低時延網絡:架構,關鍵場景與研究展望
2019-08-29 08:09:30左旭彤王莫為崔勇
通信學報 2019年8期
關鍵詞:優化
左旭彤,王莫為,崔勇
(清華大學信息科學技術學院,北京 100084)
1 引言
新應用和新場景的出現使網絡空間更加復雜,不同的應用和場景對于網絡的性能要求不盡相同,時延是影響性能的重要評價指標之一。對于游戲、直播等應用,時延是影響其用戶體驗的決定性因素;而對于物聯網(IoT,Internet of things)、自動駕駛等場景,時延則決定其能否正常工作。
計算機網絡體系采用分層架構,網絡功能被解耦并分配在不同層,每一層按照不同的協議實現各自的功能,共同完成數據傳輸過程。然而,每層協議或功能的完成可能會使應用的時延增加,比如在TCP(transmission control protocol)中通過重傳機制來保證可靠傳輸,但是這可能會增加數據分組的傳輸時延,因此低時延的實現需要每一層的努力。同時,對于特定的低時延場景,如數據中心網絡、5G 網絡和邊緣計算,傳統的分層體系架構針對一般網絡提出的低時延技術可能不再適用,需要結合場景不同特點進行時延優化。
此前有綜述工作按照時延的來源對網絡中降低時延的技術進行詳盡的分類,提供了對時延產生原因的全面分析[1-2],但是這些工作提出的技術可能無法適用于特定場景的超低時延需求或者新架構。對于不同的低時延關鍵場景,也有分別針對數據中心網絡[3-4]、5G 網絡[5-6]及邊緣計算[7-8]的綜述,但是它們僅關注某一個具體的場景,無法提供對網絡體系結構時延來源的整體分析與技術的泛化遷移。
本文在分析了應用時延需求的基礎上,按照傳統的網絡層次架構闡述了時延的來源及多種影響時延的因素,如網絡負載、路由決策等,并介紹了能夠減少協議機制與網絡功能引入時延的相關技術。
除了對傳統體系結構中時延進行分析,本文還將低時延分析具體化至數據中心網絡、5G 網絡、邊緣計算等關鍵場景。它們分處“云、管、端”的不同位置,互相配合共同構建整個低時延網絡架構。與廣域網不同,數據中心具備更高帶寬更低時延的特性,并可以靈活部署。利用其特性設計傳輸協議和優化網絡拓撲結構可以降低數據中心中任務處理的時延。隨著5G 的發展,超高數據率和超低時延成為可能,5G 為優化時延在架構調整和關鍵技術上做出努力。物聯網的興起使處在網絡邊緣的設備產生的數據量急劇增加,這加重了云端計算和網絡傳輸負載。邊緣計算通過將計算與存儲下移至網絡邊緣,降低傳輸及云端計算負載,避開網絡傳輸瓶頸并縮短傳輸距離,為用戶提供高帶寬低時延的服務。
2 應用時延需求
時延敏感型應用和超低時延場景的出現對時延提出了嚴格的要求。幾種典型應用的時延需求及需要低時延的原因如表1 所示,本節對每一種應用進行簡單介紹。最后以直播場景為例,分析該應用時延的組成。低時延網絡的研究使這些應用性能得到提升,進而優化用戶體驗。
在直播、虛擬現實(VR,virtual reality)、增強現實(AR,augmented reality)等用戶參與度較高的場景下,時延需求主要來自人與人或者人與設備之間的流暢交互。在互動直播場景下,時延超過1 s會極大影響主播與觀眾的用戶體驗[9]。VR、AR 場景中要求設備能對人給出的信號做出及時的反應,因此,人機交互體驗的優化對時延提出了10 ms 的高要求[10]。

表1 幾種典型應用的時延需求及其原因
在自動駕駛場景下,車輛要在復雜的交通環境中及時感受到環境的變化并做出反應,這要求車輛與車輛、行人、道路設施之間進行低時延通信,其時延需求達到幾毫秒[11]。另外,自動駕駛設備需要進行人機交互,尤其是切換駕駛模式的情況下,要求設備模式切換在復雜的環境中不出差錯,這也需要超低時延。
在IoT 的場景下,人與設備或設備與設備在協調工作時需要通過網絡進行通信。在工業互聯網的場景下,工廠實現高效率的自動化生產需要完成實時的操作控制,如果生產的某些步驟因未及時接收到指令而出現滯后便會影響產品質量甚至導致系統崩潰,因此工業互聯網對于時延也提出了較高的要求,達到1~10 ms[12]。
根據本節之前所述,不同的應用和場景對網絡時延有不同的需求,低時延網絡的研究使這些應用成為可能。為了滿足應用的低時延需求,首先需要探究時延的可能來源及降低時延的技術,本節接下來會以流媒體直播應用為例進行簡要闡述。
隨著視頻直播的興起,直播的質量與用戶體驗受到學術界與工業界的廣泛關注,時延是其中一個重要的評價指標。目前在比較流行的交互式直播中,觀眾會與主播進行互動并希望得到及時的回應。為了實現更加流暢的交互體驗,在實際應用中會采用時延較低的實時消息協議(RTMP,real-time messaging protocol),此時主播與觀眾之間的端到端時延可以劃分為3 個部分,分別是主播端視頻內容上傳到服務器的時延、將視頻從服務器下載到客戶端的時延和下載內容在客戶端緩沖的時延[13]。
對于直播來說,播放流暢和低時延都有助于獲得良好的用戶體驗。為防止因網絡抖動造成視頻卡頓,客戶端中往往會設置視頻緩沖區,但這會導致下載到客戶端的視頻幀不能被立即播放。視頻幀到達客戶端的時間與該幀被播放時間的差值就是在客戶端緩沖區的時延,測量和研究表明客戶端緩沖的時延在端到端時延中占有最大的比例[13]。有眾多研究關注客戶端緩沖時延優化問題,調整客戶端播放邏輯、優化傳輸等方式從網絡架構的不同層次優化了緩沖時延,同時不會導致視頻卡頓。
調整客戶端的播放邏輯以適應網絡狀況的變化需在應用層做出優化。在客戶端,調整預緩沖的數據量[14]及在播放過程中根據網絡抖動情況進行緩沖區大小的調整可以降低客戶端緩沖時延[15]。緩沖區的歷史長度可以反映網絡抖動狀況,在網絡抖動小時,縮短緩沖區長度可以實現低的客戶端緩沖時延。對于下層的數據傳輸,也需要明確時延的來源并進行優化。以傳輸協議選擇為例,在直播中應選擇不需要切片的低時延的RTMP 協議而非HLS(HTTP live streaming)協議,但是上述2 種協議均基于TCP,為了進一步降低時延,可以設計基于UDP(user datagram protocol)的專用傳輸協議。
通過上述的分析可知,降低應用感受到的時延需要網絡架構從上層到下層的共同努力。在第3 節,會按照網絡的分層體系架構,詳細地分析時延的來源并介紹相應的降低時延的技術。
3 分層模型中的低時延
為使復雜的計算機網絡系統簡化,網絡體系結構被設計為分層模型,每一層都有特定的功能,以完成數據通信的過程。網絡體系結構中每一層通信協議和處理機制的設計極大地影響了數據傳輸的性能,本節將按照網絡體系結構的分層模型對網絡中的時延來源進行分類,介紹為了降低時延而設計的協議或技術并分析其優缺點。
3.1 傳輸層時延及降低時延的技術
第2 節提到的RTMP、HLS 等協議在傳輸層都基于TCP,相比于非可靠傳輸的UDP 協議,保證端到端之間可靠且按序傳輸會引入較多的時延,包括連接建立的時延、慢啟動的時延、保證數據分組到達的丟失恢復時延、隊頭阻塞時延等。接下來將以TCP 為例,對上述時延以及優化技術進行分析。
在使用TCP進行數據傳輸之前需要完成3 次握手以與接收端建立連接,若使用安全加密的Web 服務則還存在SSL/TLS 握手。降低握手(控制信息的交互)的次數,減少數據分組往返時間(RTT,round-trip time)個數,可以有效地降低傳輸層時延,這種方式對降低短流時延具有顯著效果。谷歌[16]于2011 年提出TFO(TCP fast open),目標是在握手的同時進行數據傳輸,它通過使用cookie 實現,在確認字符(ACK,acknowledge character)回到接收端之前發送數據,該方案在2014 年被IETF(The Internet Engineering Task Force)組織標準化,但由于兼容性等問題并未被廣泛使用。此后,谷歌公司提出的快速UDP 網絡連接(QUIC,quick UDP Internet connection)[17]中采用了類似TFO 的技術,將傳輸握手和加密同時完成,實現一個RTT 時間完成握手,如圖1(a)所示。在恢復會話時,客戶端緩存的cookie和已經被加密的數據會直接發送到服務器端,服務器端利用此次的傳輸信息對客戶端進行驗證,如果驗證通過就接收數據,從而完成零RTT的握手,握手過程如圖1(b)所示。

圖1 QUIC 中握手時延優化
對于新建立的TCP 連接,初始擁塞窗口的設置以及增長速度對于短流的流完成時間非常關鍵,有很多針對于此的研究。Allman 等[18]于2002 年提出可以將TCP 初始窗口從一個最大分組長度(MSS,maximum segment size)增加到4 個MSS 而不會導致擁塞崩潰。Dukkipati[19]于2010 年提出將初始窗口數從4 提高到大于或者等于10,相較于Allman等提出的方法,此方案更加激進,在高RTT 和高帶寬時延積的網絡中,HTTP 請求的響應平均時延降低了10%左右,在低帶寬的網絡中時延也有一定程度的提升。但是之前的方案對初始窗口的設置相對固定,靈活度低,Wang 等[20]提出在大帶寬高時延場景,對慢啟動階段做修改,自適應地反復重置慢啟動閾值。通過在啟動階段適應網絡條件,發送方能夠快速增長擁塞窗口,而不會引起緩沖區溢出和多次丟失分組的風險。
在保證按序傳輸的協議中,若在傳輸過程中因分組丟失或選路不同導致先發送的數據分組后到達接收端時,位于緩沖區的后續數據分組就被阻塞而不能提交到上層,隊頭阻塞現象發生進而增加應用感受到的時延。
如果隊頭阻塞是由于分組丟失引起的,可以通過盡快通知發送端分組丟失來加快重傳,降低重傳時延,從而緩解了隊頭阻塞的情況。在TCP 的一些增強版本中加入快速重傳機制(fast retransmit)[21],重復ACK 指示分組丟失,發送端可以在了解到網絡發生擁塞的同時加快此丟失分組的重傳過程。但是重復ACK 的接收在檢測分組丟失時仍有較長時延,可通過有效載荷方法(cutting payload)[22]在此方面進行優化。在CP 方案中,如果數據分組到達交換機之后發現交換機上緩沖區不足,即會發生分組丟失,交換機可將此數據分組的有效載荷裁去,僅將數據分組頭部傳送到接收端,接收端收到數據分組頭部后會通知發送端分組丟失及發生擁塞,而不需要等待多次ACK 的到達甚至發生超時重傳。
隊頭阻塞也可能是由于數據分組無序到達引起的,在多徑TCP 中數據分組無序問題是一個重點關注的問題。為了解決多徑TCP 中數據分組的亂序到達引起的阻塞,可以在數據開始發送前或者傳輸過程中通過合理調度來緩解阻塞的情況。滑動多徑調度器(STMS,slide together multipath scheduler)[23]在數據發送前對數據分組進行調度,STMS 為RTT 小的快速路徑預分配數據分組并使序號大的數據分組在RTT 大的慢路徑上傳輸。設置通過走快速路徑和慢速路徑的數據分組的分界點,STMS 可以實現分組順序到達并緩解因無序到達而造成的隊頭阻塞。如果在傳輸中出現隊頭阻塞,可以使用機會重傳(opportunistic retransmission)[24]機制,將造成隊頭阻塞的數據分組在可能會有可用擁塞窗口的子流上重傳。
近幾年提出的新協議中也有解決隊頭阻塞的技術。比如,在Langley 等[25]提出的QUIC 中,一個連接支持多個流,每個QUIC 數據分組都是由屬于若干個流的數據幀組成的,在這種情況下,如果數據分組丟失或者先發送的數據分組晚到達,只會影響該分組中包含的數據流,其他數據流并不會發生隊頭阻塞。QUIC 以其眾多優勢而被廣泛采納和使用,并被IETF 標準化為HTTP 3.0[26]。
擁塞控制是傳輸層的重要功能,一個設計良好的擁塞控制算法不僅要最大化吞吐量,還應該實現低的排隊時延。擁塞控制可以防止隊列生成,進而直接減少排隊時延。擁塞控制算法中有一類是基于時延的算法,它們將時延作為信號來管理擁塞,時延信號會比分組丟失和顯示擁塞通知更及時地反映網絡的隊列狀況。
目前,很多基于時延的擁塞控制算法被提出[27-29],比如Copa[28]方案,在該方案中,目標發送速率被設置成所測量到的排隊時延的倒數,并且按此發送速率調整擁塞窗口,當發送速率超過目標速率就減少擁塞窗口,從而阻止了隊列的生成。谷歌擁塞控制算法(Google congestion control)[29]將(單向)排隊時延的梯度作為推斷擁塞的信號,排隊時延的梯度(導數)可以反應緩沖區的變化情況,提供了對緩沖區大小預測的能力。同時,GCC 使用卡爾曼濾波來估計排隊時延梯度,設置該梯度的自適應閾值以控制增加或減少的速率,從而實現最小化緩沖區及時延的目標。
3.2 網絡層時延與降低時延的技術
網絡層的核心功能是選擇路徑,不同路徑的端到端時延可能會有較大差別。除了端到端時延,路由算法還有可靠性、通信開銷等性能指標,路由算法完成性能指標之間的權衡。例如,后壓路由算法[30]可以實現最優的網絡吞吐量,但是被證明端到端時延隨路徑跳數呈平方式增長。在該算法中,每個節點需要為每個流維護一個隊列,而且一次只能服務一個隊列,時延性能有待提升。針對此問題,Bui等[31]提出減少每個節點維護的實際隊列的方法,提升了后壓式路由算法的端到端時延性能。
流量工程是優化網絡流量分配方式的技術,其目標是通過負載均衡降低網絡擁塞,不僅可以實現網絡帶寬利用率的提升,而且可以降低在擁塞節點的排隊時延,進而降低數據分組到達接收端的時延[32]。流量工程的概念最初是在多標簽交換網絡中提出的[33],在2000 年被引入IP 網絡中[34]。根據流量需求的可用性以及進行流量調整的操作時間尺度可以將流量工程分為在線和離線兩大類[32]。
對于IP 網絡中的離線流量工程算法,一般是修改內部網關協議中的鏈路上的權重,然后根據最短路徑進行路由[35],以期獲取端到端低時延。如果兩點之間有不止一條最短路徑,可以利用等價多路徑路由(ECMP,equal-cost multi-path routing)對流量進行平均分配。但是ECMP 方法無法考慮當前鏈路負載、時延等因素,因此平均分配可能不是最優策略。有研究提出非均等流量分配,可以在一個合理的最短路子集上進行流量均等分配[36],或者設置指數級的代價函數以使對長路徑設置的懲罰更高[37],最終實現端到端時延的優化目標。然而,離線的算法無法根據網絡負載的變化而進行動態變化,在線的流量工程彌補了這個缺點,但是動態地更新鏈路權重可能會導致路由振蕩的問題[32]。
路由和流量工程共同決定了網絡拓撲及拓撲內流量的分配,進而影響網絡的擁塞情況與時延[38],目前,關于拓撲及其上的路由策略的關系的研究較少,而拓撲與路由未合理匹配同樣會導致擁塞或者高時延[39]。針對此問題,Gvozdiev 等[39]提出評估拓撲可用性的指標、將流量路由到可用的低時延路徑的方案。該方案中的指標是可選路徑可用性大于某個閾值的入網點對數與總入網點對的比值,此指標高表示可以在更多的鏈路周圍路由到更短的路徑而不引入過多的時延,所以此指標高的拓撲與路由方案匹配更易實現低時延和少擁塞的選路。與此同時,為防止突發流量造成的鏈路擁塞,會在鏈路上剩余部分容量,但是剩余容量的增加會使路徑時延增加,所以剩余容量成為避免擁塞和降低路徑時延的關鍵點。該研究探究了拓撲與路由的匹配關系,設計剩余容量的大小,提出能應對流量變化并可以利用拓撲路徑多樣性的方案,將時變的流量低時延無擁塞的路由到接收端。
3.3 鏈路層時延與降低時延的技術
數據鏈路層可解決共享介質的訪問問題,信道接入時延是數據鏈路層時延的重要組成部分。對于非爭用型的靜態信道分配,會存在信號發送前等待時間長、信道利用率低等問題。對于爭用型的信道分配方案,由于沒有控制器進行統一管理,所以控制和計算開銷低,但是會存在信道爭用產生的沖突和等待的時延,尤其是在信道負載較高時,競爭的時延開銷不能被忽略。
802.11n 中采用CSMA/CA,幀聚合是一種降低此方案中沖突的技術。幀聚合[40]通過將多個幀聚合之后再發送,可以降低爭用的概率,從而降低等待時延和沖突之后的重傳開銷,但是計算聚合也需要花費時間,需要做兩者的權衡。在最新確定的下一代Wi-Fi 標準802.11be 中,時延和抖動被定為與高吞吐并行的項目優化目標,在數據鏈路層需要設計新的分布式的CSMA/CA 機制,以優化信道接入并保證與部署在其中的獨立接入點公平共存[41]。
對于需要超低時延通信的場景,如工業互聯網,時延要求是幾微秒到幾毫秒。IEEE 802.1 時間敏感網絡(TSN,time-sensitive networking)標準和相關研究已經尋求為超低時延通信網絡提供鏈路層支持,以解決特定業務時延抖動大,時延范圍無法確定等問題。在TSN 數據鏈路層中引入幀搶占技術(802.3br[42]和802.1Qbu[43]),為幀分配優先級。為了傳輸高優先級的幀,低優先級幀的傳輸可以被搶占,從而保證高優先級的幀不會被阻塞。另外,在幀調度方面,增加基于時隙的調度(802.1Qbv[44]),遵循時分多址(TDMA,time division multiple access)規則。該方案將不同優先級的幀分派到不同隊列,并利用開關門機制決定幀傳輸。首先在每一個時隙根據門控情況及隊列優先級情況決定可以傳輸幀的隊列,之后在每一個隊列中采用各自隊列的幀調度策略,這樣可以確保時延敏感的隊列有確定的調度時間,使時延敏感的業務得到有保證的時延。
3.4 網絡時延測量
不同層的時延都是端到端時延的一部分,而對包含單向時延及RTT 的網絡時延的測量是研究者了解并分析網絡行為及性能的重要部分。對于單向時延的測量,需要解決的一個關鍵問題是收發兩端本地時鐘的同步問題,有很多針對于此的研究,如軟件時鐘同步法(如網絡時間協議NTP(network time protocol))與硬件時鐘同步法(如利用全球定位系統GPS 接收機),以及一些優化的時鐘同步算法,如通過雙向測量檢測時鐘調整與估計時鐘偏差的Paxson 算法[45]及Moon 等[46]提出的線性規劃算法,也可通過測量RTT 繞過時鐘同步的問題。
網絡時延的測量方法眾多,主動與被動時延測量是常用的測量方法。相比于主動向網絡中發送測試數據來測量網絡時延,被動時延測量更加節省網絡帶寬資源。然而目前在被動時延測量RTT 方向時通常會利用傳輸層信息,如基于TCP 時間戳的被動RTT 測量[47]及利用擁塞控制或者流控特性的RTT測量方法[48]。但是如QUIC 等正在部署的傳輸協議隱藏了被動RTT 測量的信息。針對這個問題,De Vaere 等[49]于2018 年提出代替TCP 時間戳的輕量級時延信號,此信號使用傳輸協議頭部的三位,支持單流、單點及單向的RTT 被動測量,使被動網絡時延測量方法與傳輸獨立。不過主動時延測量也有高靈活性等優勢,所以目前在實際應用中也會采用主動與被動時延測量結合的方式。
4 低時延關鍵場景
第3 節按照網絡層次架構分析了網絡中的時延及優化技術,本節將時延分析具體到3 個關鍵的低時延場景:數據中心網絡、5G 網絡和邊緣計算。這些場景因具有不同的特性而采用了不同的低時延技術。
4.1 數據中心網絡
相比于廣域網,數據中心網絡具備更高帶寬和更低時延的特性,而且可以靈活部署,這些特性使數據中心網絡可以完成大量數據的快速存儲和處理,成為大數據和云計算重要的基礎設施。本節介紹數據中心網絡中實現低時延的技術,主要分為兩部分:一部分是傳輸層優化,優化擁塞控制與流調度以降低傳輸時延;另一部分是網絡層拓撲結構優化,從而設計合理的網絡拓撲結構來降低數據中心網絡的時延。
4.1.1 擁塞控制與流調度
數據中心網絡因為處理一些分布式的任務或者Web 請求而存在大量的短流,這些短流一般數據量較小但是希望可以獲得快速響應。數據中心網絡也存在數量較少但是數據量較大的長流,這些長流對時延要求較低但是希望可以實現高吞吐量。關于滿足數據中心網絡中短流低時延與長流高吞吐需求的研究一直在進行。
DCTCP(datacenter TCP)[50]是專為數據中心設計的類似TCP 的傳輸層控制協議。DCTCP 利用顯式擁塞通知(ECN,explicit congestion notification)向終端提供多比特反饋。當遇到擁塞時,中間交換機對數據分組進行ECN 標記,經由接收端通知發送端網絡擁塞。發送端根據被ECN 標記的數據分組比例,即網絡的擁塞情況,來調節擁塞窗口,而不是直接將擁塞窗口減半,這樣可以提升窗口恢復速度,并使交換機的緩沖隊列維持在較低水平,大大降低短流時延的同時滿足了長流的高吞吐量需求。
在數據中心網絡中,為了防止時延敏感的短流被長流阻塞,可以使用優先級隊列調度程序來提高它們的優先級,從而降低短流的完成時間及平均流完成時間。pFabric[51]就是采用了上述思想的數據中心流調度算法,該算法將流調度和速率控制解耦、流簡化調度和速率控制,并最終提供了一個接近理論最優值的流完成時間。流調度是基于優先級的,交換機可以利用很小的緩沖區來實現,因此可以降低數據分組的排隊等待時間。在速率控制方面,pFabric 不需要進行慢啟動,開始時是線速發送,當發生長時間大量的分組丟失時再利用速率控制來降低發送速率。
傳統的TCP/IP 協議棧越來越不能滿足新一代數據中心網絡工作負載的超高吞吐超低時延的需求,CPU 目前處理數據分組的開銷是不能被接受的[52-53]。第3 節的分析針對傳統的網絡體系結構,無法從本質上解決端側的處理時延開銷,該問題的解決需要利用新的技術如遠程直接內存訪問(RDMA,remote direct memory access)、數據平面開發套件(DPDK,data plane development kit)等方式,在不需要端側的操作系統參與的情況下,直接實現不同主機內存數據的傳輸和訪問。
RDMA 是為解決網絡傳輸中服務器端數據處理的時延而產生的,因為網絡I/O(input/output)存在瓶頸,所以數據中心網絡的大帶寬無法被充分利用。RDMA 的零拷貝技術,繞過內核處理,省去了中斷處理和各種拷貝的時間[52]。數據在發送端與接收端進行處理時,會完成硬件設備與應用層的直接交互而不經過內核的處理,從而實現服務器端處理的低時延,具體如圖2 所示。
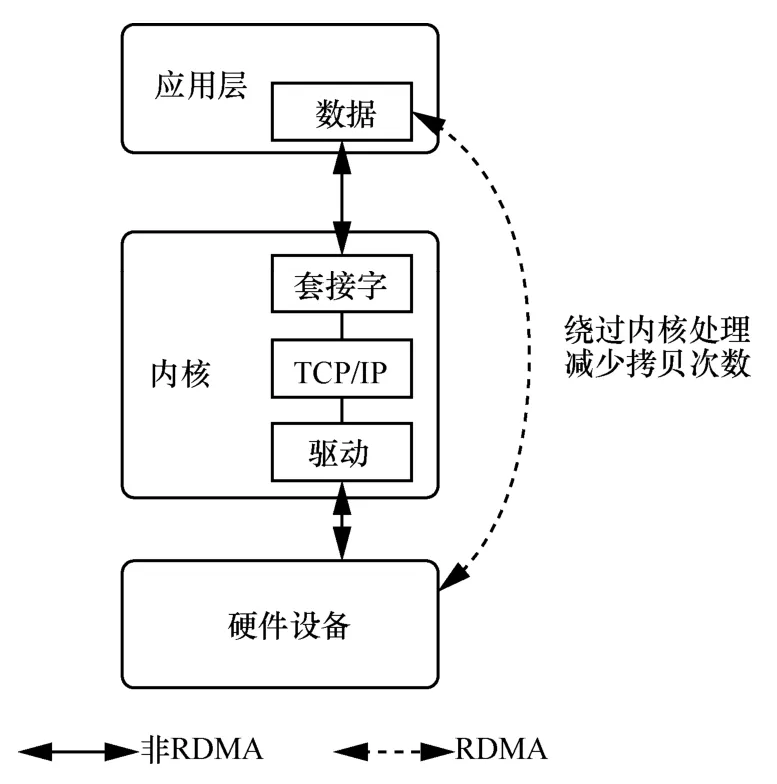
圖2 RDMA 低時延示意
RDMA 已經被部署到數據中心,目前有基于無線寬帶(InfiniBand)的RDMA 網絡,還有基于以太網的 RDMA 網絡,即 RoCE(RDMA over converged ethernet)。基于InfiniBand 的RDMA 需要更換智能網卡和交換機,成本較高,而基于以太網的RDMA 網絡只需要更換網卡,成本較低。
在基于IP 路由的數據中心網絡上,RDMA 使用RoCEv2 協議部署[53],為實現數據鏈路層的無損傳輸,RoCE 采用基于優先級的流控(PFC,priority-based flow control),但是直接利用PFC 操作粒度太粗,可能會面臨隊頭阻塞問題,導致擁塞控制效果不足,若使用流級別的擁塞控制則可以解決此問題。量化擁塞通知(QCN,quantized congestion notification)被提出以解決上述問題,但是QCN 是一個兩層的協議,無法用于網絡層。在這種情況下,Zhu 等[53]提出DCQCN(data-center QCN)以解決PFC 引入的問題。DCQCN是一個為RoCEv2 協議設計的流級別的擁塞控制算法,而且有不需要慢啟動等優勢,可以將隊列長度維持在較低的水平,降低了端到端時延。
數據中心網絡拓撲結構對時延的影響主要體現在2 個方面:網絡擁塞和路由路徑長度。一方面,數據中心網絡的流量具有高動態性,易產生擁塞熱點。當持續時間較長的大流發生擁塞時,交換機的緩沖區被填充,從而導致短流的時延增大。加之每類業務發生擁塞時往往同時涉及多條鏈路,進一步加重了熱點擁塞對傳輸性能的影響。另一方面,端到端過長的路徑會增加傳輸過程中的傳播、處理和排隊時延,這就要求拓撲結構要具有較小的網絡直徑。因此,除了傳輸協議外,合理的拓撲架構和路由方案同樣有助于通過消除熱點、實現負載均衡的方式降低數據中心網絡的時延。對數據中心網絡拓撲架構的研究大體經歷了3 個階段:有線數據中心網絡架構、光電交換混合架構和無線數據中心網絡架構。
有線數據中心網絡往往采用固定的分層樹狀結構,其傳輸性能受限于上層交換機的聚合效率,擴展性較差。在實際中,數據中心網絡通常采用高超額訂購比的結構來緩解流量高峰期的擁塞情況。之后出現了以Fat-tree[54]和VL2[55]為代表的新型樹狀拓撲結構,以Dcell[56]和BCube[57]為代表的分層遞歸拓撲結構以及以SWDC (small-world datacenter)[58]和JellyFish[59]為代表的隨機小世界拓撲結構。其中,SWDC 通入增加隨機鏈路將小世界模型引入拓撲設計,有效降低了網絡直徑,然而其采用的基于最短路的貪心路由算法會導致最差情況下網絡極低的吞吐量和不佳的負載均衡。
上述網絡拓撲結構的網絡容量和傳輸效率與傳統結構相比已有較大提升,但并未解決靜態網絡拓撲與動態熱點流量之間的根本矛盾[60]。為了實現對熱點流量的動態適配,以C-through[61]、Helio[62]和XFabric[63]為代表的光電交換混合架構提出引入光路交換(OCS,optical circuit switching)以實現可變拓撲。由于光電線路交換機往往有更大的網絡帶寬,當電交換機部分出現擁塞時,可以將流量導入光交換網絡中,實現熱點消除。另一方面,通過調整鏈路可以動態調整端到端路徑長度,從而實現適應性的時延優化。然而,由于價格高昂,且切換開銷較大,進行大規模實際部署商用OCS 交換機將面臨巨大的成本和效率考驗。
除采用OCS 交換機外,無線設備也可作為可變拓撲結構的組成部分。無線數據中心網絡架構目前往往采用60 GHz 無線電模塊[64-65]或者空間激光收發器(FSO,free space optical)[66-67]作為基礎模塊進行搭建,從而實現高度靈活的鏈路調配。但當前的無線數據中心網絡架構設計中,無線設備往往被部署在機架頂部,受到無線設備干擾和阻塞的限制,實際可使用的鏈路數量非常受限。雖然有工作提出在天花板安裝平面鏡或球狀反射鏡的方案來提高反射效率和精度,但這一方案對機架頂部的空間要求過于理想,很難部署。
為了解決這一問題,Wang 等[60]使用多反射環拓撲重新設計了無線數據中心網絡架構,其俯視圖如圖3 所示。利用部署在服務器上的無線網卡,無線信號可以被多次反射,實現與目標服務器的直連而不需要經過多跳,有效降低了傳輸路徑長度,從而避免了中間設備中的排隊和處理時延。
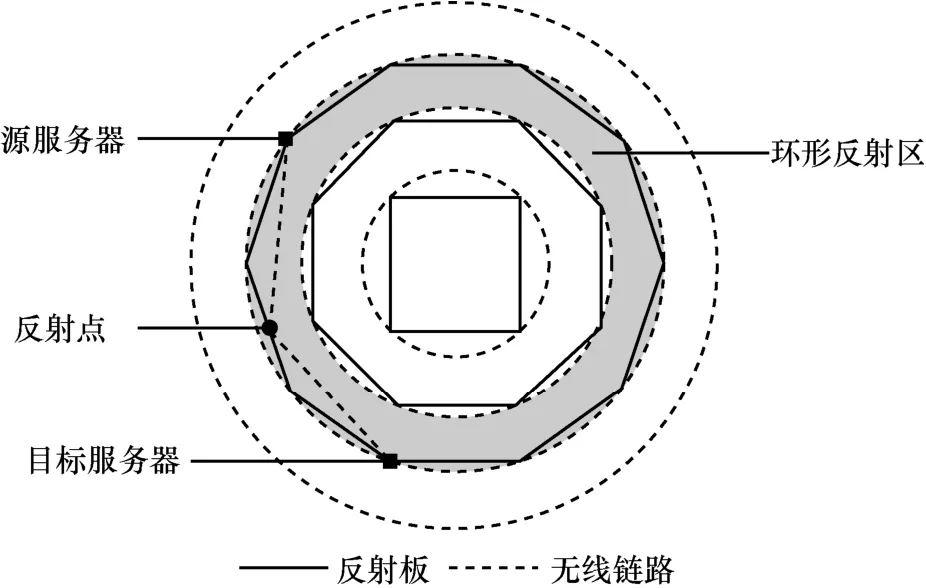
圖3 Diamond 無線反射示意
可變拓撲數據中心網絡架構為消除熱點、降低時延提供了可能,但仍需高效的拓撲自適應算法才能充分發揮其潛力。拓撲配置問題的離散性決定了基于整數線性規劃的方法缺乏擴展性,而啟發式算法往往性能不佳。為此,xWeaver[68]提出可以采用深度學習方法針對流量負載對拓撲進行動態配置。其將流量需求作為輸入,學習輸出近似最優拓撲配置,同時該方法可以靈活地支持流級別或應用程序級別的多樣優化目標,包括流完成時間或Hadoop任務完成時間等。
4.2 5G 網絡
與前四代移動通信不同,5G 旨在提供更高數據率、高可靠低時延及更廣連接的服務。5G 的目標空口時延要求達到1 ms[69],其低時延特性使自動駕駛、設備到設備通信等應用成為可能。在高可靠低時延場景下會存在時延與可靠性的權衡,比如在自動駕駛、工業自動化等應用中,除了低時延外,高可靠性亦是上述應用正常工作的重要前提。因此,在這些應用中不應采用分組丟失等非可靠方式實現低時延,而應采取其他技術完成時延與可靠性的優化。本節將從網絡架構調整和低時延關鍵技術這2 個方面分析5G 網絡為實現超低時延的設計,這些設計在優化時延的同時不會造成可靠性的降低。
3.青年價值觀教育的目標、內容、原則和方法。青年價值觀教育要把握思想政治教育的時代特點和青年的身心特點,以科學發展觀為指導思想。青年價值觀教育作為思想政治教育的題中之義,運用思想政治教育的分析研究方法,明確青年價值觀教育的目標、內容、原則和方法對我們開展教育工作具有重要意義。
4.2.1 網絡架構調整
移動通信網絡架構演進呈現分離的趨勢,功能的不斷分離使部分功能可以靈活部署并下沉至更靠近用戶的位置,這樣可縮短用戶與服務端的距離,進而降低網絡時延。對于核心網,在3G 網絡中引入直接隧道技術(DT,direct tunnel)[70],將控制面與用戶面分離,數據傳輸時繞過服務GPRS(general packet radio service)支持節點(SGSN,serving gprs support node),利用DT 將基站與網關GPRS 支持節點(GGSN,gateway GPRS support node)直接相連,這是核心網分離的開始。DT 技術的采用避免了SGSN 對數據的處理與轉發過程,縮短了時延。
在5G 時代,基于4G 核心網,5G 核心網繼續進行更完全的分離,SGSN、服務網關(SGW,serving gateway)、PDN 網關(PGW,packet data network gateway)等網元被分為用戶面與控制面兩部分[71]。分離核心網用戶平面并將用戶面下沉到回傳網之前可以減輕回傳網傳輸壓力與核心網集中處理負擔。計算與存儲的下沉與分布式架構可以使用戶數據無需到達遠距的核心網,從而實現毫秒級的時延目標。
對于接入網,5G 將基站分為集中單元(CU,centralized unit)、分布單元(DU,distributed unit)和有源天線單元(AAU,active antenna unit)3 個部分[71],其中CU 對應于4G 網絡中室內基帶處理單元(BBU,building base band unit)的實時性低的部分,DU 對應實時服務。將BBU 分離后,可以根據場景和需求靈活地對CU 和DU 進行部署,以滿足5G 中不同應用的需求,對于時延需求高的應用需求,可以將DU 部署于離用戶更近的地方。
為了提升數據傳輸速率并降低時延,提升帶寬是一個直接的選擇。目前的移動通信使用的是3 GHz以下的頻段[72],若提升帶寬可以探索使用高頻毫米波頻段[73]。由于高頻信號傳播范圍小,原來移動通信中以基站為中心的架構可以被調整為以用戶為中心[74],具體如圖4 所示。此時,用戶不僅是網絡中的節點,而且將參與網絡中的中繼、傳輸等任務。在這種情況下,基于5G 毫米波和之前的4G 組網方案,研究者們提出5G-LTE 混合組網方案及僅基于毫米波基站的獨立組網方案[75]。
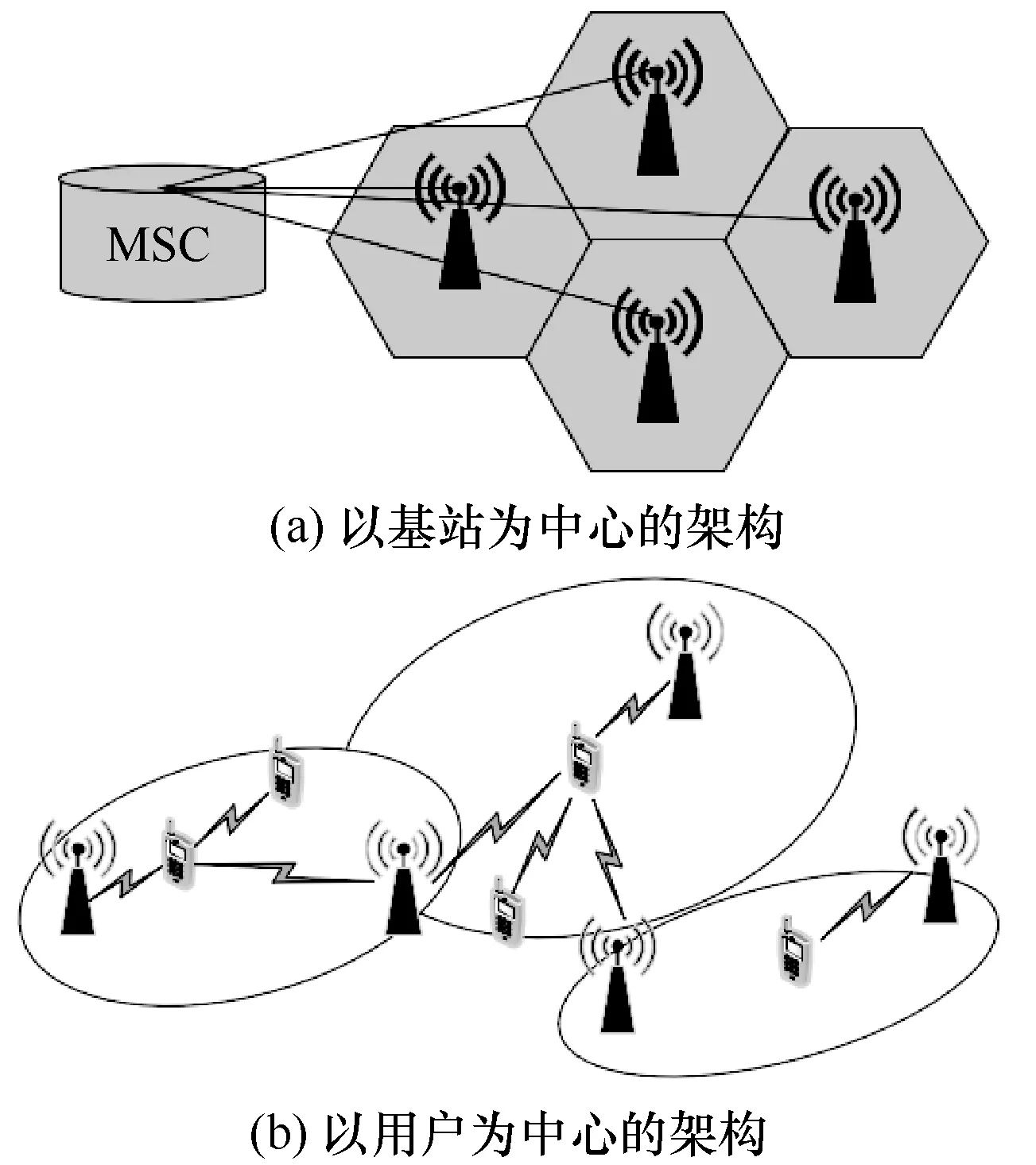
圖4 從以基站為中心轉變為以用戶為中心
4.2.2 低時延關鍵技術
除了架構上的調整外,5G 融合了多種關鍵技術來優化時延,如利用波束賦形技術,大規模多輸入多輸出技術及新型正交多址接入技術提升頻譜利用效率,優化用戶與基站之間的空口時延,實現高速數據傳輸。5G 架構對于數據傳輸時延的優化是眾多技術融合共同作用的結果。
在移動通信中多址接入是一個關鍵特征,其目標是實現用戶隨時隨地接入信道,多址接入技術一直在研究當中。第四代移動通信(4G)采用正交頻分多址(OFDMA,orthogonal frequency division multiple access),為保證信號正交而設置大信號傳輸時間間隔(TTI,transmission time interval),存在頻譜效率低、數據傳輸時延大等不足,無法滿足新興業務對時延的需求,新型的多址技術需要被提出。5G 中包含多種新型的多址接入技術,比如非正交多址(NOMA,non-orthogonal multiple access)、稀疏碼多址(SCMA,sparse code multiple access)等。這些新的多址技術可以提升頻譜利用率,減少競爭等待時間,從而降低時延。
NOMA[76]與傳統的正交多址方案有著本質的區別,在NOMA 中,功率域被引入,多個用戶可以在同一時間、同一碼型、同一頻率、不同功率等條件進行傳輸。發送端非正交發送,接受端使用干擾消除進行解調,接收端的解調過程復雜性增加,但是避免了正交信號間隔時間,提升了頻譜利用率。同時,在NOMA 中不需要采用爭用型信道分配方式,競爭等待時間縮短。SCMA[77]是一種基于碼本與碼字映射的非正交多址接入技術,數據經過信道編碼之后會按照碼本中的對應碼字進行高維調制。SCMA 使用碼分多址,通過使用多個載波組,實現頻譜利用率的提高。
4.3 邊緣計算
在傳統的云計算架構中,云端完成數據存儲與計算[78]并通過網絡將服務提供給用戶。但是隨著智能化普及,邊緣設備產生數據急劇增加,云端計算和網絡傳輸負載加重。同時由于云計算架構中數據傳輸距離長,可能無法滿足時延敏感型應用的需求。為了保證數據處理低時延,降低云計算與傳輸負載,研究者提出了邊緣計算架構。本節介紹邊緣計算中的關鍵技術計算卸載以及利用邊緣計算的具體應用。
隨著移動設備性能的提升,開發者正在開發愈加復雜的應用程序,如自然語言處理或人臉識別等,需要大量的計算與存儲資源,同時,低時延也是這些應用重要的評價標準之一。有研究發現這些應用程序通常由許多可組合組件組成[78],所以可以利用計算卸載技術,確定如何進行組件的分配,使這些應用能在移動設備上運行,此問題被稱為代碼分割問題,有眾多針對于此的研究[79-82]。
CloneCloud[80]在代碼運行前計算分割情況,它通過對目標手機和云上的進程二進制文件的不同運行條件進行離線靜態分析來確定這些卸載到云上的部分。但是,這種方法只考慮離線預處理中的有限輸入/環境條件,無法涵蓋真實的網絡狀況下的所有情況。MAUI(mobile assistance using infrastructure)[79]是在運行時進行分割決策的,它將此問題建模為一個整數線性規劃問題,但是解此線性規劃是一個NP-hard 問題,求解時間不能忽略。Hermes[82]提供一種多項式時間近似方法,以最小化卸載請求的時延,但是它只適用于一個卸載請求情況。
不過上述工作都是針對通用的計算工作負載,面向特定的應用,可以根據應用的特點進行計算卸載。VR 系統有嚴格時延要求,有研究提出VR 內容呈現可以分為交互式的前景和可預測的后景兩部分,基于此提出一種基于計算卸載的渲染方案[10],并證明了該方法的可行性。將可預測但渲染負載重的背景的預渲染和預取任務卸載到云端,而輕量級前景交互的渲染在移動端本地的GPU(graphics processing unit)上完成,以繞過網絡傳輸瓶頸,從而降低時延,優化用戶體驗。
實時視頻分析是邊緣計算的另一個重要的應用場景。視頻分析的結果需要用來與用戶進行交互或者啟動下一個系統,所以需要低時延的支持。同時,傳輸高清視頻需要高帶寬,此時將大量的視頻數據都傳輸到云端處理是不可行的[83]。利用邊緣設備的計算與存儲能力及地理上分布式的特點進行視頻分析成為一項新興并且必要的任務,進而為道路流量控制、安全監控等提供便利。
有研究提出地理上分布的公有云、私有集群和邊緣的架構是唯一能夠滿足大規模實時視頻分析的方法[83],具體如圖5 所示,具體的視頻分析任務可以分配到公有云、私有云或者邊緣設備。
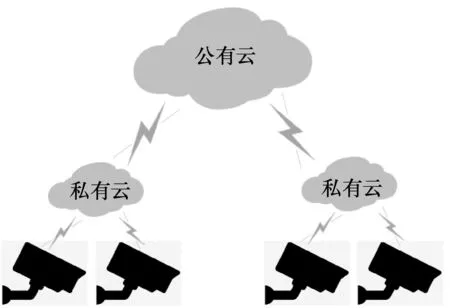
圖5 地理上分布的公有云、私有云與邊緣架構
有許多研究工作關注實時視頻分析領域。VideoStorm[84]系統中視頻分析是在私有云上完成的。此系統由一個中央管理器和一組執行視頻分析查詢任務的工作機組成,每一個查詢被連續輸入到集群中,其中包含多個對視頻進行處理的轉換。Lavea[85]是一個建立在邊緣計算平臺之上的系統,它可以卸載客戶端和邊緣服務器之間的計算。同時,邊緣服務器之間可以完成協作,以低傳輸時延或者低排隊時延為目標。通過上述操作在靠近用戶的地方提供低時延的視頻分析。
5 機遇與挑戰
5.1 基于SDN 的網絡架構革新
為了優化數據傳輸時延,滿足應用的實時性要求,網絡架構的革新與演進一直是研究熱點之一。在保持傳統網絡基礎架構不發生變化的前提下,可以利用基于SDN 的軟件化形式構造更加靈活的網絡架構,使網絡中策略的優化與部署成為可能,為時延優化提供機遇。下面將以基于SDN 架構的數據中心廣域網中的時延優化為例進行介紹。
連接數據中心的廣域網對在線服務提供商來說是重要的基礎設施,數據中心之間的低時延和高吞吐量數據傳輸可以提供良好的用戶體驗和高可靠的服務[86]。為了提供長距離的大容量鏈路,數據中心之間的廣域網資源花費很高成本,但是由于防止分組丟失而設置的冗余鏈路[87]及分布式資源分配模型[86]造成的次優流量路由等原因使數據中心間廣域網鏈路利用率并不高,很多企業對于本公司的數據中心之間的廣域網連接進行改進以期望提升鏈路利用率進而優化時延,使用SDN 進行改進是其中的一種方式。
以谷歌公司為例,谷歌公司提出B4 網絡實現其數據中心的互聯[87]。B4 架構包含三層,從下到上依次是硬件設備、局部控制器和全局控制器。B4采用定制的交換機及機制,將現有的路由協議集成在一個SDN 的環境中,局部控制器控制物理層設備并將收集的鏈路拓撲信息發送到全局控制層的服務器。當需要進行路徑選擇時,全局控制器會對所需帶寬進行預估并選擇一條最優的路徑,從而提升鏈路利用率,使可用帶寬提升,阻塞減少,從而降低了時延。為實現基于SDN 的網絡架構革新,除了提出的B4 之外,谷歌公司于2015 年提出通過SDN 實現的數據中心互聯架構[88],于2017 年提出基于SDN 的對等邊緣路由基礎架構[89],于2018 年提出網絡功能虛擬化堆棧[90]。
雖然SDN/NFV 技術提供了機遇,但是以虛擬化軟件實現硬件功能的方式也同樣使SDN/NFV 新型網絡架構難以避免地增加核心網絡和數據中心網絡的處理時延。有研究指出服務鏈時間延遲可能隨著鏈的長度線性增長[91],所以有研究提出網絡功能并行化加速的算法NFP(network function parallelism in NFV)[92]。該方法可智能識別NF 依賴關系,并自動將策略編譯成高性能服務圖。然后該框架內的基礎設施執行輕量級分組復制、分布式并行分組交付和分組副本的負載均衡合并,以支持NF并行性,最終實現在基本沒有資源浪費的情況下優化時延。如何處理好軟件化與低時延的權衡仍處在研究當中,這是推動SDN/NFV 技術進一步發展的關鍵所在。
5.2 數據驅動的低時延優化算法
面對愈加復雜的需求和計算任務,以機器學習、尤其是深度學習為代表的數據驅動方法已經在各領域展開了廣泛應用,也成為了網絡領域工業界和學術界的關注熱點[93-94]。為了降低網絡時延,需要對大量復雜的優化和調度問題進行求解。但傳統算法往往根據不真實的假設條件或者不準確的建模,采用基于固定策略的啟發式算法,從而很難在動態多變的復雜網絡環境下保持穩定的性能。機器學習算法則能夠直接從數據中學習問題特征或者直接通過與環境交互學習進行決策,從而為解決這一問題提供了新的方向。
網絡中大量的問題(如擁塞控制、流量調度等)可以建模為序列決策問題,擅長解決此類問題的強化學習技術也被應用到網絡系統的多個方面。以Skype 為代表的互聯網電話(Internet telephony)發展迅猛,但卻面臨網絡抖動帶來的巨大性能挑戰,因此如何選擇合適的中繼節點來降低通話時延這一問題亟待解決。Jiang 等[95]將這一問題建模為多臂老虎機問題,采用上限置信區間算法(UCB,upper confidence bound)實時為每對通話選擇當前最優的中繼節點,從而有效降低了通話的時延。
擁塞控制對減少網絡擁塞、降低排隊時延至關重要。在動態變化的網絡環境下,基于規則的相對固定的窗口調節策略將不可避免的產生性能下降。Remy[96]首次將擁塞控制問題建模為馬爾可夫決策過程,采用強化學習思想學習網絡狀態到窗口調節方式的映射,從而實現細粒度的精確調節。另一方面,PCC(performance-oriented congestion control)[97]和PCC vivace[98]采用在線學習方法,對網絡環境進行在線適應,一定程度上緩解了機器學習方法的泛化問題。
數據中心中的流量調度對應用性能影響巨大。當前算法往往依賴于手工參數調節,從而導致網絡環境與算法參數不匹配。Chen 等[99]提出利用深度強化學習根據當前的流量負載情況動態決策算法閾值,在保障處理效率的條件下,大幅降低了應用的流完成時間。
機器學習算法雖然優化了網絡的時延,但也對網絡系統提出了新的挑戰,尤其是深度學習算法往往需要利用梯度下降算法進行模型更新。而對大規模機器學習任務,訓練和計算往往以分布式的方式分發到多臺計算機共同完成。這時,機器間的通信開銷巨大,嚴重時會影響模型的訓練速度。因此,未來如何進行架構和同步算法設計,如何利用RDMA 和DPDK 等技術進行傳輸優化都是亟待解決的問題。
5.3 低時延新興協議設計
網絡協議作為網絡中通信的標準,是低時延網絡構建中的重要一部分。然而,互聯網在最初設計時提供的是盡力而為的服務,并未對網絡時延等指標提供保證或作出優化,為了優化時延,針對不同的應用,學術界和工業界的研究者們提出了多種新興協議,在協議層面為低時延通信做出努力。
為提升網頁訪問的速度,HTTP 2.0[100]與QUIC[25]協議被提出,在數據傳輸的握手、連接、復用等方面進行改進。為加速數據中心數據傳輸,使服務器端系統處理速度匹配數據中心網絡帶寬,RDMA 技術及相匹配的RoCE 等協議被提出。為使瀏覽器支持實時音視頻傳輸,傳輸層采用RTP 協議的WebRTC[101]被提出。
與此同時,各企業為優化自身傳輸系統,根據自身的業務提出了特定的協議,提供了更低的數據傳輸時延。如IBM 旗下的Aspera 公司提出的廣域網上海量數據傳輸的FASP 傳輸技術,它避免了TCP 在分組丟失率高時延高的鏈路上無法充分利用網絡帶寬的問題,優化了鏈路吞吐量提升了文件傳輸速度。快手研究者提出的基于UDP 的KTP(Kuaishou transport protocol)[102]傳輸協議,將碼率和幀率自適應加入,并融合了網絡性能估計與擁塞控制等,優化了傳輸時延及分組丟失等其他指標。為滿足不同的應用需求,未來可能會有更多的專用協議出現,這可能成為一個不可或缺的研究點。
6 結束語
低時延網絡對新興應用的性能提升有重要意義,低時延技術是目前的研究熱點。本文分析了TCP/IP網絡架構各層時延的來源,并總結了實現低時延的各層技術。同時,對數據中心、5G 和邊緣計算這3個關鍵場景時延優化進行了分析,希望本文的分析可以對該方向的研究提供一些啟發。此外,低時延網絡可以促進新型協議設計和數據驅動新方法的產生與發展。然而,機遇與挑戰并存,所以希望仍有針對這一問題的持續和深入的研究,這需要學術界和工業界的共同努力。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
