
端邊云AI算力爆發,華為AI全場景布局浮現
2019-08-23 11:21:14
環球時報 2019-08-23


AI與IoT技術的融合將形成AIoT,也就是萬物智慧互聯。我們現有的生活方式將被重新定義——人與環境的交互從物理按鍵進化到視覺、語音識別或虛擬現實;原本單一的硬件產品開始互聯互通、端側具備智能;無人駕駛、機器助手等新物種的出現等。AIoT即將成為工業機器人、智能手機、無人駕駛、智能家居及智慧城市等新興產業的重要基礎。
伴隨5G技術商用,AIoT會加速落地和實現。可預見的是,未來巨量的多維數據(如語音、圖像、視頻等)集中處理與邊緣式分布計算的需求,將進一步挑戰AI底層支持硬件——芯片的計算能力。同時,AIoT場景下AI應用對于端邊云互動有著強需求。強大的云會讓邊、端能力更強,而強大的端、邊則可提升數據處理的實時性和有效性,進而增強云的能力,二者需要緊密結合。
另一方面,在應用場景中,跨平臺兼容問題、訓練成本、大規模部署問題層出不窮。想出一個模型不難,開發出來也還好,但要把框架里的算法部署到數量眾多的物聯網設備上,問題將是無窮無盡的。本地算力、網絡連接能力、平臺間的不兼容,都讓開發者望而卻步。
業界首創的全棧全場景AI解決方案
2018年10月,華為副董事長、輪值董事長徐直軍在2018華為全聯接大會,發布了華為AI戰略及全棧全場景的解決方案。有媒體評價,華為在AI領域是三年不鳴,一鳴驚人。
其中最受人關注的是華為一直保持神秘的芯片產品——昇騰系列芯片。從華為公布的信息來看,昇騰(Ascend)芯片層,包含了從AscendNano、Lite、Tiny一直到云側使用的As?cendMax。可以看出昇騰系列芯片是完整AI堆棧解決方案的基礎層,目標是在任何場景下以最低成本提供最佳性能,使不同應用可以選擇最優的AI算力解決方案。
而是否要采用統一架構,是十分關鍵的選擇。統一架構的好處是:只需一次算子開發,就可在任何場景下使用;跨場景一致開發和調試體驗;更重要的是,一旦完成某個芯片的算法開發,就可順利將其遷移到面向其它場景的其它芯片上。
完美的想法如何完美實現呢?從傳統設計思路來看,無非兩種選擇:
一、采用堆疊擴展(Scaleout)的方法實現巨大的計算可擴展性。首先,設計針對最小或較小計算場景進行優化的架構,然后通過堆疊來匹配最大的計算場景,但這將不可避免地增大芯片面積和功耗,直至難以接受;
二、采用向下縮小(Scalein)的方法,即首先設計針對最大或較大計算場景進行優化的架構,然后通過精細分割來匹配最小的計算場景,但這必將導致任務調度和軟件設計異常復雜,并且可能由于電流泄漏而使低功耗目標無法達成;
面對如上利弊點,華為創造性的提出了達芬奇架構,通過可擴展計算、可擴展內存和可擴展互連等三大獨特關鍵技術,使統一架構成為可能。
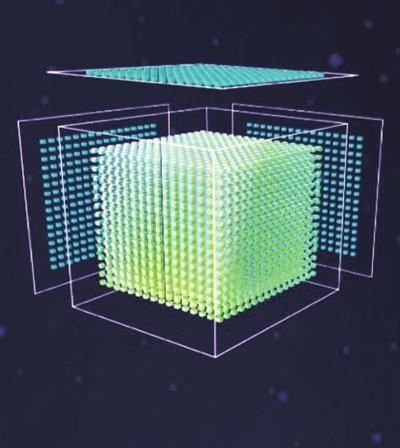
為實現高可擴展和靈活的計算能力,華為首先設計了一個可擴展的3DCube作為超高速矩陣計算單元,在其最大配置(16x16x16)下,一個Cube可在一個時鐘周期內完成4096個FP16MACs運算。以16x16x16為中心,具有CubeScalein功能和高效的多核堆疊功能,這樣就可以使用一種架構來支持所有場景。對于計算能力較低的應用場景,Cube可以逐步縮小到16x16x1,在一個周期內完成256個MACs運算。這種靈活性與一套指令集結合,成功提供了計算能力和功耗的平衡。
為實現高可擴展內存,每個達芬奇Core都配備專用SRAM,其功能固定,容量可變,適應不同的計算能力場景,提升了計算過程中數據的交換速度。
芯片內超高帶寬Mesh網絡將多個達芬奇內核連接在一起,保證內核之間以及內核與其它處理單元之間的極低延遲通信,使得高密度計算內核的性能得到充分利用。
今年4月,基于昇騰310 (Ascendmini)的Atlas人工智能計算平臺正式開售,覆蓋了從終端、邊到云數據中心推理場景:
Atlas200尺寸僅有信用卡一半大小,是一款高效能的嵌入式AI加速模塊,可以實現圖像、視頻等多種數據分析與推理計算,可廣泛被集成到智能攝像頭、機器人、無人機中。
Atlas300智能加速卡是半高半長的PCIeAI加速卡,可幫助傳統服務器實現AI算力騰飛,不僅可以提供多種數據精度及業界領先的性能,還可以兼顧能效限制,可廣泛應用于數據中心和智能邊緣。
Atlas 500智能小站是業界領先的智能邊緣產品,機頂盒大小,可實現16路高清視頻處理能力;同時也是業界首款應用半導體制冷散熱技術的智能邊緣產品,不用風扇散熱,可滿足-40°-70°室外工作環境。
Atlas800深度學習系統是一站式深度學習平臺服務,內置大量優化的網絡模型算法,幫助用戶輕松使用深度學習技術提供數據標注、模型生成、模型訓練、模型推理服務部署的端到端能力,降低使用AI的技術門檻。
據悉,華為將在8月23日發布最新的昇騰芯片,會不會是久聞大名的As?cendMax?拭目以待。
猜你喜歡
理科愛好者(教育教學版)(2022年2期)2022-05-05 00:24:02
甘肅教育(2021年10期)2021-11-02 06:14:02
閱讀與作文(英語初中版)(2021年8期)2021-09-13 02:16:29
甘肅教育(2020年21期)2020-04-13 08:08:42
家庭影院技術(2020年2期)2020-03-25 13:27:36
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
數學大世界(2018年1期)2018-04-12 05:39:02
