2020-02-06 09:15:22
漢語世界(The World of Chinese)(2019年3期)2019-07-01 02:37:48
數學大王·趣味邏輯(2019年5期)2019-06-13 20:27:43
小學科學(學生版)(2019年5期)2019-05-21 01:00:18
中學生數理化·中考版(2018年10期)2018-12-07 00:44:52
經濟技術協作信息(2018年30期)2018-11-22 06:20:24
中央社會主義學院學報(2017年1期)2017-04-16 05:34:07
中國衛生(2014年12期)2014-11-12 13:12:40
