基于性能感知的網絡切片部署方法
2019-08-29 08:10:00黃開枝潘啟潤袁泉游偉湯紅波
通信學報 2019年8期
黃開枝,潘啟潤,袁泉,游偉,湯紅波
(國家數字交換系統工程技術研究中心,河南 鄭州 450002)
1 引言
5G 系統可以支持各種各樣的垂直行業,如自動駕駛、遠程醫療、工業自動化等。傳統移動網絡“一刀切”的網絡架構無法在垂直方向滿足網絡在可擴展性、可用性和可靠性方面的性能差異要求[1]。為適應多種類型的垂直行業的需求,提出了網絡切片(NS,network slicing)的概念。下一代移動網絡聯盟(NGMN,the next generation mobile network alliance)將網絡切片定義為在相同的物理基礎設施上運行的多個虛擬網絡[2]。每個網絡切片是一個獨立的虛擬網絡,它可以根據特定的服務需求(如超低時延、高可靠性和移動性等)選取配置相應的虛擬網絡功能,創建可編程的網絡切片實例(NSI,network slice instance),為不同用戶提供端到端的定制化服務。
為了提高物理資源利用率,基礎設施運營商將不同NSI 的虛擬網絡功能(VNF,virtual network function)部署在相同的物理服務器上,與此同時,采用資源復用技術實現資源的超額分配,這種部署方式會導致共享物理資源的VNF 間過度競爭底層硬件資源(如CPU、存儲等),造成服務性能的嚴重下降,影響用戶體驗。但是現有的關于網絡切片部署的研究主要集中在提高資源利用率或降低能源消耗[3-5],僅有少數文獻[6-13]考慮到上述問題。因而,在網絡切片部署時如何有效降低因過度競爭資源帶來的服務性能下降,已成為基礎設施運營商面臨的一個挑戰。文獻[6]研究了虛擬機(VM,virtual machine)隔離技術,通過安裝多個網絡適配器,降低了共存VM 間的性能干擾。為了使底層管理者能夠非侵入式地監測VM,文獻[7]設計了一種硬件計數器,該計數器可以很好地反映不同類型應用所受性能干擾的程度。文獻[8]提出了一種基于層次聚類和優化搜索的功耗感知算法,從資源利用率的相關性角度量化了2個共存VM間的資源使用情況。文獻[9]設計了一個通用模型來描述VM 間的性能下降,根據不同VM的生命周期設計VM調度策略,不但能夠抑制物理服務器上的性能下降,還降低了運營成本。文獻[10]基于Xen I/O 機制和虛擬CPU(VCPU,virtual CPU)調度機制設計了一種性能估量模型,根據該模型估計出VM 遷移前與遷移后的性能下降,并提出了一種輕量級的干擾感知的VM 在線遷移策略,但是該策略完全基于Xen I/O 機制和VCPU調度機制,并不具有通用性。文獻[11]建立了VM 的性能模型,基于該模型放置VM 不但能夠保證VM 的性能而且能夠有效降低服務器的功耗。文獻[12]提出了一種VM 的在線放置算法,綜合考慮不同類型的資源使用情況,并使用基于閾值的位移策略來降低因服務器過載而導致的性能下降。為了解決虛擬化環境中因超額預訂帶來的性能波動,文獻[13]設計了一種基于服務等級的VM 部署策略,根據實時監測得到的網絡吞吐量和服務響應時間的變化情況對不同服務等級的VM 進行資源分配,以實現VM 間的性能隔離,但是該方法未能有效度量虛擬節點的性能下降,導致執行時服務性能已經存在不同程度的下降,所以該方法對用戶忍耐服務性能下降的能力要求很高。
針對文獻[13]中存在的問題,本文提出了一種基于性能感知的網絡切片部署方法。在網絡切片實例部署時采用先虛擬節點映射再虛擬鏈路映射的兩階段部署方式。在虛擬節點映射中,為有效度量VNF 的性能下降,從VNF 所需資源與物理服務器可提供資源之比的角度定義了VNF 的性能影響因子,優先將VNF 部署在能夠使網絡切片實例性能影響因子總和最小的物理服務器上,然后利用模擬退火-離散粒子群算法求解節點映射結果,從而能在多項式時間內求出最佳部署結果。在虛擬鏈路映射中,選取滿足鏈路資源約束條件的最短路徑作為鏈路映射結果。仿真結果表明,本文提出的方法在全網性能影響因子總和及性能影響程度方面均低于其他對比方法,證明了該方法可以在相同物理基礎設施的多個網絡切片實例間實現有效的性能隔離。
2 問題分析
2.1 網絡切片實例化及部署模型建立
網絡切片實例是一個專用的虛擬網絡,一個網絡切片實例由一條或多條服務功能鏈(SFC,service function chain)[14-15]組成,不同的服務功能鏈由多個帶順序約束的VNF 組成。網絡切片實例化流程如圖1 所示。當用戶發起服務請求時,網絡管理和編排器根據用戶服務請求的需求特點組合VNF 形成SFC;然后,結合物理網絡SG的剩余物理資源的狀態信息,嘗試為SFC 分配物理資源,如果底層物理網絡可以滿足服務請求的節點和鏈路的虛擬資源需求,則底層資源池為其分配物理資源完成實例化,并獲取可以部署的位置邏輯視圖VG,更新物理網絡的剩余資源信息,配置NSI 的生命周期并監控運行狀態;最后,按照f1→f2→f3的順序完成數據的傳輸和處理,為用戶請求提供服務[16]。

圖1 網絡切片實例化流程
物理網絡用一個有權無向圖GS=(N S,LS,CN,CL)表示,其中,NS和LS分別為物理節點集合和物理鏈路集合,ns∈NS表示通用物理服務器,l s(m,n)∈LS是連接服務器m和服務器n間的物理鏈路;CN和CL分別表示物理服務器和物理鏈路的資源屬性,物理服務器可以提供多種物理資源,CN=(c1,c2,…,cm)表示物理服務器可以提供的物理資源集合,c m∈CN表示物理資源類型,在本文中物理服務器的資源包括計算資源、存儲資源和網絡資源,CL表示物理鏈路可以提供的帶寬資源。
假設在物理網絡上部署了K個網絡切片實例,其中,第k個網絡切片實例可以表示為同樣地,表示第k個網絡切片實例的VNF 集合和虛擬鏈路集合。指第k個網絡切片實例中VNF 所需的虛擬資源集合;表示虛擬資源類型,包括VNF 所需的計算資源、存儲資源和網絡資源,表示虛擬鏈路所需的帶寬資源。
網絡切片實例到物理網絡GS的映射稱為網絡切片實例部署,在滿足資源約束條件下,將VNF映射到物理服務器上,將虛擬鏈路映射到一組物理鏈路上。變量表示網絡切片實例的VNF 和虛擬鏈路是否映射成功,值為1 表示映射成功,值為0 表示映射失敗,如式(1)和式(2)所示。

2.2 性能下降分析
當多個網絡切片實例部署到同一物理網絡上時,必然會存在多個VNF 部署在同一物理服務器上的情況,如圖2 中服務器C 上的VNFb和VNFe,在開放共享物理資源的環境下,VNFb和VNFe可能由于誤操作或過載而占用大量物理資源,影響其他NSI 的服務性能。當NSI 的服務性能下降時,會給網絡帶來多方面的影響,如表1 所示。為應對該問題,文獻[13]根據實時監測網絡吞吐量λ和服務響應時間t,在資源分配時通過最小化來避免性能下降,分別代表用戶期望的網絡吞吐量和服務響應時間;但是該方法在檢測到λ降低和t增加時才采取行動,這時虛擬節點的性能已經存在下降,如何有效度量虛擬節點的性能下降并在網絡切片部署時采取有效方法控制虛擬節點的性能下降已成為關鍵問題。虛擬節點的性能下降主要是由多虛擬節點間物理資源的過度競爭引起的[9],如圖2 所示,在服務器B 上只有VNFa,沒有其他的VNF 占用物理資源,故VNFa基本可以達到期望的服務性能;但是在服務器C 上,VNFb和VNFe間存在物理資源的競爭,故可能會導致虛擬節點的性能下降,因此可以根據服務器的資源使用情況來對虛擬節點的性能影響大小進行表征。

圖2 NSI 請求部署模型

表1 性能下降所帶來的影響
本文提出了一種基于性能感知的網絡切片部署方法,一方面從多維度的資源供需角度定義了性能影響因子,以刻畫當前物理服務器中其他應用給自身應用所帶來的性能影響;另一方面根據該性能影響因子為虛擬節點選擇可部署的服務器,采用改進型離散粒子群算法求出部署結果,并且采用最短路徑算法求出鏈路部署結果。
3 基于性能感知的網絡切片部署方法
本文提出的基于性能感知的網絡切片部署方法采用先虛擬節點映射再虛擬鏈路映射的兩階段部署方式[17]。首先進行虛擬節點的部署,對滿足節點資源約束及唯一性約束的物理服務器,根據性能影響因子的定義求出部署在這些物理服務器上時VNF 的性能影響因子,選擇使NSI 請求中所有VNF性能影響因子總和最小的物理服務器作為最終的部署位置,并利用改進型離散粒子群算法求解節點映射結果;然后進行虛擬鏈路部署,在滿足鏈路資源約束的條件下,為相鄰VNF 間的虛擬鏈路選擇最短的物理鏈路進行映射。
3.1 虛擬節點映射
在進行虛擬節點映射時,首先從VNF 所需資源與服務器可提供資源之比的角度定義VNF 的性能影響因子,并結合VNF 性能影響因子的定義,建立了虛擬節點的映射模型,然后利用模擬退火-離散粒子群算法求出節點映射結果。
3.1.1 性能影響因子的定義
在物理資源超額分配的情況下,多個VNF 間過度競爭一種或多種物理資源,使VNF 的資源供需不匹配帶來服務性能的下降。為了估計VNF 的性能影響程度,本文將VNF 的虛擬資源的需求與服務器的剩余物理資源的比值定義為性能影響因子。假設VNF 運行在相同類型的硬件上,在物理服務器x∈Ns上存在n個VNF,第i個VNF 的性能影響因子如式(3)所示。
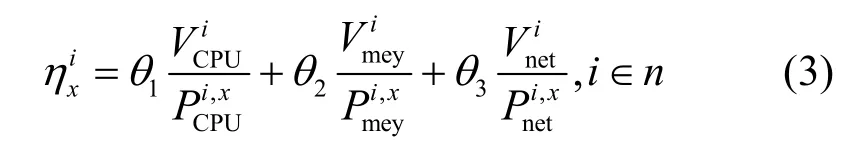
3.1.2 虛擬節點的映射模型建立
基于性能影響因子的定義,當一個NSI 請求到達時,為了保證服務質量、避免VNF 下降明顯,在選擇物理服務器時,需要保證VNF 的性能影響因子較小。故將優化目標定為最小化全網所有VNF的性能影響因子總和,如式(4)所示。此外,還需滿足如式(5)~式(9)所示的約束條件。其中,當第k個SFC 的虛擬網絡功能映射到服務器ns上時,要保證物理服務器的剩余CPU 資源、剩余存儲資源及剩余網絡資源不小于VNF 所需的相應的虛擬資源,如式(5)~式(7)所示;式(8)表示一個VNF 只能部署在一個物理服務器上,不能對其進行分割;式(9)保證了服務請求的所有VNF 全部被部署到物理網絡上。

3.1.3 虛擬節點映射結果求解
網絡切片的虛擬節點映射是一個NP-hard 問題,在多項式的時間內無法利用傳統方法進行求解,因此采用智能算法進行求解。在實際網絡中,網絡管理和編排器作為網絡切片中統籌全局的管理者,負責網絡切片的映射問題,智能算法被寫入編排器。因網絡切片在實現時融入了軟件定義網絡(SDN,software defined network)的技術,基于SDN架構并借助OpenFlow 協議可以在高度分布化和動態化的網絡中實現快速的信息交互。如圖3 所示,網絡管理和編排器接收網絡切片實例和基礎設施層發來的數據,將網絡切片實例的服務描述、網絡拓撲等信息載入網絡服務目錄中,將VNF 所需的虛擬資源等描述類的信息載入VNF 目錄中,更新NFV 實例庫的信息,將物理網絡拓撲和剩余資源等信息載入基礎設施資源庫中,待所有信息完備后,啟動智能算法,開始求解映射結果。

圖3 網絡管理和編排器
本文使用基于模擬退火(SA,simulated annealing)的離散粒子群(DPSO,discrete particle swarm optimization)算法求解節點映射結果。DPSO優化算法是一種群智能優化算法,通過研究鳥類在覓食過程中的行為特點,把所研究問題的搜索空間視為作鳥類飛行空間,每一個粒子都是所求問題的一個候選解,最優解即為鳥類最終找到的食物,在尋找最優解時利用不同個體之間的協作和信息的共享[18]。
當多個網絡切片實例映射到相同的物理網絡上時,為了保證不同網絡切片實例間的VNF 不會因為資源過度競爭而產生性能下降,本文將當前NSI 請求的所有VNF 性能下降因子總和作為算法的適應度函數,如式(10)所示。為了求出映射結果,首先,初始化由n個粒子組成一個種群,這里的每一個粒子都是一個可能解,第i個粒子可以用向量來表示,其中,i是[1,n]的整數,n是種群規模,a是當前NSI 請求中包含的VNF 總個數,xia是當前NSI 請求中第a個VNF 映射到的物理服務器的序號。然后,將代入式(10)求出當前映射方案的全網VNF 性能下降影響總和,因本文求的是最小值,適應度越低,代表當前映射方案越優。與此同時,每當計算出一個粒子的適應度,算法都會更新當前的個體最優解和全局最優解。為了使粒子快速而準確地飛向最優解,每個粒子對應一個飛行速度,第i個粒子的飛行速度可以用向量表示。本文采用帶壓縮因子的DPSO 算法,利用式(11)進行速度的更新;壓縮因子χ由式(12)求出;學習因子c1和c2分別代表粒子本身和其他粒子所獲經驗,調整學習因子能夠控制粒子在全局探測和局部開采的平衡;利用式(13)進行位置更新。
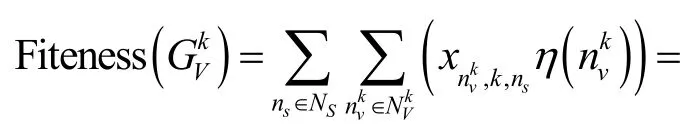

DPSO 算法是一種全局搜索算法,易跳入局部極值點,而SA 算法可以有效避免該問題。SA 算法把系統降溫時的能量看成是目標函數,將優化過程模擬成系統降到最低溫度的過程。利用SA 算法對個體最優解進行領域搜索,采用輪盤賭輸策略來選擇是否利用個體最優解替換全局最優解。突跳概率可利用式(14)進行計算,N是種群大小,f是適應度函數。速度更新式如式(15)所示。
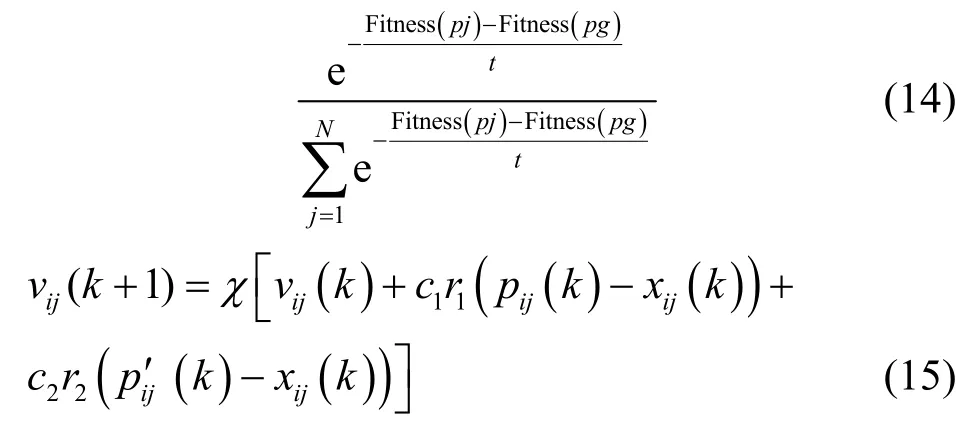
3.2 虛擬鏈路映射
完成網絡切片實例的所有VNF 的映射后,基于最短路徑[19]的思想完成不同VNF 間的鏈路映射。根據SFC 的各個VNF 間的順序約束得到VNF 的部署順序?k={f1,f2,…,fi,…,fn},假設與虛擬節點fi相連的上一級節點是,而且經過同一VNF 的fi的所有的虛擬鏈路的映射優先級相同。第k個SFC 的虛擬鏈路映射到物理鏈路p上,主要分為以下幾步。
2)檢查是否滿足鏈路資源約束,保證每條物理鏈路的剩余帶寬資源不小于虛擬鏈路所需的帶寬資源,如式(16)所示。換句話說,鏈路的資源約束由子物理鏈路的最小剩余帶寬決定,如式(17)所示。當滿足鏈路資源約束時,成功映射到pa→n→b上,保存鏈路映射結果;否則轉至3)。
3)若該鏈路與其他虛擬鏈路存在復用物理鏈路,查看是否可以釋放該鏈路的物理資源以滿足鏈路資源約束,如果可以滿足,成功映射到pa→n→b上,保存鏈路映射結果;否則轉至4)。
4)如果不存在鏈路復用或是釋放復用鏈路資源仍舊無法滿足約束,則利用算法求出次短路徑,重復上述步驟進行判斷。如果全部路徑均無法滿足鏈路約束條件,則當前虛擬鏈路映射失敗。
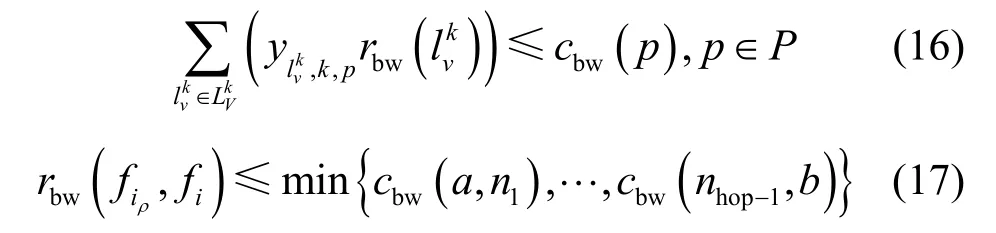
4 部署方法流程
基于性能感知的網絡切片部署方法流程如算法1 所示。
算法1基于性能感知的網絡切片部署
輸入物理網絡GS與K個網絡切片實例請求
輸出最佳映射方案
1)設置種群規模Scope、最大迭代次數maxg、c1和c2;
2)為NIND 個粒子初始化位置向量、速度向量;
3)根據式(10),計算初始種群中所有粒子的性能下降因子總和作為適應度值,并求出個體最優值pb、全局最優值gb;
5)當迭代次數在區間[1,maxg]時,重復步驟6)和步驟7);
6)當種群規模在區間[1,Scope]時,利用SA算法對粒子的pb 進行領域搜索,使用輪盤賭輸策 略,計算Fitness(pj)-Fitness(pg),當random[0,1]時,用pb替換gb;
7)當種群規模在區間[1,Scope]時,利用式(15)及式(13)更新粒子的速度向量、位置向量,并更新個體最優值pb、全局最優值gb;
8)存儲NSI 請求最佳的節點映射結果;
9)由VNF 的順序約束得到NSI 的虛擬節點部署順序?k={f1,f2,…,fi,…,fn};
10)對?i∈n獲取與VNF 相連的上一級VNF:
11)對于經過 VNF 的fi的所有的鏈路,利用最短路徑算法進行相關鏈路映射;
12)當滿足rbw(fiρ,fi)≤min {cbw(a,n1),…,cbw(nhop-1,b)}時,成功映射到pa→n→b上,轉入步驟15);否則,轉入步驟13);
13)若該鏈路與其他虛擬鏈路存在復用,且可以釋放該鏈路的物理資源以滿足鏈路約束,轉入步驟15);
14)若釋放資源仍無法滿足約束或是不存在鏈路復用,檢查剩余的次短路徑,重復步驟12)~步驟14);
15)存儲相關虛擬鏈路的映射結果;
16)輸出最佳映射結果。
5 仿真分析
5.1 實驗環境
本文使用GT-ITM 工具生成物理網絡及網絡切片實例請求,運行在配置為Intel(R)Pentium(R)3.4 GHz CPU、4 GB 內存的PC 機上,并使用Matlab對結果進行分析。將本文提出的方法(Min-Dep)與最小化部署成本(Min-Cost)[20]及最小化虛擬網間的共存度(Min-CoNum)這2 種方法從請求接受率、收益開銷比、性能影響因子總和及性能影響程度四方面進行對比。網絡參數設置如表2 所示,仿真參數設置如表3 所示。

表2 網絡參數

表3 仿真參數
5.2 仿真結果及性能分析
圖4是不同部署方法的收益開銷比的曲線。從圖4 中可以看出,3 種方法隨著NSI 請求數量增多,收益開銷比均逐漸趨于穩定,最終穩定結果顯示Min-Cost 方法的收益開銷比最大,而且本文方法(Min-Dep)的收益開銷比稍高于Min-CoNum 方法。這主要是因為Min-Cost 方法統籌考慮了節點和鏈路的成本消耗,使底層物理網絡的碎片資源數量相對較少,提高了收益開銷比。而其他2 種方法部署的目標函數都是僅從虛擬節點考慮,在虛擬鏈路的映射上在滿足資源約束的條件下,尋找最小跳的路徑,這樣增多了節點上的未被使用的碎片資源,資源利用率降低,導致收益開銷比較低。
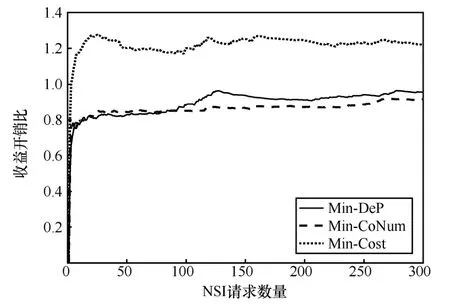
圖4 收益開銷比
圖5 反映了3 種方法隨著NSI 請求數量增多請求接受率的變化情況。從圖5 中可以看出,3 種方法的請求接受率均出現了不同程度的下降,這是因為部署到物理網絡上的NSI 請求逐漸增多,剩余物理資源逐漸減少,導致部分新到達的NSI 請求無法成功映射到物理網絡上。相較于Min-CoNum 方法,Min-Dep 方法和Min-Cost 方法的請求接受率下降更為明顯,且在部署了大概250 個NSI 請求后,Min-Dep 方法的請求接受率稍高于Min-Cost 方法。原因是Min-CoNum 方法在映射時因受節點共存數量的限制,那些部署較少VNF 的服務器會作為優先選擇對象,在一定程度上避免了因節點資源不足造成的映射失敗的情況,提高了請求接受率。而本文方法統籌3 種資源的供需比,Min-CoNum 方法期望部署成本最小化,均未考慮底層網絡資源的均衡性,故使請求接受率下降較多。

圖5 網絡請求接受率
圖6 反映了3 種方法的性能影響因子總和的對比情況。從圖6 中可以看出,Min-Dep 方法相較于其他2 種方法,性能影響因子總和維持在一個相對較低的水平。主要是由于Min-Cost 方法在部署時將最小化部署成本作為目標函數,并未考慮共享物理資源的VNF 間的性能影響,導致性能影響因子總和處于一個相對較高的水平。而Min-CoNum 方法在部署時僅是從物理服務器上共存VNF 數量考慮,并未考慮它們之間的資源供需情況,因此性能影響因子總和水平較高。
為了進一步證明Min-Dep 方法的有效性,除了考慮性能影響因子總和的對比情況,本文還對性能影響程度進行了對比。運行在VM 中的VNF 的標準性能[14,20]定義為在理想情況下運行時的性能,即物理服務器的其他VNF 全部處于閑置狀態。在實際運行時,VNF 受到的性能影響程度可以表示為它在實際情況下的性能與它在理想環境下的性能之比。在物理服務器x∈Ns上存在n個VNF,第i個VNF 在理想情況下運行時的性能設為,在實際情況下運行時的性能設為,則第i個VNF性能影響程度可以表示為


圖6 性能影響因子總和
圖7 對比了這3 種方法的性能影響程度的變化情況。在請求初始到達階段,因物理網絡剩余資源富足,3 種方法的性能影響程度相差不大;隨著請求數量的增多,底層物理資源剩余量的減少,3 種方法在性能影響程度上均呈現增長趨勢,但是Min-Dep方法性能影響程度的增長速率最慢,而且始終低于其他2 種方法,這主要是由于Min-Dep 方法在部署時優先將VNF部署在性能影響因子較小的物理服務器上,相較于其他方法,Min-Dep 方法可以在部署階段有效降低其他VNF 對自身性能的影響。
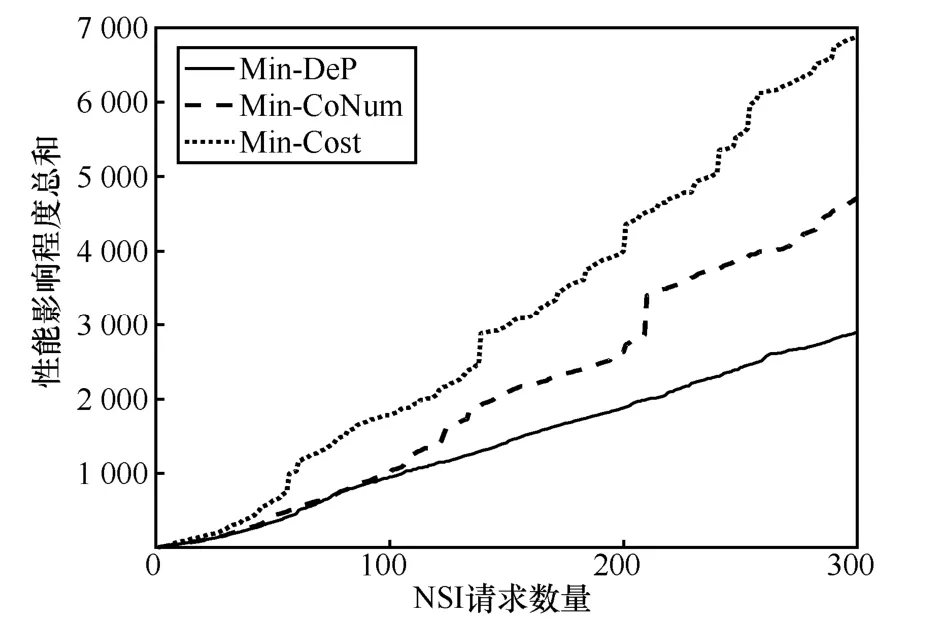
圖7 性能影響程度總和比較
6 結束語
網絡切片是5G 十分有發展潛力的關鍵技術,旨在通過建立端到端的解決方案定制化滿足不同用戶的需求。由于網絡切片是基于虛擬化技術實現的,在同一物理基礎設施上部署的網絡切片實例間仍存在因資源過度競爭帶來的性能下降問題,故本文提出了一種基于性能感知的網絡切片部署方法,并驗證了該方法的有效性。在虛擬節點部署階段,首先從多維度的資源供需的角度量化了VNF 的性能影響大小,然后將全網性能影響程度總和最小作為目標函數,并采用群智能優化算法進行迭代尋優,得到最終的節點部署結果;在虛擬鏈路部署階段,采用了最短路徑方法進行虛擬鏈路映射。最終證明了該方法可以在一定程度上降低其他網絡的虛擬網絡功能對自身網絡的性能影響,但是在網絡請求接受率和收益開銷比方面優勢不太明顯,在今后的研究中將從這2 個方面進行改進。
猜你喜歡
井岡教育(2022年2期)2022-10-14 03:11:44
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
中學生數理化·八年級物理人教版(2019年9期)2019-11-25 07:33:00
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
資源再生(2017年3期)2017-06-01 12:20:59
中學生數理化·中考版(2017年12期)2017-04-18 12:55:05
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
