考慮能耗和準時的混合流水線多目標調(diào)度
2019-08-07 03:17:30周炳海劉文龍
上海交通大學學報 2019年7期
關鍵詞:挑戰(zhàn)
周炳海, 劉文龍
(同濟大學 機械與能源工程學院,上海 201804)
符號說明:
CD—單位時間延遲交貨成本
CI—單位時間庫存成本
Eijk—工件i在第j個加工階段機器k上的能耗
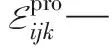
Ejk—第j個加工階段第k臺機器的能耗
pi—工件i的總體加權交貨懲罰
Pjk—第j個加工階段第k臺機器的功率
Pijk—工件i所在第j個加工階段第k臺機器的功率
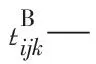
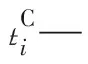

tjk—第j個加工階段第k臺機器耗時
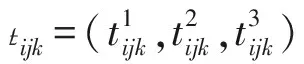
tiljk—第j個加工階段第k臺機器上工件l正好排在工件i后的加工時間
πjk—第j個加工階段第k臺機器上被指派的加工任務集合,πjk={πjk(1),πjk(2),…,πjk(njk)}
σπjk(r-1)πjk(r)—當σπjk(r-1)πjk(r)=1時,表示第j個加工階段第k臺機器上被指派的第(r-1)和第r個加工任務中執(zhí)行1次開關機
φjkir—當φjkir=1時,表示工件i在第j個加工階段第k臺機器上被指派的加工任務集合中排第r位
上標
idel—閑時
off—關機
on—開機
pro—加工
set—換模
混合流水線調(diào)度問題(HFSP)是傳統(tǒng)流水線調(diào)度問題的一種推廣,具有很強的工程背景,廣泛存在于化工、汽車、紡織、半導體等領域.HFSP同時具有流水線作業(yè)和并行機兩者的綜合特征:工藝流程復雜、不確定性大、求解調(diào)度問題難度高,在數(shù)學領域屬于非確定性多項式(NP-hard)問題.因此,研究HFSP具有重要的學術意義和應用價值[1].
在現(xiàn)實環(huán)境之中,由于人為因素和市場波動,HFSP 的生產(chǎn)參數(shù)往往是不確定的,可以通過模糊集理論進行描述[2].Hong等[3-4]首次將離散模糊概念從流水線系統(tǒng)推廣應用于研究HFSP問題,并在此后繼續(xù)推廣到了連續(xù)模糊領域.Pinedo等[5]提出與工件加工次序相關的換模時間可能會占據(jù)生產(chǎn)中機器20%的有效工作時間.
近年來,受到全球變暖和高環(huán)保要求等因素的影響[6],耗能占全國可消費能源總量 72.8%[7]的制造業(yè)開始集中關注如何在提升生產(chǎn)效率與減少能源消耗之間尋求一個平衡點,以達到綠色生產(chǎn)的目標.相關研究人員開始將研究內(nèi)容聚焦于具有節(jié)能意識的調(diào)度目標上[8].Dai等[9]針對HFSP提出一個節(jié)能模型,可以同時優(yōu)化最大完工時間和能源消耗.Luo等[10]在此研究基礎上提出電價變動模型,基于高低電價優(yōu)化電力成本.然而,目前對于考慮能耗的混合流水線在生產(chǎn)中的不確定性及與工件加工次序相關的換模時間約束問題的相關研究較少,缺乏可以參考的研究依據(jù).
因此,本文以最小化系統(tǒng)能耗和準時交貨懲罰作為雙優(yōu)化目標,使用模糊數(shù)描述加工時間和交貨期.同時,考慮換模時間與工件加工次序相關及并行機不相關兩種約束,對HFSP開展研究.最后,通過理論分析和數(shù)值實驗驗證改進型雙目標差分進化算法的可行性和有效性.
1 問題描述
同時考慮換模時間與工件次序相關及并行機不相關兩種約束的HFSP可描述如下:n個工件在流水線上進行s個階段的加工,每個階段至少有1臺機器且至少有1個階段存在并行機;同一階段的各機器加工同一工件所需的加工時間不同且互不相關,所需的換模時間與加工的上一個工件種類相關;在每一階段,各工件均要在其中任意1臺機器上完成1道工序.已知工件各道工序在各機器上的處理時間,要求確定所有工件的排序以及在每個階段機器的分配情況,使得某種調(diào)度指標最小[1].HFSP 示意圖如圖1所示,其中ms表示階段s并行機數(shù)量.為了更加有效地描述HFSP,現(xiàn)做如下假設:① 工件的加工一旦開始不可中斷;② 1臺機器同一時刻只能加工1個工件;③ 1個工件同一時刻只能在1臺機器上加工;④ 工件可在每階段的任意機器上加工.
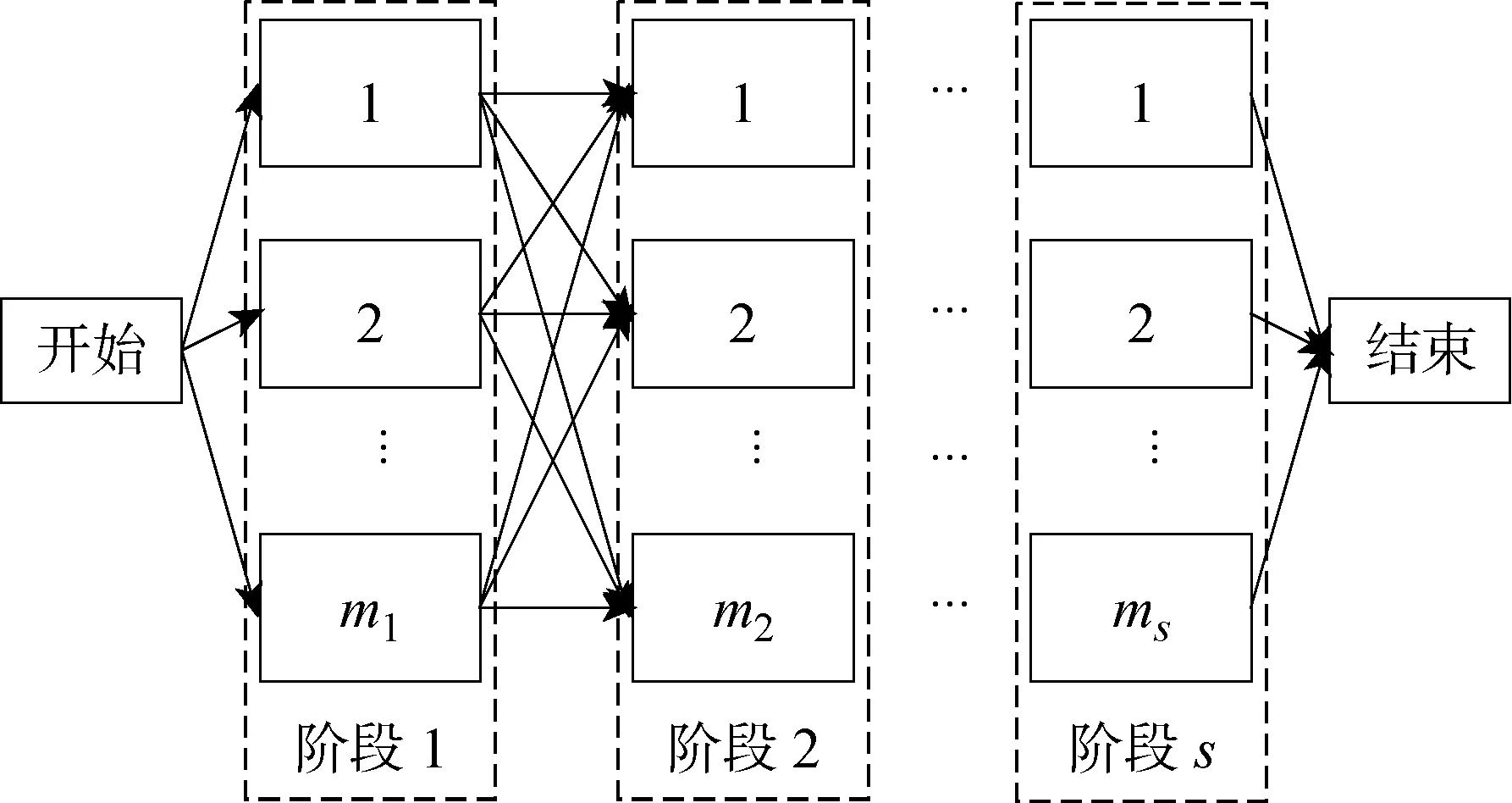
圖1 HFSP示意圖Fig.1 Illustration of HFSP
根據(jù)問題描述和問題假設對系統(tǒng)問題的建模如下:
minF=(f1,f2)
(1)
(2)
(3)
式中:
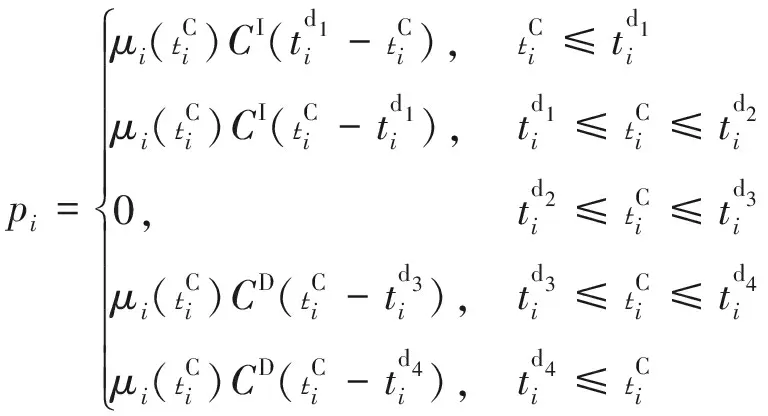
(4)
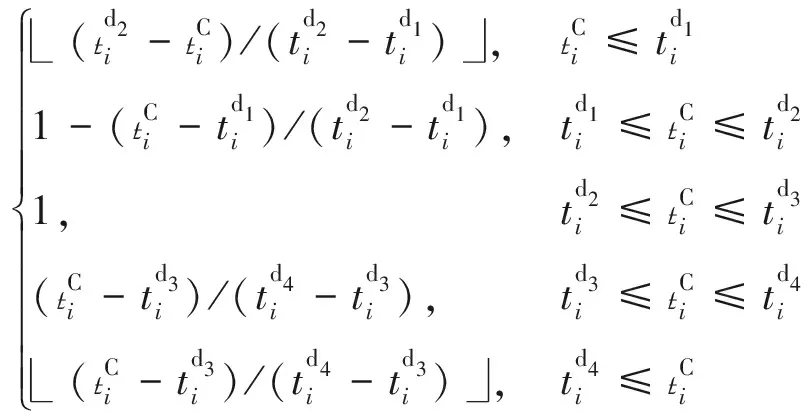
(td2i-tCi)/(td2i-td1i),tCi≤td1i1-(tCi-td1i)/(td2i-td1i),td1i≤tCi≤td2i1,td2i≤tCi≤td3i(tCi-td3i)/(td4i-td3i),td3i≤tCi≤td4i (tCi-td3i)/(td4i-td3i),td4i≤tCiì?í?????????
(5)
(6)
(7)
(8)
(9)
σπjk(r-1)πjk(r)=
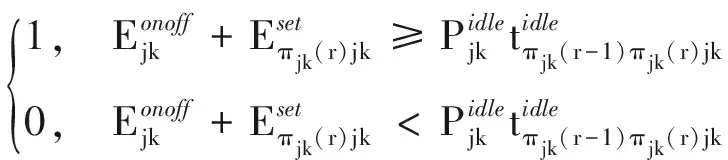
(10)
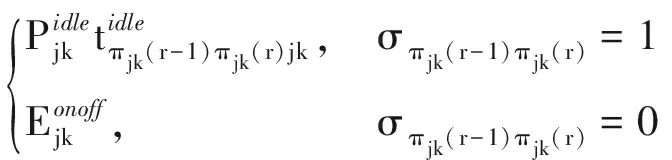
(11)
(12)
(13)
s.t.
(14)
(15)
(16)
(17)
(18)
(19)
l=1,2,…,ni=1,2,…,nj=1,2,…,s



當r=1時,設
模型中,式(1)為模型的目標;式(2)和(3)為目標函數(shù);約束(14)表示每個優(yōu)先級位置只能對應1個工件;約束(15)表示任一階段每個工件只能由1臺機器加工;約束(16)表示每一工件在進行下一道工序前必須完成當前工序;約束(17)表示每個工件在任一階段上的加工完成時間小于其完工時間;約束(18)表示同一階段調(diào)度排列中排位越靠前的工件開始處理的時間越早;約束(19)表示同一階段分配在同一機器上的排位靠后的工件必須等排位靠前的工件加工完后才可進行加工.
2 改進型雙目標差分進化算法
采用傳統(tǒng)的解析方法并不能求解中大規(guī)模的調(diào)度問題.目前,國內(nèi)外研究人員均基于啟發(fā)式算法對此類調(diào)度問題進行研究.Storn等[11]于1997年提出的一種非常有效的優(yōu)化算法——差分進化(DE)算法,已經(jīng)被廣泛地應用于各工程領域.本文基于DE算法提出一種改進型雙目標差分進化(MODE)算法,使用非支配排序以及擁擠距離評價策略比較與排序可行解.同時,引入優(yōu)質解挑戰(zhàn)機制[12]以及混沌搜索策略以保證算法的全局搜索能力.提前設置以下初始參數(shù):種群規(guī)模(Q);解的壽命(L);解的年齡(A);最大循環(huán)次數(shù)(Y).MODE算法的具體步驟如下.
步驟1編碼.根據(jù)模型特點,采用雙染色體形式表示可行解的編碼.編碼的每一個元素包含一個工件在1個階段中的機器指派情況和待加工次序.例如,一個HFSP中有5個待加工工件和3個階段,各階段中的機器數(shù)分別為2、1、3,一個可行解的編碼可寫成:
編碼首行的3個元素表示工件1分別在3個階段的1,1,3號機器上加工,且在各機器上的排序分別是1,2,1.
步驟2初始化階段.引入了NEH(Nanaz, Enscore, Ham)啟發(fā)式方法[13]初始化MODE算法,建立基于NEH和隨機生成的混合方法產(chǎn)生初始種群.首先,利用NEH啟發(fā)式方法構建一個基礎可行解,再通過成對交換方法生成Q/2個可行解,剩余Q/2個可行解隨機生成.
步驟3基于反向的搜索.反向學習(OBL)是由Tizhoosh[14]為機器智能的種群初始化提出的一種方法.對初始種群Q0反向學習后可以得到反向解集,將該解集與Q0合并后共同評估選擇得到新解集.OBL的應用能夠有效地提高群體的多樣性,避免算法陷入局部最優(yōu).
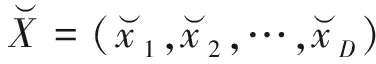
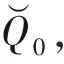
步驟4差分變異.使用DE/current-to-best/1策略以精英解針對新解集的每一個解xi生成其變異解νi.變異解經(jīng)過與原解的交叉操作得到試驗解,通過比較適應值決定是否替代原解.差分變異過程完成后得到的解集將再次經(jīng)過反向學習得到新解集,與原解集合并后利用非支配排序和擁擠距離計算得到新種群及作為領導解集的最優(yōu)Pareto前沿.其中,以擁擠距離最小的解作為精英解.
步驟5挑戰(zhàn)機制.為避免陷入局部最優(yōu)解,1次循環(huán)內(nèi)領導解集中的每個優(yōu)質解都需要比較當前年齡值(未更新迭代數(shù))和壽命,判斷其是否需要接受挑戰(zhàn).一個解每經(jīng)過1次差分變異或混沌搜索,若被更新,則其對應年齡值置0,壽命重置為初始年齡;否則,其年齡值加1.一旦達到壽命限制,啟動對該解的挑戰(zhàn)機制.為了生成更具多樣性和競爭力的挑戰(zhàn)解,每次該算法都將從以下兩種鄰域搜索策略中隨機選取一種用于生成挑戰(zhàn)解,生成的挑戰(zhàn)解分別為GPBX-α[12]和下式:

(20)

與經(jīng)過多代進化的“年老”優(yōu)質解相比,挑戰(zhàn)解難以立即具備足夠的競爭力,故較難在挑戰(zhàn)機制中獲勝.因此,對失敗的挑戰(zhàn)解再進行一次差分進化操作給予第2次挑戰(zhàn)機會.挑戰(zhàn)解一旦通過比較適應值戰(zhàn)勝對應優(yōu)質解,則取代優(yōu)質解并為挑戰(zhàn)解設置初始年齡值和壽命;若2次挑戰(zhàn)均失敗,則優(yōu)質解的年齡值減1,并允許其進入下一次循環(huán).
步驟6混沌搜索.在每次MODE算法循環(huán)的末尾引入混沌搜索,以徹底探索解空間.由于其獨特的周期規(guī)律、固有的隨機屬性等特點,混沌搜索能夠有效地更改粒子的位置,從而有助于提高算法的多樣性.
利用下式將解向量連續(xù)化后計算每個維度對應的混沌數(shù)以構建混沌序列:
(21)
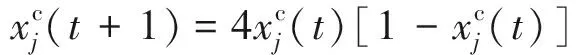
其中:t為混沌迭代數(shù),t=1,2,…,10.同樣地,混沌解若戰(zhàn)勝對應原解,則取代原解并為混沌解設置初始年齡值和壽命.
步驟7算法終止判斷.若算法迭代次數(shù)達到規(guī)定上限Y,則輸出當前的最優(yōu)Pareto前沿及其適應值;否則,進入步驟4.
3 數(shù)值實驗與分析
所有算法都在MATLAB(2016a)環(huán)境下編程實現(xiàn),并在主頻為 3.2 GHz,內(nèi)存為8 GB、Intel(R) Core(TM) i5-4570 CPU的PC機上進行數(shù)值實驗,實驗分析和結果如下.
3.1 評價指標
對于多目標優(yōu)化問題,僅將獲得的最優(yōu)Pareto前沿及算法運行時間(CPU)作為評價指標不足以評判算法的性能優(yōu)劣.因此,為了更為有效地判斷得到的最優(yōu)Pareto解的性能,還將選用Pareto解的個數(shù)(NS)、世代距離(GD)、解間距(SP)作為比較各算法的性能指標.其中,GD越小,表明算法收斂性越好;SP越小,表明算法多樣性越佳.
3.2 參數(shù)設置
測試算例中,有n=20,40,60共3個水平.每個水平各自對應2個階段數(shù)和機器數(shù),共有12個組合.由于研究考慮的是確定性的調(diào)度問題,所以每次計算的初始階段都會隨機生成完整的測試數(shù)據(jù):工件加工時間的模糊數(shù)最可能值服從[10,120]的均勻分布;模糊上下限取最可能值的75%與125%;加工功率服從[3,7]的均勻分布;工件的換模時間服從[10,20]的均勻分布;換模功率服從[2,6]的均勻分布;機器的開機時間服從[5,10]的均勻分布;關機時間服從[2,7]的均勻分布;開機功率服從[2,6]的均勻分布;關機功率服從[1,5]的均勻分布;閑時功率服從[2,6]的均勻分布;每個工件交貨期的可能值表示為
將n=20,s=3,m=5的算例組合記為n20s3m5.數(shù)值實驗中,將n=20,40,60的3類問題分別記為小、中、大規(guī)模問題.
3.3 數(shù)值實驗分析
將MODE算法與帶精英策略的非支配選擇遺傳算法(NSGA-II)、強度帕累托進化算法(SPEA2)進行對比實驗,以測試問題的求解性能.這兩種經(jīng)典算法在解決多目標問題上都具有較好的求解性能.由于此問題的真實Pareto前沿難以得到,故采用以下方法獲得近似前沿:各算法獨立運行多次并記錄每次獲得的Pareto解集,從Pareto解合集中集結新的Pareto解集作為近似前沿.
MODE算法的參數(shù)設置對于其表現(xiàn)和效率有著重要的影響,實驗采用田口方法確定各參數(shù)值,以保證算法的高效性.首先進行正交組合,然后測試各組參數(shù)以確定最優(yōu)組合.據(jù)測試,當交叉率CR=0.7,第1個權重因子W1=0.6,第2個權重因子W2=0.4,可行解的初始壽命L=8時,MODE算法能以較高的質量對問題進行求解.MODE算法以及NSGA-II、SPEA2算法的參數(shù)設置如表1所示.
由于算法的單次運行結果具有一定的隨機性,所以分別用上述3種算法對各算例進行20次獨立數(shù)值實驗,結果如表2所示.
由表2可知,當問題規(guī)模較小時,SPEA2與NSGA-II的解的個數(shù)、世代距離以及解間距性能指標都十分接近,略劣于MODE的相應性能指標.但是,在運算時間上,NSGA-II以及SPEA2所需要的運行時間略優(yōu)于MODE;當問題規(guī)模逐漸變大時,MODE相對于NSGA-II、SPEA2在解個數(shù)、世代距離和解間距方面的優(yōu)勢逐漸擴大,其相對較大的運算時間也在可接受范圍內(nèi).其中,MODE在Pareto解個數(shù)上的優(yōu)勢意味著有更多備選決策可供從業(yè)人員選擇.
圖2以n20s3m5,n60s7m15兩個算例為例,表明了在小、大兩種規(guī)模下各算法之間的Pareto前沿比較情況.由圖2(a)可知,當問題規(guī)模較小時,NSGA-II、SPEA2求得的解集互有支配,并且都被MODE求得的解集所支配,但在部分位置差距較小;而隨著問題規(guī)模的擴大,如圖2(b)所示,MODE的Pareto解集基本支配了NSGA-II與SPEA2的 Pareto 解集,且分布更為均勻.數(shù)值實驗對比結果證明了MODE算法的有效性.而MODE算法的優(yōu)秀求解能力應該歸功于算法基于DE算法的多個改進之處,其中包括基于NEH算法得到優(yōu)質初始解、優(yōu)質差分進化策略帶來更好的鄰域挖掘能力、挑戰(zhàn)優(yōu)質解更易于跳出局部最優(yōu)解、反向學習和混沌搜索策略保證算法的全局搜索能力.

表1 不同算法的參數(shù)設置表Tab.1 Parameter settings of different algorithms
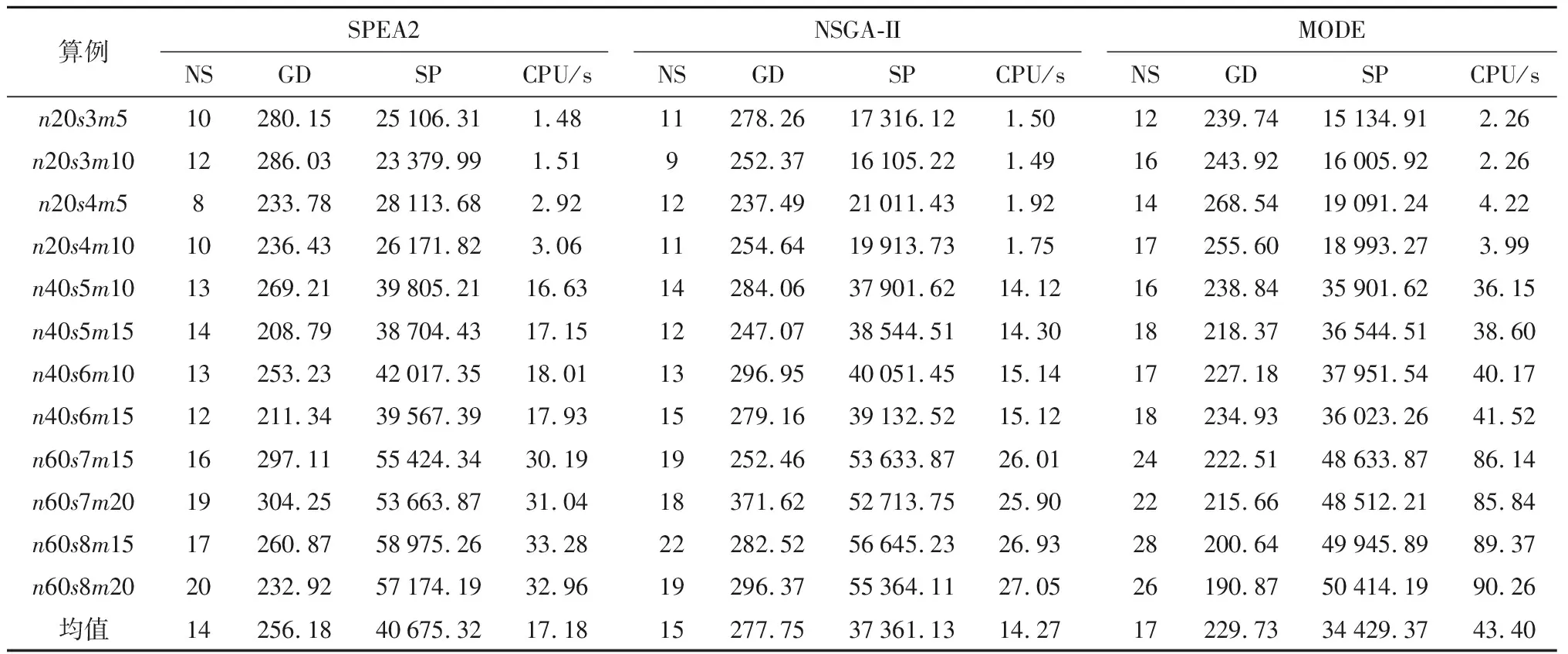
表2 不同規(guī)模調(diào)度問題的數(shù)值實驗結果Tab.2 Experimental results for different instances
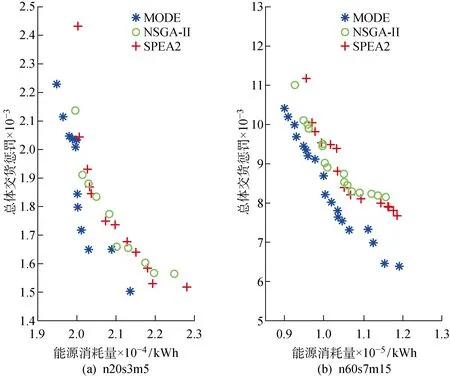
圖2 兩個算例下的Pareto解集Fig.2 Pareto solutions for two instances
4 結論
(1) 針對考慮并行機不相關、換模時間與工件加工次序相關兩種約束的混合流水線系統(tǒng),以保證準時交貨和降低生產(chǎn)能耗為雙調(diào)度目標,使用模糊數(shù)描述加工時間和交貨期以處理系統(tǒng)的不確定性.
(2) 以差分進化算法為基礎,引入NEH啟發(fā)式方法構建高質量初始解,建立優(yōu)質解挑戰(zhàn)機制避免種群陷入局部最優(yōu),通過反向學習和混沌搜索探索全局解空間,提出改進雙目標差分進化算法.
(3) 仿真實驗驗證MODE算法的有效性和較好的求解性能,豐富解決此類調(diào)度問題的理論方法.
(4) 未來的研究可在本文基礎上考慮有限緩沖區(qū),增加研究的復雜性和現(xiàn)實意義.
猜你喜歡
小哥白尼(趣味科學)(2021年7期)2021-11-05 07:25:38
小哥白尼(野生動物)(2021年2期)2021-07-16 08:35:28
童話世界(2020年32期)2020-12-25 02:59:22
童話世界(2020年26期)2020-10-27 02:23:44
中國外匯(2019年15期)2019-10-14 01:00:36
動漫星空(興趣英語)(2019年3期)2019-03-06 01:55:00
少年博覽·小學低年級(2016年10期)2016-11-24 16:07:01
少年博覽·小學低年級(2016年9期)2016-11-24 16:07:00
少年博覽·小學低年級(2016年5期)2016-05-14 11:59:03
專用汽車(2016年8期)2016-03-01 04:16:05
