一種新的IoT PaaS大數據服務平臺的設計
2019-08-17 07:39:54孫麗娜武海燕
重慶理工大學學報(自然科學) 2019年7期
孫麗娜,武海燕
(1.河南大學民生學院, 河南 開封 475004;2.鐵道警察學院 圖像與網絡偵查系, 鄭州 450053)
目前,信息科技是進入企業市場的基本技術支撐,在國際市場科技運用日益更新的壓力下,各產業邁入 21世紀的主要目標是結合工業4.0,創造出智能產線,提高年、人均產值。國際上的大公司能夠透過物聯網與大數據進行實時監控,達成公司由制造業轉型為大數據服務的目標[1-2]。對國內制造業來說,信息化所需的門坎過高,包括軟件開發、軟件測試、營運系統。目前的信息化相關服務產品已無法滿足中小型制造業及用戶對應市場這一區段的具體要求,部分產品針對單機提供的軟件或云端服務 (針對軟、硬件服務),亦無法有效全面提升產線智能。故產業亟需整合機臺物聯網與制造云服務平臺,從而提升整體產業之上、下游競爭力。
在云端服務時代,軟件服務[3-5](software as a service) 與基礎設備服務[6-7](infrastructure as a service)是大家較熟悉的兩個服務層,一般是較容易理解的類軟件及硬件層,此兩大類云端服務在過去的發展階段獲得了大多數公司與研究機構的關注與投入,經多年努力,已取得可觀的進展[8-10]。近年來,越來越多的研究團隊已開始將研發的目光聚焦于平臺服務PaaS[10-11]。平臺服務定義為提供應用程序工程師開發、執行與管理應用程序的云端系統環境,此服務將應用程序開發的系統層 (例如數據儲存與分析處理 )以API接口方式提供給應用程序接入使用,提高開發效率、降低開發與維護成本[12]。
建構高效能、高容量、高穩定性與易用性高的物聯網云端服務平臺系統是本文研究的目標。在提供客戶端軟件服務的作用平臺服務中,本文的解決策略是發展物聯網云端服務平臺技術,以大幅降低產業發展信息化的門坎,提供一個垂直整合度高的數據收集與儲存平臺,負責收集物聯網裝置的各項數據,從而建立一個具有高性能的分布式計算平臺,負責執行客戶端應用服務所上傳的數據分析應用程序。
1 大數據處理與分析
透過物聯網的建立與信息傳播技術的更新,人們生活與工作環境所產生的各項數據被系統快速地聚集,這是在物聯網盛行前所無法達到的數據規模數(PB規模以上)。據Statista 2018年最新統計數據顯示:2018年全球連接的物聯網設備數量達到了230億,至2025年物聯網設備數量將增加到750億。這說明物聯網時代的到來,伴隨而至的挑戰是對數據提供有效率的處理,故對物聯網海量數據的處理也得到越來越多的關注。
1.1 大數據分析方法
對大數據處理的挑戰已定義為4個主要方面:量(volume)、速度(velocity)、多變性(variety)、價值(value),大多數的機構或企業對大數據的處理仍著重于前3個方面,對于第4個方面則有較多不同的見解與定義。
有高質量的原始數據,容易得到高效率與高價值的信息。數據的不良情況包含不完整性、噪聲與不一致性等,數據的處理意味著在原始數據寫入數據庫前必須進行前置處理,以達到高質量的目標。前置處理主要著重于數據寫入前處理,這在數據分析前屬于重要的部分。
前面對大數據的第4個挑戰,即如何處理原始數據后提高其附加值,特別是對數據進行分析以獲取有用的信息再加以利用,這就是數據的加值服務。目前,業界采用的分析方法為早期由谷歌提出的一個程式模型MapReduce,由于其企業特性常須面對使用者并要求在大量的數據里搜尋目標數據,其架構為用一組map函數并行處理大量原始數據,再由另一組reduce函數進行運算合并的作業,這樣的分析架構在本質上已具有平行處理能力。然而,這是針對因特網型搜尋形態的作業,前提是針對大數據具有扁平而規律的結構,并分布于數個機器與儲存裝置中,對于需大量運算類型的分析工作,則不具有任何優勢。
MapReduce在對數據做中介處理時,必須對儲存裝置進行大量的輸出輸入作業,缺乏效率。為解決此問題,加州伯克利大學的AMP實驗室開發一個開源叢集運算架構 Spark,其最重要的特性是將需要處理的數據以及中介數據放于內存中,對處理的效率與速度有顯著的效能提升。
1.2 云端平臺服務
目前,各家通訊與科技公司皆積極投入平臺服務的開發,目前存在的平臺服務有:
IBM Bluemix:以Cloud Foundry為基底,建構開放式云端服務平臺,主要提供 IBM 軟件使用權給因特網與行動開發人員,進行快速應用程序開發,目標是大幅減少創建和配置應用程序所需開發時程。
甲骨文云端平臺(oracle cloud platform):針對合作伙伴及產品用戶的開發人員,簡化開發應用程序周期,提供一致化服務平臺,拓展甲骨文軟件服務(SaaS)開發應用。
亞馬遜(Amazon) PaaS:在各企業中最早大規模投入云端服務建置領域,其服務平臺主要提供應用程序信息的儲存與傳遞,主要目標是進行企業云端服務的垂直整合,為其客戶提供更完整的服務。
研華WISE-PaaS:憑借其在工業計算機全球市場的占有率第一,進行其與客戶端的垂直整合開發平臺,主要采堆積木方式,透過其伙伴合作方案,協助客戶端開發人員共同加速打造專屬物聯網應用軟件。
綜上,可以歸納出幾個關于服務平臺研發的重要方面:① 平臺跨領域的服務是一個巨大的議題與挑戰,這些企業的研發成果也無法有效地涵蓋平臺服務范圍的廣度與深度,大部分仍以企業既有客戶群進行垂直整合為出發點;② 平臺的研發目前仍著重于大量數據寫入與讀取的處理,對于增值產出的部分仍缺乏較具體的成果。
2 本文IoT PaaS架構
本平臺建構的主要目標是提供一個數據收集與儲存平臺,負責收集物聯網裝置的各項數據。同時,提供一個高性能的分布式計算平臺,負責執行應用軟件服務所上傳的數據分析應用程序。基于分布式架構,將工作進行分流,配置不同服務器,達到運算負載平衡的并行處理,得到對多傳感器數據處理與分析的有效性能表現。
2.1 平臺架構
本平臺架構采用分布式架構設計,如圖1所示,主要包含3個模塊,分別為注冊模塊、數據收集模塊與分布式運算模塊。
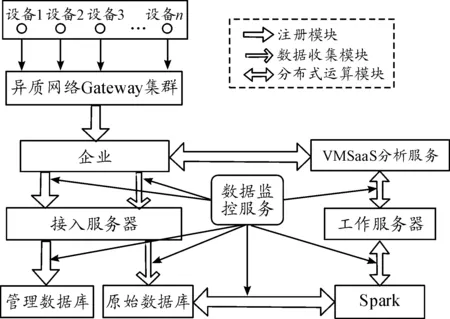
圖1 本文IoT PaaS架構
IoT PaaS平臺布署后可由營運支持接口透過注冊模塊提供的應用程序編程接口(APIs)來注冊使用者與服務,注冊之后,才能提供客戶端進行機器設備的注冊。在數據收集方面,已注冊且認證過的機器設備與傳感器可使用數據收集模塊提供的APIs將數據傳送至平臺數據庫儲存。
當數據開始寫入后,即可進行數據分析。例如,訓練一個商品退貨 (RMA)預測模型,此時云端軟件服務程序可以透過分布式計算模塊提供的 APIs將數據分析程序上傳至平臺,并使用此平臺提供的分布式計算環境進行運算,運算完成后可以使用 API進行預測模型運算 (可進行實時或批次的預測運算)并完成結果取回(如圖2),其中“ACL模組”表示訪問控制列表(access control list,ACL),目前僅提供基本權限控制,亦可用來延伸與云端垂直服務層權限進行整合,達到對云端所有服務一致的控制。
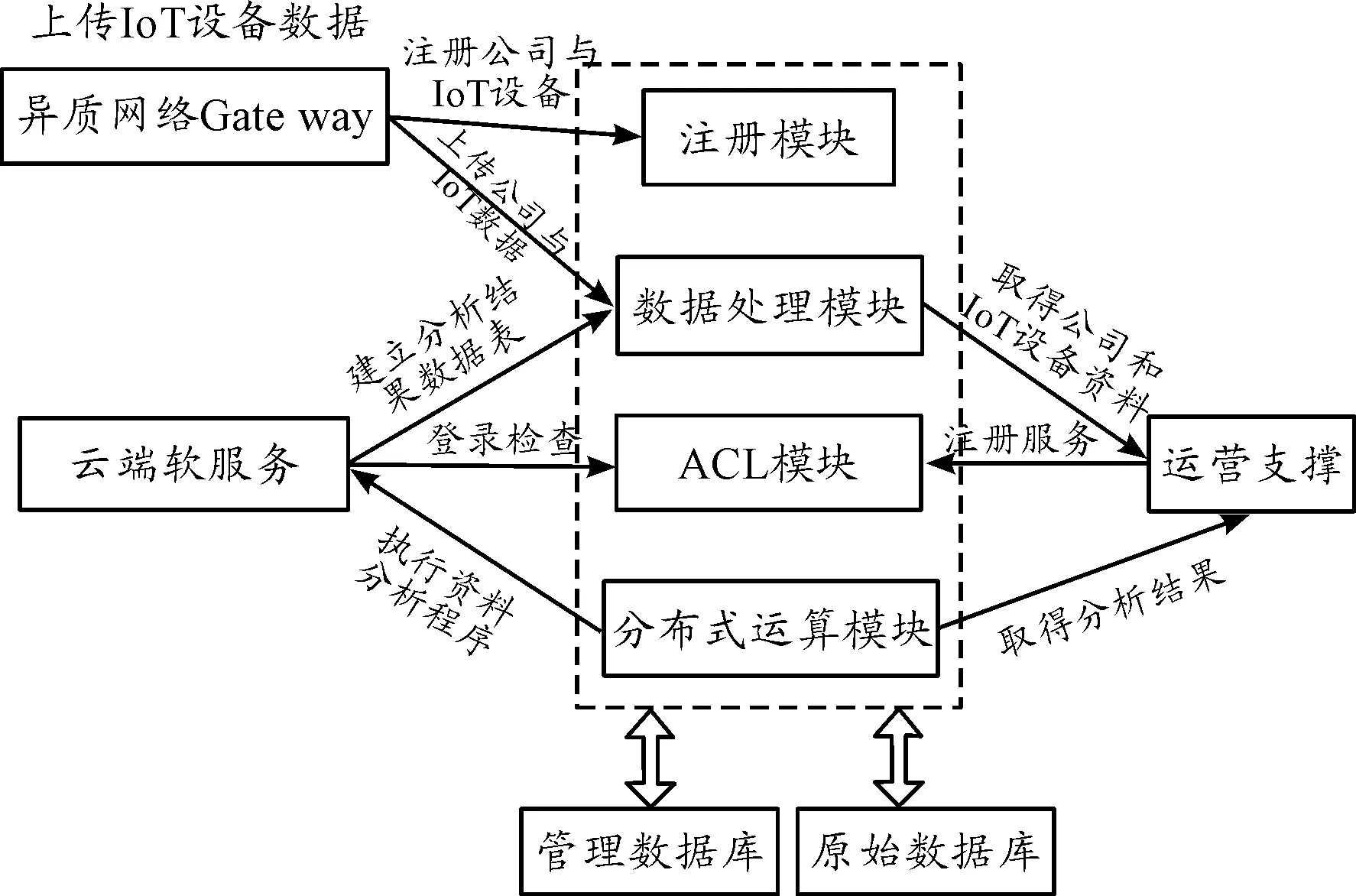
圖2 平臺模塊與周邊關系
2.2 不同模塊的介紹
1) 注冊模塊。平臺的數據注冊主要針對機器設備與傳感器,為便于對數據的后續收集與管理,將一企業組織定義為3個階層,即廠區(Company)、機器設備(Machine)與傳感器(Sensor)。注冊模塊對于任一階層對象的識別,以〈C,M,S〉定義,其中C表示廠區物件,M表示機器設備對象,S表示傳感器物件。客戶端采用此組合定義與IoT PaaS對其所屬的各階層對象進行注冊作業。
本模塊作業數據以結構化數據庫(MySQL)儲存相關管理性數據,注冊模塊的數據庫作業程序以標準SQL語法進行。此類數據庫為管理性數據庫,本身極具結構化特性,且數據量(MB)在作業能力可接收范圍內。
2) 數據收集模塊。儲存與處理來自傳感器終端設備的大數據量是本平臺研發的主要目標。因此,對于原始數據的特性須經由分析后設計其綱要結構,以決定最佳儲存與處理效能的目標數據庫。由于各產業結構與設備性質差異較大,為取得最具彈性化的設計,響應上述討論中有關大數據的多樣性挑戰,在數據綱要設計上采用以下的基本數據元設計:
{“key”,“value”[;…]};
key:數據屬性名稱;
value:原始數據值
其中“[…]”表示數據屬性數量,可由用戶自行定義,不需要預先定義數據庫綱要。
對于這類原始數據,半結構或非結構性是其主要特質。模塊提供數據以實時或批次方式將傳感器數據寫入平臺內數據庫。由于數據源的特性,對于此類數據,本模塊采用PostgreSQL數據庫作為原始數據的儲存目的地。
3) 分布式運算模塊。為實現對大量數據進行有效的實時或批次分析,分散并行運算架構是最佳選擇。采用Mesos作底層工作節點管理加上 Spark的分散運算架構建立分布式計算環境,如圖3所示。Mesos是一個開放原始碼的叢集管理系統,主要實現分散應用程序間的資源隔離與分享。
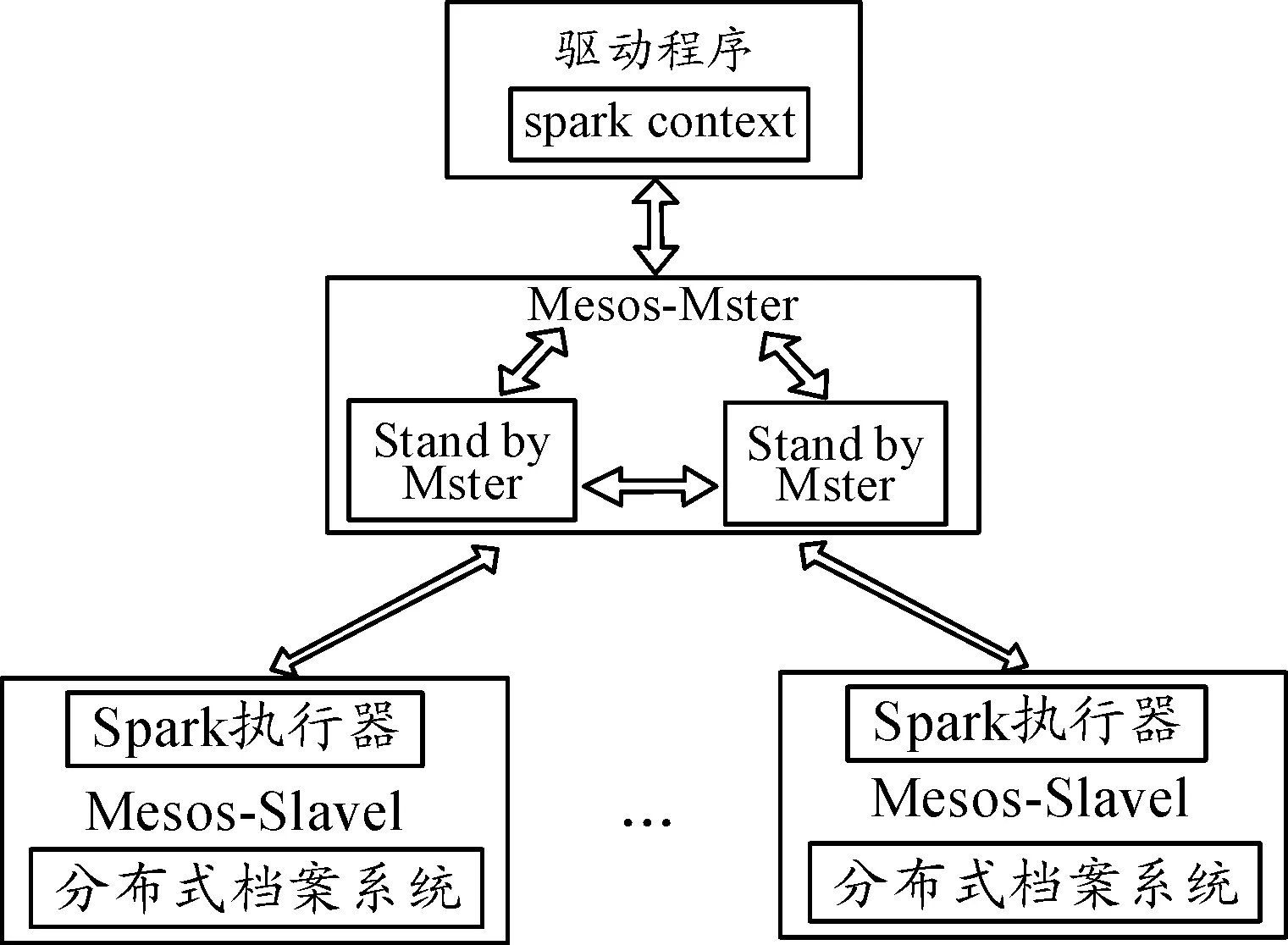
圖3 Spark分布式計算架構圖
由于Spark將運算數據塊皆存放于記憶體內部,因此在分析成效上有顯著的效率。而且,對于叢集內多工作節點的管理,Mesos采用的架構具有自動產生master管理的智能機制,所有分布式節點共享分布式文件系統。這符合對大數據分析的另一挑戰,目標是在建立分布式計算環境、提供平臺使用者進行有效的分析后,將結果反饋回終端裝置進行智能管理,以提高產能。
3 平臺通信接口設計
本平臺對應來自終端傳感器的大量數據寫入/讀取處理與智慧分析的服務,由一群高效率的服務器接口(以下簡稱API)來完成,此API集終端裝置與平臺的通訊需求,借用高效率與安全的通訊傳輸,以實現對產生的大量數據進行效的處理與應用。
本設計規范采用RESTful API軟件架構設計風格,考慮企業客戶對來自于物聯網大量數據所需的存取與數據分析需求,使用者依據本規范建置物聯設備端數據存取應用程序及快速導入業界規范的大數據分析方法,如 Hadoop/Spark,從而快速有效地建立與存取其所屬基本數據及物聯設備產生的大量數據,并針對大數據分析提供擴充功能,有效提高企業產能。
本設計規范之數據存取API服務用于物聯設備端與云端數據儲存平臺時能自動化對接、實時作業監控、提供數據集存取與導入巨量信息分析程序進行信息提取等。企業客戶可根據本規范提供的 API接口定義進行相關應用程序編程接口開發,以提供數據用戶或開發者一致性 API,進行取得、搜尋或分析所需的數據集數據,以取得有益信息并反饋給物聯設備進行產能修正,從而有效提升產能。
數據存取應用程序API接口主要提供一般結構化數據內容存取,不包括數據內容應用層面解析,如復雜數學邏輯運算篩選、應用領域所代表之意義判斷、字段之間相關性等。
界面規范準則分為語法規則和命名規則。語法規則采用RESTfulAPI的規劃,主要目標是要讓企業客戶以HTTPGET、POST、DELETE方法存取IoTPaaS數據。API呼叫回傳內容格式則以Json為主,API服務路徑采用URI通用語法組成,分為服務網址(scheme+host)、資源路徑(API service path)和服務選項 (API Query Options)。其中,服務網址為平臺上提供該類別API應用服務之協議(目前僅支持HTTP)及主機網址/域名。資源路徑接續于服務網址后,指定某一API服務項目路徑名稱。服務選項接續于API服務項目路徑后,針對某一API服務,指定欲進行的作業數據參數。
命名規則:定義API接口的命名原則,提供企業客戶于開發平臺應用程序可依循之API 呼叫,命名規則依據下列格式定義并提供API服務:
{/}{VERSION}{/}{OBJECT}[{/}{SUBOBJ}…]
其中:{}表示必要項目;[]表示選擇項目;…表示允許多重項目。
對于API界面類型,主要提供兩大類型服務,即數據異動與取出。
1) 數據異動
POST:用于新增一企業級客戶、部門廠區(company_uuid)、新增及修改機器/傳感器的基本管理數據及感測數據、分析服務應用程序的作業部署與啟動。對于企業自建的私有物聯網云端數據儲存平臺,則可用于建立分公司/單位賬號。
DELETE:刪除機器/傳感器的感測數據。
2) 數據取出
GET:用于向IoT PaaS取得數據庫的數據,包括會期標識符、企業客戶列表、機器/傳感器的管理數據、機器/傳感器的感測數據、分析服務應用程序的結果、分析服務應用程序的狀態及物聯網云端數據儲存平臺運作記錄。
4 平臺測試與分析
本文IoT PaaS服務平臺的建置實現采用最輕量的架構進行平臺設計與實行,主要目的為取得平臺的壓力參數作為擴增的架構參考數據。
本平臺測試實驗的主要參數如表1所示。測試環境部署因特網服務器(nginx+uwsgi+Flask),使其對應于處理使用者端的RestfulAPI服務要求;其次,安裝管理性數據庫(MySQL5.6)與感測器原始數據庫(PostgreSQL9.5)。分布式分析運算叢集部署包含1臺Spark驅動器、1臺Mesos-Master及2臺Mesos-slave。

表1 本文IoT PaaS 系統實驗工作環境參數
由于設計與建置一云端平臺服務對于其他云端垂直服務具有復雜的依存關系,在學界尚未有統一的量測性效能因子用作各平臺的比較,故對平臺服務的基準驗證是一項困難的工作。鑒于此,對本平臺部署完成后進行測試驗證,以設計的功能與時間效能作為參考。在功能完整性方面,平臺的設計目標在于提供高效、高容量的數據處理與分析。APIs的定義與各功能測試項目見表2,涵蓋對云端平臺服務的各功能項目。
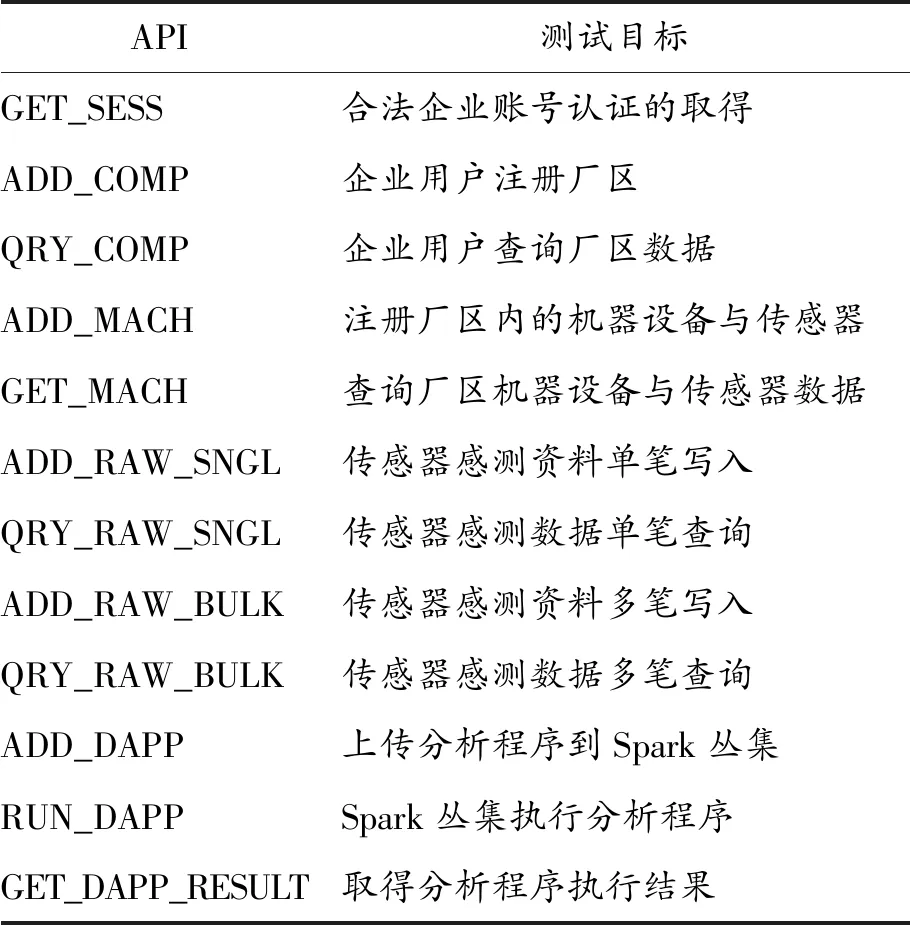
表2 API功能測試
部分應用程序支持接口(API)的運行時間分析見圖4。進行深入的時間分析可見,約70%的時間用在信息接收后的解密運算,以增進更多Restful API服務需求的數量。目前,測試單一因特網服務器的 HTTP服務時要求進行負載測試,結果表明:在完成單一“GET_SESS”API的標準測試下可達1 800 次/s。
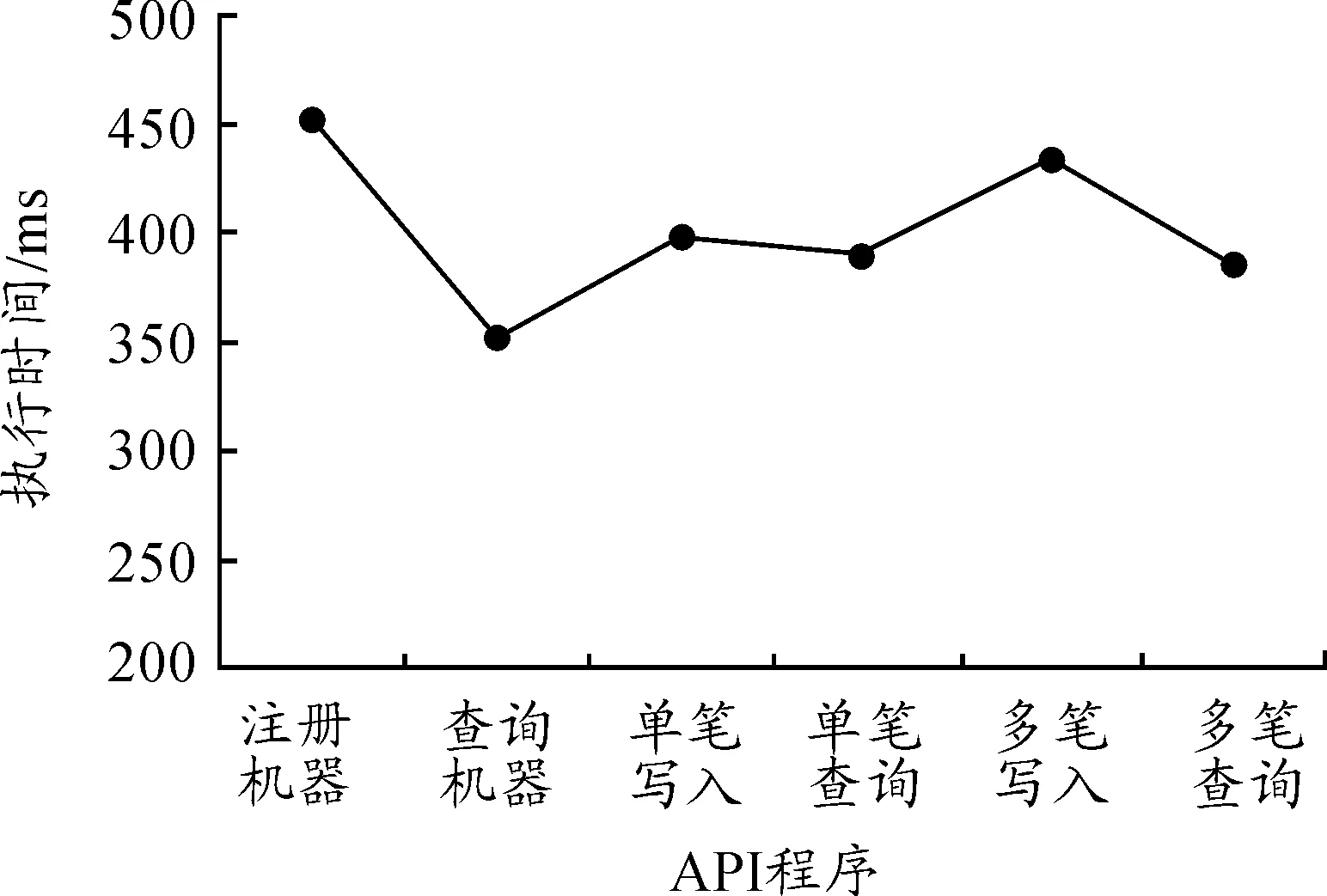
圖4 應用程序編程接口(APIs)運行時間
對于數據處理與分析的平臺服務時間效能測試結果見表3。

表3 數據處理時間效能
對于數據查詢的時間效能與傳統關系數據庫的比較如圖5所示。
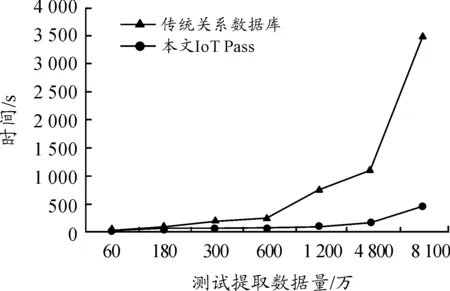
圖5 查詢數據(50萬筆)時間比較
可以看出:本文平臺并行式數據存取架構突破傳統硬件架構存取效能,以分布式儲存技術(Spark并行式數據計算叢集)提高大數據存取與平行分析效能,數據加載時間比傳統SQL服務器減少了80%。
5 結束語
本文提出一種IoT PaaS平臺,其目標在于能為客戶端有效解決終端設備大數據的處理與分析,從而推導出智慧管理策略,以有效提高產能。在數據量與多樣性方面為分布式儲存架構與非結構化數據庫的設計提供解決方案。在速度上,對于來自客戶端的API執行要求,由于提供加解密的保護機制占據了執行的大多數時間,運行時間達毫秒級。在附加價值上,提供分布式計算的 Spark環境加上分布式文件系統的可擴充性,對于原始數據分析的規模與復雜度可再進行擴增以提升其結果的價值與效能。實驗結果表明:數據查詢速度與傳統數據庫相比有顯著提高。未來研究將主要關注如何減少解密過程的時間。
猜你喜歡
今日農業(2019年14期)2019-09-18 01:21:54
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年15期)2019-01-03 12:11:33
今日農業(2019年16期)2019-01-03 11:39:20
商周刊(2017年9期)2017-08-22 02:57:56
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
