基于膠囊神經網絡的交通標志識別算法研究*
2020-12-25 03:28:50任條娟陳鵬陳友榮江俊游靜
汽車技術 2020年12期
任條娟 陳鵬 陳友榮 江俊 游靜
(1.常州大學,常州 213164;2.浙江樹人大學,杭州 310015)
主題詞:感興趣區域 卷積神經網絡 膠囊神經網絡 空間信息 動態路由 交通標志
1 前言
目前,車輛大多通過數字地圖獲得交通標志信息[1],但只限于有地圖數據的道路,因此基于人工智能和機器視覺的道路交通標志識別系統擁有大量的需求。
交通標志識別的本質是圖像的多分類問題,部分學者側重于利用機器視覺領域的特征提取以及分類器等方法實現交通標志圖像的識別分類,如:文獻[2]~文獻[4]分別使用圖像分塊的方向梯度特征和內部局部二值模式特征進行特征融合,提取圖像方向梯度特征,提取交通標志邊緣顏色、形狀和文字等圖像特征,最后使用支持向量機(Support Vector Machine,SVM)進行識別;文獻[5]在最大穩定極值區域(Maximally Stable Extremal Regions,MSER)的基礎上,增加對黃色圖像的處理,通過卷積神經網絡(Convolutional Neural Network,CNN)進行定位;文獻[6]利用距離邊界向量的方式進行檢測定位,提高其在弱光照條件下的圖像查全率;文獻[7]提出了一種基于嶺回歸和大津算法的檢測和識別交通標志方法,使用HSV(Hue Saturation Value)進行閾值分割,提取感興趣區域(Region of Interest,ROI),并用大津算法提取徑向直方圖特征,使用多層感知器實現分類。文獻[2]~文獻[7]需要人工設計先驗知識的特征,且特征提取較為復雜,需花費大量的人力和時間。部分學者側重于研究適用于交通標志識別的CNN等深度學習算法。深度學習算法無需人工構造任何圖像特征,直接提取整張圖像像素作為網絡輸入,如:文獻[8]~文獻[9]分別使用圖像聚類和圖像ROI 對圖像進行預處理,并使用CNN訓練和識別交通標志圖像;文獻[10]提出了一種基于加權多CNN的交通標志識別算法,即訓練每個CNN,采用加權分類器優化分類結構,從而提高交通標志識別能力;文獻[8]~文獻[10]均使用CNN 對交通標志圖像進行訓練和識別,部分學者還使用了LeNet-5[11]、AlexNet[12]、GoogLeNet[13]等網絡模型,但由于池化層的存在,在提取圖像底層特征的過程中會導致空間特征信息的丟失、網絡訓練數據集需求量大、算法計算量較大等問題。
綜上,雖然交通標志識別算法研究已取得較大進展,但在構建訓練數據集時需要考慮旋轉、翻轉、平移等變化的圖像,增加了算法的整體計算量。因此,本文針對傳統網絡由于池化層丟失圖像空間位置、角度等重要信息導致算法計算量大的問題,提出了基于膠囊神經網絡的交通標志識別算法,減小圖像提取特征的區域,提高模型的訓練和識別速度。
2 交通標志圖像識別原理與算法實現
圖1所示為交通標志圖像識別流程。識別訓練時,在主膠囊層中將張量的底層圖像特征轉化為向量圖像特征后,將圖像特征向量封裝成膠囊(Capsule)單元,對這些單元進行動態路由聚類獲取分類概率向量,其模長即某個類別的概率,之后經過反向傳播更新膠囊單元內的權重參數,最后固定網絡內膠囊單元權重參數,實現網絡模型訓練。在圖像識別時,主膠囊層張量向量轉換后,通過訓練好的權重參數和網絡動態路由聚類,輸出交通標志分類的結果。
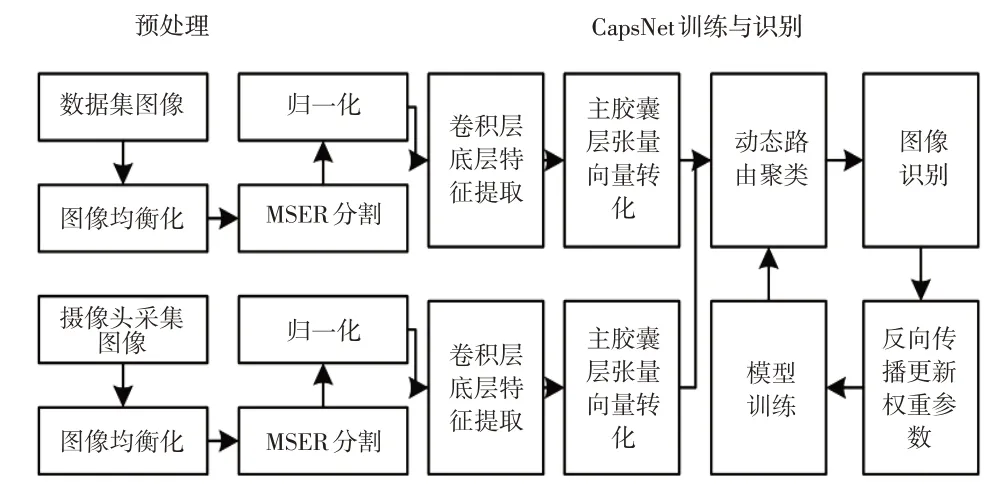
圖1 交通標志圖像識別流程
但仍需解決2 個問題:如何對輸入圖像進行預處理,獲得適用于CapsNet 網絡輸入的交通標志圖像;如何訓練和應用適用于交通標志識別的CapsNet 網絡模型,解決平移、翻轉和角度變化后同一交通標志圖像的識別問題。
2.1 交通標志采集
車載攝像頭采集自然場景下同一道路不同時刻、不同角度的警示、禁止和指示3種類型交通標志圖像。
2.2 圖像預處理
對交通標志圖像進行神經網絡識別前,需要對其進行預處理,提取擁有豐富特征信息的ROI,從而縮小圖像識別范圍,降低算法計算量,提高識別速度。
2.2.1 圖像均衡化
相較于背景區域,交通標志圖像具有較強的反光性和凸顯性。同時,受天氣、光照等自然環境因素的影響,在圖像處理時需對其亮度進行均衡化,以消除自然環境對圖像造成的干擾,增強圖像特征信息。均衡化流程如圖2所示,其中,亮度分量的直方化處理過程為:

式中,Sn為處理后的亮度分量值;Xi為亮度分量值為i的像素數量;N為像素數量總和。

圖2 圖像均衡化過程
2.2.2 MSER分割
交通標志圖像經過均衡化處理后,對其進行灰度化和二值化。由于MSER算法具有良好的仿射不變性、穩定性和簡單高效的特點,本文基于MSER算法提取交通標志圖像的ROI。該算法的基本思想如下:選取閾值t={0,1,2,…,255}對圖像進行二值分割,低于閾值的像素置為黑色(0),高于或等于閾值的像素置為白色(255)。在閾值t從0增大到255的過程中,圖像形成閉合區域,尋找圖像像素區域變化最小的區域,即為MSER穩定區域。然后,根據交通標志本身的幾何特征,篩選潛在區域,最后利用式(2)計算灰度圖像中灰度值的標準差σ,得到標志所在區域,并分割出圖像的ROI:
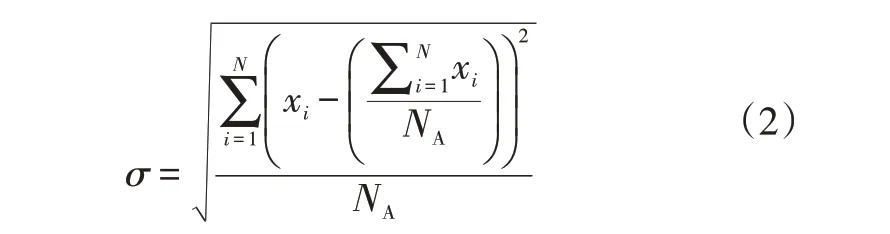
式中,xi為第i個灰度值;NA為周圍區域灰度值總數量。
MSER算法的具體實現步驟如下:
a.將交通標志圖像每列灰度值從大到小排序。
b.將排序后的灰度值放入與原圖像尺寸大小相同的矩陣中,使用并查集(UnionFind)算法判斷排序后的每列灰度值點之間是否存在鏈接。如果存在鏈接,輸出灰度值點,并將其排在相鄰位置的矩陣內,令t=0。
c.選取二值化閾值(t-Δ)、t和(t+Δ),其中Δ為閾值的變化量,分別選擇灰度值為該閾值的像素點組成的多個區域,計算這些區域的面積,計算第i個區域的變化率
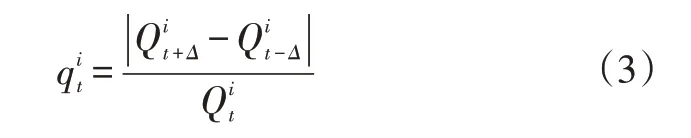
d.令t自加1,如果t<256,則跳轉到步驟c,否則變化率的計算完成。選擇具有最小變化率的區域為最大穩定極值區域Rt。
e.計算區域Rt的縱橫比R,計算區域與其外接矩形的面積比A,如果二者同時滿足式(4)、式(5),跳轉到步驟f,否則跳轉到步驟a,讀取下一張圖像:
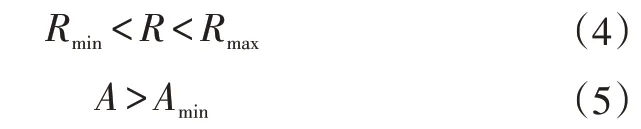
式中,Rmin、Rmax分別為縱橫比的最小值、最大值;Amin為面積比的最小值。
f.令篩選出的最大穩定極值區域的灰度值為255,其他區域灰度值為0。利用式(2)計算圖像每一個灰度值與周圍區域灰度值的標準差,將標準差最大的灰度值點作為交通標志圖像ROI邊界的灰度值點,連接這些灰度值點組成圖像區域,獲得區域的圖像坐標。分割該坐標內所有像素點,得到交通標志圖像ROI。
2.2.3 歸一化
利用最鄰近插值法將ROI圖像規格化,獲得固定大小(32×32)的圖像。
2.3 CapsNet訓練和識別
2.3.1 CapsNet網絡結構
如圖3所示,CapsNet網絡由5個部分組成。第1層為輸入層,輸入實際圖像數據。第2 層為標準卷積層Conv1,提取ROI 圖像(32×32),通過卷積提取交通標志各部分特征。第3 層為CapsNet 網絡主膠囊層,對上層輸入的特征進行不同卷積,生成1個向量作為膠囊單元,傳入數字膠囊層。第4層為數字膠囊層,通過動態路由協議進行聚類傳播與更新權重矩陣,輸出概率向量。第5層為輸出層,計算概率向量模長,輸出分類概率。
2.3.2 卷積層底層特征
卷積層具有256個大小為9×9的卷積核,其深度和步幅均為1,運用非線性激活函數提升卷積層的運算能力。卷積層提取交通標志圖像底層各部分特征,輸出24×24×256的張量。
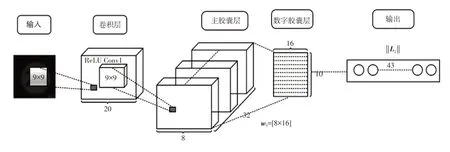
圖3 CapsNet網絡基本結構
2.3.3 主膠囊層張量向量化
主膠囊層接收卷積層提取的交通標志圖像底層特征張量,構建可作為底層特征的多維度的向量,并將該向量作為數字膠囊層輸入的底層膠囊單元。即主膠囊層通過8×32個大小為9×9和步長為2的卷積核,進行32次通道數量為8 的不同卷積,生成8 個6×6×8×32 的張量。將這8 個張量合并成6×6×8×32 的向量,即為主膠囊層輸出的底層膠囊單元。
2.3.4 動態路由聚類
數字膠囊層在主膠囊層輸出向量單元的基礎上,進行傳播與路由聚類。數字膠囊層輸入的膠囊單元表示圖像內包含的實例化參數,使用如圖4所示的動態路由算法預測更高層的膠囊單元。通過使用權重矩陣控制底層膠囊單元與高層膠囊單元間的連接緊密程度,并判斷膠囊單元間方向的一致程度,更新權重矩陣。循環執行上述操作進行動態路由聚類,獲得耦合系數。
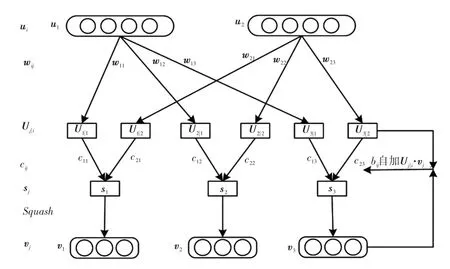
圖4 動態路由的層級結構
動態路由算法的步驟為:
a.輸入低層膠囊單元的膠囊單元和連接權重矩陣,計算所有的預測向量:
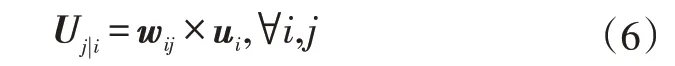
式中,ui為低層膠囊單元的第i個膠囊單元;wij為第i個膠囊單元與第j個預測膠囊單元的連接權重矩陣;Uj|i為預測膠囊單元。
并令當前膠囊所在的層序號為L,且L=0,令路由迭代次數為R,令當前循環次數r=1。
b.令bij為第L層第i個膠囊單元連接第(L+1)層第j個膠囊單元的一致性參數,令初始值均為0。
c.如果當前循環次數小于R,則跳到步驟d,否則跳到步驟h。
d.計算每一個膠囊單元的耦合系數cij:
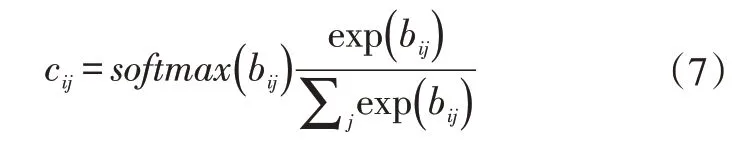
e.計算第(L+1)層中的所有膠囊單元的加權和:
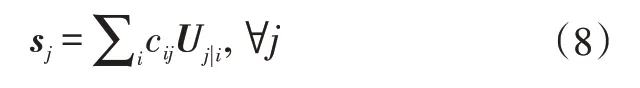
式中,sj為第j個膠囊單元的加權和。
f.采用Squash 壓縮激活函數壓縮加權和sj,獲得第(L+1)層的所有膠囊單元:
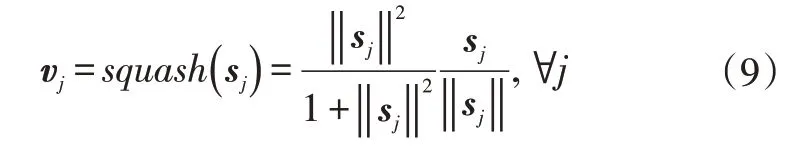
式中,vj為第(L+1)層的第j個膠囊單元。
g.根據第L層的所有預測向量Uj|i與第(L+1)層的所有膠囊單元vj的連接關系,參數bij增加Uj|ivj,r自加1,并跳轉到步驟c。
h.輸出固定動態路由過程中使用的耦合系數cij和連接一致性參數bij,輸出高層膠囊單元vj。
2.3.5 反向傳播和模型訓練
獲取數字膠囊層輸出的膠囊單元向量,根據向量長度判定其屬于某個類別的概率。同時,需構建損失函數:
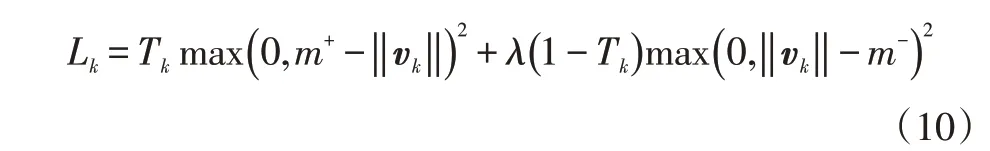
式中,k為分類類別;Tk為分類的指示函數,如不屬于類別k,Tk=1,否則Tk=0;vk為動態路由聚類為類別k的向量單元;m+、m-分別為上、下邊界;λ為權重降低損失值。
在反向傳播算法中更新權重矩陣:
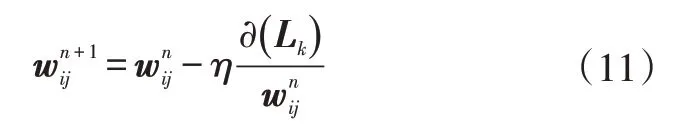
式中,為更新后的權重矩陣;η為學習率,即梯度。
同時,在訓練過程中使L自加1,從低層膠囊單元向高層膠囊單元更新。在網絡訓練結束后可確定膠囊網絡模型的權重參數,獲得網絡模型。
2.3.6 圖像識別
在圖像識別時,將圖像進行預處理輸入網絡模型。圖像經卷積層提取特征,主膠囊層將特征張量向量化,利用訓練后的權重參數,通過動態路由算法獲得43 個類別的向量,向量的模長為各類別的概率,并將概率最大的類別作為分類的最終結果。
2.4 算法實現
交通標志識別算法流程如圖5所示。
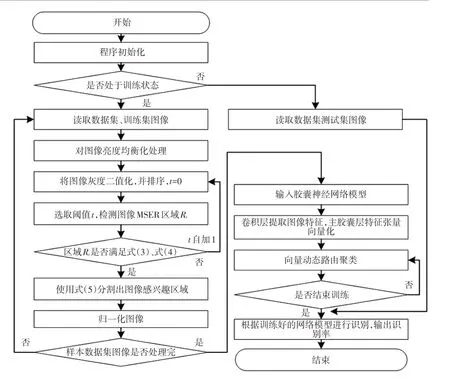
圖5 交通標志識別算法流程
3 仿真結果分析
仿真采用Ubuntu 18.04(64 位)操作系統和TensorFlow平臺,處理器為Intel?Core?i7-8700 CPU@3.20 GHz×6,使用NVIDIA RTX2060實現GPU加速訓練。
3.1 數據集準備
為驗證算法有效性,將其在如圖6所示的德國交通標志數據集(Germany Traffic Sign Recognition Benchmark,GTSRB)上進行測試,該數據集包含43種不同類型的交通標志圖片。由于GTSRB原始數據中存在很多分辨率低、運動模糊、局部遮擋、尺寸不一、光照強度不同的低質量數據,因此在數據集中添加現實場景拍攝的圖像替換部分低質量圖像,共獲得51 839張圖片的數據集,包括39 209張圖片的訓練集和12 630張測試圖片。

圖6 GTSRB數據集示例
3.2 圖像ROI提取結果分析
圖7展示了本文算法的圖像ROI提取過程,在對圖像分割時利用MSER進行交通標志分割,得到交通標志候選區域,然后利用該區域的幾何特征縱橫比、周長、面積等特征獲得交通標志所在區域位置。
為與其他算法進行比較,選用查全率Rc進行評價:

式中,NT為檢測到的交通標志數量;NZ為圖中含有的交通標志總數量。

圖7 提取ROI過程
選取846 張正常光照圖片和360 張弱光照圖片,采用HOG[4]、MSER[5]、DtBs[6]和本文算法提取圖像ROI,計算查全率和標志平均檢測時間,結果如表1所示。
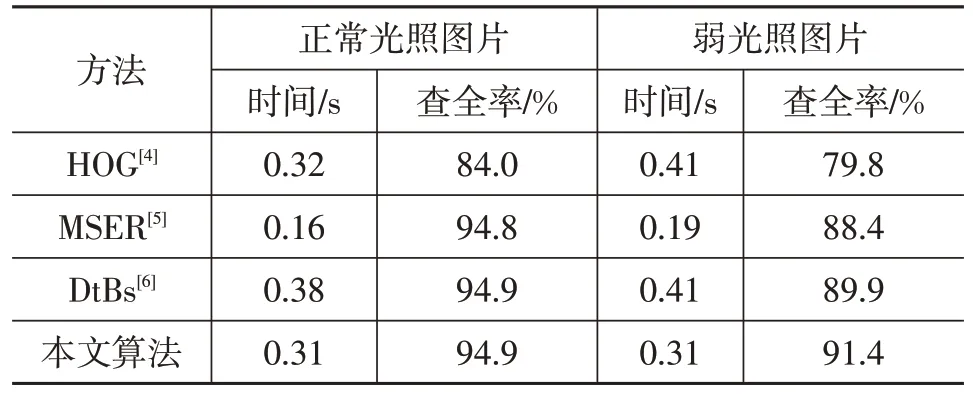
表1 在不同光照下檢測算法比較
由表1可知:本文算法、MSER和DtBs對正常光照圖片的交通標志檢測效果較好,本文算法的查全率略大于MSER和DtBs,但三者相差不大;針對弱光照圖片,本文算法對圖像亮度的均衡化可有效抑制光照對交通標志造成的影響,同時采用MSER 方法分割交通標志,避免了使用顏色閾值分割時,閾值不準確造成的漏檢,在光照條件較差(夜晚)的情況下也能有效檢測交通標志,故本文算法的查全率大于MSER、DtBs 和HOG。MSER 沒有判斷圖的形狀等特有特征,故其平均圖片提取時間較短。本文算法在MSER基礎上增加了對形狀的判斷,稍微延長了標志檢測時間,但小于DtBs和HOG算法。
3.3 網絡訓練過程性能分析
網絡訓練完成后,繪制出CNN 和本文算法在交通標志訓練過程中的識別率和損失曲線。網絡識別率隨訓練次數的變化曲線如圖8 所示,訓練開始后,當訓練次數達到10 000 次時,CNN 和本文算法模型的識別率達到98%以上,但是本文算法在訓練次數更少的情況下達到98%以上的識別率,當訓練次數達到60 000 次時,本文算法的識別率較CNN 更高。以上仿真結果表明,在網絡訓練過程中本文算法可更快達到較高的識別率且其識別效果更好。
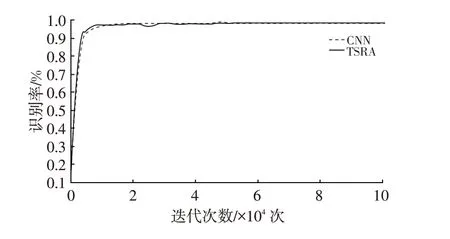
圖8 訓練時CNN和本文算法的準確率比較
CNN 和本文算法網絡訓練過程損失隨訓練次數的變化曲線如圖9所示:本文算法訓練的損失從網絡訓練開始時即在1以下,且在訓練100次后下降至0.5以下;CNN 在訓練10 000次后網絡的損失才下降到0.5以下,且訓練的整體損失較本文算法高。以上結果表明,在網絡訓練過程中,本文算法比CNN訓練收斂更快,可有效縮短訓練時間,具有更好的實時性和更高的識別率。
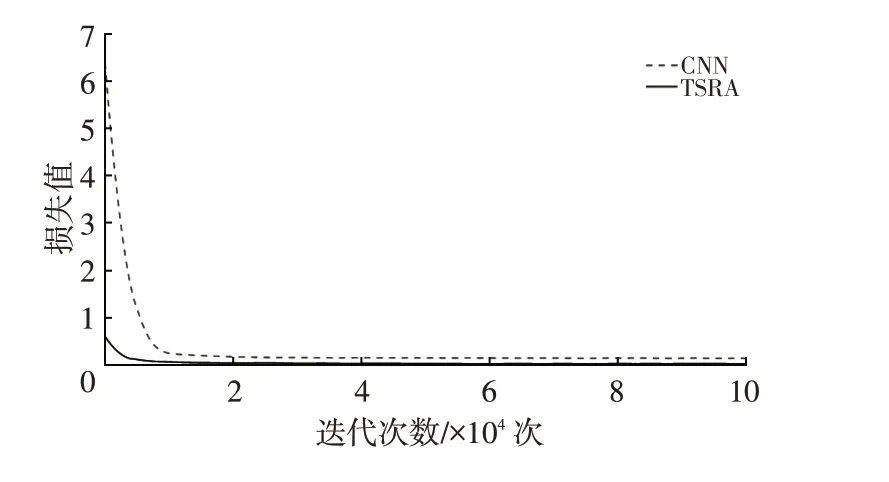
圖9 訓練時CNN和本文算法損失比較
3.4 模型性能分析
利用未經數據增強的訓練集圖像進行網絡訓練,根據訓練模塊采用CNN 和本文算法對經平移、旋轉和縮放的測試圖像進行識別,計算識別率,如表2所示:CNN網絡由于池化層的存在會丟失圖像部分空間特征,導致在識別任務中表現較為遜色,識別率下降約10%;本文算法中的CapsNet 網絡結構未使用池化層,而是使用動態路由聚類進行圖像分類,本文算法可獲得圖像底層空間特征信息且不丟失,使其能夠更好地分類交通標志,其識別率基本沒有變化,不受圖像空間變換的影響。
為了驗證ROI提取方法對交通標志識別的影響,比較加入提取ROI 前、后的識別率。結果表明,在不進行圖像ROI提取的情況下,交通標志識別率為93.1%,經過提取圖像ROI提取操作后,識別率可以達到97.2%,使用ROI提取方法可以很好地改善交通標志識別效果。
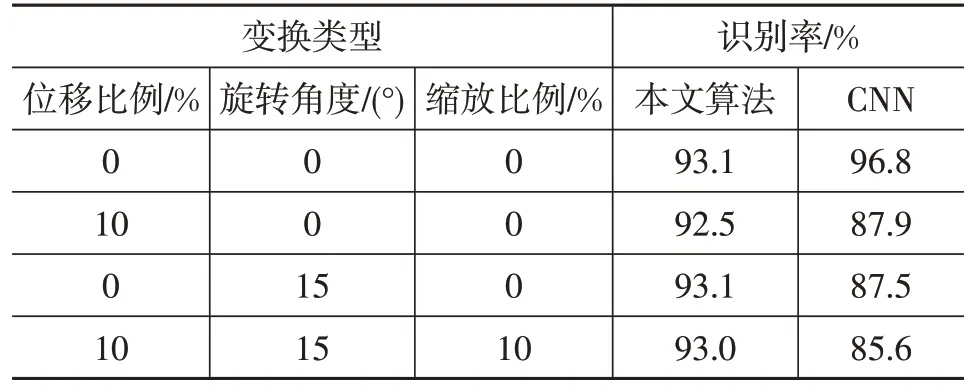
表2 圖像空間變換的識別效果比較
在選擇卷積層卷積核大小時,卷積核較大可以獲取較多的特征值,但提取圖像的參數較多。為測試CapsNet網絡卷積層提取底層特征能力,通過設置5×5、8×8、9×9、12×12共4種不同大小的卷積核,經過訓練后計算圖像的識別結果,識別率分別為91.7%、92.4%、93.1%和92.7%,選擇卷積核大小為9×9的卷積層最適合本文網絡結構。
使用卷積核大小為9×9 的卷積層時本文算法不受空間變換的影響,具有較好的識別效果,且加入ROI 提取,減少一些無關特征提取,提高了識別率。
3.5 算法識別率比較
比較經典LeNet-5[11]、AlexNet[12]、GoogLeNet[13]、CNN、SVM 和本文算法的識別率。如表3 所示:LetNet 和AlexNet屬于輕型卷積網絡,結構簡單,能夠快速完成圖像的識別任務,但其網絡深度和圖像特征的表達能力不足;GoogLeNet 和CNN 屬于深層的卷積網絡,深度特征具有很強非線性表達能力,但其網絡需要很長的訓練時間;本文算法網絡訓練時間較短,識別率最高。
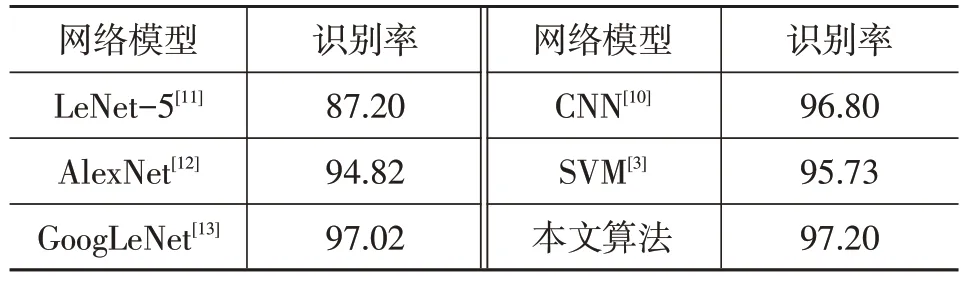
表3 算法識別結果比較%
4 結束語
本文采用ROI 提取方法和利用膠囊網絡提出了一種基于膠囊神經網絡的交通標志識別算法,在一定程度上解決了傳統算法在訓練過程中的特征丟失、交通標志識別網絡魯棒性差和識別率低等問題。仿真測試結果表明:該算法在預處理和識別圖像過程中能較好地檢測交通標志所在區域,可有效提取圖像ROI,提高弱光條件的查全率,增強魯棒性;在訓練階段,由于本文算法網絡結構簡單,具有較快的訓練速度,可縮短訓練時間;相較于經典的LeNet-5、AlexNet、GoogLeNet、CNN 和SVM 算法,本文算法的識別率更優。目前采用的數據集較小,因此下一步工作是在龐大的數據集上驗證網絡的識別能力,同時改進膠囊單元間的路由算法,提高識別率。
