一種基于K均值聚簇的虛擬機分類與部署方法
2019-08-14 10:02:18李俊雅牛思先
計算機應用與軟件 2019年8期
李俊雅 牛思先 程 星
1(濟源職業技術學院 河南 濟源 459000)2(百色學院信息工程學院 廣西 百色 533000)3(鄭州大學計算機學院 河南 鄭州 450001)
0 引 言
云計算技術的出現使得大規模數據中心的建立可以更好地滿足社會對于計算能力的巨大需求[1]。然而,這種大規模云數據中心正在消耗龐大的電力資源,進而導致的高能耗和巨量的碳排放問題。研究表明[2],2013年,全球數據中心的總體電力消耗約4.35千兆瓦特,并且以每季增長速率15%遞增。云數據中心的高能耗會導致一系列問題,包括:能量浪費、較低的投入產出率、系統穩定性以及帶來溫室效應的碳排放[3]。
另一個關鍵問題是如何在確保服務質量QoS的前提下降低數據中心能耗。云系統中的QoS通常以服務等級協議SLA的形式表達。然而,目前數據中心的資源利用率僅為50%左右,較低的資源利用率會導致巨大的能量浪費,改善主機資源利用率將有助于降低能耗。但是,一味改進主機資源利用率反過來會影響系統的QoS交付。因此,對于云數據中心而言,必須均衡地考慮能耗降低和SLA違例問題,設計高能效的部署方法。
為了降低能耗和SLA違例,實現數據中心的高能效,本文設計一種新的虛擬機部署算法,算法將根據處理負載,以自適應的方法設置三個門限值,將主機劃分為具有不同負載的四種類型,包括:低載主機、輕量負載主機、正常負載主機和重載主機,并通過設計的虛擬機遷移選擇算法對低載主機和重載主機進行虛擬機遷移,同時維持輕量負載主機和正常負載主機不變,以此在能耗降低和性能保障上作出均衡。
1 相關研究
目前,云數據中心的能耗管理方法分為三種:動態性能擴展DPS方法[4-6]、基于門限值的啟發式方法[7-11]和基于歷史數據統計分析的決策方法[12-14]。DPS方法中,系統組件可動態調整其性能以節省能耗,如逐漸降低CPU的頻率或電壓。DPS可在資源未充分利用的情況下大幅降低能耗。采用DPS方法的關鍵技術是動態電壓/頻率調整DVFS,DVFS可分為三類:基于間隔的DVFS、基于任務內的DVFS和基于任務間的DVFS。基于間隔的DVFS方法利用過去時段的CPU利用數據預測未來的利用率,并調整CPU性能,該方法在多核系統中比較最優在線算法具有更好的性能。相比而言,基于任務內的DVFS方法區分不同的任務并將其分配至不同速率的CPU上,該方法在負載提前預知的情況下表現得簡單而高效,但不適用于負載變化的云系統。基于任務間的DVFS方法利用程序的結構知識,在任務內調整處理器頻率進而節省能耗,但全局數據中心的能耗仍然較高。
基于門限值的啟發式方法通過設置門限改善資源利用率,進而降低能耗并確保系統交付的QoS。文獻[7]提出一種單門限方法ST,ST設置一個利用率門限值以確保所有主機的CPU占用在該門限以下,以此控制虛擬機遷移,其能耗節省優于DVFS。文獻[8]提出雙門限值方法DT,包括上門限和下門限,并確保所有主機的CPU占用處于兩個門限值之間。對于CPU占用未處于兩個門限值之間的主機,則需要進行虛擬機遷移。文獻[9]基于雙門限DT設計了一種改進PSO算法MPSO,該算法可以減少活動主機的數量和虛擬機遷移次數,以此降低能耗。文獻[10]研究云數據中心的能效問題,并提出基于DT的虛擬機選擇算法,該算法重點考慮了CPU占用率和資源滿意度。文獻[11]提出一種靜態三門限虛擬機部署算法,在考慮能效的情況下將最優門限間隔設置為40%,實現了能效優化。以上基于門限值的啟發式方法盡管可以節省大量能耗,但在未知可變的負載狀況下顯得并不適用。
基于歷史數據統計分析的決策方法是改進數據中心能效的有效方法。文獻[12]提出一種自適應雙門限算法,該算法通過利用近期負載數據特征預測資源占用情況。文獻[13]利用權重線性回歸預測未來負載并優化資源分配。文獻[14]通過虛擬機部署預測改進數據中心能效,但所考慮的負載類型為單一計算密集型,且僅考慮了能耗降低,而未考慮能量使用效率,即忽略了性能保障和SLA違例降低問題。盡管基于歷史數據統計分析的決策方法可以大幅降低能耗,但已有工作未考慮負載類型,且僅考慮虛擬機部署過程中的能耗降低,而未考慮SLA違例等性能因素,全局提高能效。
2 優化算法設計
2.1 自適應門限值部署模型
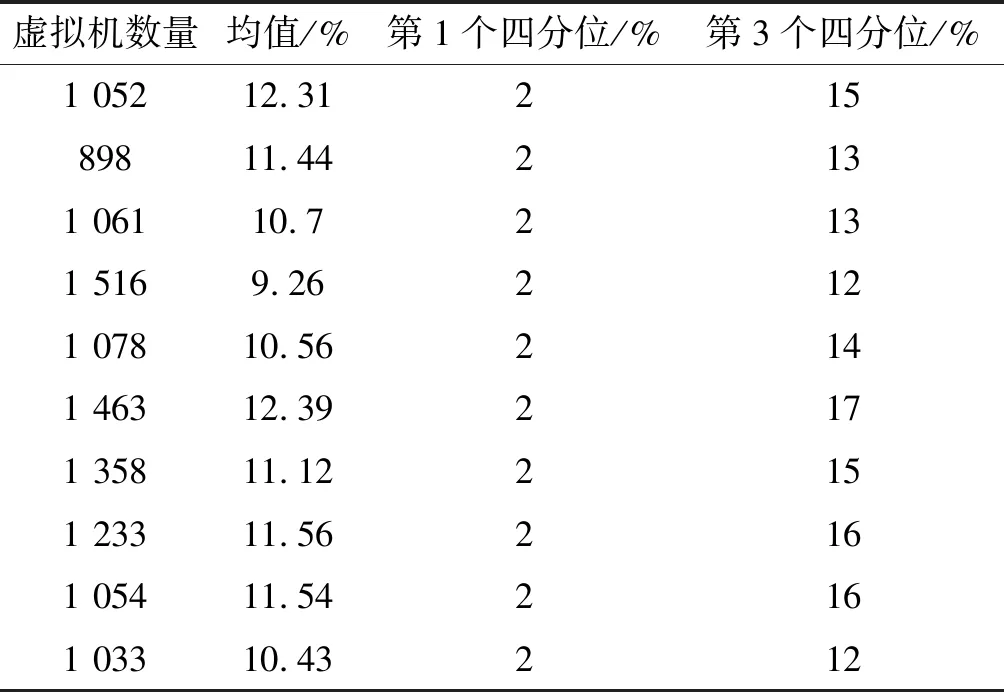
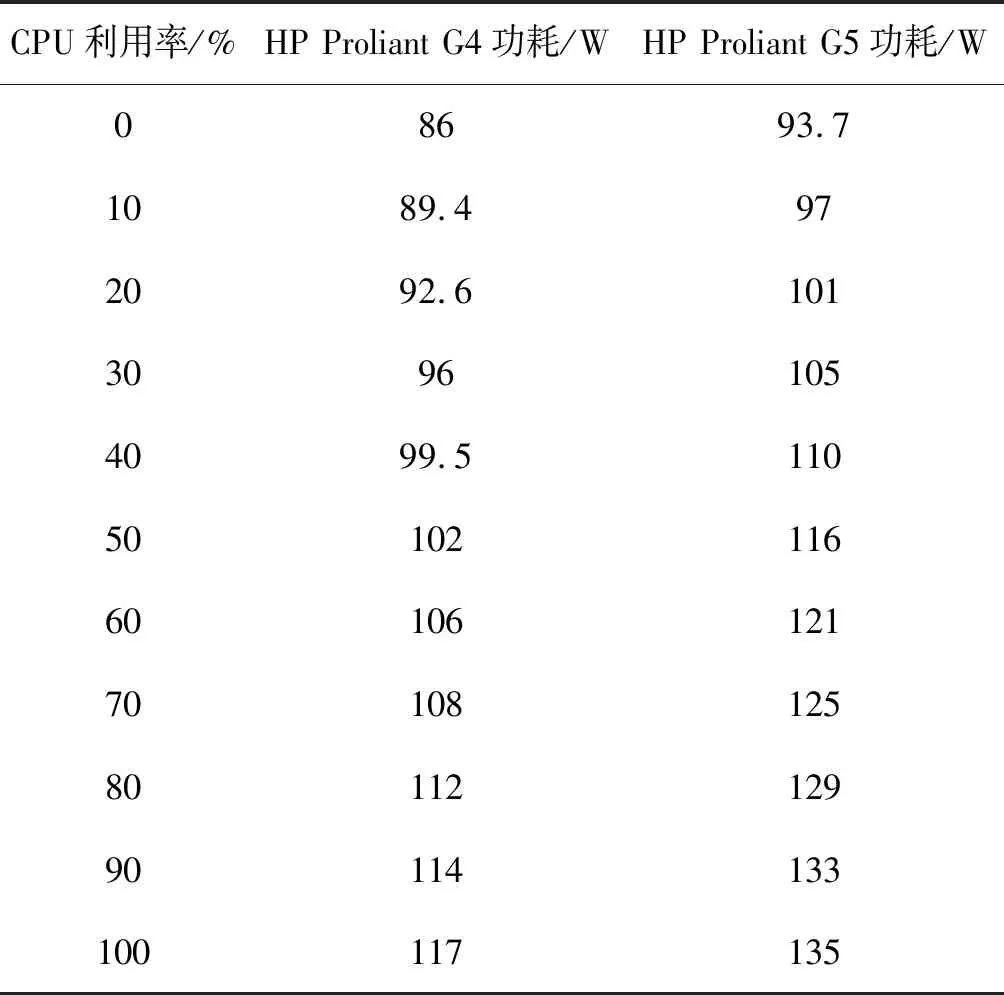
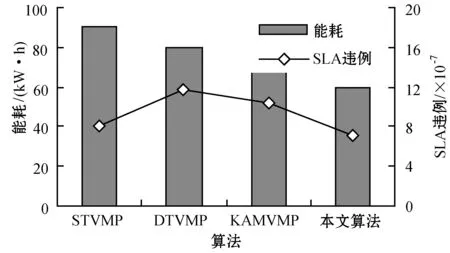
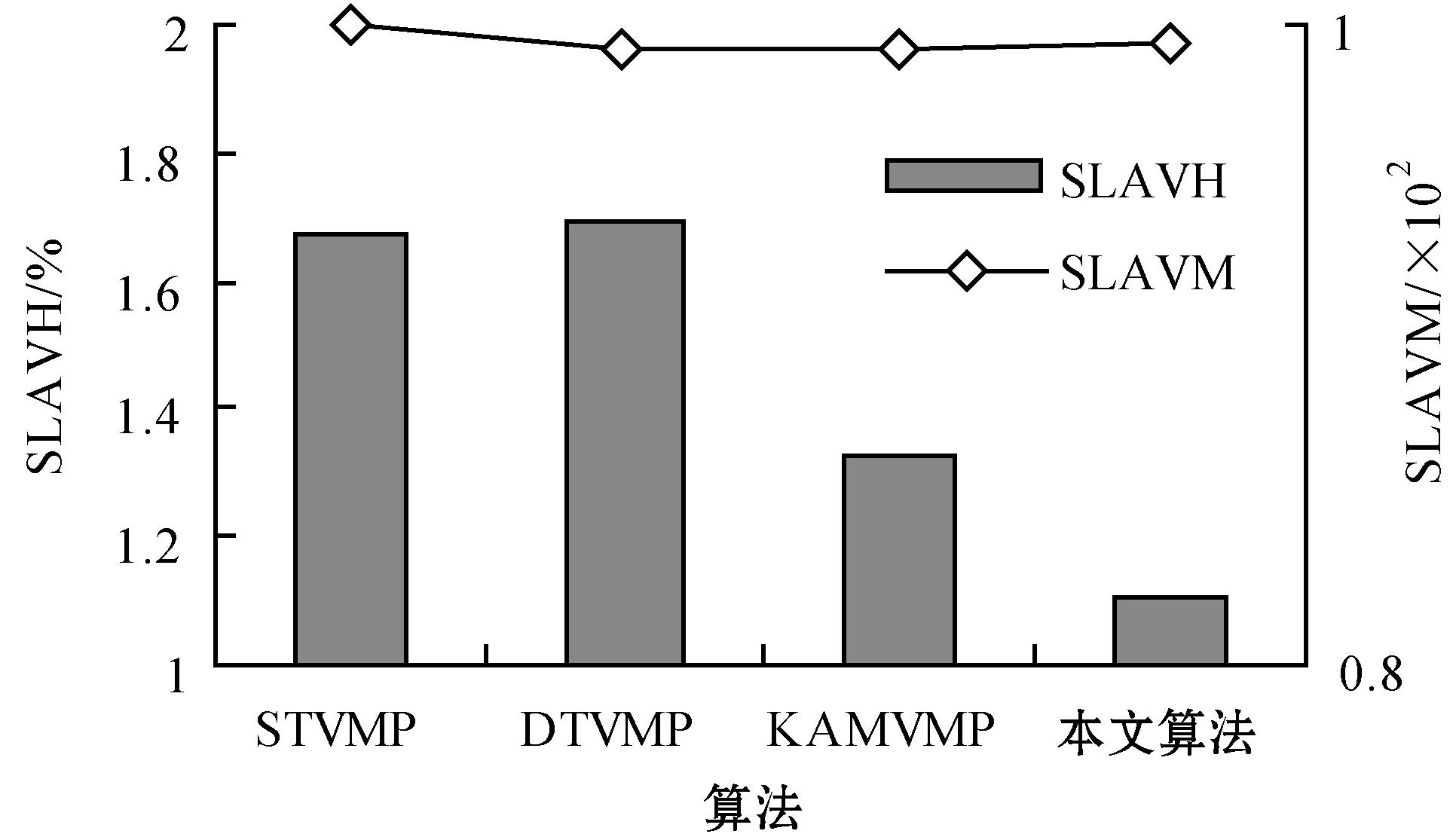
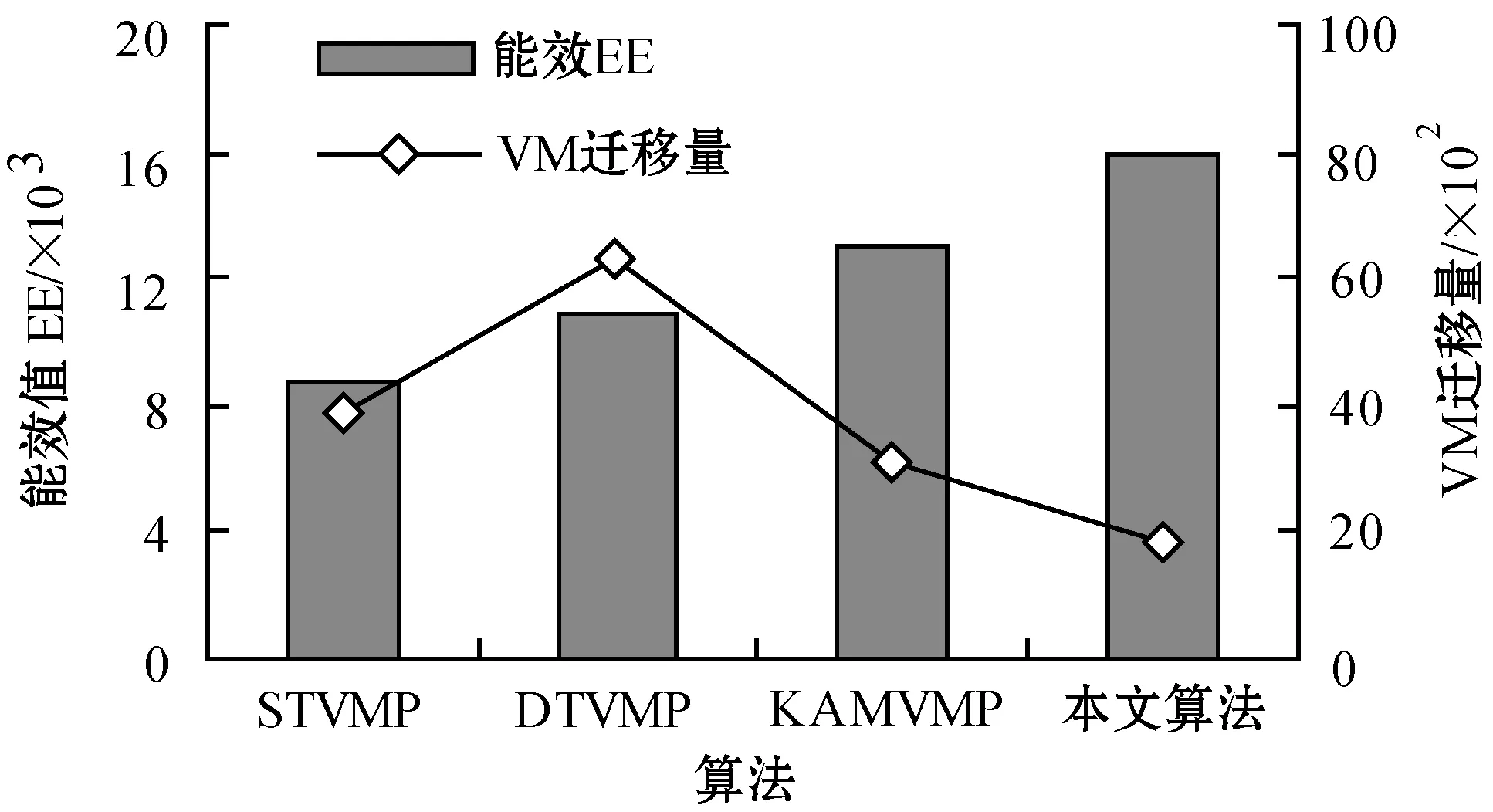
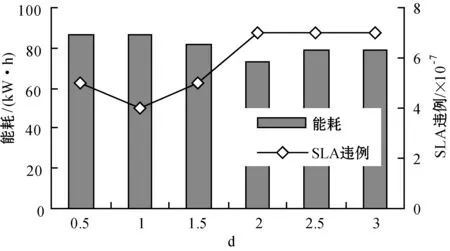
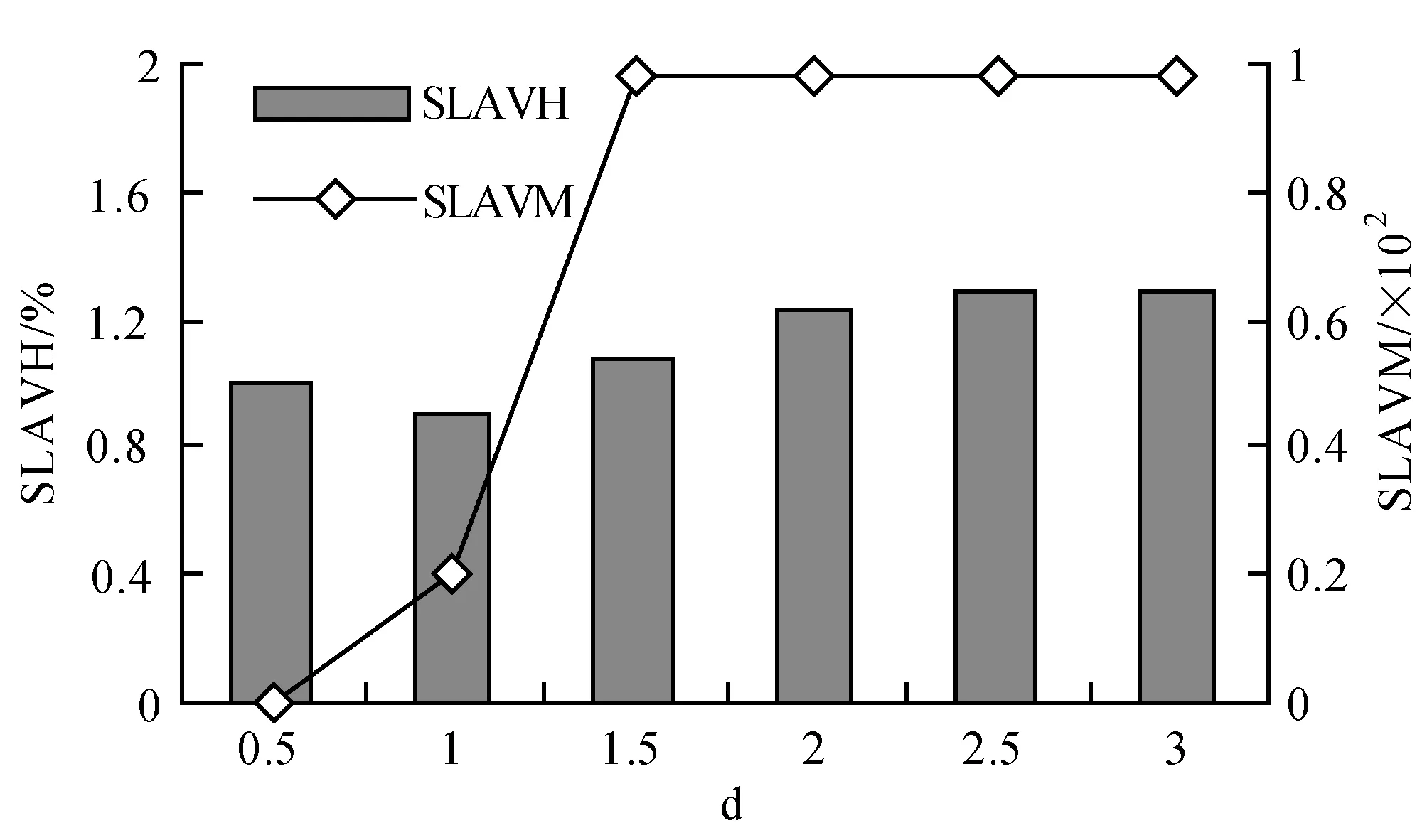
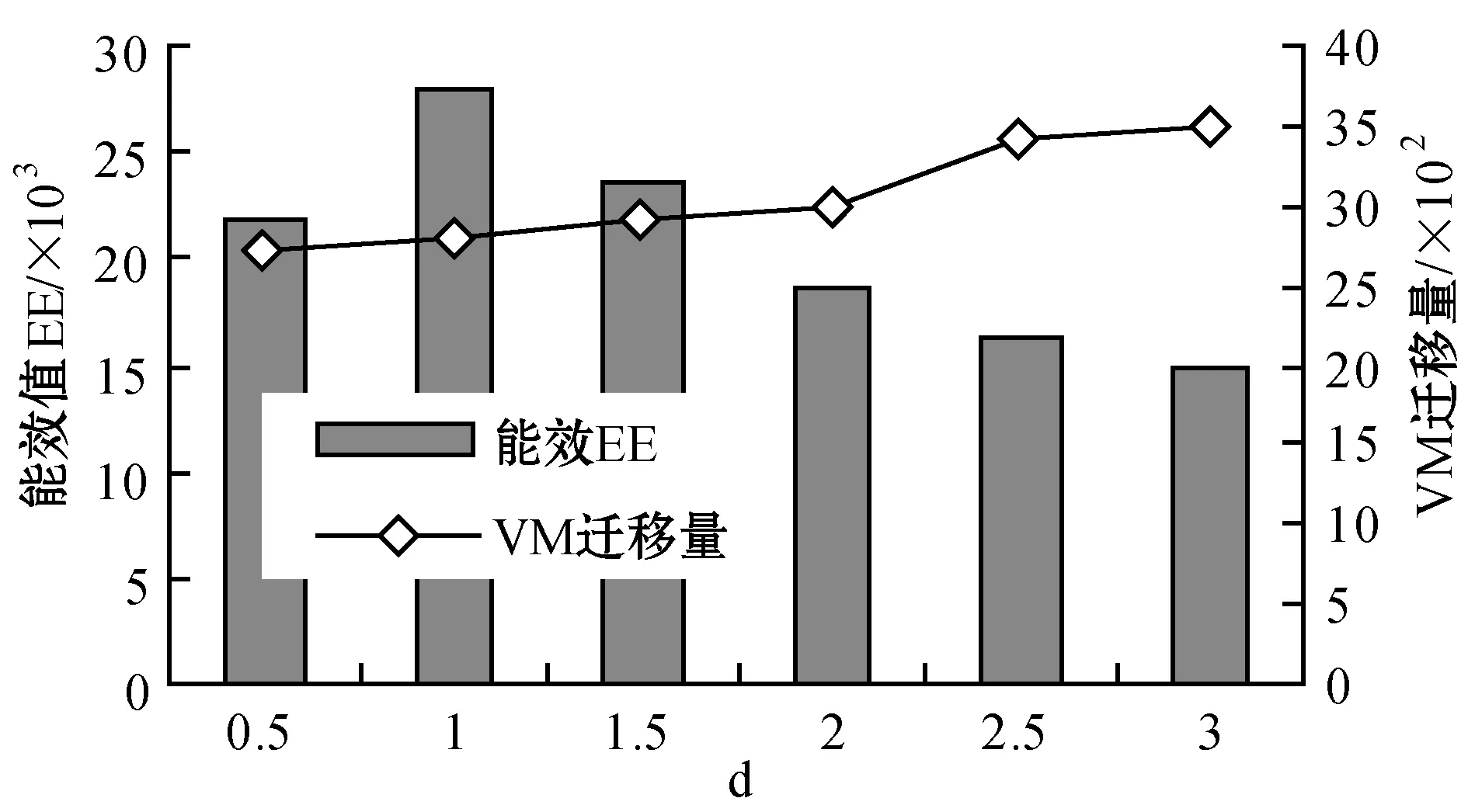
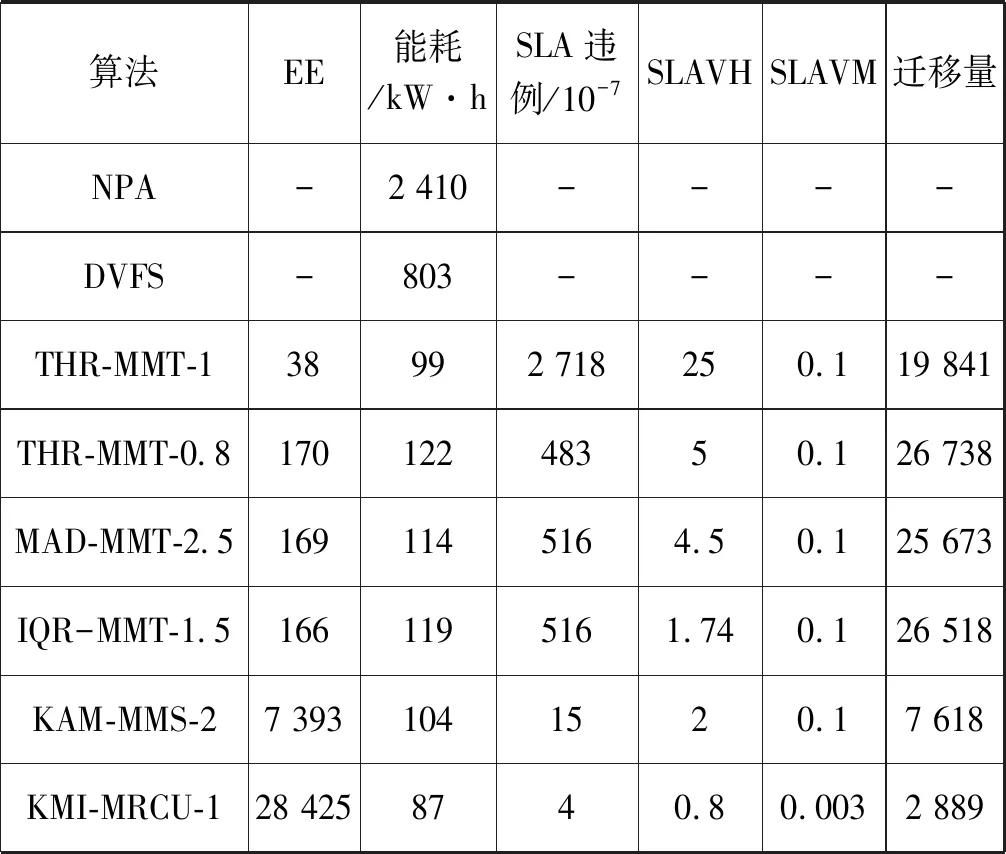
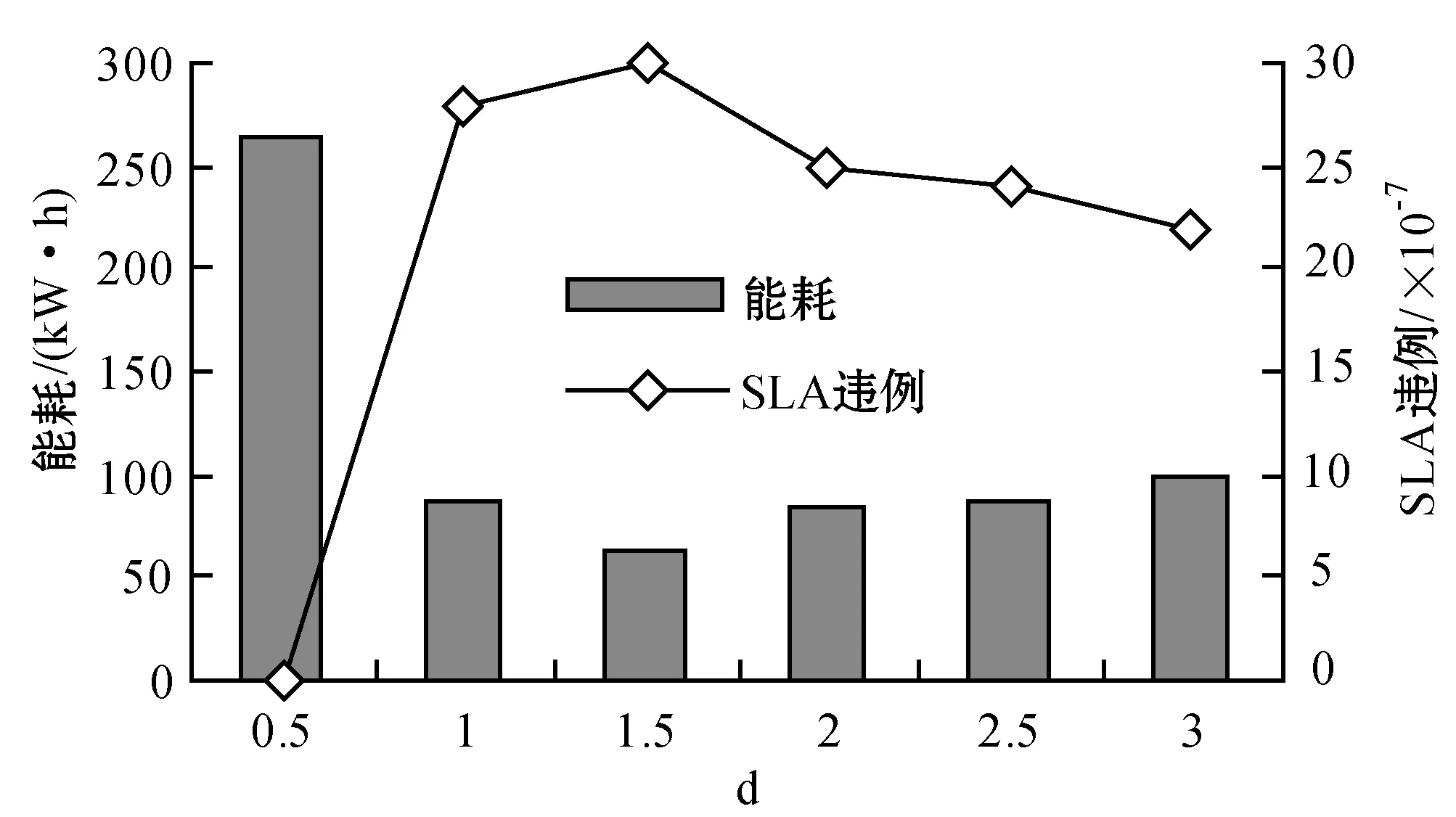
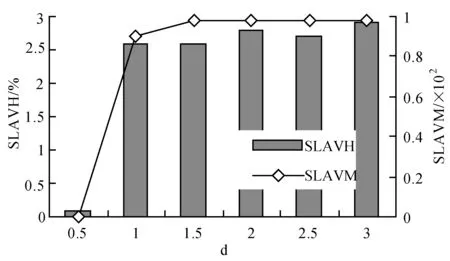
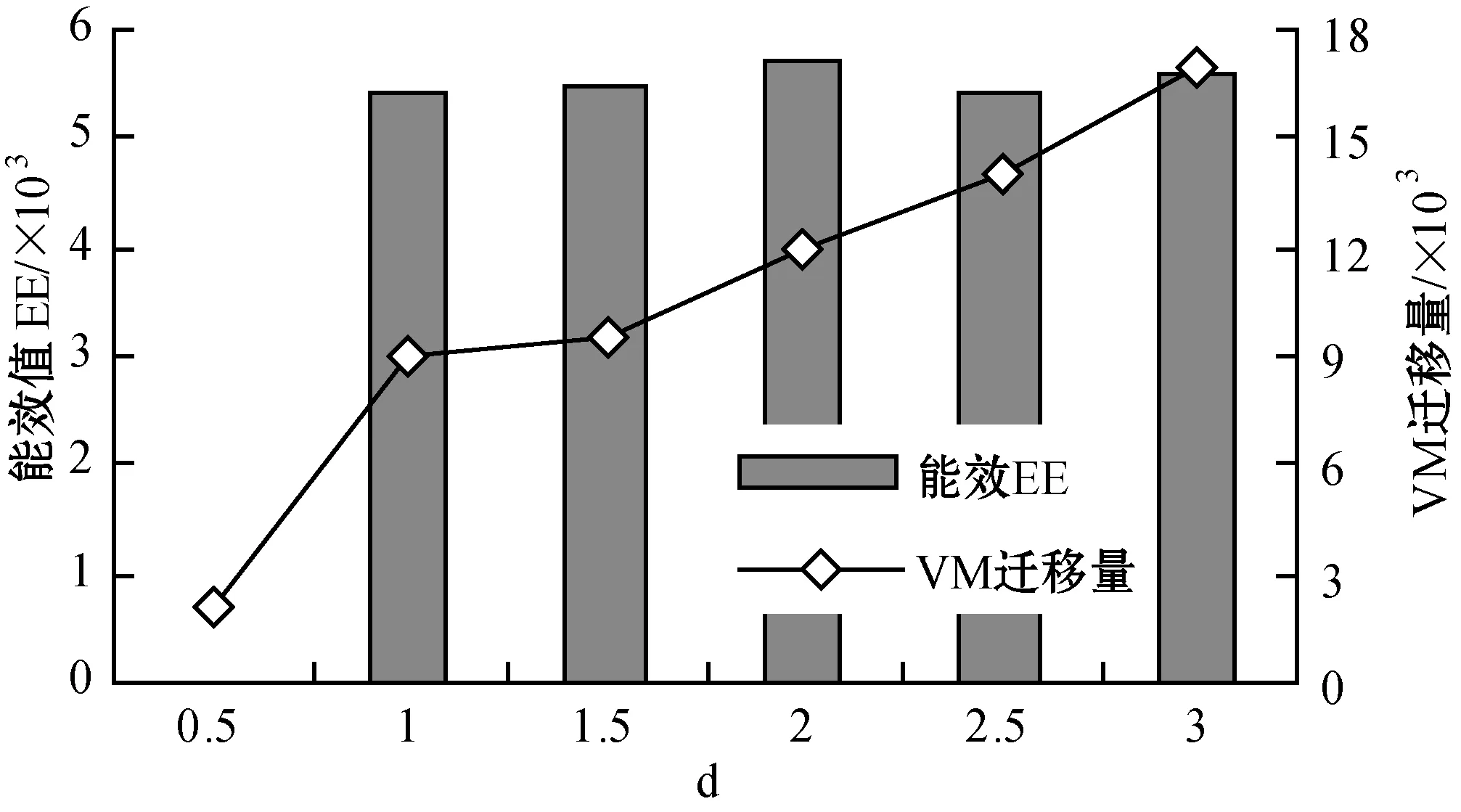
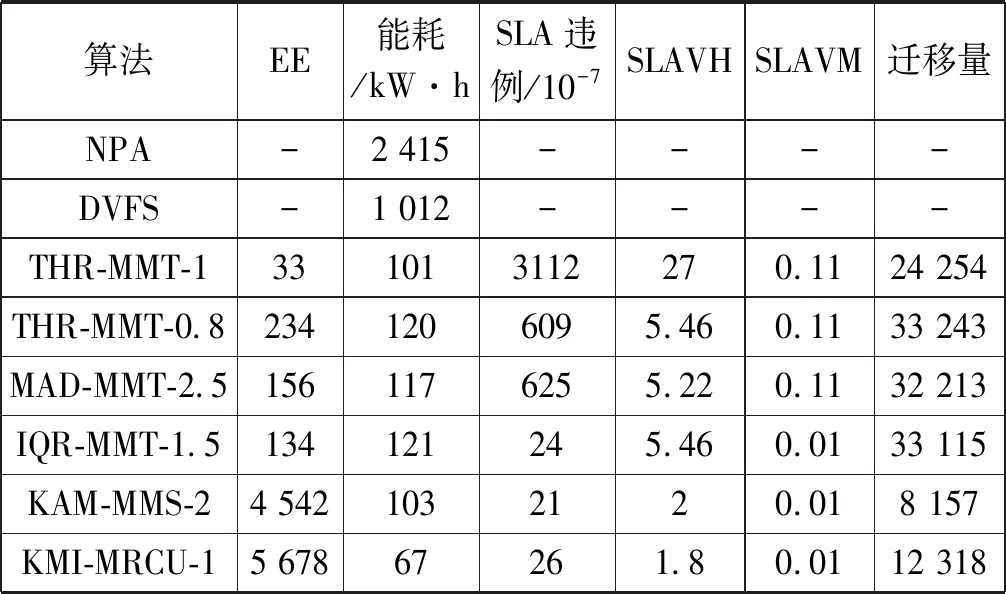
為了解決高能耗問題,將數據中心的主機基于CPU利用率進行劃分,設置三個CPU利用率的門限值為Ta、Tb和Tc,且0≤Ta 圖1 自適應三門限值下的處理流程 該模型重點需要解決兩個問題:① 如何決定三個門限值的具體大小;② 如何在重載主機上選擇需要遷移的虛擬機,以適應于計算密集型任務和I/O密集型任務的需求。以下分別進行討論。 提出一種基于中檔四分位的K-均值聚簇算法KMI計算三個門限值的大小。令H={h1,h2,…,hM}表示云數據中心中M個主機的集合,令D={U1,U2,…,Un}表示數據集,且Ut∈D(1≤t≤n)表示時間t時主機hf∈H的CPU利用率。算法1給出KMI算法的偽代碼。 算法1KMI Input:D,k,d Output:Ta,Tb,Tc 1.R=Cluster(D,k) //K-均值聚簇算法 2.fori=1 toR.lengthdo 3.MRi=(max(Ri)+min(Ri))/2 4.MR[i]=MRi 5.endfor 6.IQR=TQ3(MR)-TQ1(MR) 7. 計算Ta、Tb、Tc 算法1詳細說明:算法輸入參數包括CPU利用率數據集D、聚簇數量k和預定義的合并因子d,算法輸出為三個CPU利用率的門限值Ta,Tb,Tc。KMI算法的步驟1利用K-均值聚簇算法將D劃分為k個簇:表示為{R1,R2,…,Rk},使得: 1)Ri={Upi-1+1,Upi-1+2,…,Upi}∈D 2) 0=P0 3)Ri∩Rj=?,對于1≤i,j≤k。 步驟3中,對于每個簇Ri,算法獲取的中位值為: MRi=(max(Ri)+min(Ri))/2 1≤i≤k (1) 式中:參數max(Ri)表示簇Ri的最大值,min(Ri)表示簇Ri的最小值,步驟4可以獲得簇i的中位值MRi,該過程可產生MR={MR1,MR2,…,MRi,…,MRk}。算法在步驟6可獲得集合MR={MR1,MR2,…,MRi,…,MRk}的四分位差為: IQR=TQ3-TQ1 (2) 式中:TQ3為MR的第三個四分位,TQ1為MR的第一個四分位。式(2)的目標是得到集合MR的IQR。算法在步驟7通過以下三個公式分別計算三個門限值為: Tc=1-d×IQR (3) Tb=0.9×(1-d×IQR) (4) Ta=0.5×(1-d×IQR) (5) 式中:d表示合并因子,描述系統進行虛擬機合并的積極程度。d值越小,能耗越小,SLA違例越高,反之亦然。 考慮數據中心的執行負載為計算密集型任務或I/O密集型任務。當一個應用任務的完成時間主要由CPU的速度決定時即認為是計算密集型任務;當一個應用任務的完成時間主要由等待輸入輸出操作完成時間決定時即認為是I/O密集型任務。換言之,此時將花費更多時間等待數據而非處理數據。這種情況下,CPU和內存將消耗更多能量。 1) MRCU算法:CPU利用率與內存利用率之比最大化算法。若某一主機由于計算密集型任務成為重載主機,則利用MRCU算法進行遷移虛擬機選擇。MRCU算法選擇遷移的虛擬機v需要滿足: 2) MPCU算法:當主機由于執行I/O密集型任務發生重載時,為了降低潛在的SLA違例,可利用CPU利用率與內存利用率之積最小化算法MPCU處理。MRCU算法選擇遷移的虛擬機v需要滿足: 若主機由于I/O密集型任務出現重載,此時CPU和內存將消耗大部分能量,即CPU因素和內存因素具有同等重要性。式(7)將選擇具有最小CPU利用率與內存利用率之積的虛擬機遷移,由于此時遷移能耗較少,對應的由虛擬機遷移帶來的性能下降也有所減少,從而可以降低SLA違例。MPCU算法在選擇遷移虛擬機時也同步考慮了CPU因素和內存因素。 基于三門限值和重載主機的虛擬機遷移選擇,本節設計一種考慮同步降低能耗和SLA違例的虛擬機部署算法,并命名為最大能效算法VPME。過程如算法2所示。 算法2VPME Input:vmlist,hostlist,Ta,Tb,Tc Output:allocation of virtual machines 1. vmlist.sortByDeseasingUtilization() 2.for(vm:vmlist)do 3. minEnergyEfficiency=min,allocatedHost=? 4.for(host:hostlist)do 5.if(host meets the requirements of vm)then 6. CpuUtilize=getUtilizationAfterVm(host,vm) 7.if(Ta≤CpuUtilize≤Tb) then 8. power=host.getPower() 9. powerDiff=powerAfterAllocation-power 10. firstSlaBefore=getSlaTimePerActiveHost(host) //第一次SLA違例計算 11. firstSla=firstSlaAfterVM-firstSlaBefore 12. secondSlaBefore=getSlaMetric(host.getVmList() //第二次SLA違例計算 13. SLA=fristSla×secondSla//通過式(8)計算SLA違例 14. EnergyEfficiency=1/(powerDiff×SLA) //計算能效 15.if(EnergyEfficiency>minEnergyEfficiency)then //尋找滿足虛擬機分配具有最高能效值的主機 16. minEnergyEfficiency=EnergyEfficiency 17. allocatedHost=host 18.if(allocatedHost≠null)then 19. allocated the Vm to host 20. return allocation of virtual machines 算法2詳細說明:算法輸入為虛擬機列表vmlist、主機列表hostlist以及三個門限值Ta、Tb、Tc,算法輸出為虛擬機的分配結果。步驟1中,VPME算法首先按CPU利用率將所有虛擬機降低排列。步驟3對最小能效值進行初始化,并將已分配的主機集合初始化為空集,以備后續分配的更新。然后,對于數據中心的每臺主機(步驟4),檢測是否當前主機在可用CPU和內存大小上能夠滿足虛擬機的請求(步驟5)。若滿足,進行虛擬機分配后獲取該主機的CPU利用率(可見步驟6的變量CpuUtilize)。步驟7將維持該主機為輕量負載主機。步驟8-步驟9計算虛擬機分配前后該主機的功能差值。步驟10-步驟11計算虛擬機分配前后第一次的SLA違例(第一次SLA違例定義可參見實驗部分式(9))。步驟13計算虛擬機分配前后第二次的SLA違例(第二次SLA違例定義可參見實驗部分式(10))。步驟13計算SLA違例(見式(8)),步驟14計算能效值(見式(13)),步驟15-步驟17尋找滿足虛擬機分配具有最高能效值的主機,步驟19完成虛擬機分配。算法時間復雜度為O(M×N),M為主機數量,N為虛擬機數量。 虛擬機部署優化是對2.4節執行虛擬機部署后的優化過程,過程如算法3所示。 算法3虛擬機部署優化過程 Input:Ta,Tb,Tc,hostlist Output:migrationMap 1.for(host:hostlist)do 2.if(utilization≥Tc)then //若為重載主機 //則遷移虛擬機至擁有最高能效值的主機 3. overUtilizedHosts=getOverUtilizedHosts() 4. vmsToMigrate=getVmsToMigrateFromHosts(overUtilizedHosts) 5. migrationMap=getNewVmPlacement(vmsToMigrate) 6.elseif(utilization //若為輕載主機,維持不變 7. lowUtilizedHosts=getLowUtilizedHost() 8. vmsToMigrateB=getVmsToMigrateFromLowHosts(lowUtilizedHosts) 9. migrationMapB=getNewVmPlacement(vmsToMigrateB) 10. migrationMap.addAll(migrationMapB) 11.returnmigrationMap 算法3詳細說明:算法輸入為三個門限值Ta、Tb、Tc、主機列表hostlist,算法輸出為虛擬機遷移后的重部署結果。步驟3-步驟5通過利用虛擬機遷移選擇算法(2.3節)在重載主機上選擇需要遷移的虛擬機,并將其遷移至擁有最高能效值的主機上。步驟6-步驟9將維持正常負載主機和輕量負載主機不變。步驟10選擇低載主機上的所有虛擬機遷移至擁有最高能效效值的主機上。算法3的時間復雜度為O(M),M為主機數量。 考慮到實驗的可重復性,利用CloudSim工具包[15]搭建云數據中心環境。實驗模擬了一個包括800臺物理主機的數據中心,由HP Proliant G4和HP Proliant G5兩種主機類型組成,數量各400臺。主機具體參數如表1所示。虛擬機特征參考Amazon EC2的VM類型建立,具體描述如表2所示。 表1 機類型 表2 虛擬機類型 實驗中的測試負載數據利用現實負載CoMon項目中的PlanetLab提供的負載數據,負載流數據參數如表3所示。 表3 負載數據特征/CPU利用率 兩種主機類型不同負載狀況下的能耗情況如表4所示。 表4 不同CPU利用率下的能耗 云數據中心擁有兩種類型的SLA違例:單個活動主機的SLA違例SLAVH和由于虛擬機遷移導致的SLA違例SLAVM。本文將該指標綜合定義為: SLAV=SLAVH×SLAVM (8) SLAVH表示PH的SLAV時間與PH活動時間的比例,即: 式中:M表示PHs的數量,Tsj表示PHj所經歷的CPU100%占用從而導致SLA違例的總時間,Taj表示PHj在活動狀態下經歷的總時間。 SLAVM表示由于遷移所導致的虛擬機性能下降與虛擬機請求的總體CPU能力間的比例,即: 式中:N表示虛擬機數量,Cdi表示由于遷移導致的虛擬機i的性能降低估算,Cri表示在其生命周期內虛擬機i請求的總體CPU能力。實驗中將Cdi估算為虛擬機i所有遷移中CPU利用的10%。這意味著每次遷移可能導致SLA違例。一次動態遷移的時間長短取決于虛擬機使用的內存總量和可用的網絡帶寬。 虛擬機i帶來的性能下降為: (11) 能效指標包括兩個方面:能耗和SLA違例。基于前文定義,能效EE定義為: 式中:ppower表示能耗,ISLA表示SLA違例指標。EE值越高,能效越高。 實驗1觀察三門限的設置對于性能的影響。分別與基于單門限的虛擬機部署算法STVMP[7]、基于雙門限值的虛擬機部署算法DTVMP[10]及基于平均絕對中位差的多門限值算法KAMVMP[14]進行比較。單門限值設置為0.7,雙門限值設置為0.2和0.8,三門限值由本文的KMI算法產生,算法中的d值設置為1,測試負載以計算密集型任務為主,因此,利用MRCU算法進行遷移虛擬機選擇,即本文算法=KMI-MRCU-1,1代表d值。實驗比較分析了能耗、SLA違例、SLAVH、SLAVM、虛擬機遷移量以及算法得到的能效值等性能指標,結果如圖2-圖4所示。總體來看,單門限值算法的性能是最差的,主要原因是單門限值僅設置了CPU利用率的上限,會導致很多主機利用率較低,靜態功耗較多。雙門限值同時設置了CPU利用率的上下限,可以避免部分主機利用不充分的問題,但上下限的區間跨度仍然較大,難以適應動態的負載需求。KAMVMP算法雖然是基于多門限值思想,但僅是以最小化能耗為目標的,其能效并不一定最優。且其虛擬機遷移選擇是基于內存最小原則設計的,無法適應于不同類型的負載執行。綜合比較,本文算法具有更高的能效(能耗和SLA違例)。 圖2 能耗與SLA違例 圖3 兩種類型的SLA違例 圖4 能效與VM遷移量 實驗2測試執行計算密集型任務時d值的變化對算法性能的影響。選取3/3/2011數據集合作為計算密集型任務的測試數據。測試算法=KMI-MRCU-d,d的取值范圍為[0.5,3],遞增步長為0.5,結果如圖5-圖7所示。由圖5可知,d=2時能耗最小,但d=1時SLA違例最小。同步考慮到能耗與SLA違例(即能效),并結合圖7中的EE指標,d=1時算法具有最優能效。總體來看,過高的d值反映出虛擬機具有更高的合并積極性,能耗與SLA違例指標均表現出先降低后升高的趨勢,因此d值的選取至關重要。 圖5 能耗與SLA違例 圖6 兩種類型的SLA違例 圖7 能效與VM遷移量 表5將本文算法KMI-MRCU-1與同類型算法進行系統比較,同樣選取能耗、SLA違例、SLAVH、SLAVM、虛擬機遷移量以及算法得到的能效值等性能指標。對比算法為非功耗感知算法NPA(以滿載形式執行所有任務)、動態電壓/頻率調整算法DVFS、THR-MMT-1算法[12]、THR-MMT-0.8算法[12]、MAD-MMT-2.5算法[12]、IQR-MMT-1.5算法[12]及KAM-MMS-2算法[14]。指標中,能效EE越高越好,而能耗、SLA違例、SLAVH和SLAVM則越小越好。對于虛擬機遷移量,過多或過小的遷移量均不利于能效的提高。NPA未采用任何能量優化機制,能耗是最高的,DVFS通過降低CPU性能可以降低部分閑置能耗。NPA和DVFS均未涉及虛擬機遷移,因此其他性能指標均以“-”表示。 表5 計算密集型任務下的性能系統比較 綜合來看,本文算法KMI-MRCU-1比較其他幾種算法,在能效、能耗、SLA違例、SLAVH、SLAVM以及虛擬機遷移量等指標上均有5~10倍的性能提升,其原因可概括為:1) THR-MMT-1、THR-MMT-0.8、MAD-MMT-2.5和IQR-MMT-1.5均還是雙門限值框架,而KMI-MRCU-1是基于自適應三門限值的,多門限值的效率更高;2) 四種比較算法更側重于虛擬機部署過程的能耗優化,而本文算法考慮的是能效的最大化;3) 對于重載主機的發現,四種比較算法均利用歷史數據的統計分析進行計算,而本文算法則是通過基于歷史數據的K-均值聚簇方法計算的;4) 對于遷移虛擬機的選擇,四種比較算法均只考慮CPU或內存利用率的單一因素,而本文算法則同時考慮了這兩個因素。 與KAM-MMS-2算法比較,本文算法仍是更優的,原因在于:1) KAM-MMS-2算法仍僅是考慮能耗優化的,不是能效;2) 對于計算密集型任務,本文采取的重載主機發現與遷移選擇機制更優。 實驗3測試執行I/O密集型任務時d值的變化對算法性能的影響。選取22/3/2011數據集合作為I/O密集型任務的測試數據。測試算法=KMI-MPCU-d,d的取值范圍為[0.5,3],遞增步長為0.5,結果如圖8-圖10所示。由圖8可知,d=0.5時能耗最小,而d=3時SLA違例最小(d=0.5時算法部署失效)。同步考慮到能耗與SLA違例(即能效),并結合圖10中的EE指標,d=2時算法具有最優能效。對于I/O密集型任務,能耗較計算密集型任務更少,但SLA違例更高。 圖8 能耗與SLA違例 圖9 兩種類型的SLA違例 圖10 能效與VM遷移量 表6對I/O密集型任務下對算法性能進行了系統比較。同樣地,本文算法在各個性能指標上也擁有更好的效果。其原因可參見表5的注釋。 表6 I/O密集型任務下的性能系統比較 為了降低數據中心能耗與SLA違例,提出了一種基于三門限值的高能效虛擬機部署優化算法。算法基于歷史數據集,設計了一種中檔四分位的K-均值聚簇方法以產生主機CPU利用率的三個門限值;然后,依據三個門限值,將主機劃分為低載主機、輕量負載主機、正常負載主機和重載主機四種類型;最后,為了對重載主機實施虛擬機遷移,分別針對計算密集型任務或I/O密集型任務設計了兩種虛擬機遷移選擇方法。結果表明,所提算法不僅可以有效降低能耗,而且SLA違例也較低,具有更高的能效。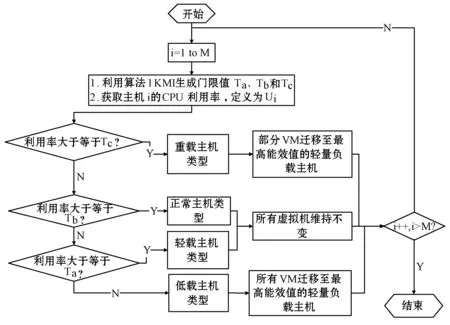
2.2 自適應三門限值取值機制
2.3 重載主機上虛擬機遷移選擇

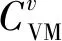
2.4 能效最大化的虛擬機部署
2.5 虛擬機部署優化
3 仿真實驗
3.1 實驗環境搭建


3.2 SLA違例指標
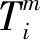
3.3 能效指標
3.4 實驗結果
4 結 語
