一種基于文本相似計算的校園智能問答系統設計
2019-09-10 07:22:44李月周江
現代信息科技 2019年22期
李月 周江

摘? 要:問答系統是繼搜索引擎之后誕生的又一用來幫助用戶在海量數據中提高檢索效率的系統。目前常見的問答系統主要應用于商業領域,針對在校學生這一特定用戶群體的智能問答系統并不多見。本文在分析問答系統現狀以及建設難點的基礎上,提出了一種面向學校這一特定領域的,用來提升在校學生學習、生活質量的校園智能問答系統建設方法,并從語料庫建設方法、問題及答案提取等多個方面進行了詳細闡述。
關鍵詞:問答系統;文本處理;相似度計算;語料庫
中圖分類號:TP311.52 ? ? ?文獻標識碼:A 文章編號:2096-4706(2019)22-0009-05
Abstract:Question Answering System(QAS) is a system that appears after the search engine to improve the retrieval efficiency of users in massive data. At present,the common QAS is mainly used in the business field,but the intelligent QAS for the students in school is rare. Based on the analysis of the current situation and difficulties in the construction of question answering system,this paper puts forward a construction method of campus intelligent question answering system,which is oriented to the specific field of school and is used to improve the quality of students’study and life. It also elaborates on the construction method of corpus,the extraction of questions and answers and so on.
Keywords:question answering system;text processing;similarity computing;corpus
0? 引? 言
隨著互聯網的快速發展,網絡上流通的信息日益增加,人們所面臨的問題不再是信息的貧乏,而是信息過載的問題。搜索引擎是目前常見的一種解決信息過載的通用解決方法,人們可以通過使用諸如百度、谷歌、360搜索等系統實現從海量數據里檢索自己需要的信息。但是對于一個通用型的搜索系統來說,系統往往提供的也是大量存在冗余的搜索答案,用戶還需要進行二次檢索和分析才能取得自己真正需要的數據。在此情形之下,問答系統被開發出來并且搭載在各類系統上,成為系統解決用戶疑問的一種輔助手段。針對特定用戶設計和開發高效問答系統,可以有效解決信息過載的問題,提高用戶使用系統的效率。
目前常見的問答系統通常針對商業領域。在信息檢索需求上,除了商業領域的需求之外,還有很多非商業需求。如在校學生在學校生活中往往會遇到各種問題,而這些問題又不具備共通性,即這個學校的學生遇到的問題可能其他學校的學生并沒有遇到過,或者這個學校的學生遇到的問題在這個學校的規章制度下具有特定的解答。因此,針對非商業應用的特定領域開發智能問答系統,能較好地解決該領域下用戶的疑問,方便該領域用戶的生活。本文即針對在校學生開發特定的非商業應用的智能問答系統,提升在校學生這一龐大用戶群體在校園生活中使用信息數據的質量。
1? 問答系統現狀
問答系統的雛形最早誕生于七十多年前,國外科學家希望計算機能像人一樣去理解和處理人類自然語言,但是受硬件設備和計算算法的限制,直到1980年左右,問答系統才開始真正受到人們的關注。計算科學之父圖靈表示,具有人工智能的計算機應該能夠像人類一樣理解自然語言并進行交流[1]。隨后人們開始關注并開展基于自然語言理解的研究和開發,越來越多的公司和研究機構也投入到基于自然語言處理的問答系統中來。
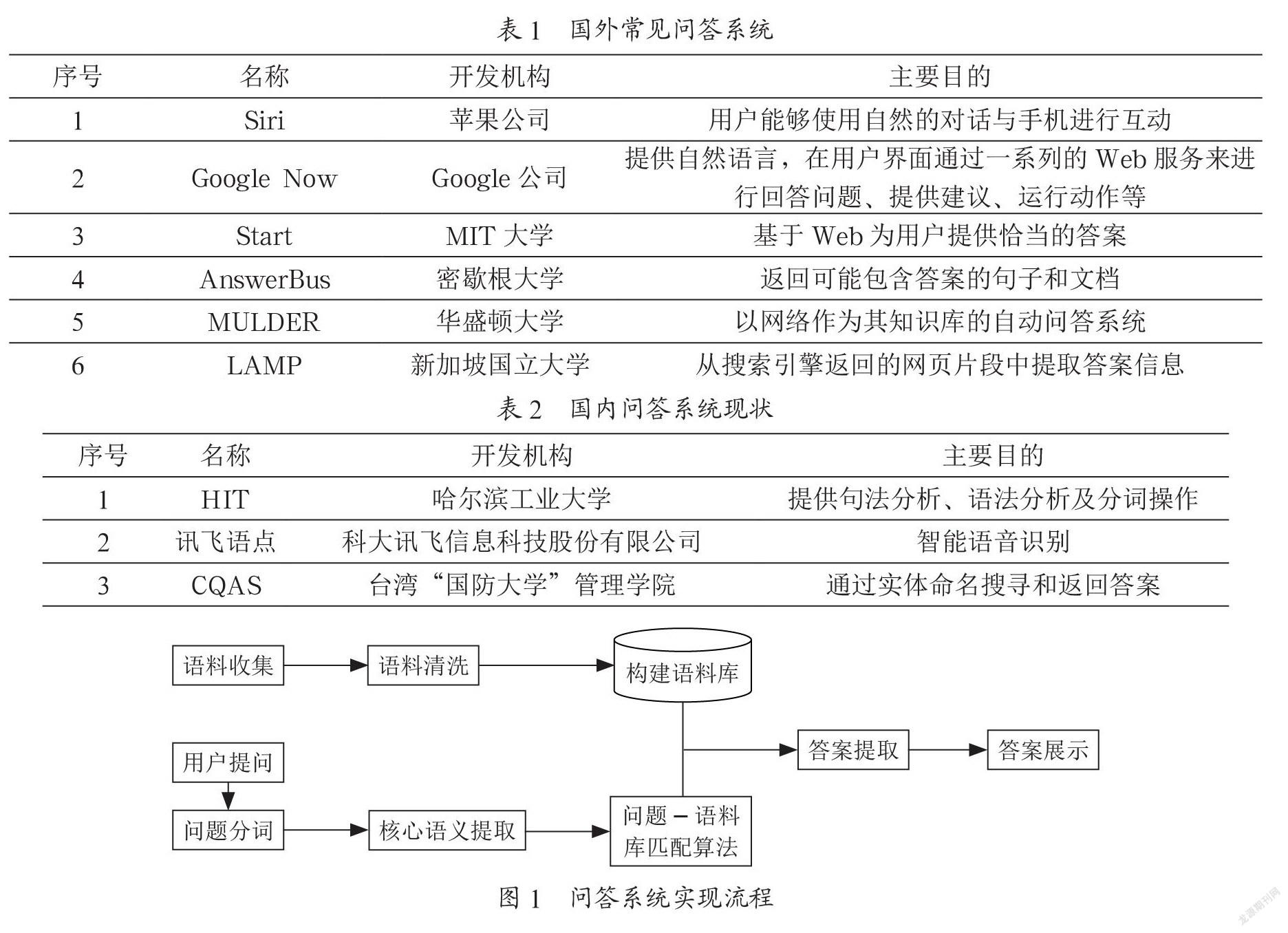
國外在問答系統技術上的研究起步比較早,目前在工業界或者學術界已經產出了一些比較成熟的問答系統和聊天機器人系統,例如,蘋果公司的Siri,谷歌的Google Now,MIT大學的Start系統,還有AnswerBus、MULDER、LAMP等,其開發機構和使用目的如表1所示。
與國外研究相比,國內的問答系統發展較為緩慢。主要原因在于中文的信息處理與英文、法文、德文等語言體系不同,在語義解析、詞法分析上較為困難,在將國外現有的問答系統遷移到中文系統上時存在較大的語言差異鴻溝。另外,問答系統的構建基礎之一是語料庫的建設,基于中文的問答系統在構建時需要重新設計和建立語料庫,也無法重用國外現有系統的語料資源,因此提升了中文問答系統的建設難度。
國內在問答系統領域走得比較靠前的研究機構主要有清華大學、北京大學、中科院計算所、哈工大、北京語言大學等,另外研究漢語問答系統的還有香港大學、香港中文大學等單位[1]。目前國內常見的問答系統如表2所示。
2? 問答系統關鍵技術
在中文問答系統的實現中需要經過語料收集、問題解析、答案提取及答案展示幾個階段,具體實現流程如圖1所示。
在系統實現過程中,首先需要構建龐大的語料庫。語料庫內容的廣度與深度決定了問答系統中答案的質量。如果語料庫過小,則問答系統會遇到答案抽取失敗的情況。如果語料庫質量過低,則在問答過程中則會出現“答非所問”的情形,同樣會影響用戶體驗。但是要構建一個高質量的龐大語料庫,需要花費大量的時間及硬件資源。本文所探討的系統設計針對特定領域,即主要針對學校這一特定環境開發智能問答系統,因此在語料庫的建設上必須針對特定領域收集、整理數據。除語料收集具有特定性之外,智能問答系統在建設上還具有分詞技術、語義消歧等通用型的問題需解決。
2.1? 中文分詞
中文分詞是自然語言處理過程中的一個技術問題。在問答系統中,用戶的提問是一個完整的句子,里面的內容從形式上看是一個一個的漢字,但是從語義理解上來看,里面包含的既有單個漢字也有連續的詞語。中文分詞技術就是將漢字序列切割成一個個單獨的詞語。與英文分詞不同,英文的句子里單詞和單詞之間以空格作為分界符,因此英文分詞技術相對來說簡單很多[2]。中文句子里通常只包含逗號(,)、分號(;)、頓號(、)等分隔符,分隔出的也是一段具有完整含義的內容,并不存在分隔符將詞與詞隔開,因此中文分詞要顯得復雜而困難。
目前常見的中文分詞技術主要基于以下三種:基于字符串匹配的分詞方法、基于理解的分詞方法和基于統計的分詞方法[3]。基于字符串匹配的分詞方法又叫作機械分詞方法,該方法將需要分解的句子按照一定的規則與一個足夠大的詞典進行逐詞掃描匹配,如果在這個足夠大的詞典中能找到某個一致的字符串,則將這個詞識別出來并將其與周圍的字分隔開。按照掃描方向的不同,串匹配分詞方法可以分為正向匹配和逆向匹配;按照不同長度優先匹配的情況,可以分為最大(最長)匹配和最小(最短)匹配;按照是否與詞性標注過程相結合,又可以分為單純分詞方法和分詞與標注相結合的一體化方法[4]。
基于理解的分詞方法是通過算法讓計算機模擬人識別句子的過程,將輸入的句子切割成單個單詞。但是由于漢語的語言系統歷經幾千年的發展,具有其特有的復雜性、概括性等特點,難以將中文像英文等西方語言體系一樣較好地轉化為計算機可以理解的形式,因此目前基于理解的分詞系統還處在試驗階段。
基于統計的分詞方法主要是采用基于統計學的知識對文本進行識別并分詞。從漢語語言的使用習慣上來看,中文詞是一種相對穩定的字與字的組合,如果一個字與另一個字相鄰出現的頻率越高,則這兩個字構成詞語的可能性就越大。基于統計的分詞方法就是統計字與字相鄰出現的頻率或概率,通過設定一個概率閾值判定是否構成詞語[5]。目前基于概率統計的分詞方法應用也較為廣泛,但是該方法也有一定的缺陷,即會在詞語抽取上抽取出一些經常搭配出現,但是在語義上并不構成詞語的“偽詞”。
2.2? 語義消歧
中文問答系統構建中還需要解決的一個問題是語義歧義的問題。與英文詞語不同,英文單詞是天然有間隔的,計算機在分析句子的時候不存在會將一個單詞的一部分與另一個單詞的一部分連接起來從而構成新詞去理解的情形。但是基于中文系統中詞語間不存在間隔的現狀,中文問答系統在理解句子時可能會出現對詞語存在多種解答的情況。例如一個句子“我家門前有條大河很難過”,這里面可以分割出“我家”“門前”“有”“條”“大河”“很”“難過”一種分詞結果,也可能分割出“我”“家門”“前”“有”“條”“大河”“很”“難過”這另一種分詞結果。這兩種分詞下體現的語義就完全不同。在漢語體系里,“家門”和“門前”是完全不同的含義。此外,即使是同一種分詞結果,系統在理解上也可能存在歧義。如上一句的分詞結果:“我家”“門前”“有”“條”“大河”“很”“難過”,其中對于“難過”一詞的理解也會存在不同含義。“難過”可以表示心情低落不開心,也可以表達動作上難以通過的意思,系統在理解上同樣可能存在歧義。
2.3? 未登錄詞識別
問答系統對于問題的理解是基于語料庫知識的理解,而語料庫的創建具有時效性,可能會出現在問答過程中出現語料庫未收集詞語的情況。在自媒體與微媒體日益發達的今天,用戶的語言習慣也發生了巨大的改變,許多基于互聯網的新詞層出不窮并且擴散速度很快,很可能有一個詞上個星期還不存在,但是這個星期人們在互聯網上已經開始大面積使用了。這些未被收集及識別的詞即稱之為“未登錄詞”。常見的未登錄詞包含一些人名、地名、公司名、互聯網流行語等等。在問答系統中,對于新詞的收錄更新率也成為了問答系統用戶體驗度的檢驗標志之一。
2.4? 短文本語義提取
在問答系統中,用戶的提問往往就是一兩個簡單的句子,文本篇幅較短。對于用戶提問,要抽取正確答案,還需要理解用戶提問數據的核心內容,也就是需要對用戶問題實現核心語義提取。在用戶語義提取上,即需要理解用戶問題的關鍵詞,也需要結合用戶問題的語境,還需要綜合考慮用戶提問時的上下文環境,在多方面數據信息結合的基礎上,才能夠正確理解用戶問題的核心本質,從而從語料庫中抽取最符合該問題的答案[6]。目前關于自然語言處理中的核心語義提取主要還是基于關鍵詞的提取方式。
3? 特定領域問答系統構建方法
本文主要針對校園環境這一特定領域用戶構建智能問答系統,因此系統構建不論從用戶分類、使用目的、語料庫構建上都存在與學校這一特定環境相關的特定內容。與通用型的問答系統不同,針對校園環境構建的問答系統用戶主要面向在校學生,他們希望獲取的信息內容主要和在校生活相關,如課程相關問題、學籍管理問題、校園制度問題、后勤管理問題等。除此之外,也存在校外游客需要針對校園相關問題提問并獲得解答。因此,針對校園領域的智能問答系統的用戶主要包含以下三種,如表3所示。
3.1? 語料庫構建
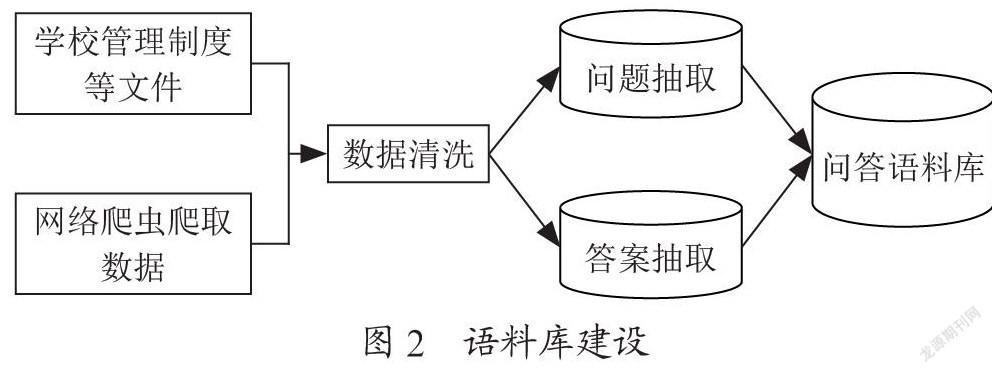
針對校園環境這一特定領域的問答系統在語料庫構建上并無太多可以借鑒的已有語料知識,主要原因在于不同的學校具有不同的管理制度,數據信息存在較強的個性化特點,因此要構建一個智能化的校園問答系統,首先需要收集各類校園相關的數據資料作為語料庫構建的基礎。語料來源可以是學校的有關規章制度、工作手冊或管理規范,也可以來源于學校在信息化建設中形成的網絡數據信息。對于網絡數據信息可以采用爬蟲技術爬取相關內容,然后經過數據清洗形成可以進入語料庫的數據。在語料庫構建上可以采取基于以下流程的建設方法,如圖2所示。
對于獲得原始語料信息,需要將長文本切割成短文本以方便實現問題和答案的抽取。對于整理形成的短文本,還需要運用分詞技術提取文本核心信息。目前常見的中文分詞工具包括開源及商業應用兩種,應用較為廣泛的開源分詞工具包括HanLP、結巴分詞、FudanNLP分詞、THULAC分詞等,這些工具在實現上涵蓋了支持Java、C++、Python等主流編程語言的實現方式。雖然不同工具分詞的準確率和時間效率有所差異,但是對于校園環境下的問答系統建設而言,這些開源工具的分詞結果都是可以接受的。
3.2? 文本相似度量算法
在構建盡可能完善的語料庫的基礎上,提高問答系統效率、提升用戶使用感受的另一影響因素是對用戶問題在語料庫中的匹配檢查。因為問答系統中用戶提交的是文本數據,因此在語料庫中尋找與用戶問題匹配的答案時最關鍵的技術就是基于文本相似度的計算。
目前基于文本的相似度計算主要包含三種方法[7,8]。第一種是基于單詞重疊數量統計的計算方法。該方法主要分析兩個不同的文本中相同單詞重疊的數量,數量越多,則認為兩個文本越接近。但是這種方法僅僅考慮單詞出現的數量而不考慮單詞出現的位置,以及其他單詞對文本語義的不同貢獻,屬于較為粗略的文本分析方法,在使用過程中也常常會出現提取共性失敗的情況。第二種方法是基于單詞語義相近度度量的方法。該方法通過將單詞轉換成向量,計算不同向量之間的相似程度來衡量不同單詞的相似性。該種方法解決了中文中同一含義可能有不同表達方式的情況,比起機械衡量兩個單詞是否一樣更加切合問答系統的實際使用情形,但也存在無法整體解析句子含義、上升到句子層面整體衡量相似度的缺陷。第三種方法是以句法作為衡量依據,通過計算兩個句子之間的相似程度提取問題核心。該種方法更加符合用戶實際情況,可以減少問答系統中提取失敗或者對應到語料庫時問題精確度低的情況。本文設計的問答系統主要針對句子進行相似度的計算。
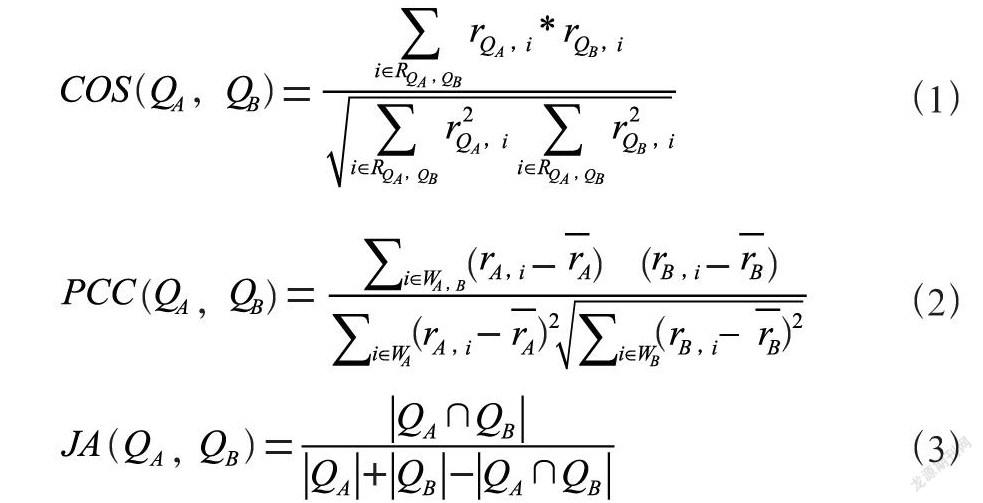
針對文本進行相似度計算首先需要將中文文本轉換成計算機可以識別并計算的形式。通常情況下是將文本轉化為一個向量矩陣。對于學校領域下的智能問答系統,首先可以將用戶問題轉化成向量Q,其中Q=(q1,q2,q3,…,qn),其中Q表示問題向量,qi表示向量中的第i個維度。對于兩個文本向量,可以對其相似度進行計算。常用的相似度計算方法有余弦相似度計算(COS)、皮爾森相關系數計算(PCC)、Jaccard系數計算(JA)等方式,對于兩個問句A和B,其計算公式如下:
在文本相似度計算中,不同的相似度計算方法帶來的計算結果也各不相同。因為本文探討的智能問答系統中,用戶提問往往是一兩個簡短的句子,因此收集到的文本屬于較短的文本類型。對于短文本通過轉化形成的向量,往往具有較低的維度。因此,在計算問答系統中的提問文本相似度時,對于低維度數據,選用Jaccard系數進行計算比較有計算優勢。
3.3? 相似度閾值
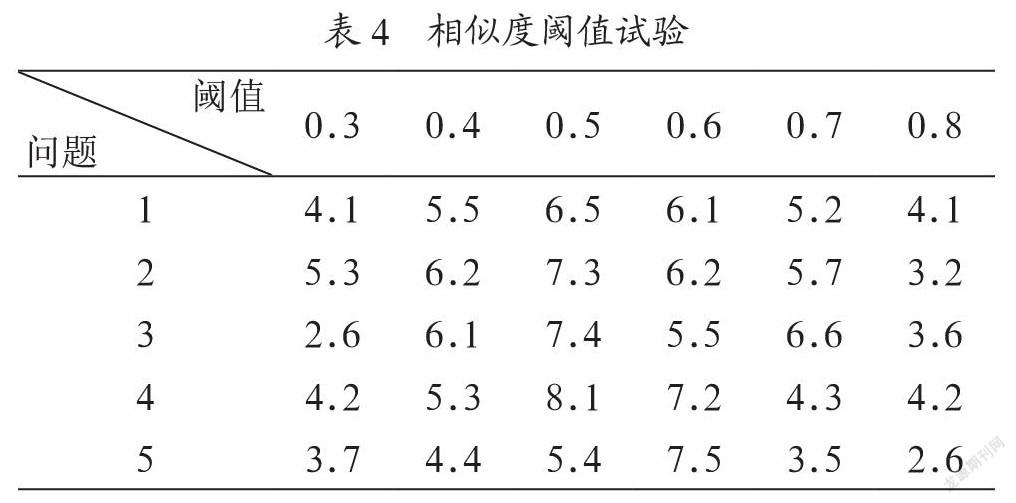
對于計算得到的相似度數據,還需要根據實際情況設置相似度閾值。如果相似度閾值設置過高,那么在系統實際運行過程中會出現用戶問題在語料庫中找不到匹配問題的情況,導致系統無法給出回答,會極大地影響用戶體驗感受。同時,如果相似度閾值設置得過低,則會在系統運行中出現用戶的一個問題可以在語料庫中匹配到多個答案的情況,這樣系統實現的效果將與普通搜索引擎毫無區別,用戶依然需要從大量數據中二次檢索答案。因此,一個合理的相似度閾值設置在系統設計中至關重要。在本文中,為找到短文本相似度設置的最佳閾值進行了多次試驗,在相同語料庫的基礎上,采取50名志愿者對系統給出的答案進行評分(10分記為滿分),每個問題的評分取50個用戶的評價平均值。每個問題在語料庫中搜索答案時,相似度閾值分別從0.3、0.4、0.5遞增至0.8。對于不同問題在相同語料庫下獲得的答案滿意度試驗數據如表4所示。
表4? 相似度閾值試驗
從上表數據可以看到,在相似度閾值較低和較高的情況下,用戶評分都不理想,在相似度閾值為0.5或0.6時可以取得試驗中較為滿意的評價。但是需要注意的是,用戶滿意度除了與相似度閾值的設定有關系之外,還和語料庫的大小有關。只有在語料庫數據充分涵蓋用戶實際生活中會遇到的問題時,用戶才能獲得較好的問答體驗。否則在語料庫不充分的情形下,即使將相似度閾值設置為試驗取得的最好數據,用戶也會產生較差的用戶體驗。
4? 結? 論
問答系統經歷了多年的發展,已經取得了一定的成就。但是目前的問答系統一般針對商業應用領域,針對在校學生構建的問答系統并不多見。我國現有2000余所高校,在校學生人數超過3000萬人,針對這一龐大的用戶領域構建面向學生的問答系統具有較高的應用價值。但是針對特定領域的問答系統構建不論從語料庫的建設還是問答方式的設計上都需要針對領域問題尋找最適合的方法。在本文探討內容的基礎上,還可進一步研究在智能問答系統中加入語料庫自動增長、語料庫自動糾錯的設計,從而使得面向學校這一特定領域的問答系統具有更高的智慧。目前問答系統雖然已有一定的建設成果,但是在大數據和人工智能蓬勃發展的今天,面向特定領域的問答系統也還有更多的建設細節亟待建設者去思考和探索。
參考文獻:
[1] 馮升.聊天機器人問答系統現狀與發展 [J].機器人技術與應用,2016(4):34-36.
[2] 黃偉,范磊.基于多分類器投票集成的半監督情感分類方法研究 [J].中文信息學報,2016,30(2):41-49+106.
[3] 王朝.面向網上訂餐的垂直搜索引擎的設計與實現 [D].成都:電子科技大學,2016.
[4] 徐曉.智能答疑系統的設計與研究 [J].微型機與應用,2014,33(5):8-10.
[5] 雷鵬飛.輿情系統中特征選擇和情感分析的研究與實現 [D].成都:電子科技大學,2017.
[6] 郭浩,許偉,盧凱,等.基于CNN和BiLSTM的短文本相似度計算方法 [J].信息技術與網絡安全,2019,38(6):61-64+68.
[7] 趙永標,張其林,谷瓊.社區問答系統中基于當前興趣的問題推薦研究 [J].現代信息科技,2019,3(11):1-4.
[8] 張明輝.情感分析在商品評論中的應用 [J].現代信息科技,2019,3(10):187-190.
作者簡介:李月(1979-),女,漢族,湖北荊門人,講師,碩士研究生,研究方向:機器學習、人工智能、軟件工程。
