自然語言處理及其在機器翻譯中的應用
2019-08-09 08:30:15王鈺
現代語文 2019年5期
關鍵詞:機器學習
王鈺


摘 要:機器翻譯是自然語言處理的一個重要分支,自然語言處理技術與機器翻譯研究的結合不僅為人們日常工作生活中各種跨語言需求提供了便利,也對解決其他自然語言處理任務有著啟發與借鑒作用。首先概括了自然語言處理的一些基本概念,然后舉例說明自然語言處理在機器翻譯中的應用,最后展望機器翻譯未來發展趨勢并進行總結。這有助于加深對自然語言處理以及機器翻譯之間關系的認識,旨在為后續的研究提供借鑒。
關鍵詞:自然語言處理;機器翻譯;機器學習
近年來,自然語言處理(natural language processing)作為根植于語言學、計算機科學和數學等多種學科沃土而成長起來的多邊緣學科,成為人工智能中亟需解決的任務之一,同時也是該領域的一個重要研究方向。自然語言處理的飛速發展,為機器翻譯研究提供了強有力的支持。當今世界,隨著通信技術與互聯網技術的迅猛發展、信息的急劇增加以及國際聯系愈加緊密,語言交流障礙問題也顯得愈加突出,對機器翻譯的潛在需求也在逐漸加大(John Hutchins,1986)。在目前人工智能(artificial intelligence)的浪潮下,機器翻譯理論、技術與未來發展趨勢越來越引人關注(李沐等,2018)。值得注意的是,對自然語言處理技術在機器翻譯中的應用、機器翻譯是否會代替人工翻譯等問題,還存在著諸多片面的認識。
有鑒于此,本文首先對自然語言處理的概念和主要內容進行簡要的介紹,在此基礎之上嘗試舉例說明自然語言處理技術在機器翻譯中的應用。在對機器翻譯與人工翻譯之間的關系進行簡要的梳理后提出本文的觀點,最后對機器翻譯未來的發展趨勢進行展望。
一、自然語言處理概述
(一)自然語言處理的概念
計算語言學(computational linguistics),也稱自然語言處理(natural language processing),是一門以計算為手段對自然語言進行研究和處理的學科(劉穎,2014:1)。Bill Manaris(1998)曾在《計算機進展》中給出這樣的定義:“自然語言處理可以定義為研究在人與人交際中以及在人與計算機交際中的語言問題的一門學科。”自然語言處理要研制表示語言能力和語言應用的模型,建立計算機框架來實現語言模型,提出相應的方法對語言模型不斷地進行完善,根據語言模型設計各種實用系統,并探討這些實用系統的評測技術。自然語言處理的概念界定,可以參見圖1:
馮志偉(2010)、張政(2010:2)指出,為了實現計算機對現實生活中自然語言的研究和處理,在自然語言處理技術所應用的各個領域中,一般需要根據具體要求經過以下幾個過程:
1.從語言學角度把自然語言處理抽象為一個語言問題;
2.把這一問題在語言學上形式化,使之能以一定的數學形式,嚴密而規整地表示出來;
3.把這種嚴密而規整的數學形式表示為“算法”;
4.根據算法建立自然語言處理的“計算模型”,這樣能夠使它在計算機上得以實現。
總的來說,自然語言的具體處理過程可用圖2進行展示:
如圖2所示,自然語言處理需要一系列的轉換加工過程。在自然語言處理中,不僅需要語言學方面的知識,而且還需要非語言學方面的知識,如心理學、計算機科學、統計學、數學、哲學、電子工程和生物學等。總之,自然語言處理是一門多邊緣交叉學科。
(二)自然語言處理的主要內容
根據語言學的通常觀點,語言可以分為以下幾個層次:語音、詞匯、語法、語義、語篇和語用。自然語言處理技術在以上各個層次的主要應用,可以進一步細分為下列內容:機器翻譯(machine translation)、語音自動識別(sound recognition)、語言自動合成(sound synthesis)、自動文摘(automatic abstracting)、人機對話(man-machine dialogue)、信息自動檢索(automatic information retrieval)、術語數據庫(term database)、計算機輔助教學(computer-aided instruction)、電子詞典(electronic dictionary)、文字自動識別(optical character recognition)、文獻自動分類(information classification)等。
目前,無論是在理論基礎、語言資源,還是在關鍵技術等方面,自然語言處理都有了相當豐富的積累(王萌等,2015)。應當說,上述應用也都有了很大的發展。比如說語音自動識別,即利用計算機對語音作出明確辨認。這一技術可用于翻譯的語音識別,也可以用于鐵路、民航等無人管理站的問訊系統。又如自然語言理解,也稱人機對話,是來研究如何利用計算機讓其理解并運用人類語言,最后用自然語言以對話的方式回答人們所提出的問題。百度公司開發的“小度”、微軟的“小冰”等都實現了智能人機對話。再如文字自動識別技術,它可以應用到一些掃描軟件上,通過對印刷字體甚至是手寫的字體進行識別,最終生成相應的電子文檔。此外,自然語言處理在翻譯領域的應用也越來越廣泛。我們知道,在應用翻譯領域,人類面對的最迫切、最重大的任務,就是如何解決計算機翻譯問題。這也是下文所著要探討的問題。
二、自然語言處理在機器翻譯中的應用
(一)機器學習
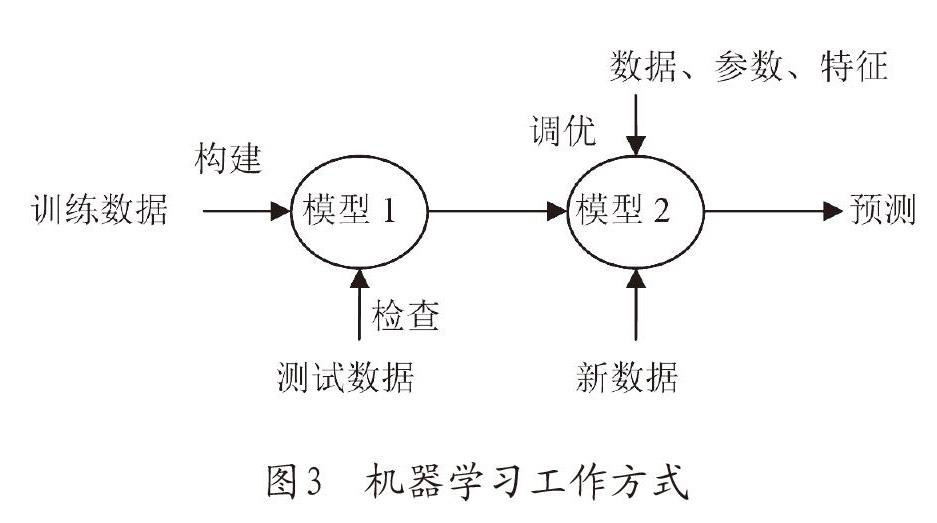
自然語言處理的一大特點就是它現在越來越多地使用機器學習(machine learning)的方法來獲取語言知識(馮志偉,2010)。機器學習是用來研究如何通過計算的手段,利用經驗來改善系統自身性能的一門學科(周志華,2016:1)。具體來說,計算機從大量數據中得出“模型”的算法,也就是前面提到的“學習算法”,然后將經驗數據提供給計算機,它就會從這些數據中產生新的模型。最后,當有新數據出現時,計算機就可以基于生成的模型幫助人類做出相應的判斷。可參見圖3:
圖3給我們形象直觀地展現了機器學習的工作方式。從圖3可以看出,首先,要將大量的訓練數據提供給計算機,構建一個初始模型,即模型1。然后,用測試數據對初始模型進行檢查,并不斷對其進行完善,接著會得到一個訓練完好的模型,即模型2。最后,再將新數據提供給模型2,人類就可以通過計算機、利用模型2去作出判斷和預測。在此之后,更多的數據,不同的特征,或調整過的參數,都可以用來提升算法的性能表現,使它不斷完善。
(二)機器翻譯
機器翻譯,就是使用計算機進行翻譯,即把一種自然語言生成另一種自然語言而又無需人類幫助的計算機系統(Hutchins et al., 1992:3)。這里的自然語言區別于人工語言,如計算機編程語言等為實現某些特定目的而創造的語言。李沐等(2018:2)指出,機器翻譯是自然語言處理研究的一個分支,它在處理過程中會涉及到很多自然語言處理的經典問題。如數據挖掘及清洗、詞字切分、詞性標注、句法分析等。此外,機器翻譯還涉及機器學習算法中的應用。就此而言,機器翻譯是一項復雜的系統工程。
機器翻譯大體可以分為基于規則的機器翻譯方法和基于語料庫的機器翻譯方法。根據建模的不同,基于語料庫的機器翻譯方法又可以分為基于實例的機器翻譯方法、統計機器翻譯方法和神經機器翻譯方法。
在機器翻譯中,數據也稱語料(corpus),也就是說基于語料庫的機器翻譯都需要大量的語料作為訓練數據來訓練模型。不同的語料類型被用來訓練不同的模型,如目標語言語料用來訓練語言模型(刻畫句子的流暢度),平行語料用來訓練翻譯模型(學習、獲取翻譯知識)等。根據研究需要,本文對李沐等(2018:38)所繪制的統計機器翻譯系統框架圖進行了改編。具體如圖4所示:
這里就以圖4中語言模型的構建為例,來簡要說明該過程中自然語言處理的應用。如圖4所示,首先,以目標語言語料為訓練數據,計算機從中學習知識并根據這些知識建立語言模型。但由于訓練數據,也就是目標語言語料的規模具有有限性,無法對所有真實樣例數據進行覆蓋,所以通常會使用數據平滑(data smoothing)算法來對語言模型進行完善,很多自然語言處理的應用都使用語言模型產出文本,這些模型基于前面出現的單詞及語境,被專門訓練來預測接下來要出現的單詞(Ranzato,M.et al.,2016)。最終語言模型建立后就可以用來估算自然語言中每個句子出現的可能性,從而提高最佳譯文的選擇質量。
如前所述,無論是在模型訓練還是在概率模型建立的過程中,都會涉及到機器學習算法。機器翻譯中各種模型的建立,也都需要各種參數特征來進一步完善它們的算法。由此可見,機器翻譯是自然語言處理的一個重要研究方向。通過以上例子,也可以看出自然語言處理技術在機器翻譯中的地位可謂是舉足輕重。
三、機器翻譯研究的探討
(一)機器翻譯與人工翻譯
隨著人工智能與機器翻譯的發展,“機器翻譯是否會取代人工翻譯”這一話題也引起了熱議。胡開寶、李翼(2016)認為,機器翻譯與人工翻譯之間的關系是互補與互動的關系。具體來說,機器翻譯以人工翻譯為基礎,機器翻譯能協助人工翻譯,同時也需要人工翻譯來進行譯后潤色。作者建議人工翻譯跟機器翻譯合理分工,并預測未來將是人機共存、人機互補的時代。祝朝偉(2018:101)指出,“機器取代人是一個偽命題”,機器在處理一些文本時始終離不開人的幫助,它的服務對象永遠是人,機器翻譯“能夠譯”但未必像人那般“譯得好”,文學翻譯等是機器翻譯永遠也無法勝任的。同時,他也認為,人機結合是未來人類需要努力的方向。
筆者認為,“機器翻譯是否能代替人工翻譯”這一問題就像“人工智能是否能代替人類”一樣,值得深入探討。機器翻譯與人工智能幾乎同時產生,幾十年來同呼吸共命運,在各個學科的交匯合作下,在社會經濟發展需求的推動下,人工智能已得到非常迅猛地發展。在這種時代背景下,機器翻譯也得到了很大發展并逐步走向商品化、實用化(馮志偉,2018)。然而,現在的人工智能僅擅長單項任務,能執行人類簡單的指令,即“弱人工智能”。在當前的技術水平下,人工智能還遠遠不能超越人類。同樣,目前的神經機器翻譯系統也只是在特定的應用領域(如新聞翻譯、日常的會話等)翻譯效果較好,如果換到其他領域,效果未必盡如人意。因此,“機器翻譯將會取代人工翻譯,翻譯人員即將失業”這類話都是言過其實,甚至可以說是危言聳聽。
誠如張政(2006:182)所言,機器翻譯是人類重建巴別塔的腳手架。機器翻譯扮演的只是一個工具的角色,它只是按照人類的意志,輔助人類減少翻譯工作的強度和量度的附庸產品。即便將來機器翻譯軟件的智能水平有了大幅度的飛躍,那也是人類認知水平不斷提升的結果。未來要繼續促進人文與科技的融合,提高翻譯效率,提升翻譯質量,建立新型的機器翻譯與人工翻譯的關系。
四、自然語言處理應用于機器翻譯的研究展望
從21世紀初,隨著電子科技的突飛猛進,機器翻譯也駛入了快車道。在數據和算法技術驅動下的機器翻譯已取得了巨大的成功。基于計算機技術、自然語言處理技術和機器學習算法的不斷發展,未來機器翻譯也會不斷革新。筆者將自然語言處理應用于機器翻譯的未來趨勢總結如下:
第一,數據規模的變遷。雙語數據規模越大,翻譯質量也就越高,由此構建的模型就可以學習到更為豐富的翻譯知識。隨著科技的發展,更多的數據可以被收集,雖然這些數據可能并不代表馬上就可以用來做訓練語料,但是它會給機器翻譯帶來更多的可能性,避免做更多的數據挖掘,可以利用機器半自動式對語料進行篩選,讓技術不斷獲得提升。
第二,新算法的變革。算法的變革在機器翻譯發展中扮演了至關重要的角色。隨著人工智能的迅猛發展,深度學習在機器翻譯中也取得了很好的效果。應用深度學習方法而構造的神經機器翻譯系統在譯文的準確率和流暢度上都有了顯著的提高。陳俊龍、劉竹林(2017)提出了寬度學習系統,可以提升訓練速度并已呈現出一定的優勢。總之,可以看出,隨著大計算、大算法的不斷推進,神經機器翻譯不會是機器翻譯的終極,接下來會產生更為先進高效的機器翻譯方法。
第三,運算的變化。高性能的計算研究與機器翻譯技術相融合,這樣翻譯質量與翻譯性能就會進一步得到提高。比如運算的加速,可能就會縮短語音翻譯的延遲;再比如說更多的運算定制就有可能實現更多的運算任務,這些運算任務放到不同的機器翻譯產品上就有可能更加方便日常生活中翻譯的使用。
自然語言處理在機器翻譯中得到廣泛應用,并不斷取得新的突破,這不僅為機器翻譯研究打開了更為廣闊的視野,還為其發展添入了更多的生機與活力,使巴別塔的重建成為可能。本文介紹了自然語言處理和機器翻譯的一些基本內容,簡要舉例說明了自然語言處理在機器翻譯中的應用,并對機器翻譯的研究進行了探討。事實上,自然語言處理在其他領域也有著相當多的應用,比如在教育領域就取得豐碩的成果,而人們學習和使用語言的方法對自然語言處理的具體研究也有著相當重要的啟示作用(俞士汶、柏曉靜,2006)。因此,在知識經濟的時代背景下,自然語言處理技術在各個領域的研究應相互借鑒,根據人類的不同需求,結合各種運算任務應用到產品當中去,以更好地服務人類。此外,隨著對人類大腦認知機制“黑箱”研究的不斷深入,相信機器翻譯的質量與效率也會得到顯著提高。
參考文獻:
[1]Chen,C.L.P. & Z.L.Liu.Broad Learning System: An Effective and Efficient Incremental Learning System Without the Need for Deep Architecture [J].IEEE Transactions on Neural Networks and Learning Systems,2017,(99).
[2]Hutchins,W.J.Machine Translation:Past,Present,Future[M].Chichester: Ellis Horwood Limited,1986.
[3]Manaris,B.Natural Language Processing: A Human-Computer Interaction Perspective [J].Advances in Computers,1998,(8).
[4]Ranzato,M.,S.Chopra.,M.Auli. & W.Zaremba.Sequence Level Training with Recurrent Neural Networks[A].International Conference on Learning Representations[C].2016.
[5]馮志偉.自然語言處理的形式模型[M].合肥:中國科學技術大學出版社,2010.
[6]馮志偉.機器翻譯與人工智能的平行發展[J].外國語(上海外國語大學學報),2018,(6).
[7]胡開寶,李翼.機器翻譯特征及其與人工翻譯關系的研究[J].中國翻譯,2016,(5).
[8]李沐,劉樹杰,張冬冬,周明.機器翻譯[M].北京:高等教育出版社,2018.
[9]劉穎.計算語言學[M].北京:清華大學出版社,2014.
[10]王萌,俞士汶,朱學鋒.自然語言處理技術及其教育應用[J].數學的實踐與認識,2015,(20).
[11]俞士汶,柏曉靜.計算語言學與外語教學[J].外語電化教學,2006,(5).
[12]張政.計算機翻譯研究[M].北京:清華大學出版社, 2006.
[13]張政.計算語言學與機器翻譯導論[M].北京:外語教學與研究出版社,2010.
[14]周志華.機器學習[M].北京:清華大學出版社,2016.
[15]祝朝偉.機器翻譯要取代作為人的譯者了嗎?——兼談翻譯人才培養中科技與人文的關系[J].外國語文, 2018,(3).
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
