一種采用Hilbert空間排列碼的場景數據調度策略
2019-08-26 05:04:42孫立偉袁昱緯周俊芳
無線電工程 2019年9期
關鍵詞:效率
孫立偉,袁昱緯,周俊芳
(1.中國人民解放軍91977部隊,北京 102249;2.中國人民解放軍92999部隊,北京 102400)
0 引言
場景數據的調度策略是實現大規模場景數據的存儲管理[1]、處理[2]、瀏覽顯示[3]和分發[4]應用[5]的基礎,對于數字地球等[6]應用性能也起著決定性的作用。隨著場景數據量以幾何級數增長,數據規模越來越大,給場景數據的組織調度效率帶來了極大的考驗[7]。目前,許多學者對數據調度算法進行了研究。霍巍提出了一種基于層次金字塔結構和四叉樹索引結構相結合的數據組織調度方法,僅僅在內存中存儲了索引結構,提高了檢索效率,但是數據冗余嚴重[8]。劉恒飛則設計了一種基于四叉樹索引結構與網格劃分的數據調度方法,減少了數據重復存儲,提高檢索效率[9]。吳穎等人則利用四叉樹分割的思想,實現對大規模場景數據的裁剪,提升場景的繪制效率,減少了內存占有率[10]。通過對傳統四叉樹索引技術[11]應用到海量場景數據調度進行研究,可知數據調度的研究主要集中在數據存儲、層次劃分以及空間索引等方面,因此本文研究并提出了一種采用Hilbert空間排列碼的大規模場景數據調度策略,利用空間排序碼的空間聚集特性,將海量高維數據向低維空間靠近,同時通過最近鄰算法提高相鄰空間數據連續存儲的概率,優化場景數據存儲管理,提高數據調度效率。
1 Hilbert空間排列碼
Hilbert曲線[12]于1891年提出,源自Peano曲線簇。采用Hilbert曲線可以建立二維甚至多維空間向一維線性空間的一一映射關系,這個一維線性空間的映射序列稱為Hilbert空間排列碼。Hilbert空間排列碼具有優良的空間聚集性能[13-14],可以使二維或多維空間中相鄰的元素在轉換的一維線性序列中盡量相鄰。
吳明光等[15]將Hilbert曲線引入數據集劃分問題,提高數據空間分布的均衡性,吳晨等[16]等將Hilbert曲線引入HBase遙感影像檢索中,提高了影像數據的檢索效率。楊明遠[17]等將Hilbert曲線引入數據庫存儲結構優化中,較大幅度地增強了算法的空間范圍查詢效率。
本文考慮在對三維場景數據集的管理中,對于瓦片狀分布的空間實體[18-19],引入Hilbert曲線及Hilbert空間排列碼,利用其空間聚集性能,優化場景數據管理策略,增加空間中相鄰的場景數據在存儲時同樣連續的概率,使場景數據處理時磁盤盡量連續讀取,提高數據調度的效率。
2 基于Hilbert空間排列碼的數據調度策略
本文采用一種高效的Hilbert空間排列碼最近鄰查詢方法,有效地規避Hilbert在臨域查詢時計算復雜的弊端,同時利用Hilbert空間排列碼良好的空間聚集性能,提高數據管理時的搜索和調度效率,具體算法描述如下:
(1)三維場景數據集的預處理
遍歷三維場景所有區域,將場景劃分為N×N個地形分塊,并構建金字塔模型的層次結構;在邏輯層面上,一般采用四叉樹對金字塔模型的層次結構進行組織和管理。
(2)專用數據集的Hilbert排列
該金字塔模型的每個層級中,每個地形分塊采用Hilbert空間排列碼的順序編碼,并按照該編碼順序進行存儲和管理。
由地形分塊的格網編碼轉化為Hilbert空間排列碼的方法如下:
① 將索引地形分塊格網的行列數采用二進制位交叉方法轉化為對應的Morton碼;
② 將Morton碼轉化為二進制,以兩位為一個單位,由高位開始,對生成的Morton碼中的10和11互換;
③ 由高位開始,設為ti,對后續各位中的10和00進行互換;
④ 將結果按順序排列,即為Hilbert空間排列碼。按照Hilbert空間排列碼的順序練成曲線如圖1所示,高階的Hilbert空間排列碼可由圖1遞歸產生。
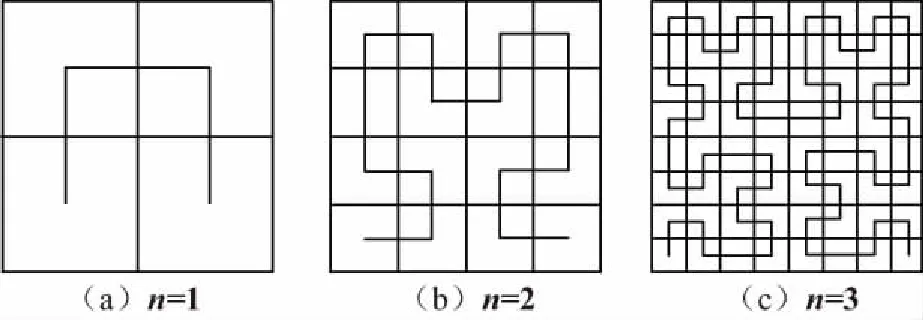
圖1 Hilbert空間排列碼示意
(3)計算視場區域格網坐標范圍
首先將視點F處的經緯度換算為格網坐標。然后為減少浮點運算,提高數據讀取效率,視場區域內的其他格網坐標,不再采用經緯度進行換算,而采用格網坐標累加的方法得到,直至遇到邊緣的角點,如圖2所示。
假設視點F處的格網坐標為(x,y),圖2中的深灰區域為視點F處可見的視野范圍,并為其進行分塊,每個分塊大小的邊長為a。視野范圍中右側矩形區域左上角格網坐標為(x+[V/a],y+[w/2/a]),右下角格網坐標為(w+{V+L}/a,y-{w/2/a}),(其中,[]表示向上取整,{ }表示向下取整),視野范圍中左側三角形所在的格網坐標則由矩形區域左上角、左下角和視點區域坐標推出。
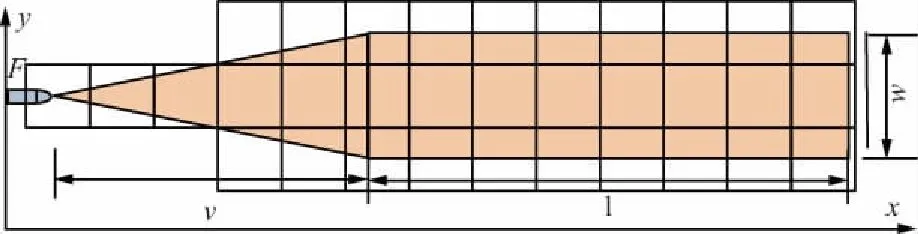
圖2 視野區域格網坐標范圍示意
(4)采取基于視點擴散的讀取思路,提取視場范圍內的地形分塊數據
得到視野區域所需地形分塊的格網坐標后,按照(2)中的方法計算視點F的Hilbert編碼;然后以F點的Hilbert為起點,按照視點方向,進行臨域搜索,搜索范圍限定在(3)得到的格網范圍內,將該范圍完全遍歷。
(5)按照Hilbert空間排列碼順序讀取和處理
在上一步的臨域搜索和遍歷的同時,對于每搜索一個分塊格網將其讀取,供處理和顯示使用。讀取時,按照首地址+偏移地址的方式進行,偏移地址=(本影像塊編碼-首影像塊編碼)×每個影像塊所占用的磁盤空間。
采用本算法對空間數據進行管理和調度,使后續進行的空間數據調度效率得到了很大的提高。例如,按照空間范圍進行查詢時,通過查詢區域內的格網范圍,得到對應的Hilbert空間排列碼,以此計算偏移地址進行提取,可以較大地減少重新計算地址的計算量,減少空間索引量,提高數據調度的性能。此外,由于Hilbert空間排列碼優秀的線性映射特性,空間數據按照該順序存儲后,空間中相鄰的地形分塊在線性存儲上也是盡量相鄰存儲的,從而減少了磁盤的訪問時間,提高了數據處理效率。
3 實驗結果
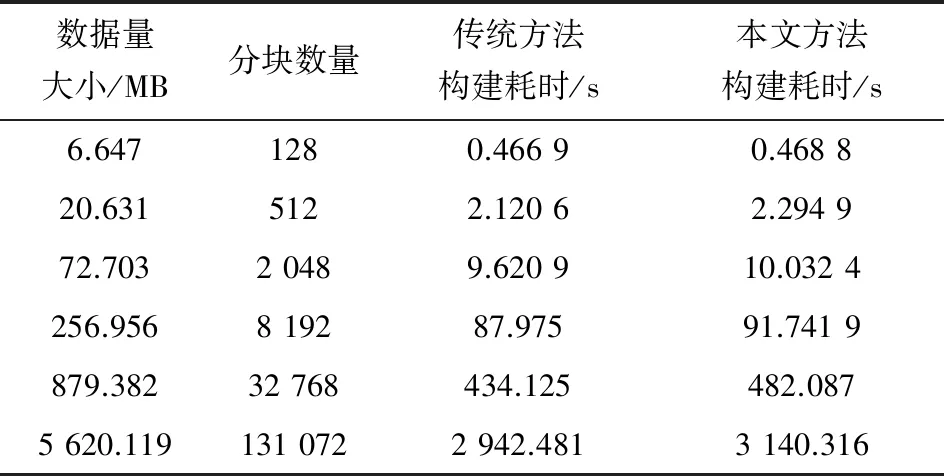
實驗采用的硬件環境為Intel Xeon? CPU E3-1271 V3 3.60 GHz,8 GB內存,NVIDIA Quadro K2200顯卡,軟件環境為Windows7,VS2010。實驗素材選取了6組場景數據,其大小分別為6.65,20.63,72.10,257.93,889.28,5 602.91 MB,分塊數量分別為128,512,2 048,8 192,32 768,131 072。
3.1 基于Hilbert空間排列碼的三維場景數據集構建測試
對6組場景數據分別采用將經典四叉樹編碼索引算法和本文提出算法構建數據集,并對比2種方法在構建時的耗時。實驗分別記錄經典四叉樹編碼索引算法和本文提出算法構建數據集的時間開銷,每組場景數據各測試5次,并計算平均值。經過實驗驗證,實驗結果如表1所示。
表1 構建結構耗時的測試結果
數據量大小/MB分塊數量傳統方法構建耗時/s本文方法構建耗時/s6.6471280.466 90.468 820.6315122.120 62.294 972.7032 0489.620 910.032 4256.9568 19287.97591.741 9879.38232 768434.125482.0875 620.119131 0722 942.4813 140.316
從實驗結果可以看出,本文方法與傳統方法在進行三維場景數據集構建的耗時相當。由于四叉樹構建的時間復雜度一般為O(nlogn),與本文算法的時間復雜度相當,其中,n為層次結構中最底層分塊數量。本文方法略多的耗時主要發生在Hilbert排列碼的計算上。
3.2 場景數據隨機讀取測試
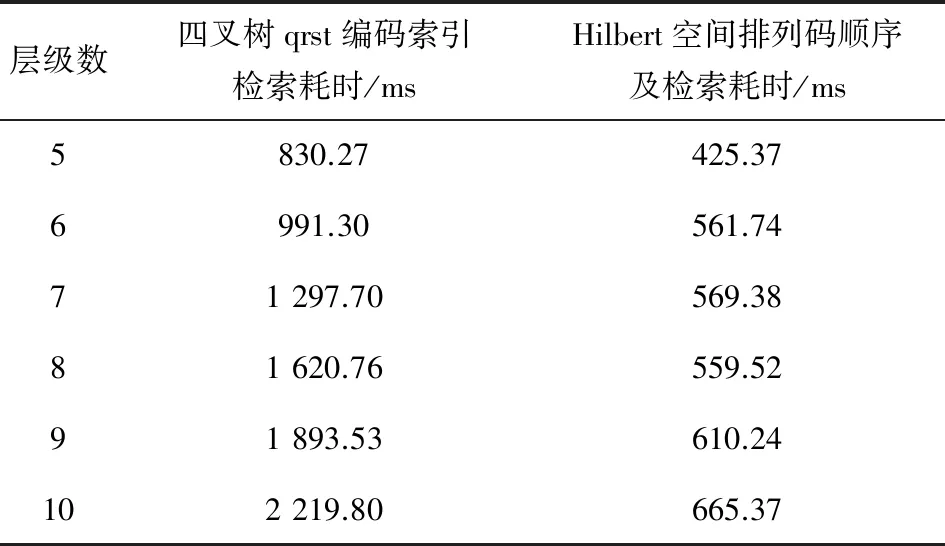
將6組實驗場景數據在金字塔模型的層次結構中進行分級、分塊后,得到層級數分別為5~10層,實驗時分別采用本文提出方法(Hilbert空間排列碼順序)和四叉樹結構(在各層級中按照先行后列、從左到右的順序)方式進行測試。實驗時,隨機指定行列號,讀取并顯示以該位置為中心的10×10個地形分塊,記錄使用上述方法在索引和讀取上的時間開銷。每組實驗場景分別進行5次測試,并計算平均值,如表2所示。
表2 場景數據隨機讀取耗時的測試結果
層級數四叉樹qrst編碼索引檢索耗時/msHilbert空間排列碼順序及檢索耗時/ms5830.27425.376991.30561.7471 297.70569.3881 620.76559.5291 893.53610.24102 219.80665.37
由表2中的實驗數據可知,本文提出的方法(Hilbert空間排列碼順序)與傳統方法的四叉樹結構(先行后列、從左到右的順序)相比,隨機讀取效率明顯提高。本文算法在數據讀取時的時間復雜度為O(nlogn),比經典四叉樹算法的O(n)略多,其中n為層級數;但由于本文方法利用了Hilbert空間排列碼的特性,瀏覽三維場景時讀取的場景分塊一般為連續的,Hilbert空間排列碼在組織數據時,空間上相鄰的分塊在磁盤存儲時相鄰的概率較經典四叉樹方法大很多,大部分的讀取能夠連續進行,減少了磁盤尋址時的開銷,縮短影像塊的讀取時間。
4 結束語
針對三維場景實時性瀏覽中的數據調度問題,本文研究了一種采用Hilbert空間排列碼的三維場景數據調度策略,通過Hilbert空間排列碼生成方法構建數據集,以提高數據管理時的搜索和讀取效率。試驗表明,與基于傳統四叉樹的調度策略相比,在構建時間相當的基礎上,本文方法的隨機讀取時間明顯減少,具有更高的場景數據調度效率。
猜你喜歡
瘋狂英語·初中天地(2021年5期)2021-07-21 02:24:28
甘肅教育(2020年14期)2020-09-11 07:57:42
中學生數理化(高中版.高考數學)(2020年5期)2020-06-02 09:19:08
商周刊(2017年9期)2017-08-22 02:57:49
遼寧經濟(2017年6期)2017-07-12 09:27:16
中國衛生(2016年9期)2016-11-12 13:27:54
時代英語·高二(2015年1期)2015-03-16 00:08:11
中國洗滌用品工業(2015年7期)2015-02-28 19:02:38
電子設計工程(2015年12期)2015-02-27 12:06:10
中國衛生(2014年11期)2014-11-12 13:11:32
