基于稀疏自編碼神經網絡的產品再設計模塊識別方法
2019-08-07 03:17:54馬斌彬馬紅占褚學寧李玉鵬
上海交通大學學報 2019年7期
馬斌彬, 馬紅占, 褚學寧, 李玉鵬
(1. 上海交通大學 機械與動力工程學院, 上海 200240; 2. 中國礦業大學 礦業工程學院, 江蘇 徐州 221116)
隨著運行時間的增長,產品功能模塊的性能逐漸退化,而產品的薄弱環節通常是退化嚴重、對產品的安全性和可靠性產生重大不利影響的功能模塊[1],因此,設計人員往往采用再設計的方法對產品的薄弱環節進行重新設計.其中,再設計功能模塊識別方法是通過找出產品的薄弱環節并對其重新展開設計,從而進一步提高產品的可靠性和服務水平.目前,國內外學者基于產品的故障數據和運行數據對再設計功能模塊識別方法進行了研究.例如:Francesco等[2]提出了改進的產品失效模式、影響和危害性分析(FMECA)方法;全睿等[3]通過建立模糊故障樹來識別影響燃料電池發動機安全性的薄弱環節.但是,由于船舶、起重機等復雜機械產品具有可靠性高、壽命長的特點,偶發的故障數據不能真實反映產品在一段時間內的連續狀態變化情況,所以基于故障數據的產品再設計模塊識別的結果不能很好地反映功能模塊間退化水平的差異.隨著傳感器和無線技術的發展,獲取產品運行狀態的實時數據變得可行[4].Shin等[5]基于產品性能時變數據,利用聚類方法分析了產品的失效情況,通過建立性能參數與設計參數之間的關聯矩陣來對產品再設計進行改進,但利用聚類方法進行失效分析需要預先設定運行工況的個數,而產品的運行工況具有復雜性和多變性,因此,很難預先確定運行工況的個數;Ma等[6]以履帶起重機的功能模塊的性能參數為輸入,通過建立混合高斯模型來擬合性能參數的取值區間,以用于產品再設計模塊的識別.但是,混合高斯模型需要在每個狀態點更新退化模型,其計算過程復雜,不利于實時處理.而神經網絡模型可用于處理具有多狀態(非線性)的性能特征參數,適用于描述運行工況復雜的產品退化狀態[7],因此,本文利用產品在健康狀態下的性能時變數據構建稀疏自編碼神經網絡(SAENN)模型,以用于產品功能模塊退化程度的評估,并通過對比模塊功能間的退化差異來識別需要再設計的功能模塊.
1 基于SAENN的產品功能退化建模
1.1 稀疏自編碼神經網絡
在產品運行過程中,傳感器采集到的各種性能特征參數在一定程度上反映了產品功能退化的程度,這些狀態信息對產品再設計具有重要的價值.然而,產品的退化過程復雜,其功能退化的規律與性能特征參數之間存在著復雜的非線性時變關系,難以利用確定的解析模型來評估,而神經網絡模型可以表征產品性能參數之間的非線性關系,因此,它可用于評估產品功能的退化程度,進而比較不同功能模塊間的退化差異.
自編碼神經網絡(AENN)模型是一種無監督的神經網絡模型,包括輸入層、隱含層和輸出層,其主要通過編碼-重構過程來表征輸入樣本的數據特性[8].通過建立AENN模型、訓練產品在健康狀態下各功能模塊的性能特征數據,能夠提取在健康狀態下產品性能參數之間的抽象特征.當產品功能發生退化時,這些性能參數的特征與健康狀態下的具有明顯差異,通過分析其差異即可評估各功能模塊的退化程度.而SAENN模型是在AENN模型的基礎上在隱含層神經元引入了稀疏性限制條件,從而增強了模型的泛化能力(模型對于健康狀態下性能特征的識別能力).稀疏性限制條件能夠使AENN模型的隱含層通過特征選擇來找出高維數據中重要的若干維,從而學習相對稀疏、簡明的數據特征,以更好地表達輸入數據,它克服了AENN模型泛化能力較差、不能提取數據內在特征的缺點.
1.2 產品功能退化評估模型的建立
以下為建立產品功能退化評估模型的步驟.
(1) 構建產品功能退化評估模型.首先,劃分功能模塊.對于機械產品來說,功能模塊可以按照實現功能的不同劃分為機、電、液等系統,每個系統均采用對應的性能特征參數來表征其功能模塊的退化程度.假設產品由N個功能組成,第n個功能表示為Fn(n=1,2,…,N),功能Fn有M個性能特征,則功能Fn的性能時變特征可用矩陣形式表示為
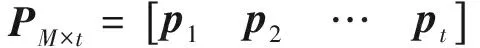
(1)
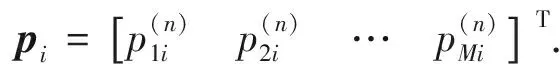
qi=sf(Wpi+b1)
(2)
式中:sf為從輸入層到隱含層的激活函數,也就是Sigmoid函數f(x)=1/(1+e-x);W∈Rd×M,為隱含層的權重矩陣;b1∈Rd×1,為隱含層的偏置向量.從隱含層到輸出層進行特征重構,將qi經過計算后所得與pi具有相同維度的性能特征向量為
(3)
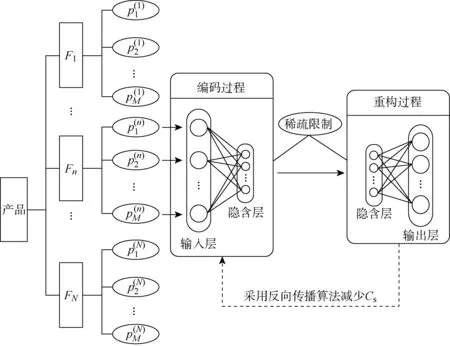
圖1 功能退化的評估模型Fig.1 Assessment model of function degradation
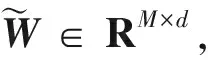
(4)
(2) 增加稀疏性限制條件.在重構誤差C的基礎上增加稀疏性限制條件.對于PM×t中M個輸入性能特征向量,假設隱含層中第k(k=1,2,…,d)個神經元的平均活躍度為
(5)
稀疏性限制條件可以表示為
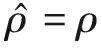
(6)
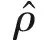
(7)
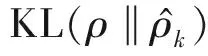
因此,加入稀疏性限制條件后的重構誤差可以表示為
(8)
式中:β為稀疏性懲罰因子的權重,決定了對稀疏性限制條件的重視程度.
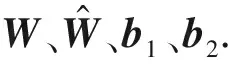
2 產品再設計功能模塊識別
2.1 功能退化程度的評估
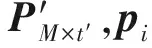
(9)
將評估矩陣中的性能時變特征向量逐次作為模型輸入,計算每一時刻的劣化指數DI,從而得到Fn的退化趨勢.
2.2 性能特征重要度的分配
性能特征重要度是性能參數對功能退化的影響程度.對于功能Fn的M個性能特征,其數值與正常的性能特征范圍的偏差對Fn層次的功能退化的影響程度有所不同.例如,液壓系統失壓比油溫偏高對功能造成的影響更嚴重,因此,在計算DI時,需給油壓分配更大的權重,以便于合理描述功能退化的程度.在實際應用中,對于性能特征重要度的分配,主要依靠工程人員的知識和經驗確定.假設性能特征重要度的權重向量為V,第j個性能特征的權重為vj,則
(10)
考慮到性能特征重要度權重的影響,修正后的劣化指數為
(11)
2.3 再設計功能模塊的識別
首先,對產品的N個功能模塊分別建立功能退化評估模型,以分析功能退化趨勢與性能時變特征的關系;然后,采用修正后的劣化指數DI表征其退化程度.在對產品的薄弱功能模塊進行識別時,應比較相同時間內不同功能模塊的DI的變化趨勢.DI值越大,說明退化越嚴重,該模塊再設計的必要性越高,在再設計過程中需要格外關注.
3 案例分析
本文以國內某大型工程機械制造企業的水平定向鉆產品為例進行案例分析.該企業的水平定向鉆產品包括小型機系列、中型機系列以及重型機系列,主要型號有SDD100型、SDD330型、SDD3000型等,本文的研究對象為重型機產品.
3.1 產品功能模塊的劃分
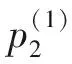
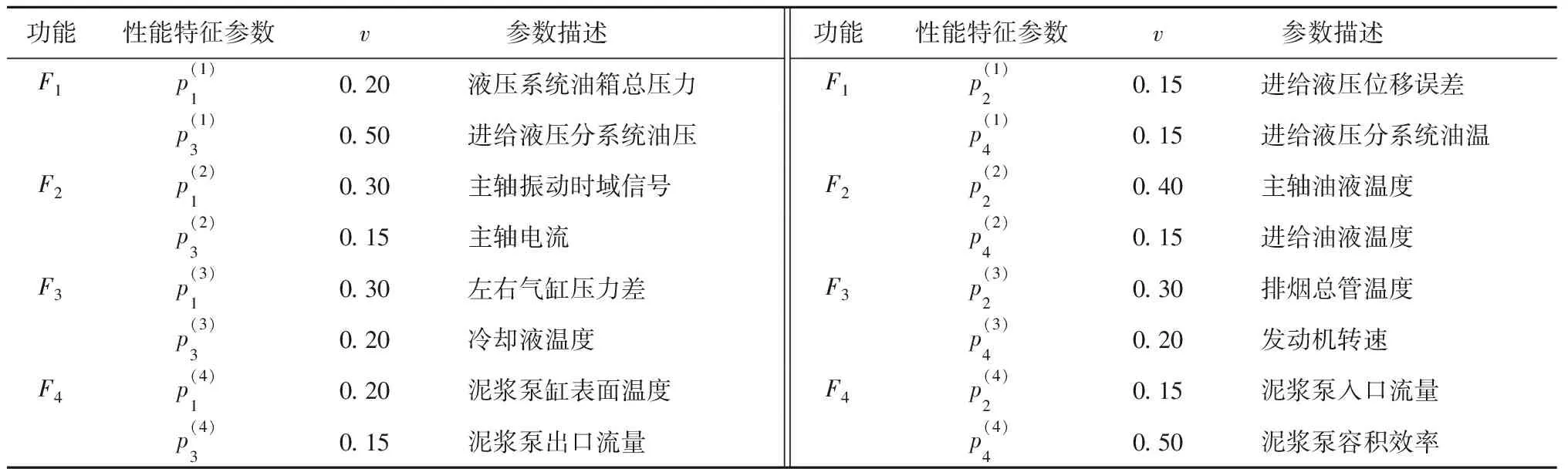
表1 功能模塊的性能特征及重要度Tab.1 Performance feature and importance rate of the function module
3.2 功能退化評估與再設計的必要性
首先,定義水平定向鉆在未出廠時的調試過程采集的性能時變數據為健康狀態下的產品性能特征,用該時段的數據訓練退化評估模型;然后,對水平定向鉆出廠后投入運行3 a內各功能退化的程度進行評估.每隔30 min采集一次各功能模塊的性能特征.其中,主軸時域信號采用振動信號的方均根(RMS)作為特征參數.對于每個功能模塊,將采集的 1 620 組健康狀態下的性能特征數據作為訓練集數據,隨機抽取其中 1 296 組數據用于模型訓練,324組數據用于模型驗證;將產品運行過程中的 6 000 組性能時變數據作為測試集數據,以評估功能模塊的退化程度.評估過程分為3個步驟:
(1) 數據預處理.由于產品功能模塊的性能時變數據的量綱和數值區間不同,直接進行訓練會導致數值區間大的性能特征過分支配數值區間小的性能特征,所以需要采用數據標準化的方法將其統一變換為無單位數據.本文采用0-1標準化方法[10]對訓練集數據進行縮放,并將縮放比例應用于測試集數據.
(3) 評估功能退化程度.獲取不同性能特征重要度的權重(見表1).采用步驟(2)中訓練好的退化模型評估測試集數據,計算得到修正后的劣化指數DI.所得3 a內不同功能模塊的劣化指數的變化趨勢如圖2所示.由圖2可見,隨著運行時間增加,各功能劣化指數均逐漸增大.而劣化指數越大,說明功能退化越嚴重.
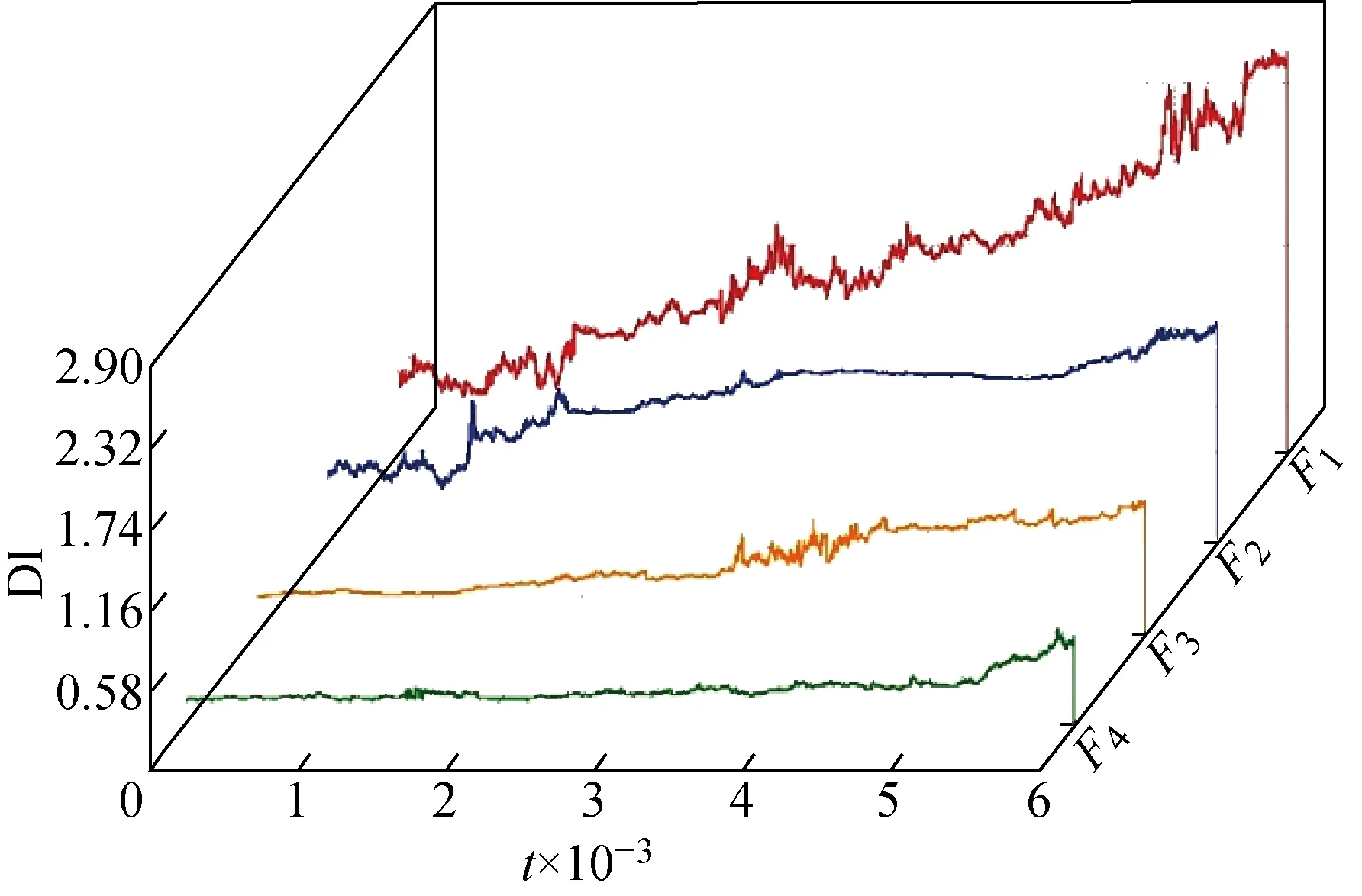
圖2 不同功能模塊劣化指數的變化趨勢Fig.2 Degradation tendency of each function module
由圖2還可以看出,液壓系統F1的功能劣化指數隨時間變化而迅速增長,其變化幅度遠超過其他功能;而機械系統F2相比初始時刻也有較明顯的增長趨勢.通過比較各功能模塊的劣化指數的最大值和變化趨勢發現,液壓系統的功能退化最嚴重.
另外,由企業調研中與產品設計師和相關技術人員的訪談可知,液壓系統中子系統眾多,但由于缺乏足夠的設計和工藝操作經驗的積累,所以液壓系統的性能指標和可靠性與國外同行業的先進水平還存在差距,提升該功能模塊的可靠性對于提升產品整體服務水平有著重要作用,因此,從實際工程的角度也說明液壓系統功能模塊再設計的必要性最高.
3.3 結果分析
為了驗證SAENN模型的精度,采用3.2節中F1的 1 620 組訓練集數據及AENN和SAENN模型對于產品在健康狀態下的性能特征提取效果進行對比,其結果見表2.由表2可以看出:SAENN模型訓練數據的平均重構誤差略大于AENN模型,這是由于增加稀疏性限制條件的正則項的緣故,但其對模型精度的影響很小,且驗證數據的平均重構誤差小于AENN模型,說明SAENN模型的泛化能力更強.因此,在訓練數據重構誤差差距不大的情況下,增加稀疏性限制條件能夠提高模型的泛化能力,減少訓練過程中的過擬合現象.

表2 不同模型的重構誤差Tab.2 Reconstruction error of each model
為進一步驗證SAENN模型的應用效果,本文采用改進FMECA方法[2]、聚類方法[5]和混合高斯模型(GMM)方法[6]識別薄弱功能模塊(液壓系統),所得功能模塊的再設計必要性見表3.其中,根據方法的不同,模塊之間再設計必要性的高低有所區別.改進FMECA方法是通過分析不同功能模塊發生的故障模式及其可能造成的影響,按照故障的嚴重性、難檢度和發生頻次進行歸納,對各功能模塊的再設計必要性進行排序;聚類方法是通過預先設定健康狀態類別數,根據時變性能特征向量與聚類中心的距離計算功能模塊的退化程度,進而比較功能模塊間的退化差異;GMM方法是通過建立混合高斯模型,將健康衰退指數作為功能模塊退化程度的評估指標,以確定各功能模塊再設計的必要性.由表3可見,利用產品故障數據進行識別時,無法確定功能模塊F2和F3的再設計必要性,其原因是產品故障數據來源于水平定向鉆的返廠維修記錄和用戶反饋信息,而水平定向鉆出廠投入運行3 a后只有2次返廠維修記錄,分別為液壓系統故障(表現為液壓管顫抖)以及液壓泵聲音異常和泥漿系統故障(表現為管路堵塞).因此,僅靠維修記錄無法評估F2和F3的再設計必要性.考慮性能時變數據后,采用聚類方法所得結果與GMM、SAENN方法的結果不同,其原因是聚類方法需預先確定工況個數,產品運行環境的多變性影響了產品退化趨勢的評估;采用GMM模型與SAENN模型的結果一致,但GMM模型訓練和評估的耗時較多,因此,采用SAENN模型進行再設計功能模塊識別的整體性能最優.

表3 不同方法識別的再設計功能模塊的必要性Tab.3 Different identified functions using different methods
4 結語
本文將產品在健康狀態下的性能時變數據應用于產品功能退化評估,提出了利用性能時變數據來指導產品再設計的思路,并將SAENN模型用于產品功能退化程度的評估,提高了再設計功能模塊識別方法的準確性和客觀性.具體方法:將產品在健康狀態下的性能數據作為訓練數據,通過訓練神經網絡來學習性能參數深層次的特征,并引入稀疏性限制條件,以增強模型的泛化能力;利用產品運行階段的性能時變數據評估產品功能退化的趨勢;對比各功能模塊間性能退化的差異,以識別需要改進的功能模塊.所得識別結果可作為產品再設計的依據,對提高產品可靠性具有重要意義.
然而,文中采用專家打分法對性能特征重要度進行評估,其主觀性較強,下一步將考慮依據性能特征對產品在健康狀態下的敏感性和產品性能的退化程度來確定性能特征重要度.
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
軟件導刊(2016年9期)2016-11-07 21:35:42
通信電源技術(2016年5期)2016-03-22 01:09:49
石油知識(2016年2期)2016-02-28 16:20:16
Coco薇(2015年1期)2015-08-13 02:23:50
自動化儀表(2015年11期)2015-04-01 01:02:40
河南科技(2014年23期)2014-02-27 14:19:15
玩具(2009年10期)2009-11-04 02:33:14
