社交網絡中的敏感內容檢測方法研究
2019-08-12 06:15:44孟旭陽徐雅斌
現代電子技術 2019年15期
孟旭陽 徐雅斌
摘 ?要: 為了有效解決社交網絡中對敏感詞進行變形處理而逃避被檢測和過濾的問題,首先識別敏感詞及敏感詞的變形詞,并采用敏感詞指紋匯聚方法將敏感詞的變形詞與原詞進行關聯。在此基礎上,采用語義指紋技術檢測重復發布的敏感內容。其次,建立基于多任務學習的卷積神經網絡模型(MTL?CNN),綜合敏感性和情感傾向兩個方面對發布文本進行檢測。對比實驗結果表明,提出的敏感內容檢測方法具有較高的處理速率和檢測準確率。
關鍵詞: 社交網絡; 敏感內容; 指紋匯聚; 情感傾向; 多任務學習; 處理速率; 檢測準確率
中圖分類號: TN915?34; TP391 ? ? ? ? ? ? ? ? ? 文獻標識碼: A ? ? ? ? ? ? ? ? ? ? ?文章編號: 1004?373X(2019)15?0072?07
Research on sensitive content detection in social networks
MENG Xuyang1, 2, XU Yabin1, 2
(1. Beijing Key Laboratory of Internet Culture and Digital Dissemination Research, Beijing Information Science & Technology University, Beijing 100101, China;
2. School of Computer, Beijing Information Science & Technology University, Beijing 100101, China)
Abstract: In order to solve the problem in social networks that the sensitive words are often processed by distortion for exception from detection and filtering, the deformable words of sensitive words are identified, and the sensitive words fingerprint convergence method is used to associate the variant words of the sensitive words with original sensitive words. On this basis, the semantic fingerprint technology is used to detect repetitively published sensitive content. A multi?task learning based convolutional neural network (MTL?CNN) model is established to detect the published texts in the aspects of comprehensive sensitivity and emotional tendency. The comparison experiment results show that the proposed sensitive content detection method has high processing speed and detection accuracy.
Keywords: social network; sensitive content; fingerprint convergence; emotional tendency; multi?task learning; processing speed; detection accuracy
0 ?引 ?言
社交網絡已經成為廣大網民溝通交流的重要平臺和獲取信息的重要入口。然而,社交網絡的廣泛應用同樣給敏感內容的傳播提供了網絡空間。少數人借助社交網絡發布暴力恐怖信息和政治敏感內容。如何高效、準確地實現敏感內容檢測,減少誤判、漏判現象,打造健康安全的社交網絡環境成為巨大挑戰。基于關鍵詞匹配的檢測方法[1?4],忽略了變形詞與原詞之間的關聯性。基于傳統機器學習的敏感內容檢測方法[5?8]準確率較低。文獻[9?11]在敏感主題的基礎上考慮情感傾向因素獲得較高的準確率,但需要訓練兩個模型,效率不高。文獻[12?14]采用深度學習方法,獲得了較好的效果。
針對現有研究中存在的問題,本文提出的敏感內容檢測方法不僅可以有效提高檢測的準確性,而且能夠很好的滿足檢測的實時性。
1 ?敏感內容檢測框架
本文提出的敏感內容檢測框架主要由三部分組成,如圖1所示。
1) 敏感詞指紋匯聚:在對用戶待發布文本進行預處理的基礎上,識別敏感詞和各種變形偽裝敏感詞。通過本文提出的敏感詞指紋匯聚方法,對識別出的敏感變形詞打上指紋值將其與原詞關聯。其中,根據是否出現敏感詞、變形情況等判斷文本是否為可疑文本。
圖1 ?敏感內容檢測框架圖
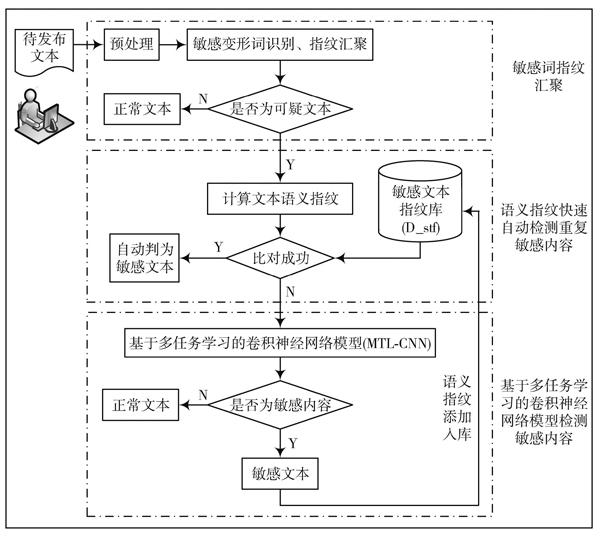
2) 通過語義指紋技術快速自動檢測重復敏感內容:對1)中判斷為可疑文本的內容,采用本文改進的基于語義指紋的快速相似敏感內容檢測算法生成文本的語義指紋,并與事先建好的敏感文本指紋庫(D_stf)進行快速匹配,實現快速自動檢測重復敏感內容。
3) 基于多任務學習的敏感內容檢測卷積神經網絡模型:對于在敏感指紋庫沒有比對成功的可疑文本采用基于多任務學習的卷積神經網絡模型進行檢測。若檢測結果為敏感文本,則將其語義指紋添加到D_stf庫中,方便下次敏感內容重復檢測。
2 ?敏感詞檢測
2.1 ?敏感詞變形詞匯識別
基于原始的敏感關鍵詞通過與敏感詞庫進行匹配即可。然而,為了躲避檢測,敏感關鍵詞都進行了變形處理。比如,夾雜特殊符號“#”“*”“&”等,拼音/拼音首字母代替字,繁體字代替,同音字代替等。
經分析發現,同音字替換由于前后都不成詞,往往在分詞時會出現連續單字(3個及3個以上),而正常文本很少出現這種情況。除此之外,敏感詞常出現在偽裝現象(如拼音替代)附近,因此只需對偽裝現象周圍的詞進行重點檢測即可,避免傳統方法要將整個文本轉化為拼音與敏感詞庫匹配而導致效率低下的問題。
因此,本文在已有方法的基礎上做出改進,改進部分的敏感詞變形詞匯識別算法如下:
輸入:社交網絡中的待發布文本T,敏感關鍵詞表D。
輸出:成功識別的敏感詞變形詞匯集合[S]。
1) 去除文本中夾雜的特殊符號,進行繁簡轉化;
2) 分詞處理,若分詞結果中出現連續3個及以上的單字,則將連續單字轉化為對應的拼音;
3) 若分詞結果中出現拼音/拼音首字母,則以此拼音/拼音首字母為中心,將前后4個詞匯均轉為漢字對應的拼音/拼音首字母;
4) 判斷步驟2)、步驟3)中連續的拼音或拼音首字母序列組合是否為敏感詞匯所對應的拼音或拼音首字母。若是,則成功識別為詞庫中該敏感詞匯的變形詞匯,并加入集合[S]。
2.2 ?敏感詞指紋匯聚
雖然對敏感詞進行了變形偽裝,但其語義并沒有發生變化。針對這種情況,本文提出將各種變形詞打上指紋并與原詞進行關聯,即實現敏感詞指紋匯聚,從語義角度保證變形詞與原詞的關聯性。
敏感詞指紋(F)定義:使用Jenkins Hash[15]哈希函數對原始的敏感詞[wi]進行哈希處理,得到一個[k]位的哈希值即為該敏感詞[wi]的指紋值[fi],每類敏感詞的指紋具有唯一性。
例如:敏感詞[wi]=“打砸搶燒”,為了便于說明問題,使用Jenkins Hash函數得到二進制hash值為100110,即[wi]對應的指紋值[fi]=“100110”(此處示例[k]=6)。注意,實際實驗采用64位指紋。
敏感詞指紋匯聚是指將敏感詞[wi]的各種變體詞匯[wi_j]均映射到原始敏感詞的指紋[fi]上。這樣無論多少個變體詞匯,每個變體詞匯[wi_j]均代表這個原始的敏感詞[wi]。以“打砸搶燒”為例,敏感詞指紋匯聚原理及過程如圖2所示。
圖2 ?敏感詞指紋匯聚原理及過程示意圖

本文共收集2 289個敏感關鍵詞,首先通過哈希函數計算每個敏感詞的指紋值,并構建如圖2所示的敏感指紋詞庫(D_sw)。從圖2中可看出,當敏感詞[wi]=“打砸搶燒”,對應的敏感詞指紋[fi]=“100110”,識別出的各種變形偽裝詞匯都將其打上指紋[fi],則此時[n]個詞匯[wi_1,wi_2,wi_3,…,wi_n]對應的指紋均為[fi],與原詞[wi]關聯。
3 ?相似敏感內容檢測
3.1 ?語義指紋的生成
由于受社交網絡信息傳播的時效性影響,不法分子會經常重復發布相同或相似的敏感內容來保證傳播效果。為保證檢測的實時性,采用語義指紋技術快速自動檢測這些重復發布的敏感內容。
Simhash[16?17]算法不僅檢測的準確率高、速度快,同時還可根據指紋距離反映出文本內容間的差異程度,被認為是目前文本相似檢測處理中最有效的算法之一[18]。
但是,由于在社交網絡中充滿了口語化表達,加之還存在著敏感詞變形偽裝現象,經典Simhash算法對相似敏感內容的檢測性能并不是很理想。為此,本文對Simhash算法進行改進,形成SWFC?SFG語義指紋生成方法,對應算法如下:
輸入:社交網絡中的待發布文本T。
輸出:文本T的語義指紋[F],指紋長度[k]設為64位。
1) 對文本T分詞,得到詞的集合[W],[W=]{[w1,w2,…,wn]};
2) 對文本進行敏感詞和敏感變形詞識別,并將各種敏感變形偽裝詞進行指紋匯聚,指紋值為[k]位的二進制hash值;
3) 對T中剩余每個元素(詞),利用哈希函數計算得到[k]位的二進制hash值,以詞頻作為權重,根據元素各位的hash值,進行調整。調整原則:若當前詞的hash值第[i]位為1,則將其置為該詞的權值,若為0,則將其置為負權值;
4) 將T中所有元素在3)中得到的hash值集合,按位進行求和運算,結果記為[F];
5) 確定語義指紋[F]的值:若[F]的第[i]位為正數,則指紋[F]的第[i]位置為1;反之,置為0。
SWFC?SFG語義指紋生成方法融入敏感變形詞指紋匯聚過程,使得敏感變形詞與原詞采用相同的編碼表示這組敏感詞,避免了Simhash算法不支持同義詞、敏感變形詞與原詞之間的語義問題,從而提高了敏感文本相似度檢測性能。
3.2 ?相似敏感文本檢測
得到文本的語義指紋后,通過兩兩比較語義指紋間的漢明距離,漢明距離越小,則代表文本的語義越相似。
事先建立敏感文本指紋庫D_stf,將已知敏感文本的語義指紋入庫,并不斷更新D_stf,再次遇到將會被自動識別。相似敏感文本檢測過程如下:
1) 由SWFC?SFG算法得到文本的語義指紋[Fi]。
2) 查詢敏感文本指紋庫D_stf,查看漢明距離小于[R]([R]通過實驗得到最佳值)的指紋是否存在。若存在,則認為當前文本與D_stf中某條文本表達一致,那么這個文本將被直接判定為敏感文本。
4 ?基于多任務學習的敏感內容檢測卷積神經網絡模型(MTL?CNN)
多任務學習[19](Multi?Task Learning,MTL)是一種機器學習的方法,最早由Caruana在1997年提出。多任務學習的目標在于把多個相關任務放在一起學習,利用任務之間的相關性,找尋任務之間有價值的共性,通過在多個任務之間共享,相互協助模型的訓練[20]。特別是在數據量較少的情況下,這種知識的共享對每個任務的學習格外有幫助[21]。
文本內容往往具有一定的語義傾向,含有敏感詞匯但卻并不一定是敏感內容。只有根據文字所表達的真實含義和情感傾向去鑒別才是正確的判斷。
結合兩個任務(Task1:敏感內容檢測;Task2:文本情感極性識別)來構造多任務學習的卷積神經網絡(Multi?task Learning Convolution Neural Networks,MTL?CNN)模型,用以實現敏感內容檢測。其中,Task1為主任務,Task2為輔助任務。
相比LSTM等模型,基于卷積神經網絡的方法可以接收平行化輸入的文本信息,大大降低了網絡模型的訓練時間。同時,卷積神經網絡有著優異的特征自抽取能力和端到端的分類功能。
本文建立的基于多任務學習的敏感內容檢測卷積神經網絡模型如圖3所示。
從圖3可以看出,首先將完成預處理以及分詞后的文本通過訓練好的詞向量模型順序映射為詞向量,此時文本內容轉化為詞向量矩陣,并作為MTL?CNN敏感內容檢測的輸入。然后,由MTL?CNN模型對輸入層的詞向量矩陣進行卷積操作。由于MTL?CNN模型同時關注兩個任務的優化目標,兩個任務在訓練過程中共享參數,使得模型能夠自動獲取文本中豐富的局部特征向量,其中不僅包括文本敏感性特征,還包括情感極性特征。通過模型的訓練過程,可以很好的結合兩個任務的文本分類標簽,通過卷積運算獲得一系列的規則。例如:“負面敏感性詞匯+正面情感極性=敏感內容”“負面敏感性詞匯+負面情感極性=非敏感內容”“正面敏感性詞匯+負面情感極性=敏感內容”等,使得此模型很好地應用于最終的敏感內容分類。
卷積過后,是池化(pooling)操作,即降維。選擇對兩個任務最終分類結果影響較大的特征。
擁有來自各個卷積核的輸出向量,將其進行拼接。在特征拼接之前的所有參數為Task1和Task2共享,特征拼接之后,兩個任務由各自的參數進行分類。最后,兩個任務均通過softmax層得到每個任務屬于不同分類的概率分布情況。
以Task1的高準確率為最終目標,當Task2對Task1的作用不明顯時,或者Task1損失值小于某一限定值或迭代次數超出規定的最大值時,停止更新網絡權值,訓練完成。
5 ?實驗分析
本文使用新浪微博數據集,其共包含2 649 567條微博數據。從此數據集中收集政治相關主題內容共21 451條,其中,實際為政治敏感非法內容2 318條(由于涉及敏感內容,收集的此類敏感非法內容較少)。其他主題的文本隨機取21 500條。從情感傾向上看,正向文本23 784條,負向文本19 167條。
5.1 ?基于語義指紋的相似敏感內容檢測實驗
1) [R](閾值)的確定
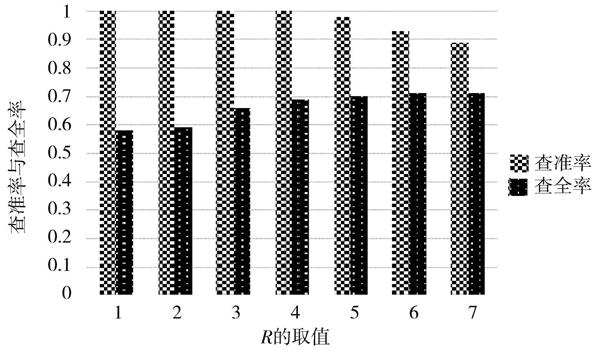
構建一個包括1 000條文本(其中重復或相似文本數為100)的數據集,通過相似檢測的查全率、查準率指標來觀察不同[R]值對結果的影響。本文分別對閾值1~7進行了實驗,結果如圖4所示。
從圖4中可以看出,當[R≥5]時,查準率開始下降,即存在將實際非相似的文本判斷為相似文本的情況。如果文本與已知敏感內容相似,則會直接被判為敏感內容。為了避免誤判,需保證查準率為1,由此可以確定[R]的最佳取值為4。
2) 改進前后算法查準率、查全率及[F]值對比
將改進后的SWFC?SFG算法與Simhash算法進行比較,在同一數據集上的測試結果如表1所示。
圖4 ?不同[R]值下本文算法的查準率與查全率
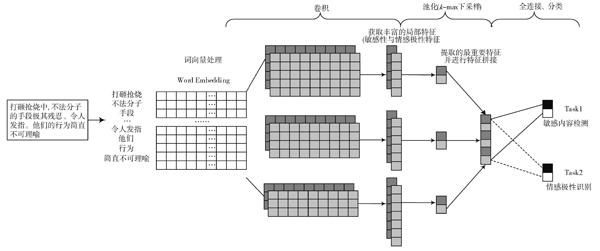
表1 ?算法對比

? ? ? ? ??
3) 不同數量級文本相似檢測耗時對比
將SWFC?SFG算法與傳統的編輯距離算法(Levenshtein Distance)進行對比,不同數量級的文本相似度檢測計算耗時情況如圖5所示。
圖5 ?算法計算耗時對比圖
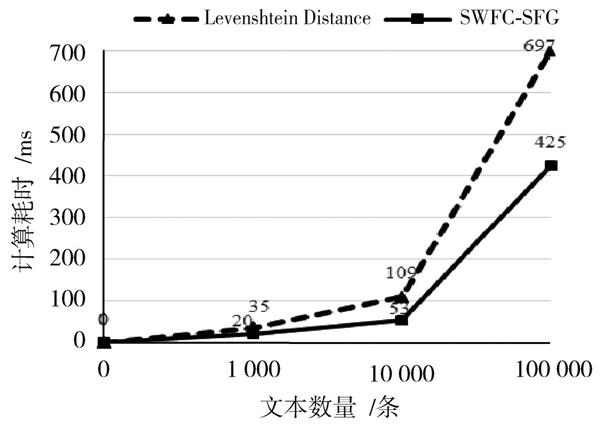
從圖5可看出,SWFC?SFG算法要優于傳統的編輯距離算法,隨著文本數量的增加,耗時增加并不明顯。
5.2 ?基于多任務學習的敏感內容檢測實驗
1) 實驗和模型參數設置
首先對數據集進行人工標注:每條數據有兩個標簽。其中,label1表示是否為政治敏感內容;label2表示情感極性。
分類前,采用中科院分詞工具NLPIR[22]進行分詞,并采用gensim的word2vec工具訓練詞向量空間。訓練參數配置如下:選用CBOW(Continuous Bag?of?Words)模型[23] ;上下文滑動窗口大小為8;單詞向量維度設為300。對于未出現在詞向量語料中的詞匯,則進行隨機初始化操作。
基于多任務學習的卷積神經網絡分類實驗采用的編程語言為Python 3.6,工具包為Google開源深度學習框架TensorFlow,其他網絡參數設置如表2所示。
表2 ?基于多任務學習的卷積神經網絡模型中的參數設置

模型總的損失函數式(3)和每個任務的損失函數式(4)中的參數[λ],[λl2]經交叉驗證[24]取經驗值[λ]= 0.05,[λl2] = 0.001。
2) 模型對比實驗
為驗證本文方法的合理性和性能,在同一數據集上,與傳統基于單任務的敏感內容檢測方法進行對比實驗。本文采用最常用的10折交叉驗證方式,并以查準率(Precision)、查全率(Recall)、F?Score作為評價指標。在相同測試集上進行實驗,結果如圖6所示。由圖6可看出本文的MTL?CNN模型優于傳統的分類模型。
圖6 ?MTL?CNN與傳統單任務敏感內容檢測實驗對比圖
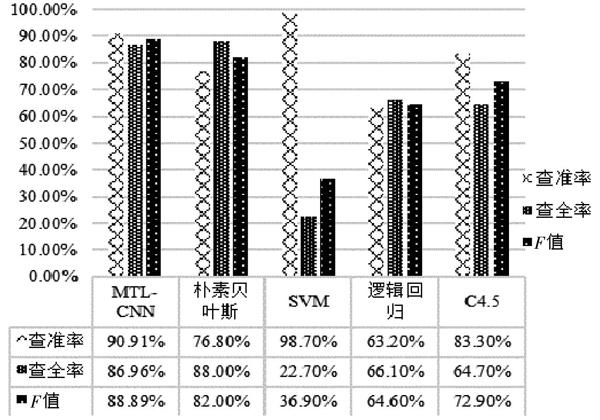
為了進一步說明多任務學習對本文研究的有效性,在同樣數據集下與單任務的CNN,LSTM模型進行了對比。除此之外,由于文獻[11]在敏感信息識別時同樣考慮了情感極性因素,但基于兩個單任務模型分別進行。因而也與文獻[11]進行了對比實驗,結果如表3所示。
從表3結果可看出,本文基于多任務的卷積神經網絡檢測模型在各個指標上均優于單任務的CNN,LSTM模型。在與文獻[11]的對比實驗中,本文方法在各指標上也均有較大提升,由此也證明了采用的兩個任務共同學習方法的有效性。同時也體現了本文基于多任務學習的方法在數據量較少的情況下,具有明顯的優勢。
表3 ?對比實驗結果

? ??
圖7 ?模型的時效性對比圖

由圖7可見,本文方法的檢測耗時更少,能夠更好的滿足實時檢測的需要。而文獻[11]需要訓練兩個模型,首先得到情感傾向,然后再通過敏感度模型進行計算,最終綜合判定,從而耗時較長。
3) 模型擴展與推廣
MTL?CNN模型同樣適用于任何類型的敏感內容檢測。例如:對于黃、賭、毒、暴力恐怖等敏感內容,只需獲取相應的數據語料并進行標注,確保每條文本均包括敏感內容與情感極性兩類標簽,然后對模型進行訓練即可。
此外,若要同時檢測多類敏感內容,只需準備好相應的數據并將模型的Task1部分的二分類任務轉變為多分類任務即可,完成到多個類別的映射。
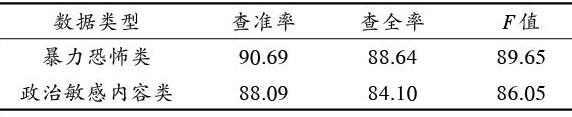
為了驗證模型的可擴展性,收集了暴力恐怖類型數據,進一步針對政治敏感和暴力恐怖這兩類敏感內容數據開展實驗。兩種類型數據量保持一致,重新訓練模型后,對測試集進行檢測所得實驗結果如表4所示。
表4 ?擴展性實驗結果
6 ?結 ?論
針對各種敏感變形詞問題,提出敏感詞指紋匯聚方法,并將其引入指紋生成算法,提出SWFC?SFG語義指紋生成方法,能夠快速、自動檢測相似或重復敏感內容。本文還進一步提出并構建MTL?CNN模型,結合敏感性與文本情感極性兩個任務共同學習。通過實驗分析發現,本文方法不僅準確率有了較大提升,而且能夠保證檢測的實時性。此外,實驗表明MTL?CNN模型仍具有很好的可擴展性。
參考文獻
[1] 段磊,唐常杰,左劼,等.Web實時環境兩級過濾中文文本內容自學習算法[J].計算機科學與探索,2011,5(8):695?706.
DUAN Lei, TANG Changjie, ZUO Jie, et al. Two level filte?ring Chinese text content self?learning algorithm in Web real?time environment [J]. Journal of frontiers of computer science and technology, 2011, 5(8): 695?706.
[2] 薛朋強,努爾布力,吾守爾[?]斯拉木.基于網絡文本信息的敏感信息過濾算法[J].計算機工程與設計,2016,37(9):2447?2452.
XUE Pengqiang, Nuet Buli, Wushour Silamu. Sensi?tive information filtering algorithm based on network text information [J]. Computer engineering and design, 2016, 37(9): 2447?2452.
[3] 徐建忠,羅準辰,張亮.語義擴展技術在敏感數據識別中的應用研究[J].現代電子技術,2016,39(12):80?82.
XU Jianzhong, LUO Zhunchen, ZHANG Liang. Application of semantic extension technology in sensitive data recognition [J]. Modern electronics technique, 2016, 39(12): 80?82.
[4] 孫艷,周學廣,陳濤.意會關鍵詞信息取證方法[J].計算機工程,2011,37(19):266?269.
SUN Yan, ZHOU Xueguang, CHEN Tao. Method of sense keywords information forensics [J]. Computer engineering, 2011, 37(19): 266?269.
[5] 陳洋.維吾爾語不良文本信息過濾技術研究[D].烏魯木齊:新疆大學,2014.
CHEN Yang. Research on the filtering method of Uyghur adverse text information [D]. Urumqi: Xinjiang University, 2014.
[6] ZENG J, DUAN J, WU C. Adaptive topic modeling for detection objectionable text [C]// 2013 IEEE/WIC/ACM International Joint Conferences on Web Intelligence. Atlanta: IEEE, 2013: 381?388.
[7] 俞浩亮.互聯網不良信息采集抽取及識別技術研究[D].昆明:昆明理工大學,2016.
YU Haoliang. Research on extraction and recognition technology of internet bad information [D]. Kunming: Kunming University of Science and Technology, 2016.
[8] ZHONG H, LI H, SQUICCIARINI A, et al. Con?tent?driven detection of cyberbullying on the instagram social network [C]// 2016 International Joint Conference on Artificial Intelligence. New York: AAAI Press, 2016: 3952?3958.
[9] 孟璽,周西平,吳紹忠.語義分析在反恐研究領域的應用研究[J].情報雜志,2017,36(3):13?17.
MENG Xi, ZHOU Xiping, WU Shaozhong. The ap?plication research of semantic analysis in the field of anti?terrorism [J]. Journal of intelligence, 2017, 36(3): 13?17.
[10] 劉梅彥,黃改娟.面向信息內容安全的文本過濾模型研究[J].中文信息學報,2017,31(2):126?131.
LIU Meiyan, HUANG Gaijuan. Research on text filter model for information content security [J]. Journal of Chinese information processing, 2017, 31(2): 126?131.
[11] 李揚,潘泉,楊濤.基于短文本情感分析的敏感信息識別[J].西安交通大學學報,2016,50(9):80?84.
LI Yang, PAN Quan, YANG Tao. Identification of sensitive information based on short text sentiment analysis [J]. Journal of Xian Jiaotong University, 2016, 50(9): 80?84.
[12] NEERBEKY J, ASSENTZ I, DOLOG P. TABOO: detecting unstructured sensitive information using re?cursive neural networks [C]// 2017 IEEE International Conference on Data Engineering. San Diego: IEEE, 2017: 1?7.
[13] ALI S H A, OZAWA S, NAKAZATO J, et al. An autonomous online malicious spam email detection system using extended RBF network [C]// 2015 International Joint Conference on Neural Networks. Kil?larney: IEEE, 2015: 1?7.
[14] 景亞鵬.基于深度學習的欺騙性垃圾信息識別研究[D].上海:華東師范大學,2014.
JING Yapeng. Research of deceptive opinion spam recognition based on deep learning [D]. Shanghai: Central China Normal University, 2014.
[15] JENKINS B. A hash function for hash table lookup [EB/OL]. [[1997?02?23] .] https: //www.researchgate.net/publication/2449?57345_A_hash_function_for_hash_table_lookup.
[16] CHARIKAR M S. Similarity estimation techniques from rounding algorithms [C]// Thirty?Fourth ACM Symposium on Theory of Computing. Quebec: ACM, 2002: 380?388.
[17] MANKU G S, JAIN A, SARMA A D. Detecting near?duplicates for Web crawling [C]// 2007 International Conference on World Wide Web. Banff: ACM, 2007: 141?150.
[18] SADOWSKI C, LEVIN G. Simhash: Hash?based similarity detection [EB/OL].[ 2007?05?12]. https://core.ac.uk/display/23320221.
[19] CARUANA R. Multi?task learning [M]. Pittsburgh: Carnegie Mellon University, 1997: 5?50.
[20] 歐陽寧,馬玉濤,林樂平.基于多任務學習的多姿態人臉重建與識別[J].計算機應用,2017,37(3):896?900.
OUYANG Ning, MA Yutao, LIN Leping. Multitask learning based multi?pose face reconstruction and recognition [J]. Journal of computer applications, 2017, 37(3): 896?900.
[21] 邵蔚元,郭躍飛.多任務學習及卷積神經網絡在人臉識別中的應用[J].計算機工程與應用,2016,52(13):32?37.
SHAO Weiyuan, GUO Yuefei. Application of multi?task lear?ning and convolutional neural network in face recognition [J]. Computer engineering and applications, 2016, 52(13): 32?37.
[22] NLPIR. NLPIR?ICTCLAS system [EB/OL]. [2018?02?15]. http: //ictclas.nlpir.org/.
[23] GT. Word2Vec (Part 2): NLP with deep learning with tensorflow (CBOW) [EB/OL]. [2015?03?05]. http://www.thushv.com/natural_language_processing/word2vec?part?2?nlp?with?deep?learning?with?tensorflow?cbow/.
[24] 李航.統計學習方法[M].北京:清華大學出版社,2012:14?15.
LI Hang. Statistical learning methods [M]. Beijing: Tsinghua University Press, 2012: 14?15.
猜你喜歡
中華詩詞(2020年1期)2020-09-21 09:24:52
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
小學生作文(中高年級適用)(2018年5期)2018-06-11 01:22:56
中學生數理化·七年級數學人教版(2017年11期)2017-04-23 07:18:00
數學大王·中高年級(2016年12期)2016-12-26 21:37:36
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
