基于M估計的改進Pauta準則在監測數據粗差識別中的研究及應用
2019-08-31 01:45:54李艷玲
中國農村水利水電 2019年8期
李 興,李艷玲,張 鵬,楊 哲
(1. 四川大學 水力學與山區河流開發保護國家重點實驗室 水利水電學院,成都 610065;2. 中國市政工程西南設計研究總院有限公司 第一設計研究院,成都 610081)
0 引 言
進入21世紀以來,隨著監測技術、計算機技術和通訊網絡技術的不斷發展,測點個數與觀測頻次隨之增多,監測數據量增長明顯[1],序列類型也較為豐富。精確識別監測序列中的異常數據是科學準確分析評價大壩安全狀況和運行性態的前提和保障,而針對目前多類型的數據序列,雖然統計學方法[2,3]、小波分析[4],四分點法[5]和抗差最小二乘法[6]等逐漸應用在粗差識別中,但依然存在適用性低、漏判和誤判等問題。經典的統計判別法Pauta準則由于其使用簡便而被廣泛應用[7],但對監測序列中含有較多離群數據如多點離群、臺階型、震蕩型數據極易出現異常值漏判的問題。李麗敏[8]等基于Pauta準則采用自學習和平滑處理檢測異常數據;毛亞純[9]和趙鍵[10]等學者在Pauta準則的基礎上提出數據跳躍法,但這些方法對含有較多離群點數據的適用性較低。為此,本文針對大壩安全監測數據粗差識別的Pauta準則存在的異常值漏判的問題,引入穩健M估計,以位置M估計量和基于位置M估計量的尺度估計量代替均值和標準差重新構造控制函數進行粗差識別。將改進Pauta準則應用于耿達水電站不同類型的測點序列,通過對比原始序列、人工剔除離群點序列和基于M估計量的參數估計與粗差識別結果探究了Pauta準則改進的可行性和合理性;并分析對比存在離群點序列和正常序列探究了改進Pauta準則的適用性。
1 基于M估計量的Pauta準則改進方法
采用Pauta準則識別粗差的前提條件是測值序列服從正態分布N(μ,σ2),且樣本數據量較大[11],其控制函數如式(1)所示:
μ(Xi,n)-3σ(Xi,μ,n)≤Xi≤μ(Xi,n)+3σ(Xi,μ,n)
(1)
式中:Xi為實測值;μ為數據序列均值;σ為標準差;n為觀測值個數。
大壩安全監測數據一般樣本量較大,但通常會由于監測儀器故障、外界環境因素擾動而導致監測序列中存在離群點,從而偏離Pauta準則關于正態分布的假定,出現異常值漏判問題。本文引入M估計量改進總體位置參數和總體尺度參數以代替傳統的均值μ和標準差σ,從而提高Pauta準則的耐抗性和穩定性。
1.1 總體參數改進
(1)總體位置參數改進。M估計量是一種加權均值,其權重依賴于數據,可充分利用監測數據序列的有效信息,基于權重函數ω的加權均值Tn為[12]:
(2)
MAD=mediani{|xi-M|}
(3)
式中:xi為樣本序列觀測量;n為序列樣本個數;c為細調常數;M為樣本序列中位數;median(·)函數返回給定序列的中位數;Sn是輔助尺度估計,通常取中位數離差MAD,即各個觀測量到中位數M的距離的中位數。
(2)總體尺度參數改進。標準差是數據序列最常用的尺度估計量,但由于標準差的運算需要均值 ,對樣本中的離群點同樣缺乏耐抗性與穩健性[13]。因此基于以上M估計量有尺度估計[14]:
(4)
式中:ψ函數為目標函數的導函數;ψ′函數為ψ函數的導函數。
(3)M估計函數選取。Huber(1972)、Andrews(1972)、Hampel(1974)和Tukey(1977)等人均提出了不同的目標函數形式[15],本文在對比不同權函數形式的基礎上引入Tukey雙權估計量,其目標函數ρ(u)、ψ函數ψ(u)、ψ′函數ψ′(u)和權重函數ω(u)如圖1所示。
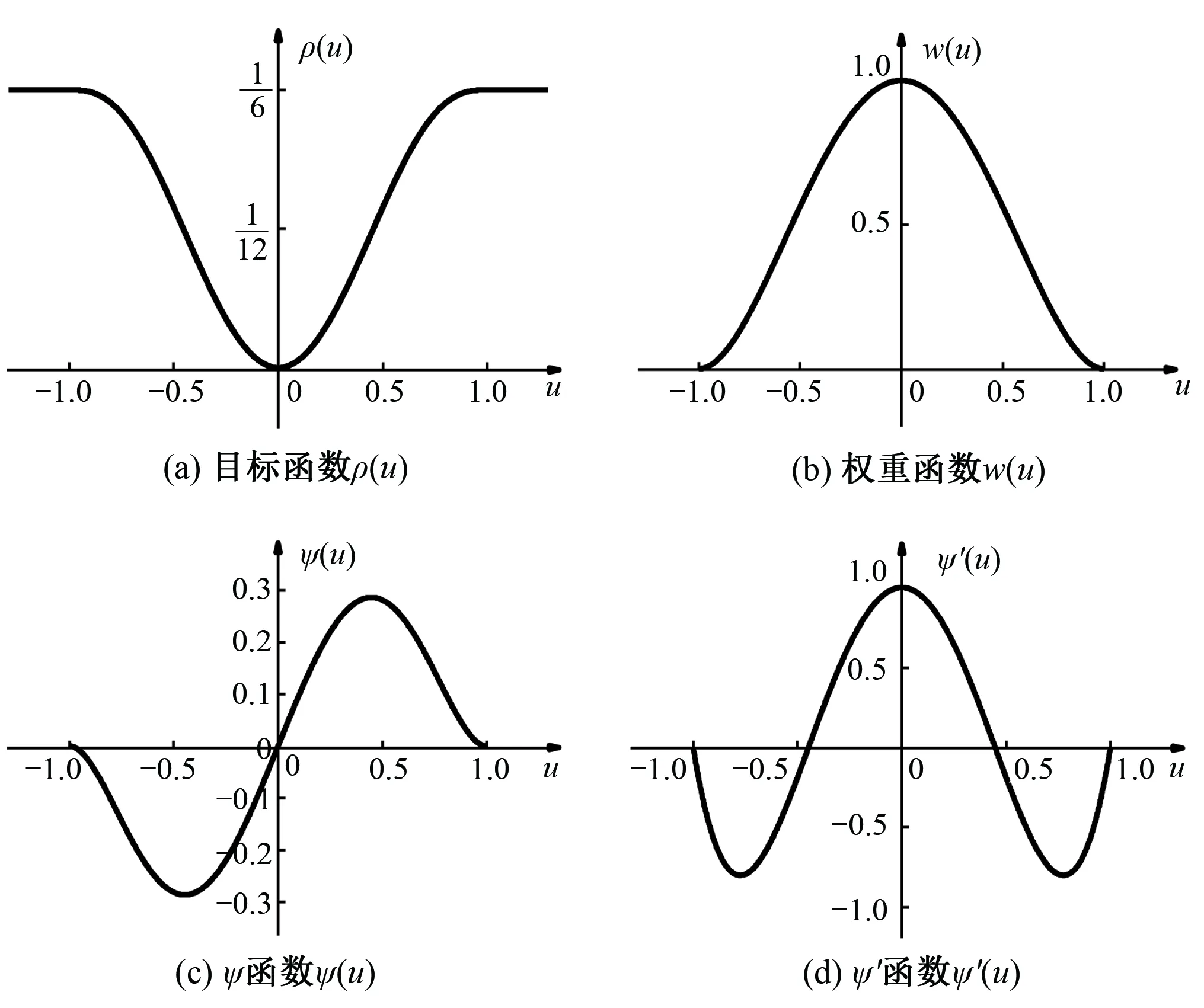
圖1 Tukey雙權 M 估計量函數圖Fig.1 Function diagrams of Tukey Tukey Bisquare
1.2 控制函數改進
由魯棒性更好的位置M估計量Tn和基于位置M估計量的尺度估計量ST代替均值μ和標準差σ重新構造控制函數,則式(1)可以改寫為:
Tn-3ST≤Xi≤Tn+3ST
(5)
因此,基于M估計量的Pauta準則可計算得到實測值的控制上下限“T±3ST”,當實測值Xi在控制范圍以內,則判斷其為正常值;否則為異常值。
2 工程應用
耿達水電站位于岷江上游右岸支流漁子溪上,主要建筑物由攔河閘、非溢流壩、沉沙池等水工建筑物組成,其監測項目主要包括環境量監測、大壩變形監測、壩基揚壓力監測、繞壩滲流監測等。監測數據離群類型主要可以分為單點及多點離群型數據、臺階型數據和震蕩型數據,因此本文選取典型“多點離群型”測點L14(水平位移)、“臺階型”測點GL09(垂直位移)、“震蕩型”測點UP05(揚壓力)和“正常序列”測點EX14(水平位移)為例進行分析,各測點序列基本特性如表1所示。
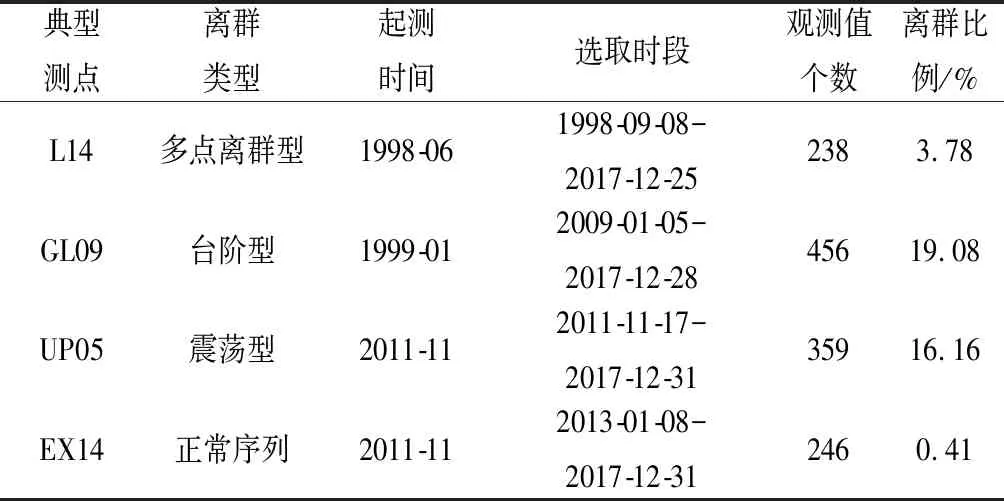
表1 典型測點序列特性Tab.1 Characteristics of typical measuring point sequences
2.1 總體參數改進效果
(1)總體位置參數改進效果。分別計算測點L14、測點GL09、測點UP05原始數據序列的均值、人工剔除離群點序列均值和位置M估計量,如表2示。可以看出含離群點序列的Tukey雙權估計量非常接近于人工剔除離群點序列的均值,而原始序列均值與剔除離群點序列的均值相差較遠;對比測點EX14數據序列的均值和M估計量計算結果發現,兩種位置參數估計值相差不大。因此,可以明顯看出基于殘差平方和的目標函數計算的均值對離群點非常敏感, M估計量的抗擾動性明顯優于均值。
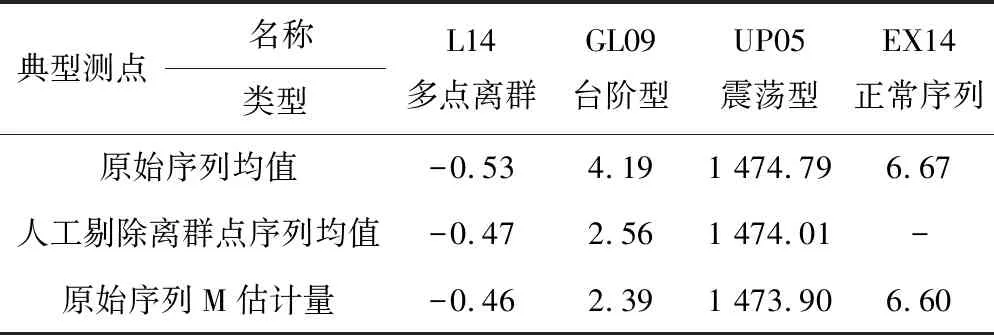
表2 典型測點M估計量與均值對比表Tab.2 Comparison of M-estimator and mean of typical measuring points
(2)總體尺度參數改進效果。再分別計算上述各典型測點原始數據序列的標準差、基于位置M估計量的尺度估計量,并將其與剔除離群點后計算的標準差進行對比,如表3示。可以看出,含離群點序列的基于位置M估計量的尺度估計量計算結果非常接近于人工剔除離群點序列的標準差,而保留離群點的原始序列計算的標準差偏差較大;對比測點EX14的標準差和基于位置M估計量的尺度估計量發現,兩種尺度估計的計算結果幾乎一致。因此,基于位置M估計量的尺度估計量的抗擾動性明顯優于標準差。
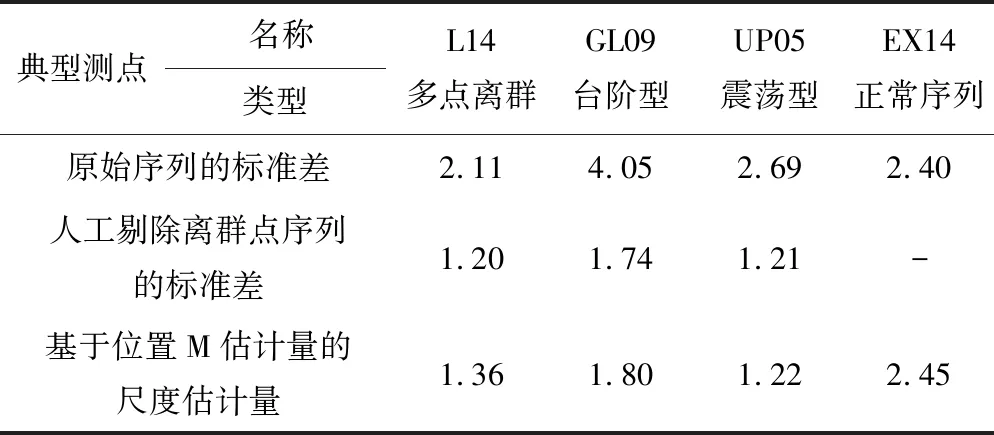
表3 典型測點基于位置M估計量的尺度估計量與標準差對比表Tab.3 Comparison of the scale estimator based on location M-estimation and standard deviation of typical measuring points
綜上,M估計量和基于位置M估計量根據樣本距離中心程度的遠近賦予不同的權重而具有較強抵抗離群點的能力,可得到正常模式下的最佳估計值;并且當無離群點時兩種方法的參數估計結果一致。
2.2 粗差識別效果
由改進的Pauta準則計算上述典型測點的控制限,并將其與傳統的Pauta準則控制限進行對比,進行粗差識別,各測點實測值和控制限過程線如圖2-圖5所示。
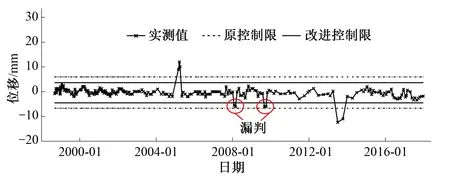
圖2 測點L14實測值及控制限過程線(多點離群型)Fig.2 Actual values and control limits of measuring point L14 (Multipoint-outliers type)

圖3 測點GL09實測值及控制限過程線(臺階型)Fig.3 Actual values and control limits of measuring point GL09 (Step type)
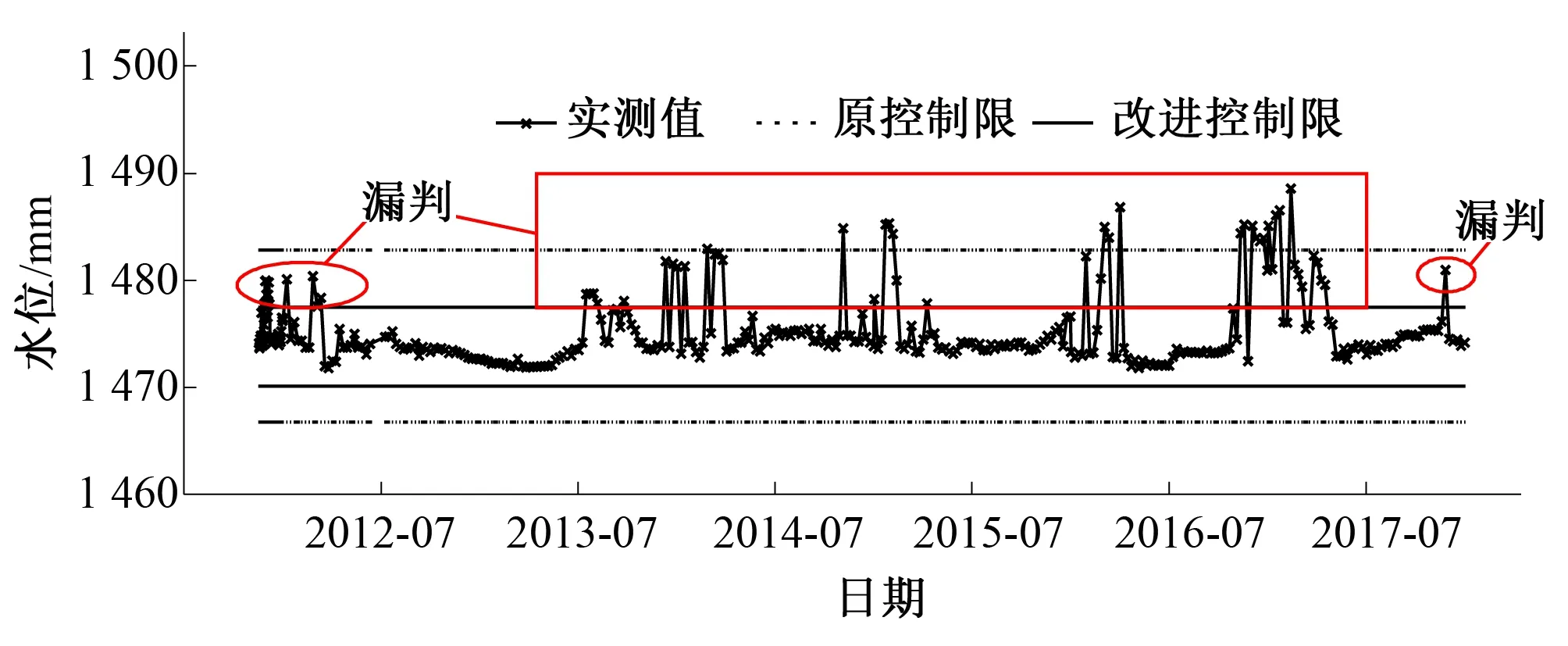
圖4 測點UP05實測值及控制限過程線(震蕩型)Fig.4 Actual values and control limits of measuring point UP05 (Oscillatory type)
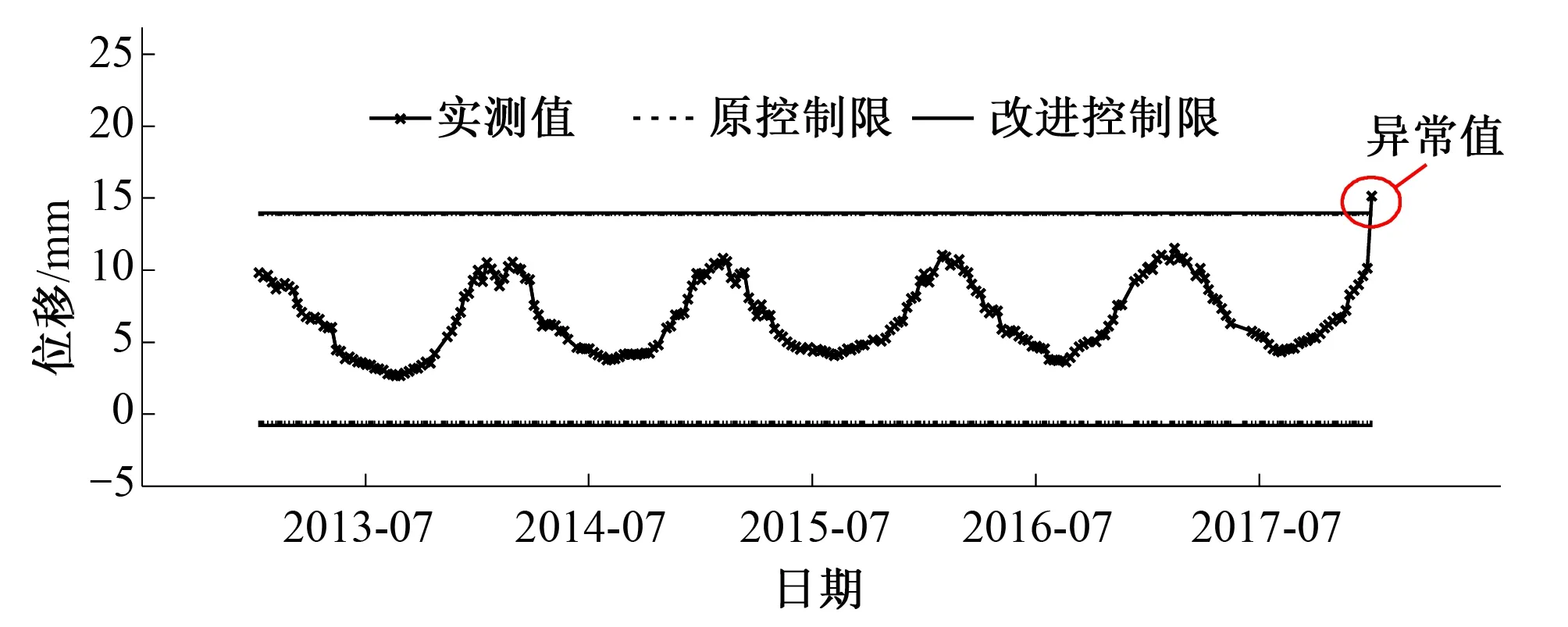
圖5 測點EX14實測值及控制限過程線(正常序列)Fig.5 Actual values and control limits of measuring point EX14 (Normal sequence)
當監測數據無可避免地存在較多離群點時,監測序列將不再符合Pauta準則關于正態分布的假定,均值和標準差不再反映數據序列特性規律,由此計算的控制限“μ±3σ”將會被拉向離群點而變寬,使得傳統Pauta準則出現異常數據漏判的問題,如測點L14在2009年10月6日出現的測值-5.90,測點GL09在2017年12月31日出現的測值11.41以及測點UP05在2017年11月26日出現的測值1 480.97采用傳統Pauta準則時均未被識別為異常突變,而采用改進的Pauta準則則消減了離群點的不利影響,有效解決了傳統方法的漏判問題,粗差識別精度大大提高,計算結果如表4示。
對于正常測值序列,兩種準則的控制限差別不大,識別效果一致。如正常序列測點EX14在2017年12月31日出現的異常突變值15.15,傳統Pauta準則與改進準則均識別為異常測值,如圖5和表4示。因此,改進的Pauta準則可同時適用于服從正態分布和含有較多離群數據而偏離正態分布的數據序列,適用性較強。

表4 傳統Pauta準則與改進Pauta準則粗差識別效果對比表Tab.4 Comparison of gross error identification effect of traditional and improved Pauta criterion
3 結 論
本文針對大壩安全監測數據粗差識別中常用的Pauta準則進行了較為深入的研究,通過對傳統方法的改進,為識別監測數據中的異常數據提供了一種高效合理的方法,并將其運用于耿達水電站,得到的結論如下:
(1)針對傳統Pauta準則粗差識別中的異常值漏判問題,引入穩健M估計構造了新的控制函數,位置M估計量和基于位置M估計量的尺度估計量消除了離群點對均值和標準差計算的不利影響,控制限的設置更加合理。
(2)通過對比分析耿達水電站不同離群類型的典型測點原始序列、剔除離群點序列、原始序列基于M估計量以及離群序列和正常序列的總體參數計算結果發現,當實際監測數據含有較多離群點時基于M估計的參數估計不會嚴重偏離真實水平;當實際監測數據無離群點時,基于M估計的參數估計與傳統方法基本一致。
(3)通過對比分析耿達水電站不同類型的典型測點采用傳統Pauta準則和改進準則的識別效果發現,實際監測數據偏離正態分布時改進Pauta準則可以有效減少異常值漏判問題;當實際監測數據服從正態分布時,兩種方法識別效果一致。
□
