無線網絡中的移動預測綜述
2019-08-29 08:10:14王瑩蘇壯
通信學報 2019年8期
王瑩,蘇壯
(1.北京郵電大學信息與通信工程學院,北京 100876;2.北京郵電大學網絡與交換技術國家重點實驗室,北京 100876)
1 引言
隨著移動互聯網以及物聯網、車聯網的快速發展,終端設備正在急劇增加,無處不在的傳感設備和智能設備產生了海量數據,包括天氣狀況、交通狀況、地理位置、社交數據等[1]。與此同時,基于位置的服務也日益受到關注,收集用戶的地理位置信息,可以更好地鎖定用戶并推出針對性服務。面對智慧城市帶來的發展機遇,挖掘這些數據背后的規律能夠解決眾多問題。例如,在無線網絡中,車輛、行人等個體的移動性引起小區的頻繁切換和資源分配,由此導致的切換時延嚴重影響了用戶對時延敏感型業務的體驗。因此,為了更加充分合理地利用無線資源,學者們在移動管理方面進行了很多探索。眾所周知,人類傾向于具有相似模式的循環行為[2-3],這使從個體之前的歷史位置信息中預測個體的移動成為可能。一旦移動被預測,就能獲取用戶在特定時間的位置,進而規劃資源或者提供定制服務。
目前,移動預測在眾多場景中被提出,包括旅游導航、交通控制、車聯網和設備到設備(D2D,device-to-device)等。其中,在旅游導航中,通過預測人群的移動模式,對景點進行推薦,避免景區人群分布不均衡,能顯著提高用戶的游覽體驗。在交通控制中,預測車輛的移動規律,對車輛行駛路線進行規劃,能夠有效避免交通堵塞。在D2D 通信中,設備通過廣播獲取當前位置的鄰近設備,并從中選取某個設備作為通信節點[4],但由于節點的移動性,網絡拓撲是非常不穩定的,雙方脫離通信范圍就會中斷連接;如果預測到每個設備的移動方向,就能夠選取更穩定的拓撲節點,提高通信連接的頑健性和傳輸速率。在無線網絡移動管理中,對終端進行移動預測,并在切換到下一接入節點前預留通信資源,能夠降低資源調度的時延,提高時延敏感型業務的體驗質量。
此外,在無線傳感網絡(WSN,wireless sensor network)中,移動傳感節點收集數據并發送到基站[5],當基站通過定向天線與移動節點通信時,定向傳輸將信號強度集中在主瓣方向上,形成指向接收機方向的定向波束,能夠提升通信容量并降低設備能耗,因此,預測移動傳感節點的位置并和基站保持定向傳輸能夠提供更高質量的數據服務。在車載網中,預測車輛的移動,并將車輛請求的內容預先緩存到即將接入的Wi-Fi 節點,在切換到該接入點后能夠迅速獲取數據,有效降低內容獲取的時延[6]。總而言之,移動預測的應用場景十分廣泛,因此對移動預測的研究是十分有價值的。
本文著重總結了移動預測的特征提取以及目前主流的移動預測方法,并結合無線網絡場景分析了各類方法在不同場景的適用性。無線網絡有多種結構和技術,包括LTE(long term evolution)、超密集組網(UDN,ultra dense network)、Wi-Fi、車載自組網(VANET,vehicle ad hoc network)等,這些網絡在覆蓋范圍、規模、部署密度、穩定性等方面存在差異,因此在不同的場景中預測算法的適用性不同。最后分析了其他因素對移動預測的影響,并指出了未來的工作和挑戰。
2 移動數據
移動預測所需的數據主要來自無線網絡(GSM、Wi-Fi)中的日志、GPS 采樣數據以及終端APP 簽到信息。GSM 日志記錄了用戶在不同小區的接入記錄、通話記錄等,通過蜂窩定位技術能夠映射為相應的位置信息,包括<基站ID,終端ID,時間戳>等信息。Wi-Fi 日志與之類似,記錄了用戶訪問節點的接入歷史、接收信號強度信息(RSSI,received signal strength information)等,通過室內定位技術能夠映射為相應的位置信息,包括<AP(access point),終端ID,RSSI,時間戳>等信息。GPS 數據是目前移動預測最常用的數據,一方面,由于智能移動終端能夠方便地獲取GPS 信息,包括終端的經緯度和時間戳;另一方面,GPS 精確地記錄了終端的移動軌跡,其軌跡可以由坐標點序列精確地描述,因此包含更加豐富的信息,能夠更準確地提取移動模式。但是GPS 數據集通常較大,處理復雜度較高,并且純粹的經緯度坐標缺乏位置含義,一般根據預測模型的需要,對數據進行特征工程處理,才能用于模式提取和移動預測。APP 簽到數據是通過智能終端的APP 收集的,例如用戶通過發布社交動態、團購、攝影等隱含位置信息的方式,獲取操作APP 時產生的簽到記錄。
4 種數據對比及部分開源數據集總結如表1 所示。其中,通過GPS 采樣的數據集GeoLife Dataset來自微軟GeoLife 項目。該項目從2007 年4 月到2012 年8 月收集了182 個用戶的軌跡數據。這些數據包含了一系列以時間為序的點,每一個點包含<經度,緯度,海拔,時間戳>等信息,共計17 621 條移動軌跡,總距離120 多萬千米,總時間48 000 多小時。通過Wi-Fi 采樣的數據集Dartmouth Campus Dataset[7]來自美國達特茅斯學院數千用戶為期3 年的校園Wi-Fi 接入記錄,該Wi-Fi 網絡包含了近450個接入點,有大量的接入點切換記錄。通過GSM采樣的數據集Rice Context Dataset[8]來自Ahmad等獲取的基站日志,該日志包含了10 個手機用戶為期近2 個月的基站接入記錄,每條記錄包含基站每30 s 或60 s 采集一次的<基站ID,信號強度,信道>等信息。通過APP 簽到采樣的數據集Gowalla Dataset 來自Gowalla 的基于位置服務的社交網絡簽到數據,該數據集包含了近20 萬用戶近6 個月的600 多萬條簽到記錄,每條記錄包含<用戶ID,時間戳,經度,緯度,位置ID>等豐富的信息。此外,研究者也可以根據條件自主獲取符合研究要求的數據樣本。
3 移動軌跡處理
移動預測首先要對移動軌跡進行處理。軌跡是由個體的移動形成的按時間連續的位置序列。軌跡的2 個要素分別是空間特征和時序特征。空間特征是在軌跡序列中元素所代表的位置含義,決定了移動預測的精度,同時能夠反映個體的移動模式所具有的實際意義。通過對原始數據的處理得到有意義的軌跡序列,再結合適當的數據結構能夠提高預測的性能。時序特征由采樣方式決定,分為3 種:基于時間的采樣方式、基于位置的采樣方式和基于事件的采樣方式。
3.1 空間特征
原始軌跡序列,如GPS 坐標序列,并不建議直接用來進行位置預測,因為預測的準確度較低,因此需要通過聚集、抽象來提取更高層次的空間特征。本文將空間特征劃分為3 類:偏好區域的空間特征、偏好語義的空間特征和偏好路徑的空間特征。
1)偏好區域的空間特征
偏好區域的空間特征表示區域性的空間位置,如“時刻T離開區域A,時刻T+1 到達區域B”,反映了簡化的移動過程,其區域的粒度影響預測的精度。每個空間位置的定義往往與場景相關。常用的有路網模型和小區模型。
路網模型將平面劃分為N×N個網格狀區域,對每個網格進行編號,用戶所處的網格就是該時刻用戶的位置區域,如圖1(a)所示。一種典型的路網模型——馬里德網格模型,是在城鎮通過橫縱交錯的道路將平面劃分為網格狀[9],規定行人和車輛在道路上移動。在路網模型中,Wi-Fi 接入點或基站一般通過泊松分布分散在地圖上。
小區模型的劃分粒度一般和無線網絡的具體類型有關,LTE 網絡的基站覆蓋較廣,小區數目較少,位置狀態也少,因此復雜度較低;而UDN 的微基站和Wi-Fi 的接入點十分密集,狀態數多,復雜度高[10],如圖1(b)所示。
偏好區域的空間特征將地圖劃分為有限個區域,對于每一個用戶,其位置狀態即為對應的區域編號,用戶在下一時隙將要到達的區域就是要預測的位置,這個區域可能是用戶當前的區域,也可能是其他區域。 通過區域特征構造的軌跡序列為{r1,r2,…,ri,…,rn},其中ri表示第i次采樣用戶所在的區域ID。
2)偏好語義的空間特征
偏好語義的空間特征表示有地理意義的空間位置,如“時刻T到達餐廳,時刻T+1 到達學校”,反映了個體的移動意圖,是移動信息服務的起始點。每個地理位置的定義都與生活模式相關,典型的有興趣點(POI,point of interest)模型和地標模型。
POI 模型[11]是個體在移動過程中有偏好的移動行為。在眾多位置中,有一些是個體頻繁訪問的或長久駐留的,而有一些是偶爾訪問的。其中頻繁訪問的位置定義為POI,是用戶位置的狀態,例如家、工作樓以及健身房等。POI 的提取通常通過GPS數據進行聚類得到,如圖1(c)所示。以用戶的興趣點為空間特征能提高對個體移動模式的理解,不過也存在對偶爾訪問,甚至從未訪問的新穎位置的不可達問題,預測被局限在少數高頻訪問的位置。
地標模型將城市版圖通過標志性地理位置表示,這些地標包括個體已經訪問或者未曾訪問的位置。相比POI 模型,地標模型在語義庫中有更豐富的語料,但同時預測的維度也更高,如圖1(d)所示。通過區域特征構造的軌跡序列為 {loc1,loc2,…,loci,…,locn},其中loci表示第i次采樣時用戶所在的地標ID。

表1 4 種常用移動預測數據源對比
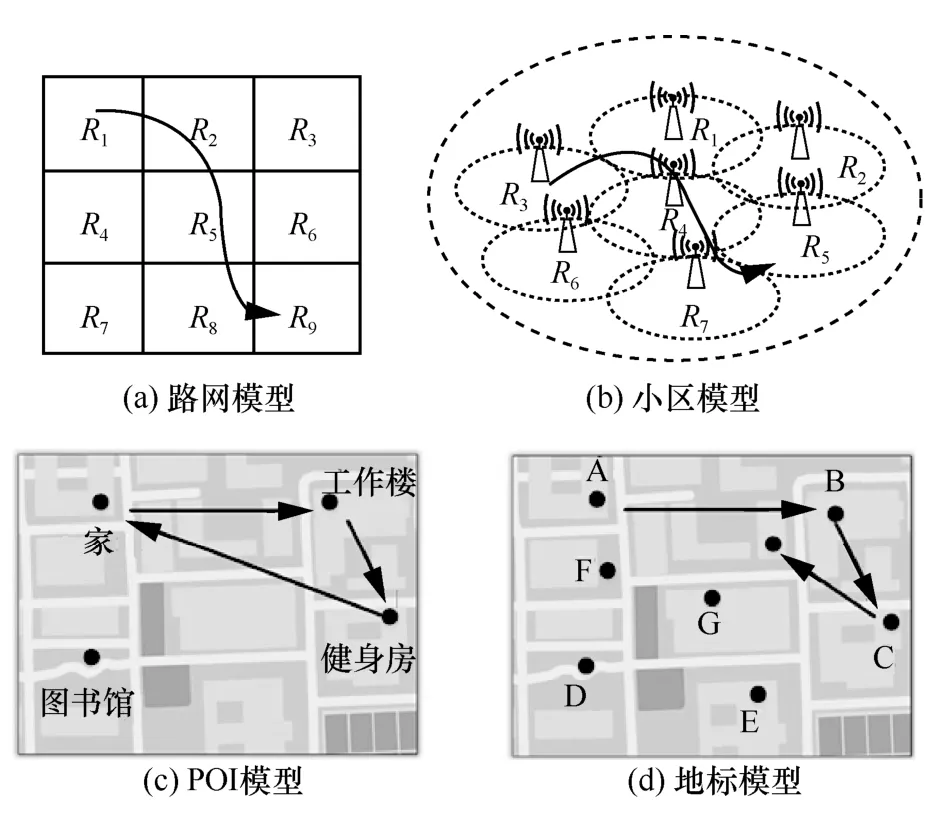
圖1 空間特征示意
3)偏好路徑的空間特征
偏好路徑的空間特征表示移動行為中帶有過程性的特征,表現為相對穩定的周期性重復的軌跡,如“時刻T到時刻T+1 經過學院路”,可通過GPS 傳感器獲取軌跡細節,反映了個體移動的典型軌跡。
在路網模型、POI 模型等空間特征中,移動預測將簡化的位置作為預測的原子狀態,將個體連續的移動路徑抽象為在不同的位置間的轉移,其抽象的粒度影響了預測空間的維度,粒度過大,雖然維度會降低,但是預測的精度也會降低而失去應用價值。相比而言,通過路徑將軌跡樸素地表示[12],能夠近似描述個體的移動過程,達到路徑細節的存儲和復現。路徑概率樹[13]就是基于路徑語義構造的數據結構,進行移動模式提取和預測。如圖2 所示,移動軌跡被分割成多段路徑。用戶甲的軌跡序列為 {p1,p2,p4},用戶乙的軌跡序列為{p3,p4}。
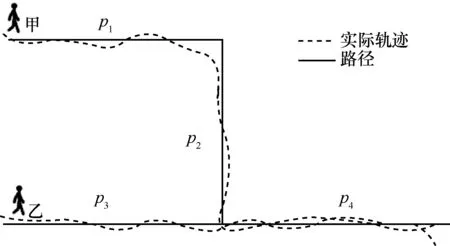
圖2 路徑特征示意
3 種空間特征各有利弊。路網模型和小區模型數據處理簡單,原始軌跡數據映射到該模型只需簡單的距離測量,并且模型粒度容易調控,只需對網格數目調整即可,但是缺乏對個體移動規律的理解;POI 模型和地標模型便于理解個體的移動規律,但是預處理復雜,對駐留點的聚類復雜度高,并且忽視位置轉移之間的具體移動過程;路徑特征的預處理更加復雜,不僅要對駐留點、交叉點進行聚類和提取,還要進行冗余路徑清洗和相似路徑合并,抽象出典型的路徑特征,但該特征包含豐富的移動細節,適用于各種需要移動預測的場景。
采用何種空間特征,需要由具體的應用需求決定,例如在蜂窩網小區切換中,只需要預測用戶何時到達下一小區的覆蓋范圍,此時使用POI空間特征只會增加復雜度,而不會明顯提高準確性和實用性。
3.2 時序特征
通過定位設備所收集的移動軌跡數據并非都是有價值的,過于密集或過于稀疏都會降低預測系統的性能,同時還要保證位置的特定時序以適應所應用的場景。因此要根據模型需要對數據進行采樣構成特定時序的軌跡序列。采樣方式有3 種[14]:基于時間的軌跡采樣、基于位置的軌跡采樣和基于事件的軌跡采樣。
1)基于時間的軌跡采樣
軌跡數據通過等時間間隔采樣收集。例如GPS數據,目前移動終端大多都有GPS 傳感器,能夠等間隔5 s 獲取<經度,緯度,時間戳>等定位信息,研究者也可以設置更大的時間間隔。
2)基于位置的軌跡采樣
當地理位置發生改變時,將位置樣本加入軌跡序列。例如Wi-Fi 接入點切換時和基站切換時的小區位置,以及經過數據清洗和路徑提取后,路徑發生轉移時的路徑位置。
3)基于事件的軌跡采樣
當事件發生改變時,將位置加入軌跡序列,如使用智能終端發布社交動態、購買一張電影票或者餐票、登錄購物商城等。通常由智能終端的APP 在使用過程中產生,常用的有社交網絡的簽到數據。基于事件采樣依賴于智能終端的使用動作,且記錄的用戶行為并不完整。
以圖1(a)網格中的移動軌跡為例,其采樣的數據空間如圖3 所示。
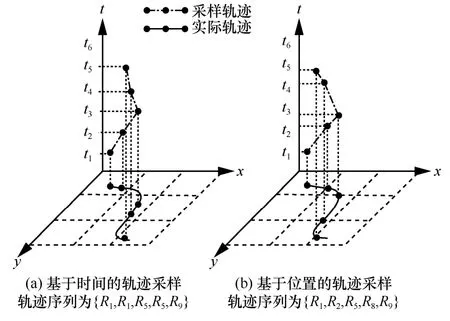
圖3 基于時間和位置的軌跡采樣
4 移動預測模型
移動預測主要解決2 個問題:個體在何時到達下一個位置以及個體的下一個位置是何處。前者要預測的是個體在一個地點的到達時間和駐留時間,是基于時間序列的移動預測;后者要預測的是個體的下一個駐留地點,是基于位置序列的移動預測。如果同時兼顧二者,由于個體的移動在時間維度和空間維度都有很大的隨機性,目前還很難做到較高的預測準確度。
隨著人工智能和大數據的發展,一些新的預測模型在移動預測上產生良好的效果。因此本文通過數學方法對移動預測模型進行分類,將預測方法分為3 類:基于概率統計模型的移動預測、基于判別模型的移動預測和基于頻繁模式挖掘的移動預測。
4.1 基于概率統計模型的移動預測
基于概率統計的機器學習算法在處理大規模樣本分類和線性系統學習中有高效和靈活的優點。常用的有馬爾可夫模型(MM,Markov model)、隱馬爾可夫模型(HMM,hidden Markov model)、貝葉斯模型等,通過計算聯合概率預測可能的位置。
4.1.1 基于馬爾可夫模型的移動預測
馬爾可夫模型根據樣本數據計算各個狀態的轉移概率,建立馬爾可夫鏈,通過初始時刻位置狀態和狀態轉移概率矩陣,計算未來時刻位置的概率并進行預測。馬爾可夫鏈是具有馬爾可夫性的隨機變量序列,變量的所有取值范圍被稱為狀態空間,在移動預測中位置集合就是狀態空間。而k階馬爾可夫鏈意味著時刻t所處的狀態分布與t之前的k個狀態有關,是一種“有限記憶”系統。因此只要求系統中任意2 個狀態之間的轉移概率就能確定模型。假設軌跡序列為 {…,st-2,s t-1,st,st+1,st+2,…},由一階馬爾可夫鏈定義可知,st+1的狀態只與st有關,其滿足條件概率
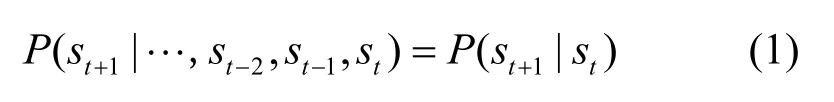
馬爾可夫模型是應用最廣泛的位置預測方法,但該模型也存在一些缺陷。對于高階馬爾可夫鏈存在復雜度太高和零頻率問題,而低階馬爾可夫鏈的準確性不高,因此研究者在馬爾可夫鏈的基礎上提出了改進方法,他們分別從引入社交特征、弱預測器集成學習、變階馬爾可夫的角度對馬爾可夫預測進行改進。其中,文獻[15]以馬爾可夫模型為基礎對節點的移動性進行初步預測,然后利用與其社會關系較強的其他節點的位置對該節點的預測結果進行修正。文獻[16]將馬爾可夫模型與回歸模型進行集成學習,通過投票機制提升性能。文獻[17]通過變階馬爾可夫模型的逃逸機制來解決零頻率問題,并采用樹結構來減少高階馬爾可夫模型所需的內存。文獻[18]基于個體的歷史上車和下車記錄,構造出行事件的位置序列,預測用戶的出行需求并提供給用戶個性化打車服務。文獻[19]引入時間因素對移動的影響,對馬爾可夫狀態轉移概率引入參數加以修正。文獻[20]通過非齊次馬爾可夫從駐留時間序列中預測移動用戶何時離開當前位置以及下一步到達何處。研究者還針對軌跡片段缺失、數據稀疏等樣本問題做出改進,引入新的特征或數據提高預測準確性。其中,文獻[21]針對不完全軌跡,放寬模型假設的馬爾可夫性質,對馬爾可夫鏈的條件轉移概率重新定義,使其適用于斷續軌跡的預測。文獻[22]解決在使用單個用戶的軌跡數據建立狀態轉移矩陣時所產生的數據稀疏性問題,通過度量用戶移動行為相似性的方法,將用戶進行聚類,對同組用戶建立共享狀態轉移矩陣。文獻[23]采用馬爾可夫模型進行位置預測,同時采用概率密度函數對離開時間和到達時間進行預測,對預測的結果進行結合,在一定程度上克服了馬爾可夫模型無法兼顧時空特征的缺點。
4.1.2 基于隱馬爾可夫模型的移動預測
HMM 是一種特殊的貝葉斯網絡,它有5 個元素,如圖4 所示,包括有限的隱藏狀態S、有限的觀察狀態O、隱藏轉移概率矩陣A、觀察轉移概率矩陣B和狀態概率π。其中,S、O都是已知,HMM 可以表示為λ=[A,B,π],通常利用Baum-Welch 算法學習參數λ。在一些場景中,無法直接獲取某狀態空間(隱藏狀態)的值,但是能夠通過另外的狀態空間(觀察狀態)間接獲取,此時馬爾可夫模型不再適用。在移動預測中,將空間特征作為隱藏狀態,相應的時刻為觀察狀態,就能夠將時間特征和空間特征關聯,預測未來某個時段的位置。
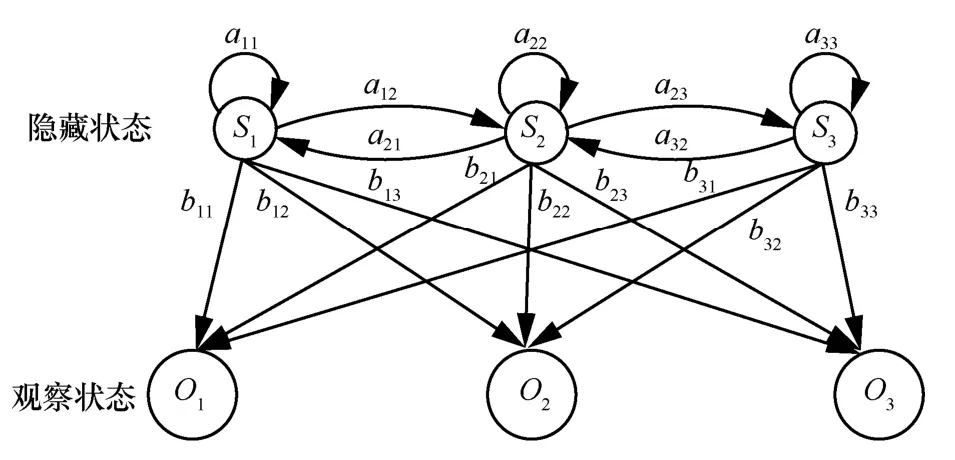
圖4 隱馬爾可夫模型
研究者從應用的角度提出HMM 移動預測,其中,文獻[24]提出一種Wi-Fi 場景AP 選擇方案,通過預測用戶移動獲取高質量的連接,同時降低掃描能耗,該場景為室內移動預測,無法直接觀察到用戶的歷史位置,但通過歷史的AP 連接記錄作為觀察序列能夠間接預測用戶的位置。文獻[25]提出一種自適應流媒體(DASH,dynamic adaptive streaming over HTTP)的視頻質量智能調控方案,用戶所在的道路弧段為隱藏狀態,包含噪聲的GPS 采樣點為觀察狀態,預測將要到達的路段,結合用戶位置和速度進行帶寬估計,進而自適應調整視頻源的編碼。文獻[11,26]則分別根據位置熵(位置熵[9]是指根據用戶訪問各個地點的概率或頻次計算的信息熵,反映用戶移動的規律性程度)和社交距離對用戶進行分組,并對各組用戶分別訓練隱馬爾可夫模型,同組用戶模型共享,相對地提高了整體預測性能。
2 種模型從統計的角度出發,能夠充分利用先驗知識,但也意味著需要豐富的數據關聯信息。此外,用于移動預測的概率統計模型還有多種。文獻[27]利用高斯混合模型進行預測,每個高斯分布代表一個特征的概率分布,對預測的結果由高斯分量加權的概率表示,在數據樣本不足以及數據關聯模糊的情況適用。文獻[28-31]利用樸素貝葉斯模型進行移動預測,樸素貝葉斯模型要求各個特征之間相互獨立,如果特征之間有很強的關聯性,會導致樸素貝葉斯模型效果不佳,但它是最易實現的線性分類器。
4.2 基于判別模型的移動預測
基于概率統計的模型能夠對線性系統進行高效的學習,但是對分類決策存在較高的錯誤率,從概率分布的角度考慮,屬于生成模型(馬爾可夫模型除外)。生成模型根據大量樣本統計目標序列和觀察序列的聯合概率,產生概率密度模型進行預測,反映同類數據的相似度,不關心判別邊界,能夠充分地利用先驗知識;判別模型根據有限樣本生成判別函數進行預測,尋找不同類別之間的最優判別邊界或分類面,反映的是異類數據之間的差異。生成模型的收斂速度更快,但是分類效果往往弱于判別模型,判別模型如支持向量機(SVM,support vector machine)、人工神經網絡(ANN,artificial neural network)、深度神經網絡能夠逼近任意非線性函數,有更加強大的學習能力。
基于判別模型的機器學習算法如SVM、ANN通常用于分類問題。在移動預測中,通過原始軌跡處理和空間特征提取,構造出樣本長度為n的軌跡序列 {l1,l2,…,ln},通過滑動窗口取出長度為steps的元素,作為分類任務的特征向量,將滑動窗口外的下一個元素作為分類任務的標簽,從而構造出分類數據集,滑動窗口越大,意味著受越多歷史時隙的位置影響。數據集構造方法如圖5 所示,本質上是將預測問題轉化成了分類問題。
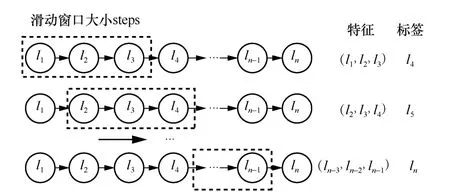
圖5 訓練所用的數據
4.2.1 基于SVM/ANN 的移動預測
SVM 適用于解決中小樣本、非線性以及高維問題,對于數據噪聲有很強的抗噪能力,能夠降低異常值對模型的影響。其分類的基本思想是通過定義適當的核函數,將輸入空間非線性變換到高維空間,并在此高維空間尋找支持向量來組成最優超平面。由于所預測的位置有多種可能,需要利用多值SVM 進行預測。ANN 在處理隨機數據、非線性數據方面具有明顯的優勢,對數據規模大、信息不明確的系統尤為適用,并且模型結構簡單,當數據充足時,ANN 能有效應用于移動預測,有較強的頑健性和容錯能力,但缺點是神經網絡需要大量的參數,訓練時間較長。
利用上述2 種算法進行移動預測,很方便引入其他特征,例如天氣特征、交通特征等,通過特征工程處理后,對圖5 方式構造的特征向量進行擴充,構造新的特征向量,在無法獲取不同特征內在關聯情況下能夠簡單有效地將多種特征結合。文獻[32-33]利用多值SVM 在異構網絡中對終端進行移動預測,避免了馬爾可夫模型的維數災難,所輸入特征向量采用圖5 所構造的數據樣本。其中,文獻[32]為區別隨機移動模式(移動的規則性和可測性較低的移動模式,只受近期位置影響較大)和規則移動模式,通過設定位置熵閾值將用戶進行區分,并對二者采用不同維度的特征向量進行預測。文獻[34-35]將ANN 應用于車載云計算,利用ANN 預測車輛路線,在路邊單元切換過程前預留計算資源,使計算任務快速遷移。
上述傳統機器學習方法在短期的移動預測中效果良好,但是對于長期的預測能力不足。例如用戶在工作日每天的行程大多是規律的,但是每個周末會去俱樂部或游泳館活動,以及每個月初會去醫院檢查身體,這種長期的行為模式是普遍存在的。但是對于這類移動模式,傳統的機器學習方法往往會當作異常值處理,若單純地增大網絡規模來提高訓練準確度,會產生過擬合現象。而基于深度學習的移動預測能夠有效解決此問題。
4.2.2 基于深度學習的移動預測
基于深度學習的預測模型如循環神經網絡(RNN,recurrent neural network)能夠處理大規模的數據集,并從中挖掘出長期的時間依賴關系。RNN因其具有記憶性而被廣泛應用于機器翻譯、自然語言處理等領域,它能保留多個歷史采樣時刻的數據對當前采樣產生的影響,因此方便用來提取具有循環移動行為的移動模式。實際應用中較少使用原版的RNN,因為訓練過程會產生梯度爆炸或者梯度消失,導致記憶能力有限。實際中為了能夠存儲更長期的數據對后文的影響,采用RNN 的變體,如長短期記憶網絡(LSTM,long short-term memory)、門控循環單元(GRU,gated recurrent unit)等,相比于RNN 存在梯度指數衰減而使網絡后面的樣本對前面的樣本感知力下降的問題,LSTM 等能夠過濾對后文有用的樣本特征,從而訓練更深層的網絡。雖然版本不同,但訓練和預測的過程是相同的。RNN 結構如圖6 所示。
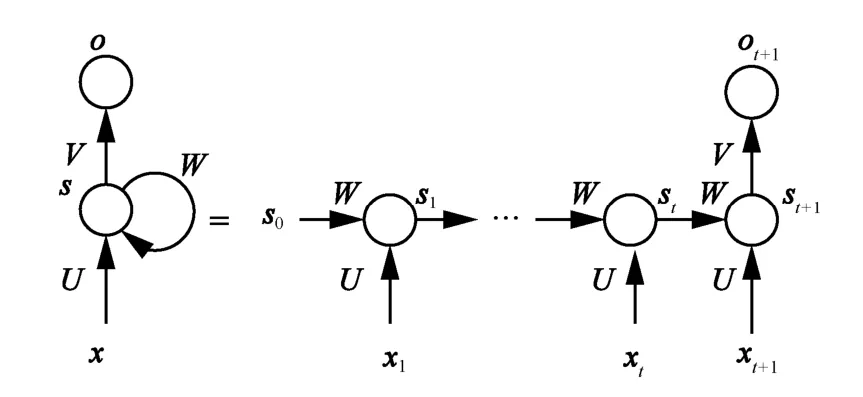
圖6 多對一循環神經網絡結構
圖6 中,x表示輸入層向量,其中xt表示第t(t=1,2,3,…)步的輸入向量;步長代表循環周期,即最多能夠通過隱藏層的連接獲取多少步長的歷史輸入對目標的影響,例如ot+1能夠獲取x1,…,xt+1對其產生的影響,s t表示第t步的隱藏層輸出,o t表示第t步的輸出層輸出;U表示輸入層和隱藏層之間的權重矩陣;W表示連續2 個隱藏層間的權重矩陣;V表示隱藏層和輸出層之間的權重矩陣。對于多對一(多個輸入一個輸出)網絡結構,只保留最后一步的輸出。
RNN 參數的傳遞式為
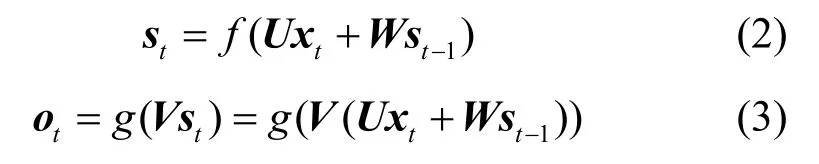
其中,f(?)為隱藏層激活函數,g(?)為輸出層激活函數。在移動預測中,通過圖5 方式構造數據集,要強調的是滑動窗口的長度和RNN 的循環周期保持一致。假設滑動窗口大小為 steps,將樣本{l1,l2,…,lsteps}分 別輸 入RNN 的每步的輸入層,lsteps+1為輸出標簽,通過lsteps+1和ot計算損失函數并進行穿越時間的反向傳播算法訓練。預測時將目標前steps 步的數據樣本傳入模型,可直接得到預測值。
文獻[36-37]針對位置劃分維度過高導致LSTM 維數災難,使用詞向量代替One-Hot 編碼提高學習效率。文獻[38-39]通過引入車輛特征、方向特征、天氣特征或文本特征提高RNN 預測準確性,例如車輛型號和行駛速度相關,而天氣也影響車輛的駐留時間和行駛速度,通過卷積神經網絡(CNN,convolutional neural network)將這些特征融合并嵌入LSTM 網絡進行聯合訓練,有效地進行了車輛位置預測。文獻[40]引入RNN 的Attention 機制,識別更長期的以及多種周期層次的移動模式,Attention 機制在模型輸出時會選擇性地專注考慮輸入樣本的某些信息,因此能夠顯著提高預測性能。
SVM 和ANN 只能進行短期預測,RNN 因為記憶性能夠進行長期預測,但是復雜度較高,需要大量的訓練樣本,當樣本數目少于某個閾值時,性能就會劇烈下降,產生欠擬合現象。
4.3 基于頻繁模式挖掘的移動預測
數據挖掘常用的方法有分類、聚類、頻繁模式挖掘(即關聯分析)等。頻繁模式挖掘建立在大數據的基礎上,從海量的、有噪聲的、不完整的、隨機的數據中提取頻繁出現在數據中的頻繁項集。頻繁項集能夠發現大型事物或者數據之間的關聯或相關性。頻繁模式挖掘常用FP-Growth算法和Apriori 算法。利用Apriori 算法進行移動預測分為3 步,首先對用戶原始移動軌跡進行特征處理,構造軌跡序列;然后對所提取的軌跡序列計算所有候選頻繁項支持度,超過支持度閾值的候選頻繁項構成頻繁項集;最后通過置信度計算與當前序列最相關的頻繁項,從而進行預測。其中,頻繁項集就是所提取的移動模式,對當前軌跡序列和頻繁項進行匹配,匹配到置信度最高的頻繁項。
文獻[41-42]分別利用FP-Growth 和Apriori 對移動進行預測,其中前者結合最長公共子序列算法進行改進,所謂最長公共子序列算法是通過發現和當前序列相似的歷史最長公共子序列進行模式匹配;后者將人群移動模式應用于無線網絡規劃,改進基站的部署方案。文獻[43-46]等對軌跡序列進行相似度度量,根據相似序列進行移動預測。文獻[47-48]針對軌跡信息缺失、數據稀疏、冗余等問題做出特征處理及改進。文獻[49]在馬爾可夫模型中嵌入Apriori 關聯分析來提高預測性能。
FP-Growth 算法將提供頻繁項集的數據庫壓縮到一棵頻繁模式樹(FP-tree,frequent pattern tree),但仍保留項集之間的關聯信息。頻繁模式樹是一棵特殊的前綴樹,它解決了Apriori 算法會產生大量的候選集的問題。Apriori 算法需多次掃描數據,每次利用候選頻繁項集產生頻繁項集;FP-growth則利用樹形結構,不需要產生候選頻繁項集而直接得到頻繁項集,減少了掃描數據的次數,效率更高,但Apriori 的算法擴展性較好,可以用于并行計算領域。
在實際預測中,很多研究者構造了其他樹結構完成序列匹配。文獻[46,50]通過概率后綴樹采用單一序列的模式匹配進行預測。文獻[13]構造了基于路徑特征的概率基樹進行決策,能夠應用于多序列的模式匹配,如圖7 所示,移動終端在路徑a1有概率選擇接連走路徑a2a3,有概率選擇走路徑a4,依次類推,其轉移概率是通過歷史統計所得的位置轉移頻率。文獻[51]綜合考慮了用戶的地理觸發意圖、時間觸發意圖和語義觸發意圖,與傳統的頻繁模式只能代表3 種意圖中的一種不同,通過判斷軌跡語義和時間屬性來修正候選頻繁項的支持度,生成更接近真實模式的頻繁項集,有效地提升了預測性能。
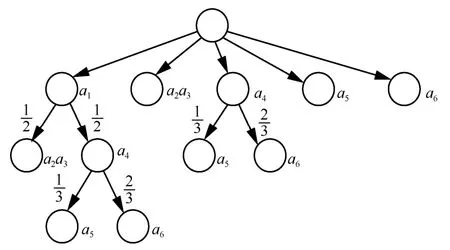
圖7 基于路徑的概率樹
以上總結了幾種被廣泛使用的移動預測算法,在應用中具體采用何種算法,需要根據數據集規模、移動的規律性、數據的連續性、異常值數量、時間復雜度、特征維度等綜合考慮,每種算法都有各自的利弊,需要研究者合理利用算法的優勢,甚至集成不同算法提升預測準確性。
5 其他因素對移動預測的影響
除了時空維度本身的規律,還有很多因素影響用戶的移動,如天氣特征、交通特征、身體特征等,因此移動預測是一個結合多維環境因素的復雜過程。例如天氣因素,用戶每天晚上都會去健身房,但是因為霧霾而暫停;又如交通因素,因為節日導致的交通擁堵迫使用戶放棄外出活動。此外,還有社交因素、健康因素等,這些隨機事件會擾亂用戶的慣性行為,但又是時常發生的。本文對其中的社交因素進行重點闡述。
社交網絡是用戶社交關系的部分體現,相似的用戶或者具有緊密社交關系的用戶往往具有相似的行為模式,例如,用戶甲和乙是關系密切的同事,那么在午飯時間有很大的概率同時從辦公室到食堂就餐。因此基于位置的社交網絡被用來對個體的移動性進行預測是有效的。文獻[28,52]將社交關系作為影響移動的特征,對其他模型預測結果進行修正。文獻[53-54]則考慮到移動預測基于歷史數據,無法預測未曾訪問的區域,引入社交關系協同濾波擴大預測候選集,解決部分新穎位置不可達問題。文獻[55-56]應用圖像識別和文本識別,從用戶社交網絡的文字圖片中提取文本特征,增加特征維度來提高預測準確性。
6 無線網絡場景中移動預測總結
無線網絡是移動預測重要的應用場景。在蜂窩網、Wi-Fi 或超密集組網中,由于用戶的移動性,基站或接入節點的資源(通信資源、計算資源)分配會隨著時間變化。文獻[7-8,24,57-59]將移動預測應用在不同的網絡場景中預測即將接入的節點,在切換前預留通信資源,實現無縫切換服務,具體使用的預測模型因場景而異。文獻[14,38,60]預測應用在車載自組織網絡中,車載自組織網絡相比于移動自組網具有車輛移動速度快、移動路徑受限等特點,當車輛換道可能存在危險時,并線警告將提醒有意換道的駕駛員。并線警告使用V2V 通信和周邊車輛的路徑預測,利用鏈路的通信范圍來預測駕駛員換道可能產生的碰撞。路徑預測用于確定在3~5 s 的時間內,駕駛員要到達的車道區域是否被占用。如果該車道已被占用,則并線警告將會提醒駕駛員潛在的危險。文獻[61]將預測應用在內容中心網絡的主動緩存,預知用戶移動性,在最佳預取節點緩存請求的內容,提高緩存的命中率。文獻[62]將移動預測應用在移動邊緣計算(MEC,mobile edge computing)的任務遷移,將應用發布的任務預先遷移到下一MEC 服務節點,避免任務遷移導致的長時間宕機而影響用戶體驗。以及上文提到的將預測應用在無線傳感網絡定向通信和自適應流媒體,實現智能調控視頻質量。此外,還有更多應用值得研究者挖掘。
由于不同場景使用的軌跡序列的數據規模,特征維度以及預測目標的精度需求有所差異,采用的預測方法有所偏向。例如對于特征維度較高的數據,使用SVM 能夠更好地進行分類及預測;如果所預測的位置狀態較少,高階馬爾可夫模型綜合性能良好且易實現;如果預測用戶長期的移動模式,循環神經網絡性能更好。
在無線網絡中,采用何種算法并非絕對,影響算法性能的主要是所構造的軌跡序列,而軌跡序列是從原始數據通過特征工程得到的。因此,只要針對原始數據進行細致的特征處理,再選擇合適的算法,就能得到針對該場景相對較好的預測性能。表2總結了研究較多的移動預測在無線網絡中的應用。

表2 移動預測在無線網絡中的應用
7 結束語
移動預測是智慧旅游、個性化服務、城市規劃等場景重點關注的問題,目前學者致力于提高移動預測的準確性,為此提出了各種有效的模型,但也存在一些難以解決的問題。一是預測粒度、預測復雜度和預測準確性的權衡,為了提高預測的準確性,往往做出過于理想化的假設,但是其結果大多失去應用價值,而深度學習模型和頻繁模式挖掘往往復雜度過高,在一些實時的應用場景如城市交通調度會有較大時延,難以應用。二是位置熵較高的非規則用戶難以預測,位置熵越高概率分布越均勻,意味著用戶移動更加隨機,規律性不強,這類用戶不遵循固定的行為模式。有學者嘗試根據位置熵對用戶進行分類,建立不同分組的預測模型,但是對位置熵高的群體,預測結果仍然不太理想。三是軌跡數據的發布會產生隱私泄露的風險,若被攻擊者利用,會對用戶的安全產生威脅,因此對軌跡數據的隱私保護尤為重要,目前隱私保護技術尚未完善。四是移動預測要解決的主要問題,即實現時間依賴與空間依賴結合的移動預測,目前的移動預測大多為2 種,根據位置序列預測用戶的下一個位置,或根據時間序列預測用戶駐留時間或到達時間,因為時間與位置之間的關聯不穩定,預測的準確性不高,有學者通過將時間簡單分段與位置建立關聯,但所提出的解決方案缺乏準確性和頑健性。以上正是移動預測必須要解決的一些問題和難點。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
