邊緣計算下的AI檢測與識別算法綜述
2019-08-30 03:31:56孔令軍李華康
無線電通信技術 2019年5期
孔令軍,王 銳,張 南,李華康
(1.南京郵電大學,江蘇 南京 210003;2.北京中燕信息技術有限公司,北京 102488;3.中國航天系統科學與工程研究院,北京 100048)
0 引言
隨著人工智能(Artificial Intelligence,AI)熱潮的興起,深度學習等多種算法相繼被探索出來,并廣泛應用在安防、交通、醫療、教育、零售、家居等領域[1]。卷積神經網絡(Convolutional Neural Network,CNN),是深度學習的代表算法之一,并被廣泛應用于計算機視覺、自然語言處理等領域[1]。
ImageNet[3]比賽的開展,促使圖像領域卷積網絡快速發展,深度學習方法遠遠超過傳統方法的準確率,使得CNN獲得了巨大的關注。隨后的比賽中,CNN逐漸取代了傳統的目標檢測算法。為了進一步增加模型的準確率,卷積網絡的模型不斷被加深,導致現在的模型需要龐大的計算能力和內存才能勝任某些工作。深度學習理論的蓬勃發展,帶動了商業化的需求,尤其是在智慧城市等相關領域,如人臉識別、車輛檢測及車牌識別等。傳統的監控系統設計方式由客戶端和服務器構成:客戶端負責收集圖片并上傳服務器,服務器負責對圖片運用人工智能算法進行分析。隨著客戶端的增加,客戶端所產生的數據量也將隨之變大。這些數據若都交由云端服務器管理平臺來處理,將會造成網絡傳輸和服務器端巨大的壓力。同時,設備之間的性能不相同使得實時協同工作難以保證,數據泄露風險還將增大。IDC表示到2019年,近50%物聯網創建的數據將被存儲、處理、分析,并在網絡邊緣進行操作。麥肯錫估計,到2025年,物聯網應用的經濟影響可能會從每年3.9萬億美元增長到11.1萬億美元。他們舉例說:“在2025年,通過遠程監控改善慢性病患者健康狀況的價值可能高達每年1.1萬億美元。”Markets And Markets的一份新研究報告預計,邊緣計算市場預計將從2017年的14.7億美元增長到2022年的67.2億美元,在預測期內復合年增長率超過35%。Gartner的分析報告顯示,目前,大約10%的企業生成數據是在傳統的集中式數據中心或云之外創建和處理的,到2022年,Gartner預測這一數字將達到50%。隨著5G時代的到來和AI硬件的發展,實時、智能、安全、隱私等四大趨勢催生了邊緣計算與前端智能的崛起。
1 邊緣計算以及卷積網絡發展概況
本節將主要闡述邊緣計算發展歷程以及深度學習中CNN的發展歷程。
1.1 邊緣計算發展歷程
邊緣計算最早可以追溯至1998年提出的內容分發網絡(Content Delivery Network,CDN),它是一種基于互聯網緩存網絡,通過中心平臺的負載均衡、調度等將用戶訪問指向最近的緩存服務器上,以此降低網絡阻塞。2009年提出的Cloudlet概念,高性能、資源豐富的分布式服務器為移動設備提供計算或者資源訪問服務,此時邊緣計算強調的云服務器功能下行至邊緣服務器,以減少帶寬和時延。隨后,在萬物互聯的背景下,邊緣數據迎來了爆發性增長,為了解決面向數據傳輸、計算和存儲過程中的計算負載以及數據傳輸帶寬等問題,研究者開始探索在生產者的邊緣增加數據處理功能,即萬物互聯服務的功能上行,具有代表性的是計算設備端處理即移動邊緣計算。
邊緣計算能夠解決網絡擁塞、服務器計算壓力大以及數據安全性等問題,然而對于卷積網絡算法,受限于邊緣計算硬件設備性能限制,網絡模型的大小以及計算要求也必須做出相應的優化,以適應邊緣計算設備使用。于是各種壓縮卷積網絡模型算法,如剪枝、結構化卷積核等算法被提出,用來降低模型對資源的消耗。
在谷歌學術上以“邊緣計算”為關鍵詞搜索到論文數量趨勢如圖1所示。2015年以前,邊緣計算處于技術發展累計階段;2015—2017年,邊緣計算開始快速發展,文章數量增長了10倍之多。直到2018年,邊緣計算開始穩健發展。
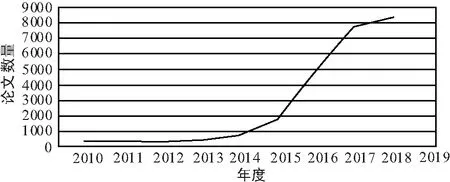
圖1 谷歌學術上以“邊緣計算”為關鍵詞搜索到論文數量
1.2 深度學習下CNN發展歷程
第一個神經網絡是LeNet網絡[1],它于1998年被提出,用于進行手寫數字識別任務。它確定了卷積網絡的構成,即由卷積層、池化層以及全連接層組成。由于傳統算法不需要大量的計算量也能達到相同的效果或者更好的效果,使得它的出現并沒引起太多關注。隨著計算機硬件性能不斷提高,2012年AlexNet[5]網絡以絕對優勢一舉奪冠,自此CNN引起了廣泛關注,呈現出越來越多關于CNN的研究成果。AlexNet由5個卷積層以及3個全連接層組成。其中提出的局部響應歸一化層(LRN),用于對數據進行歸一化,解決特征圖二維平面內點之間的聯系,以提升訓練速度。一年后,VGG網絡[6]被提出,它提供了一種新的思路,即:隨著網絡層的深度增加,效果也會隨之增加。此后的網絡設計中通過不斷堆疊的卷積層,使得網絡層的深度也不斷增加,算法效果不斷提高。VGG提出的第2年,GoogleNet[7]獲得了比賽冠軍,其不僅增加了深度,還通過結構化網絡設計增加數據的重利用來提高效果。GoogleNet提出的如圖2 inception模塊所示結構,通過使用1x1,3x3,5x5卷積核以及3x3最大池化層過濾特征圖獲得結果,并合并結果作為提取到的特征圖。為了降低計算量,使用了1x1卷積核提前過濾,獲得通道維度較少的特征圖,然后通過卷積核進行卷積操作, 維度減少的inception模塊如圖3所示。
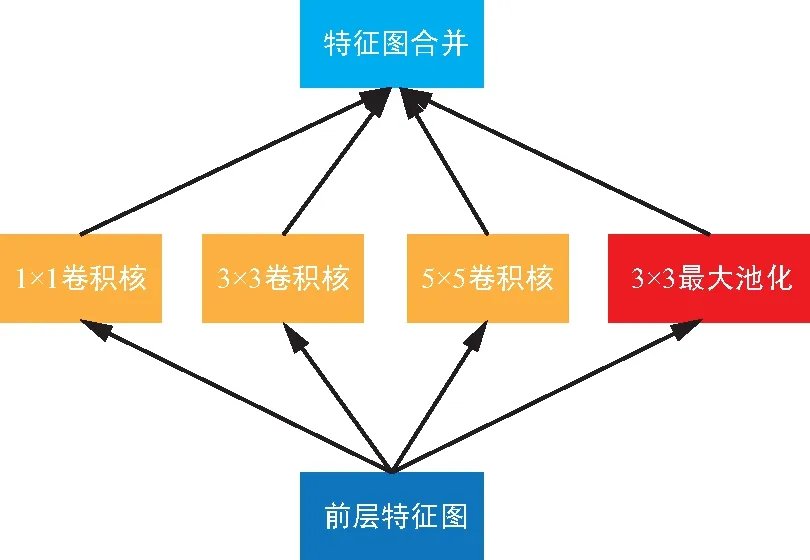
圖2 inception 模塊
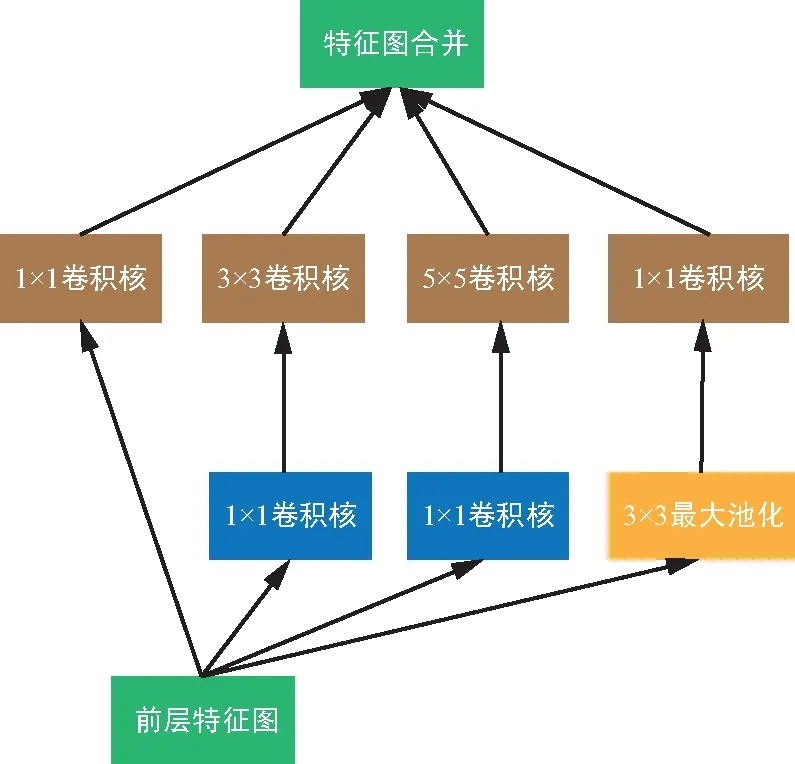
圖3 維度減少的inception 模塊
inception這種方式提高了參數的利用率,使得網絡能夠提取各種不同維度形狀特征來提高識別效果。隨后的網絡設計也越來越深,由于每次卷積后都會通過激活函數進行激活,對數據進行篩選,這種做法能夠強化卷積網絡的線性表達能力。但隨著卷積網路的深度增加,被過濾掉的特征也隨之增加,網絡也將退化,梯度也隨之消失,不容易訓練。為解決這個問題,ResNet[8]引入殘差網絡單元,如圖4所示。將未被卷積的特征屬性與經過卷積后的特征屬性進行特征融合,并重新加以利用,使得識別效果顯著增加。隨著殘差單元的提出,借鑒了參數重利用的網絡算法不斷被提出,網絡性能得到一定提升,識別效果也進一步增強。一種全新的結構DenseNet[9]網絡借鑒了殘差單元思路,設計了一個結構簡單全新的網絡,性能及效果突破了Resnet的各種指標。Densenet相對于Resnet更加強調特征的復用,幾乎將所有的淺層特征圖作為輸入進行卷積操作,極大減少了參數量,通過密集的連接緩解了梯度消失的問題。它頻繁將不同深度特征通過通道合并,當前特征圖融合了幾乎所有前層的特征圖,幾乎所有層相當于直接連接輸入和損失函數,這樣就能夠減輕梯度消失問題。
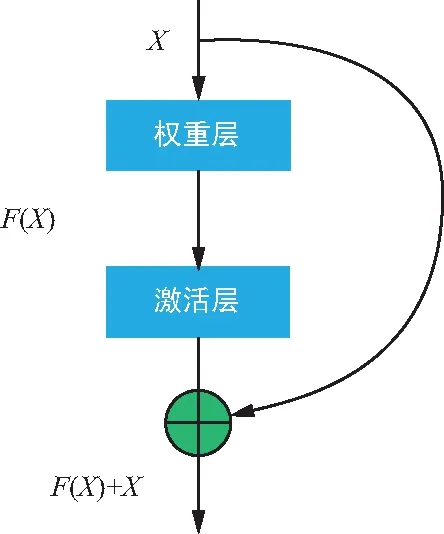
圖4 殘差網絡單元
對上述卷積網絡進行特征提取后,便可以將提取到的特征圖應用到各種圖像算法中,比如目標檢測、目標跟蹤、關鍵點定位、生成對抗網絡等。
2 目標檢測識別算法
2.1 MTCNN算法
MTCNN算法[9]既可以用于人臉檢測,也可以用于其他目標檢測算法中。圖5 為MTCNN人臉檢測算法,它首先通過圖像金字塔將輸入圖像變為不同尺度的圖片,然后送入P-Net網絡獲取人臉預測框預測,再將P-Net預測得到的人臉框送入R-Net及O-Net進行多次判斷預測,之后再通過極大值抑制算法刪減多余的預測框。訓練時通過預測交叉熵損失函數訓練人臉/非人臉:
(1)
人臉框回歸以及關鍵點定位損失函數都使用L2范式:
(2)
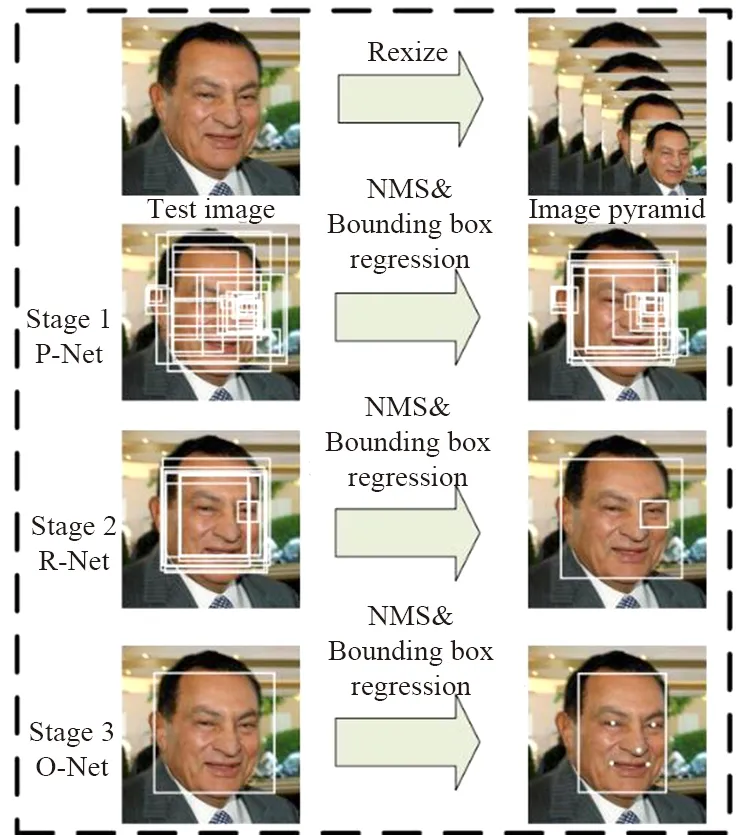
圖5 MTCNN人臉檢測
2.2 Faster R-CNN目標檢測算法
Faster R-CNN算法[10]由目標檢測算法R-CNN[11]發展而來。在ImageNet目標檢測比賽中,R-CNN最先將卷積網絡運用于目標識別,以壓倒性優勢戰勝了傳統目標檢測算法。R-CNN具體做法是:通過提取圖像ROI區域生成ROI區域組,再將區域分別送入CNN進行特征提取,并將提取到的特征送入SVM分類器判別是否屬于該類別,并使用回歸預測修正候選框的位置。
R-CNN經過一系列發展,演化出了性能和效果雙優的Faster R-CNN目標檢測算法。Faster R-CNN檢測過程如圖6所示[10]。
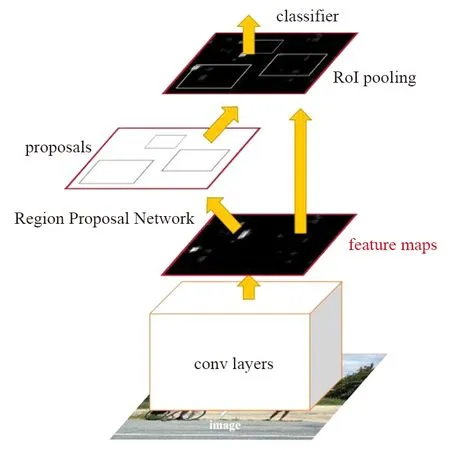
圖6 Faster R-CNN檢測過程
通過卷積網絡進行圖片的特征提取,獲取圖片的特征屬性圖,并通過Proposal層類似于區域候選網絡(Region Proposal Network,RPN)獲取候選anchor。Faster R-CNN anchor提取如圖7[10]所示。Faster R-CNN通過特征屬性圖滑動窗口上的anchor獲取不同形狀候選框,每個候選框對應特征圖上一點,然后通過分類損失函數和回歸損失函數進行聯合訓練。
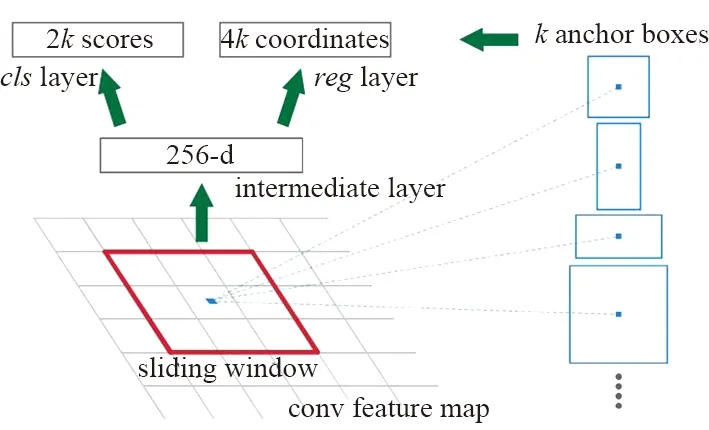
圖7 Faster R-CNN anchor提取
聯合訓練損失函數如下:
(3)
(4)
(5)
(6)
(7)
Faster R-CNN的提出使得目標檢測算法性能以及效果能夠基本用于實際環境,檢測的速度達到17 fps。
2.3 YOLO目標檢測算法
YOLO[12]來源論文中的”You Only Look Once”,不同于R-CNN一系列網絡將目標檢測分為兩類任務:通過RPN獲取候選框完成候選框回歸任務和分類任務。YOLO則是將兩類任務合并成單任務進行。其基本過程為:① 將圖片分為S*S個網格,對于物體中心點出現在某網格內部,則此網格負責檢測該物體;② 每個網格生成B個檢測框,若檢測框包含物體,則認為此檢測框需要預測出此物體,并且還需負責框的回歸任務。訓練損失函數同Faster R-CNN類似。相對于Faster R-CNN,YOLO算法性能高,但缺陷也比較明顯,例如每當一個格子最多預測一個物體目標,且當出現不常見的長寬比時,YOLO網絡的泛化能力就會降低。
2.4 SSD目標檢測算法
SSD[13]算法作為三大目標檢測算法之一,擁有Faster R-CNN的高精確度以及YOLO的高性能。
SSD算法和YOLO算法架構如圖8所示,同Faster R-CNN和YOLO相比,它增加了多尺度特征屬性圖,而且用淺層網絡檢測小目標、用深層網絡檢測大目標,同時利用Faster R-CNN的anchor思想選取不同大小形狀的anchor框,增加對不同大小形狀物體的魯棒性。框回歸損失函數以及分類損失函數與Faster R-CNN一樣。
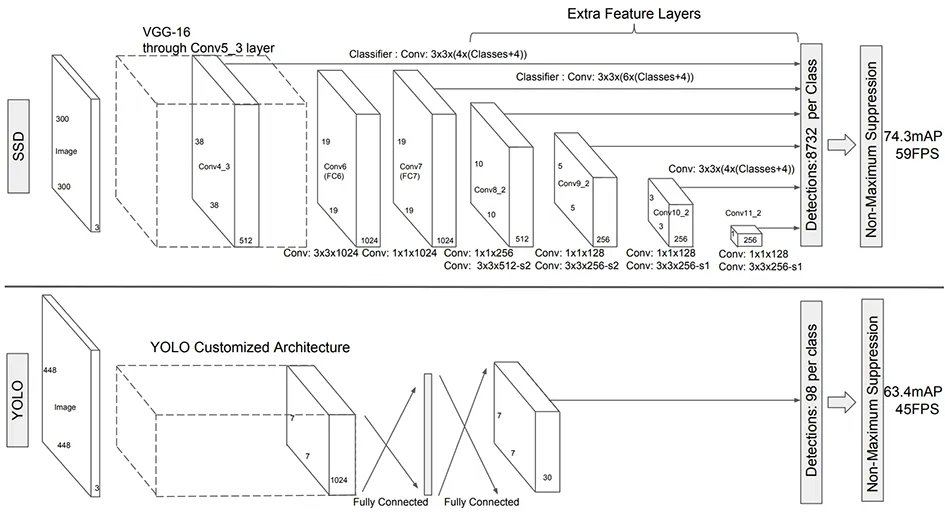
圖8 SSD算法以及YOLO算法架構
2.5 其他目標檢測算法
其他使用卷積網絡進行目標檢測的算法都是依據上述3種算法改進而來,例如以Faster R-CNN為代表的two stage和以SSD為代表的one stage方法。相比較而言,two stage有更高的精確度,one stage有更快的速度。取得階段性進展的有R-FCN,FPN,RetinaNet[14],Mask R-CNN,YOLO v3,RefineDet[15],M2Det[16]。主要介紹其中典型的3個算法:RetinaNet,RefineDet,M2Det。
造成one stage 和two stage效果區別的因素是什么呢?主要原因便是對anchor的處理方式。Two stage對anchor進行了篩選及微調,然后送進分類與回歸器中,而one stage直接將anchor送入分類器與回歸器中訓練,這種方式導致了anchor類別中的負樣本過多,使得訓練樣本不均衡。為解決這個問題,RetinaNet將原來的Focal Loss替換了原來的交叉熵誤差。Focal Loss的公式為:
FL(pt)=-αt(1-pt)γlg (pt),
(8)
可以看出,當某類別的數量越大,貢獻的Loss平均下來越小,反之則平均貢獻的Loss越大,這種做法降低了樣本數量對訓練損失的影響,使得量少類別對訓練的貢獻值提高。
RefineDet由2個內部連接模塊組成,分別為:ARM(Anchor Refinement Module)和ODM(Object Detection Module)。ARM網絡和Faster R-CNN中的RPN網絡類似,進行預預測,ODM如SSD中的anchor處理,使其具有二者的共同優點。
M2Det使用了主干網絡+MLFPN來提取圖像特征,采用類似SSD的方式獲取預測框以及類別,最后通過NMS得到最后的檢測結果。
其中,最關鍵的是進行圖像特征提取的結構MLFPN,其主要由3個部分組成:
① 特征融合模塊FFM;
② 細化U型模塊TUM;
③ 尺度特征聚合模塊SFAM。
由圖9 的M2Det網絡可以看出,FFMPv1對主干網絡提取到的淺層特征和深層特征進行融合,FFMv2通過融合不同深度特征圖,最終的SFAM通過拼接聚合不同類型的屬性圖,最終將包含廣泛信息的特征圖送入類似于SSD網絡中進行目標檢測以及分類。
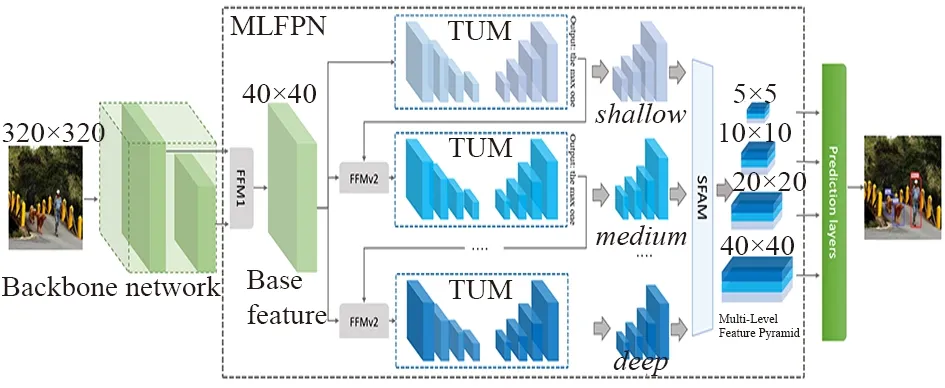
圖9 M2Det網絡
2.6 識別算法介紹
如圖10所示,利用卷積網絡進行識別可分為2個步驟:利用卷積網絡進行圖像特征提取,然后利用softmax進行分類。
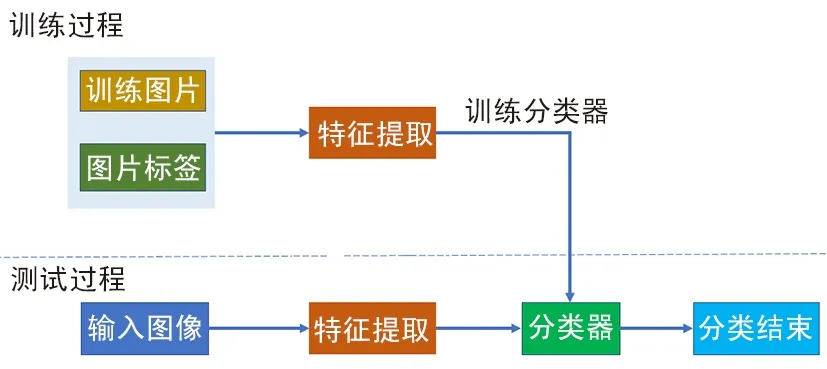
圖10 識別過程
常見的識別算法主要是特定場景下的識別,例如車牌識別和人臉識別。效果比較好的開源車牌識別算法,例如Openvino框架下的LPRNet[17]通過卷積網絡進行特征提取,并使用CTC LOSS損失函數訓練,算法正確率能夠達到95%左右。人臉識別一般通過卷積網絡進行特征提取,再通過比較歐氏距離或者矩陣余弦距離進行人臉識別,有名的例如以mxnet框架寫的開源的insightface。
3 算法優化
邊緣計算中首先需要對卷積網絡模型進行優化,以滿足卷積網絡運行于特定設備上具有的實時性。卷積網絡模型優化主要有5種方式:① 卷積核優化;② 參數修剪和共享;③ 知識蒸餾算法;④ 低秩因子分解;⑤ 輕量級網絡模型設計。
3.1 卷積核計算性能優化
卷積核優化算法中較新也較好的方式是shuffleNet[14]網絡中卷積核所使用的方式。為減少計算量,最直觀的方式是直接減少卷積層的計算量。常規卷積的卷積核通道數和輸入特征圖的通道數一致。如圖11所示,MobileNets深度可分離卷積操作為最經典MobileNets[19]的核優化方式,具體做法是將卷積分為深度卷積和逐點卷積,通過基于深度可分離卷積,將典型的卷積操作圖11(a)分解成深度卷積圖11 (b)和逐點卷積圖11 (c)。假設經典的卷積維度Dk*Dk*M,Dk為卷積核平面維度,M為輸入特征屬性通道數,N為輸出特征維度通道數。深度可分離卷積首先通過卷積核為Dk*Dk*1對特征圖平面特征方向過濾,如圖11(b)所示。再通過卷積核1*1*M對特征圖的通道方向進行過濾,如圖11(b)所示。二者可以認為是分別對平面維度和通道維度進行降維。
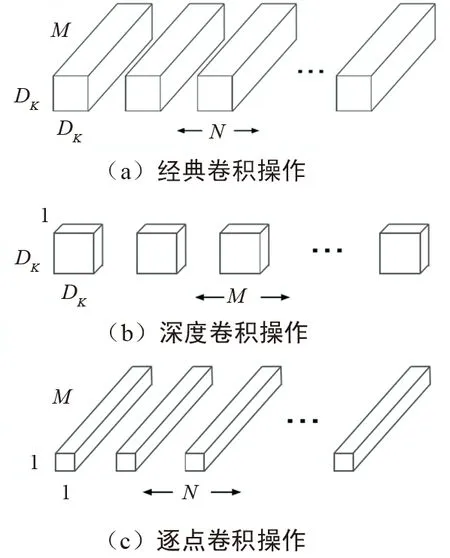
圖11 移動網絡深度可分離卷積操作
由于通道間信息不連通,這種方式會使通道間充滿約束。為了解決這種問題,Face++團隊提出了shuffleNet網絡。與MobileNet一樣,shuffle利用群卷積和深度可分卷積思想,優化了核卷積用以解決通道之間的約束。如圖12(a)組卷積所示,Shufflenet的方法將特征圖通道分組進行卷積,增強了通道內部的信息聯通。然而分組卷積僅解決了特征圖組內信息的流通,組外信息并不能流通,降低了信息的表達能力。當然可以將卷積后的特征圖在組內部切割,然后將切割后的部分按順序排序,如圖12(b)所示。而shuffle通過通道混洗操作使得數據的通道維度上進行無序打亂,用以增加信息的表達能力,提升識別效果,如圖12(c)所示。 組卷積通道混洗如圖13所示,在Shufflenet經典模塊圖13(b)中,特征圖首先通過組點卷積核操作,分組進行混洗操作,然后利用一般標準的組深度可分離卷積核進行過濾,將過濾后特征圖再通過組點卷積過濾。一般而言這種方式雖然能夠過濾掉沒用的信息,但同時也會過濾掉有用的信息。通過與輸入數據加和,以防止有用信息被過濾掉。
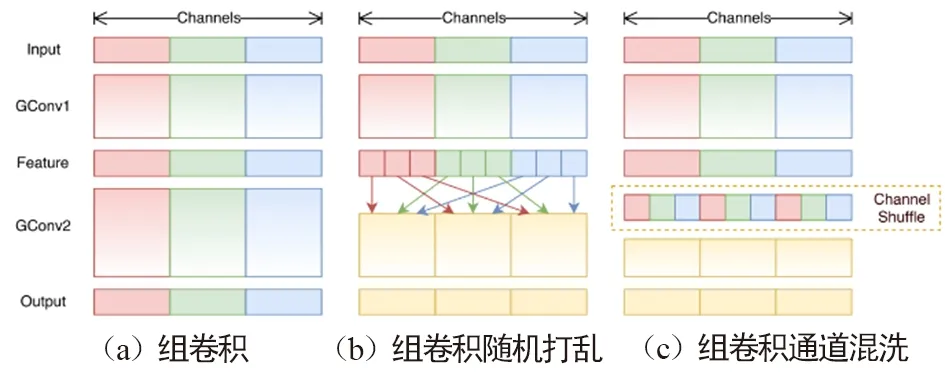
圖12 shuffle通道維度上的組卷積操作
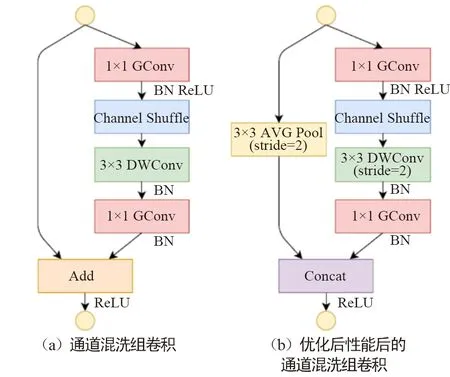
圖13 混洗模塊
為減少計算量,通過將組深度可分離卷積的滑動間隔stride由1修改成圖13(b)中的2,再利用平均赤化層下采樣輸入特征屬性,最終通過將得到的特征圖進行通道級聯,取代圖13(a)混洗模塊的特征圖求和。雖然通道級聯增加了通道的維度,但由于下采樣減少了平面維度,導致計算成本并未增加很多。通過實驗發現,此方式能夠顯著降低網絡所需的計算性能,而網絡的效果并沒有顯著降低。第二代ShuffleNet v2[20]網絡指出了以往架構過于注重FLOPs的不足,提出了2個基本原則和4項準則指導網絡架構設計,無論在速度還是精確度上,都超過以往通過壓縮卷積核計算要求的算法。
3.2 剪枝和參數共享
參數共享在卷積網絡上用于降低計算量和減少參數,最開始的剪枝應用便是dropout,它通過隨機剪枝防止過擬合并加速訓練,當然也可以用來降低參數量。
早期的剪枝方式通過權重的重要性剪枝方法進行分結構化剪枝[21],刪除不重要的權重參數重新進行訓練,直到達到滿意的模型大小,并且模型效果沒發生顯著改變。隨后提出的基于偏差權重衰減的最優腦損傷和最優腦手術方法,是通過減少損失函數的海森矩陣來減少連接數量。研究表明剪枝方式的精確度比重要性剪枝方式好。然而此方式的剪枝并不能應用于實際卷積網絡層上,因為此類方法導致剪枝后的權值矩陣是無規則稀疏的,其僅僅將剪枝后的權重設置成0,輸入和0相乘消耗計算量,因此實際加速效果較低。只有剪掉的枝葉從搭建的網絡中消失,才算完成剪枝。通過結構化剪枝可以使剪枝后的模型運行于實際場景中。與非結構化剪枝不同的是,結構化剪枝設置了一系列的剪枝約束條件。根據細粒度的程度,結構化剪枝可以分為向量機剪枝、核級剪枝、組級剪枝和通道級剪枝4種類型。結構化剪枝能夠直接降低模型的計算FLOPS。
3.3 知識蒸餾
正如Hinto提出來的一個例子[22],幼小的昆蟲擅長從環境中汲取能量,而成年后則擅長遷徙繁殖等方面。與這個例子相同的是,在訓練階段,神經網絡能夠從大量數據中訓練模型網絡;使用階段,則能夠應用于更加嚴格的包括計算資源及計算速度的限制。一般首先在大數據集上訓練一個復雜網絡模型,一旦網絡模型訓練完成,便可以通過“蒸餾”方式,從大型模型中將所需要的應用模型提取出來。知識蒸餾中,軟目標是通過復雜模型預測得到的概率分布,硬目標則是真實樣本的概率。參考復雜模型的結構、深度等信息重新設計一個小模型,再將小模型的預測值分別與軟目標和硬目標做交叉熵的損失,并將兩部分損失進行聯合訓練。軟目標與硬目標的綜合訓練損失所占的比重不斷地由9:1通過迭代訓練慢慢變成1:0。對于卷積網絡,一般通過類別的shot-hot碼進行訓練,相當于使用硬目標進行訓練。總而言之,將復雜模型預測得到的數據作為小模型的樣本標簽,對網絡加以訓練,以增加網絡的泛化能力。
3.4 權值張量低秩分解
卷積網絡核的參數權重W可以看作一個四維張量,他們分別對應卷積核的長、寬、通道數以及輸出通道數。通過合并某些維度,四維張量能夠轉變成更小維度的張量。基于權值張量低秩分解方法,其實質是找到與張量W近似、但計算量更小的張量。現階段已經有很多低秩分解算法被提出,例如優必選悉尼AI研究院入選CVPR的基于低秩稀疏分解的深度壓縮模型。
3.5 輕量級網絡模型設計
在卷積網絡模型中,合并網絡層不改變網絡輸出是重要模型的優化方式。例如,BatchNorm層(簡稱BN層)在深度學習中歸一化網絡模型加速訓練,放置于卷積層或全連接層之后。測試時,通過將BN層合并到卷積層或全連接層中以減少計算量。
假設BN層輸入數據為X,則BN層處理數據獲得輸出為:
(9)
卷積操作的權重為w,偏置為b,假設卷積網絡輸入為X,卷積網絡的輸出為Yconv,則卷積網絡操作為:
Yconv=WX+b。
(10)
由式(9)和式(10)可知,通過卷積、池化操作后結果為:
(11)
因此卷積層更新后的權重W*以及偏置b*可以得出:
(12)
(13)
4 邊緣計算硬件發展歷程
對于邊緣計算,成本及性能是重要的考量因素。一直以來,并行計算兩大廠商之一的英偉達非常重視并行計算在數學上的應用,不但開發出了CUDA庫用于并行計算,還開發出了CUDNN庫等各種矩陣運算庫用以優化運算性能,僅需要學會簡單的C++便能方便地調用顯卡加速運算。各種深度學習框架如Caffe,Tensorflow等對nvidia的cuda支持,使其移植到嵌入式設備的成本極低,這些因素都使得英偉達旗下顯卡占有重要的市場Nvidia硬件對比如表1所示,給出了嵌入式產品端的主要參數。理論上核心越多,并行計算能力越強,從表1中可以看出,Tx1的并行計算能力是Nano的2倍,而使用新架構Pascal的Tx2性能是Tx1的2倍,另一款產品Jetson Xavier則能夠提供超過Jetson Tx2的20倍以上性能,但昂貴的價格使不能被大規模部署。
表1 Nvidia硬件對比
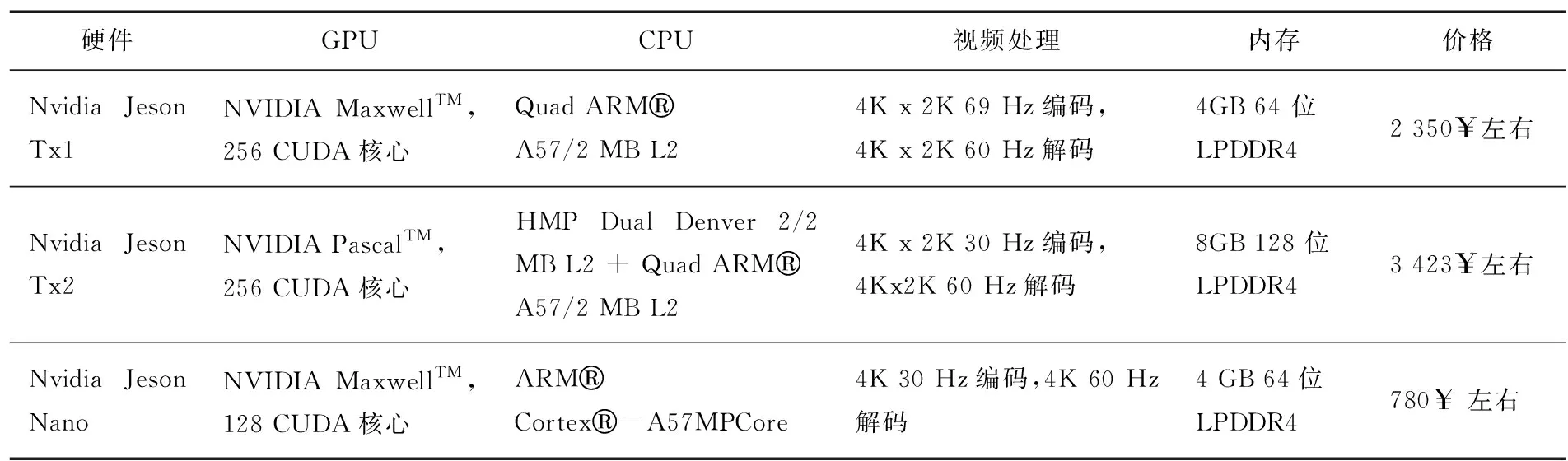
硬件GPUCPU視頻處理內存價格Nvidia Jeson Tx1NVIDIA MaxwellTM,256 CUDA核心Quad ARMA57/2 MB L24K x 2K 69 Hz編碼,4K x 2K 60 Hz解碼4GB 64 位LPDDR42 350$左右Nvidia Jeson Tx2NVIDIA PascalTM,256 CUDA核心HMP Dual Denver 2/2 MB L2 + Quad ARMA57/2 MB L24K x 2K 30 Hz編碼,4Kx2K 60 Hz解碼8GB 128 位LPDDR43 423$左右Nvidia Jeson NanoNVIDIA MaxwellTM,128 CUDA核心ARMCortex-A57MPCore4K 30 Hz編碼,4K 60 Hz解碼4 GB 64位LPDDR4780$ 左右
英特爾也于2016年收購了一家硅谷公司Movdius,該公司主要為各種消費設備設計神經網絡加速芯片,其開發產品中的神經網絡計算棒使用的是Movidius芯片,可以通過openvino調用Movidius芯片進行加速計算,但其安裝包目前為止支持樹莓派的armv7架構以及x86架構。在收購另一家公司Nervana后,英特爾將很快推出專為人工智能打造的系列處理器—英特爾神經網絡處理器(以前稱為“Lake Crest”)。
AI視覺套件角蜂鳥是基于英特爾神經網絡的Movidiu芯片開發的,它多提供一個攝像頭。研揚科技開發的UP系列單板,可以看作是一個能夠運行x86架構桌面平臺的嵌入式產品,它只有信用卡大小,能夠支持神經網絡計算棒以及研揚和英特爾聯合推出的AI Core作為并行加速計算擴展,雖然UP單板有x86平臺的高性能優點,但其價格也比較昂貴。
谷歌作為深度學習領域一個重要的公司,不僅維護深度學習開源框架(Tensorow),還推出了硬件加速平臺 Edge TPU,其設計目標就是簡單流暢運行TensorFlow Lite。處理器使用的 Cortex-A53/Cortex M4F,GPU為GC7000Lite,內置了Google Edge TPU加速Tensorow運算。另一款專為樹莓派設計的AIY Edge TPU Accelerator 則僅需利用USB-C/USB-B與Linux系統連接,即可加速tensorflow-lite運算。此外,華為的HiKey 970,可提供強大AI算力,支持硬件加速,性能強勁。寒武紀的Cambricon-1A,Cambricon-1H8,Cambricon-1H16系列可廣泛應用于計算機視覺、語音識別及自然語言處理等智能處理關鍵領域。
其他推出的比較小眾的產品,例如LightspeeurTM光矛系列是全球首款可同時支持圖像和視頻、語音與自然語言處理的智能神經網絡專用處理器芯片方案,相比邊緣計算硬件市場上其他解決方案,能夠高出幾個數量級。例如其產品LaceliTM人工智能計算棒可以在1 W功率下提供超過9.3萬億次/s的浮點運算性能,而Movidius每瓦功率范圍運算能力則是0.1萬億次。恩智浦BlueBox是一款開發平臺,可為開發自動駕駛汽車的工程師提供必要性能、功能安全和可靠性平臺,并且配備雷達、激光探測與檢測(LIDAR)等自動駕駛必須的模塊。中星微的“星光智能一號”是中國首款嵌入式神經網絡處理器(NPU)芯片。Deepwave公司推出的AIR-T(Artificial Intelligence Radio Transceiver)具有嵌入式高性能計算功能。深鑒科技于2018年上市的“聽濤系列列SoC”,只需1.1 W功耗,卻能達到4.1TOPs峰值性能。性價比是小眾平臺產品的最佳優勢。
5 結束語
Faster R-CNN,SSD,YOLO等目標檢測算法優缺點分明,通過研究其原理,發現設計網絡模型及損失函數是提升AI性能和效果的重要方式。然而,高昂的計算代價會阻礙AI算法在邊緣計算硬件上的部署,因此模型優化精簡和移植將是AI商業化的必經之路。隨著硅芯片的發展使得AI算法部署成為可能,邊緣計算將解決人工智能的最后一公里,構建萬物感知、萬物互聯、萬物智能的嶄新世界。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
