基于校園大數據的學生行為特征分析與預測方法
2019-08-17 07:40:00李鐵波
重慶理工大學學報(自然科學) 2019年7期
李鐵波
(吉林交通職業技術學院, 長春 130000)
隨著信息技術的不斷發展,校園中各項服務管理平臺不斷增加,使得積累的數據呈海量增長,包括學生消費規律、生活習慣以及學習情況等行為數據,已經形成了一個比較完整的校園大數據環境[1]。為實現校園數據的高效管理和共享,充分利用學生在校行為數據建設數字校園、智慧校園,使得校園信息化水平得以提升,需要采用數據挖掘方法優化學生管理,根據學生的行為特性分析其行為規律,及時指導學生行為向全面、健康方向發展。因此,對學生行為進行挖掘分析已成為學生管理的關鍵問題。文獻[2]建立了學生校園行為分析預警系統,通過挖掘學生行為和心理問題,幫助管理者進行宏觀決策,輔助教學安全管控;文獻[3]對學生網絡行為指標和成績數據進行挖掘,采用線性支持向量機、梯度上升樹和KNN等算法檢驗了學生學習能力對學習成績的影響程度,并給出了需要對學生進行干預的閾值;文獻[4]采用矩陣模式合并不同的數據,并采用Hadoop分布式處理平臺提高大數據處理效率;文獻[5]采用決策樹、關聯規則、邏輯回歸3種數據挖掘方法對學生上網行為相關屬性與學生學習質量之間的關系進行了研究,實現了較好的預期效果。
基于此,針對目前學生信息化管理過程中存在的問題,建立了基于校園大數據的學生行為分析與預測平臺,圍繞大數據環境下學生消費規律、生活習慣、學習情況等行為數據,利用決策樹、神經網絡以及樸素貝葉斯組合預測模型,分析學生行為特點和規律,對學生行為進行預測和預警,便于學校掌握學生生活與學習動態,及時做好引導,實現對學生的有效管理。
1 數據挖掘理論
1.1 數據挖掘流程
數據挖掘指在海量數據中提取隱含的具有潛在利用價值的信息,并通過分析為人們提供決策作用的過程。數據挖掘是一個不斷往復優化的過程,主要包括數據預處理、數據挖掘以及模型評估,其流程如圖1所示。數據預處理是將雜亂的、不符合規則的數據進行清洗和篩選,為數據挖掘提供數據基礎;數據挖掘是在處理好的數據中提取有用信息的過程,是數據挖掘的核心環節;最后要對模型進行評估,以檢測結果是否達到預期要求[6]。

圖1 數據挖掘流程
1.2 數據挖掘算法
對已有的信息進行數據挖掘分類分析,可以得到預測模型。不同的模型,所用算法也各不相同,隨著研究的不斷深入,各種算法不斷被完善和優化。根據研究內容,現只對決策樹、神經網絡以及樸素貝葉斯算法進行分析對比。
1) 決策樹分類方法、
決策樹是一種基于信息增益理論的預測模型,代表對象屬性與對象值之間的一種映射關系,是目前應用最廣泛的數據分類算法之一。決策樹是一種樹形結構,包含了若干個節點和分支,分別代表某個屬性上的測試和測試輸出。決策樹分類精度高,易于理解和實現,但不適合類別較多的數據結構。常見的決策樹算法有ID3、C4.5/C5.0等[7],主要用于事件的預測分析,預測過程通常分兩步:一是構建決策樹,由訓練樣本進化而成;二是決策樹的剪技。對決策樹進行檢驗、校正,測試各節點的屬性值,對輸入數據進行分類,然后用該類的屬性值完成預測對象的估計。例如預測用戶是否具有償還貸款的能力,可用圖2表示。
2) 神經網絡分類方法
神經網絡以海量數據并行處理和計算為基礎,具有自學習和高速尋找優化解的能力,通常用作數據分類、聚類及預測。BP神經網絡是一種按誤差逆傳播算法訓練的多層前饋網絡,能學習和存貯大量的輸入和輸出映射關系,是目前應用最廣泛的神經網絡模型之一,其表達式為[8]:
H=fj(∑wijxi+θj)
(1)
式中:wij為網絡權重;θj為神經網絡閾值;fj為激勵函數;xi為網絡的輸入。
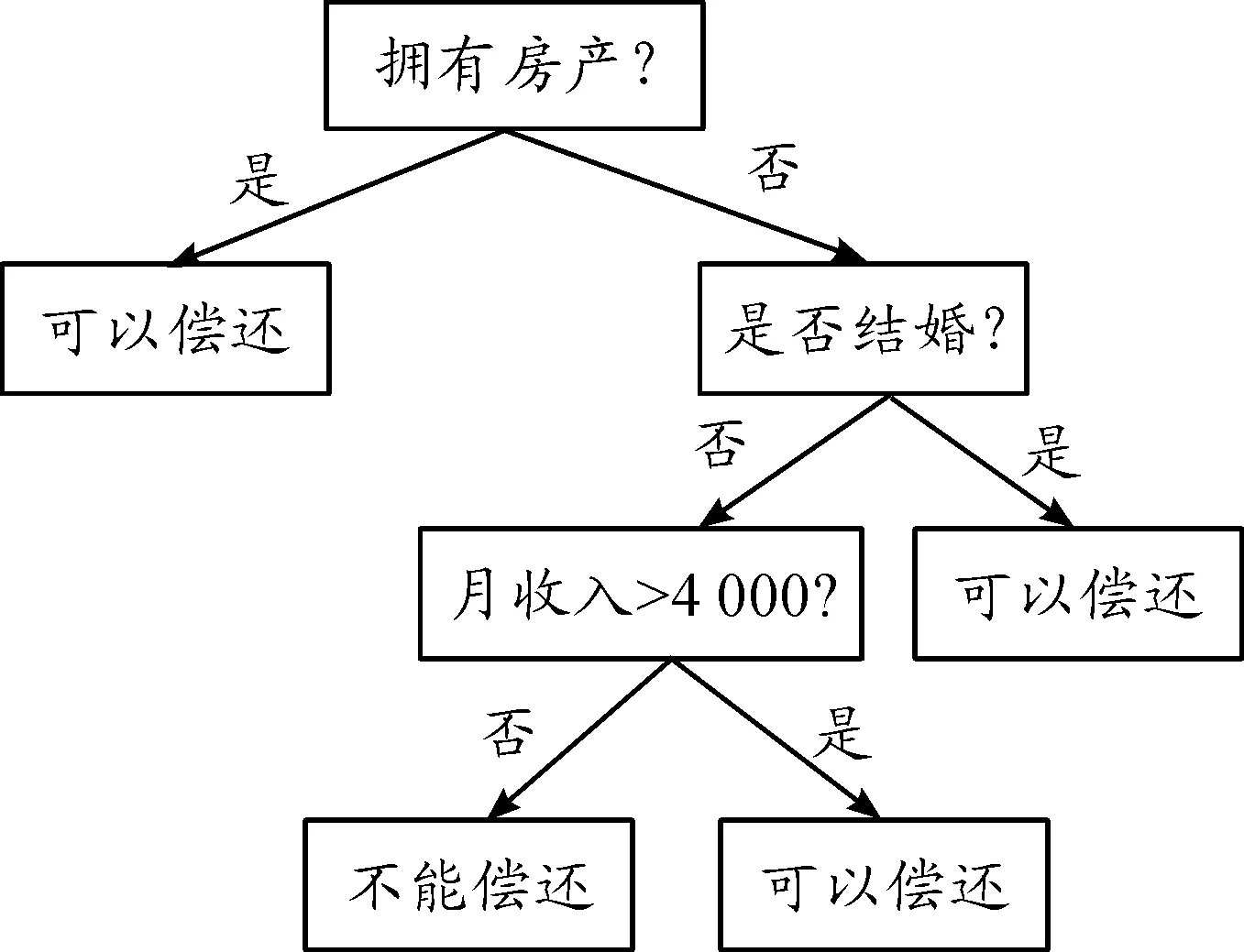
圖2 決策樹結構模型
神經網絡的學習和記憶具有不穩定性,為完成對復雜非線性映射功能, BP神經網絡采用有師學習方式進行訓練,如圖3所示,訓練中以誤差最小為原則,逐層修正各閾值和權重系數。

圖3 BP神經網絡訓練過程
3) 樸素貝葉斯(NB)分類算法
樸素貝葉斯是一種簡單的概率分類算法,是求解每個待分類實例在各個類別中的后驗概率。設X表示屬性集,包含d個屬性,Y表示類變量,P(Y|X)為Y的后驗概率,P(X|Y)表示類別Y的條件概率,P(Y)稱為先驗概率。現有一類別的標號為y,以特征屬性間的相互獨立為前提,類條件概率可表示為:
(2)
由此可推導出樸素貝葉斯公式[9]:
(3)
算法流程如下:
① 設x=(a1,a2,…,an)為待分類樣本,aj=(j=1,2…,n)為樣本各屬性取值;
② 選取訓練樣本,用n維向量X表示數據樣本,類標簽集合為C=(c1,c2,…,cm);
③ 計算各屬性在給定類標記下的條件概率;
④ 確定后驗概率的大小;
⑤ 預測屬性集所屬類別。
1.3 基于多算法組合的數據挖掘模型
針對上述分類算法的特點,將決策樹、神經網絡以及樸素貝葉斯3種分類算法進行結合,構建組合預測模型。現構造Lagrange函數[10]如下:
(α1xi+α2yi+α3zi-yi)2+
(α1xi+α2yi+α3zi-zi)2+
λ(α1xi+α2yi+α3zi-1)
(4)
式中:xi,yi,zi分別為3種模型的預測值;αk為模型的權重系數,k=1,2,3;λ為Lagrange函數算子。變換后得到:
(5)

組合模型的預測流程為:
① 劃分數據集,其中訓練集樣本占60%,測試集樣本占40%;
② 分別選用3種分類算法對訓練集進行建模;
③ 在單一模型中對測試集中的樣本數據進行預測,得到預測結果;
④ 將步驟3中的預測結果代入式(4),計算權重系數,建立組合預測模型;
⑤ 根據式(5)得出組合預測結果,具體流程如圖4所示。

圖4 組合模型預測流程
2 基于校園大數據的學生行為特征分析與預測平臺
2.1 平臺架構與流程
Spark是專為大規模數據處理而設計的快速通用的計算引擎,能更好地適用于數據挖掘與機器學習等需要迭代的算法[11-12]。針對上述問題,建立了基于Spark的學生行為分析與預測平臺,為提高數據處理效率,平臺采用分布式并行計算框架,如圖5所示。
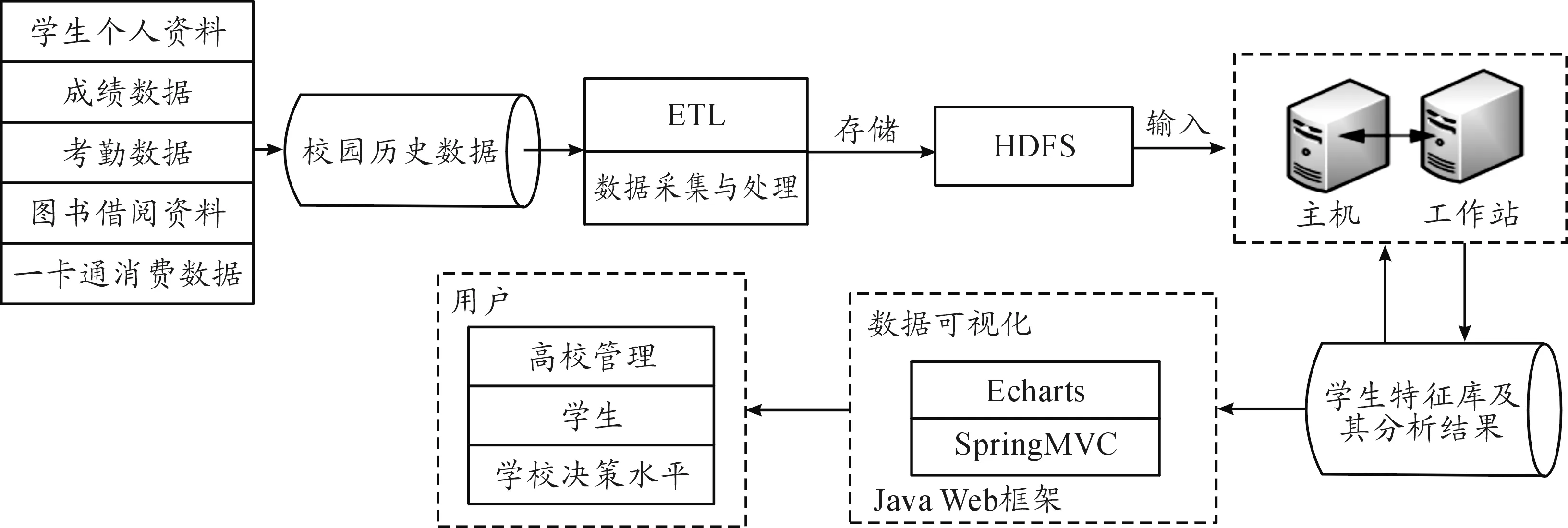
圖5 平臺架構與流程
平臺以校園各管理平臺中學生的消費、考勤、成績以及圖書借閱等數據作為數據來源。首先,將經過預處理后的學生數據存儲到分布式系統 HDFS中,為確保數據轉換方便,以及數據與關系型數據庫中數據類型保持一致;其次,將數據進行聚類分析,關聯規則挖掘,完成對學生行為分類、行為分析等工作,從而通過分析學生行為特征,預測學生生活規律和習慣。
2.2 學生行為數據處理
預處理是整個數據挖掘過程中關鍵的步驟,包括對數據的采集、過濾、分析以及特征提取等幾個過程。其中數據采集是為了獲取學生行為數據,通過校園“一卡通”等各管理平臺獲得;采集后的數據往往雜亂無章,需要進行清洗過濾,以去除重復數據、異常值和缺失值,為數據挖掘提供良好的數據基礎;數據分析是對過濾后的數據進行進一步認識和管理;特征提取是將原始數據進行變換,以此降低數據挖掘的復雜度,獲得準確、有效的數據挖掘結果。通過分析數據可用性以及評價學生在校行為的指標,構建學生行為特征庫,如圖6所示。

圖6 學生在校行為特征指標
1) 消費規律
對學生在學校的消費行為進行分析,提取包括學生消費習慣、月平均消費額、學期消費額、單筆最高消費以及消費頻次等在校消費記錄作為數據特征來源,從而找出學生的消費規律和消費水平。
2) 學習情況
為了分析學生的努力程度和學習成績,以課堂考勤率、圖書閱讀量、學習時長、學習習慣以及課程通過率等作為數據特征來源進行分析,從而了解學生平時的學習情況,掌握學習動態。
3) 生活習慣
為了對學生的生活習慣進行有效評價,將學生的作息時間、身體鍛煉情況、上網時間以及活動地點等作為評價指標,對采集的數據進行分析,從而了解學生平時的生活習慣規律。
2.3 行為結果分析
采用吉林交通職業技術學院數字化校園“一卡通”記錄以及各部門管理系統中的數據作為數據來源,包括10 000名在校學生從2016年10月到2018年10月的學生校園消費記錄、圖書館借閱與自習記錄、校園網絡訪問記錄、課堂學習與成績記錄以及體育鍛煉記錄數據等。首先,通過Sqoop工具將數據進行轉換后導入到HDFS 中并完成對數據清洗等預處理;其次,對準備好的數據進行分析,建立學生行為特征庫;最后,利用特征庫中的各項指標為學校提供管理學生的決策。由于篇幅有限,這里只對與學生學習有關的數據進行處理,以分析學生的努力程度。在Spark 平臺上依據努力程度可將學生劃分為8組,分析得到學生各指標的平均值如表1所示。
由表1可見:第2、3及6組的大部分學生學習比較刻苦,學習成績也比較高,占總人數的54.47%。只有少數的學生努力程度不夠,成績較差,占總人數的5.04%。其余部分的學生雖然成績合格,但努力程度還不夠,如果加以督促成績會有更大進步。分析結果與真實情況基本一致,表明用所提出的方法進行學生行為分析合理有效。
3 基于校園大數據的學生行為特征預測實例
采用所構建的組合預測模型對學生行為進行分析預測,通過平均相對誤差反映學生行為特征預測結果與真實值之間的關系,并與單一預測方法進行對比。測試數據規模分別為200、500、1 000、2 000、5 000以及 10 000 名學生。預測平均相對誤差如圖7所示,學生典型行為特征指標的平均相對誤差如圖8所示。
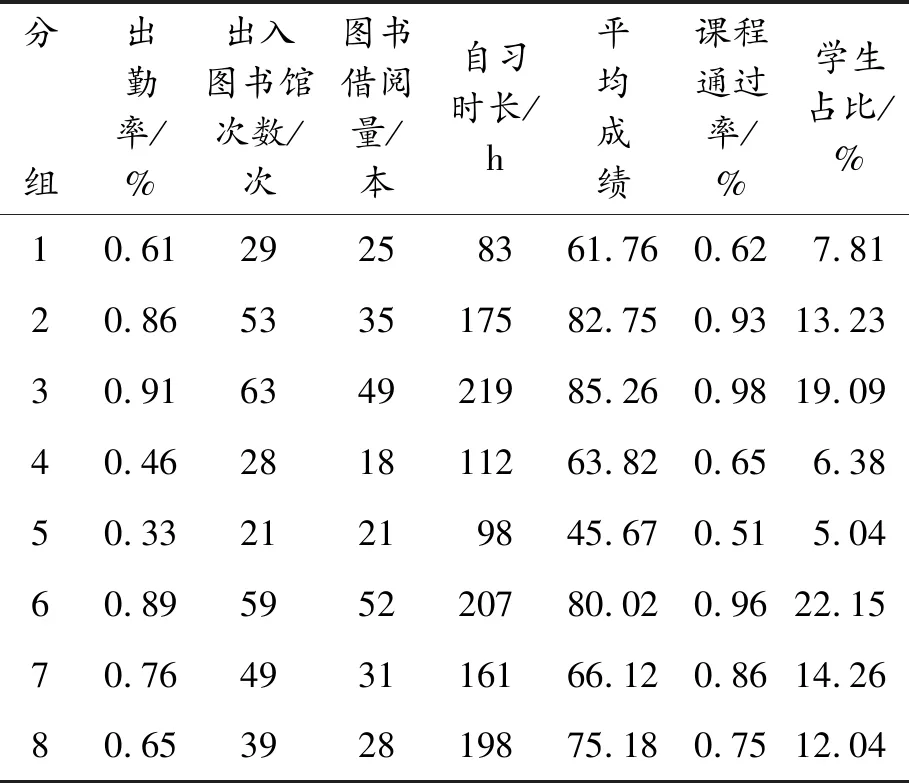
表1 學生努力程度分析結果
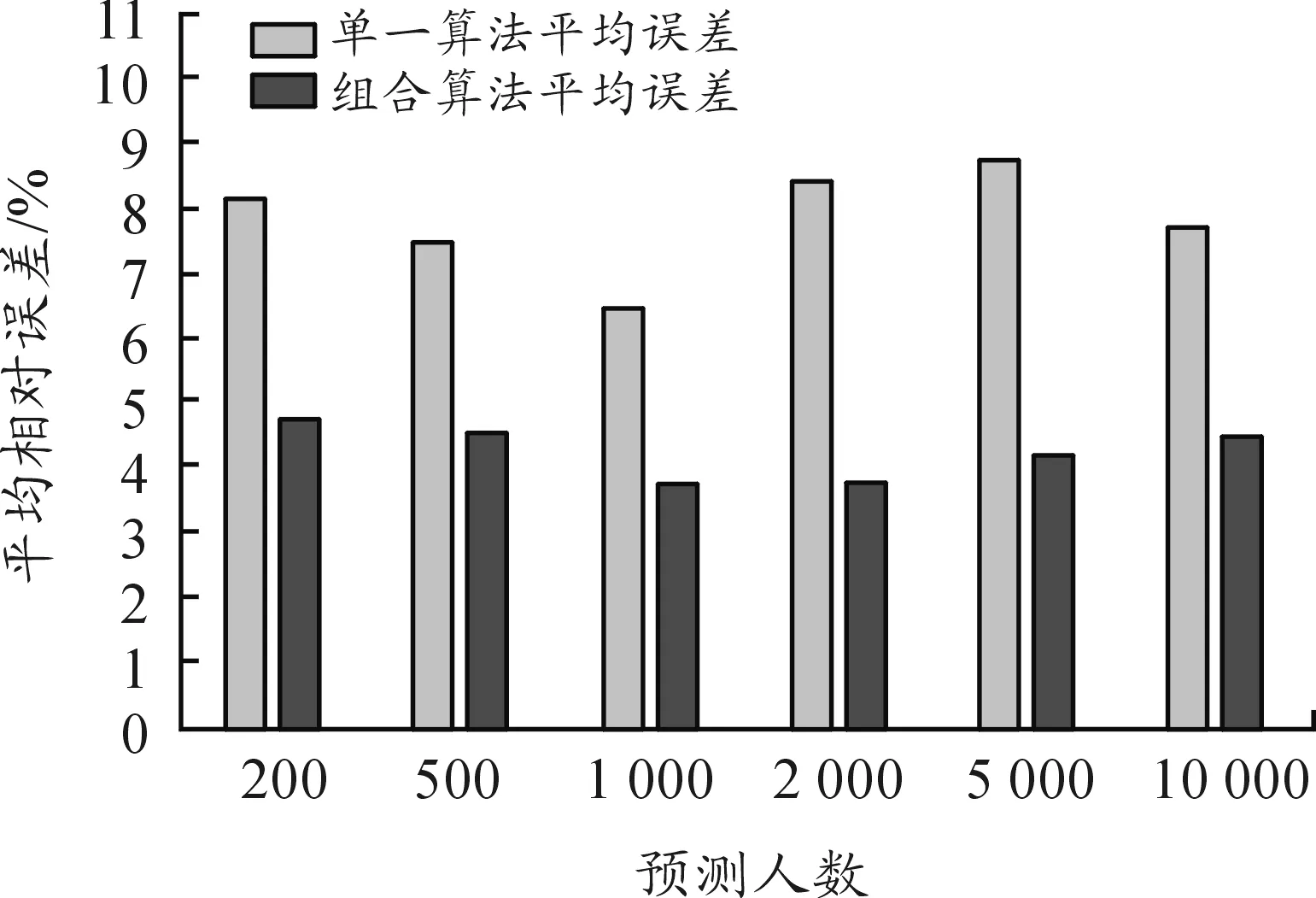
圖7 預測平均相對誤差

圖8 學生行為各指標平均相對誤差
可見,與傳統預測方法相比,本文提出的基于多算法組合的學生行為預測模型預測精度較高,平均相對誤差不超過5%,具有很好的預測效果。隨著預測學生人數的增加,平均相對誤差變化不大,預測精度基本保持穩定,從而表明此預測模型的可擴展性較高。各個學生行為特征指標上的相對誤差分布比較均勻,說明在各維度的學生行為特征上的平均相對誤差都比較小,適合多維學生行為的預測。
4 結論
1) 探討了數據挖掘相關理論,對典型數據挖掘算法進行分析,為提出新的預測模型提供基礎。
2) 利用學生校園行為數據,構建基于Spark的學生行為分析和預測平臺,建立了以消費規律、生活習慣以及學習情況等在校行為為指標的評價體系,從而建立能夠描述學生個人行為的特征庫,分析表明,所建平臺可有效預測學生在校行為,預測結果與實際情況相吻合。
3) 利用決策樹、神經網絡以及樸素貝葉斯算法建立組合預測模型,對典型的學生行為作為實例進行預測。預測結果表明:與傳統預測方法相比,所建組合模型預測精度高,可擴展性好,平均誤差不超過5%,學校可以根據學生的行為特性分析掌握學生生活與學習動態,以及時發現問題,有效預警。
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
電力與能源(2017年6期)2017-05-14 06:19:37
琴童(2017年3期)2017-04-05 14:49:04
小天使·二年級語數英綜合(2017年3期)2017-04-01 17:17:48
山東工業技術(2016年15期)2016-12-01 05:31:22
信息通信技術(2015年6期)2015-12-26 01:16:46
中學生天地(A版)(2015年5期)2015-06-01 02:46:03
下一代英才(2014年10期)2014-10-27 02:33:47
